
融合Kinect和IMU多模态数据的多阶段运动去噪网络
2024-02-28 08:18郭奇涵谢文军程景铭刘晓平
小型微型计算机系统 2024年1期
郭奇涵,谢文军,王 冬,程景铭,刘晓平
1(合肥工业大学 计算机与信息学院,合肥 230601)
2(安全关键工业测控技术教育部工程研究中心,合肥 230601)
3(合肥工业大学 软件学院,合肥 230601)
0 引 言
动作捕捉是指使用传感器实时记录物体在运动过程中关键点的位置.动作捕捉技术在虚拟现实、增强现实、电影特效、游戏、体育训练和康复医疗等领域中有着广泛的应用.在工业应用中,光学式和惯性导航式动作捕捉系统最为常见.这些系统往往要求模特穿着特定的动捕服装或佩戴传感器,能够精确捕捉到人体关节点的位置移动,但价格昂贵,且需要较大的空间.在日常应用中,普通消费者和研究人员通常使用低成本高噪声的运动采集设备,如Kinect和惯性测量单元IMU(Inertial Measurement Unit).Kinect设备是微软公司推出的一种低成本动作捕捉设备,能够实时采集人物的25个关节点位置,其精度可以满足一些体感控制和体感游戏的要求,但是容易受到遮挡和环境问题的影响.IMU传感器广泛使用在智能手机、手表、手环和眼镜等设备中.惯性测量单元与光学式传感器不同,数据的精度不会受到环境和遮挡问题的影响,但是数据较为稀疏.可以看出,Kinect和IMU本身均存在精度和适应场景的缺陷,但能够形成互补:前者弥补后者数据稀疏性的缺点,后者能够弥补前者易受到环境和遮挡产生高噪声的缺点.
针对低成本动作捕捉中存在的高噪声问题,基于深度学习的去噪算法是一种有效的手段.本文从多模态数据的角度出发,根据Kinect和IMU之间的互补性,提出一种结合了Kinect和IMU数据的多阶段去噪网络MMCapNet(Multi-modal Multi-stage Capture Network),在提高输出结果精确度的同时,也增强了算法的鲁棒性,使得网络不再严格依赖于某一模态数据,即使Kinect数据出现大量噪声,本网络仍能正确恢复人体运动序列.
本文的主要工作分为以下3个方面:
1)提出了一种基于多模态运动数据融合去噪方法.使用特征提取器将Kinect和IMU数据提取为运动特征,利用运动特征估计关节点位置,通过两种模态的互补关系,提高输出结果的精确度和方法的鲁棒性.
2)提出了一种针对Kinect和IMU模态数据的多阶段预测网络结构.根据关节点的类型不同,将全身关节位置估计任务拆分为3个子任务,逐步估计,最后将3部分的估计结果组合为完整的人体姿态,提高了整体的预测精度.
3)建立了同步采集的Kinect、IMU和动捕设备的多模态噪声数据集.在已有2180332帧日常运动多模态数据集的基础上,设计采集了227160帧包含高噪声的多模态人体运动数据集,用于提高去噪算法的泛化能力并测试其鲁棒性.
1 相关工作与简介
运动数据去噪(Motion Denoising)或运动数据重建(Motion Recovery)在动作捕捉技术的应用中在扮演者重要的角色.目前,在运动数据去噪领域中,深度学习的方法得到了广大学者的使用.例如,Holden等[1]在CMU数据[2]中添加噪声,然后利用位置约束反向传播,更新网络中的参数,经过训练后得到一个具有去噪能力的神经网络.后来,Holden等[3]又使用全连接残差网络实现了对光学动作捕捉数据集CMU数据集的去噪.Holden等[4]提出基于CNN(Convolution Neural Network)卷积神经网络的角色运动合成方法,通过先把噪声运动数据映射到数据流形(motion manifold)上,然后再将其重映射到原有的数据空间中,达到去除运动数据中噪声的目的,该方法对于不同类型噪声的处理结果差异较大.Aksan等[5]提出基于Transformer结构的STTrans方法,通过双注意力机制,显示地使用时序和结构信息补全运动序列.针对具体的使用场景,不同应用往往会采用不同模态的运动数据.因此针对不同模态的运动数据,也有着各自的去噪方法和相关研究.
