
基于CATPCA 的优化Transformer 卫星电源消耗时序预测研究
2023-07-06 09:51张璋常亮田明华邓雷常建平董亮
北京理工大学学报 2023年7期
张璋,常亮,田明华,邓雷,常建平,董亮
(1.中国科学院 微小卫星创新研究院,上海 201203;2.中国科学院大学,北京 100049;3.上海微小卫星工程中心,上海 201203)
卫星在通信、导航、遥感等方面都发挥着重要作用,是国家重要的战略资源.提高卫星运行的高可靠性,进行在轨任务最大化,已经成为航天领域的共识.这很大程度依赖于卫星电源系统效能,电源系统需要完成电能的产生、变换、存储以及分配,这是其他分系统正常工作的基础.卫星电源系统可以归为3 个部分进行分析,即太阳能电池阵、蓄电池以及卫星负载.太阳能电池阵完成电能的产生和转换,提供给卫星负载;蓄电池在电能充足时作为负载进行充电,在电能不足时则作为电源和太阳电池阵同时为负载供电.考虑到日地间距、工作温度、太阳入射角、空间环境、寿命衰减等因素,太阳能电池阵的输出功率在不断变化;蓄电池则因工作温度、性能退化等因素影响,随在轨时间、在轨环境变化具有不同的充放电功率;卫星负载则取决于任务模式的转变运行不同载荷,还需要考虑到载荷间散热、协同工作等引起的其他因素影响,如温度,加热器功率等.因此,如何对在轨不同时期,不同状态下对卫星电源进行准确预测是非常重要且具有难度的.这也将是卫星蓄电池自主健康管理卫星在轨任务规划等后续卫星在轨应用的重要技术支持[1−2].
针对卫星能源预测这一问题,国内外学者从20世纪80 年代开始进行广泛深入研究.采用物理模型进行数学拟合是最为传统的方式之一.主要应用在卫星太阳电池阵输出电流拟合[3],太阳电池阵输出功率估计[4],蓄电池组充放电估计,以及在轨星上供配电性能分析等方面.主要通过对太阳电池阵或者蓄电池产生影响的主要因素进行重点分析,例如:日地距离、太阳光强度、太阳入射角、工作温度、空间环境和天线遮挡等因素,进一步选取变量进行曲线拟合,通过引入形变因子,衰减修正等方式提高精确度[4].该方式非常明确且过程清晰,缺点是复杂系统分系统间相互影响,物理模型建模复杂,新的难以分析拟合,会产生较大误差.
时间序列分解是解决卫星电源预测问题的另一手段.广泛应用于太阳能电池功率衰减、星上蓄电池寿命估计等方面[5].该方法运用统计分析方法时序分解出典型的趋势成分、季节成分、随机成分以及循环因素,通过自回归模型(AR)、滑动平均模型(MA)、差分自回归移动平均模型(ARIMA)、指数平滑等进行预测分析.可以对电源的趋势项、周期项、随机因素都得出良好估计,对于电池衰减、寿命预测等单变量时序预测中能够得出良好预测模型.但传统时间序列预测模型主要应用于单一数据自回归,因此该方法通常需要至少3 个周期以上的长周期连续数据来完成对目标变量预测分析.如果数据有很大的变异性,就不能得到预测的有效结果.对于较为复杂的多维时间序列,预测效果并不理想.
基于数据驱动的神经网络电量预测是较为新型的方式,初期以浅层的BP 神经网络、贝叶斯网络、支持向量机等为例,取得了较好的效果.但在实际复杂系统的泛化能力较弱,难以在高维数据中挖取深层特征.通过深度学习的不断发展,国内学者开展了更深入的研究,以长短期记忆网络(LSTM)[6]、深度信念网络(DBN)、自注意力模型(Transformer)为代表,该方式利用深度神经网络对复杂系统出色的拟合能力,完成自适应学习,成功应用在卫星蓄电池的健康状况区间预测、光伏功率预测等方面.但该方法对于数据质量要求较高,对数据处理模型提出了较高要求,同时需要较好的计算性能完成训练.
