
基于YOLOv3不同场景辣椒采摘机器人识别定位研究
2024-01-11 07:54刘思幸陈福康董佩璇
农机化研究 2024年2期
刘思幸,李 爽,缪 宏,柴 岩,陈福康,王 健,董佩璇
(1.扬州大学 机械工程学院,江苏 扬州 225127;2.扬州市蒋王都市农业观光园有限公司,江苏 扬州 225127;3.江苏亿科农业装备有限公司,江苏 扬州 225231)
0 引言
识别不同形状、尺寸和位姿的辣椒对人类而言十分简单,对机器人来说却是十分困难[1]。何屿彤、李斌等[2]采用改进YOLOv3的方法对猪脸进行识别,平均精度均值比原模型高9.87%。毕松[3]等基于深度卷积神经网络设计了对光照变化、亮度不均、前背景相似等自然环境下典型干扰因素具有良好鲁棒性的柑橘视觉识别模型,识别平均精度均值达86.6%。李善军[4]等针对柑橘表面检测费时费力的问题,提出一种改进SSD深度学习模型,可同时对多个柑橘进行实时分类检测。吴露露、马旭[5]等根据病斑的形态特点提出一种基于边缘检测与改进Hough变换的病斑目标检测方法,检测圆拟合精度达87.01%,圆心定位误差为4.44%。陈海燕[6]等针对自然环境下鼠兔毛色与背景颜色相似的问题,构建一种局部纹理差异性算子LTDC来表征目标和背景之间的细微差异,能实现高原鼠兔目标的准确定位。薛月菊[7]等针对猪舍昼夜交替光线变化、热灯光照影响及仔猪与母猪粘连等问题,提出基于改进Faster-R-CNN的哺乳母猪姿态识别算法,平均精度均值达93.25%。此外,还有众多学者对不同大小、颜色和形状的果实[8-10]以及不同姿态、距离的动物[11-13]进行目标检测实验并获得了良好效果。
本文采用YOLOv3模型对辣椒进行精准检测,并对不同补光位置、枝叶遮挡和果实重叠场景做识别实验[14-16]。为了准确获取辣椒的空间三维坐标,构建基于YOLOv3和realsense深度相机的识别定位系统,旨在为采摘机器人对不同作业场景的理解以及控制模型建立提供理论参考。
1 新技术论述
1.1 样本数据采集
样本取自扬州大学机械工程学院现代农业装备实验室,使用S-YUE晟悦相机采集正向光、顶光、背光和侧光4种不同位置,以及果实重叠和枝叶遮挡的辣椒图像,共2000张。数据集按7:2:1比例配置,即训练集1400张、测试集400张、验证集200张。对数据集进行翻转、增亮、变暗、加入椒盐噪声等操作,以增加模型鲁棒性和泛化性。利用labelimg工具对数据进行标注,类型为PascalVOC,标注类别为pepper。
1.2 YOLOv3网络模型
YOLOv3网络框架如图1所示。其主干网络修改为Darknet-53,内部包含5个残差块,并采用跳跃式连接,缓解了神经网络中因深度增加带来的梯度消失问题[17]。与传统卷积网络不同,YOLOv3利用步幅为2的卷积层代替池化层进行下采样,有效避免了低层级特征的损失。每一次卷积后分别进行Batch Normalization正则化与Leaky ReLU操作。

图1 YOLOv3网络结构图Fig.1 YOLOv3 network structure
网络输出结果分为(13,13,75),(26,26,75)和(52,52,75)等3种感受野。维度75可拆分为3×(20+1+4),3代表先验框个数,20代表预测目标类别数,1代表先验框是否包含目标的置信度,4代表先验框的4个微调参数bx、by、tx、ty。其数学表达式为
(1)
其中,tx、ty、Pw、Ph为网络的输出结果,bx、by分别为先验框中心的横纵坐标点;bw、bh为先验框的宽和高;Cx、Cy为先验框中心点相对图像原点的偏移量。图2为先验框和预测框示意图。

1.先验框 2.预测框图2 预测框回归示意图Fig.2 Schematic diagram of prediction box regression
1.3 目标三维定位方法
辣椒三维坐标中的深度Z通过realsense相机的SDK函数获得。利用MatLab对相机的内外参作标定,从而建立像素坐标系到相机坐标系的映射模型,标定的平均误差仅0.08,满足精度需求。标定结果如图3和图4所示。
The study outcome was to evaluate the compliance of the Hospital personnel with a FIT-based screening program by measuring the personnel participation rates.
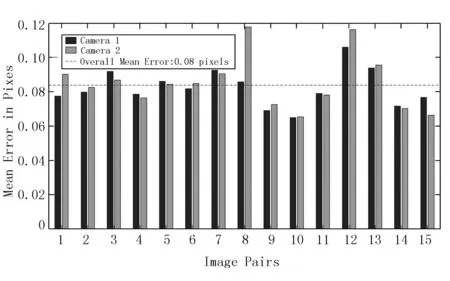
图3 标定误差直方图Fig.3 Calibration error histogram