基于RGB-D相机的Kinect设备是一种低成本高噪声运动数据采集设备,能够实时提供节点的坐标信息.基于Kinect模态的去噪方法包括:Moon等[6]将多个不同位置的Kinect设备提取的骨骼数据进行融合,并使用卡尔曼滤波(Kalman filter) 提高估计精度.Tripathy等[7]针对Kinect数据中存在的骨骼长度变换问题提出一种约束粒子滤波器(Constrained Particle Filter),减少骨骼长度的变化. Li等[8]提出了可直接对真实设备采集结果使用的双向循环网络BRA(Bidirectional Recurrent Autoencoder),提高了对于含有真实噪声数据的处理能力.Li等[9]在BRA网络的基础上添加了感知约束,能够在保证输出结果位置精度的同时,丰富运动的细节表现.Bilesan[10]等通过添加IR标记(infrared marker),利用Kinect的深度相机定位标记位置,通过标记位置修正骨骼输出.与Kinect设备类似的基于视觉的方法都会受到环境和遮挡问题的影响[11],这使得基于视觉的方法往往适合在光照稳定的室内简单场景下.通过使用多个Kinect设备、额外的传感器和对于运动的先验知识可以提高数据的精度.
IMU是一种常见的便携式传感器,包含3个轴加速度传感器及3个轴陀螺仪组,可测量加速度和姿态角.IMU数据具有稀疏性和高噪声的特点,不会受到光照和遮挡问题的影响.Marcard等[12]提出SIP网络,能够在只使用6个IMU设备的情况下,通过优化SMPL人物模型[13]参数以符合IMU数据测得的关节角度和加速度信息来完整重建出整个运动序列,该方法只能处理完整的长序列.Huang等[14]提出一种基于双向长短时记忆单元的人体姿态重建方法DIP.该方法也只使用6个IMU设备便可以重建人体运动序列,与SIP[12]不同的是,DIP通过双向长短时记忆单元对运动序列中的时序信息加以利用,实现了实时重建运动序列并驱动SMPL模型.但DIP方法的重建结果仍存在全局位移累计误差不断增大的问题.Liu等[15]和Henschel等[16]通过引入额外的超声波传感器或RGB视频来解决全局位移的估计问题.Yi等[17]在不增加输入的情况下,利用支持足模型和根节点加速度模型,提出了高实时性、高精确度的具有全局位移的人体姿态实时估计方法TransPose.不同于基于视觉的方法,这些方法不会受到遮挡和环境问题的影响,但是由于IMU数据较为稀疏,难以适用于精细人体模型,如本文所使用的72节点动捕人物模型.
本文根据不同模态数据间的互补关系,提出融合Kinect和IMU数据的去噪网络MMCapNet,旨在解决低成本动作数据中存在的问题.本网络可以在Kinect和IMU数据都完整的情况下提高输出结果的精度,也可以通过IMU数据的补充来解决Kinect数据在受到干扰后输出结果精度降低的问题.
2 多模态多阶段去噪方法
2.1 日常运动多模态数据集
鉴于当前缺乏同时包含Kinect数据、IMU数据和高精度动作捕捉数据(Mocap数据)的数据集,尤其是针对高噪声情况专用数据集,团队设计并自采了多模态数据集MMD.该数据集中包含了3个部分,分别是Kinect数据、IMU数据和Mocap动作捕捉数据.Kinect数据包含了人体25个关节点的位置,记作K=[P0,P1,…,P24]∈R75,其中Pi表示i号节点的坐标位置,即三维空间下x,y, z坐标,Pi∈R3.IMU数据包含了5个节点的加速度和姿态角,记作I∈R30.Mocap动作捕捉包含了人体72个关节点(手部节点48个、身体节点24个)的位置,记作M∈R216.节点模型如图1所示.

图1 人体骨架模型示意图Fig.1 Human skeleton model
该数据集由多名模特在室内场景下采集,活动空间约为4m×4m×2m.对于Kinect和Mocap数据,进行空间同步,将其变换到同一坐标系下.参考文献[14],将多个IMU设备进行坐标统一.该数据集中包含有广播体操621208帧、八段锦583859帧、体育运动272335帧和日常运动702930帧,共计2180332帧.