本文针对高维卫星工程真实数据,提出一种卫星电源消耗预测方法,由基于分类主成分分析、Hurst指数分析、灰色关联分析[7]的数据处理模型和由对抗生成网络架构[8]组成的改进Transformer[9]预测模型组成.从卫星在轨真实数据入手,进行采样统一、数据清洗、缺失填补,进一步针对任务模式等分类数据进行最优量化,最后进行整体降维,对高维数据完成特征提取.区别于Onehot 编码对分类数据直接赋值,可以更好地模拟分类数据间的分布关系,提高后续预测精度.改进Transformer 预测模型则以对抗生成网络为架构,利用Transformer 对时序数据的出色拟合能力,运用生成器、判别器的相互博弈以及真实数据同生成数据的均方误差(MSE)作为损失函数,进行模型训练.将连续16 个时间步时序数据输入多学习Transformer 网络模型,进行卫星耗电量时序数据拟合,得到了良好的预测效果.
1 相关性分析
1.1 重标极差分析法
重标极差分析(R/S)由 HURST 于1965 年提出,随非线性理论的不断发展,是一种非参数的时间序列统计方法[10].通过Hurst 指数计算完成对时间序列的变化趋势以及强度进行定量分析,可以定量地描述各个变量长期相关性.Hurst 指数体现了时间序列的自相关性,尤其代表序列中隐藏的长期趋势,统计学上称为长期记忆.Hurst 指数的计算步骤如下:
(1)将总长为M的序列Rt切割为长度为n(n>3)的A=N/n连续区间,即:An=M.区间表示为Ia,Ia中的元素表示为Rk,a,k=1,2,···,n,每一区间Ia均值为
(2)计算子区间Ia偏离子区间均值的累积离差:
(3)计算子区间Ia极差:
(4)计算子区间Ia标准差:
(5)计算子区间Ia的重标极差:
(6)重复对每个子区间计算,得出重标极差序列(R/S)a的均值为
(7)将子区间n的长度增长为n+1,n+2,...重复步骤计算,直至长度为n=N/2,通过最小二乘法对方程log(R/S)a=logC+H×logn进行估计,获取H即Hurst指数.
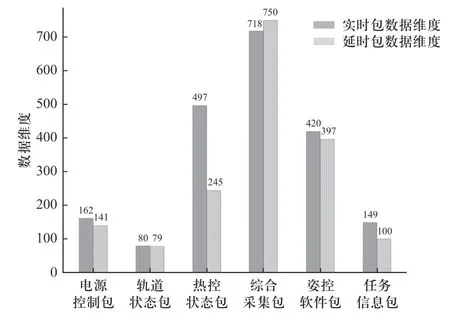
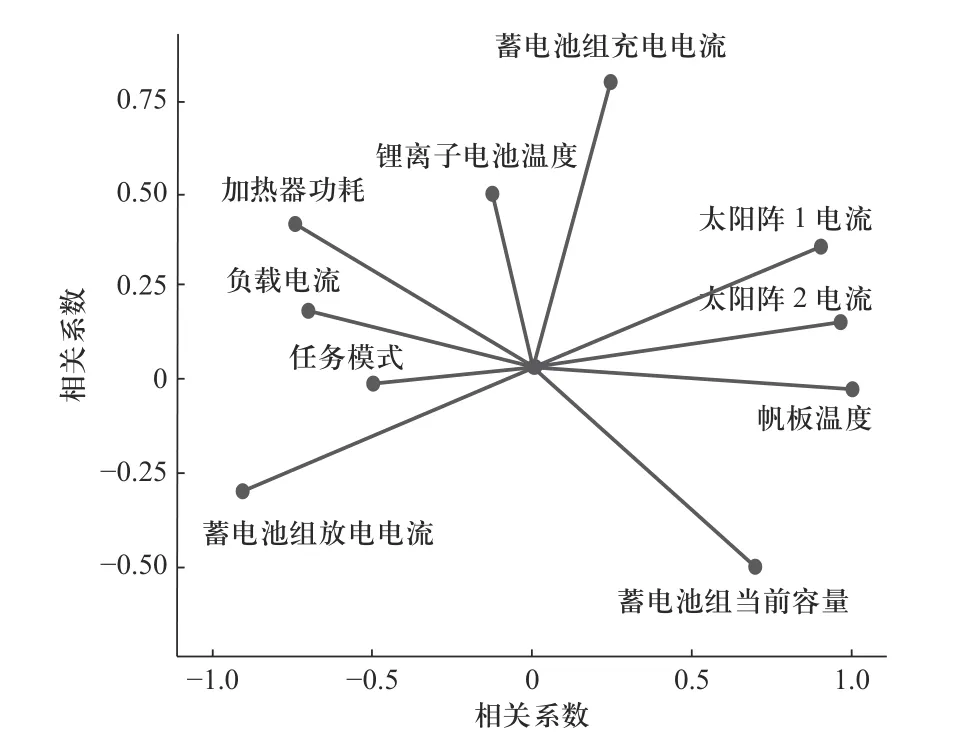
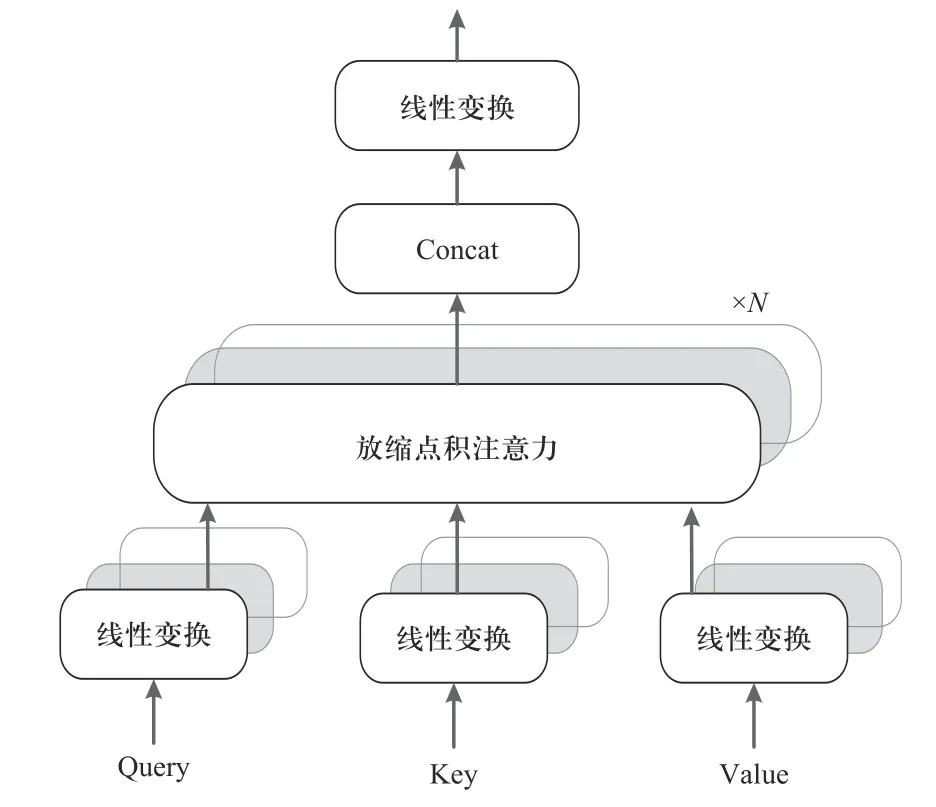
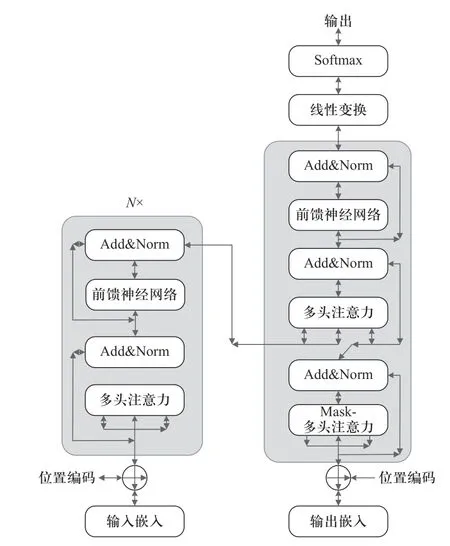
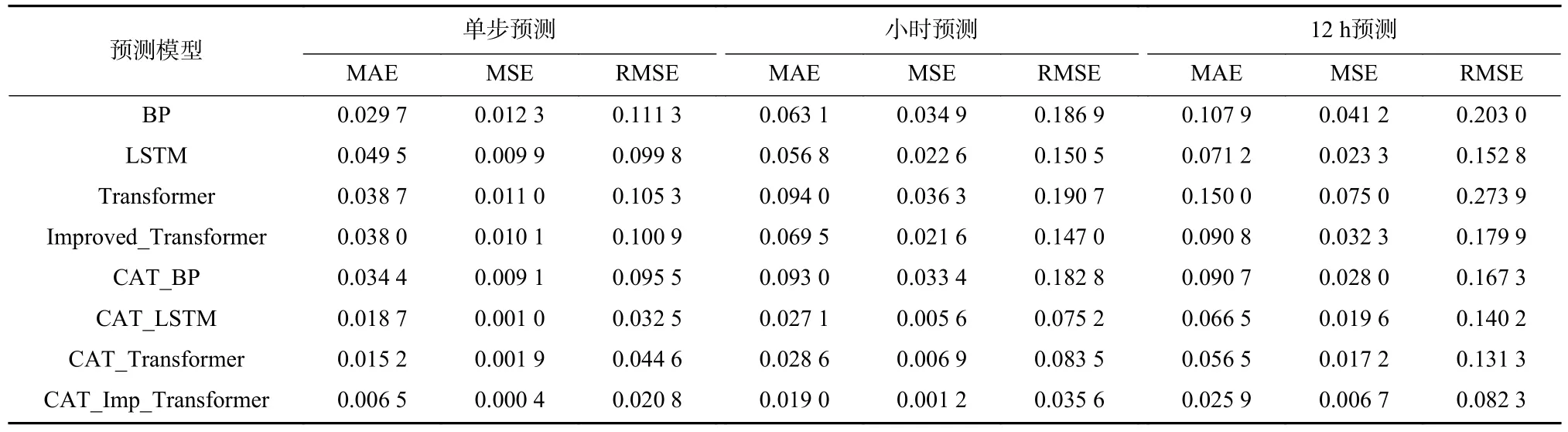
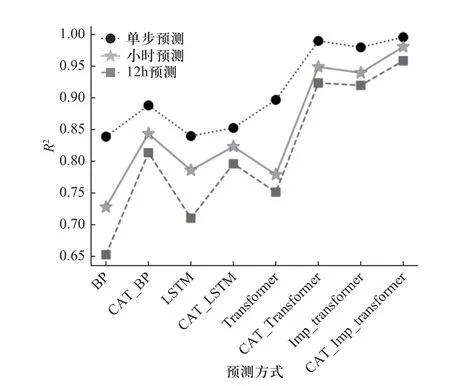
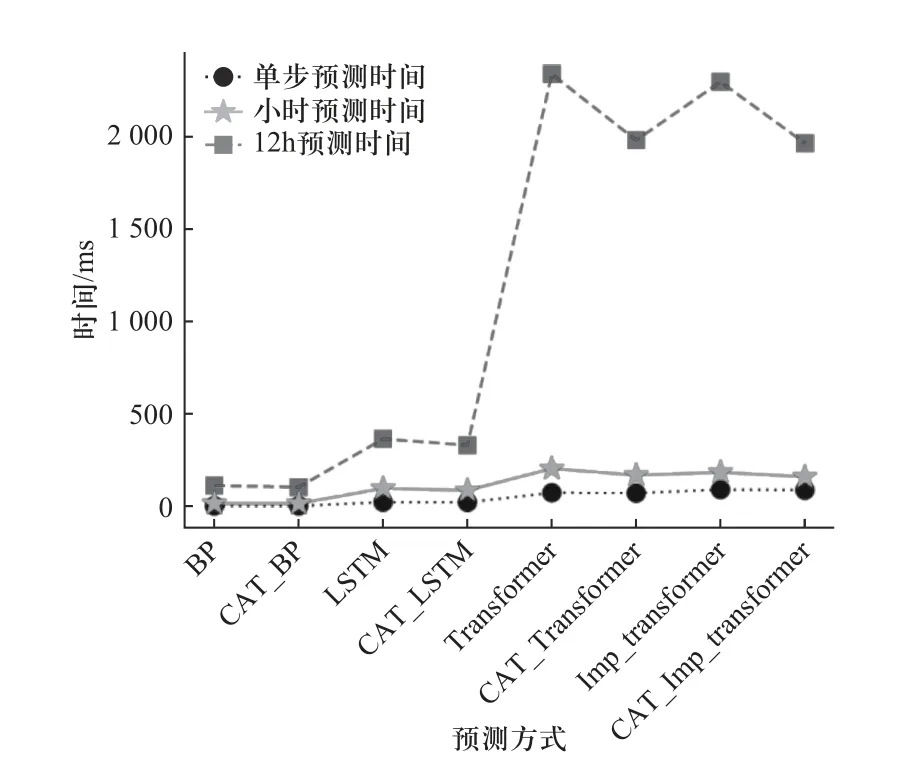
