
分段时间注意力时空图卷积网络的动作识别
2024-02-28 08:18吕梦柯郭佳乐丁英强陈恩庆
小型微型计算机系统 2024年1期
吕梦柯,郭佳乐,丁英强,陈恩庆,2
1(郑州大学 电气与信息工程学院,郑州 450001)
2(河南信通智能物联有限公司,郑州 450007)
0 引 言
随着人工智能技术的发展,人体动作识别成为了计算机视觉领域热门的研究方向之一.研究人体动作的识别可以帮助人们深入地理解视频,也可以帮助人们做一些自动化地处理.在智能视频监控、智能安防、医院监护系统、养老院监护系统等场景下具有广泛的应用前景.深度相机等一系列多用途的视频采集传感器的出现,使得人们可以依据RGB图像、光流、深度图像[1]、骨骼特征图等多种数据对人体动作进行建模.在这么多种类的视频数据中,由于骨骼数据没有复杂的背景信息和动态环境,具有更强的表达能力和环境适应性,可以更加专注于动作本身,因此出现了越来越多的针对骨骼点数据的动作识别研究.
最早基于骨骼点的人体动作识别方法采用手动构建特征的方式,对视频数据进行采样、手动提取特征、编码和训练分类,这种方法对于多样性的变化没有很好的鲁棒性[2,3],并且需要手动大量调参,消耗人力.近年来随着计算机硬件水平的不断提高,深度学习通过其端到端的方式,自动提取特征,展现出了比传统方法更强大的建模能力和泛化能力.因此越来越多的研究人员使用深度学习对人体动作进行建模和分类识别.在深度神经网络动作识别领域最早使用的有卷积神经网络(convolutional neural network,CNN)[4-6]和递归神经网络(recurrent neural network,RNN)[7,8].虽然这两种网络相比于传统手工提取特征的方法有更高的识别准确率和鲁棒性,但是都无法利用骨骼点数据的骨架信息和连接结构.而在进行各种动作时骨骼点数据的连接结构信息是非常重要的.近些年出现的图卷积神经网络(GCN)可以接收图结构数据作为输入,对于骨骼点数据的建模分析相比于CNN和RNN拥有先天优势.2018年Yan等人[9]首次提出将图卷积网络应用于骨骼点动作识别,提出了时空图卷积网络(ST-GCN)将图卷积网络扩展到时空域,同时考虑了骨骼点在空间和时间上的邻接关系.2019年石磊等人[10]在ST-GCN的基础上提出双流自适应图卷积网络(2s-AGCG),额外引入了两个可学习矩阵.但是其可学习矩阵Ck直接进行矩阵卷积,不仅计算量大,而且忽略的帧间的差异性,将一整个视频统一对待,学习一个关系矩阵.但其实每个动作视频流中,我们在不同时刻关注的位置点可能并不相同.针对此问题,本文提出分段时间注意力时空图卷积网络用于骨骼点动作识别.
在2S-AGCN模型中Ck表示模型根据每一个样本学习的一个独有的图,用来捕捉关节间的相似性.其具体产生方式为使用经典的高斯嵌入函数通过θ分支和φ分支两个卷积层之后相乘得到.这种方法不仅计算量大,而且忽略了时间帧段之间的差异性,无法适应不同动作的变化,无法保证该注意力图是最优的.为了解决这个问题,本文提出将时间帧进行分段处理,迭代处理搜索最优的分区个数,同时采用全局注意力图,并且将通道数压缩为1,进一步降低计算量,以便能够在嵌入式硬件平台上进行部署.本文以2s-AGCN为比较对象,在NTU-RGBD数据集和Kinetics-Skeleton数据集上进行了大量对比实验,结果表明,本文所提方法拥有比目前多数文献更高的动作识别精度.
1 相关工作
1.1 基于深度学习的动作识别