图4 相机标定结果Fig.4 Calibration results of camera
假设相机坐标系中辣椒的空间位置Pc为(Xc,Yc,Zc),则像素坐标系与之映射关系为
(2)
2 应用的方式方法
2.1 实验设计
采摘经常在傍晚、夜间或环境较暗的情况下进行,故一般搭载补光系统。为了研究光照角度、枝叶遮挡和果实重叠对识别效果的影响,基于YOLOv3算法对正向光、侧光、背光和顶光4种光照情况以及果实重叠和枝叶遮挡场景进行识别实验。
1)算法环境搭建:实验采用的操作系统是Ubuntu20.04.2,CPU为酷睿i7,内存16G。GPU为NVIDIA GEFORCE RTX3070显存,cuda版本10.0.1,cudnn版本10.0.1,深度学习框架为pytorch1.2.0。
2)实验平台搭建:将辣椒植株按株距330mm、垄距600mm和行距300mm布置于实验室土槽中,参数如表1所示[18]。模拟枝叶遮挡和果实重叠将辣椒模型粘贴在植株的坐果位置。光源分别按正向光、顶光、背光和侧光位置摆设。其中,顶光光源在植株正上方1m处;侧光的光源在植株左侧或右侧斜45°1m处;背光的光源在植株正后方偏上45°处,距离1m;正向光在辣椒正面1m处。实验过程如图5所示。

表1 实验环境与田间参数Table 1 Experimental environment and field parameters

图5 辣椒采摘不同场景识别实验流程图Fig.5 Flow chart of different scene identification experiment for picking pepper
枝叶遮挡分为轻度遮挡、中度遮挡和重度遮挡。轻度遮挡即枝叶与果实遮挡面积为0~30%,中度遮挡即枝叶与果实之间的遮挡面积为30%~50%,重度遮挡即枝叶与果实之间的遮挡面积大于50%。
果实重叠分为轻微重叠、中度重叠和重度重叠。轻微重叠即果实与果实之间的重叠面积为0~30%,中度遮挡即果实与果实之间的遮挡面积为30%~50%,重度遮挡即果实与果实之间的遮挡面积大于50%。
2.2 性能评估指标
采用精确率(P)、召回率(R)以及平均精度均值(mAP)作为模型的评价指标。精确率用来评价识别的精确性,精确率越高模型的错检率越低;召回率用来评价识别的全面性,召回率越高模型的漏检率越低。平均精度均值是指平均精度值(AP)在所有类别下的均值。评价指标的计算公式为
(3)
(4)
(5)
(6)
式中TP-预测正确的正例;
FP-预测错误的正例;
FN-预测错误的反例;
TN-预测正确的反例;
C-目标类别数。
3 获得的效果和突破
3.1 不同光照场景识别效果
图6所示为模型训练结果。由图6可知:召回率Recall在迭代300次时达0.98,平均精度均值mAP达0.95,精确率达0.854,满足辣椒采摘识别精度需求。

图6 模型训练结果Fig.6 Training results of the mode
表2为不同光照场景识别结果对比。由表2可知:识别成功率由高到低依次为正向光、顶光、侧光和背光,分别为92%、88%、84%和78%。
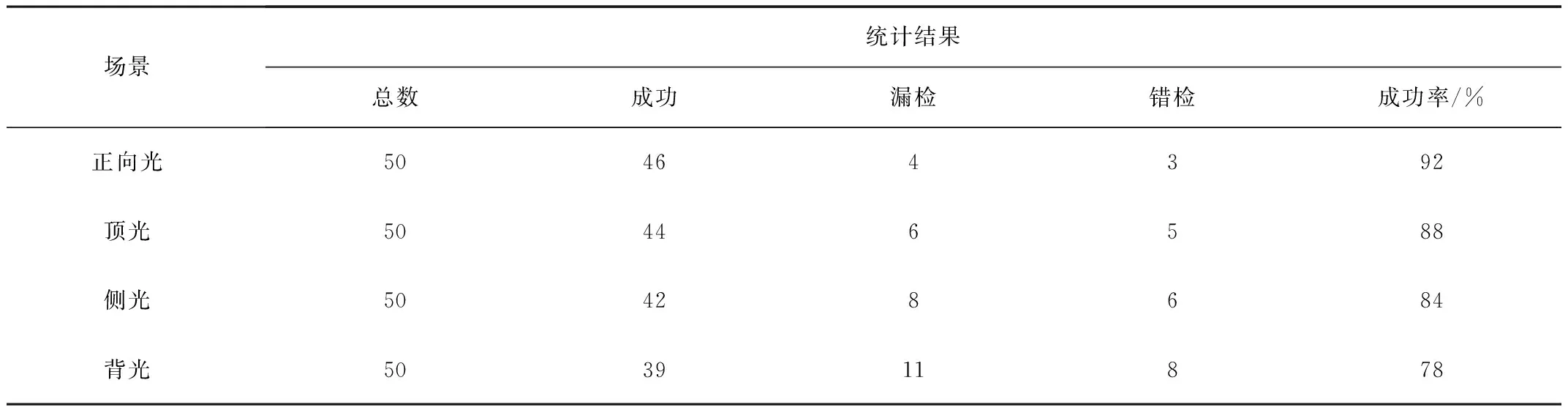
表2 不同光照场景识别结果对比Table 2 Comparison of recognition results under different lighting conditions
图7为不同光照场景识别效果。由图7可知:不同补光位置下,辣椒的果实、叶子颜色变化明显,阴影交错复杂;在正向光场景下,辣椒叶子和果实颜色基本不变;侧光场景下,辣椒颜色泛白,特征信息丢失较多,严重影响果实识别精度;顶光场景下,辣椒颜色和形状特征丢失较少,但光线稍显暗淡。由于光照集中在顶部叶片,使得前景和背景区别明显,有利于辣椒的精准识别。背光场景下,光线多从枝叶和辣椒之间穿透,模型输入大量噪声信息,且背光场景下叶片颜色更显暗淡,背景信息更复杂,导致辣椒的特征更难提取。

