
基于深度学习的雾霾天气下的车牌号码识别方法
2024-03-05 08:15杨云王静姜佳乐
液晶与显示 2024年2期
杨云, 王静, 姜佳乐
(陕西科技大学 电子信息与人工智能学院, 陕西 西安 710021)
1 引言
随着我国经济社会的发展,车辆数目迅速增长,给交通管理带来了巨大的挑战。车辆的车牌号码识别现已成为智慧交通系统的重要一环,在缓解交通压力问题上起着至关重要的作用。车牌识别技术主要应用于城市交通、高速公路、停车场及小区出入口等。随着机动车数量的持续增长,公路运输负荷越来越重,与交通有关的治安和刑事案件逐年上升。为了有效遏制城市内车辆乱停、闯红灯、逆行等违章行为,城市内各个路口大力安装检测系统,而车牌识别系统是其重要组成部分,可应用于交通违法行为的检测,更加方便道路管理以及更好地满足刑侦、治安等业务的需求。我国高速公路发展迅速,将车牌识别技术应用于高速公路便于进行收费管理,同时便于交警对违反交规的车辆进行监控。停车场和小区出入口的车辆管理仅靠人工记录是非常困难的,车牌识别技术的应用可以节省人力、提高效率。
目前的车牌检测、识别模型有着较好的效果,但应用在雾霾、雨雪等场景下往往会出现大量漏检。因此研究复杂场景下的车牌识别十分必要。
目前已有的车牌检测方法主要包括传统的识别方法和基于深度学习的识别方法。传统的识别方法流程主要包括:对彩色图像进行灰度化、滤波处理、边缘检测[1]、车牌的粗定位、车牌细定位、字符分割以及字符识别。通过人工提取车牌特征实现车牌识别的方法受环境影响大,且识别准确率低[2]。相比于传统的检测方法,基于深度学习的算法提高了车牌识别的鲁棒性,不仅在停车场、高速公路等简单场景下有良好的检测效果,而且在车牌倾斜、图像模糊等复杂情况下也有更加稳定的鲁棒性。目前目标检测主要以单阶段目标检测和双阶段目标检测为主。双阶段目标检测先对目标进行定位,然后进行识别,因此检测精度较为准确,但很大程度上降低了检测速度。单阶段目标检测将目标定位和识别过程相统一,更适合对目标进行实时检测[3]。
郝达慧等[4]用YOLOv5网络进行车牌检测,并设计LPCRNet网络对车牌字符进行识别,车牌检测准确率达98.6%,字符识别准确率达88.9%。杨杰等[5]提出了雾霾环境下基于Zynq的实时车牌识别系统,系统着重强调实时性。田智源等[6]提出了一种基于自适应去雾算法的雾霾天气下的车牌识别系统,提出一种新型的车牌检测和车牌识别模型且达到了较高的车牌识别率。毛晓波等[7]提出了基于PSO-RBF神经网络的雾霾天气下的车牌识别算法,使用改进的暗原色先验去雾算法对车牌图像进行预处理,然后对预处理后的图像进行车牌定位、字符分割和字符识别。
本文采用双阶段目标检测算法,提出了一种雾霾天气下的车牌号码识别方法。使用图像去雾算法对图像进行预处理。设计了车牌检测网络ACG_YOLOv5s,引入CBAM注意力机制、自适应特征融合网络ASFF模块以及Ghost卷积模块来搭建检测网络。最后用LPRNet网络对检测到的车牌进行识别,从而实现雾霾天气下的车牌号码识别。
2 车牌识别流程总体设计
车牌检测和识别流程如图1所示。

