
结合出行方式的Trans-BiLSTM移动目标位置预测方法
2024-03-05 01:41姚子宣冉义兵
小型微型计算机系统 2024年3期
姚子宣,魏 东,冉义兵
(北京建筑大学 电气与信息工程学院,北京 100044)
(建筑大数据智能处理方法研究北京市重点实验室,北京 100044)
0 引 言
近年来,随着科技和社会的进步,人们生活水平逐渐提高,通信技术和定位技术也在飞速发展,具有全球定位系统 (GPS)功能的便携式设备得以普及,获取大量高精度GPS轨迹数据变得更方便和快捷,人类的日常活动产生的大量轨迹数据,为基于位置的服务(LBS,Location Based Services)提供了数据支撑.基于位置的服务在推荐系统[1]、目的地预测[2]、辅助城市规划[3]等场景均有应用.其中位置预测是基于位置的服务的重要组成部分,是上述应用场景的重要技术支撑,如何精准、高效地进行基于GPS轨迹数据的位置预测是目前的研究热点之一.
目前,研究人员普遍认为位置预测的本质是从历史轨迹中挖掘目标的运动规律,并以此为依据给出目标下一个可能出现的位置.其研究成果主要分为三类:基于马尔科夫链[4,5]、基于频繁模式挖掘策略[6,7]和依赖循环神经网络的位置预测模型[8,9,11,12].
在位置预测研究中,马尔可夫链是较为经典的算法,其核心是提取历史轨迹中的关键位置并获取其访问概率,从而构建位置转移矩阵,最终计算得到的预测结果为目标访问概率最大的位置.文献[4]首先采用聚类算法从历史轨迹中提取出个人经常访问的位置,然后再构建模型进行位置预测,判断人员可能到访的位置.文献[5]在文献[4]的基础上采用了基于密度的聚类算法,并考虑预测结果与前序多个位置的相关性,在不同的真实数据集上进行测试,获得仅考虑前序2个位置时效果最佳的结论.上述两种方法并未考虑目标访问同一位置时的时间因素,在不同时间访问同一位置的意义不同,将影响预测结果的准确性.
目标的移动模式具有一定规律,可以采取频繁模式挖掘策略,从历史轨迹中获取目标移动的频繁模式,进而提高预测准确率.文献[6]在预测目标下一位置时,首先确定与当前运动模式最匹配的历史模式,再预测目标的下一位置.文献[7]通过引入并行计算的方法提高频繁模式挖掘的预测效率.上述两种方法考虑了目标移动的实际意义,提升了预测准确率,但是频繁模式挖掘方法需要遍历全部数据集,时间复杂度高.
全球定位系统(GPS,Global Positioning System)轨迹是时间序列数据的一种,循环神经网络(RNN,Recurrent Neural Network)已广泛应用于时间序列数据预测.文献[8,9]均提出了基于RNN的位置预测模型.前者考虑了时间因素对预测结果的影响,在预测时引入时间特征,可以预测移动目标出现在预测位置的时间.后者在此算法基础上添加降维模块,以提高模型应用在更长轨迹上的运行效率和准确率.
受制于RNN无法捕获序列的长时间依赖关系的建模原理,轨迹数据序列较长时,预测结果受输入序列中后序位置的影响大,与前序位置几乎无关联,影响预测结果准确性.文献[10]在RNN的基础上增加筛选门机制构建长短期记忆网络(LSTM,Long Short-Term Memory),通过筛选输入和历史状态来保障模型具备传递长时依赖关系的能力.然而,较长的轨迹数据使得神经网络需要处理高维的输入向量,导致模型效率降低.文献[11]在LSTM基础上引入位置分布式表示模型,将包含人员运动模式的高维one-hot向量降维成低维位置嵌入向量,在较长轨迹数据序列输入的情况下提高了模型效率,并取得了更优的结果.此外,对于实际应用,轨迹数据中关键位置对预测结果应有更高的影响权重.而基于LSTM的位置预测模型,其输入是同权重的顺序序列,在降维后会产生细节丢失的问题,使得模型无法充分利用上下文信息发掘轨迹中的关键位置.文献[12]采用双向长短期记忆网络(BiLSTM,Bi-directional Long Short-Term Memory),利用航速、经度、纬度和航向等属性对不同类别的舰船航迹进行预测,在预测精确度和预测稳定性两个方面均得到提高.
尽管BiLSTM为轨迹预测提供了新的方法,并在某些方面取得了显著的进步,但其仍然存在一些局限性.首先,BiLSTM虽然能够捕获序列中的前向和后向信息,但在处理长序列数据时,仍可能出现部分上下文信息的丢失.此外,BiLSTM在对长序列的输入处理上仍然面临计算效率和模型复杂度的问题.Transformer模型,尤其是自注意力机制,为解决上述问题提供了新的思路[13,14].该机制能够为序列中的每个元素分配不同的权重,从而确保模型能够更加聚焦于关键的上下文信息,而非均匀地处理整个序列.此外,Transformer的并行化处理能力使其在处理长序列时具有更高的计算效率.文献[15]中提出GETNext模型采用图卷积神经网络计算兴趣点嵌入后的时空信息,并通过Transformer模型进行预测下一时刻兴趣点,结果表明Transformer模型在处理时间序列数据方面,更容易捕获前后信息的依赖关系.因此,在位置预测领域,Transformer模型的引入可以使模型发掘轨迹数据中的关键位置,从而提高模型性能.
用户的出行方式对轨迹预测有显著的影响.然而现有研究在位置预测过程中往往忽略用户出行方式的关键作用,同时在处理长时间序列依赖问题中效果较差.基于此,本文提出了一种融合Transformer和BiLSTM的位置预测模型.首先构建基于XGBoost的用户出行方式识别模型,从中挖掘与出行方式相关的重要特征,这些特征与轨迹序列共同构成预测模型的输入数据.然后设计预测模型Trans-BiLSTM,它依赖Transformer的能力有效地处理长时序依赖关系,模型内部的多头注意力机制使得重要数据点在预测结果中有更大的影响,同时借助BiLSTM双向传播机制,弥补目标位置预测需要先验知识的缺陷,从而在轨迹预测任务中更好地学习长距离依赖关系,提升轨迹预测的准确率.
在现实GPS轨迹数据集上进行目标位置预测,实验结果表明,本文所提出的Trans-BiLSTM模型取得了较好效果,与常用LSTM和BiLSTM模型相比,目标位置预测的结果RMSE指标提升67.4%和17.7%.
1 模型框架概述
本文目标位置预测模型分为3个步骤,轨迹数据预处理与特征提取、XGBoost特征筛选和Trans-BiLSTM目标位置预测模型,整个模型流程图如图1所示.

