
基于结构化深度聚类网络的人脸表情识别研究*
2023-12-13 03:47胡宇晨李秋生
赣南师范大学学报 2023年6期
胡宇晨,李秋生
(赣南师范大学 a.智能控制工程技术研究中心;b.物理与电子信息学院,江西 赣州 341000)
0 引言
人类的面部表情是对心理情感的一种表达,人与人之间可以通过面部表情来传达情感与社会信息.美国的传播学家Mehrabian通过实验验证了,面部表情的表达占情绪表达的五成之多,心理学家Ekman、Friesen[1]把表情分为6种,分别为开心(happy)、伤心(sad)、惊讶(surprise)、害怕(fear)、生气(angry)与厌恶(disgust).人脸表情识别的应用非常的广泛,可应用于社会公共场合的人脸表情分析,以加强公共治安的管控;在交通领域,可通过人脸表情识别来判断驾驶员是否是疲劳驾驶或酒后驾驶,以降低交通事故的发生;可通过分析犯罪分子的表情、微表情或伪动作来判断犯罪嫌疑人的心理动向等.
在早期的人脸表情特征提取方法中,需要大量的专业知识来分析面部的特征,这就需要专业人士来进行人工的特征提取,再将特征向量输入到分类器中进行训练,如果特征提取的质量较差,会直接影响表情分类的效果.常用的人脸特征提取方法有局部二值模式(local binary pattern,LBP)[2]、局部定向模式(local directional pattern,LDP)[3]和Gabor小波[4]变换等,这样的特征提取方式易受到干扰.随着计算机硬件性能的不断提高,计算机的计算能力得到了极大的提升,同时人工智能与深度学习的兴起,深度学习在人脸表情识别领域得到了广泛的应用,神经网络对于表情图片的复杂特征有着更好的提取,使得识别更加的准确,例如最近兴起的卷积神经网络(convolutional neural network,CNN)[5].CNN只需要将原始图像输入即可,或将表情图像做简单的图像处理,避免了传统的特征提取方法的复杂性.例如LeNet、VGG、ResNet等神经网络常被用来作为人脸表情识任务的基础网络,后来者也是在原有网络的基础上进行改进,改进的方法有增加神经网络的层数,来提取更为精确的面部表情特征,如文献[6]提出了一种融合式的卷积神经网络,该方法将改进的LeNet和ResNet相结合,两个网络独自提取人脸面部表情特征,再将提取的表情特征相结合,特征向量连接,用于分类,该方法可以提高面部表情识别的准确性和鲁棒性.
同时,聚类算法已成功应用于各种现实世界的任务,如图像聚类[7]和文本聚类[8]等.而深度学习在人工智能和机器学习领域的重大突破,使得深度学习与聚类的结合引起了学术界的高度关注.深度聚类[9]的基本思想是将聚类的目标与深度学习强大的表示能力相结合.然而,学习有效的数据表示是实现深度聚类的一个重要前提.例如,使用自动编码器[10]学习K-means方法得到的数据表示.然而,这两种方法的结合通常只关注数据本身的特征,而很少考虑数据的结构信息.
经典的频谱聚类方法[11]将实验数据视为加权图中的节点,并利用数据的图结构信息进行聚类.本文借鉴频谱聚类的思想,并结合图卷积神经网络在编码图结构方面的优势.在结构化深度聚类网络中,利用GCN网络[12]将经过KNN网络预处理的人脸特征点的图结构信息集成到深度聚类过程中.同时,自编码器学习到的人脸特征点信息传递给相应的GCN层,构建了一个双重自监督机制,以统一这两种深度神经网络体系结构,并使整个模型能够不断迭代更新.通过实验验证,本文提出的模型在人脸表情识别任务中展现出较好的识别率.该方法充分利用图结构和人脸关键点特征的有效性,并通过迭代更新不断优化模型性能.
1 相关技术
1.1 人脸关键点的提取
由于不同人的面部通常具有相似的结构特征,而肤色、年龄等因素会导致面部图像在外观上呈现出巨大的差异,这些因素对于表情分类并没有实质性的影响.因此,为了提取更具有意义的结构特征用于表情识别,本文采用图卷积网络对人脸关键点进行特征提取.通过利用GCN的图结构分析能力,捕捉人脸关键点之间的关系和表情信息,从而提取出更具有区分度的特征用于表情分类.这种基于图结构的特征提取方法能够有效地克服面部图像的变化因素,提升表情识别的性能.
在表情识别中,由于表情通常只发生在人脸的局部区域,如眉毛、双眼、鼻子、下颚线和嘴巴等位置.为了提取具有鉴别性的特征,需要根据人脸特征点、动作单元或者人脸上的器官对表情进行区域划分.与表情相关的动作单元几乎都在人脸的眉毛、眼睛、鼻子和嘴巴等区域.本文采用dlib人脸关键点提取算法对图像进行预处理操作,并提取68个关键点[13]进行区域划分,如图1所示.为了减少计算量,每个关键点仅使用位置特征表示,即对于某一关键点,其特征表示为坐标.

