
一种干扰系数自探测的网络事件选取方法
2024-03-05 01:41冯艳爽鲁锦涛
小型微型计算机系统 2024年3期
臧 洁,任 旭,冯艳爽,王 妍,肖 萍,鲁锦涛
1(辽宁大学 信息学院,沈阳 110036)
2(荣科科技股份有限公司,沈阳 110027)
3(中国刑事警察学院 公安信息技术与情报学院,沈阳 110854)
0 引 言
近年来,随着互联网的快速发展、电子产品的快速更新迭代,微博、微信、抖音等网络社交和短视频平台的快速崛起,人与人之间的社交变得更为便捷.跨地域、跨年龄、跨文化水平的社交成为了现实,大幅降低了社交成本,改变了人们的生活方式.
民众可以通过互联网发表、传播各种观点和情绪,这些不同观点和情绪的总和形成了网络舆情.网络舆情是由于各种事件的刺激而产生并通过互联网传播的人们对于该事件的认知、态度、情感和行为倾向[1],其影响力日益扩大.当前我国网民数量世界第一,互联网相关治理政策的出台难以应对互联网的快速蔓延.互联网上频繁出现各类热点事件,受到大量关注的同时,也出现了很多网民隐藏在网名背后表达自我观点的状况.伴随着民众发表的各种言论,热点事件一再发酵,往往可以在短时间内造成较大的影响力,而且近年来很多事例表明,网络舆情产生的影响存在向真实社会蔓延的趋势.
对于网络舆情领域的相关研究,大致从以下3个方面入手:1)对网络突发事件舆情的演变势态进行分析[1,2],主要关注网络突发事件发生后,舆情演变规律以及及时发现潜在的风险,以便进行应对操作;2)舆情风险定量评估[3],主要研究网络事件发生后对其影响力进行准确评估判断,精准掌握事件影响程度;3)从舆情传播观点角度定性分析[4],针对网络事件发生后民众观点倾向变化,探讨如何应对事件扩散所带来的一系列影响.以上研究,都可以给相关部门在应对舆情时,提供可参考和借鉴的理论依据.
经过研究发现,关于网络舆情方面的研究大多针对单一事件自身的传播趋势[1-7],并未对同一时刻,不同事件共同传播过程中所存在的竞争关系进行有针对性的研究.如果关注多事件,必须找到影响多事件传播的关键影响因素,重新设计具有多事件容量的网络事件传播模型,从理论、建模、实验等各方面均需结合多事件传播的特征进行研究,具有一定的难度.
本文以多网络事件共同传播所产生的事件间干扰为出发点,以不同类型事件间所产生的干扰效果不同为根据,以mSIR-CA(Multiple SIR-Cellular Automata)模型为核心,提出了一种干扰系数自探测的网络事件选取方法.随后,利用粒子群算法与微博平台真实事件数据集对方法进行参数寻优,经过实验证明,本文提出的方法对干扰事件有效性分类和干扰强度判断具有较好的准确性.
1 问题描述及相关工作
本文在对网络事件扩散规律研究中发现,同一时刻互联网中并不是仅有单一事件进行传播,而是众多事件同时进行扩散传播,事件的数量庞大,整个网络空间被这些事件占据.假设网络空间中所有正在传播的事件构成事件集合T,该集合中一部分事件在经历舆情发生期、发展期、高潮期以及回落期之后逐渐淡出网民视野,被移出集合T,但立即有新发生的事件进入网络空间,并开始传播,即加入集合T.
网络用户在上线期间,会在浏览各类社交平台过程中,接触到正在处于传播过程集合T中的部分事件,但由于在线时长和信息浏览量的限制,单一用户接触到的事件集合T1为集合T的子集.集合T1中所包含的多个事件对于用户注意力存在竞争关系,用户在此次在线过程中通过评论、转发、搜索等行为表现对事件的关注,注意力落在一个或有限的几个事件中,某一时刻用户仅关注某一事件.各大平台相关热搜榜单也从侧面反映出事件间所存在的竞争关系,登榜事件在集合T所包含的所有正处于传播过程中事件的竞争中取得了一定优势,热搜榜单通过数据排名量化了竞争结果.
