
健身行为的人体姿态估计及动作识别
2024-03-05 08:15付惠琛高军伟车鲁阳
液晶与显示 2024年2期
付惠琛, 高军伟*, 车鲁阳
(1.青岛大学 自动化学院, 山东 青岛 266071;2.山东省工业控制技术重点实验室, 山东 青岛 266071)
1 引言
人体姿态估计和动作识别在社会安防、医疗防护和运动健身等领域有重要的应用价值[1-2]。在安防监控领域,可以帮助提醒潜在的犯罪行为或危险情况,在捕捉到危险事故时可以及时给出警示以防止事态恶化,同时极大地减少监控人员的工作量。在医疗保健领域[3-4],可以在患者康复过程中给予帮助,并在患者发生跌倒等意外情况时及时检测和预警,极大地缩短获得医疗救护的时间,尽可能地保障人们的生命安全。在运动健身领域,可以帮助识别动作,提取动作特征,进行动作评估和指导,从而帮助改善人们的运动姿态,提高运动效果以及防止因运动姿势错误而产生的运动伤害[5-7]。
早期的人体姿态估计主要采用模板匹配的方法,通过建立不同姿态的模板与检测目标进行对比,分析两者特征的异同,推断检测目标中人体骨骼关节点的位置[8-9]。随着深度学习的发展,卷积神经网络被广泛运用到目标检测和姿态估计问题中[10-13],其中又分为基于概率热力图和坐标点回归这两种方法。基于概率热力图的方法是对检测图像中的每一个像素点用高斯分布的叠加进行概率估计,将原始图像编码成概率分布热力图,在热力图中越是符合关键点特征的位置其概率值越高。随后将概率分布热力图解码成原始检测图像,得到原始图像中的骨骼关节点的空间坐标,其中又分为自低向上和自顶向下两种方法[14]。
基于坐标点回归的方法是直接在原始目标图片上学习目标特征,直接得到目标的骨骼关键点的位置。文献[15]采用了自底向上的openpose网络模型,采用了MobileNets轻量化网络,使模型能够快速地检测宇航员的操作姿态。虽然检测计算速度较快,但在实际应用中,自底向上的方法受复杂的环境和遮挡的影响较大。文献[16]采用了自顶向下的alphapose模型,采用了Track-Net算法评估球员的运动状态。虽然检测的精度较高,但是计算量过高,检测时间较长,难以做到实时检测。
本文针对复杂的健身动作识别,采用基于坐标点回归的YOLOv7-POSE算法作为框架,在原本只有姿态估计功能的网络中加入了动作分类的功能,并引入CA注意力机制,将通道注意力沿两个空间方向分解并聚合特征,有效地强化了网络对人体动作特征的学习。引入了HorNet网络结构替代原模型中的CBS卷积核,通过门控卷积和递归结构实现特征的空间交互,在减少计算量的同时提升检测性能。将主干网络中的空间金字塔池化结构替换为空洞空间金字塔池化结构,在提升识别精度的同时加快了收敛速度。将模型中目标检测部分的CIOU损失函数更改为EIOU损失函数,将CIOU中的预测框的长宽比损失项拆分为预测框与锚框长框的差值,加速了损失收敛并提高了坐标回归的精度。
2 主干网络及结构改进
2.1 YOLO-POSE网络
不同于基于概率热力图的方法,YOLO-POSE省略了将原始图像编码成热力分布图的步骤,直接端对端地训练模型,大幅提升了训练和推理的速度。将人物目标检测和人体关键点估计在同一个框架中进行组合,采用了多尺度预测的策略,将一个人物的所有关键点与目标检测的锚框相关联,在完成姿态估计任务的同时不引入大量的计算量。其网络结构如图1所示。

图1 YOLOv7-POSE结构图Fig.1 YOLOv7-POSE structure diagram
YOLOv7-POSE的主要网络结构由Backbone主干网络和Head区组成,最基本的卷积核为CBS卷积核。多个基础的CBS卷积构成了高效聚合网络ELAN结构。ELAN结构通过在输入和输出端之间添加短路径的连接以及对网络层权重的调整,能够控制梯度路径的长短,从而保留更多的特征信息,从输入的图片中提取出重要的特征,能够提高训练效率,加快收敛速度。图2(a)和图2(b)分别是输入ELAN结构的图像以及ELAN网络结构提取的部分特征图。

