
核泄漏事故风险评估中的概率分析及预测
2024-03-04 12:05何博文
合肥工业大学学报(自然科学版) 2024年2期
何博文, 关 群
(1.范德堡大学 土木与环境工程系,田纳西 纳什维尔 37212; 2.合肥工业大学 土木与水利工程学院,安徽 合肥 230009)
核泄漏是一种可对人类以及周边环境造成巨大破坏的工程事故,通常可分为核芯完全熔融和核芯部分熔融[1],具体表现为反应堆内部由于温度超过设定温度所导致的核芯和燃料棒的融化及放射性物质的泄漏[2]。历史上曾出现过多次举世闻名的重大核泄漏灾害事故,例如,2011年的日本福岛事件,1986年的切尔诺贝利事件及1977年的美国三里岛事件[3]。因此,核泄漏被认为是当代最危险的工业事故之一,其重要性值得业内工程师以及科学家投入大量精力来研究。
本文基于统计分析的角度,探究核泄漏事故的发生与反应堆自身的设计因素和外部影响因素之间存在的联系,为核反应堆工程师在未来反应堆的选址、设计及相关建设运营方面提供参考。
1 统计方法
1.1 样本选取
本文重点选取在全球范围内具有核泄漏事故记录的核反应堆和从未发生过核泄漏事故的核反应堆进行研究。对于具有核泄漏记录的核反应堆,不仅采取具有全球重要影响的核泄漏记录的核反应堆,同时也采取一些具有不著名核泄漏历史记录的核反应堆来组成研究样本。为了扩充样本容量, 本文不仅选取大型商用核反应堆(例如切尔诺贝利核反应堆),同时也采取小型还未商用的反应堆(例如实验与科研反应堆)来组成研究样本。对于未发生过核泄漏事故的核反应堆样本,其样本个例均来自全球正在商用运行的核反应堆机组。
1.2 数据采集
本文在全球范围内选取50个核反应堆组成研究样本。样本反应堆的特征参数来自世界核协会与国际原子能机构[4-5]。通过确定核反应堆的设计类型,确定其设计公司并查找该公司该产品的技术报告和设计手册的方法来最终确定该反应堆的所有相关设计参数。同时,采取大量来自研究文献的信息来评估样本反应堆是否建造在一个易发生地震与海啸的位置。例如,在样本反应堆中,有一个是由关西电力公司建造运营的三滨核反应堆。文献[6]研究发现建造的三滨核反应堆位置下有剧烈的地壳运动痕迹,显示其位置具有很大的发生7.4级及以上地震的可能性,从而影响三滨核反应堆的运营。同时,由于日本是一个狭长的岛国,对于地震之后接连发生海啸有极大的可能性,而海啸对临近海岸线的建筑物包括核电站会造成巨大的破坏和影响。基于这些信息,三滨核反应堆的建造地址是一个不够理想且易于发生核泄漏事故的地理位置。同样采取大量来自研究文献的信息判断在核泄漏事故中是否存在人为操作上的失误。例如,历史上著名的三里岛核泄漏事件中,一位核电站操作人员误判了阀门的开关状态这一重大关键性的人为操作失误,直接导致了美国核工业历史上无可挽回的结果[7]。