(8)Hurst 关系如式(7)所示,C为常数,N为观察值的个数,根据H值的不同,可以将序列分为3 种类型:0 灰色关联分析 (grey relation analysis, GRA) 属于灰色系统的应用范畴分支,是一种多因素统计分析方法[7].该方法对分析样本的规律性与数量要求不高,适应性更为广泛.可以根据灰色关联度大小来判断各影响因素间的密切程度,避免预测时考虑过多次要影响因素而降低预测效率.本文以各维度的样本数据为依据,确定各影响因素与卫星电压(预测量)的关联度,从而筛选输入数据维度. (1)矩阵x为电压以及其他变量 (2)同向化x矩阵中的各元素,用倒数法将逆指标转化为正指标,记作x. (3)对数据矩阵无量纲标准化处理,处理后矩阵为 (4)选择最优样本数据Y+和最劣样本数据Y− (5)计算样本点到最优最劣参考样本数据的欧氏距离为 (6)计算样本点到最优样本数据的接近度,为灰色关联系数: Wk∈[0,1],关联系数与1 越接近,代表该样本数据与最优样本数据的相对距离越接近,即该变量与卫星电压的关联度越大. 主成分分析(principal component analysis, PCA)[11−12]是一种无监督学习方法,通过正交变换将由m个线性相关变量表示的数据转换为由p个线性无关变量表示,又称为主成分.PCA 适用于多维连续变量,并假定变量间存在线性关系,而卫星在轨数据包存在大量分类关键数据,如任务模式,加热模式,使PCA无法应用.故本文采用分类主成分分析(categorical principal components analysis, CATPCA),运用最优尺度变化将分类标签转化为数值,并保证量化转换成变量的方差最大;进一步将量化数据带入对数据整体降维.在保留在轨数据中大部分信息的前提下,用少数不相关的变量来替代相关的变量,提高数据质量. (1)假设对n个对象m个变量进行估计,给定观察分数矩阵为Hn×m,其中变量为Xj(j=1,2,···,m) ,是H的列向量.若Xj为标签分类变量,则通过最佳缩放变换,类别数据可以量化为 (2)其中Q为类别量化矩阵.Sn×p为目标分数矩阵,代表对象在主成分上的得分.Am×p为成分载荷矩阵,aj表示矩阵的第j列.那么原始数据和计算出的主成分间差异最小化最小化损失函数如下: 其中tr 为迹函数,CATPCA 算法通过最小化式(14)中的损失函数实现量化. (3)将量化数据带入源数据的分类数据,进行数据标准化: (4)计算相关矩阵 式中:x∗为标准化数据矩阵,特征值为 λ1∼λm,特征向量为u1∼um. (5)确定主组件.差异贡献率为 累积的方差贡献率为 确定最小的p值,令 卫星在轨源数据主要由多个信息包组成,分为实时包、延时包两个部分,每个部分包括电源控制包、轨道状态包、任务信息包等.每种数据包的维度如图1所示,共约2 000 个维度,存在大量维度冗余.实时包通常数据采样周期小,以s 为单位,同时字段和延时包相比较多.