图1 车牌识别流程总体设计Fig.1 Overall design of license plate recognition
首先使用AOD-Net算法对图像进行去雾操作,利用去雾操作可获取更多的车牌特征信息,得到相较于原始车牌图像更清晰的图像。然后使用基于YOLOv5改进后的ACG_YOLOv5s网络作为车牌检测网络。最后将ACG_YOLOv5s网络检测出来的车牌输入到车牌识别网络中,对车牌号码进行识别。
3 雾天图片处理
AOD-Net(All-One Dehazing Network)算法基于大气散射模型[8],是一种基于CNN的去雾网络模型[9]。AOD-Net模型在无雾的条件下仍具有较好的性能,适合应用于车牌号码识别。
在雾霾天气下拍摄的图片质量会因雾霾的存在而受到很大的影响,在很大程度上降低了目标检测的准确率。雾霾天气下,拍摄设备接收到的光源主要来自光源经过空气中悬浮粒子发生散射形成的大气光以及反射光衰减后到达拍摄设备的光。雾天成像的数学模型[10]如式(1)所示:
式中:I(x)表示雾霾图片,J(x)表示清晰无雾图片,A表示全球大气的光照强度,t(x) 表示透射率,透射率可以表示为式(2):
式中:β表示大气散射率,d(x)为拍摄目标到传感器的距离。透射率越小意味着雾霾越大,1-t(x)值也会更大,大气光照进入到拍摄设备的光线就越强。
由式(1)可得,清晰无雾图片J(x)的计算公式如式(3)所示:
AOD-Net算法的模型如图2所示,AOD-Net包括K值估计模块和复原图像模块(清晰图像生成模块)两部分。
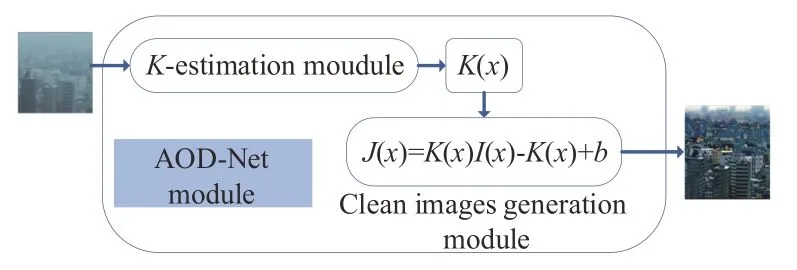
图2 AOD-Net模型Fig.2 AOD-Net model
AOD-Net将有雾图像输入到K值估计模块中。K值估计模块通过一系列卷积和拼接操作来提取图像中的特征信息进而得到变量K(x),然后复原图像模块可利用K(x)得到无雾图像。
对式(3)进行变形得到:
式中,b是一个常量。联立式(3)和式(4),可得K(x)的值为:
从式(5)可以得出,K(x)与输入的有雾图像I(x)、大气光照强度A和透射率t(x)有关,K(x)随着输入的有雾图像的变化而变化。AOD-Net算法采用对大气的光照强度A和透射率t(x)的联合估计,即将其统一为K(x)变量,通过最小化无雾图像和模型的输出结果J(x)之间的误差而训练模型。
K值估计模块网络结构如图3所示。网络由五层卷积层和三层连接层构成,采用了多尺度的特征融合方式。卷积层的作用是为了提取图像特征,影响卷积层输出结果的因素有卷积核大小、卷积核个数、步幅和填充。其中步幅是卷积核滑动的像素个数。卷积核会按照一定的规律在特征图上滑动,最后对卷积核的值和特征图对应位置上的像素值相乘相加再叠加偏置项得到特征图的输出。连接层是将多个特征图在通道维度上进行拼接。第一层连接层融合了Conv1层和Conv2层特征,将第一层卷积和第二层卷积的输出作为第三层卷积的输入。第二层连接层融合了Conv2层和Conv3层特征,将第二层卷积和第三层卷积的输出作为第四层卷积的输入。第三层连接层融合了Conv1层、Conv2层、Conv3层、Conv4层特征,即将前四层卷积的输出作为第五层卷积的输入。最后将拼接结果通过Conv5卷积层来估计K值。利用三层连接层将不同卷积层的特征信息进行融合,减少了在卷积过程中的特征信息损失。该神经网络的5层卷积层卷积核大小分别为1×1、3×3、5×5、7×7、3×3,5层网络中都各有3个卷积核,因此AOD-Net也是一个轻量级网络。
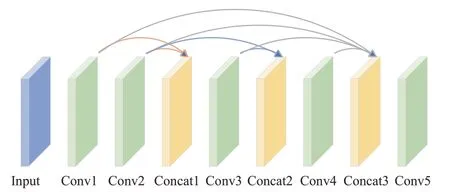
图3 K值估计模型Fig.3 K-value estimation model
复原图像模块将K值作为自适应参数由雾霾图像估计清晰图像。利用估计得到的K(x),再结合输入雾霾图像I(x)和常量b,可根据式(4)计算出去雾后的图像J(x)。
本文首先用AOD-Net算法对车牌图片进行预处理,抑制雾霾对车牌识别的影响。去除雾霾效果如图4所示。从图4可以看出,AOD-Net算法抑制雾霾效果显著。去雾后的图像,便于车牌的检测和识别。