图2 ELAN特征提取图Fig.2 Extraction diagram of ELAN feature
Backbone层输入的信息经由Head层中PANet网络融合各个尺度的特征,最后每个Head层的输出会连接两个解耦头用来预测人物目标框和人体关键点,其输出结果为人体目标以及每个人体上的17个关键点,具体部位如图3所示。

图3 YOLOv7-POSE的17个人体关键点Fig.3 17 key points of the human bod有of YOLOv7-POSE output
每个检测目标框由锚点横坐标Cx、锚点纵坐标Cy、预测框的宽W、预测框的高H以及检测框置信度boxconf和类别置信度classconf六个数据所确定。每个关键点由横坐标、纵坐标和置信度三个数据元素所确定,因此网络对每个目标人物,目标框检测头要预测6个元素,关键点检测头要预测51个元素,共需要预测57个元素,如式(1)所示:
2.2 CA注意力机制
CA注意力(Coordinate Attention)的结构如图4所示。与传统通道注意力机制不同,CA注意力将通道注意力沿两个空间方向分解成两个一维特征,一个方向关注特征的通道间的信息,另一个方向关注特征的位置信息[17]。

图4 CA注意力机制结构图Fig.4 Structure diagram of CA attention mechanism
SE(Squeeze-and-Excitation)等传统的注意力采用了全局池化的方法获取通道关系信息,但是难以获取位置信息[18],针对这种情况,CA注意力机制分别使用尺寸为(H,1)和(1,W)的两个池化核将输入信息x沿横纵坐标方向对每个通道进行编码,将输入量进行分解成两个一维特征和,得到的第c维的特征输出结果如式(2)和式(3)所示。
随后将输出的中间特征f分别在横纵两个方向上分解,得到两个独立的中间特征f h和fw,并分别使用一个1×1的卷积和sigmiod激活函数σ进行变换使其维度与最初的输入相等,从而得到特征gh和gw,如式(5)和式(6)所示。
最后将上一步的输出gh和gw合并最终得到了CA注意力机制的输出,如式(7)所示。
通过对通道和位置特征的关注,CA注意力能加强网络对特征的学习,提高检测精度,同时参数量较小,不会影响模型的推理速度。
2.3 HorNet网络
HorNet网络借鉴了Transformer的动态权重、长距离建模以及高阶空间交互等特点[19],采用了高阶的门控卷积以及递归设计来实现高阶空间交互,从而强化了网络的模型容量,获得了与Transformer相似的自适应空间混合能力。HorNet的引入使得网络在不增加额外计算量的情况下获得精度提升,因此本文用HorNet代替YOLOv7-POSE中的CBS卷积核,HorNet结构如图5所示。
