
一种无需手工标注的半监督学习关键词抽取方法
2024-02-28 08:18蔡茂东沈国华黄志球
小型微型计算机系统 2024年1期
蔡茂东,沈国华,3,黄志球,3
1(南京航空航天大学 计算机科学与技术学院,南京 210016)
2(南京航空航天大学 高安全系统的软件开发与验证技术工业和信息化部重点实验室,南京 211106)
3(软件新技术与产业化协同创新中心,南京 210093)
0 引 言
随着科学技术的不断发展,各种知识文献的数量也在爆发式的增长,传统的获取知识的方式也越来越不能满足人们在信息时代的需求.关键词(也称关键短语、关键字)是一组能够代表文章主要内容的词语,根据关键词,人们能够快速概览一篇文章的关键知识.在信息检索(Information Retrieval,IR)[1,2]系统中,使用关键词进行检索,能够快速定位相关主题的文章.然而手动分配关键词是一项耗时费力的任务.由此,自动关键词抽取(Automatic Keywords Extraction,AKE)技术应运而生.AKE还被广泛运用于各种自然语言处理(Natural Language Processing,NLP)任务中,例如摘要生成[3,4]、文本分类[5]、知识图谱构建[6]等.
根据对语料资源的需求程度,我们可以将AKE方法分为无监督方法、监督学习、半监督学习.
无监督的关键词抽取方法,通常分为3步:首先从文本中根据一定的规则,初步筛选出候选词;然后,制定评分公式,给每一个候选词打分,并按照分数高低,给这些词语排序;最后,根据需求,选取得分最高的前K个词语(即TopK)作为关键词.
监督学习将关键词抽取视为一个二分类的任务,即文本中的每一个片段被标记划分为了两类:是关键词和不是关键词.许多分类算法或模型被使用,如支持向量机[7],朴素贝叶斯和决策树[8],深度神经网络[8-10]等.尽管监督学习在关键词抽取任务中可以取得较好的效果,但这类方法都需要大量的带有准确标注的高质量的数据集.在缺少标注数据的低资源领域,监督学习无法高效快速的运作,如果手工标注数据集,则需要耗费大量的人工.
半监督学习的关键词抽取可以被形象地视为少量“种子”的增殖过程.该类方法需要一个少量的带有准确标签的初始数据集,被称为“种子集合”.种子通常需要手工标注,但是需要的数量相比监督学习要少.然后通过自扩展迭代的方式训练各种分类模型,从而不断地抽取出更多的关键词.
无监督方法不需要语料资源用于模型的训练,使用相对方便快捷,但是其结果还不够理想(F1值还有待提升).监督学习方法的效果需要大量高质量的带准确标签的数据集支持.现有半监督学习方法减少了对数据集的需求,但仍然需要手工标注少量数据集,并且其迭代过程的各项细节还有待进一步优化.
本文的主要贡献如下:
1)参照现有的公开数据集Hulth 2003,制作了一个新的数据集CPB 2022,一同用于关键词抽取方法的训练、评估和对照(Computer Science,Physics and Bio-medicine,CPB).
2)提出了一种考虑了词频、词长、和词大小写特征的无监督算法LCF(Length Case and Frequence).
3)提出了一种无需手工标注的,结合了LCF算法、全称/缩写词抽取方法AF(Acronym &Full-name)、自动过滤规则的自扩展迭代半监督学习方法LCF-AF-FBS(Filtered Bootstrapped SciBERT,FBS).
1 相关工作
关键词抽取的相关算法最早可以追溯自1957年Luhn提出的基于词频(Term Frequency,TF)的算法[11],这也是最早的基于统计学特征的无监督算法.词语在文本中出现的频率,可以被认为是关键词的一个基本判据.然而,单纯的考虑词频,可能会导致引入许多广泛存在,但并不关键的日常用词.由此,Salton等人提出了TF-IDF算法[12],该算法在词频的基础上,引入了逆文档频率(Inverse Document Frequency,IDF)的特征,TF-IDF算法旨在找出那些在在当前文本中出现的频率较高,而在总的语料库中出现频率不高的词语.在此基础上,还出现了考虑词性[13]、词长[14-16]、位置[15,16]、词共现[17]等特征的算法.
