
基于KPCA-PSO-ELM算法的地表水化学需氧量紫外-可见吸收光谱检测研究
2024-03-07 01:50郑培超周椿棪王金梅尹义同曾金锐何雨欣
光谱学与光谱分析 2024年3期
郑培超, 周椿棪, 王金梅, 尹义同, 张 莉, 吕 强, 曾金锐, 何雨欣
重庆邮电大学光电工程学院, 光电信息感测与传输技术重庆重点实验室, 重庆 400065
引 言
随着社会和工业发展, 大量生产生活废水直接排入地表水域中, 造成严重污染。 由水污染带来的问题已经严重影响社会发展。 化学需氧量(chemical oxygen demand, COD)是水质检测的重要指标, 用于表征水体有机物含量。 化学需氧量越大, 说明水体污染越严重, 对生物危害越大。 目前, 化学需氧量检测方法主要是重铬酸钾耗氧量(CODcr)和高锰酸钾耗氧量(CODMn)等实验室化学方法。 传统化学方法存在分析时间长、 二次污染等缺点, 难以满足实际场景下的检测要求。 为了防止水体污染继续加重, 亟需发展一种水质COD的快速、 实时检测方法。
近年来, 由于光谱法快速、 无污染等优点, 被广泛应用到水质检测中。 针对水质污染物常用的光谱检测技术有荧光光谱、 近红外光谱及紫外吸收光谱等[1-4]。 其中, 紫外-可见吸收光谱(UV-Vis)作为一种高效、 实时、 精确的光谱方法。 通过测量水体吸光度实现水质COD的定量分析, 是当前水质检测中运用最为广泛的光谱技术之一[5-7]。
目前, 使用紫外吸收光谱进行COD的检测多采用基于单波长和多波长的方法, 采用COD在其某些特定波长下的吸收峰实现其定量分析。 Mai等[8]采用吸收光谱在254 nm处的吸光度结合偏最小二乘回归和主成分回归对印染废水COD进行检测, 将结果相对误差控制在5%以内。 方坷昊等[9]采用COD在240~300 nm波段内的特征波长和560 nm处的特征波长建立非线性预测模型, 标准溶液预测结果误差控制在3.5%内。 Zhang等[10]采用400和600 nm处斜率对紫外-吸收光谱的一阶导数光谱进行补偿, 将PLS预测模型R-squared(R2)提升至0.99。 然而, 实际水体组分复杂, 存在浊度、 色度等干扰, 单波长或多波长模型难以满足预测的需求[11-13]。
基于全光谱的化学需氧量检测方法, 逐渐成为当前研究热点。 张峥等[14]使用主成分分析对全光谱数据进行压缩, 并联合粒子群优化极限学习机(particle swarm optimization extreme learning machine, PSO-ELM)算法对COD进行检测, 较ELM模型运行效率提升了一个量级。 Li等[15]使用改进的bagging算法对全光谱数据建模, 测试集R2达到了0.931 7, RMSEP降低到5.39 mg·L-1。 对于实际水体的检测, 全光谱预测模型较单波长和多波长预测模型具备良好的抗干扰能力和较高的预测精度。 基于全光谱数据模型存在信息冗余、 高特征维度、 干扰复杂等缺点, 会导致模型无法收敛或过拟合。 对光谱信息进行预处理和数据压缩方法直接影响全光谱吸收光谱法对COD的预测精度。
由于实际水体成分复杂, 紫外-吸收光谱存在非线性变化。 内核主成分分析作为一种非线性数据压缩方法, 可以有效处理线性不可分的数据集。 本工作提出了一种基于内核主成分分析的全光谱水体化学需氧量检测方法。 使用内核主成分分析对全光谱数据进行压缩, 建立基于粒子群优化的极限学习机回归模型, 以实现对COD快速、 实时检测。
1 实验部分
1.1 装置
实验装置如图1所示, 主要包括光源、 光谱仪、 样品槽、 光纤等。 光源采用氘卤灯(爱万提斯, Avalight-Hal-Cal-Mini), 光源的出射光经光纤耦合到10 mm×10 mm×30 mm石英比色皿。 产生的透射光经光纤光谱仪(复享光学, NOVA)接收。 采集到的光谱数据传输到计算机中进行数据处理与建模。
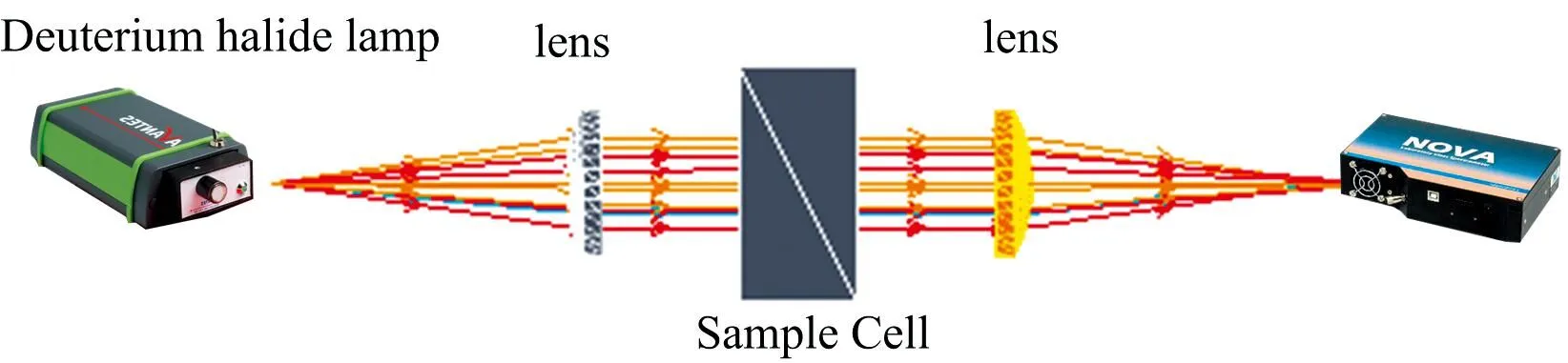
图1 实验装置示意图
1.2 样品
采集了重庆主城内长江、 嘉陵江、 盘龙溪、 白溪、 白云水库、 丰收水库所采集到的6类地表水共217个样本。 所有样本经实验室化学法(CODMn)测定后, 作为光谱法建模结果的参考。 采用紫外-可见吸收光谱对水体有机物定量分析的理论基础是朗伯-比尔定律, 不同的有机物有不同吸收峰, 不同浓度的污染物吸收强度也不同。 图2是以去离子水为参比, 待测样品所采集到的紫外-可见吸收部分光谱, 可以看出吸收段主要集中在400 nm之前, 吸收峰在200 nm附近。