图1 模型流程图Fig.1 Model flow chart
1)轨迹数据预处理与特征提取:首先对历史轨迹进行去重和过滤,再根据时间阈值进行分割.由于过短的轨迹无法提供充足的训练样本,因此需要按照轨迹长度筛选去除过短的轨迹.之后提取轨迹中的时空特征并计算出行方式的运动学特征,便于模型学习目标的日常移动模式.
2)XGBoost特征筛选:训练XGBoost模型对输入特征进行重要性排序,筛选出影响出行方式的主要特征,将用户出行方式特征与轨迹序列一并作为预测模型的输入,进而提高目标位置预测精度.
3)Trans-BiLSTM目标位置预测模型:在结合用户出行方式的基础上,本文采用Transformer编码器和BiLSTM模型[16]组合的方式对轨迹数据进行目标位置预测.Transformer的编码器部分通过位置编码和多头自注意力机制处理轨迹特征数据,输出编码后的高级轨迹特征表示.其中,多头自注意力机制通过计算后一个隐层状态向量与前序隐藏状态向量间的相似度,更新权重的方式对新的隐层状态向量序列进行加权,挖掘轨迹中对预测结果影响权重较大的特征属性.Transformer的高级轨迹特征表示作为BiLSTM的输入,BiLSTM模型在LSTM模型基础上构建,引入双向传播机制充分利用轨迹中的位置上下文信息,使模型具有更强的预测精度.
2 位置预测模型
2.1 轨迹预处理与特征提取
GPS轨迹数据属于时序数据类别,由GPS装置在固定的时间间隔中记录,其涵盖了位置的纬度和经度信息以及时间细节等.后续叙述中Ti代表一段轨迹,pi代表轨迹中的一个位置点,loni,lati,ti分别代表轨迹点的经度、纬度和记录时间.历史轨迹是一个轨迹集合T={T0,T1,T2,…,Tn},其中一段轨迹是一个点集合T={p0,p1,p2,…,pn},其中每个位置是一个三维向量pi=(loni,lati,ti).历史轨迹数据中包含多段轨迹,这与每次采集的周期有关.
2.1.1 数据去重与过滤
原始GPS数据由于采集设备在受到外部干扰时会产生重复值和异常值,此类数据会对特征提取的准确性及位置预测的精确度造成影响.因此,必须对原始GPS数据进行去重和清洗操作.
原始GPS数据存在两种主要的重复情况,第1种是GPS轨迹数据中的轨迹点具有相同的时间戳,对于这种情况,本文采用遍历对比的方式找到时间戳重复的轨迹点,仅保留此时间戳对应的第1个轨迹点.第2种是不同轨迹段存在时间重叠情况,即一段轨迹的时间跨度内含有另一轨迹段的时间戳,并且重叠时间里的出行方式是不同的,从而影响轨迹分割,此时应删除重叠时间内的轨迹点,保证每条轨迹的时间段不存在重叠情况.
异常值是由于采集设备受干扰而产生与实际位置不符且偏移量大的轨迹点.此类轨迹点会使目标的运动学参数异常,如步行轨迹段中出现瞬时速度、加速度过大的值,与实际情况不符,故需标识并排除,在去除后进行插值补充.此处阈值设定基于实验经验,详见表1.插值补充取异常轨迹点前后两点的中值,计算方法如式(1)所示:
(1)

