
基于机器学习的煤矿瓦斯浓度预测技术
2024-03-05 01:45徐平安张若楠周小雨赵琦琦
陕西煤炭 2024年3期
徐平安,张若楠,周小雨,赵琦琦
(平安煤炭开采工程技术研究院有限责任公司,安徽 淮南 232000)
0 引言
煤矿在正常生产过程中,需严格控制采掘工作面瓦斯浓度在1%以下,然而在遇到构造、风量不足、区域瓦斯含量增高等情况时,采掘工作面瓦斯浓度非常容易超限。煤矿发生瓦斯灾害前,往往伴随瓦斯浓度异常,因此准确判断瓦斯浓度是进行瓦斯突出预测、通风设计等工作的基础。
煤炭资源是中国重要的基础能源资源,伴随着煤矿开采深度加深,瓦斯灾害越来越成为影响开采安全性的重要因素。周明[1]提出一种基于ELM的煤矿瓦斯浓度预测方法,并对其进行深入研究,并通过实验验证其对于煤矿瓦斯预测的可行性;刘锋[2]提出一种基于PCA-RVM的煤矿瓦斯浓度预测方法,其通过在PCA的基础上进行改进达到相较于使用PCA方法预测瓦斯浓度更好的预测结果;蔡亚东[3]提出一种基于概率密度机的瓦斯浓度预测方法,通过深入研究与瓦斯浓度相关的概率模型,实现对煤矿瓦斯浓度的预测;戚昱[4]通过研究信息融合与GA-BA 2种模型方法相互结合,实现精确预测煤矿瓦斯浓度;马莉等[5]深度结合PSO、Adam、GRU方法提出PSO-Adam-GRU方法并将该方法应用到煤矿瓦斯预测中;王勇哲[6]通过研究信息融合技术与瓦斯浓度的数值关系,实现煤矿瓦斯的浓度预测以及安全评估。综上所述,通过数学方法建模煤矿瓦斯浓度预测模型是具有一定可行性的,但目前的方法仍存在无法拟合实时煤矿瓦斯数据,并需要考虑影响煤矿瓦斯浓度的多种因素的问题。
近年来随着神经网络技术的发展,如何将神经网络方法与煤炭瓦斯监测相结合成为学术研究的重要课题。李旭等[7]提出一种基于长短期记忆-门控循环单元的神经网络瓦斯浓度序列预测算法,并通过使用吉林八连城南11902上顺工作面一年的实验数据验证该方法的可行性;谢谦等[8]在针对LSTM算法的反向传播过程中使用的Adam算法进行改进,并结合Attention机制提出Attention-aLSTM算法,实现在LSTM算法的基础上针对预测性能提升14.2%;王德忠等[9]利用GA算法优化LSTM网络参数,以解决LSTM网络预测不平衡和易陷入局部极值的问题,提出GA-LSTM瓦斯浓度预测模型,相较于RNN和BP方法得到了更加准确的瓦斯浓度预测结果;兰海平等[10]基于LSTM方法研究针对瓦斯超限和煤与瓦斯突出事故的超前预测模型,并验证其子样本长度和超前预测时长的关系;李铖翔[11]通过分析GRNN神经网络的结构及原理,验证其在瓦斯浓度预警方面的可应用性;刘超等[12]通过运行皮尔逊系数对瓦斯浓度数据进行特征选择,提出Pearson-LSTM预测模型,并在玉华煤矿2409工作面进行实验验证其预测的准确性。上述方法均验证了神经网络在煤矿瓦斯浓度预测方面的可行性。