在无监督算法中,除了基于统计学特征的,还出现了基于图的算法.该类算法将每一个候选关键词视为图上的一个节点,通过制定相应的规则,建立起节点之间的关系,然后根据节点之间的关系,和节点本身的属性,计算出每个节点的得分.TextRank算法[18]是基于图的算法中的一个典型代表,该算法使用词性标签(Part-of-Speech Tag),筛选出名词性短语作为候选短语,然后为每一个候选短语两边设立一定宽度的窗口,在窗口范围内共现的短语将会建立共现关系,然后运行PageRank算法[19]直至收敛.在此基础上,还出现了SingleRank和ExpandRank[20].SingleRank改进了共现度的计算方式,ExpandRank则利用与目标文档相近的文档来辅助构建词图,丰富了图表示的信息.
随着深度学习技术的发展,关键词抽取也可以被视为序列预测任务[9,10],预测在一个文本序列中,哪一部分属于关键词.这通常属于监督学习的范畴,即需要预先准备好的,给关键词打上标签的文本,然后进行模型训练.
半监督学习方法,最早由Yarowsky等人提出[21],并由Kim[22]以及Ganesh[23]等人改进,他们将文本分类、实体抽取或者关键词抽取任务,视为种子在语料库中的自扩展迭代增殖过程.这首先需要手工标注少量的种子.如何更加方便合理地自动制作种子集合来代替人工,在每一轮迭代后,添加怎样的自动过滤规则,并设置合理的迭代终止条件,是需要继续研究的问题.
2 方法介绍
图1是本文方法的概述图,总体步骤如下:

图1 方法总体流程图Fig.1 Overall method flow chart
1)使用无监督方法进行种子集合的制作.
2)使用种子对语料库进行自动标注.
3)将标注好的数据作为深度学习模型的输入进行训练.
4)使用训练好的模型对语料库进行预测,抽取更多关键词.
5)根据规则对抽取结果进行自动过滤并添加到种子集合.
6)对步骤2~步骤5进行迭代直到满足终止条件.
以下小节将分别介绍每个步骤的细节.
2.1 无监督算法
本文需要抽取的关键词,可以被认为是名词性短语的一个子集.
名词性短语通常包括如下3种类型:
1)单个或者连续的多个名词.
例如:TextRank、computer vision.
2)单个或者连续的多个形容词加类型1.
例如:neural network、
unsupervised statistical algorithm.
3)两个类型1或者类型2中间加一个介词.
例如:Internet of Things、Deep Learning for Java.
其中,第1,2两个类型参考自文献[18].本文在此基础上添加了第3个类型.
本文使用了NLP工具NLTK[24]制定了如下的词性标注正则表达式来抽取以上3种类型的名词性短语:
{
(
(1)
其中,JJ表示形容词、NN表示普通名词单数、NNS表示普通名词复数、NNP表示专有名词、IN表示介词.
*、+、?为通配符,分别表示该通配符前面的一对<>中所表示的词性单词或()中所表示的词性句式匹配0~n次、1~n次以及0~1次.
关键词相比于普通的名词性短语,通常具有如下的特征:
1)关键词通常在当前文本中出现的频率较高,而在总的语料库中出现频率不高.
2)关键词通常较长,包含的单词较多.
3)关键词中,往往包含首字母大写单词或者全大写单词(缩略词).
现有的关键词抽取算法,例如TF-IDF算法[12],考虑了特征1,文献[14-16],考虑了特征1和特征2,本文在此基础上引入了第3个特征,即考虑了单词的大小写.
本文定义了如下的,结合了以上3种特征的公式,来为名词性短语打分:
phraseScore(p)=log2(1+wordNum(p))·
log2(2+upperWordNum(p))·TF(p)·IDF(p)
(2)
其中,p为待打分的名词性短语,wordNum为该短语中包含的单词数量,upperWordNum为该短语中包含大写字母的单词数量.
给每个候选词打分之后,半监督学习方法需要选取得分最高的前K个词(TopK),作为种子,加入种子集合.K值将作为本方法的超参数,在实验章节根据实验结果探究并确定.
除此以外,本文还制定了启发式规则,来抽取全称、缩写词对,将其抽取结果一同加入种子集合,作为LCF方法结果的补充.
其具体规则如下:
格式1:全称词(缩写词)
例如:“The linked open data includes several resource description framework(RDF)knowledge bases.” 其中 “resource description framework”和“RDF”就是满足该格式的一对全称、缩写词.
格式2:缩写词(全称词)
例如:“The event-based ontology called CRM(Conceptual Reference Model).”其中“Conceptual Reference Model”和“CRM”就是满足该格式的一对全称、缩写词.
本文使用了NLP工具ScispaCy[25]的基于规则的匹配组件实现了全称、缩写词抽取的方法.