表1 运动学参数阈值Table 1 Kinematic parameter threshold
2.1.2 轨迹分割与特征提取
为了构建位置预测模型,需要学习移动对象在一定周期内的出行方式,这就要求对历史轨迹进行分割.本文按照时间阈值将轨迹进行分割,如果历史轨迹中前后两点(pk,pk+1)的时间间隔(tk,tk+1)大于时间阈值△t,则认为pk为前一段轨迹的终点,pk+1为下一段轨迹的起点.若经过分割后的轨迹段内轨迹点数量过少,则表明目标移动的持续时间短,无法准确反映移动目标的出行方式,故需要删除此段轨迹.
目标的移动模式具有一定的规律性,在不同的时间经过相同的位置时,其实际情况的含义有所不同.所以在进行位置预测任务时,本文提取GPS轨迹中的经纬度和时间作为基础特征,将其转化为向量后可以直接作为神经网络的输入.本文所提出的位置预测模型首先识别轨迹段的出行方式,那么需要提取轨迹段的运动学参数作为出行方式识别的特征.出行方式特征包括轨迹点特征和轨迹段特征.GPS轨迹可视化如图2所示.

图2 轨迹可视化示例Fig.2 Track visualization example
轨迹点特征包括速度、加速度和偏转角.在进行出行方式提取时,首先需要得到两个轨迹点间距离L,再获取两点间时间差△t,最后计算速度v与加速度a.计算公式为:
(2)
(3)
其中R为地球直径.
每两个轨迹点航向差的绝对值为偏转角Di,其中航向Hi指每个轨迹点和下一点连线与真北方向的方向角,计算公式如式(4)所示:
Di=|Hi+1-Hi|
(4)
轨迹段特征通过对轨迹点特征应用统计学方法计算得出,用以表述此段轨迹整体的运动学参数,减少极端值对识别结果产生的影响,其中包括此段轨迹中轨迹点特征的平均值、标准差、众数、值域、最大三值和最小三值,分别用于表述轨迹段内运动学参数的集中趋势、离散程度、极值等信息,共计30个.
本文引入航向变化率、停止率和速度变化率[17]3个特征,以更好地区分目标的出行方式.航向变化率HCR(Heading Change Rate)表述移动目标航向变化超过Ht的频率,Ht设为19°.停止率SR(Stop Rate)表示移动目标的速度低于Vs的频率,Vs设为3.4m/s.速度变化率VCR(Velocity Change Rate)体现移动目标速度变化大于Vc的频率,Vc设为0.26m/s.计算公式如式(5)~式(7)所示:
(5)
(6)
(7)
此外,出行方式通常会决定目标的出行距离,因此轨迹长度也属于轨迹段特征之一.
综上所述,轨迹段特征包含34项,即出行方式识别模型的输入向量的维度为34.
2.2 基于XGBoost的出行方式特征筛选
在预测用户位置时,只关注轨迹序列显然是不够的,考虑到用户出行方式对位置预测的重要意义,因此构建基于XGBoost的出行方式识别模型,筛选对出行方式具有显著影响的特征集,作为预测模型的出行方式表征向量.
2016年,文献[18]提出XGBoost算法.它是一个优化的分布式梯度增强框架,在模型的训练过程中,逐步通过决策树达到优化目的,进而求取最优解.XGBoost本质上是加法模型,其计算公式为式(8)
(8)
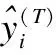