缺点是只在某些特定时段可以获取,导致时序数据时间连续性较差,同时存在大量重复,错续且采样时间不定问题;延时数据相对采样周期较长通常以min 为单位,只获取到保留部分字段,优点是相对数据时间连续性相对较好,采样周期相对比较稳定.本文以2021 年某日的电源控制数据包为例,图2中为了显示清晰仅列举电源控制包和任务信息包.如图2 所示卫星时序数据的特点是指某些时段较为密集,同时每日密集时间段不同;不同数据采样周期不同,并且包内数据周期也并不稳定,存在大部分空缺.采样不稳定以及数据维度冗余等问题,对于时序数据相关分析与挖掘是致命问题,故本文建立卫星时序包数据分析处理模型,提取分析有效数据. 图1 卫星数据包统计图Fig.1 Statistical map of satellite in-orbit data packets 工程实际通过信息物理系统采集获得的数据,受测量设备,传输设备,存储设备及人为因素影响,数据质量不确定,存在采样周期不稳定、数据缺失、数据冗余和数据缺失等问题.同时为解决数据的多元共线性以及分类数据量化的难点,本文建立了基于CATPCA 卫星时序处理模型,步骤如下: (1)首先将卫星在轨实时包和在轨延时包进行采样统一,确定时序数据周期.进一步通过人为经验筛数据维度. (2)针对每个单独维度进行标准差离群值处理,去除离群值. (3)考虑到数据存在缺失问题,进一步对数据进行补遗和修正,选择K近邻补全算法对数据进行填充.通过选取数据集中相近距离的K个完整的最邻近数据完成缺失值填补.通过欧式距离判断样本点间的远近. 式中:Xi={xi1,xi2,···,xim}为i个 样本点的前m维数据;xir为i个样本点的第r维数据. (4)通过重标极差分析法计算Hurst 指数判断变量是否存在可预测性,计算结果如表1 所示. 表1 变量Hurst 指数Tab.1 Variables Hurst index (5)进一步运用灰色关联法判断输入数据维度和预测卫星电压的相关关系,对输入维度再次筛选,计算结果如表2 所示. 表2 分类变量最佳量化值Tab.2 Best quantification values for categorical variables (6)将筛选后的输入维度中的分类变量进行最优标度量化,进一步对数据进行降维处理,获得最终输入主成分.为方便观察每个维度对最终电量的影响,以双变量相关系数作图如图3 所示. 图3 卫星电压预测成分载荷图Fig.3 Load diagram of satellite voltage prediction component Transformer 模型自2014 年以来,具有强大的特征提取能力,成功应用在机器翻译、文本摘要等序列型数据应用方面.Transformer 摆脱了传统的循环神经网络、卷积神经网络的结构,由位置编码、编码器、解码器和全连接神经网络组成.