1.3 解释变量
本研究把可能与核泄漏事故发生相关联的因素分为内部因素和外部因素。内部因素是指由反应堆自身特性所决定的因素,例如反应堆一系列的设计参数。外部因素是指由非反应堆自身特性所决定的因素,例如人为以及不可抗力因素。
根据人为环境因素,本文在内部因素中选取设计功率、堆芯高度、堆芯直径、燃料类型、冷却液类型和慢化剂类型6个变量。设计功率是衡量核反应堆输出能力的表征量;堆芯高度、堆芯直径是表征核反应堆堆芯大小的几何量;燃料类型、冷却液类型及慢化剂类型是代表核反应堆类型的表征量。同时,在这些内部因素中,设计功率、堆芯高度和堆芯直径是数值变量;燃料类型、冷却液类型及慢化剂类型是类别变量。本文使用虚变量表示不同的燃料、冷却液及慢化剂类型。
对于外部因素,选取建造地址和人为操作因素作为模型独立自变量。建造地址是反映样本反应堆的安全运行是否容易遭受由地理位置而带来的不可抗力因素,诸如地震或海啸的影响的表征量。人为因素是反映在整个核反应堆运行过程中,样本反应堆的安全运行是否容易遭受由于重大人为操作失误因素而带来的运行风险的表征量。同时,在这些外部因素中,两者均为布尔变量,即0代表建造地址不易受诸如地震、海啸的影响以及没有发现任何人为操作失误的历史记录;1代表建造地址容易受诸如地震、海啸的影响及发现存在人为操作失误的历史记录。本文研究的变量类型见表1所列。
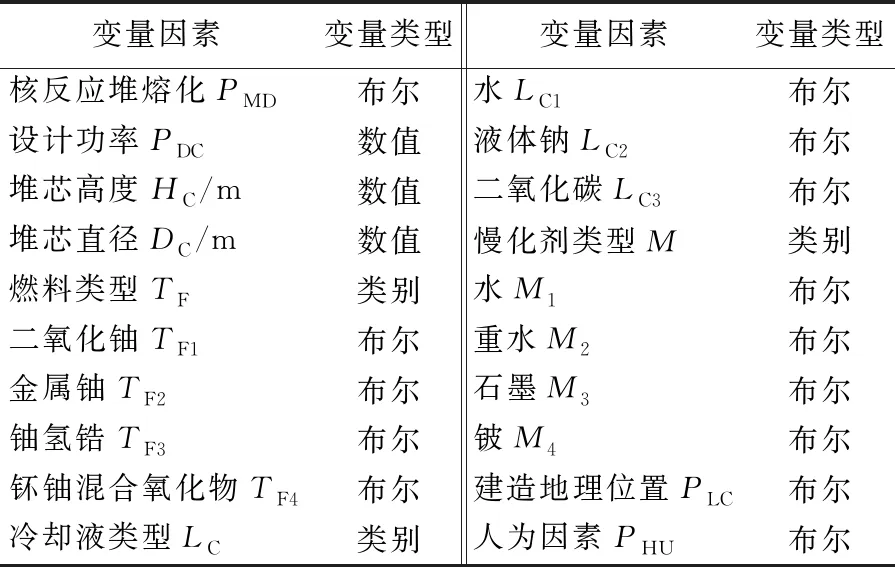
表1 变量因素类型
2 模型建立
2.1 逻辑回归模型
逻辑回归模型(logistic regression model,LRM)是基于一系列独立自变量预测并分类系统应变量的统计学分析方法[8]。LRM不同于传统的判别式分析模型,其自变量无需服从正态分布,或要求其每个组别中都有相同的方差[9],存在明显的优势。此外,LRM对其输入自变量基本不存在任何限制[9]。在本研究中,LRM中的独立自变量为布尔类型、类别类型、数值类型。LRM可允许在不同复杂程度的模型中进行预测精确性的对比。最简单的模型是只用一个与应变量具有最显著数值关系的变量作为独立自变量的模型,而最复杂的模型是采取所有可能与系统应变量有关系的变量作为独立自变量的模型。本文采用具有最精确的分类预测能力,同时具有最少独立自变量的LRM。