图2 地表水紫外-可见吸收光谱
1.3 数据处理
光谱数据处理流程如图3所示。 将数据按照7∶3的比例随机划分成训练集和测试集, 然后对训练集和测试集的光谱数据进行去噪、 增强、 特征提取等处理, 对训练集光谱数据进行回归模型训练, 得到光谱-COD浓度的反演模型; 再将测试集的光谱数据输入训练集的反演模型, 进行光谱数据与COD浓度反演, 获得测试集的COD浓度。

图3 光谱数据处理流程
1.3.1 光谱数据预处理
光谱数据中既有信息, 同时又包含了噪声。 采用Savitzky-Golay(SG)滤波算法对光谱进行滤波处理, 可以有效抑制随机噪声, 提高信噪比。 原始输入数据用给定的多项式的拟合值代替, 对每个数据反复此操作, 直到得到所有数据的平滑值[16]。 采用窗口大小为21、 多项式阶数为3的SG滤波, 滤波算法也可以看作是一种加权平均的过程。 为了降低由于信号波动带来的影响, 再将滤波后每个波长下的吸光度用区间积分值代替, 即每一个点的值都用该点前后10个点的积分值代替。 不同样本光谱数据积分后, 会产生数据量纲带来误差, 还需要将所有光谱数据进行归一化。 经过滤波、 增强和归一化等预处理后的数据较未处理的光谱更为平滑, 此时不同样本在此吸收段内的区别更明显, 如图4所示。