图1 人脸68关键点示意图
作为常用的人脸特征点提取技术,dlib算法提取的68个关键特征点能够显著定位和标识面部轮廓,包括外轮廓17个点、左右两个眉毛各5个点、鼻子九个点、左右眼睛各6个点、嘴部20个点(包含嘴部内圈和外圈).这68个点能够更加详细地描述人脸眼睛、眉毛、鼻子、嘴巴和外轮廓的位置信息.
1.2 KNN图构建
将经过局部二值化处理的表情图像转化为图结构形式,假设经过预处理图片的所有像素点矩阵为X∈RN×d,每一行的xi代表第i个样本,为每一张图片的像素值,N为样本个数,d为数据的维度.对于每个样本,首先找到它的前K个相似领域,并设置边来连接这些领域.用来构建各样本的相似领域矩阵S∈RN×N的计算方法有很多种,本文列出了两种方法:
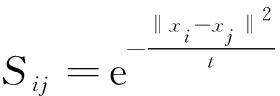
(1)
Sij=xjTxi
(2)
再计算完矩阵S之后,选取每个样本的前k个相似点作为近邻,构造无向k近邻图.此方法可以从非图数据中得到邻接矩阵A.
1.3 自编码器与解码器
正如之前提到的,学习有效的数据特征对于深度聚类非常重要.对于不同的数据类型有不同的无监督学习方法,如去噪自编码器[14]、卷积自编码器[15]、LSTM编码器[16]与生成对抗式自编码器[17],以上都是一些不同神经网络结构的自编码器.因通用性的考虑,本文采用了最基本自编码器对人脸表情图片进行表示,图2所示为自编码器的结构.

图2 自编码器结构
假设自编码器中有L层,ζ表示网络层数.编码器第ζ层的学习,可用H(ζ)表示,公式如下:
(3)

