
混合卷积神经网络用于高光谱小麦品种鉴别
2024-03-07 01:51李国厚李泽旭金松林赵文义潘细朋张卫东
光谱学与光谱分析 2024年3期
李国厚, 李泽旭, 金松林, 赵文义, 潘细朋, 梁 政, 秦 莉, 张卫东*
1. 河南科技学院信息工程学院, 河南 新乡 453003
2. 北京邮电大学人工智能学院, 北京 100876
3. 桂林电子科技大学计算机与信息安全学院, 广西 桂林 541004
4. 安徽大学互联网学院, 安徽 合肥 230039
5. 宁波大学信息科学与工程学院, 浙江 宁波 315211
引 言
与可见光图像相比, 高光谱成像技术不仅能够较好地反映种子的形状和大小, 还能够反映样本内部的化学成分差异。 同时, 机器学习和深度学习在计算机视觉领域广泛应用于识别、 分隔、 检测等[1]。 因此可利用该技术辅助机器学习或深度学习进行种子的快速、 高效及无损鉴别[2-4]。 高光谱成像技术能够捕获小麦种子的光谱和空间信息, 深度学习能够充分挖掘和利用高光谱图像内部的像元依赖关系, 进而实现种子的鉴别。
传统的高光谱图像鉴别方法主要以提取数据的光谱特征为主, 但受天气、 光强、 噪声等因素干扰, 所捕获的光谱信息和高光谱图像之间存在非线性, 限制了传统方法的鉴别能力。 Wei等[5]将随机子空间线性判别和高光谱技术应用于大豆品种的无损鉴别, 但其鉴别性能不稳定。 朱启兵等[6]利用支持向量数据描述方法构建高光谱玉米鉴别模型, 分类精度达到92.28%, 并解决了传统分类器对新类别样本的错分问题。 Mahesh等[7]将线性判别分析和二次判别方法结合起来对小麦种子高光谱图像进行鉴别, 但小样本严重制约该模型的鉴别能力。 总的来说, 不足的样本和有限的特征限制了传统鉴别方法的性能。
基于机器学习的高光谱图像分类方法依据光谱特性手动或半自动地提取特征。 例如, Fabiyi等[8]提出一种基于随机森林方法的水稻种子分类器, 将RGB和高光谱水稻图像相结合, 取得良好的分类效果。 Miao等[9]将流形学习算法中的t分布随机邻域嵌入机制引入到高光谱图像分类中, 对8个品种糯玉米种子的分类精度达到97.5%。 Wang等[10]采用高光谱成像技术对四种大豆品种进行分类, 并建立基于全波长的支持向量机分类模型, 分类准确率为95.19%。 Sivakumar等[11]在近红外和短波红外区域使用高光谱成像技术采集豆类粉的光谱数据, 并使用最小二乘判别分析对其进行鉴别, 分类模型精度可达95%。 Shao等[12]采用高光谱成像技术对蜂蜜建立了纯蜂蜜和掺假蜂蜜的样本分析模型, 并使用支持向量机进行分类, 但分类性能欠佳。 张航等[13]使用支持向量机对小麦种子高光谱图像进行分类, 但随着小麦种子的品种增多, 分类精度不断下降。 上述研究表明, 传统方法和机器学习方法都过于依赖光谱信息, 而高光谱图像存储具有“同谱异物性”和“同物异谱性”, 想要准确鉴别变得颇为不易。
基于深度学习的方法结合高光谱技术逐渐应用到种子鉴别领域。 例如: Nie等[14]使用深度卷积神经网络建立了杂交种子品种分类模型, 六种杂交黄秋葵种子和杂交丝瓜种子的分类精度达到95%。 Zhao等[15]使用一维和二维卷积对小麦种子的高光谱图像进行分类, 分类精度为95.65%。 Wu等[16]提出一种带加权损失的深度卷积神经网络, 根据老化时间将高光谱成像的水稻种子分为三类, 为每一类分配适当的权重, 获得的最高精度为97.69%。 Gai等[17]提出一种基于一维卷积神经网络的光谱分析模型对具有瘀伤苹果的高光谱图像进行鉴别, 精度可达95.79%。 Liu等[18]提出一种基于改进ResNet18高光谱图像的大豆品种鉴别方法, 分类精度为97.36%。 Hao等[19]对枸杞的高光谱图像和纹理数据进行融合, 通过选取最佳波长构建不同区域的枸杞光谱鉴别模型, 使用二维卷积神经网络的分类精度可达97.34%。 由此可见, 深度学习相较于传统方法和机器学习, 具有非常明显的优势, 能够较好地解决非线性、 小样本和过拟合等问题。
深度学习是一种对数据进行表征学习的方法, 一般通过无监督或半监督的方式学习数据的特征, 用来取代人工获取的特征。 卷积神经网络具备较强的特征提取和模型表达能力, 又是最典型的深度学习模型之一, 因此本文以不同品种的小麦高光谱图像为研究对象, 基于卷积神经网络提出一种基于注意力机制的三维卷积和二维卷积混合卷积网络模型(attention-based mix convolutional neural network, AMCNN)。 该网络模型中的三维卷积可以提取空间和光谱信息, 但是会增加计算复杂度, 而二维卷积能够提取空间信息和图像纹理信息, 两者的结合能够加强空间和光谱之间的信息融合, 减少复杂度和算法运行时间。 加入注意力机制又能够提取图像纹理信息, 提高了鉴别的准确性。 试验结果表明, 本文提出的方法具有良好的鉴别性能, 为小麦品种鉴别及分类提供了一种新的思路。
1 实验部分
AMCNN的网络框架, 由三维卷积层、 二维卷积层和全连接层组成, 如图1所示。 (1)首先对数据进行预处理, 即感兴趣区域提取、 主成分分析降维和多元散射校正, 然后将处理好的数据输入AMCNN模型。 (2)AMCNN模型的三维卷积层中包括三个三维卷积, 每次卷积运算后添加批次规则化层(batch normalization, BN), 以减少过拟合并加速收敛。 (3)AMCNN模型的二维卷积层中包括三个二维卷积, 在每个卷积操作后引入注意力机制, 它会沿着通道维度和空间维度推断注意力图, 然后将注意力图乘以输入特征图进行自适应特征优化。 Leaky ReLU用于三维卷积层和二维卷积层模块的激活函数, 防止神经元在输入为负时无效, 充分利用三维和二维卷积模块的自动学习特征能力。 (4)AMCNN模型的全连接层使用LogSoftmax作为模型最后一层的输出, 将原本由CrossEntropy Loss损失函数处理的Log工作提到预测概率分布中, 跳过了中间的存储步骤, 防止中间数值的下溢出, 使得数据更加稳定。

