
英汉翻译语法误译校正方法研究
——基于K均值聚类
2022-09-02 10:30吴南辉沈炎松
漳州职业技术学院学报 2022年2期
吴南辉,沈炎松
(1.漳州职业技术学院 国际合作学院,福建 漳州 363000;2.漳州职业技术学院 电子信息学院,福建 漳州 363000)
在自然语言处理领域内,语法校正逐步成为主要的研究方向之一。在机器学习方法持续发展进程中,越来越多的学者着手研究应用机器学习类算法实现语法的校正,以此规避以往语法校正的效率低及精度差等问题[1]。英汉翻译所涉及的两种语言体系在表达方式与语法上均具有极大的差距,无法完全通过直译的方式实现英汉翻译[2]。通常情况下,英汉翻译大多采用意译和直译两种方式,由于两种语言体系的结构存在差异,且所涉及到的文化因素也有所不同,导致意译存在一定的制约性,易出现误译问题[3-4]。另外,因不恰当的选词与专业知识不足等也易导致出现语法误译现象,降低英汉翻译的准确率,为实际应用带来不便。为有效解决以上问题,需选取出恰当的方法对英汉翻译语法误译实施精准高效的校正,提升英汉翻译的精确度[5]。为此,研究者进行了很多的研究。
文献[6]通过数据增广和复制的语法错误纠正方法将复制机制与自注意力模型相结合,生成文本语法错误纠正模型,实现文本语法错误的纠正,该方法可针对文本语法内的错误词汇实施纠正,但对于缺词与语序等语法问题效果不理想;文献[7]方法通过LSTM与N-gram结合的语法错误纠正,主要针对介、冠词错误实施纠正,通过将各类词汇构成词汇集用于LSTM模型内,并结合N-gram投票方法完成错误纠正,该方法可纠正语法内的介、冠词错误,错误纠正的平均F1值约为32.76%左右,但其纠错过程的耗时较长,整体效率不理想。文献[8]提出TF-IDF(特征频次-逆文档频次)特征提取算法,其本质为对词汇的出现频次权重以及各个文本之间的相似程度实施运算,获得此词汇的最优语法,达到提取语法特征的目的。该算法能够防止语法内语义及词汇的丢失,提取语法特征准确度高,可为语法误译特征提取及校正奠定扎实的基础。K均值聚类方法作为异常检测领域内的常用方法之一,其本质是运用不同类样本的中心作为各类的代表实施迭代,以此持续动态调节不同类中心实现聚类。其优点为自适应性强、自主性高等,其检测结果可随着样本分布模式的更换自主更新,整体检测性能较高[9-10]。
综合以上分析,本文研究一种基于K均值聚类的英汉翻译语法误译校正方法,以英汉翻译语法数据预处理与特征提取为基础,运用K均值聚类实现语法误译特征检测,构建误译校正模型,实现英汉翻译语法误译的校正,高效精准地校正英汉翻译语法内的各类误译问题,提高翻译的准确性,为使用者的使用提供便利。
一、英汉翻译语法误译校正方法设计
(一)英汉翻译语法数据预处理及特征提取
1.英汉翻译语法数据预处理
为了令所提取的语法特征能够直接应用到K均值聚类算法内,在提取英汉翻译语法特征之前,需对采集的英汉翻译语法数据实施数值化与归一化预处理[11]。
1)数值化处理:由于语法数据属于非数值属性,在K均值聚类算法内不能实施距离运算,故需将语法数据各维度的属性转化为数值。通过不同维度属性所呈现的频次将初始属性取代实现数值化,防止转化过程中相同属性各个值之间存在的不均等距离,导致聚类误差。
2)归一化处理:语法数据内的不同维度数值具有较大差距,为了更有效地运用各维度数据,需对不同维度数据实施归一化处理,处理算法为

某个维度内的最高与最低数据分别以Nmax和Nmin表示;待归一化数据以Xλ表示。
2.英汉翻译语法特征提取
在上述英汉翻译语法数据转换后,选取TF-IDF算法由预处理后的英汉翻译语法数据内提取语法特征,构成英汉翻译语法特征样本集[12]。通过对英汉翻译语法内文本的接近程度与词汇的出现频次权重,实施运算提取语法特征。其中,英汉翻译语法内词汇的权重可通过IDF和TF二者的乘积得到,在此基础上,将词汇的最佳语法提取到,运算式为

文档编号以b表示;词汇通过sl表示;W表示权重。
IDF的任务是提高出现频次较少词汇的关键度以及文本的差异性,其运算公式为

全部文档内所存在的i词汇数目以mi表示;英汉翻译文本内所包含的文档个数以M表示。
TF代表特征频次,其表达式为:

(二)基于K均值聚类的英汉翻译语法误译特征检测


(三)语法误译校正实现
1.误译校正模型构建


4)通过校正模型集Eall内的全部子模型依次对VTT-1向量实施校正,统计全部校正结果后实施投票;
5)输出整体的最终校正标记,当标记等于-1时,代表此语法存在误译;当标记等于1时,则代表此语法正确。
二、实验分析
(一)实验方案设计
实验中选择BNC(British National Corpus)语料库中的数据为例,由其中随机抽取部分语料作为实验对象,所抽取实验部分语料内共包含10种语法误译类别,分别为动词错误、缩写词错误、修辞错误、语态错误、语序、词汇错误、缺词、主谓错误、名词单复数错误及多词,通过本文方法对实验部分语料内语法误译实施校正,检验本文方法的实际应用效果。
将实验部分语料随机划分为5个数据集(A、B、C、D、E),各数据集的基本情况如表1所示。

表1 实验数据集
首先,通过本文方法对各实验数据集实施预处理,并提取其中语法特征,然后对所提取的语法特征内的误译特征实施检测,将本文方法的误译特征检测结果呈现,检验本文方法的误译特征检测效果。
(二)实验结果分析
检测过程中,设定由5个实验数据集内所提取的5个语法特征样本集(A1、B1、C1、D1、E1)的初始聚类参数k值依次为23、25、100、45、180,通过本文方法对各个特征样本集依次实施三次重复实验,取平均值作为误译特征检测结果,如表2所示。

表2 本文方法的误译特征检测结果统计
分析表2可得出,本文方法可实现语法误译特征的检测,所检测出的各语法特征样本集内的语法误译特征个数与对应数据集内的误译类别数量十分接近,验证了本文方法的误译特征检测效果较好。
为进一步检验本文方法的误译特征检测能力,提升实验结果的可信度,运用本文方法对5个语法特征样本集重新实施10次检测实验,统计本文方法的综合检测准确率(PR)、检测率(DR)及F1值,验证本文方法的误译特征检测性能。统计结果如图1所示。
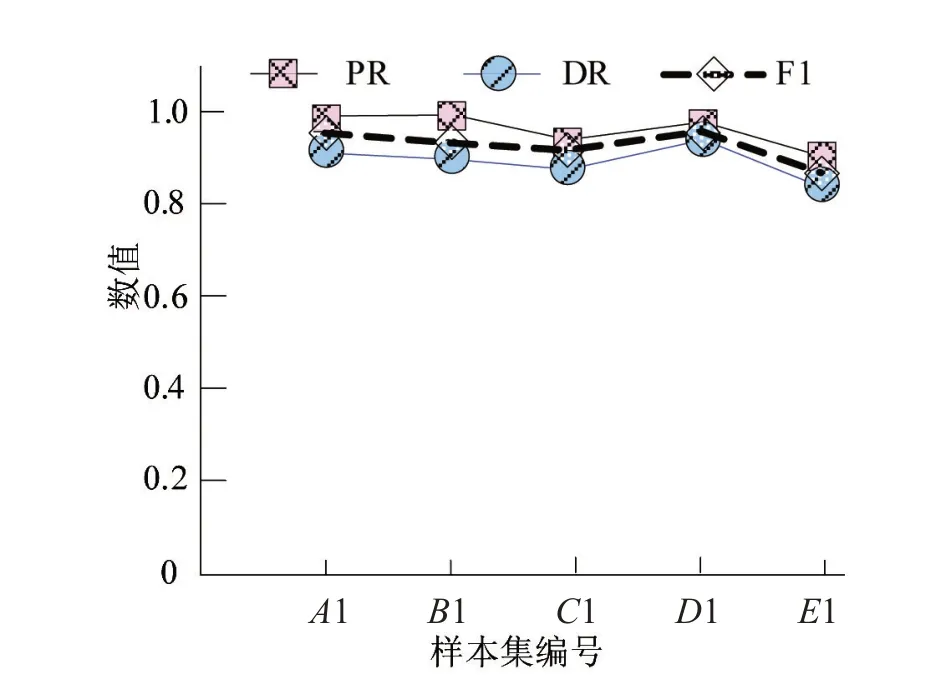
图1 本文方法误译特征检测性能统计
检验本文方法检测各语法特征样本集内误译特征过程中的聚类收敛用时情况,以其中三次实验为例,检验结果如图2所示。
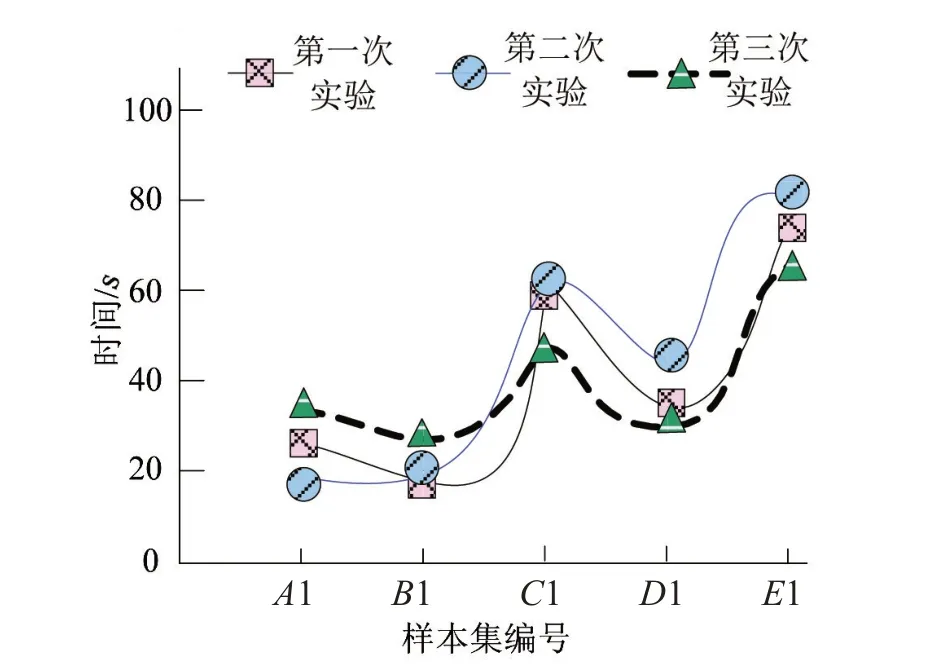
图2 本文方法误译特征检测中的聚类收敛情况
结合图1—2可以看出,本文方法的误译特征检测率、准确率及F1值均较高,数据集内数据量的多少对本文方法的误译特征检测性能的影响较小,对检测过程中聚类收敛用时情况影响相对较大,三次实验本文方法针对相同样本集检测时的聚类收敛用时较为接近,整体而言,本文方法的误译特征检测综合性能较为理想。
进一步验证误译特征检测性能,分析误译特征未检测出的具体数据,以数据集A为例,实验结果如表3所示。