决策树在考虑某个节点进行分裂时,XGBoost将评估所有可能的分裂特征和其对应的分裂节点.对于每个分裂,都将计算其带来的目标函数的信息增益.分裂增益计算公式为式(9):
(9)
其中,GR和GL分别表示左右子节点的梯度总和,而HL和HR是它们的二阶梯度总和.λ和γ是正则化参数.
根据模型训练过程可将式(8)展开,当前积累的树由前T-1颗树加上当前第T颗树,公式为式(10):
(10)

(11)
(12)

XGBoost模型在训练过程中为特征赋予了重要性分数,这使得它能够用于特征选择.在决策树中,特征的重要性是通过多个方面进行评估的:特征被选为分割节点的频率,使用某特征进行分割带来的训练损失的平均减少,以及该特征分割影响的观测值数量.结合这些评估指标,可以对模型的特征进行相关性排序.
如图3所示是轨迹特征数据与出行方式之间的相关性得分.为了更清晰地展示结果,图中只显示了排序的前20个特征.此外,为了探究特征数量对预测模型结果的影响,本文依次选取不同数量的特征与轨迹序列一并作为预测模型的输入.如表2所示是不同特征数与MAE的关系.

表2 不同特征集的平均绝对误差Table 2 Average absolute error of different feature sets

图3 特征重要性排序结果Fig.3 Feature importance ranking results
由表2可知,特征维度为8时MAE最低,因此选定前8个特征作为出行方式最相关的特征,分别为航向变化率、速度下四分位数、速度均值、速度四分位差、停止率、速度变化率、速度上四分位数.
2.3 Trans-BiLSTM预测模型
本研究提出一种结合Transformer和BiLSTM优势的位置预测模型.一方面,Transformer编码器处理强规律性的文本数据具有独特优势,其内部多头注意力机制先评估隐层状态与先前状态的相似度,经过标准化后,生成多个权重向量度量每个时序数据点的重要性.另一方面,BiLSTM模型采用双向传播,弥补了目标位置预测需要先验知识的缺陷,使模型学习到轨迹数据前后之间的关联.因此,结合Transformer编码器和BiLSTM模型,可以构建一个更加高效和准确的时序预测模型,模型的结构如图4所示.
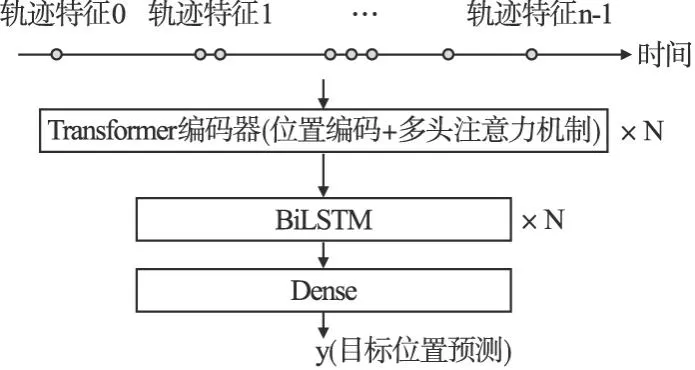
图4 Trans-BiLSTM结构图Fig.4 Trans-BiLSTM model structure diagram
2.3.1 Transformer编码器
轨迹数据经过轨迹预处理和特征提取,获取到对目标位置预测较敏感的多维特征,多维特征数据整合存储为.csv格式文件.通常用户均带有明确目的前往目标位置,途经的位置很大程度上由用户所在城市的固有路线决定,并且轨迹数据特征具有时间序列的前后位置关系.因此,采用自然语言处理算法不仅可以有效处理较强规律性的轨迹特征,而且通过位置嵌入的编码方式能够计算前后目标位置的表征向量,类似于文本的上下文语义感知.本文采用Transformer的编码器部分依次进行轨迹特征数据的位置编码和多头自注意力机制处理,模型结构如图5所示.