(4)
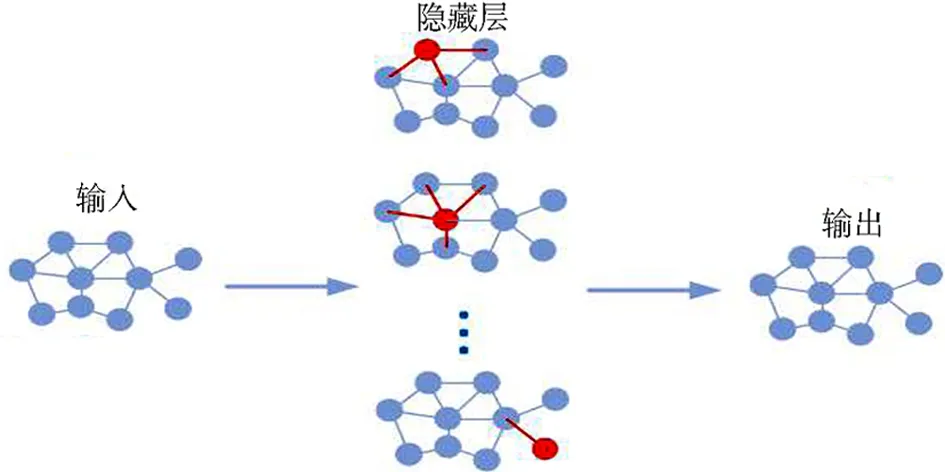
图3 图神经网络结构

图4 图卷积计算示意图
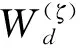
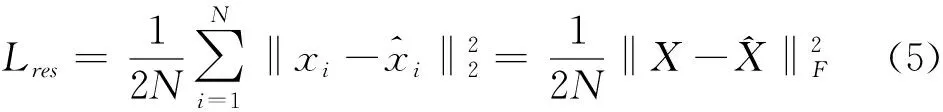
1.4 GCN图卷积神经网络
自编码器模块学习的图片特征整合到GCN模块并传递给下一层,如此GCN网络将同时学习两种不同数据信息,即图像数据本身的信息特征和图像之间的关系信息.图3所示为GCN图卷积神经网络的结构.
假设权值矩阵为W,通过卷积计算即可得到GCN第ζ层的图卷积信息Z(ζ),可用如式(6)表示,图4所示为图卷积计算示意图.

(6)

Z(ζ-1)=(1-ε)Z(ζ-1)+εH(ζ-1)
(7)


(8)
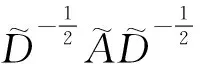
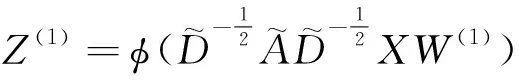
(9)
GCN网络的最后一层是具有softmax功能的分类层:

(10)
1.5 双自监督模型


图5 SDCN结构化深度聚类网络
对于第i个样本和第j个聚类,本文用t分布[18]作为内核来度量数据特征hi与聚类中心向量μj之间的相似性,如下所示:
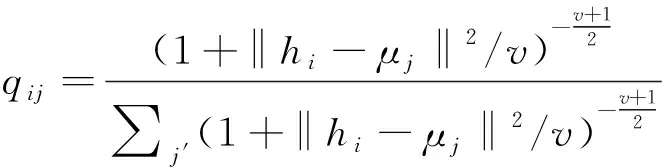
(11)
其中hi是H(L)的第i行,μj通过K-means对预训练编码器学习到的特征进行初始化,v是t分布的自由度,qij可以看作是将样本i分配到聚类j的概率.将Q=[qij]作为所有样本分配的分布.在获得聚类结果分布Q后,通过学习高置信度赋值来优化数据表示,即数据表示更接近聚类中心,从而提高聚类内聚性.计算目标P分布公式如下:

(12)
其中fj=∑jqij为软聚类频率.在目标分布P中,Q中的每个赋值都被平方并归一化,使得赋值有更高的置信度,从而得到以下目标函数:
从图7可以看出,在未加补偿网络时,电路没有正常运行,输出电压为3.5 V。并且,电路的输出电压会随着串联电阻或并联电阻的扰动引入而发生变化,输出电压不稳定;当加入1 V的电源扰动时,电路输出电压明显增大。
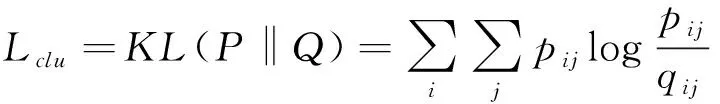
(13)
对于GCN模块的训练,可以将聚类任务作为一种真值标签,但是这种策略会带来噪声和琐碎的麻烦,并导致整个模型崩溃.如前所述,GCN模块也将提供一个聚类分配分布Z.因此,可以使用分布P来监督分布Z,如下所示:
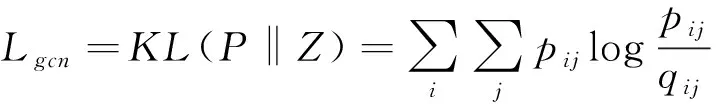
(14)
通过这种机制,SDCN可以直接将聚类目标和分类目标两个不同的目标集合在一个损失函数中.因此,提出的SDCN的总体损失函数为:
L=Lres+αLclu+βLgcn
(15)
其中α>0是平衡原始数据聚类优化和局部结构保持的超参数,β>0是控制GCN模块对嵌入空间扰动的系数.
2 实验结果与分析
为检测本文算法性能,实验环境为:CPU是Intel(R) Core(TM) i5-9500 CPU,频率为3.00 GHz,内存为8 GB,电脑的操作系统为Win10.