基于深度学习的方法一般采用端到端的形式,通过网络模型自动学习视频动作中的特征来完成分类任务.基于CNN的方法有Simonyan等人[11]提出的双流CNN,其将视频看作一段图像序列,单帧RGB图像作为空间流输入,用于提取空间特征,连续的光流帧作为时间流输入,用于提取时序特征,最后将两个网络进行融合.基于RNN的方法主要采用LSTM网络,Ng等人[12]提出使用LSTM网络对连续时间帧进行建模.相比于传统双流网络,LSTM由于其长短期记忆的特性,可以很好地提取连续时间帧上的序列信息.以上都是基于视频帧的动作识别.骨骼点动作识别的难点在于,CNN和RNN网络接收的都是图像帧数据,属于欧几里得数据,而图像视频骨骼点数据属于非欧几里得数据.如何将非欧几里得数据作为神经网络的输入,是人们近几年研究的热点.Li等人[13]首次将CNN应用于骨骼点的动作识别,将骨骼点数据构造成伪图像数据输入到CNN网络中,实现了在时间和关节上聚合特征.虽然这种方法可以同时在时间和空间上提取特征,使模型达到较高的识别准确率,但是其没有充分利用骨骼点数据的天然连接关系.
1.2 基于图卷积网络的骨骼动作识别
图卷积网络(GCN)从人体空间结构出发,将人体骨骼点构建为一种图结构,充分利用了人体骨骼点之间的连接关系.Yan等人[9]首次将GCN引入骨骼动作识别,提出了时空图卷积网络(ST-GCN),将图卷积同时扩展到了时空领域.对每个骨骼关节点来说,同时考虑空间上和时间上的相邻节点.ST-GCN根据真实的人体骨骼连接关系,构建了一种固定的邻接矩阵,因此网络无法对时空图进行优化,学习一些不存在的连接关系.然而在很多实际动作中,非相邻关节点间的运动特征也是有联系的.针对这个问题,石磊等人[10]提出了双流自适应图卷积网络(2s-AGCN),在ST-GCN预定义的时空图基础上,引入自适应邻接矩阵和数据注意力矩阵两个可学习矩阵.其中自适应邻接矩阵根据数据样本学习两个节点间的连接关系及联系的强弱,数据注意力矩阵根据每一个样本学习一个独有的注意力图.通过这两个可学习矩阵,模型能够学习更丰富的连接关系.文献[14]提了出动作结构图卷积网络(AS-GCN),引入一种被称为A-link的推断模块,用于从动作中捕获潜在的依赖关系,获得更强的表现力.文献[15]提出了有向图神经网络(DGNN),将骨骼数据表示成一个有向非循环图,这样可以同时提取到骨骼点信息和它们之间的依赖关系.但是上面这些方法在关注骨骼点数据空间联系的同时,忽略了动作过程中的细节信息.现有的这些方法将整个动作序列帧融合在一起做卷积,提取注意力特征图.这样做使得模型对于相似动作的识别的鲁棒性不高,不能很好地适应复杂动作的识别.针对这个问题,本文提出分段时间注意力时空图卷积模型,将时间帧进行分段处理,在每一段内对通道进行压缩,从而实现在提高模型对相似动作识别准确率的同时,降低模型计算量.下面第2节,第3节将分别详细介绍所提方法和测试实验的结果.
2 分段时间注意力时空图卷积网络
2.1 时空图卷积网络
时空图卷积网络(ST-GCN)提出将人体骨骼关节点构造为一个无向时空图G=(V,E),其中V为节点特征,V={vti|t=1,…,T,i=1,…,N},vti代表不同节点特征,t为不同帧的节点,i为不同人体关节点.E为边特征,E={Es,Ef}.其结构如图1所示,该骨架序列包含N个关节点和T帧,同时具有空间和帧间的连接,所以被称为时空图,并将此作为网络的输入.时空图的建模包含空间域和时间域,在空间域中,根据人体骨架的自然连接关系,将每一帧内的骨骼节点连接起来,形成空间域边集合ES={vtivtj|(i,j)∈H},H为人体关节点集合.在时间域中,将相邻帧间的相同骨骼节点连接起来,形成时间域边集合EF={vtiv(t+1)i}.

