
面向联邦学习激励优化的演化博弈模型
2024-03-05 01:41孙跃杰赵国生廖祎玮
小型微型计算机系统 2024年3期
孙跃杰,赵国生,廖祎玮
(哈尔滨师范大学 计算机科学与信息工程学院,哈尔滨 150025)
0 引 言
深度学习技术蓬勃发展至今,能否获取足够的高质量样本数据是制约其发展速度的重要因素之一.由于数据安全、竞争关系等因素,获取数据过程中出现了严重的数据孤岛问题,并且在数据的集中过程中还存在数据泄漏的风险.因此联邦学习(Federated Learning,FL)作为新兴的分布式机器学习范式应运而生[1].它使得各个参与方可以在不泄露底层数据的前提下共同建立模型,适用于训练数据涉及敏感信息以及数据量过大无法集中收集的情况.然而,当客户参与联邦学习时,会不可避免的消耗他们的设备资源,同时客户也承担着一定的安全风险,因此对联邦学习激励机制的研究一直是当下的热点.
区别于博弈论的一次直接达到纳什均衡,演化博弈论的行为主体在演化过程中会动态修正自己的行为,在多次博弈之后达到均衡.据此而建立的联邦学习激励机制更切合实际并且更加有助于联邦的长期稳定发展.
本文将演化博弈中的“适者生存”的基本思想运用到联邦学习当中,将演化稳定策略(Evolutionary Stabilization Strategies,ESS)与复制动态方程(Copy Dynamic Equations,CDE)相结合,提出了一种演化均衡的联邦学习激励机制(Evolutionary Balanced Federated Learning Incentive Mechanism,EBFLIM).本文的主要贡献如下:
1)通过模型质量评估算法评估联邦参与者提交模型的质量同时量化其训练成本,并对低质量模型提交进行筛除,以提升联邦任务的完成效果.
2)提出了一种演化均衡的联邦学习激励机制EBFLIM,克服了联邦学习中参与者虚报训练成本造成的激励不匹配问题,实现了对联邦学习激励机制的优化.
本文其余部分组织如下:第1节总结与联邦学习激励机制和演化博弈论相关的研究工作;第2节提出面向联邦学习激励优化的演化博弈模型;第3节针对本文提出的优化方法进行仿真实验;第4对本文进行总结并交代下一步工作.
1 相关工作
1.1 联邦激励机制
为了联邦激励能够更合理的覆盖参与者的资源消耗,吸引更多高质量数据用户加入联邦,已有很多学者投入了联邦学习激励机制的研究.Tang等人[2]针对组织异质性和公共产品特性提出了社会福利最大化问题,并提出了一种针对cross-silo FL的激励机制,同时提出了一种分布式算法,使组织能够在不知道彼此的估值和成本的情况下最大化社会福利.Yu等人[3]为了解决训练成本和激励之间暂时不匹配的问题,提出了联邦激励机制,通过上下文感知的方式将给定的预算进行动态划分,最大化集体效用,同时最小化数据所有者之间的不平等.Ding等人[4]针对non-IID数据进行了最优契约设计.契约规定了每一个类型用户参与联邦学习能够获得的奖励并且会给到服务器更偏好的用户类型更高的奖励,从而达到激励相对高效、低成本用户参与联邦学习的目的.Bai等人[5]首先构建众包系统的激励模型.其次,结合反向拍卖和VCG拍卖的概念,提出了一种基于拍卖的激励机制.Sun等人[6]首先考虑了空地网络的动态数字孪生和联合学习,其次基于 Stackelberg 博弈设计联邦学习的激励机制.此外,考虑到不同的数字孪生偏差和网络动态,设计了一个动态激励方案,以自适应地调整最佳客户的选择及其参与程度.Richardson等人[7]考虑联邦参与者因冗余数据获得奖励的搭便车现象,提出了基于影响力的激励方案保证激励预算与联邦模型价值成比例有界,防止联邦被迫支付多余奖励.杜等人[8]提出了以在线双边拍卖机制为基础的ODAM-DS算法.基于最优停止理论,帮助边缘服务器在适当的时间选择移动设备,最小化移动设备的平均能耗.Hu等人[9]首先,将数据质量和数据量相结合,构建了特定指标下的联邦学习激励机制模型.然后,对基于服务器平台和数据岛的效用函数构建的激励机制模型进行了两阶段的Stackelberg博弈分析.最后,导出两阶段博弈的最优均衡解,确定平台服务器和数据岛的最优策略.从等人[10,11]建立了一个关于FL激励机制设计的推理研究框架,提出了FML激励机制设计问题的精确定义,基于不同的设置和目标提供了一个清单,供实践者在没有深入博弈论知识的情况下选择合适的激励机制.同时在文献[11]中基于VCG 提出了一种联邦激励机制,使社会剩余最大化,并使联邦的不公平最小化.
1.2 演化博弈论