图4 AOD-Net模型的去雾效果对比Fig.4 Comparison of AOD-Net model dehazing effect
4 车牌检测网络ACG_YOLOv5s
4.1 YOLOv5结构基本原理
YOLOv5有YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x五个版本[11],这几个模型的结构基本相同,不同的是模型的深度和宽度,即在网络的同一位置,卷积核的个数不同以及卷积层的数量不同。这5个版本的模型大小依次递增,YOLOv5相比于YOLOv3等具有模型小的特点,适合嵌入式设备使用。
YOLOv5包含输入端、骨干网络Backbone、颈部Neck层和输出层4大模块[12],其网络结构如图5所示。

图5 YOLOv5网络结构Fig.5 YOLOv5 network structure
YOLOv5网络输入640×640的RGB图像,如果原图像尺寸不是640×640,则通过缩放将其尺寸变成640×640之后再输入网络。
YOLOv5主干网络包括Focus模块、CBL结构、C3结构、SPP结构。YOLOv5中图片通过Focus结构会将输入图片的尺寸缩减1/2,通道扩充为4倍。例如输入图片的大小为3×608×608,经过切片操作[13]后,得到12×304×304的特征图。CBL结构由卷积、批量归一化和激活函数组成。C3层包含CBL结构和残差结构,能够记录梯度变化,增强网络学习能力。SPP是空间金字塔池化层,该模块先通过一个卷积模块将通道数减半,然后分别做卷积核分别为5、9、13的最大池化,将3次最大池化的结果与未进行池化操作的特征进行融合。
YOLOv5网络中Neck层用于特征融合。随着网络深度的加深,所得特征图的特征信息变强,目标检测效果更好,但是减弱了目标的位置信息,容易损失小目标的信息。YOLOv5采用特征金字塔(FPN)和路径聚合网络(PAN)结构将特征进行多尺度融合,加强了对小目标的检测。FPN以上采样的方式将深层的特征信息传递融合到浅层,PAN结构以下采样的方式将浅层信息传递融合到深层,使不同尺寸的特征图都包含强语义信息和强位置信息。
Head层是预测输出部分,主要负责对骨干网络提取的特征图进行多尺度目标检测。
4.2 融合注意力机制
注意力机制的核心思想是强调特征图中的重要信息,在深度学习目标检测领域效果显著,在提高模型性能的同时也在一定程度上降低了计算量。
混合注意力机制CBAM[14](Convolutional Block Attention Module)采用将空间和通道相结合的方式,相比于只关注通道的SEnet(Squeeze-and-Excitation Networks)取得了更好的效果,其结构如图6所示。空间和通道相结合使目标检测能力在通道和空间维度上得到提升。对于网络中某层输入特征图F,先根据原特征图计算通道注意力向量MC(F),输入特征图F与其相乘可得中间特征图F',再由F'计算空间注意力向量MS(F'),MS(F')与F'相乘,得到CBAM输出结果F″,如式(6)~(7)所示:

图6 混合注意力机制Fig.6 Mixed attention mechanism
通道注意力模块结构如图7所示。对于网络结构中某一层特征图F(设其结构为H×W×C),分别对其进行平均池化和最大池化,得到平均池化特征图(1×1×C)和最大池化特征图(1×1×C),减少了单一的池化操作对特征信息的影响。所得两个特征图通过一个共享网络(Shared MLP)得到两部分结果,将这两部分结果相加并通过Sigmoid函数可得通道注意力向量MC(F),计算如式(8)所示:

图7 通道注意力模块Fig.7 Channel attention module
空间注意力模块更关注位置信息,其结构如图8所示。

图8 空间注意力模块Fig.8 Spatial attention module
将网络中某一特征图F'(设其结构为H×W×C)从空间维度上分别进行平均池化和最大池化,得到两部分结构为H×W×1的特征图,然后拼接两部分特征图并进行一次7×7卷积操作,最后将结果送入Sigmoid函数可得空间注意力向量MS(F'),计算公式如式(9)所示:
针对YOLOv5的3层预测输出部分,网络浅层输出的特征图有较大的尺寸适合检测小目标,因车牌图像(94×24)相较于输入图片(640×640)尺寸较小,通过多次实验发现,将CBAM加入到浅层预测输出层之前,可以加强网络在训练过程中对关键特征的提取,抑制不重要的特征信息,达到提高检测目标精度的目的。CBAM融合到原始YOLOv5网络的位置如图9所示。

图9 融入CBAM后部分网络结构Fig.9 Part of the network structure after integration into CBAM
4.3 ASFF替换PANet结构
卷积神经网络结构中的浅层特征关注的主要是目标的位置信息,经过不断卷积所得到的顶层特征更加关注语义信息,为了提高目标检测效能就需平衡不同层级的特征图信息。YOLOv5在颈部特征融合网络中采用了PANet结构,PANet采用双向融合的方式虽可以丰富特征层的语义信息但赋予了不同层的特征图相同的权重。在车牌识别中,车牌图像形状类似,尺寸不会有太大的差异,因此对于浅层网络中尺寸小的特征图,由于预测的是较大尺寸的目标,所以应赋予其较小的权重,PANet结构不是很好的选择。
自适应空间特征融合[15](Adaptively Spatial Feature Fusion,ASFF)结构如图10所示。ASFF结构的核心思想是自适应地学习各尺度特征融合的空间权重,通过自适应学习到的权重可对网络赋予不同特征层不同比重的权值,从而突出重要特征信息,且当某层特征图匹配某个目标时不会忽视其他特征图的信息,解决了不同层级的特征图之间特征着重点不一的问题。

图10 ASFF网络结构Fig.10 ASFF network structure
图10中x1、x2、x3分别是来自YOLOv5网络的Head层预测输出部分的3个特征层,xm→n表示xm经过特征缩放以后生成与xn层相同尺寸的特征图。以ASFF-3为例,该层得到新的特征如图10所示,x1、x2、x3层的特征图分别与来自3个特征层上通过训练得到的权重参数α3、β3、γ3相乘,再将相乘结果求和即可得ASFF-3层的融合特征图。融合公式如式(10)所示:
由于采用相加的方式,所以要求特征缩放以后的特征图尺寸和通道数都要相同,就需要用到1×1卷积调整通道数。表示l层所求特征图(i,j)位置处的特征表示从m级调整到n级所得特征图中映射位置(i,j)处的特征向量表示映射到l层网络自主训练得到的权重。计算如式(11)所示:
在YOLOv5网络中,3层检测层所包含的语义信息侧重点不同。浅层检测层更容易识别小目标,所以对于目标较小的车牌图像,浅层检测层应赋其较大的权重,以降低小目标的漏检率。因此本文在YOLOv5网络PANet结构之后引入ASFF模块,加强对小目标的检测。
4.4 Ghost卷积替换
Ghost卷积[16]模块与传统卷积不同,其结构如图11所示。首先对输入特征图进行少量传统卷积操作得到中间特征图,然后对中间特征图进行线性变化运算得到Ghost特征图,最后拼接中间特征图以及线性变化运算所得Ghost特征图得到最终的结果。Ghost卷积与传统卷积相比,采用将传统卷积和线性变化操作结合的方式,所需计算参数量明显降低;而传统卷积操作是对输入特征图所有通道进行卷积操作,需要计算大量的参数。

