
基于改进DeepLabV3+算法的高分影像地物分割研究
2024-01-10 08:30龙北平刘锟铭占小芳李恒凯
江西科学 2023年6期
龙北平,刘锟铭,占小芳,李恒凯
(1.江西省地质局地理信息工程大队,330001, 南昌; 2.江西理工大学,341000, 江西,赣州)
0 引言
随着遥感技术的进步及设备的更新,通过无人机获取遥感影像成为一个主流趋势,且通过无人机影像实现分类的方法在农业、林业、环境监测、城市规划、灾害响应等领域中得到广泛应用。无人机以其灵活性高、操作简便等优势,可获取具有丰富空间和光谱信息的遥感影像,为地物分类提供更准确的特征。无人机所获取的高分辨率遥感影像使得目标对象的几何、纹理和光谱特征等更加明显,从而为目标对象信息的提取与分类提供了大量的新特点[1]。早期的遥感图像的分割主要为基于边缘监测[2]和影像特征[3]的分割方法。然而,新特征增加的同时也伴随着干扰和冗余信息的增加,这导致传统的遥感信息提取方法已不足以满足实际需求。为此需要一种全新的手段,对高分辨率遥感影像的信息进行高精度提取与分类。
当前,计算机与数据资源的高度结合,为深度学习技术的发展起到了强力的推动作用,使得深度学习成为当下热门的研究领域[4]。深度学习方法不仅能够深入挖掘地物的深层次特征信息,还为高分辨率遥感影像地物的分类提供了新的思路[5]。虽然牛全福等[6]的研究证明传统的随机森林方法对耕地、林地、草地和灌木具有较好的可分性。但面对海量的遥感数据,深度学习方法似乎是更佳的选择,因此越来越多的学者将深度学习方法应用于遥感影像的图像分类、地物类型的识别和地物信息的提取等领域[7]。徐丽坤等[8]通过大量实验优化了深度信念网络模型的网络层数、神经元个数和迭代轮次等参数,构建出最优深度信念网络,并将该模型与传统的浅层网络分类器进行对比,证明了该方法在高分辨率遥感影像的分类研究中具有较高的分类精度。朱袁杰等[9]利用卷积神经网络(CNN)能够根据特定场景语义来分析训练影像的优势,对南京市建邺区城市绿地用地进行分类,结果表明,该模型的分类准确度高达87.74%。然而,随着大量数据的堆叠,影像特征信息的丰富,这些经典的深度学习模型在地物分类的精度上再有所提升是相对较难的。
近年来,DeepLabv3+语义分割网络逐渐出现在大众视野[10]。DeepLabv3+模型是DeepLabV1模型不断改进优化得到的,最初的DeepLab V1是于2014年提出的第一个版本,采用了全卷积网络(Fully Convolutional Network)的思想来进行语义分割。该模型使用了空洞卷积(Atrous Convolution)来增大感受野,并引入了条件随机场(Conditional Random Field)进行细化。随后的DeepLabV2则是在其基础上引入了空洞空间金字塔池化(ASPP)模块,用于捕捉不同尺度下的上下文信息。ASPP模块通过多尺度空洞卷积和金字塔池化的结合,提高了分割模型对多尺度物体的理解能力。DeepLabV3则是为了进一步提升模型的收敛性和稳定性引入了残差连接和批归一化技术,同时使用了更为强大的主干网络。在2018年所提出的DeepLabv3+引入了空洞可分离卷积(Depthwise Separable Convolution)来减少参数量和计算量,并采用了更大的感受野和更密集的特征金字塔,使其能够处理更为复杂的遥感影像,极大提升影像的分类精度[11]。同时,其具有清晰的网络结构和能够捕获多尺度信息的优点,在遥感影像信息解译提取方面得以广泛应用。文献[12]利用DeepLabv3+模型对复杂分辨率影像中养殖用海信息进行提取并分类,并将分类结果与传统的机器学习分类结果进行对比,证明了DeepLapv3+的准确性和有效性。文献[13]利用DeepLapv3+提取高分辨率遥感影像的典型要素,实现了对分割信息边界的优化,结合形态学滤波处理,要素边界轮廓明显优于初始分割结果。文献[14]基于DeepLapv3+模型,从样本数据平衡的角度出发,调整权重系数,使DeepLabV3+模型对于遥感影像中建筑垃圾的分割mIoU达到82%。
