
基于图分类的智能车辆复杂场景风险等级评估与建模
2023-07-06 09:51吕超孟相浩崔格格龚建伟
北京理工大学学报 2023年7期
吕超,孟相浩,崔格格,龚建伟
(北京理工大学 机械与车辆学院,北京 100081)
配备有先进辅助驾驶系统的智能车辆已成为现代交通系统的重要组成部分.使智能车精确地评估和识别当前场景的风险等级是辅助驾驶系统能够发挥作用的重要基础:随着汽车保有量的逐年增加和交通参与者种类的提升,交通场景变得越来越复杂,交通事故频繁发生,其中在多交通参与者存在的复杂交通场景下发生的交通事故占总数的6%,同时占比死亡原因的67.2%[1],并且随着驾驶场景复杂程度的提升而有所增加.因此针对智能车辆提升其主动识别复杂场景风险等级的能力至关重要.
然而针对复杂场景风险等级的数据评价及场景建模仍然是智能车辆发展的瓶颈问题.一方面,由于驾驶经验和个性的差异,不同驾驶员往往有各自的标准来判定驾驶风险,如何合理的选择车辆客观特征参数来反映驾驶员主观对场景风险程度的理解成为了首要考虑的问题.另一方面,动态复杂的交通场景难以理解和建模[2],随着交通参与者的增加也提升了对该场景的风险等级的识别难度.
在以往的研究中,许多学者设计了不同的风险等级评估指标,包括碰撞时间[3]、车辆当前位置等[4],这些参数通常利用主车与周围交通参与者之间的几何或运动学关系来评估确定性驾驶风险[5],然而这些参数无法充分反映驾驶员的主观意识,并且未能捕捉到多个动态交通参与者之间的复杂交互关系.
驾驶场景建模方面,得益于传感器技术和目标识别算法的快速发展,驾驶数据的采集变得更加便捷和经济.并且对包括动静态要素的“场景”进行了定义[6],文献[7]中首次提出“行车风险场”概念,将驾驶员行为和周围复杂环境相结合,为智能车风险等级技术研究提供一种新的思路和方法,然而模型中待定参数确定方法未明确,只在简单跟车场景中验证其可行性.
基于上述不足,本文中提出了一种数据驱动的复杂场景风险等级图分类模型,采集并处理驾驶员视角下城市交叉路口实车数据,提取驾驶车辆的特征参数—纵、横向加速度并使用K-means 算法对特征数据进行聚类,从数据层面对驾驶员的主观操作特征进行反映,得到的标签作为图表示模型预训练使用.最后,使用图表示方法对场景数据进行逐帧建模,通过3 种图核方法中进行训练验证,从而实现复杂场景的危险等级识别和分类.
1 问题定义与方法框架
图作为一种新的数据表示形式,与传统方法相比,能够在关注单个节点属性的同时增加对节点之间关系的建模,因此被认为是捕捉不同对象之间交互关系的理想技术[8].在智能交通领域,道路上的车辆、行人等交通参与者可以当作是鸟瞰图上的多个节点,它们之间交互关系可以视作是图模型中的边.复杂场景的危险等级识别任务更加注重多交通参与者之间的交互关系,并且随着场景复杂程度的增加,图模型的表征优势更为明显.
本文中针对主车视角复杂场景下的风险等级分类问题相关定义如下:在某一时刻t的主车视角场景中,选取反映驾驶车辆危险程度的主要特征向量Ft,通过聚类算法对Ft进行分类处理,得到相应的场景分类标签用于模拟人类驾驶员对该场景的危险等级评估,同时对该场景主车周围交通参与者进行逐帧图模型建模,表示出相应的节点和边的关系,将分类标签与图模型结合,利用基于图核的相似性度量方法进行验证,从而对该图模型的可靠性进行说明.图1展示了总体框架的结构.