本研究使用可产生2种输出结果的二元LRM,即输出结果可以是判定反应堆出现核泄漏事故或反应堆无核泄漏事故。采用50个来自不同组别的反应堆来训练回归模型,即19个具有核泄漏事故历史的反应堆和31个无核泄漏历史的反应堆。选取19个具有核泄漏事故历史的反应堆的原因在于该类反应堆的数量在全球范围内较少,它们的样本已经充分利用了此类样本所能提供的有限的信息。对于另一组31个无核泄漏历史的反应堆,首先在数据库中排除所有具有核泄漏事故历史的样本,然后采取随机选取的方式在数据库中剩余的反应堆样本里选取31个反应堆来组成第2组无核泄漏历史记录的样本。
在建立LRM之前,本文采用卡方检验方法(chi-squared method)测试各个独立自变量与应变量的显著性水平[10-11]。具体步骤为从建立最简单的只含有一个独立自变量的模型开始到最复杂的含有所有独立自变量的模型,利用ANOVA chi-squared测试方法检测每个模型之间是否产生显著性差别,判断各个独立自变量与应变量之间是否存在显著联系[12]。独立变量及其显著性水平对应的P值(显著性水平概率)见表2所列。
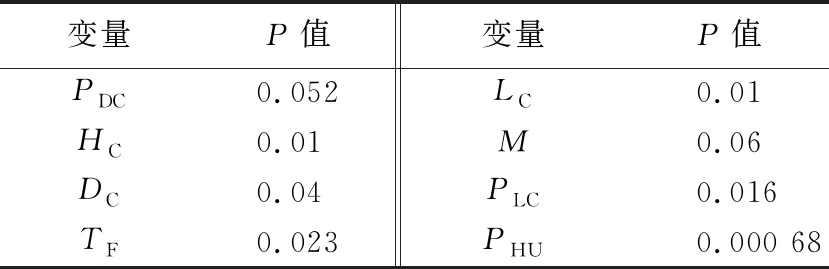
表2 独立变量与其显著性水平
从表2可以看出,每个独立自变量都与发生核泄漏之间存在潜在的联系。基于各个变量和P值,采取98%(P值小于0.02)和95%(P值小于0.05)2种显著性水平来建立模型。对于98%显著性回归模型,只在模型中采取P值小于0.02的独立自变量作为预测变量,即堆芯高度、冷却液类型、建造地理位置以及人为因素,而放弃P值大于0.02的独立自变量。同理,对于95%显著性回归模型,采取所有P值小于0.05的独立自变量作为预测变量,即模型中将包括除了设计能力和慢化剂类型的所有独立自变量。
在这以上2种具有不同显著性水平的模型中,样本反应堆的输出泄漏概率大于0.5将会被分类为发生核泄漏组,输出泄漏概率小于0.5将会被分类至无核泄漏发生组。使用Nagelkerke的R2值评估模型的精确度,即通过衡量模型样本预测分类成功的概率来衡量模型评估核泄漏发生风险的能力[13]。
2.2 线性判别模型
本文采取线性判别模型(linear discriminant model,LDM)的方法来评估预测核泄漏事故发生风险,不同于LRM,LDM同样有其优势与劣势。在本研究中,较小的样本容量(50个核反应堆)会导致LRM所产生的结果具有不稳定性[14]。而在LDM中,在每组样本数据中每一个自变量服从正态分布的假设前提下,可近似地认为该模型可以很好地解决这一问题[15],然而这也无法确定在每组样本数据中每一个自变量确实严格地服从正态分布。因此,LDM的存在确实带来了一个明显的权衡,即模型的稳定性与不确定性之间的取舍[16]。