采煤面瓦斯的多源特征和瓦斯混合气体的运移特征使得瓦斯浓度既具有一定的规律性,又具有一定的复杂性,是典型的非线性时间序列预测问题。首先,矿井瓦斯浓度是典型的时间序列数据,单个瓦斯监测点的瓦斯浓度与该测点历史瓦斯浓度具有时间相关性。其次,巷道内瓦斯同样受到煤层厚度、瓦斯抽采量、巷道内瓦斯风排量的影响,因此在预测瓦斯浓度时,应将这些影响因素纳入模型之中。采煤工作面回风巷瓦斯较为稳定,基本能够反映整个巷道的瓦斯情况,旨在实现对采煤工作面回风巷的瓦斯浓度进行主动预测。
1 瓦斯浓度预测算法
瓦斯浓度预测研究采用“广义线性回归”算法,广义线性模型是线性模型的扩展,其在一般线性回归模型的基础上,将模型的假设进行推广而得到应用范围更广更实用的回归模型。通过联结函数建立响应变量的数学期望值与线性组合的预测变量之间的关系。其特点是不强行改变数据的自然度量,数据可以具有非线性和非恒定方差结构,符合瓦斯浓度预测的特征。
1.1 算法分析
机器学习是一种实现人工智能的方法,而线性回归是机器学习中的一种重要方法,其理论依据是将训练数据传输给计算机,计算机自动求解数据关系,在新的数据上做出预测或给出建议。从数据中寻找规律、建立关系,根据建立的关系去解决问题,满足文中所研究的瓦斯浓度预测的需求。
线性回归算法中单变量线性回归需要经过已知的数据计算出平方误差代价函数(代价函数/损失函数),然后使用梯度下降法把大量数据之间的平方误差代价函数的常数部分降低到最小,使得线性回归方程可以拟合现有的所有数据,多变量线性回归的时候,因为变量的个数较多并且之间的数量级差距较大,所以在缩小平方误差代价函数的时候不能直接使用梯度下降法,要在所有的变量进行特征缩放(均值归一化或者正规方程法)之后再进行梯度下降,最终得出多变量线性回归的拟合方程。
1.2 模型建立
该算法基于煤矿工作面采集的多种影响到采煤工作面回风巷T2瓦斯浓度的因素,包括回风巷上隅角T0甲烷传感器历史数据、采煤工作面产量数据、工作面瓦斯抽采量数据、工作面煤层厚度数据、回风巷道风速数据,以此建立基础数据集。在基础数据集的基础上,基于时间关联性将基础数据集中的数据整理形成瓦斯浓度影响因素数据集,其中数据元组格式见表1。处理完成后,得到数据集。

表1 数据对应名称
上述步骤数据分析建立的基础数据元组仍需进一步处理得到用于预测T2位置瓦斯浓度的算法模型。首先,步骤1中的数据元组提供了影响T2位置瓦斯浓度的影响因素,其主要用处是用于预测下一数据采集时刻的T2位置瓦斯浓度,因此将数据元组格式化为(T0_MAX,EXTRACT_COUT,COAL_PRODUCTION,COAL_THINKNESS,WIN_SPEED_AVG)格式。
为保证数据的可用性,对数据元组的每一列进行标准化处理首先对每一列数据进行平均值求解,其公式为
(1)
式中,xi为单个样本数据的值;N为每列数据的样本总数;μ为平均值。
求得平均后,再进行标准差求解,其公式为
(2)
式中,σ为标准差。最后对元组中每列数据的单个数据进行z-score标准化,其公式为
(3)
通过上述得到标准化后的数据集。