图1 场景风险等级评估模型总体框架Fig.1 Overall framework of risk level assessment model for scenarios
2 驾驶员特征提取与风险等级评价
本文中旨在通过所驾驶车辆的自身特征以及与周围交通参与者的信息来对危险程度进行说明,对于驾驶员而言,不同风险等级场景下会做出不同程度驾驶操作,从而通过改变车辆的特征数据来对不同风险程度的场景进行反应,则需要对驾驶员操作数据进行提取,基于此训练出某些特征数据作为输入的评判标准,得到相应的危险程度标签用于后续实验.
2.1 驾驶员操作特征数据选取
场景风险等级的定义为所驾驶车辆与周围交通参与者发生碰撞的可能性大小,从数据驱动的角度出发,通过驾驶员在所处场景中的操作数据变化来反映驾驶员对该场景风险等级的理解与反应,同时可以使训练出来的模型更加具备人的操作特征.
基于驾驶员对于不同风险等级的场景所做出的反应,如紧急刹车或是紧急转向的动作,寻找出所驾驶车辆上的特征数据变化.并通过对车辆的安全性问题的研究[9],文中同时选取驾驶车辆的直行加速度ax,t和转向加速度ay,t作为特征数据Ft来说明驾驶员的紧急刹车或是紧急转向的避让动作,反映所处场景的危险程度.考虑高维特征向量Ft=[ax,t,ay,t]T包含比单独考虑二者更大量的隐含信息[10],进而说明特征选择的可靠性.
2.2 基于聚类的风险等级评价方法
K-means 聚类算法可以将n个样本按照各自所属类别划分成k个集群,其中每个数据点都只属于一个集群,并且分类使数据点与相应的类群所有数据点的算术平均值之间的距离平方之和达到最小.在类别内的方差越小,该类群内的数据点相似性就越强.对 于 数 据 集,其 中fi∈Rn为n维 的 驾 驶员特征矢量,N为样本数量.该非监督学习方法的损失函数为
式 中:µk为 类 群Ck数 据 的中 心 点;ωik为数 据 点 所 属类别判断,对于数据点fi,若其属于类群Ck则 ωik=1,反之则 ωik=0.
另外在对高维数据进行聚类处理的过程中,由于高维数据的非线性特征,简单线性K-means 聚类方式很有可能会出现分类错误的现象.谱聚类则可以将高维无组织的数据点按照其特征频谱的唯一性分成多个不同的数据组,将连接在一起或紧邻在一起的数据点在相似性矩阵A中表示,然后通过拉普拉斯映射进行数据降维;对降维后的映射数据再进行聚类分析.即根据相似性矩阵A构造其对角加权矩阵D,则有拉普拉斯矩阵L=D−A.并求解以下广义特征值问题:
最后,对特征向量排序 0=λ0≤λ1≤···≤λM;即U=[e0e1···eM],通过选择前p个特征向量,就可以构造出一个数据的p维流形嵌入表示Y=[e1···ep]T.获得了数据的拉普拉斯映射Y后,就能够通过挑选合适的K值,对Y进行K-means 聚类运算.
3 基于图模型的行驶场景建模
图表示模型可以同时提取场景中交通参与者的动态信息和交互信息,更好地理解驾驶场景.模型中的节点和边可以很好地体现多个对象之间的交互关系,并且交通参与者的数量及对应交互关系的变化可以通过图的动态变化实现自适应.
3.1 图模型节点定义及场景几何划分
在城市道路场景中,车道线的限制更为规范,城市交叉路口场景更加结构化,并且采集到的数据视角随驾驶车辆的移动而发生变化,出现在主车视野内的交通参与者的轨迹会受限于场景下的几何特征,很少有复杂交叉及不规则现象出现.
文中构建了主车视角下的规则矩形网格图模型,如图2 所示,网格随车辆视野的移动而固定于车辆前方进行移动.采集车辆前视方向范围转换为用于训练的鸟瞰图模型,每一个交通参与者本身可以定义为图模型中的节点.另外在危险场景建模问题下,所驾驶车辆与其他车辆存在交互关系,因此本车也是图模型中的重要节点,所驾驶车辆始终处于鸟瞰图的下方居中位置.根据所采集数据视野范围及城市道路十字路口车道数,将网格y方向划分为5 个部分,x方向划分为3 个部分.