对于建立的LDM,基于表2采取与LRM相同的2种显著性水平来考虑。对于自由模型,采取95%的显著性水平,模型中包含堆芯高度、堆芯直径、燃料类别、冷却剂类别,建造地理位置及人为操作作为独立自由变量。对于保守模型,采取98%的显著性水平,模型中仅包含堆芯高度、冷却剂类别、建造地理位置及人为操作作为独立自由变量。在二分问题中,与LRM类似采取50%作为既定观测值来区分样本。
2.3 支持向量机
基于LRM和LDM,采用支持向量机(support vector machine,SVM)的方法来学习并分类核反应堆样本。采取与前2个模型相同的显著性水平来建立SVM模型。不同的是在SVM中,采取径向核的方法来达到实现非线性边界决策的效果[17]。同时采取十折交叉验证的方法,即将样本容量均等分为2组,即每组25个样本个例,分别用其来训练模型和检测模型[18]。该方法可对每种显著性水平的SVM选取最佳的代价函数cost及径向核参数γ。
3 结果与预测分析
3.1 逻辑回归模型
3.1.1 逻辑回归的自由模型
在自由模型中,有堆芯高度、堆芯直径、燃料类别、冷却液类别、建造地址以及人为因素这6个预测变量可以达到95%的显著性水平,因此该模型中包含这6个预测变量。该自由模型公式为:
(1)
x=-18.08-0.22HC-0.91DC+0.71TF1+
9.76TF2+14.19TF3+0.001TF4+19.37LC1+
15.34LC2+22.81LC3-4.25PLC+6.52PHU
(2)
该模型的预测准确率为92%,具体预测结果见表3所列。该模型的R2值为0.76,P值为2.86E-05,模型具体信息见表4所列。

表3 LRM中自由模型预测结果

表4 LRM中自由模型计算结果
采用受试者工作特征曲线 (receiver operating characteristic curve,ROC)及其线下面积(area under the curve,AUC)来评估本文中出现的所有判别模型的预测能力。ROC曲线是根据一系列不同的二分类方式,以真阳性率(敏感度)为纵坐标,假阳性率(特异性)为横坐标绘制的曲线[19]。AUC是衡量模型优劣的一种性能指标,其越接近于1.0,分类方法真实性越高,等于0.5时,则真实性最低,模型无应用价值[20-22]。该自由模型的ROC曲线如图1所示, AUC值为0.953 1。