图7 不同光照场景识别结果Fig.7 Recognition results of different lighting scenes
3.2 果实重叠和枝叶遮挡识别效果
枝叶遮挡和果实重叠识别结果对比如表3所示。由表3可以看出:轻度遮挡和轻度重叠场景下,辣椒识别成功率达96%,满足采摘识别精度需求;枝叶遮挡错检率高于果实重叠,漏检率低于果实重叠,识别成功率总体高于果实重叠。这是因为做标签遇到枝叶遮挡时,难免将枝叶部分框进ground truth中,导致模型在训练时错误地将带有枝叶的辣椒作为预测对象;而果实重叠场景识别成功率低是因为YOLO模型识别小目标和密集物体性能差。
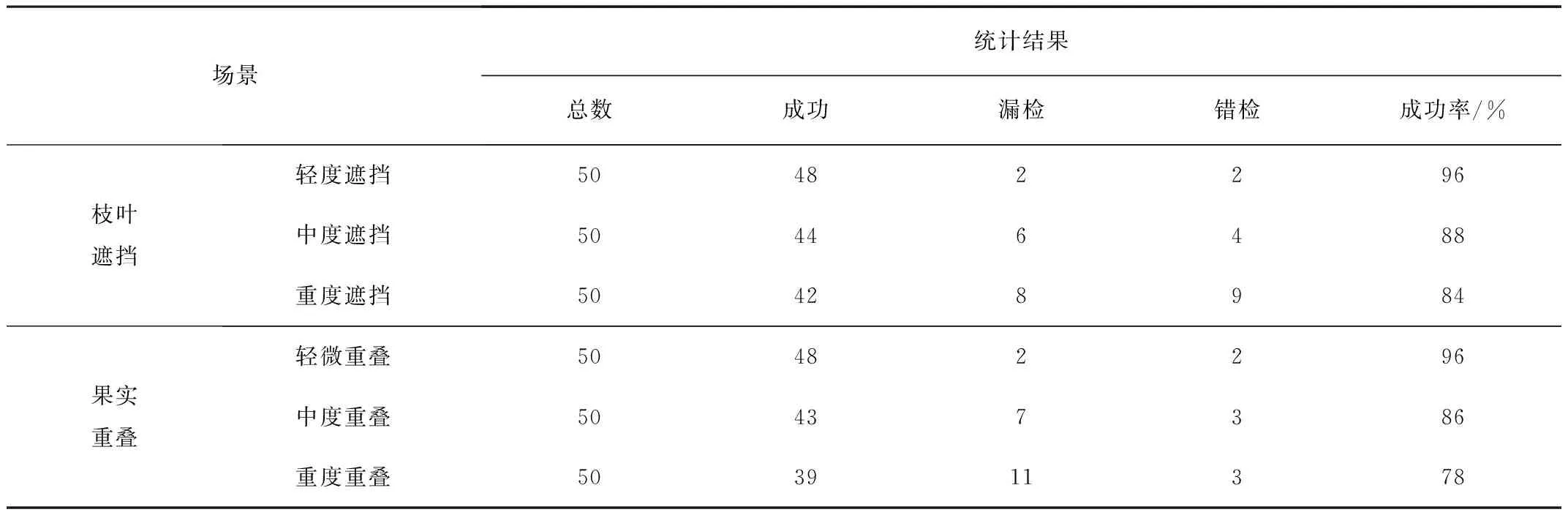
表3 枝叶遮挡和果实重叠识别结果对比Table 3 Comparison of recognition results of branch and leaf occlusion and fruit overlap
不同遮挡程度识别结果如图8所示,不同重叠程度识别结果如图9所示。中度遮挡和中度重叠时,模型错检数无明显提升,两者识别成功率分别为88%和86%。由图8、图9和表3可知:重度遮挡和重度重叠时,两者漏检数明显增多,枝叶遮挡的错检率明显高于果实重叠。