博弈论作为解决双方或多方收益问题的重要手段应用于各种环境,基于博弈论的联邦学习激励机制的研究近年来也非常火热.Hasan等人[12]使用享乐博弈将联邦的交互建模为稳定的联盟划分问题.解决了是否存在确保纳什稳定联盟分区的享乐博弈的问题,并分析了纳什稳定集的非空条件.丁等人[13]针对以数据为中心的开放信息系统,基于演化博弈构建了面向隐私保护的多参与者访问控制演化博弈模型.Byde等人[14]描述了一种基于演化的评估拍卖机制的方法,并将其应用于包括标准第一价格和第二价格密封投标拍卖在内的机制空间,对拍卖理论进行了扩展.王等人[15]介绍并给出了混合均匀有限人口中随机演化动力学问题与确定复制方程的相互转化关系.同时介绍了无标度、小世界等复杂网络上演化博弈的研究结论.全等人[16]通过利用一个广义适应度相关的Moran过程,研究了一个有限规模的良好混合种群中的对称2×2博弈的演化模型,给出了博弈的进化稳定策略,并将其结果与无限种群中复制者动力学进行了比较.王等人[17]综述了网络群体行为和随机演化博弈模型与分析方法等方面的研究工作.针对以上方面的若干研究方法进行总结,并探讨了通过随机演化博弈进行网络群体行为研究的可行性.
由于联邦参与者虚报成本而造成激励不匹配的问题会导致集体利益受到损害,但现有的联邦学习激励机制缺乏对激励不匹配问题的重视.
因此本文在考虑了信息不对称因素的同时,构建演化博弈模型,设计了更符合实际应用场景的联邦学习激励机制.
2 面向联邦学习激励优化的演化博弈模型
本节提出一种面向联邦学习激励优化的演化博弈模型.首先在联邦学习系统中建立联邦参与者-联邦组织者演化博弈模型(Federal Participant-Federal Organizer Evolutionary Game Model,FPFOEGM),然后通过对联邦参与者提交的模型进行质量评估来过滤低质量模型,同时结合联邦参与者的信誉度指标设计联邦激励策略,最后通过求解复制动态方程得到演化稳定策略.
2.1 模型假设
基于客户-服务器架构构建的联邦学习系统模型如图1所示.考虑当前有n个联邦参与者表示为P={p1,p2,…,pn}.有模型使用者向联邦发送任务请求并将自己获得收益的一部分下发给联邦用于激励联邦参与者.为了能够对模型进行质量评估和筛选,同时量化参与者训练成本,在联邦中加入具有一定计算能力的联邦组织者,组织者接收参与者提交的模型进行筛选后将符合条件的模型上传至参数服务器进行整合,并作为协调方在激励预算允许的范围内对参与者进行激励.
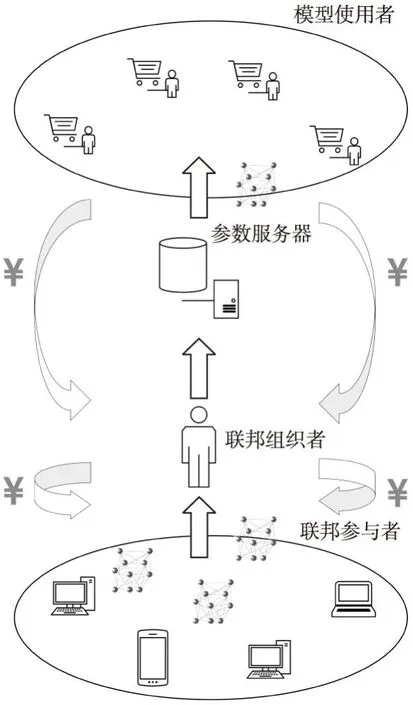
图1 基于客户-服务器架构的联邦学习模型Fig.1 Federated learning model based on client-server architecture
本文在FPFOEGM模型中设置以下假设条件:
1)博弈参与者均具有有限理性.联邦参与者通过选择合适的模型提交策略获得收益;联邦组织者通过选择适当的激励策略获得收益.
2)博弈双方的策略选择随着博弈进行发生动态变化.
3)联邦组织者的博弈收益即为联邦的收益.
2.2 模型构建
FPFOEGM模型可以用一个三元组进行表示,FPFOEGM={M,S,U}.
1)M=(Np,No)表示演化博弈参与者,Np为联邦参与者,No为联邦组织者.
2)S=(Sp,So)表示联邦参与者和联邦组织者的策略空间,其中Sp={Sp1,Sp2,…,Spn}为联邦参与者的策略集,So={So1,So2,…,Som}为联邦组织者的策略集.
3)U=(Up,Uo)表示博弈双方收益函数集合,Up为联邦参与者的收益函数,Uo为联邦组织者的收益函数.
在演化博弈模型中,联邦参与者和联邦组织者均有多个博弈策略可选择,并且双方选择同一个策略的概率会随着博弈进行发生变化,因此双方的策略选取是一个动态过程.
2.3 基于演化博弈的联邦学习激励优化方法
本节对联邦参与者提交模型的质量进行了评估并且针对联邦中的成本虚报现象设定信誉度指标.提出了一种基于演化博弈的联邦学习激励优化方法.
2.3.1 模型质量评估
将模型质量评估加入FPFOEGM模型,量化模型训练成本的同时去除低质量的模型提交.当联邦参与者接收到来自模型使用者发布的任务时,将从参数服务器中下载模型数据并使用本地数据进行训练,提交训练好的模型表示为M={m1,m2,…,mn},有m个评估模型质量的指标A={a1,a2,…,am},G=gij表示联邦参与者提交的训练模型mi在指标aj上的评估值.模型质量的评估与测试集的测试结果密切相关,因此基于混淆矩阵将模型质量评价指标总结为准确率(a1)、精确率(a2)、召回率(a3)3种.
由于以上评估指标均与模型质量成正相关,因此可以通过式(1)对指标进行归一化处理,并以此为依据去除低质量模型.
(1)