在网络开始训练之前,需要进行数据预处理.预处理共包括两个部分,分别为切片和标准化(normalization).切片是指将一段长运动序列使用长度为w的滑动窗口进行切分,将其划分为多个短运动序列(clip),便于后续的mini-batch梯度下降.相邻短运动序列间,前一个短运动序列的后s帧与后一个短运动序列的s帧相同(s为滑动窗口的滑动步长).经过切片处理,可以得到n个短运动序列,将每个短运动序列记作clipi,clipi=[K,I,M]∈Rw×(75+30+216).通过计算得到数据在每个维度上的均值mean∈R321和方差std∈R321,通过公式nclip=(clip-mean)/std对每个短运动序列进行标准化处理后得到标准化数据集S=[nclip0,nclip1,…,nclipn-1].通过对数据集进行标准化处理,提高网络在训练过程中的收敛速度.为了提高网络泛化性和避免过拟合,参考Moon等[18]指出的人体姿态估计网络的常见错误类型,对预处理后的训练数据进行了数据增强.最后,使用增强后的数据集S′作为训练数据集.
2.2 高噪声多模态数据集
在2.1节日常运动多模态数据集中,Kinect数据和IMU数据作为网络输入数据,而高精度动作捕捉Mocap数据作为真值,用于计算损失,以指导网络学习.该数据集是面向日常使用场景的环境下录制的,因此数据集中的Kinect数据和IMU数据中包含的噪声较小.为了提高和测试去噪方法的鲁棒性,即当Kinect模态存在大量噪声时,本文方法能够保证输出运动序列中每个骨骼关节点的位置精度,除了日常运动数据集,还需要高水平噪声的数据集.因此,遵循日常运动数据集的录制要求和规范,本文专门采集了高噪声数据集HMMD,其噪声样例如图2所示.

图2 高噪声数据集样例Fig.2 Samples of high-noise data
该噪声数据集的采集设备和参数均与日常运动数据集MMD相同.为了采集到高噪声的Kinect数据,本数据集在录制过程中,不再限制模特在Kinect相机的有效采集范围内运动,而是故意在有效范围的边缘或者外部运动,以采集到具有较大噪声的Kinect数据.另外,本数据集也专门采集了由自遮挡等原因导致的高噪声Kinect数据,如图2所示,第1行为Kinect设备采集结果,第2行为高精度动作捕捉设备采集结果.高噪声数据集共有227160帧.
2.3 网络结构
本文根据IMU设备的佩戴位置和人体骨骼节点的位置关系,将人体72骨骼节点分划分为3类,分别为5个关键节点(core)、19个身体(body)节点和48个手部(hand)节点,分别对应图1(b)中 Mocap人物模型的正方形节点、大圆节点和小圆节点.关键节点是指佩戴了IMU设备的节点,这些节点的运动信息最为完整,在两种模态的数据中都有直接对应的数据.手部节点是指手掌和手指的全部节点,这部分节点数量最多,在空间位置比较集中.其他节点统称为身体节点,代表人体躯干上的关节点.
整体网络结构如图3所示,网络整体由两个特征提取器(FE1、FE2)和3个关节位置估计器(JE1、JE2、JE3)组成.网络输入为Kinect和IMU两个模态的运动数据Xkinect和XIMU,分别标准化并经过特征提取器FE1、FE2后得到运动特征Fkinect∈R512和FIMU∈R5122,将两个运动特征向量拼接(concat)后得到完整的特征向量,然后经过3个关节位置估计器JE1、JE2和JE3,分别估计得到关键节点、身体节点和手部节点的坐标位置Pcore∈R15、Pbody∈R57和Phand∈R144,最后将3部分节点坐标组合为完整的人体姿态.其中JE1的输入向量为X(1)=[Fkinect,FIMU],输出向量为Pcore,JE2的输入向量为X(2)=[Fkinect,FIMU,Fcore],输出向量为Pbody,JE3的输入向量为X(3)=[Fkinect,FIMU,Fcore,Fbody],输出向量为Phand.这里特征提取器将运动特征向量Fkinect和FIMU作为其输入一部分,并非原始数据Xkinect和XIMU,详细解释见2.4节.特征提取器和关节位置估计器的结构相同,均为全连接层、两个Bi-LSTM和全连接层串联得到.