2.2 自扩展迭代的半监督学习方法
该方法的整体流程即为该章节开头所述的步骤2~步骤6.其中,步骤2的自动标注的实现细节如下:
本文使用了“BIO”的标注策略.对于一个给定的待标注的文本,以及种子集合,首先将种子集合中的关键词按照长度降序排列(其目的是为了优先标注较长的关键词,以避免可能发生的嵌套标注).然后使用ScispaCy工具将文本和种子集合中的每一个关键词都转换成令牌(Token)序列,通常一个单词为一个Token.之后依次匹配文本序列和对应的种子序列,根据文本的每个部分是否存在于种子集合中,将文本中的每一个Token标记为“B”或“I”或“O”.其中“B”(Begin)表示为一个关键词的开头,“I”(Inside)表示一个关键词的中间或结尾,“O”(Outside)表示非关键词.在标注过程中,始终保证如下2条准则,不符合准则的标注操作不会执行:
1)“I”标签的左邻一定是“I”标签或者“B”标签;
2)后标注的“B”标签和“I”标签只能覆盖“O”标签;
表1是一个自动标注的结果示例.
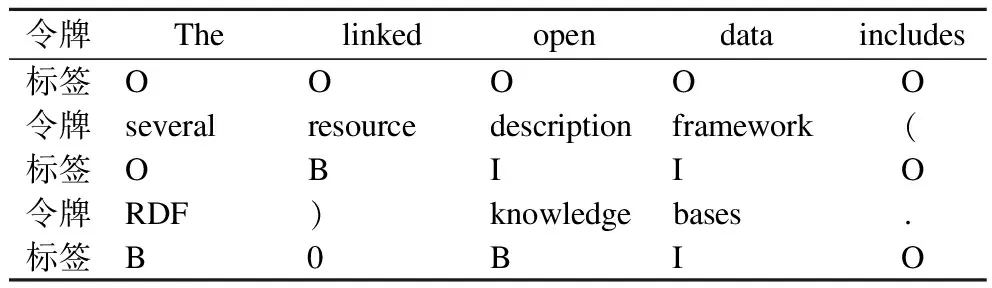
表1 自动标注结果示例Table 1 Result example of automatic annotation
给定一个待标注的句子:
“The linked open data includes several resource description framework(RDF)knowledge bases.”
以及种子集合:
{“resource description framework”,“knowledge base(s)”,“RDF”,…}.
标注好的结果如表1所示.
步骤3中具体的深度学习模型在本文的方法中是低耦合的,在本文在实验中使用的深度学习模型为SciBERT[16].
步骤5的过滤规则如下,只要满足以下任一情况将被过滤:
1)该候选词已经存在于种子集合中.
2)该候选词只包含一个单词并且可以在WordNet中检索到.WordNet是一个通用领域的英语字典的API,若一个候选词只包含一个单词且能在该字典中检索到,说明其更可能为通用词汇而非关键词.
3)该候选词以一个停用词开始或结束.
4)该候选词包含乱码或其他异常字符.
现有自扩展迭代方法的默认终止条件通常为不能再抽取出更多的候选词(也就是召回率不再增加).然而,该方法的缺点是,尽管召回率会随着迭代次数的增加而增加直至趋于稳定,但它的精确率却会不断降低.这是因为除非人工干预,否则无法在步骤5中进行完美的过滤,从而导致错误的累积和放大.而由此得到的F1值通常随着迭代次数的增加先增大后减小.因此,将迭代次数N作为方法的一个可调整的超参数,通过实验评估来找到一个最佳的N是很有必要的.
3 数据集
本文使用了公开数据集Hulth 2003以及一个新的自制数据集CPB 2022用作实验的训练、评估和对照.
Hulth 2003数据集由Hulth[26]首次使用,该数据集包含了Inspec数据库从1998至2002年的2000篇计算机以及信息技术相关文章的标题、摘要和关键词.Inspec数据库的每篇文章的标题和摘要都有两种分配的关键词.一个是“受控”(controlled),另一个是“非受控”(uncontrolled).“受控”关键词,通过给定的字典分配,而“非受控”关键词则由该数据库的专家根据标题和摘要的内容自由分配.在本文中,只使用非受控关键词来评估各方法的效果,因为其由专家手工分配,数量更多,更加全面,也更加可靠.
Hulth还将数据集分为3个部分,1000篇用于训练,500篇用于验证,500篇用于测试.