图4 预处理后紫外-可见吸收光谱图
1.3.2 核主成分分析算法
内核主成分分析(kernel principal component analysis, KPCA)作为主成分分析(principal component analysis, PCA)改进算法, 是一种针对非线性数据的特征压缩方法。 KPCA借助映射函数将数据从原始空间映射到高维特征空间H中, 使得数据在高维空间中可分[17],H中映射函数数据的协方差矩阵表示为式(1)
(1)
计算协方差矩阵CH的特征值和特征向量, 其特征值为λ, 特征矢量β。 此时定义矩阵M=[Mi,j]n×n,Mi,j=(φi)·(φj), 可通过核函数来确定。βk是β的第k个特征矢量, 对其进行归一化处理, 即βkβk=1则可得到原始空间中任意一样本x的映射数据φ(x)在特征矢量βk上的投影为式(2)
(2)
将映射数据中心化得到数据第k维的非线性主成分为式(3)
(3)
1.3.3 粒子群优化算法
粒子群优化算法模拟鸟群觅食行为, 每个粒子都代表种群中的个体。 每个粒子初始位置都是随机, 通过不断迭代从潜在解中找到当前最优解[18-19]。 计算每次迭代后适应度函数以更新个体和群体极值。 粒子群优化算法中粒子速度和位置的更新公式如式(4)和式(5)
Vid(t+1)=wvid(t)+c1r1[Pid-Xid(t)]+
c2r2[gid-Xid(t)]
(4)
χid(t+1)=χid(t)+vid(t+1)
(5)
式(4)和式(5)中,w为惯性权重,c1和c2分别为个体和群体的学习因子,r1和r2为[0, 1]之间随机数。 通过不断迭代确定粒子的最优解。 权重w设置为0.6, 学习因子c1,c2设置为2。
1.3.4 极限学习机算法
假定存在N个不同样本(xi,yi), 其中特征xi∈Rn, 标签yi∈Rm, 具有K个隐含层节点前馈神经网络输出可以表示为
(6)
式(6)中,G(x)为网络的激励函数,αi是第i个连接输入层到隐含层节点的权值,bi则是第i隐含层节点的偏差,βi是第i个连接隐含层节点到输出的权值。 若存在K个隐含层节点的前馈神经网络能以零误差逼近全部个样本, 则存在αi,bi,βi使得式(7)和式(8)成立
(7)
Wβ=Y
(8)

(9)
式(9)中,W+为隐含层输出矩阵W的Moore-penrose广义逆。
1.3.5 KPCA-PSO-ELM回归模型
ELM的初始输入权值和隐含层偏差是随机给定的, 而输出权值矩阵则是由输入权值矩阵和隐含层偏差计算得到, 通常会导致部分隐含层节点失效; 在实际应用中ELM可能需要设置一定数量的神经元才能达到理想的精度。 因此采用粒子群优化算法对ELM的输入权值矩阵和隐含层偏差进行优化, 可以得到最优的神经网络。 对于模型中隐含层神经元, 一般问题设置为20~40, 此处设为30, 将RMSE作为适应度函数, 即模型的评价指标。 使用KPCA对预处理过的光谱数据进行压缩, 再将数据输入到ELM模型中, 最后使用PSO对ELM模型进行优化, KPCA-PSO-ELM流程图如图5所示。

图5 KPCA-PSO-ELM流程图
2 结果与讨论
图6给出了利用KPCA-PSO-ELM模型的参数优化结果。 由图6(a)可以看出, 采用KPCA对光谱数据进行压缩, 方差贡献率随着主成分数量增加快速上升, 在第5个核主成分时候方差累计贡献率到达0.999, 内核主成分分析对光谱数据有明显的降维效果。 图6(b)显示粒子群优化算法经过前100次迭代后适应度快速下降到一个稳定值, 200次迭代后不再出现明显下降, 经过500次迭代后模型训练集的RMSE下降至0.363 0 mg·L-1。