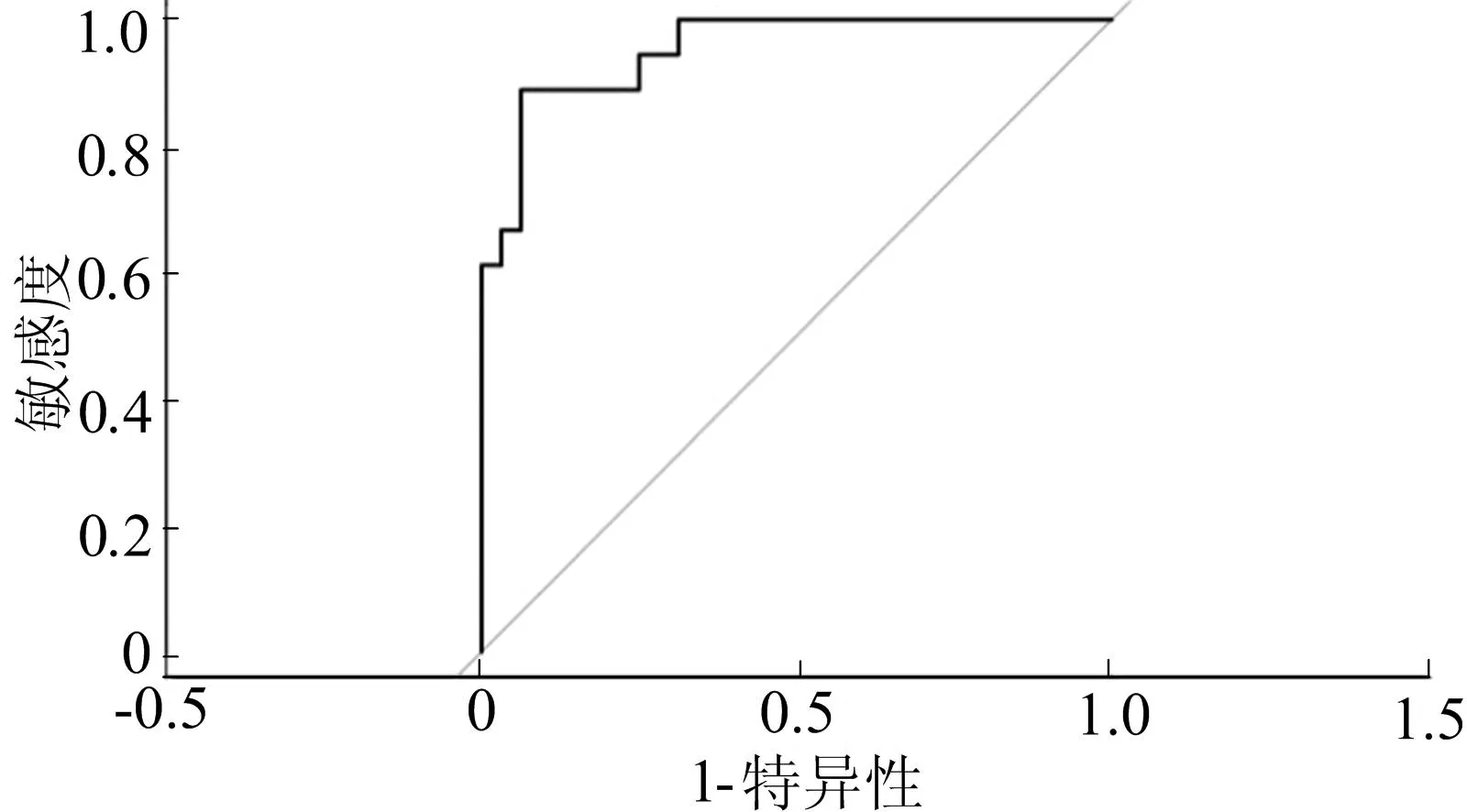
图1 LRM中自由模型的ROC曲线
3.1.2 逻辑回归的保守模型
在保守模型中,有堆芯高度、燃料类别、建造地址以及人为因素4个预测变量可以达到98%的显著性水平,因此该模型中包含这4个预测变量。模型公式为:
P/(1-P)=ey
(3)
y=-19.05-0.39HC+18.69LC1+
18.55LC2+21.64LC3-3.16PLC+4.79PHU
(4)
该模型的预测准确率为88%,具体预测结果见表5所列。该模型的R2的值为0.68,P值为6.41E-06,计算结果见表6所列。该保守模型的ROC曲线如图2所示,AUC值为0.946 2。
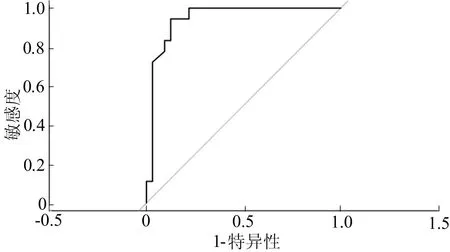
图2 LRM中保守模型的ROC曲线

表5 LRM中保守模型预测结果

表6 LRM中保守模型计算结果
3.2 线性判别模型
3.2.1 线性判别的自由模型
在线性判别的自由模型中,先验概率值πk通过训练模型数据部分计算得出,核泄漏组和无核泄漏组πk值依次为0.36、0.64。在LDM中,假设每个预测变量都近似地服从高斯分布。高斯分布的系数平均值μk、方差σ2可由样本数据来预估得到。线性判别模型中利用这些预测变量的高斯分布信息构建。在线性判别过程中主要步骤分为抽取步骤和分类步骤。
在抽取步骤中,输入的预测变量线性组合形成判别式隐藏变量。该模型中相关预测变量的系数及判别式系数分别见表7所列。具体的2组数据的判别结果如图3所示。从图3可以看出,在每组中判别式的分布差别较大,表明该模型可较好区分2组数据。
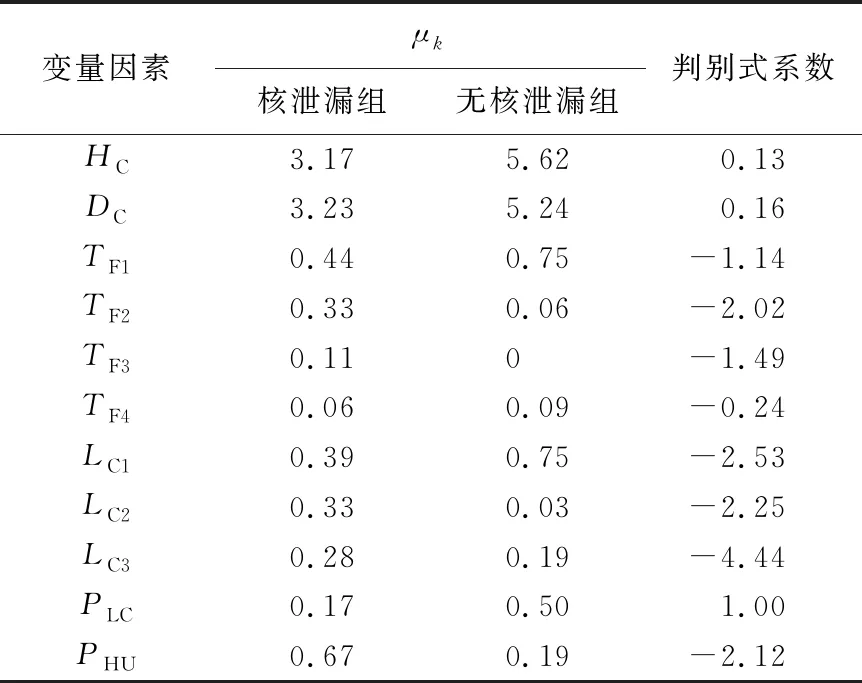
表7 预测变量的μk和判别式系数
自由模型的预测准确率为86%,具体预测结果见表8所列。自由模型的ROC曲线如图4所示,AUC值为0.960 1。
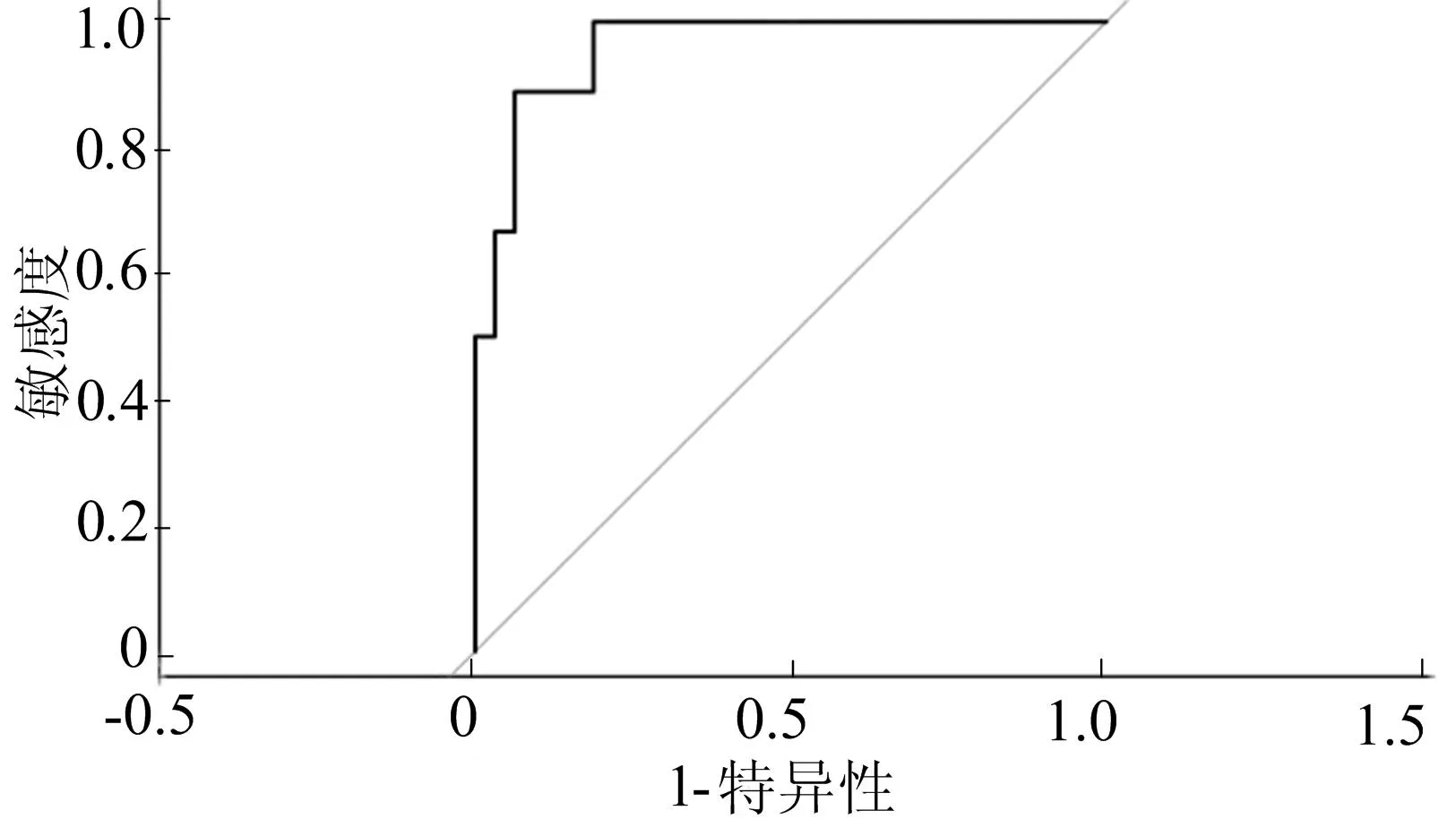
图4 LDM中的自由模型ROC曲线

表8 LDM中自由模型预测结果
3.2.2 线性判别的保守模型
保守的线性判别模型只包含堆芯高度、冷却液类别、建造地址与人为因素4个预测变量。该保守模型的样本先验概率值πk与自由模型中的先验概率值相同,先验概率及保守模型判别式系数见表9所列。
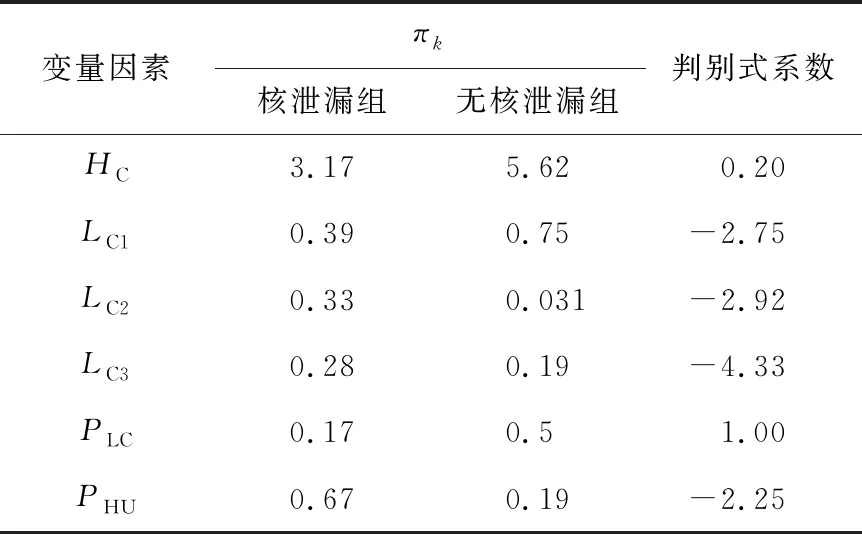