(2)
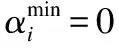
针对模型使用者对模型性能的不同需求,引入权重ωj,使模型质量评估结果更加符合实际情况.通过式(3)对参与者pi第k次提交模型的质量进行评估,便于联邦组织者进行激励策略选择.
(3)
模型质量评估算法如表1所示.

表1 模型质量评估算法Table 1 Model quality assessment algorithm
2.3.2 信誉度评估
在联邦学习中,每个参与者追求个体利益最大化时,存在虚报训练成本的情况,即上报联邦的成本与提交模型的质量不匹配,这会导致集体利益受到损害甚至造成合作失败.因此在对联邦参与者提交的模型进行质量评估后,针对虚报成本现象进行信誉度评估.
一般情况下,联邦学习中的联邦参与者的训练成本与其提交的模型质量成正比,因此本文假设其真实训练成本与模型质量在数值上相等.在联邦学习中,联邦参与者上报的成本超出真实成本越多,其信誉度越低,反之信誉度则越高.
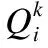
(4)
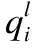
(5)

(6)


表2 信誉度评估算法Table 2 Reputation evaluation algorithms
2.3.3 激励分配方法
在对联邦参与者提交模型的质量及其信誉度进行评估的基础上,设计激励策略削弱联邦参与者虚报训练成本的欲望提高联邦整体效用.

(7)
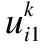
(8)
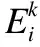
(9)
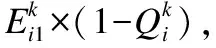

(10)

(11)
综上可得:
(12)
激励分配算法如表3所示.

表3 激励分配算法Table 3 Incentive allocation algorithm
2.4 收益矩阵分析
在FPFOEGM中,考虑到联邦参与者虚报训练成本的情况引入了联邦组织者,联邦参与者为P,联邦组织者为O.构建联邦参与者的策略集{PS1,PS2},PS1表示诚实即上报成本等于真实训练成本、PS2表示虚报,即上报成本大于真实训练成本;构建联邦组织者的策略集{OS1,OS2},OS1表示使用模型,OS2表示不使用模型.一般情况下,联邦给予联邦参与者的激励可以覆盖其训练成本.
下面分析博弈过程中参与者的收益情况,参与者在不同策略下的收益情况如表4所示.