上述文献研究表明,基础的DeepLapv3+网络在很多领域均能取得显著成效,可应用于高分辨率遥感影像地物分类研究中。但基础的DeepLabv3+网络依旧存在缺陷,如训练速度慢、边缘目标分割精度低等问题。针对上述问题,本文以寻乌县作为研究区域,提出一种引入双注意力机制的DeepLabv3+网络模型,以期弥补DeepLabv3+算法缺陷,为高分辨率遥感影像的地物分类提供方法借鉴。
1 研究区和数据
1.1 研究区域概况
寻乌县(115°21′22″~115°54′25″E,24°30′40″~25°12′10″N)位于江西省赣州市东南边境(图1),处于广东、福建、江西三省交汇地界,该县总面积约为2 300 km2,属亚热带季风气候,雨量充足,气候温和,是典型的丘陵山区农业县。

图1 研究区地理位置及部分无人机影像
1.2 研究数据
本研究所使用的数据来自于实地采集的高分辨率无人机遥感影像,包括有分布在寻乌县内的12景影像。影像有红、绿、蓝三个波段,空间分辨率均为0.5 m,每张影像的大小均在10 000像素×10 000像素以上。将所采集到的无人机影像进行影像校正、去噪及影像增强等预处理后,得到无人机正射影像。由于受到计算机GPU内存限制,需要对原始影像进行裁剪,通过调用GDAL库,将其批量裁剪为大小为256像素×256像素的影像,再通过目视解译的方法在影像上标绘出不同的地物类型作为样本标签,构成地物类型数据集。最终,按照4:1的占比将数据集分为训练集与测试集。
2 研究方法
2.1 方法
2.1.1 改进的DeepLabv3+网络 经典的DeepLabv3+网络于2018年[15]提出,该算法在原有的DeepLabv3网络上加以完善,添加了编码-解码结构,使之成为了现阶段DeepLab网络系列中最优秀的网络。
首先,原始的Deeplabv3+网络的编码器部分采用Xception网络结构[16]来提取特征获得高层特征,然后将高层特征输入到ASPP(Atrous Spatial Pyramid Pooling,空洞空间金字塔池化)模块中,进行影像特征提取,获得多尺度信息。其中ASPP模块主要有5个并行分支组成,特征图输入后将经过1x1卷积,扩张率为6、12、18的3x3卷积和全局平均池化操作,最后对特征融合后的特征图进行1x1卷积以降低通道密度。最终,通过ASPP能够识别不同尺度的目标特征信息,有效地分割多尺度目标。解码器部分主要是将高、低层特征相融合,将编码器提取的高层特征经过4倍上采样至低层分辨率,将低层特征通过1x1卷积将通道数降到48,后将上采样后的高层特征与低层特征融合,再经过3x3卷积进一步提取细化后的特征,最后通过上采样恢复至输入图像大小,输出模型的最终预测结果。
而本研究中将特征提取网络更换成更为轻量化的MobilenetV2,来减少模型的参数量和计算量,从而降低计算机GPU的压力。MobileNetV2引入了一种新的网络结构,称为倒残差块(Inverted Residual Block)。这种块结构能够在保持模型轻量级的同时提高网络的表达能力和学习能力,通过使用1x1卷积进行特征维度扩展和降维,然后使用3x3的深度可分离卷积进行特征提取。并且,MobileNetV2结合了多尺度特征表示的方法,通过引入多个不同大小的倒残差块和特征融合技术,使网络能够同时处理不同尺度的特征,从而提高对多尺度目标的检测和分类能力。
同时,本文在原始Deeplabv3+的网络结构基础上进行优化,在网络的高层次语义特征提取模块中加入通道注意力机制,对低层次的语义特征加入空间注意力机制,优化后的网络结构如图2所示。

图2 改进Deeplabv3+网络结构
2.1.2 通道注意力机制 通道注意力机制通过利用特征的通道间关系来产生通道注意力图。因为特征图的每个通道都被视为特征检测器,所以通道注意力注重输入图像是否有意义。为了更好地计算通道注意力,对输入特征图的空间维度进行压缩。同时,常用平均池化来聚合空间信息,但最大池化在收集特殊特征时能得到更好的效果[17]。所以,本文同时使用了平均池化和最大池化。通道注意力模块如图3所示。