网络事件在网络空间的传播和传染病在人际间的传播有很多共同点,网络舆情仿真建模相关领域不少学者选择借助传染病模型(SIR模型)对网络事件的传播规律进行研究.部分学者将传染病模型应用于社交网络舆情研究[8-11],也有将传染病模型应用于网络谣言与辟谣信息传播相关领域[12,13].其他,诸如Chen[5]提出了群体极化模型,借助SIRS模型并引入BA网络对信息扩散过程中的舆论极化现象进行研究,并提出了相应措施;张雷等[14]通过KNN算法对网络舆情进行定量分级,并结合SIR模型进行仿真模拟.
元胞自动机(Cellular Automata,CA)凭借其并行迭代运算的特点,在对网络空间以及网络用户不同状态的表现上具有明显的优势.Alves[15]等于2002年在自由选举舆情分析中应用了元胞自动机理论;方薇[16,17]、党小超[18]等也在元胞自动机网络舆情应用中进行了诸多探索.近年来,元胞自动机在网络舆情方面的应用更加细化,毛乾任等[19]关注于网络舆情观点聚合,将模糊推理理论与元胞自动机相结合,研究网络舆情中观点视角下的聚类效应,之后还对导控策略影响下的网络舆情传播进行了研究;姚翠友等[20]提出基于用户属性的微博舆情演化元胞自动机模型,得出相关部门可以通过增加网络事件参与度等方式,更好地发挥舆情引导作用;滕婕等[3]将CA模型与SEIR传染病模型相结合,应用于群体辟谣信息的扩散效果预测,并对谣言传播过程存在的规律进行研究.
分析以上研究发现,当前应用于网络舆情仿真领域的模型多关注单一时间推演,受事件容量限制,无法完成多事件同步推演.为了更快、更优地选取干扰事件,首先需要提出新的模型对多事件的发展进行推演.
2 mSIR-CA模型
本文结合多事件发展特征,将SIR模型和CA模型进行融合,提出了mSIR-CA(Multiple SIR-Cellular Automata)模型作为网络事件选取方法的事件推演模型.
mSIR-CA模型将经典SIR传染病模型与元胞自动机CA(Cellular Automata)进行融合,并将SIR模型的单事件分支结构进行改进,划分出多事件分支结构,通过元胞个体兴趣偏好模拟真实网络空间的用户喜好结构.此模型能够完成不同类型事件同时竞争扩散的推演工作,其模型矩阵静态构建如图1所示.

图1 mSIR-CA模型矩阵静态示意图Fig.1 mSIR-CA static diagram of model matrix
图1中,元胞矩阵A为二维有限元矩阵,利用横纵坐标i,j可以确定矩阵中每一个元胞个体的位置.元胞邻域选择类扩展Moore型邻域,用来对初始时刻矩阵中在线用户比例Dt0进行控制.根据类扩展Moore型邻域构建的经典元胞状态转换表达式如式(1)所示:
(1)

进一步对基于无分支顺序结构的经典SIR状态转换关系进行改进,得到具有分支结构、支持多事件容量的多重SIR状态转换规则,其转换规则如图2所示.
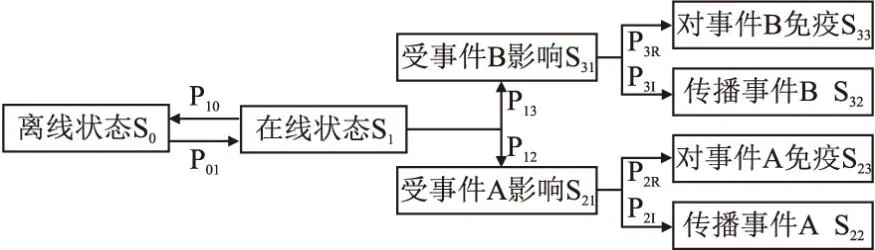
图2 多重SIR状态转换规则Fig.2 Multiple SIR state transition rules

(2)
3 网络事件选取方法设计
3.1 网络事件选取方法流程
不同的事件会产生不同的干扰效果,如何通过以上模型构建网络事件选取方法,使其能够对不同事件干扰影响下的扩散程度进行准确判断及应对,是该过程的重点内容.