图5 Transformer编码器Fig.5 Transformer encoder
位置编码使用正弦和余弦函数来编码位置信息.由于Transformer编码器没有明确的顺序感知能力,需要通过位置编码来获取轨迹序列的前后信息.对于序列中的每个位置,位置编码器会生成一个固定大小的向量,其中每个维度对应一个不同频率的正弦或余弦函数,不同位置的编码向量在空间上具有不同的角度,从而能够表达它们之间的相对位置关系.位置编码的公式如下:
PE(pos,2i)=sin (pos/100002i/dmodel)
(13)
PE(pos,2i+1)=cos (pos/100002i/dmodel)
(14)
其中,pos表示位置,i表示维度索引,dmodel表示模型的维度.
每个目标位置生成的位置编码向量与轨迹特征向量对位相加,输入到多头自注意力机制层.通过引入位置编码,模型能够利用位置信息描述轨迹特征之间的依赖关系和顺序关系.

(15)
多头注意力机制在计算注意力时,允许模型共同关注来自不同位置的不同表示的信息.带有h个注意力头的计算公式如式(16):

(16)
其中,fC(·)是合并h个注意力头输出的全连接层,Atti(Q,K,V)表示第i个头的自注意力.然后多头注意力的输出MultiHeadAtt(Q,K,V)经过Add &Norm层和前馈神经网络层输出更新的轨迹特征向量.Add &Norm层的计算公式如式(17):
LayerNorm (X+MultiHeadAtt (X))
(17)
其中,X和MultiHeadAtt(X)分别表示多头注意力层的输入和输出向量,输入和输出的维度相同,进行残差连接,用于解决多层网络训练的梯度消失问题,让网络关注全局和局部的特征向量,残差结构如图6所示.LayerNorm()函数会将该层神经元的输入转成均值方差,以加快收敛.

图6 残差模块图Fig.6 Residual block diagram
最后,由前馈网络层输出编码后的特征表示,该层由两层全连接层组成,第1层的激活函数为Relu,第2层不使用激活函数,计算公式如式(18)所示:
FFN(X)=max(0,XW1+b1)W2+b2
(18)
其中,X表示输入,W1、W2为权重,b1和b2为偏置.
最终,前馈神经网络层FFN(X)输出编码后的轨迹特征表示,且输出矩阵的维度与X一致.
2.3.2 多层BiLSTM网络
传统的LSTM模型通过门控机制选择性吸收历史信息以解决长序列数据依赖情况,避免了模型梯度消失或爆炸问题.通常LSTM模型根据输入,已知当前时刻和之前时刻的轨迹信息,而对于未来的轨迹位置信息一无所知,因此无法关联轨迹序列前后时刻的紧密的信息.为解决此问题,本研究在LSTM的基础上融合了双向传播策略,从而构建了BiLSTM.模型结构如图7所示.

图7 BiLSTM结构图Fig.7 BiLSTM structure diagram

(19)
(20)
(21)
BiLSTM通过双向信息流的策略考虑到了前后时间点的状态对结果的作用,从而允许网络在进行位置预测时充分利用位置序列中的前后依赖关系.
3 实验研究
3.1 数据集
本研究选用源于微软亚洲研究院GeoLife项目的GPS轨迹数据进行实验研究.这一数据集在基于地理位置的服务、用户行为模式分析等多个学术领域已得到广泛运用[17,19,20].这些GPS轨迹由一系列带有时间戳的点组成(详见表3),其中每个点都包含纬度、经度以及海拔的相关信息.本研究仅采用纬度、经度和时间进行实验分析.