参照Hulth 2003数据集的制作方法,本文制作了CPB 2022数据集,该数据集包含的文章数量、关键词的分配方式、训练集、验证集、测试集的划分等,都与Hulth 2003一致.和Hulth 2003的区别在于,CPB 2022数据集搜集的文献出版日期是从2021年1月至2022年4月,文章所属的学科为计算机科学、物理学和生物医药学.
表2展示了各类方法所需要的数据集资源.在需要调整超参数、以及评估方法最终效果的前提下,监督学习需要使用数据集的全部资源,即训练集的文本和关键词、验证集的文本和关键词、以及测试集的文本和关键词.

表2 方法所需的数据集资源Table 2 Datasets resources required by methods
在表2中,×代表该资源不需要,√代表需要,○为可选.这些方法在实际使用时,若已经根据经验预设了方法的超参数,则无须使用验证集,若不需要评估实验的最终结果,则无须使用测试集.
本文方法的优势在于无需手工标注关键词的数据集,为了模拟该低资源环境,同时又能够与其他方法进行对照,本文的半监督学习方法,不使用训练集的关键词,只使用其标题、摘要文本作为语料资源.尽管相比无监督算法,本文的半监督方法需要训练集的文本,但是在实际的工程应用中,无标签的文本获取成本远低于带标签的文本.
4 评估方法
本文使用精确率(Precision),召回率(Recall)和F1值来评价每种方法的效果,定义如下:
(3)
(4)
(5)
其中,Standard为数据集提供的标准关键词集合,Extraction为待评估的方法抽取出的关键词集合.精确率为正确抽取的关键词数量和抽取的关键词数量之比.召回率为正确抽取的关键词数量和标准关键词的数量之比.F1值是精确率和召回率的一种调和平均.
5 实 验
实验章节分为两部分,首先比较了LCF算法和现有其他无监督算法,选择了合适的K值用以制作初始种子集合,并结合AF方法用作补充.然后探寻了最佳的自扩展迭代方法的迭代次数N,并验证了过滤规则的有效性.
5.1 无监督算法相关实验
本文在Hulth 2003和CPB 2022的验证集的合集上,评估了LCF算法的K值和精确率、召回率、F1值之间的关系.结果如图2所示.

图2 LCF方法的K值和精确率、召回率、F1值之间的关系Fig.2 Relation between K,precision,recall and F1 value of LCF method
从图2中可以看到,随着K值增加,精确率不断下降,召回率不断上升,当K小于等于2时,具有较高的精确率(大于0.9),但此时召回率较低,当K大于10后,F1值增长趋于平缓,当K等于13时,F1值达到最大,此后F1值开始略微回落.
然后,本文在Hulth 2003和CPB 2022两个数据集的验证集上做了LCF算法的相关消融实验.超参数K设为10.
在表3中,×代表去除该组件,√代表保留该组件,类型3即为中间带有介词的名词性短语,若去除类型3,此时的词性标签正则表达式为:

表3 K=10时LCF算法在验证集上的消融实验Table 3 Ablation experiments of LCF algorithm on the two validation sets when K=10
{
(6)
特征3即为名词性短语的大小写特征,若去除特征3,此时的名词性短语的评分公式为:
phraseScore(p)=log2(1+wordNum(p))·TF(p)·IDF(p)
(7)
由表3可知,类型3和特征3的添加,对精确率和召回率的提升都有一定的贡献,其中类型3对召回率的提升更大,特征3对精确率的提升更大,而二者的同时使用,使得召回率保持相对高位的同时,精确率进一步提升.
表4为LCF算法和其他现有的无监督算法在Hulth 2003和CPB 2022的测试集上的评估结果.K值统一设为10.

表4 K=10时,各无监督算法在测试集上的评估结果Table 4 Evaluation results of various unsupervised algorithm on the two test sets when K=10
可见LCF方法的F1值在接近或达到最佳方法的同时,具有相对高精确率的优势.
为了进一步满足半监督方法对于初始种子集合的高精确率要求,根据图2评估结果,选择将K等于2时LCF算法的抽取结果加入种子集合.为了对初始种子集合作进一步补充,本文还使用了缩写、全称抽取方法(Acronym &Full-name,AF).
由表5可知,AF方法的精确率很高,但是召回率很低,只有很少的关键词是以缩写紧跟着全称的形式存在的.AF和LCF方法结合使用来制作的初始种子集合(两种方法的抽取结果取并集)相比单独使用LCF方法的精确率和召回率都提升了.