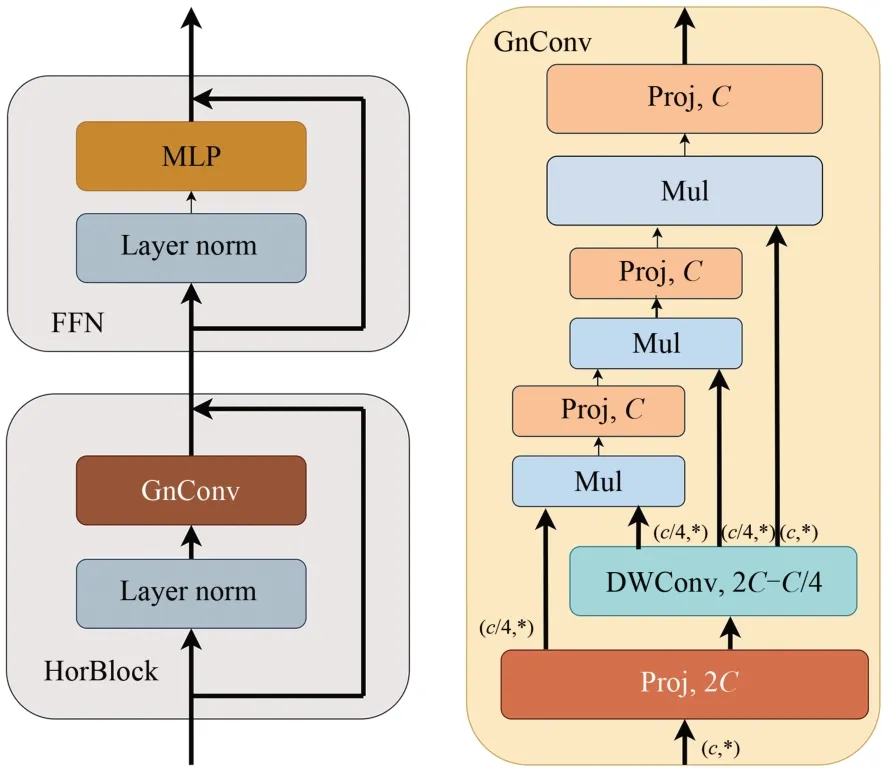
图5 HorNet结构图Fig.5 HorNet structure diagram
图5左侧为门控卷积GnConv,其内部运算操作包括卷积、线性投影以及元素积,其输入输出关系如式(8)所示,其中x、y分别为门控卷积的输入输出特征。首先将输入x进行线性投影运算φ得到T0、P0,将P0做卷积运算并与T0进行点积运算得到T1从而完成一阶空间交互。
高阶空间交互与一阶交互类似,首先对输入x进行线性投影,求得投影特征T0和P如式(9)所示,随后将投影特征依次送进门控卷积中进行递归运算,如式(10)所示,并通过将每次的输出特征缩小a倍来平缓训练过程。式(10)中的gk是维度映射函数,能够保证空间交互过程中的维度始终相等,gk函数如式(11)所示。
最终的递归输出Pn会再次进行线性投影从而得到GnConv的结果,同时对每一阶的通道数进行约束,如式(12)所示,来保证高阶空间的交互运算不会带来过多计算量。以此来确保总运算量是有界的,其上界如式(13)所示。
2.4 空洞空间金字塔池化
空间金字塔池化结构可以在对图片进行放缩和剪裁处理时防止图片发生失真,从而使得特征网络的输入端能够接纳任意宽高比的图片[20]。
空洞空间金字塔池化能在扩大感受野的同时,不降低输入图片的分辨率[21],在帮助提高检测人体大目标的同时,也能更加精确的估计骨骼关键点的小目标,非常适合人体姿态估计任务。本文将YOLOv7中原有的空间金字塔池化结构替换为空洞空间金字塔池化结构,空洞空间金字塔池化结构如图6所示。
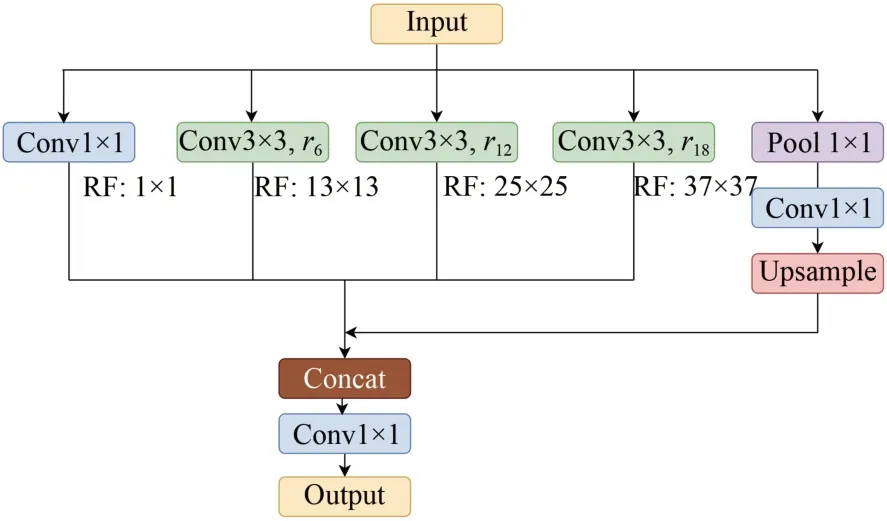
图6 空洞空间金字塔池化结构图Fig.6 Structure diagram of space pyramid pool
空洞空间金字塔池化结构具有4个并行的且采样率不同的空洞卷积层,这些采样率不同的卷积层会形成不同的感受野,从多个尺度获取图片中的特征信息,再对各个空洞卷积层提取到的特征进行融合,得到了最终的特征提取结果[21]。
2.5 边界框损失函数
YOLOv7-POSE中的目标边界框损失函数采用了CIOU损失函数,其计算公式如式(14)所示,其中IOU是真实框与预测框的交集面积与并集面积的比值,如式(15)所示,其中b与bgt分别表示预测框和真实框中心点的坐标位置,ρ(b,bgt)是两个中心点的欧式距离的平方,c2是预测框与真实框所组成的最小闭区域的对角线的长度,w和h是框的宽和高,α是权重系数,v是预测框与真实框宽高比的惩罚项。