网络事件选取方法的运行过程如图3所示.首先,收集部分当前网络空间中正在传播的事件,构建动态事件池,选取某一事件作为目标事件确定事件类型属性以及初始扩散指标;之后,从事件池中选取一组同处于扩散过程中的多个不同备选干扰事件,将其传入干扰事件选取方法中,分别与目标事件进行共同传播推演,并将结果与目标事件单一传播结果进行比较;通过事件选取方法对其进行有效性分类,分别给出能产生有效影响的建议事件以及无法产生有效影响的无效事件,并且通过推演过程各项指标对有效事件进行排序,最后给出首选、次选建议.

图3 网络事件选取方法运行过程Fig.3 Operation process of interference event selection method
网络事件选取方法本质上是对多个事件进行分类排序的过程,能够根据不同目标事件从相应的不同事件组中进行推演,将结果进行分类排序,最终给出事件选取结果,具体方法流程图如图4所示.
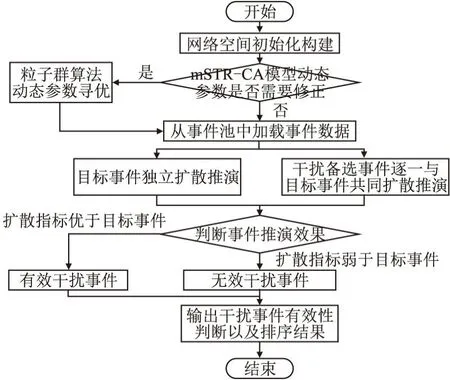
图4 网络事件选取方法流程Fig.4 Network interference event selection method and process
首先构建符合目标平台用户偏好比例的网络空间,依此建立支撑方法运行的静态基础矩阵;之后,根据具体干扰事件选取方法应用平台、借助先验知识事件集对mSIR-CA模型动态参数进行有针对性的参数寻优,以保证网络事件选取方法的准确性;最后,根据上文所述事件推演过程,给出最终的有效性判断和效果排序建议.
当平台发生变化、或者平台自身用户属性特征发生变化、或者模型动态参数无法满足准确性需要等情况,可以再次进行动态参数寻优,使其归于合理范围,从而提升方法性能.
3.2 动态参数寻优过程
在网络事件选取方法中,对动态参数进行寻优是重中之重,本文采用粒子群算法进行模型参数寻优,其流程如图5所示.