表1 各数据集表情总类分类数量

图6 JAFFE数据集样图

图8 FER2013数据集样图
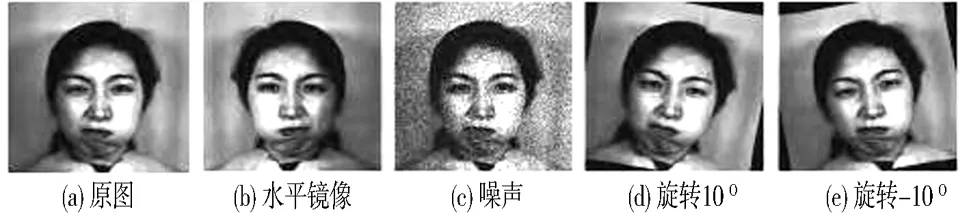
图9 旋转图像
2.1 实验数据集
本文采用的是JAFFE[19]、CK+(Extended Cohn-Kanada)[20]与Fer2013人脸表情数据集进行实验,实验数据集的表情总类分类数量如表1所示.其中JAFFE数据集中含有10名女性,且每为女性的图片都包括7类表情图片,有愤怒(angry)、厌恶(disgust)、恐惧(fear)、高兴(happy)、悲伤(sad)、惊讶(surprise)、自然(neutral).每张图片的大小为256*256,一共包含213张.如图6所示.
CK+(Cohn-Kanada)数据集中包括123个对象,981张不同的表情图片,包含愤怒(angry)、厌恶(disgust)、恐惧(fear)、高兴(happy)、悲伤(sadness)、惊讶(surprise)、蔑视(contempt).如图7所示.
Fer2013数据集图片的数量为35 886张图片,分为表情愤怒(angry)、厌恶(disgust)、恐惧(fear)、高兴(happy)、悲伤(sad)、惊讶(surprise)、自然(neutral).每张图片大小为48*48,该数据集的样本每种表情的图片数量分布不均匀,不易分辨图像的表情,以及拍摄人脸的角度问题增加了分类的难度,数据集图片如图8所示.
2.2 实验数据预处理
由于CK+与JAFFE数据集的样本数量较少,直接使用数据集会导致特征提取的准确度较低,本文通过旋转图像方法来增加训练集数量,再用DCGAN(深度卷积生成对抗网络)生产更多的表情图片.通过数据增强,JAFFE数据集经挑选得到916张图片,CK+数据集经挑选得到4 895张图片,极大地扩充了CK+、JAFFE的训练数据集.图9所示为数据增强效果示意图.
2.3 评价的标准
在图像的分类问题中,评价该分类方法的标准有准确率(Accuracy)、混淆矩阵(Confusion matrix)等,本文采用准确率与混淆矩阵作为评价分类的标准.其中准确率的公式为:

(16)
在式中TP为正例分类正确的数量,TN为负例分类正确的数量;P和N分别为所有的正例和负例.本文的混淆矩阵可表示为表2:

表2 混淆矩阵
表2中的TP表示为正例分类正确图片数,FP为正例分类错误图片数,TN为负例分类正确图片数,FN为负例分类错误图片数.
2.4 实验结果
为验证本文方法效果,实验结果给出了SDCN网络和其它一些方法的识别率和混淆矩阵.