表4 参与者和组织者的收益矩阵Table 4 Benefit matrix of participants and organizers
其中c1、c2分别为联邦参与者选择诚实策略和虚报策略时,其真实训练成本.s为来自联邦的激励收益,e1、e2为联邦使用模型获得的收益.
基于上述收益矩阵,设x为P中采用策略PS1的参与者所占比例,y为O中采用策略OS1的组织者所占比例.则联邦参与者如实上报成本和虚报成本下的期望收益如式(13)所示:
(13)
联邦参与者的平均收益如式(14)所示:
(14)
由此可得联邦参与者的复制动态方程如式(15)所示:
(15)
同理,联邦组织者使用模型和不使用模型的期望收益如式(16)所示:
(16)
联邦组织者的平均收益如式(17)所示:
(17)
则联邦组织者的复制动态方程如式(18)所示:
(18)
2.5 演化稳定策略
基于联邦参与者与联邦组织者的复制动态方程,对EBFLIM模型的演化稳定策略的求解过程如下:
1)计算复制动态方程的稳定解
2)演化稳定性分析
①联邦参与者上报成本策略的演化博弈分析

图2 联邦参与者复制动态相位图Fig.2 Replication dynamic phase diagram of federated participants
②联邦组织者策略的演化博弈分析

图3 联邦组织者复制动态相位图Fig.3 Replication dynamic phase diagram of the federation organizer
③联邦参与者与联邦组织者的博弈演化稳定策略
演化稳定策略指如果绝大多数个体选择演化稳定策略,那么小部分的突变个体就无法入侵到这个群体[18].根据上述演化稳定均衡解,构建雅可比矩阵,求出行列式与迹.雅可比矩阵构建如式(19)所示:
(19)
根据雅可比矩阵计算其行列式和迹,结果如式(20)和式(21)所示:
(20)
TrJ=(1-2x)[y(s1-s2)+(c2-c1)]+
(1-2y)[x(s2-s1+e1-e2)+(e2-s2)]
(21)
在EBFLIM模型中,选择虚报策略的联邦参与者的实际训练成本较低,所以c1>c2在基于模型质量以及联邦参与者信誉度的联邦激励机制的作用下,联邦参与者和联邦组织者的收益满足以下条件:s1-c1>s2-c2,e1-s1>e2-s2.
利用雅可比矩阵判断是否为演化稳定策略,若局部平衡点对应矩阵的行列式DerJ大于零,且迹TrJ小于零,则为ESS;若DerJ大于零,且迹TrJ大于零,则为不稳定解;若DerJ小于零,且迹TrJ为任意值,则为鞍点.
基于以上条件局部均衡点稳定性分析如表5所示.

表5 局部均衡点稳定性分析Table 5 Stability analysis of local equilibrium point
3 仿真实验
3.1 仿真设置
本文使用经典MNIST手写数据集进行实验仿真.为了真实还原联邦学习系统环境,将训练图例按照随机比例分配给10名联邦参与者以模拟参与者持有不同训练资源的情形,并从中随机选取5名有意虚报训练成本的参与者.本实验在Windows系统下通过Matlab平台搭建GoogLeNet执行手写数字识别训练任务以模仿参与者训练模型的过程.具体参数设置如表6所示.

表6 训练参数设置Table 6 Training parameter setting
3.2 实验结果分析
首先对参与者提交模型的质量及参与者信誉度进行评估,在EBFLIM中,联邦参与者提交高质量的模型可以得到更多的激励收益,同时也会提升联邦的总体效用.10名联邦参与者使用各自持有的数据对模型进行训练,之后用相同的测试集对他们训练好的模型进行测试,测试准确率如图4所示.