CIOU损失函数结合了真实框与预测框的重合面积、中心的欧氏距离并且考虑到了中心点重合并且宽高比不同的情况[22]。但是在式(16)中没有考虑宽和高与置信度的直接差异,增加了纵横比的相似性,减缓了收敛速度,阻碍了网络模型有效地减少预测框和真实框之间的差异。本文引入了Yi-Fan Zhang提出的EIOU边界框损失函数,如式(18)所示[23]。EIOU舍弃了CIOU中复杂且定义不明的惩罚项v,并用欧式空间距离来表示独立的宽和高的损失项,解决了模型训练时纵横比相似性带来的阻碍,有效提高了收敛速度,提高了边界框的回归精度。
3 实验与结果分析
3.1 实验环境
本文的模型训练在Win10和Python3.9环境下进行。使用Pytorch 1.12.1作为深度学习框架,并使用了CUDA11.3硬件加速工具。实验使用了NVIDIA RTX3080 GPU,Intel(R)Core(TM) i7-12700KF@3.60 GHz处理器,设备内存为32.0 GB。
3.2 数据集的准备
本文针对健身动作人体姿态估计及动作分类的任务,组织同学在不同背景下,从不同角度拍摄了健身运动中的6种常见动作,并采用LabelImg软件自行标注了动作数据集16 000余张,分为俯卧撑(Push up)、躺姿抬腿(Lying Leg Raise)、盘腿坐(Sit in Meditation)、臀桥(Glute Bridge)、深蹲(Squatting)、压腿(Leg Pressing)6种类别,并将训练集、测试集和验证集按照8∶1∶1的比例进行划分,训练批次为16,学习率为0.005,模型迭代120轮。数据集中各类别具体数量如表1所示。
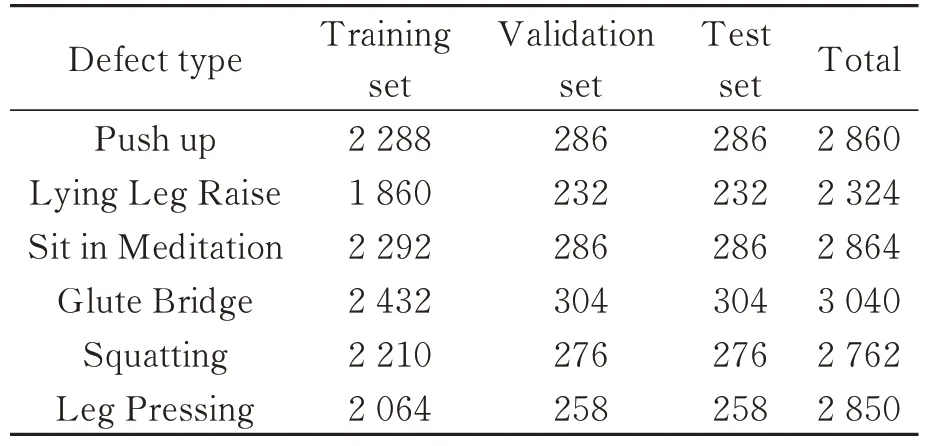
表1 数据集中的目标分类及数量Tab.1 Classification and number of targets in the data set
3.3 模型评估指标
对于人体关键点估计任务,不能只是简单地通过真实点与预测点之间的欧氏距离来衡量估计的精度,而是要为不同类型的点赋予不同的加权值,计算真实点与预测点之间的相似度。本文针对人体姿态估计任务采用了关键点相似性指标OKS、平均精度AP和均值平均精度mAP评估网络模型的预测点与真实点的相似度,并用混淆矩阵评价动作分类的准确度。
目标关键点相似度OKS计算方式如式(19)所示:
其中:p表示检测图片中人物的编号;pi表示该人物的骨骼关键点编号;vpi表示该关键点在图片上的可见性,vpi=0表示该关键点未标注,vpi=1表示该关键点不可见,vpi=2表示该关键点可见;dp表示真实点与预测点之间的欧式距离,dp的值越小表示该点预测的效果越好,即距离dp与oks指标成反比;Sp表示识别该人物的目标检测框所占面积的平方根,当距离dp相等时,目标人物面积越小则预测的效果越好,即Sp与OKS指标成反比;σi度量不同关键点的标准差,是对现有的数据集中所有关键点进行计算得到,表示不同关键点对人体整体的影响情况,σi的值越小,表示该点对数据集整体的影响效果越好。