将经由特征工程产生的数据集进行切分,将数据集的70%数据用于模型训练,20%的数据进行评估,10%做瓦斯浓度预测校对使用,根据训练的模型规律进行评估调整。
采用线性回归的第一准则,因变量Y需要是“定量变量”,即数值变量,这里预测的T2甲烷传感器浓度符合第一条件。煤层厚度决定了瓦斯的总量;日产量影响了每天大概的瓦斯涌出量,对工作面之中的瓦斯浓度的影响主要是抽采量和风排量,风排瓦斯中,瓦斯会跟随风流经过工作面和回风巷至采区回风巷中,因此,煤层厚度、瓦斯抽采量、日产量、风速与T0瓦斯浓度传感器和T2瓦斯浓度传感器的数值是一元回归或者高阶回归的关系,本身的一元回归或者高阶回归的关系并未改变,所以本次模型建立采用广义线性回归的算法进行数据拟合,同时数据也服从高斯分布。建立多因素的广义线性回归模型,其计算公式为
θT2=ωDD+ωCC+ωQQ+ωSS+ωθT1θT1+b
(4)
式中,D为煤层厚度,m;C为瓦斯抽采量,m3;Q为日产量,t;S为风速,m/s;θT1为T0瓦斯浓度;θT2为T2预测瓦斯浓度;ω为各影响因素对于T2瓦斯浓度影响的偏移权重;b为公式整体相对于T2瓦斯浓度的偏移量。
将影响T2瓦斯浓度的影响因子与相应的权重用向量方式表示ρ=[D,C,Q,SθT1],ω=[ωD,ωC,ωQ,ωS,ωθT1],则可将公式简化为
θT2=ωTρ+b
(5)
上述步骤中基于影响T2位置瓦斯浓度的多种因素之间的线性关系建立了相应的多因素广义线性回归模型为θT2=ωTρ+b。
为了实现该模型对于实际预测值的拟合,通过最小二乘法对上述模型中的影响因素进行相应训练,其计算公式为
(6)
式中,y为训练集中原始的T2位置瓦斯浓度;θT2为通过多因素广义线性回归模型预测的T2位置瓦斯浓度。
通过上述采样方法,划分训练集与测试集,使用凯明正态分布方法对模型权重赋予符合正态分布的处置,进行13轮模型训练,得到训练损失结果如图1所示。
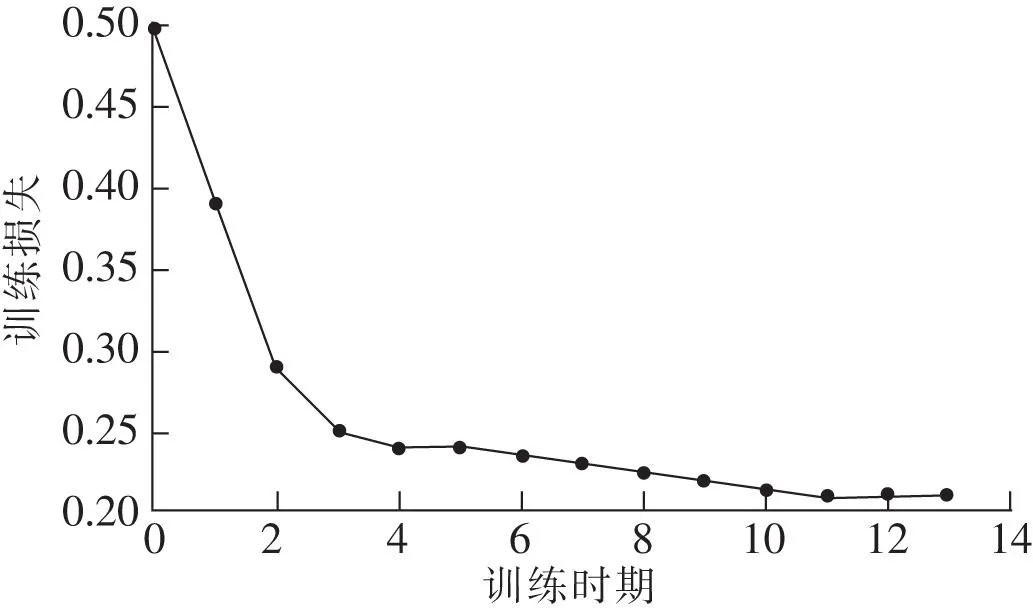
图1 训练损失结果Fig.1 Training loss results
从图1可以看出,随着训练轮次的加深,算法的损失逐渐减小,模型学习到的内容逐渐增多。
2 预测结果对比
试点矿井数据选取的是淮南矿业集团顾桥矿1126(3)采煤工作面的相关数据,该矿井为瓦斯突出矿井,因此采用大数据预测的方式能提高矿井的生产安全可靠性。通过分析,此次实验选取的T0甲烷传感器数据、风速数据、抽采量数据、日产量数据、煤层厚度数据等均与采煤工作面环境中瓦斯浓度大小息息相关。T0甲烷传感器反映的是本采煤工作面回风上隅角的瓦斯积聚情况,若数值较大,可能造成回风巷瓦斯浓度变大;风速影响风排瓦斯含量,若风速变小,容易造成瓦斯积聚,造成瓦斯浓度上升;抽采累积量为本采煤工作面煤层中赋存的瓦斯抽采量,当抽采量提高时,说明正在回采的本煤层吨煤瓦斯含量较高,抽采充分后,则在回采过程中空气中的瓦斯含量会降低,抽采不充分,则空气中瓦斯含量会升高;日产量数据能够反映本采煤工作面回采的速度,当回采速度过快时,煤层中释放至空气的瓦斯含量就会提高,所以当空气环境中瓦斯浓度较高时,必须停止回采。通过上述分析,可以看出,想要科学准确地预测出回风巷瓦斯浓度,必须将这些相关因素纳入模型之中,进行权衡学习。