表3 轨迹数据示意Table 3 Track points contain information examples
实验平台采用主频为3.6Ghz的英特尔i9 CPU及32GB内存,和支持计算加速功能的图灵架构GPU.模型代码调用了标准pytorch框架和sklearn库.
3.2 评价指标
目标位置预测常被视为多分类任务问题,而本研究的预测输出是实际地理坐标,故将其视作回归任务进行处理.为了评估模型预测与真实地理位置之间的偏差,采用了平均绝对误差(MAE)、平均平方误差(MSE)以及方均根误差(RMSE)作为评价指标.鉴于测试数据涵盖了多条轨迹,模型的最终评价指标是基于所有测试结果的均值得出的.相关计算公式如式(22)~式(24)所示:
(22)
(23)
(24)
3.3 实验结果与分析
3.3.1 预测模型参数设置
在神经网络模型中,隐层节点数(hidden_dim)对网络的复杂性、训练速度和学习表现有直接影响.模型隐层节点过少会导致欠拟合,反之模型隐层节点过多会产生过拟合问题,即模型在训练集效果好但在测试集效果差.模型中学习率(learning_rate)决定了网络权重每次更新的步长.设置得过小会导致权重的调整缓慢,而过高的学习率可能使权重难以稳定地收敛,降低预测准确率.因此,为确保模型具有较好的训练速度,本文对多组预测模型超参数设置进行了验证和调优,隐层节点数量和学习率对模型的性能影响分别如图8、图9所示.

图8 隐层节点数量对模型的性能影响Fig.8 Effect of the number of hidden_dim on the performance of the model

图9 学习率对模型的性能影响Fig.9 Effect of learning_rate on model performance
从图8可以观察到,当隐层节点数量设置为128时,模型表现最为优越.然而,隐层节点数量为64时的性能与前者相近.因此,综合考虑模型的训练效率与性能表现,本研究中隐层节点数量设置为64.由图9可知,学习率为1e-3时,模型的3个指标最低,即模型预测的精度最高,因此本文选择学习率为1e-3.
基于上述分析结果,模型超参数设置与说明如表4所示.

表4 超参数设置与说明Table 4 Setting and explanation of hyperparameters
多组预测模型的超参数包括轨迹分割时间阈值、轨迹点数阈值、隐层节点数、批量训练数据大小、训练轮次、早停法参数、学习率等.
3.3.2 位置预测算法对比分析
本文将所提出的Trans-BiLSTM目标位置预测模型与RNN、GRU、LSTM、BiLSTM、Trans-LSTM、Trans-BiLSTM模型进行对比实,对比实验结果如表5所示,多组模型MSE随训练步数(Training Steps,每一个epoch具有训练样本总数/ batch_size个训练步数)变化如图10所示.