架构核心为自注意力机制(self-Attention)和前馈神经网络(FNN),相比于注意力机制[13]更加适合获取数据的内部相关特征,完成样本自学习.自注意力机制通过缩放点积注意力计算特征矩阵的注意力值[9].计算公式为 式 中:Q为 查询矩阵;K为键 值 矩 阵;V为值 矩 阵;dk为矩阵Q和K的维度. 多头注意力机制是由多组缩放点积注意力组成的.自注意力机制会使模型聚焦于重点的某个特征.采用多头注意力机制,通过拼接关注点不同的矩阵,完成源数据在不同子空间的特征提取,如图4 所示.多组不同Q、K、V矩阵计算放缩点积注意力进行线性变换和拼接获取最终输出.注意力头为 图4 缩放点积注意力机制Fig.4 Scaled dot product attention mechanism Qi、Ki、Vi分别代表注意力头h eadi的Query、Key、Value 矩阵.多头注意力机制为 式中:W0为线性变换系数矩阵. Transformer 模型由多头注意力主导,进行求和、归一化等操作,模型结构包括位置编码、编码器、解码器和全连接神经网络4 部分.其中,编码器由多头注意力机制和前馈神经网络子层组成;解码器包括mask-多头注意力机制和前馈神经网络等组成.如图5所示. 图5 Transformer 模型Fig.5 Transformer model 求和为 前馈神经网络为 归一化为 式中:X为模型输入;Z为首次求和和归一化输出;Y为二次求和归一化输出.编码器与解码器等各个网络之间进行残差连接和归一化,可以提升网络收敛速度和泛化能力.模型训练的损失函数采用均方误差(MSE),模型训练的优化采用Adam 算法和Dropout 算法. 对抗生成网络架构由生成网络和判别网络两部分组成.其中,生成器可以生成与真实卫星电源数据相似的预测数据;判别器网络负责判别生成的卫星电源数据的真伪.生成对抗网络基于零和博弈理论,通过设计互为博弈的生成器与判别器进行多次对抗、迭代优化,完成两者的性能训练.目的是达到在最大化判别网络性能的前提下,生成网络可以产生符合真实数据特征的样本[8,14]. 生成对抗网络模型如图6 所示,训练流程可以分为两部分,首先固定生成器对判别器进行优化,循环训练判别器最大可能准确地进行真伪判别;进一步更新生成器的参数,训练生成器尽可能减小生成样本和真实数据的差值,使判别器判别不出生成数据的真伪.两个网络不断迭代训练,生成数据分布将与真实样本数据趋于拟合,判别器无法对数据进行区分,对数据的误判几率为50%,称为纳什平衡.博弈过程如下: 图6 生成对抗网络Fig.6 Generative adversarial network 式中:G为生成网络;D为判别网络;V为价值函数;V(D,G) 生 成数据和样本数据的差异程度;V(D,G)为固定生成器、训练生成器.V(D,G)为固定判别器、训练生成器. 