图2 图表示模型构建Fig.2 Graph representation model construction
3.2 图模型边的定义
在图模型中,2 个节点间通过一条边的连接来表示这2 个节点有一定的相互联系或相互作用.在本文中中定义图模型的边为周围交通参与者之间的潜在碰撞关系.由于在城市道路环境中交通参与者之间的距离越小,相撞的概率就越高,因此在图模型中距离被认为是近似相互作用的重要度量.则在节点标签定义划分的网格基础上对于车而言,存在于以车辆A为中心的3×3 网格内的其他车辆被认为与A具有边连接,相距2 个网格以上的两车则会被认为没有联系;而对于行人而言,作为交通参与者中的弱势群体,加强行人与车辆之间交互的考虑,则在图模型中扩大边的设置范围来体现对与行人之间的强交互行为,即车辆与周围行人之间存在交互边的范围定义为该节点周围的5×5 网格中.此外由于碰撞是相对的,所以本文中定义的边都是双向的且标签为1,定义的模型边如图2 左图所示.
3.3 图模型节点标签定义
本文中根据图的网格结构,将交通参与者的连续位置离散化为网格占有率.具体是在检测到有交通参与者存在的网格内由数字1 开始进行不重复的填充,通过一系列的填充数字来表征节点间的邻接矩阵,从而实现节点边的唯一表示.另外对于不同组数据中的不同交通参与者,通过对其多种真实信息的结合考虑来实现节点的唯一编码标签.
对于车辆节点标签Lv而言,结合考虑了该车相对主车速度vi,在图网格中的x、y坐标位置来对其进行编码,对于行人节点标签Lp,由于行人相对速度失真,其相对速度更多的是考虑本车的速度,因此在对行人节点标签进行定义的时候仅考虑其在图网格中的x、y坐标即可.表示为
3.4 基于图核的场景风险等级分类
图是一种复杂的非线性结构数据,使用传统的线性分类模型无法对图整体进行分类,因此在训练危险场景识别分类器之前,需通过一定的方法将图的内积投影到高维空间中,再用线性模型进行训练.本节介绍将3 种图核算法,基于路径计算的最短路径图核(shortest-path kernel),基于邻域聚合计算的邻域哈希图核(neighborhood Hash kernel)以及基于Weisfeiler-Lehman 算法的WL 图核,并将在实验部分对3种图核方法进行实验对比.
最短路径图核对于图结构数据而言,是将每一张图分解为最短路径的组合,从而实现图的分类,即给定2 个图G和G′,它们对应的最短路径图分别是S=(V,E),S′=(V′,E′),则:
式 中,kwalk(1)(e,e′)为 长 度 为1 的 行 走 路 线 边 (e,e′)的 核函数.
邻域哈希图核主要思想是图中的每个节点接收来自邻居节点的信息更新节点本身的标签,并统计它们的公共标签数来度量不同图之间的相似度.即给定2 个图G和G′,使用简单邻域哈希对2 个输入图的节点运算 (1,2,···,h)次后,2 个输入图的更新图分别为G1,G2,···,Gh和则2 个输入图的相似度量计算如下:
式中c为2 个图有共同标签的数量.
Weisfeiler-Lehman 算法通过判断2 个图中对应节点的特征信息和结构信息来判断这2 个图是否同构.即使用一种高效的计算方法将图的特征信息及结构位置信息隐射为节点的ID,将2 个图的相似度问题转化为2 个图节点集合ID 的相似度问题,则有:
式中h为图及图节点序列计算所迭代次数.