表3 FER2013识别率对比
表3给出了在Fer2013数据集上的性能比较结果,其中包括MI+MI、Mixer Layer、Eric Carman、Lor Voildy等4种算法.从表中可以看出,MI+MI算法的分类准确率并不理想,仅为61.1%,Mixer Layer、Eric Carman、Lor Voildy算法准确有所提高,但也仅有2%~4%的提升,并不明显.而本文算法相比较与MI+MI算法有着9%的提升,与Lor Voildy算法比较也有着5%的提升,分类准确率有着较大的提升,识别率达70.3%.而该网络在此数据集上的识别率仅为70%左右的原因在于,该数据集存在大量的表情图片不规范,如侧脸、手部遮挡,不同表情数量分布不均,部分图片表情与标签不符,此外,一些图片呈现复合表情,这会给网络的训练带来一定挑战,增加了识别的难度.从图10的混淆矩阵图中可以发现高兴表情的识别率最高,达到了80%,而恐惧表情的识别率最低,仅为56%.
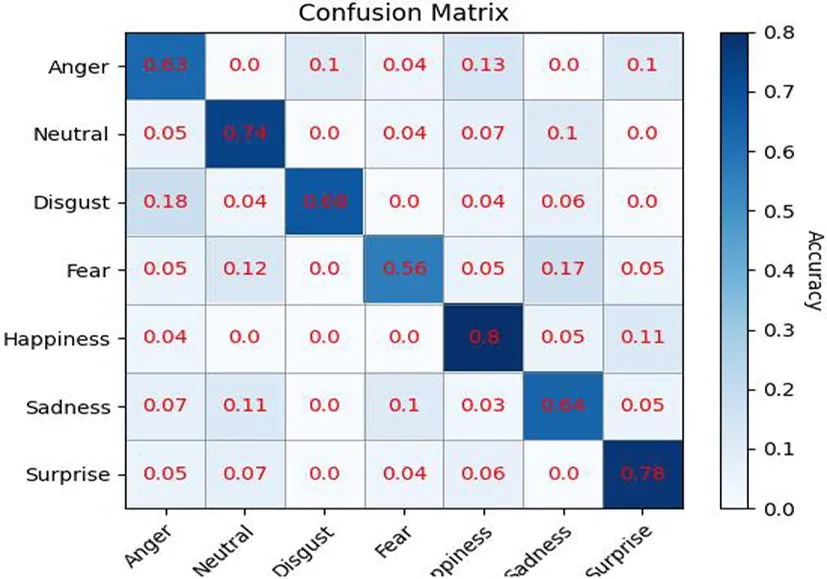
图10 SDCN网络在FER2013数据集上的混淆矩阵
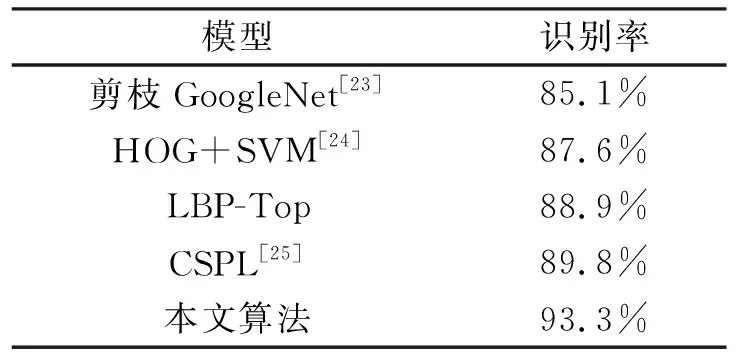
表4 各模型于CK+的识别率对比
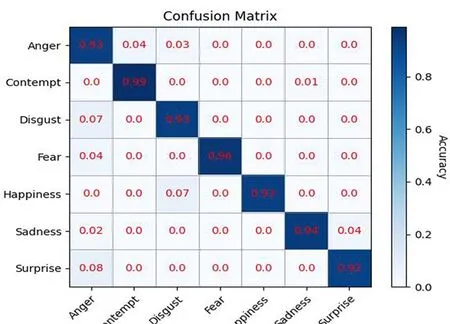
图11 SDCN网络在CK+数据集上的混淆矩阵
表4给出了在CK+数据集上的性能比较结果,其中包括剪枝GoogleNet、HOG+SVM、LBP-Top、CSPL等4种算法.从表中可以看出剪枝GoogleNet算法的分类准确率为85.1%,传统HOG+SVM、LBP-Top算法与CSPL算法模型识别率分别为87.6%、88.9%与89.8%,较剪枝GoogleNet算法有着2%~4%的提升.而本文算法相比较剪枝GoogleNet算法有着8%的明显提升,与HOG+SVM、LBP-Top算法与CSPL算法比较也有着4%~6%的提升,分类准确率有着较大的提升,识别率达93.3%.而该网络在此数据集上的识别率不同于Fer2013的原因在于,CK+数据集是在实验环境下获得的数据集,图像质量较高,表情与人脸采集较为规范,并且该数据集通过数据增强与DCGAN网络的处理使得数据集数量增加,所以在该数据集上表情识别率较高.从图11的混淆矩阵图中可以发现,各表情的准确率都较高,当中蔑视表情的识别率最高,达到了99%,而惊讶表情的识别率最低,为92%.
表5给出了在JAFFE数据集上的性能比较结果,其中包括剪枝GoogleNet、LBP+SVM、传统LDP、GL-DCNN等4种算法.从表中可以看出剪枝GoogleNet算法的分类准确率最低为83.8%,传统LBP+SVM算法、传统LDP与卷积神经网络GL-DCNN算法模型识别率为88.2%、89.8%、92.9%,较剪枝GoogleNet算法有着5%~9%的提升.而本文算法相比较剪枝GoogleNet算法有着10%的明显提升,与传统LBP+SVM算法、传统LDP与卷积神经网络GL-DCNN算法比较也有着2%~5%左右的提升,识别率达94.5%.
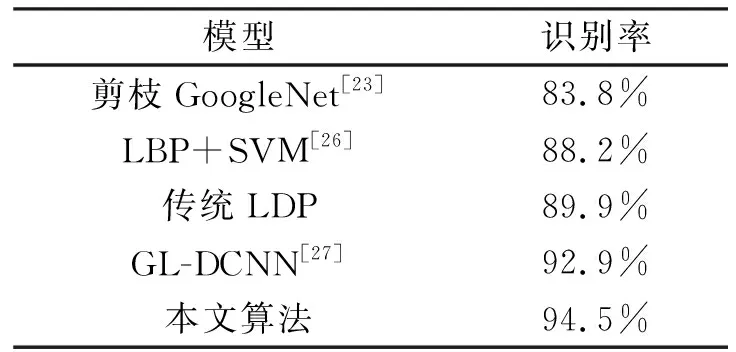
表5 各模型于JAFFE识别率对比