图8 不同遮挡程度识别结果Fig.8 Comparison of recognition results of branch and leaf occlusion

图9 不同重叠程度识别结果Fig.9 Comparison of recognition results of fruit overlap
3.3 三维定位实验结果
辣椒在相机坐标系下的真实坐标为(X,Y,Z),利用模型测得的坐标为(X0,Y0,Z0),定位系统的测量误差为ΔX、ΔY、ΔZ,则综合定位误差ΔE为
(7)
表4为辣椒三维坐标识别结果。实验表明:基于YOLOv3和realsense深度相机的识别定位系统可实现辣椒的三维坐标定位,综合定位误差最大只有0.024m,满足采摘精度需求。
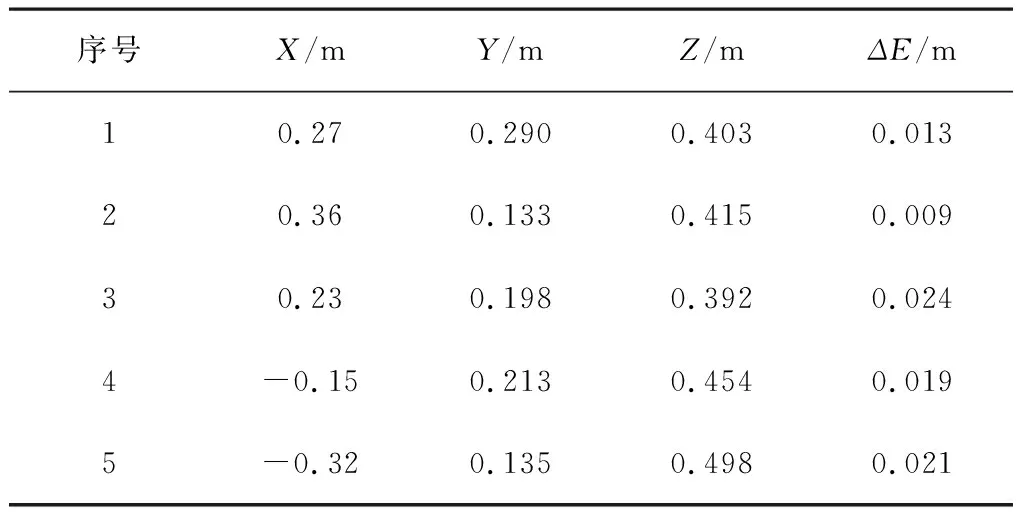
表4 辣椒中心点三维坐标计算结果Table 4 Results of 3D coordinate of pepper center points
4 结论
1)基于YOLOv3网络模型搭建了辣椒识别系统,包含软件环境和硬件平台。实验表明:召回率达0.98,平均精度均值达0.95,精确率达0.854,满足辣椒采摘识别精度需求。
2)基于4种不同光照场景对YOLOv3模型识别效果做了对比,成功率由高到低依次为正向光、顶光、侧光和背光。其中,正向光的识别成功率达92%,分别高于顶光、侧光和背光4、8、14个百分点。
3)基于不同枝叶遮挡和果实重叠程度对模型识别效果做了对比实验,结果表明:轻微遮挡或重叠时(遮挡或重叠面积小于30%),模型识别成功率几乎不变,保持在96%左右;中度遮挡或重叠时(遮挡或重叠面积在30%~50%之间),模型的漏检率有所上升,整体识别成功率达86%左右;重度遮挡或重叠时(遮挡或重叠面积大于50%),辣椒难以被识别,错检率和漏检率皆明显上升。
4)基于YOLOv3模型和realsense深度相机的识别定位系统可实现辣椒的三维坐标定位,综合定位误差最大仅0.024m,满足采摘机器人的精度需求。
猜你喜欢
中国机械工程(2022年8期)2022-05-09
中国机械工程(2021年8期)2021-05-07
当代陕西(2020年17期)2020-10-28
电子制作(2019年12期)2019-07-16
音乐教育与创作(2019年8期)2019-05-16
电子测试(2018年6期)2018-05-09
中成药(2018年3期)2018-05-07
电子测试(2017年11期)2017-12-15
中成药(2017年7期)2017-11-22
传奇故事(破茧成蝶)(2015年1期)2015-02-28