4 实验及分析
4.1 实车数据采集
为获取车辆多种操作特征及场景中交通参与者的信息,文中采取了在主车视角下搭载的一系列车载传感器进行数据采集.该传感器系统包含一个安装在汽车顶部的毫米波雷达用于收集主车周围车辆的相对位置及各自的相对速度,用于采集方向盘转向角度、制动信号和车辆纵、横向加速度等信息的CAN 总线,以及一个安装在车辆前窗玻璃上的相机用于采集场景信息,整个数据采集传感器系统如图3所示.该系统可以按照数据采样间隔为0.1 s 来对数据进行采集,具有可靠的采样频率以满足后续数据处理分析精确度的需要.

图3 车载传感器系统Fig.3 Vehicle Sensor System
对于场景道路的选择,首先考虑了城市交通路网中最繁忙的交叉路口作为此次复杂场景的研究对象,场景中包含大量交通参与者.因此,选取北京市海淀区魏公村路口的直行、学院南路的右转,以及学院南路的左转作为数据采集场景.文中所采集的数据是从所驾驶车辆进入交叉路口的不可换道区域到完全通过该交叉路口时的无抽帧数据,并且剔除在红灯时候的停车数据,以及场景中不存在交通参与者的情况,保证实验数据复杂可靠.
4.2 风险程度聚类标准选取
对于聚类方法及类别数的确定本文中主要使用残差平方和(residual sum of square)的肘部原则以及轮廓图这2 个标准进行评判,并且结合聚类算法的效果进行比较和选择.
式中K为对应聚类数,根据该函数绘制RSS 相对于类别数K的曲线,曲线明显的弯折部位对应的K值则作为使用的聚类类别数.
文中对于所选用的车辆纵、横向加速度二维特征向量Ft使用K-means 方法的8 次聚类计算的RSS和SC 值如图4 所示.可以看出当K=3 时,特征数据的RSS 值出现了明显的弯折,轮廓系数为最大值SC=0.834,即K=3 时出现了“肘部”,其次K=4 时轮廓系数为SC=0.776,初步表明K=3 时的聚类效果优于K=4 时的聚类效果.

图4 对特征数据Ft的K-means 聚类Fig.4 K-means clustering of feature dataFt
为了进一步验证,绘制了K取值为3 和4 时的轮廓图,可以看出当K=3 时,各分类分布均匀且没有小于零的数据(小于0 的数据为错误分类到该类别中的数据),表明此时分类效果较优.但是可以看出当K=4 时,在第1、2、3 类中均有分类错误的数据,如图4 中圈出部分所示.因此对于Ft使用K-means 聚类时选择K=3.
作为对比实验,文中使用谱聚类中的KPCA 方法对特征数据Ft进行降维处理,计算前20 个特征向量的特征值如图5 所示,可以看出对应KPCA 方法特征值曲线图在特征向量个数为5 时出现明显“肘部”,绘制对应轮廓图可以看出,各部分分布并不均匀,尤其是第3 类的结果,并且在第1 和第4 类中出现了分类错误的现象.

图5 KPCA 方法分类效果Fig.5 Classification effect of KPCA method
综上,在对特征数据Ft的聚类处理过程中选用Kmeans 聚类算法,并且以K=3 进行.
4.3 图模型构建及验证
基于前文模型定义,对于实车数据场景中的图网格划分,根据车载传感器检测到的最远距离以及交通参与者在城市道路上发生影响的距离将x方向的每一间隔设置为10 m,y方向的网格划分则结合考虑了交叉路口转向时候的危险程度,以及与主车的影响程度选取相邻两车道的交通情况进行划分,设置y方向的网格宽度为2 m.其中第2 列和第4 列网格代表相邻两车道的交通参与者于主车前方发生急剧变道情况,并且这两列的设置更是考虑了后续在图模型中使边的设置更加分明.网格划分情况如图2(a)所示.
根据前文关于场景图模型构建以及特征数据聚类部分的实验描述,寻找相应的节点和边的关系,部分图场景的构建与风险等级聚类结果的对应关系如图6 所示.