表9 预测变量的πk和判别式系数
LDM中的保守模型判别结果如图5所示。保守模型的预测准确率为88%,具体预测结果见表10所列 。

图5 保守模型的线性判别式

表10 LDM中保守模型预测结果
ROC曲线如图6所示,AUC值为0.941 0。

图6 LDM中的保守模型ROC曲线
3.3 SVM
3.3.1 支持向量机的自由模型
在SVM的自由模型中,同样包含与前面所有自由模型相同的6个预测变量。在SVM模型建立过程中,把50个样本核反应堆均等分为训练模型部分和检验模型部分。利用十折交叉验证的方法,SVM自由模型最佳参数选择代价函数cost取5,径向核参数γ取1。SVM中的自由模型在检验数据下的ROC曲线如图7所示,该曲线与横坐标之间的面积为0.618 1。利用检验数据计算得出模型的预测精确度为68%。自由模型的预测结果见表11所列。

图7 SVM中的自由模型ROC曲线

表11 SVM的自由模型的预测结果
3.3.2 支持向量机的保守模型
在SVM的保守模型中,预测变量的数量减少为4个。同样利用十折交叉验证的方法,选择的最佳参数代价函数cost取1,γ径向核参数取1。SVM中的保守模型在检验数据下的ROC曲线如图8所示,AUC为0.611 1。利用检验数据计算得出该保守模型的预测精确度为84%,高于自由模型。SVM的保守模型预测结果见表12所列。

图8 SVM中的保守模型ROC曲线

表12 SVM中保守模型预测结果
4 讨 论
4.1 重要影响因素
通过统计模型的构建,确定影响核泄漏事故的重要因素。对比自由模型与保守模型可看出,在核泄漏事故中,堆芯高度、建造地理位置及人为因素是影响事故发生的重要因素。值得注意的是,在自由模型和保守模型中,堆芯高度的让步比均小于1,表明此预测变量与核泄漏事故发生风险之间可能存在负相关的关系。
另一个重要的影响因素是人为因素。在所有模型中,人为因素与核泄漏事故发生风险均存在非常明显的正相关关系:在越有可能发生人为操作失误的样本中,发生核泄漏事故的风险越大。人为因素也可能会是主导所有其他因素并成为影响核泄漏事故发生的唯一因素。尽管在样本核反应堆中,有一些未发生过核泄漏事故的样本也存在人为操作失误的历史记录,但这并不妨碍人为操作失误可以直接导致核泄漏事故发生这一结论。同时,基于LRM发现人为操作这一预测变量的让步比大于1,P值较小,说明在本研究中,人为因素可覆盖其他所有预测变量的趋势并有可以单独主导核泄漏事故发生的可能性。即使增大样本大小,人为因素与核泄漏事故之间联系的强度不会改变,依然可能是影响核泄漏事故发生的最重要因素。