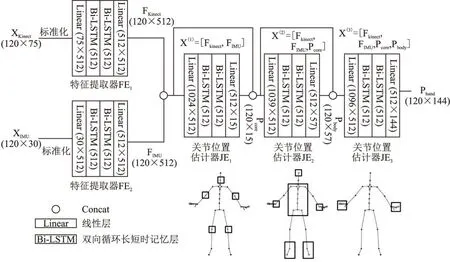
图3 网络结构示意图Fig.3 MMCapNet atchitecture
2.4 损失函数
训练过程中所使用的加权关节位置损失Loss由3个部分的线性组合构成,分别是关键节点误差Losscore,身体节点误差Lossbody和手部节点误差Losshand,其函数表达式为:
Loss=α1Losscore+α2Lossbody+α3Losshand
(1)
(2)
(3)
(4)
3 相关实验
3.1 实验设计
为验证MMCapNet网络的有效性和合理性,共设计了4个实验,分别是多模态消融实验,多阶段消融实验、跨层连接消融实验和对比实验.实验平台处理器为4核Intel(R) Xeon(R) Silver 4114 CPU @ 2.20GHz,显卡为Tesla P100 16G.本文使用Tensorflow 1.4,Adam优化器[19],Batch Size为64.参考文献[8],学习率设为0.0001,所有的Bi-LSTM层都设置dropout为0.2.
3.2 多模态消融实验
多模态消融实验的目的是验证IMU模态数据的引入对输出结果位置精确度的作用.实验使用与图3中结构相同的关节位置估计器作为基础网络结构,数据集为数据增强后的日常运动数据集S′,共2398365帧,随机选取日常运动数据集中的85%作为训练数据,余下15%作为测试数据.如表1所示,实验包含5个部分,各部分有着不同的输入数据,相同的网络结构和真值(ground-truth),输入数据分别为:1)输入数据只有Kinect数据Xkinect∈R75;2)输入数据只有IMU数据XIMU∈R30;3)输入数据包含完整Kinect数据Xkinect∈R75和下肢IMU数据XIMU下肢∈R12;4)输入数据包含完整Kinect数据Xkinect∈R75和上肢IMU数据XIMU上肢∈R12;5)输入数据包含完整的Kinect数据Xkinect∈R75和IMU数据XIMU∈R30.
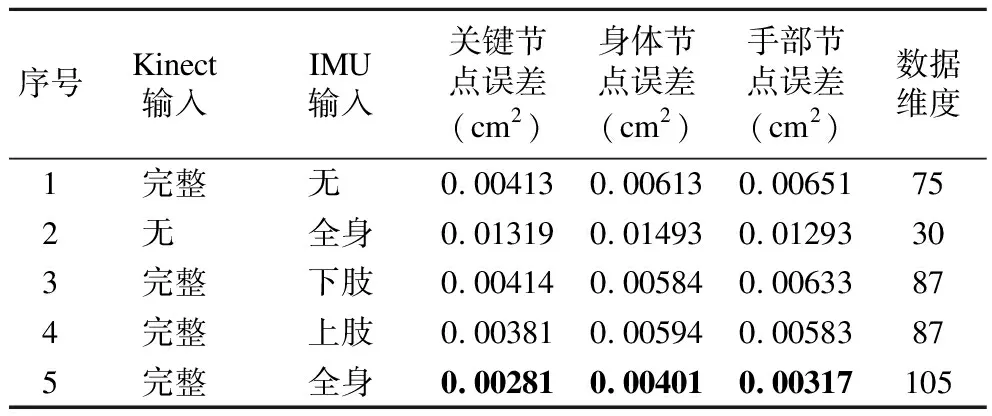
表1 多模态消融实验结果Table 1 Multi-modal ablation experiment results
实验结果如表1所示.对比Kinect和IMU作为输入数据的结果,Kinect作为输入时的关节误差更低,表明相比于稀疏的IMU数据, Kinect数据能够得到更加精确的输出结果.在Kinect数据输入完整的条件下,对比不同数量IMU输入的结果可以看出,IMU数据的增加能够降低3类节点的估计误差.当输入数据为完整的Kinect和IMU数据时,即输入数据维度最大时,各类节点的估计误差均为最低.