表3 误译特征未检测出的数据分析表
根据表3可知,应用本文方法后,未检测出的误译样本数仅为0.8 MB,占比仅为0.89%,该值低于1%,并且未检测出的最多数据仅为0.2 MB,因此,本文方法可以有效检测出误译数据,提高了检测准确性。
通过本文方法基于以上实验结果对各数据集内的语法误译实施校正,得出最终校正结果如图3所示。

图3 本文方法的语法误译校正结果
由图3能够得出,本文方法可实现英汉翻译语法误译的校正,通过本文方法校正后能够有效区分正确语法与误译语法。其中,本文方法校正所得出的5个实验数据集的误译语法样本数依次为89、71、475、197及890,与各实验数据集的实际语法误译样本数极为接近,语法误译的校正精度均可达到98%以上,由此说明,本文方法具有较好的语法误译校正性能。
三、结束语
英汉翻译文本质量的高低直接影响学者的应用情况,为此,本文针对一种基于K均值聚类的英汉翻译语法误译校正方法展开研究。通过结合数值化与归一化方法,预处理所采集的英汉翻译语法数据,采用TF-IDF算法经过预处理的英汉翻译语法数据内提取出语法特征,构成语法特征样本集,运用K均值聚类检测出该样本集内的语法误译特征,并依据所检测误译特征生成误译校正模型,实现对输入的英汉翻译语法文本集内语法误译的校正。实验结果表明:本文方法能够实现语法误译特征的检测,且由各语法特征样本集内所检测出的语法误译特征个数与对应数据集内的误译类别数量几乎吻合,具有较高的误译特征检测率、准确率及F1值,整体校正精度超出98%,具有较高的实际应用性。
猜你喜欢
校园英语·月末(2022年3期)2022-05-10
国学(2020年1期)2020-06-29
甘肃教育(2020年22期)2020-04-13
家庭影院技术(2018年11期)2019-01-21
新闻爱好者(2018年12期)2018-02-18
摄影之友(影像视觉)(2017年10期)2017-11-07
摄影之友(影像视觉)(2017年1期)2017-07-18
雷达学报(2017年6期)2017-03-26
卷宗(2016年6期)2016-08-02
互联网天地(2016年1期)2016-05-04