针对复杂时间序列预测精度不高和累计误差等问题,本文提出了一种多学习改进Transformer模型,模型流程如图7 所示.模型以生成式对抗网络为构架运用卷积判别网络对Transformer 数据生成网络进行训练,运用判别网络和生成网络的博弈训练以及最小化预测值均方误差的多监督学习方式,利用判别器网络对Transformer 数据生成网络进行优化学习,解决固有的时间预测过程中的累计误差问题,提升卫星电源消耗预测的精度,如图8 所示.其中,卫星电源预测模型为实现Transformer 多变量实际序列预测,将连续的N×16 个时间步的数据作为输入,并结合最小化预测值均方误差和对抗生成网络中的判别器模型损失,构建出多学习网络损失函数,改进网络模型的优化目标. 图7 改进Transformer 卫星能源预测方法Fig.7 Energy prediction method of improved Transformer satellite 图8 卫星电源预测模型Fig.8 Satellite power prediction model 式中:yi为实际值;为预测值. 将对抗生成网络架构的判别器的损失作为Transformer 生成器的正则项,提高网络预测精度和预测的鲁棒性.改进网络损失函数为 如图7、图8 所示,训练和预测步骤如下. (1)数据清洗:针对高维卫星电源数据的周期混杂和冗余问题,对卫星在轨数据首先进行采样周期统一,进一步完成离群值剔除等清洗操作. (2)量化降维:针对高维卫星电源数据中存在多类数据问题,对经过清洗的数据进行最优标度量化降维,将分类数据赋值合理的量化数值并进行统一降维,提升数据质量. (3)数据集分割重构:将数据分割为训练集、测试集、验证集,并且将输入数据重构大小为N×16,每个输入都是完整的16 个时间步多元数据. (4)对抗生成架构:将重构数据输入Transformer生成模型,与判别器网络进行博弈训练. (5)位置编码:奇数位置为余弦编码,偶数位置为正弦编码,输入样本元素中的顺序问题将通过位置编码标识. 式中:pos为样本中元素的位置;i为向量维度;dm为位置向量的维度. (6)多头注意力机制:以自注意力机制为基础获取对每个样本的关注度,将不同投影结果拼接起来,得到多头注意力机制的输出. (7)前馈神经网络计算:完成多头注意力机制后进行归一化处理,进行前馈神经网路计算.进一步进行编码器中每个子层的残差连接和归一化.子层的输入为 式中:LN为层归一化;uL为均值;为方差;α为增益;β为偏置. (8)输入判别器:将由Transformer 网络生成的预测数据输入CNN 判别器,对数据进行真伪标签判别. (9)训练Transformer 生成网络:利用判别器对相应数据的真伪标签和MSE 对生成器网络,即Transformer 进行训练学习. (10)循环训练:使Transformer 生成网络同判别器网络进行循环训练,直至到达纳什平衡. 