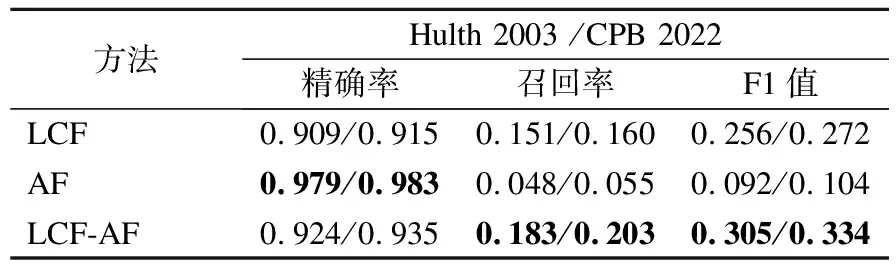
表5 制作初始种子集合的方法在验证集上的评估结果Table 5 Evaluation results of the methods of making initial seed sets on the two validation sets
不单独使用AF方法的抽取结果作为初始种子集合的原因是,其抽取结果的构成单一,并且过少的数据不能满足深度学习模型对于训练数据量的要求,这会导致训练结果的不确定性增加.
5.2 自扩展迭代实验
本文的自扩展迭代方法的一个重要的超参数为迭代次数N,表6分别展示了在每轮迭代之后无过滤的LCF-AF-BS方法以及有过滤的LCF-AF-FBS方法在Hulth 2003和CPB 2022的训练集上训练,在验证集上评估的迭代次数N和精确率、召回率、F1值之间的关系.

表6 无过滤和有过滤的自扩展迭代方法在验证集上评估的迭代次数N、精确率、召回率、F1值之间的关系Table 6 Relation between N,precision,recall and F1 values evaluated by the unfiltered and filtered self-expanding iteration methods on the two validation sets
由表6的结果可知,添加的过滤规则有效地降低了每一轮的迭代造成的精确率损失.并且使得达到最佳F1值的迭代次数延后了,从第4次迭代增加到了第8次左右,并且使最佳F1值由0.512/0.538增加到了0.602/0.615.
根据验证集的实验结果,确定了自扩展迭代方法中的各项超参数如表7所示,其中Lr和Epochs是深度学习模型SciBERT的超参数.

表7 实验超参数设置Table 7 Experimental hyperparameters setting
本文的实验是在谷歌云计算平台Colab上实施的,其硬件配置如表8所示.

表8 实验硬件配置Table 8 Experimental hardware configuration
确定了超参数之后,自扩展迭代方法在Hulth 2003和CPB 2022的测试集上的最终评估结果如表9所示.
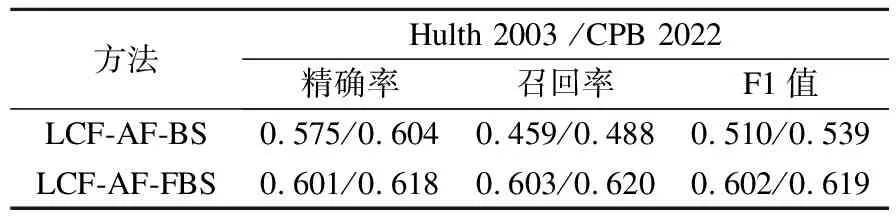
表9 自扩展迭代方法在测试集上的最终评估结果Table 9 Final evaluation results of the self-extended iteration method on the two test sets
6 有效性分析
本文提出的无监督方法LCF,涉及到了候选短语的大小写特征,以及全称、缩写词抽取方法AF,适用于以英语为代表的具有这些特征的语言,在中文等语言环境中,无法发挥其优势.本文的半监督学习方法涉及到了深度学习模型SciBERT,相比无监督算法,需要相对高的硬件配置条件.因此,如何扩展本方法的语言适用性范围,如何在保证方法性能的前提下降低硬件配置要求,还需要进一步研究.
7 总 结
本文提出的半监督的自扩展迭代关键词抽取方法LCF-AF-FBS(表9)在无需手工标注关键词的前提下,相比现有的无监督算法(表4),其F1值高出约0.1.监督学习方法的高效是建立在以有现成的大量的高质量的带标签的数据集为前提的,无法在缺少标注的低资源环境下快速运用.在实际的工程应用中,LCF-AF-FBS方法可以在低资源环境下作为无监督算法的一种优化和替代.
猜你喜欢
儿童时代·幸福宝宝(2019年9期)2019-10-28
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
莫愁·家教与成才(2017年7期)2017-07-11
公民与法治(2016年10期)2016-05-17
海峡姐妹(2016年2期)2016-02-27
计算机工程(2015年8期)2015-07-03
求学·理科版(2015年6期)2015-06-18