图3 通道注意力机制
特征图分别进行2种池化操作后,得到2个相应且不一样的空间特征描述符,然后将它们分别传递到共享网络,最后,对每个特征求和并输出特征向量。其过程可用式(1)表示[18]:

(1)
式中,x表示输入信息,W1和W0分别表示共享网络的权重系数,⊗表示像素分别进行乘积。
2.1.3 空间注意力机制 空间注意力与通道注意力不同,空间注意力更注重输入图像哪里是有意义的地方,与通道注意力相互补充。为了计算空间注意力,沿着通道轴进行池化操作,即每次池化时对比的是不同通道间的数值,而非同一通道不同区域的数值。最后进行组合形成有效的特征描述符。空间注意力模块如图4所示。

图4 空间注意力机制
2.2 模型参数构建及模型评价指标
2.2.1 模型参数构建 根据本文提出的引入双注意力机制的V3+MobilenetV2混合网络模型对获取到的寻乌县无人机高分辨率RGB影像进行训练与优化。该模型基于TensorFlow深度学习框架,网络模型的具体参数设置如下:首先,学习率作为网络模型重要超参数,在模型训练过程中,学习率的不同跳动范围会使得网络模型产生过拟合或欠拟合等状况发生,为解决这一问题,研究将初始学习率设置为0.005,并采用CosineAnnealing(余弦退火)学习率衰减机制让学习率在模型训练过程当中不断降低,从而加速模型收敛,防止出现过拟合等现象。其次,为降低梯度系数或梯度存在较大噪声问题,使用Adam优化器,同时将参数momentum设置为0.9。最后,使用Focal Loss作为损失函数,用于平衡正负样本。
2.2.2 轻量级特征提取网络与深层次特征提取网络对比 本研究以DeeplabV3+模型基础,分别设计L-DeeplabV3+(Lightweight DeeplabV3+ model,轻量级DeeplabV3+模型)以及D-DeeplabV3+(Deep DeeplabV3+ model,深层次DeeplabV3+模型)进行对比试验,分别以轻量级网络MobilenetV2、深层次网络Resnet50作为模型的主干特征提取网络进行模型的训练。
2.2.3 双注意力机制对模型优化的有效性验证 为验证双注意力机制对轻量级网络模型优化的有效性,本研究设计的DAD-DeeplabV3+(Dual attention mechanism Deep deeplabV3+ network model,双注意力机制深层次deeplabV3+网络模型),以及DAL-DeeplabV3+(Dual attention mechanism lightweight deeplabV3+ network model,双注意力机制轻量级deeplabV3+网络模型)与L-DeeplabV3+、D-DeeplabV3+进行对比试验。
2.2.4 模型评价指标 对于一个随机样本,其模型预测结果有以下4种情况:1)真阳性(True Positive,TP),预测为正样本,实际也是正样本;2)假阳性(False Positive,FP),预测为正样本,实际为负样本;3)真阴性(True Negative,TN),预测为负样本,实际也是负样本;4)假阴性(False Negative,FN),预测为负样本,实际为正样本。
交并比IoU是某一类预测值和真实值的交集和并集之比,像素精度Accuracy为预测正确样本数占总样本数的比例,精确率Precision为预测正确的正样本数占预测为正的样本数的比例,召回率Recall为所有的正样本中被模型成功预测出来的数量占的比例。交并比、像素精度、精确度、召回率的计算公式如下:
(2)
(3)
(4)
(5)
本研究以平均交并比mIoU、平均像素精度mPA、平均精确度mPrecision和平均召回率mRecall作为评价指标对模型预测结果进行评价,计算公式如下:
(6)
(7)
(8)
(9)
3 结果与分析
为验证本文对模型优化的有效性,选取寻乌县域内部分无人机遥感影像作为验证集对模型进行验证,通过模型的预测,得到复垦地、果园、林地、水域、工业用地、道路、建筑用地及耕地8种地物类别。在相同验证影像数据集内,通过对轻量级网络模型、深层次网络模型及加入双重注意力机制的模型进行对比试验,所得到的各模型的各项评价指标均值如表1所示。