在本文中,引入均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、R2_score 来反映模型的预测效果,以上前3 个指标参数越小,表明模型的预测效果越好,R2_score 值越接近1,则表示数据预测拟合效果越好 式中:n为样本个数;yi为实际值;为预测值;为真实数据的平均值. 本文采用PyTorch 神经网络框架,在Python3.8 环境下构建预测模型.实验数据来自某遥感卫星2020~2022 年间运行数据.为验证本文算法的有效性,分别运用BP 神经网络、LSTM、Transformer、Improved_Transformer 4 种算法进行对比分析,完成单步预测、小时预测和12 h 预测.另外,对是否采用上文中数据处理模块进行算法训练进行参考对比分析,分析数据处理模块的适用度,算法对数据的敏感度.表3 记录了各算法的评价指标. 表3 预测性能对比Tab.3 Prediction performance comparison 其中,前4 种BP、LSTM、Transformer、Improved_Transformer 算法分别是采用数据清洗后源数据直接进行训练,后4 种CAT_BP、CAT_LSTM、CAT_Transformer、CAT_Imp_Transformer 算法则是通过上文所述的最优量化数据处理模块后进行训练;对以上8种方法进行单步预测、小时预测、天预测. 由表3 和图9 可以看出,经过数据处理模型后,各算法的预测精度都有一定提高,证明了本文数据处理模型的有效性.另外,BP 神经网络对数据质量的依赖较小,而LSTM、Transformer、Improved_Transformer 等深度神经网络算法则对训练数据质量要求较高,经过上文提出的数据模块之后预测精度有较大提高.每种算法单步预测相比小时预测、天预测等多步预测精度都要高,原因是多步预测会引进多个单步预测的累计误差.图9 可以更直观地展示出各算法的拟合预测精度.R2衡量了预测值对于真值的拟合好坏程度,R2越接近1,代表拟合效果越好.如图9 和表3 所示,本文提出的CAT_Imp_Transformer算法可以在多步预测时仍然保持良好精度,MAE 小于0.03,R2达到0.94,可以完成高精度预测,满足应用需求. 图9 预测结果R2 对比Fig.9 Comparison of prediction results R2 图10 则对8 种算法的预测时间进行了对比分析,单步预测的时间相差不大,12 h 预测中可以看出BP 用时较短约100 ms,Transformer 模型用时较长约2 s;另外经过数据模块量化提取数据特征后,预测时间也有所减少.