图4 测试准确率Fig.4 Test accuracy
通过对测试结果进一步分析可以得到10个模型对应的混淆矩阵,通过公式(22)计算Precision和Recall.
(22)
其中TP表示是正类并且被判定为正类的实例,FP表示实际为负类但被判定为正类的实例,FN表示本为正类但被判定为负类的实例.
每个模型识别不同类别测试样例的精确率与召回率应被分以不同的权重,在仿真实验过程中,为了简化实验过程,将不同分类的权重均设置为1,则进一步处理后,不同模型对应的精确率与召回率如图5所示.
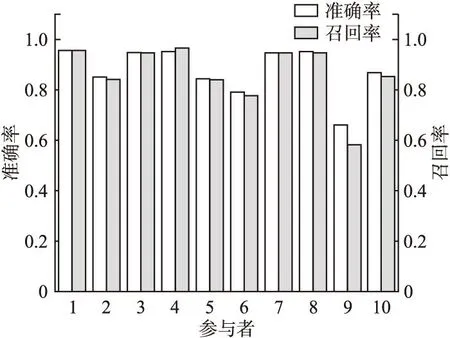
图5 处理后的精确率与召回率Fig.5 Precision and recall after processing
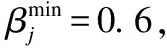

表7 参与者的模型质量、上报成本和信誉度Table 7 Model quality,reporting cost,and creditworthiness of participants
由表7数据可知,参与者9因未能通过模型质量筛选而被移出联邦,在本实验设置的条件下,对使用模型评估算法前后两种状态下的联邦学习系统引入FedAvg框架[19]进行参数聚合得到两个训练模型,用相同测试集对两个模型进行测试,输出相应的混淆矩阵,测试结果表明,在参与者9持有数据占比仅为0.3%的情况下,经过模型质量筛选后聚合得到的模型的精度仍比未经过筛选得到的模型提高了0.01%.在联邦学习实际应用的过程中,该方法对联邦模型精度的提升效果会随着数据量以及联邦参与者数量的增加而更加显著.
(23)
在个体收益分享法中,参与者i对集合体做出的边际收益被用于计算他能得到的收益分成如式(24)所示:
(24)
其中v(X)表示评估集合体效用的函数.
使用3种不同的激励分配方法,联邦参与者的激励收益情况如图6所示.

图6 不同分配方法下参与者的收益Fig.6 Benefits of participants under different distribution methods
EBFLIM在进行激励分配时,综合考虑了参与者虚报成本的现象,降低虚报参与者的激励收益,同时提高诚实上报训练成本的参与者的激励收益.如图6所示,利用平均分配法和个体收益分享法均会导致部分诚实上报训练成本的参与者的收益占比小于或等于部分真实训练成本较低的虚报者,而EBFLIM对虚报者的激励收益进行了削减并将其二次分配给诚实上报成本的参与者,与平均分配法和个体收益分享法相比诚实参与者的收益提升了70%和57.4%,虚报参与者收益降低了65%和69.5%,达到了提高联邦参与者积极性,减少虚报现象的目的.
进一步分析联邦参与者与联邦组织者的演化过程和模型中最优策略的选取问题.[x,y]初值分别取[0.2,0.8],[0.4,0.6],[0.6,0.4],[0.8,0.2],图7展示了在激励机制的作用下博弈双方的动态演化的过程,可见不同初始状态的策略选择经过演化最终会达到一定的稳定状态并且该状态可以使参与者与联邦均获得最佳收益.

图7 不同初始状态的动态演化过程Fig.7 Dynamic evolution process of different initial states
4 结束语
本文提出了面向联邦学习激励优化的演化博弈模型,分析评价表明,优化后的联邦学习激励方法能够有效的限制联邦中虚报成本的参与者的收益,降低其虚报成本的动力,同时在不同初始情况下参与者与联邦均能选取使双方收益最优的策略,提高了联邦的整体效益.下一步的工作首先是将其它导致联邦学习激励不匹配的因素融合进来,以适用于更多样的情形.其次是尝试对所提激励优化方法进行应用.
猜你喜欢
公民与法治(2023年12期)2023-12-11
汽车工程师(2021年11期)2021-12-21
家庭影院技术(2020年10期)2020-12-14
东坡赤壁诗词(2020年4期)2020-09-02
家庭影院技术(2019年7期)2019-08-27
赢未来(2018年22期)2018-12-24
儿童故事画报·发现号趣味百科(2017年10期)2018-03-13
妇女生活(2016年10期)2016-10-12
俄罗斯问题研究(2013年1期)2013-03-11
中国宪法年刊(2012年0期)2012-03-25