甲烷传感器浓度数据、风速数据、抽采量数据是通过安全监控系统进行实时获取,由数据库中得到相关数据集,工作面产量数据是由生产调度系统所获取的相关数据,在建模过程中选取1个月的数据量,并根据数据集划分,将数据集的70%数据用于模型训练,20%的数据进行评估,10%做瓦斯浓度预测校对使用,本次模型的建立、训练以及校对工作依托大数据搭建的数据科学平台进行完成,将数据集按照数据解析、特征工程提取、切分数据集、训练模型、校对模型等步骤依次进行,最终能够得到相关的预测结果对比。
选择数据集中的20%数据进行预测评估,见表2数据,其中mae为平均绝对误差,即预测值和实际值的绝对差值(差值和的平均值),mse为均值方差,rmse为均方根误差。
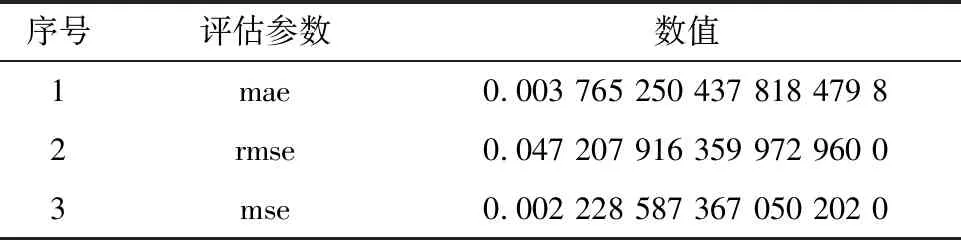
表2 评估结果
图2所示为一段时间的数据集对应的预测评估结果predict曲线为预测值曲线,T2_max曲线为真实值曲线。
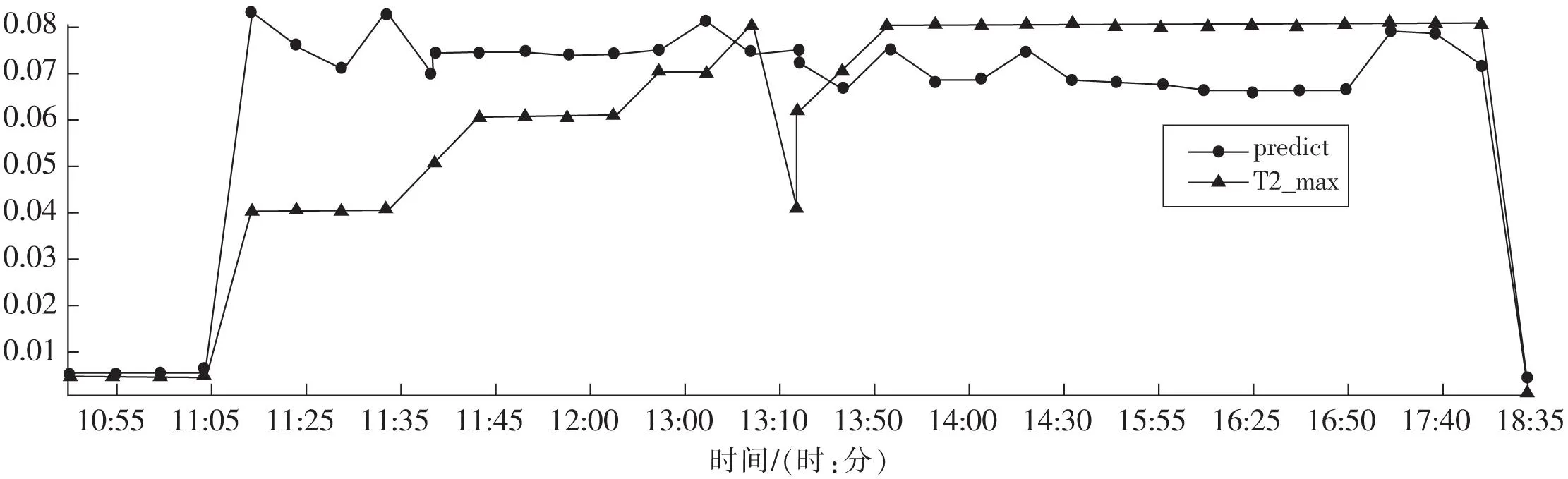
图2 预测结果对比Fig.2 Comparison of predicted results
预测实验在较为理想的情况下进行,历史数据较为稳定,且现场无偶然突发情况,如图2所示,在模型迭代13次之后,能够在变化趋势上进行较为准确的预测,达到了本次研究的要求与目的。
3 结语
瓦斯灾害是煤矿领域的重大安全问题,随着煤矿智能化水平的不断提高,探索深度机器学习对煤矿瓦斯浓度进行预测具有现实意义,通过深度学习,能够掌握瓦斯浓度变化的规律,对日后瓦斯预测预报,防范瓦斯灾害的发生具有重要意义,能够为煤矿的回采与掘进工艺提供更为精准的风险预判依据。同时,将大数据、深度学习等智能化技术引入煤矿瓦斯治理工作中,具有较高的使用价值。在今后的研究工作中,将会在此成果的基础上,对模型进行推广,以求更好适用于矿井生产。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
中学生数理化·高一版(2021年2期)2021-03-19
建材发展导向(2019年5期)2019-09-09
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
山东工业技术(2016年15期)2016-12-01
当代化工研究(2016年7期)2016-03-20
江西煤炭科技(2015年1期)2015-11-07
河北能源职业技术学院学报(2015年3期)2015-02-27
河南科技(2014年18期)2014-02-27
河南科技(2014年15期)2014-02-27
