
融合kmeans 聚类与Hausdorff 距离的点云精简算法改进
2022-09-01 15:09彭海驹严科文赖浩源张泽鑫
地理空间信息 2022年8期
彭海驹,严科文*,林 松,赖浩源,张泽鑫
(1. 惠州市自然资源规划勘测院,广东 惠州 516000)
随着三维激光扫描技术的不断发展,点云精简成为高效处理海量的点云数据重要技术手段。常用的点云精简方法有体素下采样法[1]、曲率采样法[2]、基于聚类的精简方法、随机采样法。相关研究人员对几种方法分别进行探讨,归纳出其面临的问题有容易丢失特征点数据、精度较差、曲率估算精度较差问题等[3-4]。针对上述问题,本文对融合kmeans 聚类与Hausdorff距离的点云精简算法进行改进,基于其对特征区域和非特征区域采用不同特征点提取策略的原理,在非特征点区域仍然采用kmeans 聚类算法提取特征点,但采用手肘法确定聚类数,保证聚类精度。在特征区域采用维数特征Hausdorff 距离代替主曲率Hausdorff 距离提取特征点,避免了曲率的估算和在曲率值过小时设定Hausdorff 距离阈值,最后融合kmeans 聚类簇心与采用维数特征Hausdorff 距离提取的特征点实现数据精简。
1 融合kmeans与Hausdorff距离的点云精简算法
1.1 kmeans聚类算法
kmeans 聚类算法中的k代表聚类个数,means 代表取每一个聚类中数值的平均值作为该簇的中心,即每一个簇都用这个类的中心描述[5]。这种聚类算法容易实现,其具体实现流程如下:
1)确定簇的个数k。
2)计算各个采样点到簇中心的距离,一般是欧氏距离。
3)根据新划分的簇,更新“簇中心”。
4)重复步骤(2)和步骤(3),直到“簇中心”不再移动。
1.2 Hausdorff距离
Hausdorff距离是一种描述两组点集之间相似程度的量度[6-7],若存在两组数据点A={a1,a2,…,an} ,B={b1,b2,…,bn} ,则这两组数据的单向Hausdorff 距离为:

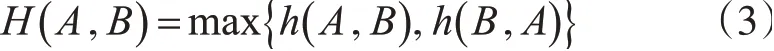
1.3 算法描述
融合kmeans 与Hausdorff 距离的点云精简算法首先建立空间索引,然后基于局部点云数据拟合局部曲面,再通过拟合曲面估计采样点的2 个主曲率值。对于某一采样点pi和其邻域内某点qj的主曲率分别为k1、k2和k1'、k2',则采样点与其邻域内点曲率的Hausdorff距离计算公式如下:
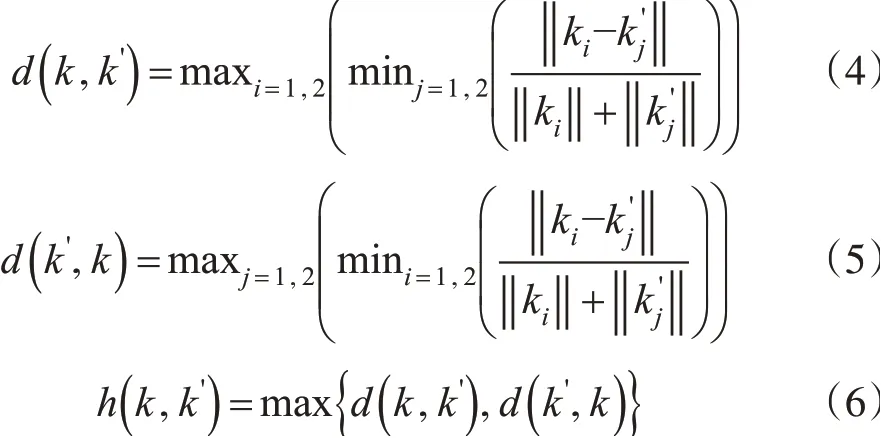
因此,采样点pi的Hausdorff距离可以表示为:
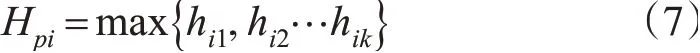
该方法通过设定Hausdorff距离阈值实现特征点云的提取,然后对于非特征区域采用kmean 算法聚类,将每个聚类中心作为非特征区域的特征点与通过Hausdorff距离阈值提取的特征点融合完成精简。
2 改进的融合kmeans与Hausdorff距离的点云精简算法
2.1 手肘法
手肘法是一种确定数据聚类最优聚类数的方法[8],李健[4]等采用平均密度计算kmeans聚类数,并没有考虑聚类精度,对于聚类结果通常采用SSE作为精度检验指标,其计算公式如式(8)所示。而手肘法的核心思想就是使得SSE 最小。对于kmeans 来说,k值取得越大,则样本的划分更加精细,每个簇的聚合程度更高,则SSE越小。并且,当k的取值小于真实聚类数时,SSE 会随着k值的增大迅速下降;当k达到真实聚类数时,SSE 的下降幅度会骤减。随后继续增大k值,SEE 会慢慢趋于平缓。SSE 和k值的关系图与一个手肘相似,而这个肘部对应的k值就是真实聚类数。