综上,实验结果表明多模态的输入有助于优化数据去噪的结果.这是因为不同模态间的数据所包含的信息不同,能够相互补充,网络通过结合不同模态信息能够对关节位置做出更加精确的预测.
3.3 多阶段消融实验
多阶段消融实验的目的是验证多阶段预测对于提高输出结果精确度的作用.上述工作[8,14]中都提出了端到端的关节点位置估计方法.这些方法都没有对不同类型的节点进行区分.Yi等[17]指出,在估计关节点位置坐标的任务中,根据节点的类型分阶段估计,对估计精度有着明显的提升,受其启发,本文将人体节点按照2.3中的描述,将节点划分为3种类型,在以下实验中,依次按照关键节点、身体节点和手部节点的顺序预测坐标位置.单阶段预测使用一个关节位置估计器,多阶段预测使用串联的3个关节位置估计器.实验数据集与3.2节相同.本实验共包含4个部分:1)输入数据为Kinect数据,单阶段预测全身节点位置,如图4(a)所示;2)输入数据为Kinect数据,多阶段预测3部分节点位置,如图4(b)所示;3)输入数据为Kinect和IMU数据,单阶段预测全身节点位置,如图4(c)所示;4)输入数据为Kinect和IMU数据,多阶段预测3部分节点位置,如图4(d)所示.

图4 多阶段消融实验网络结构图Fig.4 Multi-stage ablation experiment network architecture
如表2所示.当Kinect作为输入数据时,多阶段预测的输出结果都具有更低的位置误差,关键节点误差、身体节点误差和手部节点误差分别降低47.8%、19.2%和2.2%.当Kinect结合IMU作为输入数据时,多阶段预测的输出结果与Kinect作为输入数据有着类似的结果,多阶段输出结果的位置误差比单阶段预测结果的低,3类节点误差分别降低53.8%、27.4%和9.2%.

表2 多阶段消融实验结果Table 2 Multi-stage ablation experiment results
实验结果表明无论是单一模态输入,还是多模态输入,通过显式的利用骨骼节点的层次关系,都能够提高关节点位置的估计精度.在输入数据中,IMU数据包含四肢的运动信息,Kinect数据主要包含躯干和四肢的运动信息.这两个模态的数据都缺少手部的运动信息的描述,但是去噪网络能够在手部运动信息缺失的情况下通过其他身体部位的运动信息对手部的节点位置做出合理预测.通过引入IMU模态数据,不仅能够增加关键节点和身体节点的估计精度,也能增加手部节点的估计精度.
3.4 跨层连接消融实验
跨层连接消融实验的目的是验证特征提取器的作用.JE2和JE3两个位置估计器的输入可以分为两个部分,运动特征和节点估计结果.根据文献[17],通过将已估计节点作为位置估计器的输入,有助于估计器在全部运动特征中提取当前估计节点有关的特征信息.本实验包含两个部分:1)将原始数据作为运动特征,如图5(a)所示;2)将特征提取器所提取的特征向量作为运动特征,如图5(b)所示.本实验中的特征提取器为RNN.