图11 Ghost卷积Fig.11 Ghost convolution
在不考虑偏置项的情况下,设使用传统卷积所需的网络参数为p1,使用Ghost卷积所需的网络参数为p2,计算公式如式(12)和式(13):
其中:n表示传统卷积卷积核个数即输出特征图通道数,c表示输入特征图通道数,k表示传统卷积卷积核大小,d表示线性操作卷积核大小,s≪c。
两者参数量之比如式(14)所示:
设使用传统卷积浮点型计算量为F1,使用Ghost卷积的浮点型计算量为F2,计算公式如式(15)~(16)所示:
两者浮点型计算量之比如式(17)所示:
其中,h'和w'分别表示原始特征图的高和宽,其它含义同上。当k与d大小相等时,通过式(14)和式(17)计算得出,Ghost卷积与传统卷积相比,所需参数量和计算量均为传统卷积的1/s。
本文用Ghost卷积模块替换原YOLOv5网络中所有普通卷积模块,在保持模型效果的同时减少了模型的参数。
5 车牌识别网络LPRNet
LPRNet(License Plate Recognition Network)用于车牌号码识别,是第一个没有使用RNN(Recurrent Neural Networks)的轻量级网络[17],支持识别变长字符车牌,在光线暗、视角差、强光等复杂情况下有较好的鲁棒性。LPRNet网络模型小且高效,适合部署到嵌入式设备上。
在车牌倾斜角度大、雨雪天气、强光等特殊环境下,车牌识别成为一项复杂而重要的任务,所以一个强大的车牌识别系统应能够在不同的环境下有较好的适应性。早期的车牌识别过程包含字符分割和字符识别两个阶段。字符分割包括投影分割法、平均分割法等,它以二值化图像作为输入,因此分割质量易受图像噪声、模糊等的影响。而LPRNet在识别车牌时采用端到端的识别方法,在免于对车牌图像进行分割的同时减轻了网络训练过程中数据标注的工作量,极大提高了训练效率。
LPNNet整体架构是CNN(Convolutional Neural Network,CNN)+CTC Loss[18],骨干网络以RGB图像作为输入。为了利用局部字符的上下文信息,使用宽卷积(1×13的卷积核)取代了基于LSTM(Long Short-Term Memory)的RNN(Recurrent Neural Networks,RNN)网络。网络最终输出字符序列因网络的输出编码和车牌字符长度存在不相等的情况,而以往将输出编码和字符长度进行对齐可能会导致模型无法收敛,因此采用CTC Loss(Connectionist Temporal Classification Loss),解决了输入和输出序列未对齐的问题,避免了对车牌图像进行分割而进行端到端的训练。
6 实验
6.1 实验平台
在实验中,ACG_YOLOv5s网络训练、LPRNet网络训练环境是Ubuntu20.04操作系统、python 3.8编程语言,使用Pytorch深度学习框架,显卡型号为NVIDIA RTX A4000。两部分实验部分参数设置如表1所示。