式中,Ci为第i个簇;p为Ci中的采样点;mi为Ci的质心。
以斯坦福大学兔子点云为例,其原始点云数据如图1所示,共8 171个点。采用手肘法,以100个聚类数作为步距,计算聚类个数在100~8 000 的SSE 值,结果如图2 所示。图中随着k值的不断增大,SSE 不断减小,且整个图形符合手肘法的趋势。分析图2 可知,当k小于1 000时,SSE的下降幅度较大;当k大于1 000时,SSE开始缓慢下降,故对于该兔子点云数据的聚类个数可取值为1 000,图3 为k取1 000 时兔子点云聚类效果图。

图1 原始兔子点云

图2 聚类个数与SSE间关系
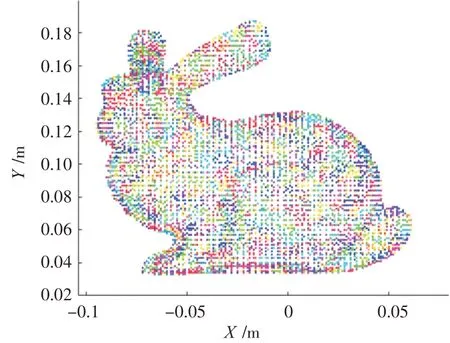
图3 k=1 000 聚类结果
2.2 维数特征
主成分分析法(principal component analysis,PCA)是一种数学降维方法[9],能够将原来变量重新组合成一组新的互不相关的几个综合变量,从综合变量中选取部分综合变量能较完整的反映原来变量的统计信息。对于采样点P,其邻域点集为Pi=[xi yi zi],则可以通过式(8)得到P点的协方差矩阵M。

式中,k为P点邻域点个数;Pˉ为P点邻域点集的质心点坐标;M是一个对称半正定矩阵,故其矩阵的3 个特征值都为非负值,对于点云数据,则这3 个特征值所对应的特征向量为两两正交的向量。
对采样点P邻域内点集进行主成分分析可以得到3 个特征值λ1、λ2、λ3,其中λ1≥λ2≥λ3,这3 个特征值之间有以下关系:
1)λ1≥λ2≥λ3时,局部区域表现为线型,如图4a所示。
2)λ1≈λ2≥λ3时,局部区域表现为面型,如图4b所示。
3)λ1≈λ2≈λ3时,局部区域表现为球形,如图4c所示。

图4 特征分析示意图
依据3个特征值按式(9)定义了维数特征[10],其中,a1D+a2D+a3D=1。特征维数描述了局部区域点云数据的空间分布特征。
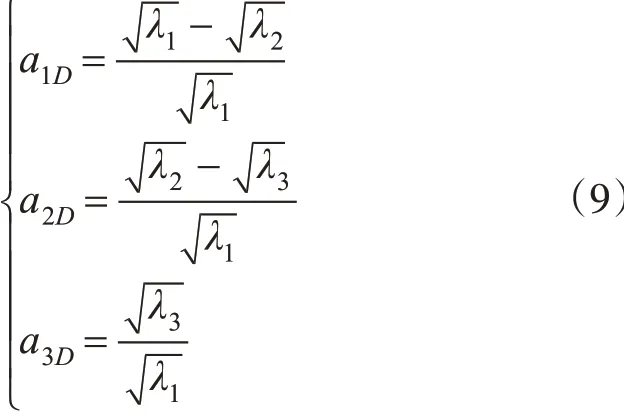
2.3 改进后算法
在李健[4]等提出的融合kmeans 与Hausdorff 距离点云精简算法的基础上,先采用维数特征的Hausdorff 距离提取特征点,再对剩余非特征点利用手肘法确定最优聚类数,以每个聚类中心点作为非特征区域内的特征点,保证数据均匀,不造成空洞。改进后的算法首先避免了在平面区域曲率值过小而需要设定阈值的问题,同时在确定聚类数中也保证了聚类精度。
对于某一采样点pi和其邻域内某点qj的特征维数分别为a1D、a2D、a3D和则采样点与其邻域内点维数特征的Hausdorff距离计算公式如下:
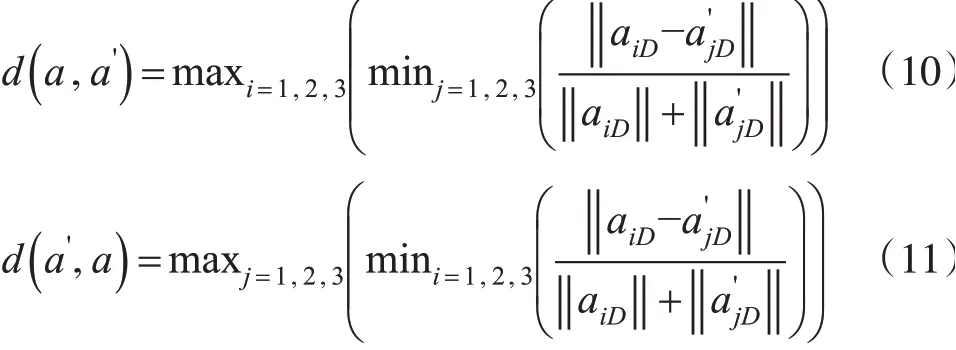
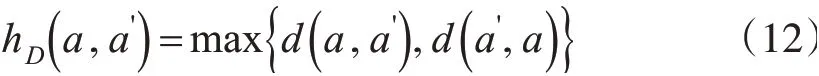
因此,采样点pi的维数特征Hausdorff 距离可以表示为:

3 实例验证与分析
采用Rigel VZ-1000扫描仪对某古亭建筑进行高密度多站扫描,依据标靶球粗配准后,再采用最近点迭代算法(iterative closest point,ICP)精配准,然后利用SOR算法去除少量体外孤点,利用拉普拉斯滤波算法平滑表面毛刺点,配准去噪后点云数据如图5a所示。
本文通过将改进的精简算法与李健提出的精简算法、基于曲率的精简算法、随机采样精简算法和体素下采样精简算法的实验结果进行比较,来评价改进后的方法,5 种精简方法实验结果如图5b、c、d、e、f所示。

图5 不同精简方法实验结果
原始点云个数为726 417个,采用5种精简方法将古亭点云都精简至20%左右。基于曲率采用和随机采样2 种方法在檐顶剔除了大量数据点,特别是基于曲率的精简方法造成了数据整体分布不均匀,本文方法、文献[5]方法和体素下采样方法都能够获得较为均匀的数据。图6为本文方法和文献[5]方法提取特征点和非特征区域内特征点的结果图,其中对于文献[5]中基于曲率Hausdorff距离提取68 415个特征点,如图6a所示;采用本文方法中基于维数特征Hausdorff距离提取70 791个特征点,如图6d所示;依据手肘法确定最优聚类个数约为70 000个,为保证相同精简率,对于文献[5]中剩余非特征区域依据剩余非特征点密度提取聚类中心点73 057个点,如图6b所示;本文方法对于剩余非特征区提取聚类中心7 000 个点,如图6e 所示;文献[5]方法和本文方法融合特征点和非特征区域特征点结果如图6c、f 所示。可以看出虽然提取的特征个数相同,但是本文方法的特征点相较于文献[5]方法在檐顶的特征点更多。

图6 2种Hausdorff距离提取特征点及非特征区域特征点图
为了定量分析5种精简算法的精简精度,对精简后的点云数据建立三角网,通过统计三角形个数和三角形总面积来评定精简精度[11-12]。统计结果如表1 所示。以原始点云三角形总面积近似为真值,采用其他5 种精简方法精简后的点云构建的三角网总面积都小于真值,符合精简后的数据精度有损失的规律,其中采用本文方法精简的结果最接近真值,其表面精度损失较少,即精简精度相对于其他4种方法精简精度较高。

表1 不同精简方法的结果比较
4 结 语
本文改进了融合kmeans 聚类和Hausdorff 距离的点云精简方法,通过对聚类数的确定和Hausdorff距离计算参数加以改进,提出了先通过计算特征维数的Hausdorff距离提取特征点,然后采用手肘法确定剩余非特征点的最优聚类数,将特征点和聚类中心数据融合作为点云精简结果的技术路线;最后通过实际扫描的古亭建筑的点云数据,分别采用本文方法,文献[5]方法、基于曲率采样、随机采样和体素下采样5 种方法进行精简实验,结果表明改进后的方法在相同的精简率下精度更高。
猜你喜欢
闽南师范大学学报(自然科学版)(2022年3期)2022-12-06
湖北大学学报(自然科学版)(2022年3期)2022-12-01
计算机技术与发展(2021年6期)2021-07-06
延安大学学报(自然科学版)(2020年4期)2021-01-15
家庭影院技术(2020年10期)2020-12-14
电子制作(2017年17期)2017-12-18
岁月(2015年3期)2015-04-03
视野(2013年5期)2013-08-15
燃气涡轮试验与研究(2010年4期)2010-04-16
当代人(2006年8期)2006-11-09