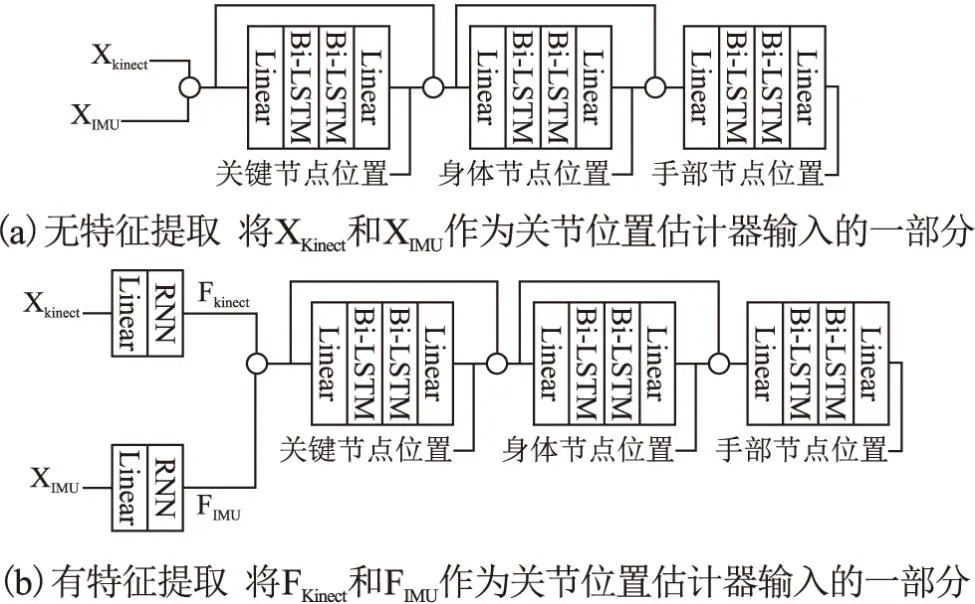
图5 跨层连接消融实验网络结构Fig.5 Cross layer connection ablation experiment network architecture
实验结果如表3所示,对比原始数据和特征向量作为运动特征的结果,当特征向量作为运动特征时,输出结果具有更高的位置精度.

表3 跨层连接消融实验结果Table 3 Cross layer connection ablation experiment results
3.5 对比实验
对比实验的目的是验证不同方法对于高低水平噪声数据处理的鲁棒性.本文从日常运动和高噪声中随机选择85%和50%作为训练数据,其余部分作为两组测试数据.本实验使用2.4节中的3种关节位置误差作为评价指标.本文方法的输入为Kinect数据与IMU数据,其它方法的输入均为Kinect数据.
如表4所示,其中星号(*)上标表示高噪声数据集下的结果.通过对比MMCapNet和CNN、BRA、DIP方法测试结果可以发现MMCapNet的3种关节误差在日常运动和高噪声数据集上均明显比CNN、BRA、DIP的低.MMCapNet在日常运动数据集上的估计误差与STTrans接近,但是在高噪声数据上的估计误差均低于MMCapNet.

表4 对比实验结果(*表示高噪声数据集的测试结果)Table 4 Comparison experiment results
图6为一段120帧连续运动去噪结果中等间隔截取的6帧,间隔为20帧.第1行为Kinect输入,第2行为Ground-Truth,后4行为不同方法的输出结果.图7为不同运动去噪结果中截取的特定帧.在图6第3列中,Kinect输入的左手部分包含较大噪声,除本文方法外,其他方法都没能正确估计左手位置.在图6最后两列中,CNN、BRA、DIP的估计结果的腰部都呈现不同程度的倾斜,其中DIP的最为明显,STTrans的腰部虽然能够正确还原,但是双脚朝向存在明显错误.在图6前两列中,左手数据存在明显缺失和错误,CNN、BRA、DIP都受到Kinect输入数据的影响,很难正确估计左手的坐标位置.但由于IMU数据的补充,本文方法依然能够合理估计左手位置.在图7后两列中,人物处于侧身状态,Kinect设备无法处理,因此Kinect数据中手部和腿部都出现了严重错误,可以明显看出,CNN、BRA和DIP方法都缺乏对于这种侧身自遮挡情况的处理能力,STTrans方法能够恢复躯干的侧身状态,但是没有正确重建右腿的抬起状态.