表1 网络训练部分参数设置Tab.1 Parameters setting in the network training section
6.2 数据准备
CCPD数据集主要采集于合肥市,包含的车牌图片中车辆省份主要为皖,所拍摄的图片涉及雨天、模糊、雪天、倾斜等复杂情况。
本文YOLOv5网络实验数据集包括两部分。一部分来源于CCPD2019数据集中的CCPD-weather。CCPD-weather是在雨、雪、雾天气的情况下拍摄的,其部分图片如图12所示,选取其中的5 999张。另一部分是通过在网上搜寻到各个不同省份的带有背景的车牌图片,并利用Python的第三方库pillow对该部分数据进行雾霾增强,效果如图13所示。这部分数据共13 857张。CCPD数据集可根据其文件命名规则得到对应的标签。对于没有标签的数据,利用labelmg对图片进行标注,生成xml文件,然后用Python脚本将xml文件转化成txt文件。

图12 CCPD-Weather数据集Fig.12 CCPD-Weather dataset

图13 雾霾增强前后的图像对比Fig.13 Comparison of the images before and after haze enhancement
LPRNet部分的数据是根据CCPD命名规则将车牌图片在原始带有背景的图片上裁剪出来,同时根据命名规则将图片名转换成车牌字符,除安徽省外其余省份的图片通过在网上搜寻得到,共搜集到36 715张,同样也对该部分数据进行了雾霾增强。
两部分实验都将数据按8∶1∶1划分为训练集、验证集和测试集。
6.3 网络模型评价指标
本文对网络模型的评价指标主要包含精确率(Precision,P)、召回率(recall,R)、各个类别平均精确率(AP)的平均值(mean Average Precision,mAP)。计算公式如式(18)~(20)所示:
其中:TP表示真实值为正例且预测为正例的样本数量,FN表示真实值为正例且预测为负例的样本数量,FP表示实际负例预测为正例的数量,AP表示平均准确率,N为总类别数。mAP由单类别精确率AP求和后再求均值得到。
6.4 实验结果及性能分析
在车牌检测网络训练完成后,会生成results.csv来保存训练过程中的数据。利用Origin软件对数据进行可视化展示,精确率、召回率、IOU阈值为0.5的平均精准度与训练轮次的关系如图14所示。消融实验如表2所示。
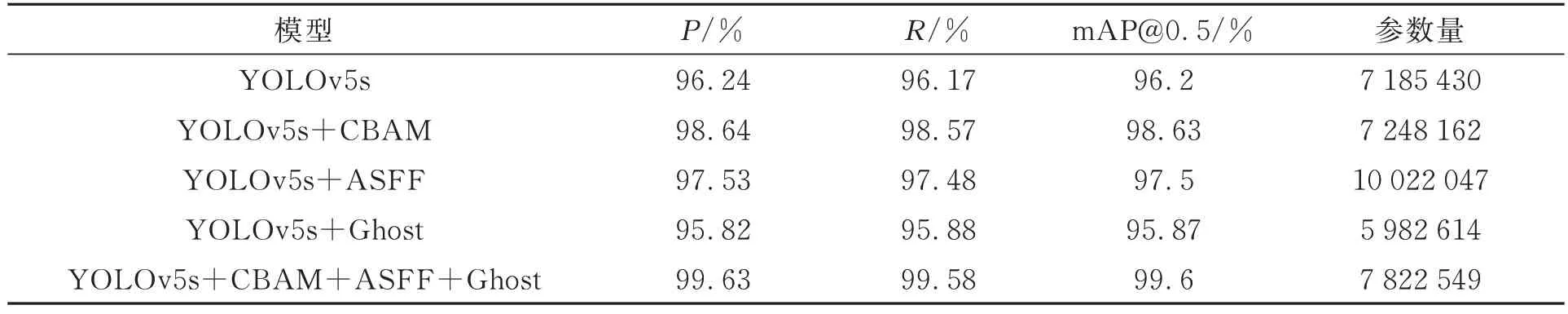
表2 车牌检测部分消融实验Tab.2 Partial ablation experiment of license plate detection

