
基于AISI网络的虚拟场景多视图三维重建模型研究*
2024-01-10 08:36陈金娥
桂林航天工业学院学报 2023年4期
陈金娥
(安徽医学高等专科学校 人事处,安徽 合肥 230601)
多视图三维模型重建方法近年来被广泛地应用于医疗诊断、建筑施工、空间设计、场景侦查等领域,具有良好的发展空间。
文献[1]提出了多层次感知的多视图三维模型重建方法,采用权值共享和解码器实现虚拟场景多维度的搭建,但是输出的三维重建模型结果与实际设计目标偏差过大,结果不可靠,很难满足精度要求高的用户需求。文献[2]采用基于超点图网络的三维点云室内场景分割模型方法,利用胶囊卷积网络,通过三维模型的体素感知原理,实现场景多视图的模型重建。此方法可以实现简单的虚拟场景三维重建,但是对于特殊的场景设计,无法做到自适应调整,具有针对性。
为此本文提出基于AISI网络虚拟场景多视图三维重建模型研究方法,通过ASIS网络框架、代价体正则化以及特征感知原理,提高三维重建模型的精准度、完整性和有效性为目的,满足各个领域的发展需求。
1 ASIS网络框架原理分析
ASIS网络框架的工作内容是将三维立体场景根据连接特征,提取主干网络,再分别切割出语义信息一致的实例[3]。框架原理如图1所示。

图1 ASIS网络框架原理图
1.1 构建代价体
代价体代替传统多视图三维重建模型的图像一致性学习过程,利用视觉特征点,完成空间虚拟场景中实际距离的推断,降低实际场景与虚拟场景之间的误差。场景深度平面个数计算公式如式(1)所示:
(1)
其中,M表示虚拟场景深度平面的个数,S表示深度间隔尺度变量,n表示两个待计算平面角度的间隔相机椎体变量,∂表示平面空间中特征通道个数,Li表示图像数据集合。
本文通过可微分单应性变换方法构建代价体,构建代价体前需要确定虚拟场景搭建需要平面的个数,依次控制模型遍历计算的范围[4]。单应性矩阵的优点是通过平面扫描算法识别虚拟空间图纸内的各类特征点,矩阵计算公式如式(2)所示:
(2)

单应性矩阵扫描方法可以计算三维空间构件之间的距离和,不仅保证扫描精度和准确度,而且扫描范围大,降低扫描时间,提高虚拟场景深度平面识别效率[5]。扫描实例如图2所示。

图2 回归网络扫描边缘框架图(以门为实例)
1.2 代价体正则化与回归网络
代价体正则化与回归网络是过滤视图图像的噪声干扰,借助squash函数达到提高网络信息拟合精确度的需求[6]。squash函数如下:
(3)
其中,Hi表示卷积层的输入量,Ki表示卷积单元,Ri表示正则化遍历的步长,t表示样本数据时间维度,dj表示模量计算尺度;kt表示噪音因子。
将构建的代价体进行正则化分类,将虚拟场景中可以连接的搭建节点进行过滤分类,可以一定程度上减少重建模型的计算量[7]。代价体正则化编码过程图如图3所示。

图3 代价体正则化编码过程图
将转换的网络信息利用squash函数进行调用,输出虚拟场景多视图重建的边缘集合,调用映射函数实现一一对应的深度映射关系,避免平面要素丢失,保证虚拟场景重建模型的精准度[8]。映射函数如式(4):
(4)
其中,Fi表示图像的映射函数,d(p)表示有效的图像像素集合,Hr表示映射发出端的深度值,l表示像素初始深度的估计值,f(loss)表示损失函数,di(p)1表示训练元素深度推断概率体的期望值。
代价体回归网络模拟图如图4所示。
代价体回归网络的特点是数据训练时间长,对于三维虚拟场景边界的识别和构建清晰明确,更好的固定模型的参数量和场景边界,以便生成更加清晰的模型图像。