图1 时空图Fig.1 Spatiotemporal map
ST-GCN共提出3种空间配置分区方式,其结构如图2所示,(a)输入骨架序列图,其中空心节点表示本次卷积的中心点,虚线内其他点表示当前节点的相邻节点.(b)单标签划分:把当前节点以及相邻节点全部划分为一个子集,让子集内每个节点权重相同做内积.这种方法忽略了局部信息和关节点之间的差异性,无法计算局部微分属性.(c)距离划分:把当前节点归为一个子集(空心节点),把当前节点相邻节点归为另一个子集(距离为1的实心节点),增加了当前节点与相邻节点的差异性信息.(d)空间配置划分:根据关节点与中心点的距离关系进行划分,分为当前节点(空心节点),与当前节点相邻且离重心距离近的点(标号为1的实心节点),与当前节点相邻且离重心距离远的点(标号为2的实心节点),3个子集,设置3种权重向量.具体表示公式为:

图2 空间配置分区方式Fig.2 Spatial configuration partition
(1)
其中r表示节点到重心的平均距离.这种划分方法进一步增加了关节点的差异信息,能够表征关节点的向心运动与离心运动,更符合人体动作的实际情况,具有更好的动作建模能力.后续的方法采用的都是这种分区方式,或是在这种方法的基础上稍加改进,如文献[16]提出的多配置分区,额外引入两个分区来建模物理上不存在连接关系的关节点的连接信息.
ST-GCN的整体公式如公式(2)所示:
(2)
其中fin是网络输入的上面所定义的时空图,Ak是邻接矩阵,Mk是注意力掩码,Wk是权重矩阵,Kv是分区个数,一般取3,⊙表示对应位置元素相乘.由于ST-GCN的注意力矩阵Mk与邻接矩阵Ak是点积直接相乘,并不是矩阵相乘,就会出现如果邻接矩阵Ak中有些元素的值为0.因此不管Mk中对应位置元素的值为多少,点积之后的结果都是0,无法建立本身不存在连接关系的关节点之间的联系.例如跑步,手部关节与腿部关节之间是有关系的,但是它们之间并没有显式的连接,就并不能建立它们之间的关系.基于此问题,2s-AGCN提出引入额外两个邻接矩阵来学习物理上不存在连接关系的关节点之间的相关性[10].其结构如图3所示,可以用公式(3)表示:
(3)

图3 2S-AGCN空间图卷积结构(左)和多分段时间注意力(右)Fig.3 Convolution structure of spatial graph(left)and multi-segment temporal attention(right)
其中Bk是一个大小跟Ak一样的邻接矩阵.不同的是,它没有进行归一化操作,完全由数据中学习,不仅能表示两个关节点之间是否有联系,而且还能表示它们之间联系的强弱.Ck是针对每一个样本学习一个独有图,通过公式(4)得到,其中Wθ和Wφ是高斯嵌入函数的权重.
(4)
2.2 分段时间注意力时空图卷积网络
目前多数基于2s-AGCN 的模型都是采用上述方式,直接将输入与高斯嵌入函数卷积之后再融合得到数据注意力矩阵Ck.输入数据大小为C×T×N,将输入数据经θ分支编码后转换为N×CT,将输入数据经φ分支编码后转换为CT×N,然后将两个分支产生的矩阵相乘得到N×N的注意力矩阵Ck.从中我们可以看出,此类方法把整个动作所有帧融和在一起进行卷积,这样做会导致模型无法准确捕捉整个动作流中的细节部位,只做了大体轮廓上的注意力特征提取.针对此问题,我们提出分段时间注意力时空图卷积网络,通过使用搜索合理的分段个数,在每个时间段内同时进行注意力特征的提取.相对于原网络,极大地提高了模型对于局部细节特征的提取能力,最后将其融合为一个新的注意力矩阵Ck.
在分段时间注意力时空图卷积网络中,我们的输入数据大小依旧为C×T×N,经高斯嵌入函数θ分支编码后,我们将时间帧分为h段,数据大小变为C×h×T/h×N.我们观察到最后得到的注意力矩阵大小为N×N,与通道C是没有关系的,因此我们在每一个时间段上对通道C求均值,来降低数据维度,降低计算量.最后得到的数据大小为h×N×T/h.同样的方法,φ分支编码转换后的数据大小为h×T/h×N,对两个分支得到的数据进行相乘,并将第一维数据求和就可以得到数据注意力矩阵Ck.其空间网络结构可以用图3中右侧图表示.
为了进一步优化模型,我们还在十层的GCN网络之后引入一个协调注意力模块[17],可以将数据中的位置信息嵌入到注意力图中,用来加强网络提取到的特征.与单特征向量的通道注意力不同,协调注意力把特征沿水平和垂直两个方向进行1D全局池化来聚合特征,得到两个具有位置信息的注意力图.这种方法不仅可以捕获交叉通道信息,还可以捕获方向和位置信息.其结构如图4所示.