4.2 模型不确定性分析
文中模型潜在的不确定性主要来自样本数据,样本数据的大小偏小。虽然历史上发生核泄漏事故的次数较多,但关于这些核泄漏事故的详细历史记录较少,因此极难囊括所有的核泄漏事故并把它们全部都用在此研究样本中。尤其在LRM中,较小的样本数量可能会在构建该模型时造成误差,因此LRM的精确度会随着样本数量的增加而变得更为精确。另外,在样本反应堆中,采用现阶段不同运行状态的核反应堆。这些不同运行状态的核反应堆样本会在一定程度上给模型结果带来不确定性。例如,将正在安全运行的核反应堆样本完全归为安全的无核泄漏事故发生的核反应堆样本是不严谨的。核泄漏事故是一种一次性事件,不能被看作反应堆内部的自有特性,因此不会发生核泄漏事故与目前还没有发生核泄漏事故是不能完全等价的。也就是说,对于这些目前还没有发生核泄漏事故的“干净”的核反应堆样本,其在未来依然有发生核泄漏事故的风险,尽管概率很低。从另外一个角度来诠释这一样本不确定性,发生核泄漏事故可被视作为一个核反应堆的内在“基因”,一些样本核反应堆已经展示出了此“基因”,另外一些样本核反应堆在现阶段还没有展示出此“基因”,但并不能完全排除其没有易发生核泄漏事故的“基因”。然而,本文研究的是评估一些列核反应堆的内在、外在属性与其发生核泄漏事故“基因”之间的内在联系,却使用这些样本的外在表现来代表其内在发生核泄漏事故“基因”,这必然会给模型结果带来不确定性。此外,本文对预测变量之间存在的关联性进行探讨,以日本的核反应堆为例,由于日本倾向于建造沸水型反应堆(boiling water reactor,BWR),采取的来自日本的核反应堆样本倾向为BWR,这些样本均有很相似的燃料类型、冷却液类型以及慢化剂类型等特性。由于日本国的国土面积较小,在靠近海岸线的位置建造核反应堆是不得已选择,会大大增加核反应堆受到海啸或者地震影响而发生核泄漏事故的概率,从而在一些样本核反应堆中,可以很明显得到预测变量之间的关联性。预测变量之间的关联性如图9所示。
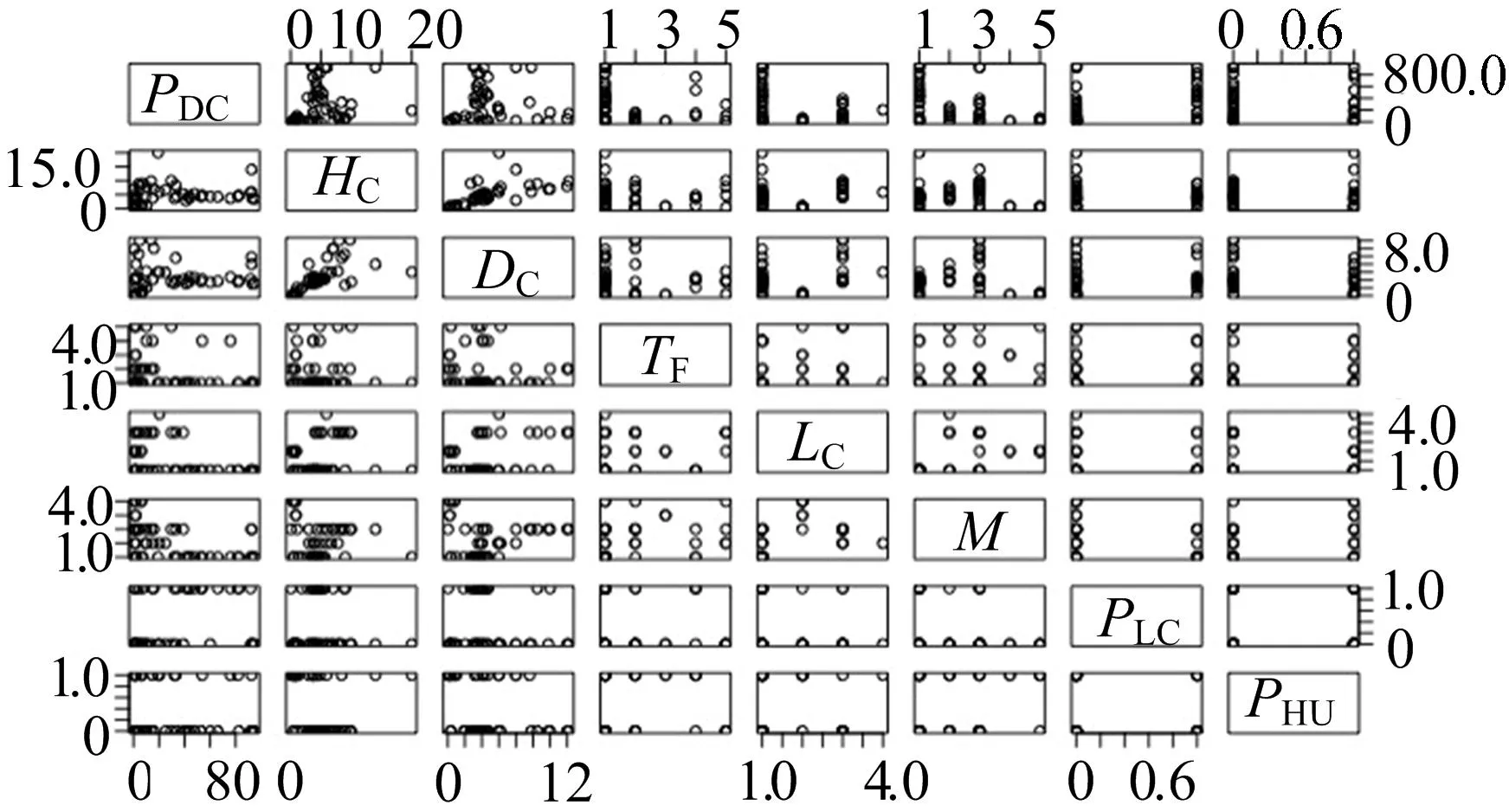
图9 预测变量之间的相关性
根据以上分析,本文所建立的LRM和与LDM均由相同的一组数据训练和测试,LRM和与LDM中的预测准确性就是样本数据的训练误差。因此对于这2种模型,当其被用于预测一组新的数据时,模型所产生的真实的预测准确性要低于上述所报道的预测准确性。此外本文所建立的SVM的预测误差要大于LRM和LDM,说明这2种模型在预测新的数据时可能会产生大于本文所报道的预测误差的结果。