最后通过归一化使关键点的欧式距离dp、人体目标的面积Sp、标注偏移σ与OKS的增减性与上述分析保持一致。
平均准确率(Average Precision,AP)是预测的结果在验证集上的平均准确率。如式(20)所示。给定OKS一个阈值s,若某关键点的OKS值大于s则认为该点成功检出,否则认为该点错检或误检。
平均准确率均值(mean Average Precision,mAP)通过给定关键点不同的阈值,计算不同阈值情况下对应的AP并进行平均计算。
对于动作分类任务,本文沿用了混淆矩阵作为评估指标。混淆矩阵是分类任务中的常用指标,矩阵中元素表示了各类别的检测分类情况。矩阵中每列的类别为网络对各个类别的预测分类,每行的类别表示数据集中的正确类别。每列中的元素表示网络在分类预测中,将数据集中真实的各个类别分类到该列对应的类别的数量;每行中的元素表示数据集中该行的真实的类别样本在网络分类预测中被分类到各个类别的数量。
3.4 实验设计
为了验证改进后的算法对人体姿态估计以及动作分类的检测效果及改进部分对性能的提升情况,本文进行了4组对照实验。
第一组实验用热力图对引入CA注意力机制前后的模型进行检验,验证CA注意力机制的效果。
第二组实验将HorNET结构的模型复杂度与原始模型及Swin Transfomer结构进行对比,验证HorNET是否优于原始卷积及Swin Transfomer结构。
第三组进行消融实验,把本文算法逐个剔除各个改进部分并依次进行训练,并将训练后的mAP指标与原始算法、本文改进算法以及数据集格式相同的主流算法High-Resolution Net进行对照,验证各个改进部分对姿态估计性能的提升效果。
第四组实验首先比较改进后的算法与原始算法的混淆矩阵,验证在分类功能上的提升效果;随后在验证集上采用随机抽样检测的方法,抽取验证集中的图像进行实际检测效果的比较。
3.5 损失函数收敛对比
改进前后的YOLOv7-POSE的验证集损失函数对比如图7所示。图7中曲线A为原始的YOLOv7-POSE损失函数,曲线B为改进后的损失函数。从图7中可以看出,改进前模型的损失函数在初始约20轮的曲线下降较快,且曲线波动较大。在训练60轮之后,波动趋于平缓,损失函数逐渐减小。在训练约100轮时,损失函数逐渐稳定,模型逐渐收敛。而改进后模型的损失函数在训练约50轮趋于平缓,在训练约80轮时损失函数逐渐稳定。由此可见,改进后算法的损失函数收敛更快,且收敛后损失函数的值更低。