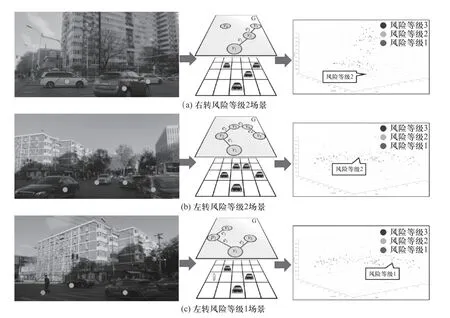
图6 场景搭建与聚类处理Fig.6 Scene construction and clustering processing
针对不同场景具体处理数据量如表1 所示.

表1 交叉路口实车数据处理量Tab.1 Data processing volume of real vehicles at intersections
在得到了每组数据的逐帧风险等级标签、节点标签、节点边组成的邻接矩阵等信息之后,将相应数据用邻域哈希图核、最短路径图核和WL 图核3种图核方法进行验证,分别进行10 次重复实验,并取平均值作为最终结果以消除偶然误差造成的影响,所得精度结果如图7 所示.

图7 实车数据风险等级识别分类准确率Fig.7 Real vehicle data risk level identification and classification accuracy
从所示的危险场景识别准确率图中可以看出,图结构模型对复杂场景的危险程度识别分类有不错的表现,验证精度都在80%以上,其中交叉路口左转数据的邻域哈希图核和最短路径图核验证的准确率甚至达到了90.0%和89.0%,并且表明邻域哈希图核对于表示图模型中交通参与者之间的关系有着更好的效果.另外为了进一步对上述图方法识别分类结果进行说明,对模型的查准率、查全率及F1值进行类别加权计算,如表2 所示.

表2 实车场景验证结果Tab.2 Validation results of the real vehicle scene
在对实验结果的分析中,由于该模型危险程度识别是通过车辆运行过程中的横、纵向加速度二维特征进行聚类,转弯时候的横向加速度的变化更为明显,在聚类处理的过程中更加可靠,因此转弯数据的验证精度好于直行数据.
综上,横、纵向加速度对于驾驶员主观风险程度评价具有较好的表征能力,并且基于图表示的复杂场景风险程度识别模型针对有多交通参与者存在的城市场景有着不错的效果,所有识别结果精确值都在80%以上,可以准确的对复杂场景风险等级进行评估.
5 结 论
文中提出了一种基于图模型的风险程度识别方法,主要包含3 项工作:首先对驾驶员视角下的城市交叉路口数据进行了实车采集与处理,获得了城市交叉路口真实场景数据.其次通过K-means 对包含驾驶车辆纵、横向加速度的二维特征进行聚类分析,得到不同场景下的危险程度标签用以训练场景风险等级识别器.最后使用图表示模型对场景数据进行建模,结合聚类结果及处理得到的图模型数据通过邻域哈希图核、最短路径图核和WL 图核3 种图核方法进行验证.对于交叉路口直行、左转、右转复杂场景,3 种图核识别精度均在80%以上,并且对于实车左转场景的结果可达89%.实验结果表明该风险等级评估模型展示了对有多种交通参与者同时存在的复杂场景的适应能力,能够较为准确的根据驾驶员行为输出驾驶场景的风险等级,为自动驾驶和辅助驾驶系统的开发提供了新的思路.在未来的工作中,将会考虑在提出的模型中引入更多的交通参与者特征数据和环境信息,并且考虑时序对场景风险等级的影响,以提升模型的动态化性能.
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11
体育科技文献通报(2022年3期)2022-05-23
数学年刊A辑(中文版)(2019年3期)2019-10-08
现代营销(创富信息版)(2018年10期)2018-10-12
电子测试(2017年15期)2017-12-18
北京航空航天大学学报(2017年6期)2017-11-23
雷达学报(2017年6期)2017-03-26
浙江大学学报(工学版)(2016年10期)2016-06-05
华人时刊(2016年13期)2016-04-05
电子设计工程(2015年6期)2015-02-27