4.3 模型对比
本文6种模型的预测准确率对比见表13所列。对比自由模型与保守模型发现,保守模型的预测准确率要大于自由模型的,除了LRM的情况。对比不同模型的预测能力发现,LRM的预测准确率要强于其他2种判别模型。总体来看,3种不同模型类别均具有基本预测核反应堆发生核泄漏事故风险的能力。

表13 模型的预测准确率对比 %
另外一种直观地对比3种不同类型模型的预测能力的方法就是通过比较ROC曲线的AUC。3种自由模型与保守模型的ROC曲线对比分别如图10、图11所示。
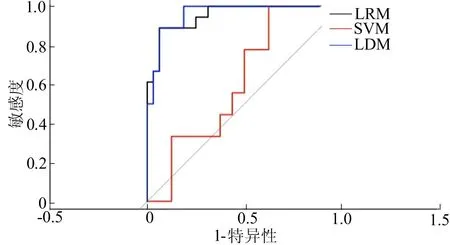
图10 自由模型的ROC曲线对比

图11 保守模型的ROC曲线对比
由图10、图11可知,LRM和LDM的预测能力均比SVM更精确,然而SVM有最接近真实值的预测准确性,因此也是解决这一类问题非常好的的模型类别,尤其考虑到该风险评估系统的非线性特征。
5 结 论
本文通过构建概率统计分析模型探究核反应堆中的内部和外部因素与核泄漏事故之间的关联性,并对核泄漏风险的影响因素进行评估。通过对3种不同模型研究并预测核反应堆发生核泄漏事故风险的安全评估能力。利用样本中的训练数据组与检测数据组构建3种不同概率统计分析模型并检测其预测能力。LRM中自由模型的预测准确率为92%,保守模型的预测准确率为88%;LDM中自由模型的预测准确率为86%,保守模型的预测准确率为88%;SVM中自由模型的预测准确率为68%,其保守模型的预测准确率为84%。
通过构建并比较3种不同类型的概率统计分析模型发现,核反应堆内部和外部因素均会影响核泄漏事故发生的安全风险。但在这些影响因素中,外部因素比内部因素更具有支配地位,并在整个评估体系中起主要作用。此外,虽然LRM和LDM在预测计算方面相较于SVM更加精准,但其仍然没有SVM在这个风险评估体系中更加适用,原因是该风险评估体系是非线性的。
猜你喜欢
科学大众·教师版(2021年7期)2021-08-03
文学教育下半月(2020年5期)2020-06-08
都市生活(2019年1期)2019-05-04
辐射防护通讯(2019年3期)2019-04-26
载人航天(2016年4期)2016-12-01
核技术(2016年4期)2016-08-22
焊接(2016年1期)2016-02-27
核科学与工程(2015年3期)2015-09-26
核科学与工程(2015年2期)2015-09-26
核科学与工程(2015年2期)2015-09-26