图7 损失函数对比Fig.7 Example of dataset images
3.6 对比实验
为了验证CA注意力的效果,采用Grad-CAM可视化结构对引入CA注意力前后的模型进行对比验证,对比结果如图8所示。图8(a)和图8(b)分别是引入CA注意力前后的模型验证图。可以看出,引入了CA注意力后,模型能更好地聚焦于人体区域。

图8 特征关注对比图Fig.8 Feature focus contrast diagram
各个模型的模型复杂程度如表2所示,由表中数据可得,HorNet网络结构的引入提升了模型精度,同时降低了模型的参数量以及计算量。而引入Swin Transfomer结构之后,虽然能够提升模型精度,但模型的大小、参数以及计算量大幅提升,因而在本检测任务中,HorNet结构优于原始结构以及Swin Transfomer结构。

表2 不同改进的模型复杂度Tab.2 Different improved model complexity
本文通过对原始模型和各类改进方法的检测指标以及数据集格式相同的High-Resolution Net算法进行对比来设计了消融实验,来验证改进部分对算法性能的提升效果,表3为引入不同改进方法后算法的检测指标。由表3数据可得,YOLOv7-POSE-E引入表中所有改进项,mAP值达到95.7%,比High-Resolution Net高4.2%,比原始YOLOv7-POSE提高了4%。YOLOv7-POSE-A在YOLOv7-POSE-E的基础上去掉了CA注意力机制,mAP值为94.8%,比原始YOLOv7-POSE-E下降了1.3%。YOLOv7-POSE-B在YOLOv7-POSE-E的基础上去掉了HorNet结构,mAP值为93.6%,比YOLOv7-POSE-E下降了2.1%。YOLOv7-POSE-C在YOLOv7-POSEE的基础上去掉了空洞空间金字塔池化,mAP值为94.2%,比YOLOv7-POSE-E下降了1.5%。YOLOv7-POSE-D在YOLOv7-POSE-E的基础上去掉了EIOU损失函数,mAP值为95.4%,比YOLOv7-POSE-E下降了0.2%。可以得出引入的各个改进项能带来精度的提升。

表3 不同改进方法的性能指标Tab.3 Performance index of different improvement methods
3.7 改进前后网络的动作分类性能对比
改进前后网络的混淆矩阵分别由图9、图10所示。对比可见,改进后网络的躺姿抬腿类别的分类准确率提高了15%,臀桥类别的分类准确率提高了13%,压腿类别的分类准确率提高了13%。改进后的动作分类性能显著提升。

图9 原始网络的混淆矩阵Fig.9 Confusion matrix of original network

图10 改进后网络的混淆矩阵Fig.10 Confusion matrix of the improved network
训练结束后,将改进前后的模型在测试集上推理测试,测试集中也包含了各类复杂背景下不同角度拍摄的动作,部分测试集中的结果如图11和图12所示。图11为测试集在增加了分类功能的原始网络模型上的部分推理结果,图12为测试集在改进后网络模型上的部分推理结果。由图11(a)和图12(a)对比可得,改进前的模型在侧面躺姿抬腿图中的左髋、左膝和左踝3个关键点处的偏差较大;而改进后模型对上述3点的估计偏差明显减小,且算法置信度有所提升。由图11(b)和图12(b)对比可得,改进前模型在侧面臀桥图上漏检了左肩和右手腕处的关键点;而改进后模型对该图中的左肩和右手腕处关键点正确地进行了估计。由图11(c)和图12(c)对比可得,改进前模型在上侧面臀桥图中整体关键点估计偏差较大,且把改图错误的分到了躺姿抬腿类别中;而改进后模型对该图中的关键点估计整体偏差较低,并将其正确地分类为臀桥类别,且置信度较高。由图11(d)和图12(d)对比可得,改进前模型在侧面俯卧撑图中对左膝和左踝两处关键点的估计偏差较大,且整体置信度偏低;而改进后模型对该图中所有关键点正确地进行了估计且置信度较高。由此可见,改进后模型对关键点估计和分类的效果有所提升。尤其对于臀桥类别,改进前模型的关键点估计偏差较高,分类精度较低,而在改进后模型的关键点估计和动作分类情况均有较大提升。

图11 原始网络模型的识别效果Fig.11 Recognition effect of original network model

图12 改进后网络模型的识别效果Fig.12 Recognition effect of improved network model
4 结论
针对健身行为的人体姿态估计和动作识别问题,本文提出了一种改进的YOLOv7-POSE姿态估计及动作识别算法,通过自行拍摄不同环境下各种角度的健身动作制作了数据集。在原始YOLOv7-POSE网络中添加了分类功能,并引入了CA注意力机制,沿两个空间方向分解了通道注意力并对其进行聚合特征,强化了网络模型对人体动作特征的学习。引入了HorNet结构替代原模型中的CBS卷积核,强化了网络的模型容量,减少了网络模型的计算量并提高了关键点的估计准确率和动作识别。根据人体姿态估计要同时检测人体大目标和估计关节点小目标的任务,将主干网络中的空间金字塔池化结构替换为空洞空间金字塔池化结构,在不降低识别精度的同时加快了收敛速度和识别速度。将模型中目标检测部分的CIOU损失函数更改为EIOU损失函数,加速了损失收敛并提高了坐标回归的精度。改进后网络相比于原始网络,mAP值提高了4%,躺姿抬腿类别的分类准确率提高了15%,臀桥类别的分类准确率提高了13%,压腿类别的分类准确率提高了13%,关键点错检、漏检的情况显著减少。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
中国卫生(2014年2期)2014-11-12