图12 SDCN网络在JAFFE数据集上的混淆矩阵
JAFFE数据集与CK+数据集类似,都是在实验环境下获得的数据集,图像质量较高,表情与人脸图像的采集较为规范,且JAFFE采样者都为女性,每个女性的相同表情具有较多的相似性,所以在该数据集上表情识别率较高.从图12的混淆矩阵图中可以发现除恐惧与悲伤外,其他各表情的准确率都较高,原因在于恐惧与悲伤表情中有较多的相似特征,使得两表情的识别率偏低.其中蔑视表情的识别率最高,达到了99%,而惊讶表情的识别率最低,仅为92%.
总体来看,以上三个数据集的实验可以验证人脸关键点的结构化特征与SDCN网络相结合有效提高了人脸表情识别的准确率和泛化性能.
3 结论
为了解决卷积神经网络在人脸表情识别中存在的特征提取不足以及关键区域特征无法精确提取的问题,本文提出了一种创新的人脸表情识别网络.该网络利用GCN图卷积神经网络对人脸表情图像中的关键点进行特征提取,并将预处理的表情结构化特征与SDCN网络相结合,充分利用人脸表情中的结构信息.该网络由GCN网络、K-最近邻(KNN)图构建网络和编码器网络等模块组成,在双自监督模型的作用下,将自动编码器和GCN模块统一在一个框架中,并有效地端到端训练两个模块提取的特征,相互协作,提高了人脸表情识别的准确率和泛化性能.
针对数据集样本不足的问题,本文采用了数据增强和DCGAN网络生成更多的表情图片的方法.在Fer2013、CK+和JAFFE这三个大型数据集上进行了对比实验,通过混淆矩阵分析发现,本文方法在这三个数据集上的识别率分别达到了70.3%、93.3%和94.5%,与现有方法相比,在表情识别的准确率方面具有优势.
通过这种方法,表情图片的特征重构过程从低维到高维不断接近自编码器学习到的多重特征.经过实验证明,本文提出的模型在人脸表情识别任务中表现出较好的识别率.该模型的设计充分考虑了图结构和人脸关键点特征表示的有效性,并通过迭代更新不断优化模型的性能.
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
动漫星空(2018年9期)2018-10-26
成都信息工程大学学报(2018年3期)2018-08-29
中国交通信息化(2018年3期)2018-06-13
电子设计工程(2017年20期)2017-02-10
中国交通信息化(2016年2期)2016-06-06
电子器件(2015年5期)2015-12-29
发明与创新(2015年33期)2015-02-27