表5 模型性能对比Table 5 Model comparison results
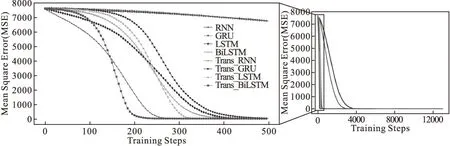
图10 模型对比结果图Fig.10 Result graph of model comparison
首先,根据表5发现LSTM模型相比RNN和GRU模型的目标位置预测结果明显更好,其中GRU模型效果略好于RNN模型.从图10可以看出,RNN和GRU模型的MSE曲线收敛速度相比其他模型较慢,而LSTM模型训练轮次仅需要33轮即可获得较优效果.实验表明,LSTM模型在处理轨迹时间序列数据方面具有计算效率高的优势.
其次,对比BiLSTM模型与LSTM模型、Trans-BiLSTM模型与Trans-LSTM模型的性能,BiLSTM和Trans-BiLSTM模型在引入双向传播机制后,其性能表现优于LSTM和Trans-LSTM模型,其目标位置预测的RMSE指标值分别提升了60.3%和51.2%,模型的MSE曲线收敛速度也有较大提升,训练的轮次分别多10和6轮次.实验表明,通过双向传播机制提取轨迹数据上下文关联信息的方式,虽然耗时稍多,但在目标位置预测模型中发挥了重要作用.
再次,对比Trans-RNN模型与RNN模型、Trans-GRU模型与GRU模型、Trans-LSTM模型与LSTM模型,以及Trans-BiLSTM和BiLSTM模型的性能,发现在模型中引入Transformer编码器,4组对比实验模型的RMSE指标分别提升了7.7%、1.4%、33.2%、17.7%.同时,Trans-RNN模型和Trans-GRU模型在RMSE指标上没有取得明显提升,但在模型效率方面均提升了一倍左右,模型的训练轮次和MSE曲线收敛速度获得明显优化.Trans-LSTM模型和Trans-BiLSTM模型的RMSE指标提升幅度较大;这两种模型的初始训练MSE曲线收敛速度较慢,但是随着训练迭代次数的逐渐增多,以上两种模型的收敛速度明显超越了原始LSTM模型和BiLSTM模型.实验表明,模型引入Transformer编码器能够较好地处理较强规律性的轨迹特征,其中位置编码能够计算前后目标位置的表征向量,多头自注意力机制能够筛选掉对网络权重更新贡献较小的特征输入,而增大对模型输出产生更大影响的输入权重.
最后,本文将所提出的Trans-BiLSTM模型分别与BiLSTM和Trans-LSTM进行对比.虽然Trans-BiLSTM模型相比BiLSTM和Trans-LSTM模型在训练轮次方面分别多3和6轮次,但相比RMSE指标方面分别提升了17.7%和51.2%.由图10可以发现,Trans-BiLSTM模型的MSE曲线收敛速度在初始阶段不如BiLSTM模型,但之后迅速收敛超越了BiLSTM模型.同时,Trans-BiLSTM模型的整体MSE曲线收敛效果优于Trans-LSTM模型.实验表明,所提出的Trans-BiLSTM对少样本数据敏感度欠缺,但是在处理大量具有上下文特征的轨迹数据方面具有明显优势,一旦提取到轨迹特征的上下文信息,MSE曲线便能迅速收敛,且目标位置预测的误差相比其他7个模型达到最低.虽然效率上稍有牺牲,但是在相同条件下Trans-BiLSTM模型具有更好的RMSE指标和收敛效率.
4 结束语
位置预测作为基于位置服务的核心环节,对于智能导航、位置推荐和路径规划等应用场景具有重要的技术支撑价值.其中,GPS轨迹数据是支持这些服务的关键数据源,因此,基于GPS轨迹数据的位置预测已成为学术界和工业界的关注焦点.
当前位置预测算法往往忽略用户出行方式的关键作用,并在处理长时间序列依赖问题中效果较差.针对这两个问题,本研究提出了一个结合出行方式的高效位置预测模型.在该模型中,首先对轨迹数据进行适当的分割,并从中提取出行方式的运动学特征.随后,采用基于XGBoost的方法识别出行方式,从中筛选出与出行方式紧密相关的关键特征.这些特征与轨迹序列数据共同作为预测模型的输入.为了充分挖掘轨迹中的深度上下文关系,融合了Transformer编码器和BiLSTM模型进行位置预测.Transformer模型内部的多头注意力机制使得重要数据点在预测结果中有更大的影响,借助BiLSTM双向传播机制,弥补目标位置预测需要先验知识的缺陷,从而在轨迹预测任务中更好地学习长距离依赖关系,提升轨迹预测的准确率.实验结果表明,所提出的Trans-BiLSTM模型取得了较好效果,与常用LSTM和BiLSTM模型相比,目标位置预测的结果RMSE指标提升67.4%和17.7%.
本文计划在后续的研究中进一步探讨位置的语义信息对预测效果的潜在影响.通过整合轨迹数据中的语义特征来增强位置预测模型的性能.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
现代装饰(2018年5期)2018-05-26
数学小灵通·3-4年级(2017年9期)2017-10-13
中国三峡(2017年2期)2017-06-09