图6 KPCA-PSO-ELM模型参数优化
以实验数据建立的KPCA-PSO-ELM模型对地表水COD预测结果, 如图7所示。 可以看出测试集样本包含在训练集中, 训练集拟合优度R2为0.930 2[见图7(a)], 测试集拟合优度R2为0.932 0[见图7(b)], 训练集和测试集R2均在0.93以上, 仅出现了少数几个离群点, 说明该模型性能满足实际检测要求, 泛化性较好, 针对地表水有好的预测结果。
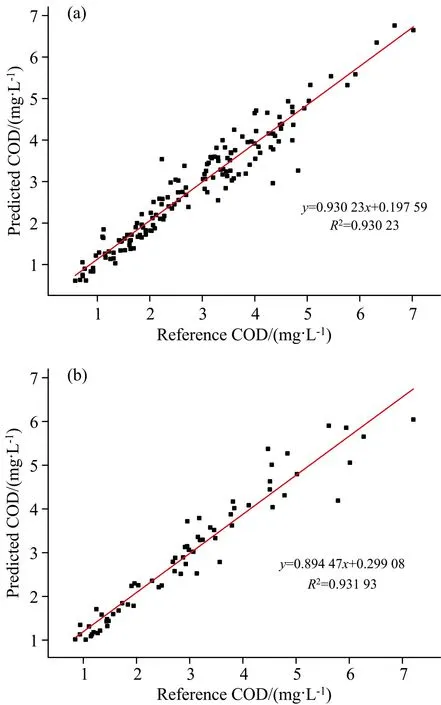
图7 KCA-PSO-ELM模型回归结果
此外, 本文还对比了PCA、 套索回归(least absolute shrinkage and selection operator, LASSO)、 连续投影算法(successive projection algorithm, SPA)光谱数据特征方法在PSO-ELM模型上的表现。 表1为数据经过PCA压缩后的结果, 可以看出第一主成分占据绝大部贡献率, 前5个主成分累计贡献率已经达到99.94%。 选取方差累计贡献率99.9%以上主成分建模。 Lasso返回非零权重的特征, 由于核参数lambda对结果影响极大, 对该参数进行了优化, 结果如图8所示。 SPA保留交叉验证下10个投影最大的特征。

表1 PCA主成分贡献率

图8 Lambda交叉验证曲线
以上四种光谱特征方法在PSO-ELM模型测试集RMSE分别为0.400 7、 0.715 1、 0.473 7和0.412 6 mg·L-1。 由图9可以看出, 基于KPCA特征提取模型的相对误差相比于其他三种模型, 误差波动最小。
表2列出了测试集样本的预测值和参考值以及相对误差。 以上四种特征提取方法模型的相对误差绝对值的均值为9.26%、 17.18%、 11.73%、 11.74%, 其中KPCA仅有一个样本误差超过40%, 证明在此模型中KPCA优于其他三种方法。

表2 测试集样本COD浓度ELM回归预测值
表3为不同特征方法模型的参数比较, KPCA-PSO-ELM模型训练集的RMSE为0.363 0 mg·L-1, 拟合优度R2为0.930 2, 测试集的RMSE为0.400 7 mg·L-1, 拟合优度R2为0.931 9。 KPCA-PSO-ELM模型的训练集和测试集的R2均在0.93以上, 说明所提出的模型优于其他模型。

表3 不同特征提取模型评价参数比较
3 结 论
以地表水COD作为研究对象, 建立了基于KPCA-PSO-ELM结合紫外-可见吸收光谱模型。 对比了ELM模型在PCA、 LASSO、 SPA等特征提取方法下, 模型的表现情况。 基于KPCA-PSO-ELM预测模的训练集和测试集模型R2均在0.93以上, 测试集RMSE为0.400 7 mg·L-1, 相比于其他模型的RMSE分别降低了78.46%、 18.22%、 2.97%。 结果表明, KPCA-PSO-ELM作为一种结合了非线性特征提取算法的预测模型, 能够实现对地表水COD快速、 实时的检测。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
测控技术(2018年10期)2018-11-25
中国资源综合利用(2017年1期)2018-01-22
浙江工业大学学报(2017年5期)2018-01-22
山东工业技术(2016年15期)2016-12-01
中国粮油学报(2016年5期)2016-01-23
中国光学(2015年5期)2015-12-09
食品工业科技(2014年23期)2014-03-11
郑州大学学报(理学版)(2014年3期)2014-03-01
无机化学学报(2014年1期)2014-02-28