总之,CAT_Imp_Transformer 算法减小了卫星电量时序预测的误差累计问题,在峰值和谷值都有较好的预测精度,各项指标均有改善,如图11 所示.但是如上分析也展现了该算法对于数据质量要求较高的缺陷,需要对数据进行良好的处理,否则可能无法学习到数据的特性,产生较大误差;相对预测时间相比于BP 等浅层神经网络较长,但是可以限制在数秒内,影响不大,后续可以进一步改善. 图10 预测时间对比Fig.10 Prediction time comparison 图11 预测结果Fig.11 Prediction results 本文阐述了一种卫星耗电量预测方法,由最优量化数据处理模型和改进Transformer 电压预测模型组成,可以在地面端对卫星电源耗电量当前状态进行预测,作为后续任务的可靠支撑.通过本文研究得出以下结论:采用最优尺度变换对分类变量进行合理量化,可以根据数据本身的关联得出符合分布的量化值,再进行统一降维,即分类主成分分析,是一种有效的多型变量数据特征提取算法,通过数据数据处理模型令后续预测时间减少约25%,可以在2 s内完成预测.后续研究可以将数据处理模型轻量化、流程化,使后续的研究数据获取更为方便. 将连续时间步数据输入对抗生成网络架构,能够通过训练Transformer 生成网络和判别网络达到纳什均衡来预测未来时间步数据,结合MSE 作为损失函数,可以达到良好的训练效果,单步预测的MSE为0.000 4,天预测拟合优度达到94%,BP 神经网络拟合优度约为80%,很大程度上提高了预测精度.后续的研究中可以从模型的训练时间改善进行入手,另外可以考虑结合其他方法进行非参数优化,进一步提高模型的精度.1.2 灰色关联分析
1.3 分类主成分分析
2 数据处理分析模型
2.1 源数据
2.2 基于CATPCA 的卫星时序处理模型


3 预测模型
3.1 Transformer 模型
3.2 对抗生成网络架构

4 改进Transformer 卫星能源预测模型
4.1 卫星电源预测模型


5 算例分析
5.1 评价指标
5.2 基于CATPACA 的改进Transformer 耗电预测结果分析

6 结束语
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
军民两用技术与产品(2021年10期)2021-11-25
电子制作(2019年19期)2019-11-23
科学家(2019年3期)2019-08-18
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
科学与财富(2016年28期)2016-10-14
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