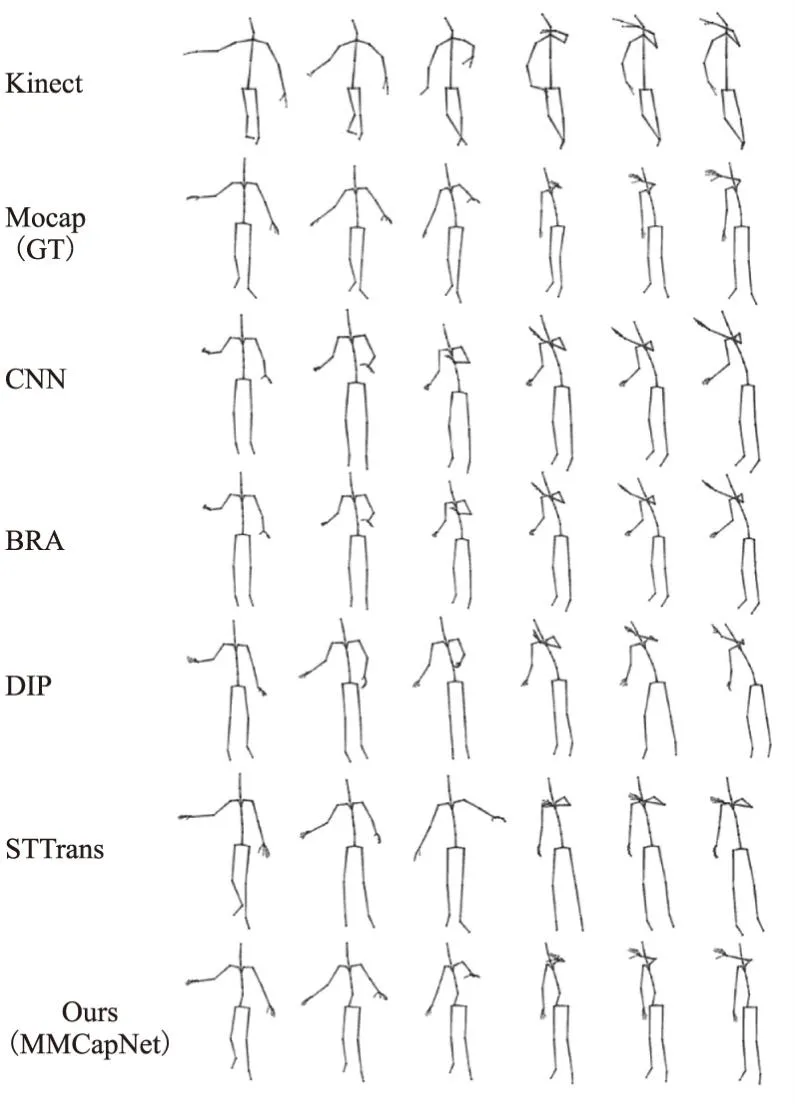
图6 连续帧对比实验结果Fig.6 Comparison experiment results on consecutive frames

图7 非连续帧对比实验结果Fig.7 Comparison experiment results on non-consecutive frames
综上,多模态网络MMCapNet拥有更好的预测精度和鲁棒性.当Kinect数据噪声较大时,特别是挥手(图6后3列)、侧身(图7后两列)等动作引起自遮挡时,本方法能够利用模态间信息的互补关系来正确估计关节位置.在实验过程中,通过440629帧测试数据计算,MMCapNet的计算速度达到2.4毫秒每帧,可以支撑基于Kinect和IMU设备的实时运动数据采集.
4 结 论
本文针对低成本动作捕捉运动数据的去噪问题提出了一种融合Kinect和IMU的多模态多阶段去噪网络MMCapNet.通过融合Kinect和IMU两种具有互补关系的模态数据和用3个位置估计器分别估计关键节点、身体节点和手部节点的多阶段预测结构,既提高了日常运动数据集上的预测精度,也提高了对于高噪声数据的处理能力,解决了Kinect设备无法处理自遮挡情况的问题.针对高噪声多模态运动数据集的缺乏问题,本文采集了包含了227160帧的3种模态的高噪声多模态同步数据集,能够提高和验证去噪算法的精确度和鲁棒性.基于MMCapNet可以支撑通过Kinect和IMU设备实时融合采集高精度的人体运动数据,且通过两类数据互补增强高噪声场景下的采集鲁棒性.
本文主要探讨了Kinect和IMU模态的融合方法.在更多模态的数据支持下,未来的工作将探索Kinect、IMU和视频等其它运动数据形式的融合去噪网络.此外,在多阶段预测中对于节点的分类可以进一步优化,从各节点估计误差的差异和节点的层次关系,对节点进行更细致的划分,充分利用多阶段预测的优势.
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
数学年刊A辑(中文版)(2020年3期)2020-10-27
今日中国·法文版(2020年7期)2020-07-04
中国特种设备安全(2019年1期)2019-03-13
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
山东青年(2016年2期)2016-02-28
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
噪声与振动控制(2015年4期)2015-01-01
计算物理(2014年2期)2014-03-11