图4 协调注意力结构图Fig.4 Coordinate attention network diagram(left)
在骨骼数据中,我们可以利用的不止是骨骼关节点,关节点与关节点之间的骨架同样具有丰富的信息.因此,我们可以将所有的骨骼用向量表示,称为骨骼向量.我们将人体骨骼数据中的中心关节点视为源关节点,则骨骼向量的大小表示这段骨骼的长度,由两个骨骼节点的坐标差值得到.骨骼向量的方向表示这段骨骼的方向,由靠近源关节点的节点指向远离源关节点的节点.我们将骨骼节点数据和骨架数据经过相同的网络得到不同的结果,最后使用双流融合的方法将两种数据得到的结果进行融合处理,得到最终得分.
本文提出的用于骨骼点动作识别的分段时间注意力时空图卷积网络模型的整体结构如图5所示,网络整体包括一个初始批量归一化层(BN),十个分段时间注意力模块(由SegT-AGCN与TCN级联组成),一个协调注意力模块(CA),一个全连接层(FC).

图5 基于多分段的时间注意力图卷积网络整体结构Fig.5 Whole structure of graph convolutional network based on multi-segment temporal attention matrix
3 实验结果及分析
3.1 数据集和实验设置
NTU-RGBD[18]:NTU-RGBD数据集包含有56880个动作数据,分为60种动作类别.其中40种为日常行为,9种与医学健康相关,11种为双人动作.这些动作的执行者年龄在10岁到35岁之间.每一个动作数据样本由骨架帧组成,每帧最多两副骨架,每幅骨架由25个骨骼点的三维坐标表示.该数据集采用微软的Kinect V2摄像头采集,并设置3个摄像头在3个不同方位同时采集(-45°,0°,45°).每个动作表演者会重复做两次,分别对着左侧与右侧两个摄像头,这样就可以得到2×3个不同角度下的数据.该数据集的划分有两种方式,跨目标划分(X-Sub)与跨视角划分(X-View).X-Sub方式下,我们将40位表演者按编号进行训练集与测试集划分.X-View方式下,我们对3个相机按编号划分训练集与测试集.Kinetics-Skeleton[19]:Kinetics数据集包含有300000个动作数据,分为400个动作类别,涵盖了日常生活到复杂交互等各种动作,是一个比较全面的数据集.该数据集中的数据样本由骨架帧组成,每个骨架含有18个关节点,分别用三维坐标表示.我们使用文献[10]中的方法对这两个数据集进行数据预处理.
本实验所采用的硬件设备为2块NVIDIA TITAN V显卡,软件信息cuda10.0,python3.7.5,pytorch1.71.本实验使用随机梯度下降优化策略,初始学习率设置为0.1,权重衰减率设置为0.0001.在NTU-RGBD数据集上,批大小设置为32,训练次数为50个epoch,在第30和第40个epoch时将学习率除以10.在Kinetics-Skeleton数据集上,批大小设置为64,训练次数为65个epoch,在第45和第55个epoch时将学习率除以10.
3.2 实验比较分析
本文所提出的多分段时间注意力时空图卷积网络是以双流时空图卷积网络(2s-AGCN)为基础模型得来的.下面首先进行最佳时间帧分段个数搜索实验,获得最佳的分段数量.然后在此基础上对所提的各个模块与基础模型做了对比消融实验,以验证组件有效性.最后进行骨骼模态与关节模态的融合实验得出最终的双流网络分类得分,并与目前主流的方法进行比较,验证该方法的有效性.为了使结果更加准确,我们每个实验都重复3次求平均值得出最终的得分.