图14 训练模型参数对比Fig.14 Comparison of training model parameters
本文利用检测网络生成的权重文件对测试集进行测试。由图14和表2可知,原始的YOLOv5s模型的P、R、mAP@0.5分别为96.24%、96.17%、96.2%。改进后的网络模型ACG_YOLOv5s相比于原YOLOv5s模型mAP提升了3.4%,达到99.6%,且P和R都有一定程度的提升。YO-LOv5s网络在加入CBAM注意力机制后,相比于原YOLOv5s模型mAP@0.5提升了2.43%,因此CBAM注意力机制对模型效果的提升发挥了很大的作用。原YOLOv5s网络在引入ASFF模块后,相比于YOLOv5s网络mAP@0.5提升了1.3%。ASFF模块的引入虽增加了参数量,达到了10 022 047,但同时提升了模型的性能,因此本文保留了ASFF模块,并用Ghost模块降低了引入ASFF模块带来的参数量增加问题的影响,使得目标检测在维持良好效果的前提下参数的计算量大幅减少。由表2可以看出,在YOLOv5s网络中引入Ghost模块之后,P、R、mAP@0.5相比于原YOLOv5s网络有所下降,但很大程度上减少了参数量。
主流检测网络不同算法实验结果对比如表3所示。由表3可知,与Faster-RCNN、YOLOv3、YOLOv4、YOLOv5S相比,本文的检测准确率和mAP@0.5都有一定的提升。本文的权重文件大小是Faster-RCNN的1/24,是YOLOv3的1/17,在提升检测效能的同时减少了模型的内存占比,适合将其部署到嵌入式等设备。本文提出的ACG_YOLOv5s网络模型与原YOLOv5s相比,检测速度有所下降,但可满足实际应用的需要。

表3 主流检测网络性能比较Tab.3 Comparison of mainstream detection network performance
为了避免对定位到的车牌进行分割,本文重新训练了LPRNet网络,实现了免分割车牌字符识别。用LPRNet部分的数据集对LPRNet训练所得模型进行测试,准确率可达96%。最后分别在无雾和有雾的环境下测试,测试结果如图15、16所示。可看出本文方法不仅可识别清晰的车牌图像,而且在原始图片使用AOD-Net算法对车牌图像去雾之后,图像变得清晰,经过车牌检测网络和字符识别网络可对车牌号码进行正确识别且达到了较高的准确率。

图15 清晰图像车牌识别结果Fig.15 Recognition results of license plate with clear image

图16 雾霾图像测试结果Fig.16 Test results of foggy images
7 结论
本文提出了基于深度学习的车牌识别算法,可对清晰图像以及雾霾天气下的车牌图片进行检测和识别。先用AOD-Net算法对图像进行预处理,得到去雾后的图像;然后用ACG_YOLOv5s网络对车牌进行检测;最后用LPRNet对车牌进行识别。对YOLOv5网络改进如下:首先在YOLOv5网络颈部加入CBAM注意力机制,提高模型的抗干扰能力,让网络加强对关键特征的提取。其次用ASFF模块替换原YOLOv5网络中的PANet结构,赋予3层输出检测层上的特征图不同的权重,加强对小目标的检测。最后将网络中的传统卷积替换为Ghost卷积,在保持原模型效果的同时减少网络训练过程中的参数。
实验结果表明,ACG_YOLOv5s相比于原YOLOv5s模型,mAP提升了3.4%,可达99.6%。LPRNet的识别准确率达96%。两个模型总大小为15.72 MB,所占内存空间较小。由于本文收集到的31省的雾霾天气下的车牌数据相较于CCPD等大型数据集较少,学习到的车牌字符的特征有限,下一步将继续增加数据集,争取进一步提升车牌的识别准确率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年12期)2019-07-16
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
电视技术(2014年19期)2014-03-11