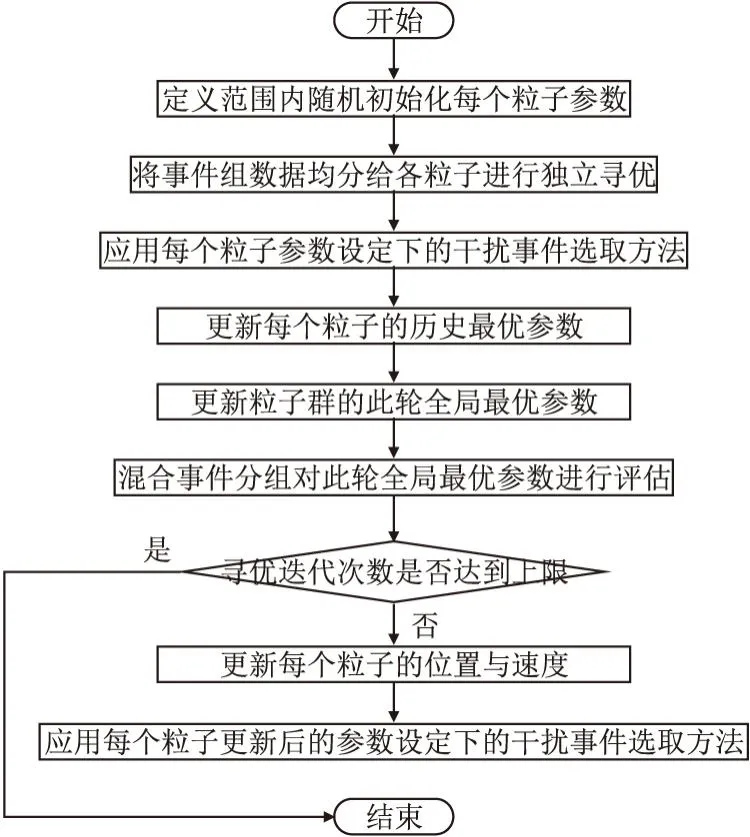
图5 粒子群算法寻优流程Fig.5 Optimization process of particle swarm optimization
根据事件选取方法中待寻优参数个数、各参数寻优范围以及网络事件数据集规模设定粒子个数n,每个粒子携带随机b1组事件信息进行寻优,其中事件组中包含单个目标事件以及与其相关联的多个备选干扰事件.
对图2中除P01、P10外的其余3组,共6个人为设定转换概率阈值参数进行自动化寻优,每组中对应两个阈值之和为1,因此每个粒子仅需对3个阈值参数进行寻优,便可还原为6个阈值参数对应值.其中,每个粒子寻优维度d∈(1,2,3,4),迭代次数上限kmax=25.对于全局最优解,从训练集中整体随机抽取b2组事件信息进行推演评价.个体最优解和全局最优解,通过分类准确度以及排序准确度进行评价,不设最优阈值,25轮寻优迭代之后,输出参数寻优结果.
4 实验结果与分析
4.1 实验数据及参数设置
本文采用的数据集为2020年全年微博热搜数据,通过第三方自行爬取获得.数据集围绕热搜话题条目建立,原始数据包含热搜关键词、URL链接、当日话题被爬取次数、最高热度值以及在榜最高位次、上榜时间等,共计104252条数据.
对原始数据集进行分析,发现其包含事件数量过多,可用于网络干扰事件选取方法训练及验证的有效事件密度低,符合真实干扰事件关联关系的事件数量有限,因此,本文对数据集进行了数据处理.首先,排除重复事件,根据事件选取方法,将事件进行筛选分组和类型标注,对于存在双重属性的部分事件,分别予以标注;之后,根据事件爆发时间,将爆发时间点接近的每5个热搜事件归为一组,每个事件组中选取一个事件为目标事件,另外4个事件作为干扰事件;然后,将干扰事件数据与目标事件数据进行综合比较,对每个分组内的干扰事件进行分类标注;最后将有效干扰事件按照扩散范围大小进行排序标注.按照此方法,共计筛选出240组1200条真实事件数据,供参数寻优及方法验证,其中160组800条事件作为真实事件训练集,80组400条事件作为真实事件验证集.
实验使用的有效元胞矩阵大小设置为100×100,初始元胞在线状态密度为Dto=0.70,人为设定模型转换参数设置依次为:P01=0.001;P10=0.0005;P12=0.67;P13=0.33;P2I=0.8;P2R=0.2;P3I=0.7;P3R=0.3.并以此为对照进行参数寻优效果评价.