3.2.1 最佳时间分段个数实验
首先对不同分段个数进行了实验分析,以获得最佳的时间帧分段个数.在同一个数据集相同的划分方式下,骨骼点数据(Joint)与骨架数据(Bone)在经过相同网络模型后,得分具有正相关性.因此,本小节搜索最佳分段个数实验我们只使用骨骼点单流数据,不进行双流融合.数据集使用NTU-RGBD和Kinetics-Skeleton,其中第一列代表本小节实验所采用的模型方法.第2列准确率(CV)代表模型在NTU-RGBD数据集X-View分区方式下的准确率,第3列则是在NTU-RGBD数据集X-Sub分区方式下的准确率,最后一列表示在Kinetics-Skeleton数据集上的准确率.实验结果如表1所示,SegTx代表时间帧分段个数为x,从实验结果中我们可以看出,令时间帧进行分段提取注意力,能有效提高模型的准确率得分.在分段个数为4时出现拐点,当分段个数小于4时,随着分段个数的增加,模型的准确率有明显提高;当分段个数大于4时,随着分段个数的增加,模型准确率趋于平稳.结果分析:当我们对一整个动作帧进行分段时,可以在每一段内提取注意力.一般一个完整的动作,在开始中间和结束,我们关注的位置并不相同,因此增加分段个数可以显著提高模型最终的得分.而当分段个数大于4时,模型得分不再显著增加的原因是:一个完整的动作一般我们将它分为3到4个部分就可以实现完整表达,再多的分段个数只会增加模型的计算量,并不会对模型的最终得分有帮助.为了进一步验证分段为4时的模型的优越性能,本小节给出模型训练过程中Loss值的变化图、Top1得分变化图、Top5得分变化图3种(横坐标均取31-50Epoch),结果分别如图6,图7,图8所示.从图中我们可以看出分段为4时Loss值最低,下降最快,Top1和Top5准确率均表现最好.
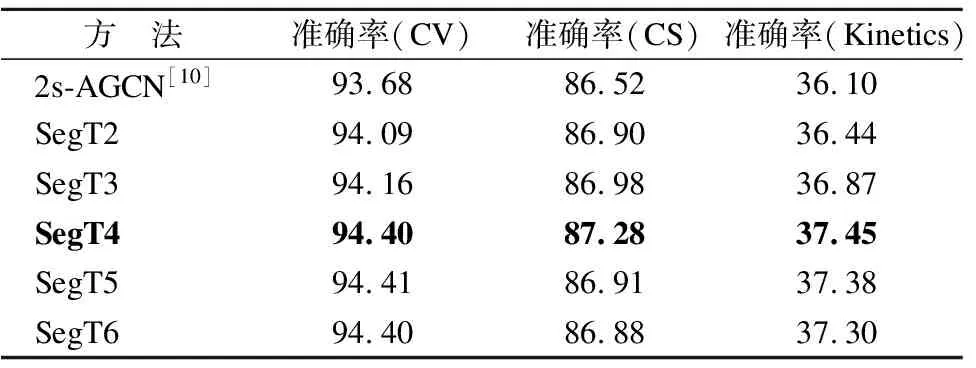
表1 不同分段个数对模型性能影响Table 1 Influence of different number of segments on model performance

图6 Loss变化曲线图Fig.6 Loss curvilinear statistical graph

图7 Top1准确率变化曲线图Fig.7 Top1 accuracy curvilinear statistical graph

图8 Top5准确率变化曲线图Fig.8 Top5 accuracy curvilinear statistical graph
3.2.2 所提各模块消融实验
本小节实验验证了所提时间帧分段模块以及协调注意力对模型的促进效果.本次实验在NTU-RGBD数据集X-View划分方式下骨骼点数据上进行.实验结果如表2所示,从表中我们可以得知,在原网络模型的基础上加添了时间帧分段(分段个数设置为4,由第3.2.1节的实验得出)之后模型准确率提升了0.72个百分点.添加协调注意力模块后模型准确率提升了0.68个百分点.同时添加所提的两个模块后模型准确率提升了1.18个百分点.由此可以得出本文所提方法可以有效提升基础网络模型的准确率.