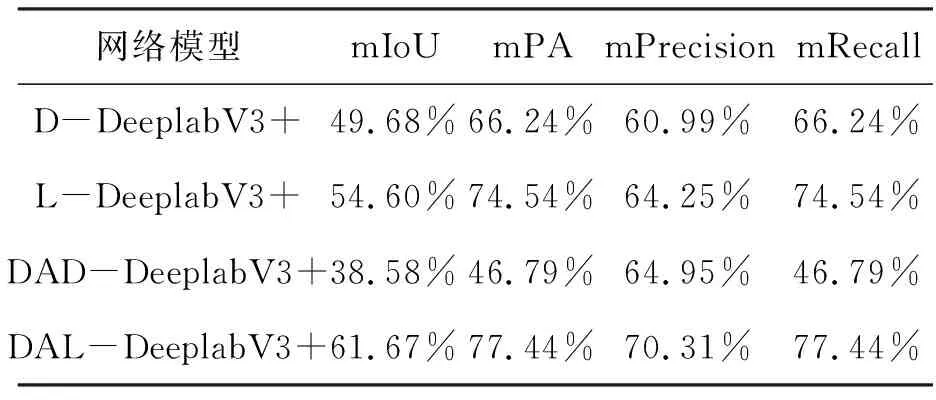
表1 上述各模型评价指标对比
在表1中,轻量化网络的表现明显优于深层次网络,在没有注意力机制优化的模型当中,轻量化网络的各项评价指标均值远高于深层次网络模型。且在使用双重注意力机制对深层次网络模型进行优化之后,模型的各个评价指标均值不升反降,可见双重注意力机制对深层次网络模型并没有优化效果。但在轻量化网络当中加入双重注意力机制模块优化后,模型的表现显著提升。
根据表1所示,本文所提出的DAL-DeeplabV3+模型在各项模型评价指标当中均为最优值。相对于效果较好的L-DeeplabV3+而言,DAL-DeeplabV3+模型精度在mIoU、mPA、mPrecision及mRecall4个指标上分别提升了7.07%、2.90%、6.06%、2.90%,全方位地提升了模型的语义分割能力。
表1中的数据为模型各项评价指标均值,所反映的是各个模型的整体性能。为反映出模型对于各类地物的分割能力,将模型运用到各类地物的预测当中,各模型对于地物的分割精度如图5所示,本文所提出的DAL-DeeplabV3+模型在复垦地、园地、林地、水体、道路、建筑用地及耕地这6类地物的分割上具有较高精度,分割精度分别为0.83,0.92,0.82,0.90,0.96,0.84,0.72,而对于工业用地的分割效果与其他各模型都较差,精度都低于0.5。

图5 模型分割精度
为了更细致准确地表达各模型对不同地物的分割效果,对比分析不同模型下的各地物分类精度(图6)。研究结果显示,本文所提出的DAL_DeeplabV3+模型在地物交界处能够分割得更精细,林地以及道路等地物类型的分割结果与标签的真实值最接近。在第一组的对比影像当中,地物类型较为简单,只包含未利用地和林地两类,本文所提出的模型对影像的预测值与真实值基本相同,而其他模型都与真实值有一定偏差。同样,在第二组对比影像中,本文所提出的模型对影像的预测值也是与真实值较接近的,在地物边界处其他几个模型预测出真实值中不存在的地物类型,而本文所提出的模型并没有。而在第三组的对比影像当中,由于林地与园地的影像特征接近,模型出现了错分的情况。
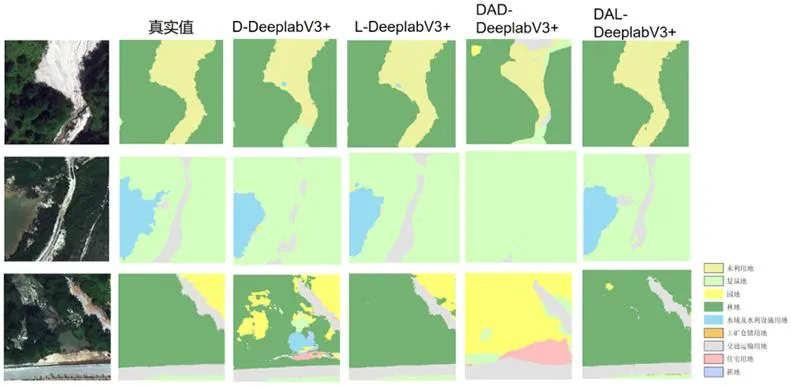
图6 各模型分类结果示意图
总体而言,针对南方山地丘陵地区的复杂地物情况,本文所提出的DAL_DeeplabV3+模型对于地物的识别取得较好的效果。在地物分类任务当中降低了地物错分的概率,使地物分类更接近地表的真实值,在高分辨率遥感影像地物分类的任务中能够较为准确地对地物进行识别、分类。
4 结论
本研究以DeeplabV3+为基础,针对无人机高分辨率RGB遥感影像,提出加入双注意力机制的算法:1)在高层次语义特征提取模块中加入通道注意力机制;2)在低层次语义特征提取模块中加入位置注意力机制。实验结果表明相对于原始算法进行优化后的模型在mIoU、mPA、mPrecision以及mRecall4个指标上分别提升了7.07%、2.90%、6.06%、2.90%,有效地提高了高分辨率影像的分类精度。同时,在多个方面提升了深度学习语义分割模型南方山地丘陵地带的地物分类精度。
然而,在工业用地的分类上,各模型的分割精度均不理想。这是由于在寻乌县域内存在较多的矿区以及各类厂房,工业用地的地表特征复杂多样、模型难以区分,因此,导致分割精度较低。这也是后期需要对模型进行优化的一个方向。从研究结果也可以看出,模型对于地物类型分割的平均精度不是很高,其原因是应为各地物类型之间的分割精度差异较大,多个类型地物的分割精度都在85%以上,少数类别的地物分割精度较低,从而拉低了整体的精度,其中对于道路的分割精度最高,对于工业用地的分割精度最低。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
电视技术(2014年19期)2014-03-11