图4 代价体回归网络模型图
2 虚拟场景多视图三维重建模型设计
2.1 获取多视图三维数据
以单个构建为单位,分别遍历多视图图像的各个实例,获取场景的单元参数。为了保证三维场景的高度还原,本文设定获取的多视图三维数据由4个必备参数组成。参数1为三个方向的坐标定位值以及相对位置坐标;参数2为构建的颜色信息;参数3为视图图像的语义标签,用于表示该单元的类别和切分区域;参数4为普通数据,用于后期数据编译,提取特征参量[9]。四个参数分别从位置、细节、特征三个方面对视图单元进行定位,使得获取的数据具有分析意义。网络框架分割原理图如图5所示。

图5 ASIS网络框架分割原理图
2.2 初始三维图像预处理
对于三维图像数据的预处理分别两部分,首要是遍历多视图三维数据库,通过ASIS网络框架对虚拟场景图像进行分割,另外是筛选出虚拟场景空间的细节特征、位置特征、显著特征。
分割模块的依据是协调三维数据的语义标签和位置标签的信息,将每个实例进行分类,然后通过代价体回归网络计算,核算出不同实例类别之间的分界线[10]。对于一个构件内的总多实例,采用二层编码的方式进行记录,一层记录所属构件单元,二层编码记录维度内的实例,区分各个点的所属位置[11]。特征矩阵如式(5):
(5)

构件、实例切割后,对每个区域内的数据进行筛选,通过特征矩阵提取出具有代表意义的特征量,为虚拟场景多视图架构重建奠定相对位置基础[12]。
2.3 虚拟场景多视图并行匹配
虚拟场景的多视图并行匹配的要素为细节特征、位置特征、显著特征,只有从多个角度对构建模型进行约束,才可以高度还原虚拟场景的位置[13]。并行匹配原理如图6所示:

图6 虚拟场景多视图并行匹配原理图
细节体征包括构件的形状特征、大小特征,细节特征计算公式如下:
(6)
其中,L(X)表示细节特征表达式,w表示批标准化,αCon(X)表示修正线性单元,β表示卷积核尺寸,ConV2表示特征向量。
显著特征表达式如下:
(7)
其中,G(X)表示显著特征,L表示全局通道数量,ε(X)表示全局最大池化,b表示突出概率比。
显著特征的识别是通过全局的池化对输入数据进行过滤,提前会设定好已经存在体素的特征,利用卷积操作辨认显著特征与其他特征表现出的体素差异,进行匹配对应即可[14]。
位置特征如式(8):
(8)
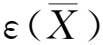
位置特征的感知条件是将虚拟场景的三维立体维度进行压缩,选择全局平均池化对有效数据进行识别,学习整体数据,输出独立架构的尺寸以及相对对象位置[15]。显著特征识别模拟图如图7所示。

图7 显著特征识别模拟图
最后利用权重函数计算三个特征值的平衡点,权重公式如式(9)所示:
(9)
其中,X′表示通道注意力权重,⊗表示矩阵乘法,⊕表示广播加法,其他未知数意义同上。
将细节特征、位置特征、显著特征在虚拟场景的所有通道中进行并行匹配运算,通道的注意力权重趋近于1,则此点位构件的最佳重构位置,完整虚拟场景单独构件的位置匹配。
2.4 多视图三维立体视觉重建模型生成
虚拟场景多视图三维重建模型利用惩罚函数优化场景内的各个构件,输出搭建的整体,惩罚检验函数如式(1)所示:
(10)
其中,D表示惩罚函数,g表示二元交叉熵,τ表示惩罚权重。
惩罚函数是在全局的角度上,对三维空间整体的布局利用惩罚函数进行融合,优化构件之间细节的衔接,保证重建模型的连续性和完整性。
3 实验分析
3.1 实验背景及过程
本文选择对照试验检验本文研究的基于ASIS网络的虚拟场景多视图三维重建模型的准确度和完整度,实验面向的对象是一个复杂的虚拟环境图像,应用的方法为目前主流的Colmap重建方法、MVSNet重建方法以及本文设计的重建模型方法,对比每种重建模型输出的效果,检验基于ASIS网络的虚拟场景多视图三维重建模型构建方法的可行性。
在实验中分别选择三种相同配置的电脑用于软件支持,并提前将重建虚拟环境的图纸存入电脑中,两组试验依次进行,以满足实验要求。设置选取了合成图像数据集ShapeNet的子集,并将数据集划分为4/5的训练集与1/5的测试集。网络以尺寸为224×224的图像作为输入并输出323分辨率的三维空间网格,体素化阈值t设置为0.3。选用Adam优化器进行梯度运算,将其初始学习率设置为0.001,衰减率设置为0.5。
3.2 实验数据分析
试验结束后,读取试验数据,三种应用方法分别输出的多视图三维重建模型图像如图8所示:

图8 重建模型效果对比图
三种方法都可以实现虚拟场景的搭建,细致观察传统方法2构建的模型图质量差,还原基本的场景后,会存在不明曲线。传统方法1和本文设计方法的区别直观不明显,因此通过提取计算机数据,完整性误差、准确性误差、重建整体度的误差数据汇总图如图9所示。
图9展示了相同虚拟环境图像在不同方法中构建模型应用输出结果的完整性、准确性误差、重建整体度的评价数据。因为本文采用代价体正则计算原理和回归网络遍历方法,解决虚拟场景多视图模型构建中产生的漏洞,明确虚拟场景空间构造的边界线,降低完整性误差和准确性误差,提高模型重建的高还原度。

图9 误差数据汇总图
根据图9可以得知,传统方法1的平均完整性误差为0.449,平均准确性误差为0.481,平均重建整体度为0.439。传统方法2的平均完整性误差为0.455,平均准确性误差为0.412,平均重建整体度为0.418。本文研究方法的平均完整性误差为0.382,平均准确性误差为0.393,平均重建整体度为0.410。从上述数据可以看出,与两种传统方法中性能较优的方法相比,本文方法的完整性误差降低16%,准确性误差降低4%,重建整体度提高2%。因此,说明本文方法的优化效果较为明显。
另外汇总三种方法构建时间,测试结果图如图10所示。

图10 模型构建进度结果图
观察图10,可以清晰的看出本文设计的重建模型方法用时最短,三种模型构建方法整体进度差别主要显示在场景重现阶段,对于数据采集和数据输出所耗用时间的长短差距不大,稳定在1~2 min之间,但是场景重构阶段的时长对于Colmap重建方法的差距较小,与MVSNet重建方法的差距较大,提前10 min完成重建。结合方法模拟重建的精度测试结果,基于AISI网络虚拟场景多视图三维重建模型的工作效率高,比传统方法提高50%,具有可应用性。
综上所述,本文设计的基于AISI网络虚拟场景多视图三维重建模型方法的精准度和工作效率比传统方法的效果更优,具有良好的精准性和可适配性。
4 结束语
针对数据网络计算方法准确性低的问题,本文研究了一种基于AISI网络虚拟场景多视图三维重建模型研究方法,得出以下结论:
1)利用ASIS网络框架、数据降噪处理、惩罚函数增强虚拟场景多视图三维重建模型还原的精准性,达到更高的虚拟场景的重建效果。
2)通过多视图并行匹配方法,增加重建模型的自适应性功能,提高模型应用的效果和价值。
在接下来的研究中可以侧重建模型数据安全的加密处理,进一步加强模型的自适应性,提高虚拟场景模型的匹配度。
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
今日中国·法文版(2020年7期)2020-07-04
软件(2020年3期)2020-04-20
中国特种设备安全(2019年1期)2019-03-13
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
光学精密工程(2016年6期)2016-11-07
腹腔镜外科杂志(2016年12期)2016-06-01