表2 各个模块对模型性能的影响Table 2 Influence of each module on model performance
3.2.3 骨架与关节双流融合实验
本小节验证了在骨骼点数据与骨架数据的双流融合下本文所提方法的有效性.本节实验在NTU-RGBD数据集X-View划分方式下进行.实验结果如表3所示,实验结果表明在两种模态数据上以及双流融合后,本方法均可以提供模型分类得分.

表3 双流网络性能Table 3 Two-Stream network performance
本小结又在NTU-RGBD和Kinetics-Skeleton数据集数据集上与目前一些主流方法进行对比实验,验证了本文所提方法的有效性.实验结果如表4和表5所示,结果表明,本文所提方法在NTU-RGBD数据集X-View划分方式下,准确率得分比2s-AGCN提高了0.8个百分点;在X-Sub划分方式下,准确率得分比2s-AGCN提高1.6个百分点,在Kinetics-Skeleton数据集上,准确率得分比2s-AGCN提高1.7个百分点.

表4 不同方法在NTU-RGBD数据集下的比较Table 4 Comparison of different methods based on the NTU-RGBD dataset

表5 不同方法在Kinetics-Skeleton数据集的比较Table 5 Methods compared on the Kinetics-Skeleton
3.3 模型应用及未来方向
基于本文所提方法,构建了一套人体异常行为检测系统,可以用于实时检测一些特定的行为动作,根据需求不同可以进行特定调整,本次实验设定检测动作为跌倒行为,主要用于保障老年人独自在家时的健康状况.
本系统主要包含三大网络模型,第1步将摄像头获取到的视频数据流输入到YOLOV3[23]中进行人体目标检测,获取到人物位置.第2步根据获取到的人物位置信息对视频帧数据进行裁剪,然后送入AlphaPose[24]网络中进行人体骨骼点信息提取.第3步将人体骨骼点信息送入本文所提模型SegTCA-AGCN中进行动作识别.其整体结构如图9所示.系统实验结果如图10所示.在未来将对模型和系统进行升级改造,以应对更多的应用场景.
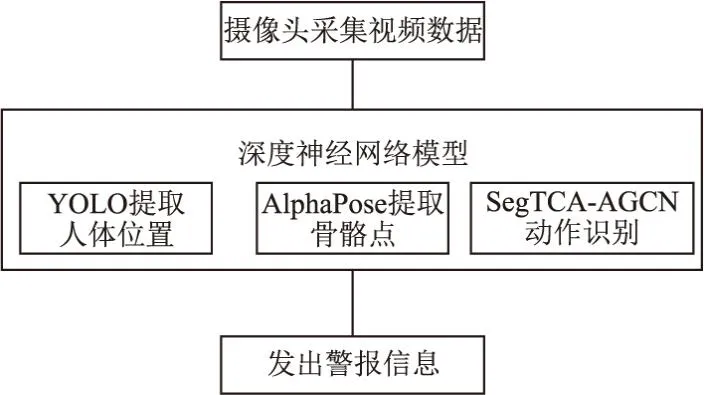
图9 异常行为检测系统结构Fig.9 Abnormal behavior detection system structure

图10 人体异常行为检测系统Fig.10 Human abnormal behavior detection system
4 结 语
本文提出了一种多分段时间注意力的时空图卷积网络,用于骨骼点动作识别.通过实验搜索出合理的分段个数,将动作帧分段处理,使模型能够更好地提取不同时间段内的特征信息,以提高模型的泛化能力和识别准确率.为了验证该方法的有效性,在NTU-RGBD和Kinetics-Skeleton两个大型数据集上进行大量实验.最终结果表明,本文所提模型获得了比目前多数文献更高的识别准确率,为该领域的研究提供了新思路.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中老年保健(2021年5期)2021-12-02
数学物理学报(2021年4期)2021-08-30
中老年保健(2021年5期)2021-08-24
小学生学习指导(低年级)(2018年11期)2018-12-03
小布老虎(2017年1期)2017-07-18
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年9期)2016-07-12
中国当代医药(2013年35期)2013-12-10