网络干扰事件选取方法本质上是分类排序算法,因此在参数寻优后,事件选取方法结果的准确性需要通过计算分类精确率P、分类召回率R、分类准确率ACC以及排序准确率acc进行综合评价,各指标计算如公式(3)~公式(5)所示:
(3)
(4)
(5)
其中TP、TN、FP、FN分别表示正类样本被准确判定个数、负类样本被准确判定个数、正类样本被错误判定个数、负类样本被错误判定个数.其中对于某一备选干扰事件,经过网络干扰事件选取方法推演,在有效干扰事件与无效干扰事件的分类结果中符合真实事件数据集的标注结果,则此事件被认定为是正确分类判定,反之则为错误分类判定;在事件扩散范围排序结果中,排序位次符合真实事件数据集的标注结果,则此事件被认定为正确排序判定,反之则为错误排序判定.
实验运行环境为Windows10 20H2版本644位操作系统,计算机采用2.30GHz,Intel(R)Core(TM)i7-10875H处理器,16GB内存;实验使用Python3.6实现.
4.2 事件选取方法寻优过程准确性评价
在寻优过程中,实验记录每次迭代全局最优解参数下的选取方法在真实事件训练集的评价结果,因为粒子群算法重复实验结果并不唯一,并且网络干扰事件选取方法存在随机变量,因此实验结果图为单次实验结果,如图6所示,横轴为粒子群算法寻优轮次,纵轴为各评价指标结果数值.

图6 参数寻优过程中方法结果准确性变化Fig.6 Accuracy of method results changes in the process of parameter optimization
干扰事件选取方法多次实验结果相近,但存在误差,多组参数值均可满足相同的准确性指标,因此,可认为参数值应处于一定范围之内,范围内的参数值差异不会对事件选取准确率产生显著影响.
从图中可以看出,经过改进的粒子群算法寻优过程后,事件选取方法整体准确性有了明显的提高,其中对于真实事件训练集中,有效干扰事件与无效干扰事件的分类准确率达到85%以上,对于事件干扰强度的排序准确率达到了75%以上.粒子群算法寻优过程中,初始阶段的随机参数设定值并不理想,准确率也较差,但是,随着寻优过程的进行,参数值逐渐向合理区间靠拢,并在第9轮寻优过后趋于平稳,所以可将寻优结果参数认定为处于网络干扰事件选取方法合理参数范围之内.
4.3 基于验证集的方法准确性评价
使用真实事件数据验证集,对经过参数寻优后的网络干扰事件选取方法进行结果验证,具体验证集事件统计信息如表1所示.该数据集中包含80组事件,共400个事件,其中目标事件80个,有效干扰事件153个,无效干扰事件167个.

表1 真实网络事件验证集信息Table 1 Real network event verification set information
将网络干扰事件选取方法应用于真实事件验证集中,对事件集中的各事件组进行干扰事件选取,并将得到的事件选取结果与真实事件验证集中人工标记结果进行比较,统计整理得到事件选取方法结果中各项分类数据,具体运行结果如表2所示.

表2 真实网络事件验证集信息Table 2 Real network event verification set information
经由上述结果可以求出,网络干扰事件选取方法结果与真实事件验证集进行对比后的TP、TN、FP、FN数值,以及真实事件验证集的分类精确率P、分类召回率R、分类准确率ACC和排序准确率acc,结果如表3所示.

表3 方法验证评估结果Table 3 Method validation evaluation results
通过表3可以看出,干扰事件选取方法应用于真实事件验证集中具有较好的准确率,但相比寻优过程中使用的训练集,寻优参数设定下的事件选取方法在事件验证集下的准确率略有降低,造成该结果的原因可能有:
1)方法自身存在随机变量,使得重复实验条件下事件选取结果存在小幅误差;
2)真实事件训练集与验证集所包含事件数量有限,训练集与验证集分类排序比例自身存在差异;
3)粒子群算法寻优机制导致,寻优结果为大量重复选取后的最优结果,而基于验证集的选取结果仅为同参数下单次实验所得,不可避免会出现在验证时准确率下降的问题.
将寻优过后的参数设定与人工合理参数值设定的网络干扰事件选取方法进一步进行准确性比较,此实验同样采用真实事件验证集对其准确性验证,分别将人工参数与寻优参数输入网络干扰事件选取方法运行真实事件验证集,得到结果如图7所示.

图7 人工设定参数与寻优参数性能对比Fig.7 Performance comparison between manually set parameters and optimization parameters
网络干扰事件选取方法使用寻优后的参数运行结果相较于人工设定参数,在真实事件验证集上的准确率有一定幅度的提高,其中分类准确率提高约3.5%,排序准确率提高约2.5%.两者相较于随机参数设定下的事件选取方法均具有更好的准确率,说明参数寻优对于网络干扰事件选取方法来说,是必要且有实际效果提升的.
4.4 不同规模模型方法性能对比
借助mSIR-CA模型,网络干扰事件选取方法对不同事件传播干扰进行推演,模型中其他可变参数的不同设定,也会影响事件选取方法最终的性能指标.为了充分说明所提方法的有效性,又从调整模型矩阵大小、迭代次数两方面进行了实验.通过调整对应数值大小,记录方法单次事件选取实际运行时间、真实验证集上的整体分类准确率和排序准确率,综合比较不同运算量下方法的性能差异.
不同模型参数设定下,单次运行时间变化如图8(a)所示,每组数据均重复进行5次之后取平均值,分别记录了在50×50、100×100、150×150、200×200矩阵大小下,改变模型迭代次数为250、500、750、1000次情况下的网络干扰事件选取单次运行耗时.从图中可知,在相同模型矩阵大小设定下,事件选取单次运行时间会随着迭代次数增加而线性增加;相同模型迭代次数设定下,方法单次运行时间随着矩阵增大呈平方关系增加.造成该现象的具体原因为:模型迭代推演过程中涉及到大量简单运算,整体网络干扰事件选取方法的绝大部分运算时间消耗在与模型推演相关的简单运算中,改变迭代次数或者矩阵大小,会直接影响到网络事件选取方法的时间消耗.

图8 不同规模模型下网络干扰事件选取方法单次耗时与准确率对比Fig.8 Comparison of single time consumption and accuracy of network interference event selection methods under different scale models
不同模型参数设定下,对事件验证集运行后的准确率又进行了评估.通过调整模型参数值,计算分类准确率ACC以及排序准确率acc,并与4.3节中经过寻优实验结果所采用的100×100大小矩阵以及500次迭代数值设定下的干扰事件选取结果进行对比,结果如图8(b)所示.
由结果可知,通过改变矩阵大小与推演迭代次数,能够对网络干扰事件选取方法的性能产生较大影响.矩阵大小和迭代次数设定小于合理范围时,干扰事件的分类准确率以及排序准确率大幅降低;矩阵大小和迭代次数设定偏大时,能够从整体上提高方法的分类准确率以及排序准确率指标,但提升幅度较小.
同时,考虑本节前述实验,矩阵大小以及迭代次数的增加会大幅延长单次事件选取的运行时间,在网络干扰事件选取方法运行时间与精确率上需要进行取舍.过于追求准确率则会导致运行时间增加,有违网络舆情领域相关研究所尊崇的及时性原则;为了追求时间效率简化模型规模,可能会造成事件选取方法内部模型对于真实网络空间的模拟大幅度失真,使得方法准确率出现断崖式下降.该实验结果说明了本文所述方法参数设定能够兼顾时间消耗与准确性,具有较好的性能表现.
5 结束语
本文以不同网络事件共同传播所产生事件间的干扰为依据,以mSIR-CA模型为核心,设计了一种干扰系数自探测的网络事件选取方法.该方法能够针对特定事件和事件类型差异,从多个备选事件中选取有效干扰事件和无效干扰事件,并对其进行排序.以获取的微博平台真实事件为数据集,经过参数寻优后,方法在干扰事件有效性分类和干扰强度判断方面取得了较好的准确性结果.
未来的工作中,将对事件选取方法所容纳的事件影响因素进行扩充,或与其他现有模型的功能进行融合,以使方法理论更加完善.
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
中国交通信息化(2018年5期)2018-08-21
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