图1 AMCNN框架示意图
1.1 混合卷积模块
传统的二维卷积模块中, 卷积仅应用于空间维度, 覆盖前一层的所有特征图, 以计算二维鉴别特征图。 但是高光谱图像需要捕获多个频带中编码的光谱信息及空间信息。 二维卷积无法处理光谱信息。 引入的三维卷积可以从高光谱图像中提取不同光谱间的特征关系, 三维卷积模块首先用于人类行为识别[20], 能够在空间和时间维度中同时捕捉特征, 但增加了计算代价。

(1)


(2)
参数详情如式(1)。
1.2 注意力机制模块
卷积注意力模块(convolutional block attention model, CBAM)[21]是一种简单高效的用于前馈神经网络的注意力模块, 也是一个轻量级通用模块, 所以它可以嵌入任何卷积架构中, 而无需考虑模块损失并进行端到端训练。 主要网络架构是由一个通道注意力模块和一个空间注意力模块组成, 如图2所示。

图2 CBAM模块示意图
通道注意力机制是在空间维度上压缩特征图以得到一维矢量, 然后对其进行操作, 不仅考虑平均池化(average pool), 还考虑最大池化(max pool), 发送聚合特征映射的空间信息到共享网络, 然后压缩输入特征图的空间维数, 最后将MLP输出的特征进行基于element-wise的加和操作, 再经过sigmoid激活操作以生成通道注意力图。 平均池化对特征图上的各像素点都有反馈。 在进行梯度反向传播计算时, 最大值池化仅对特征图中响应最大的地方有梯度的反馈, 通道注意力机制的表达式见式(3)
Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))
(3)
空间注意力机制是压缩通道中的特征图, 通道维度上分别进行平均池化和最大池化。 将生成的通道注意力图和输入特征图做乘法操作, 进行最大池化操作以从通道上提取最大值; 进行平均池化操作的目的是提取通道平均值。 最大池化和平均池化均以高乘以宽的次数进行提取, 然后对提取的特征图进行融合获得一个2通道特征映射。 空间注意力机制的表达式见式(4)
Ms(F)=σ(f3×3([AvgPool(F); MaxPool(F)]))
(4)
式(4)中,σ为sigmoid操作, 3×3表示卷积核的大小。
1.3 损失函数
使用交叉熵损失函数CrossEntropy Loss作为损失函数, 用于评估实际输出与期望输出之间的接近程度。 交叉熵原本是信息论中的概念, 用来估算平均编码的长度。 在深度学习中, 一般作为多分类问题的损失函数, 交叉熵刻画的是两个概率分布的距离, 交叉熵值越小, 两个概率分布越接近。 对于给定的两个概率分布p、q, 其表达如式(5)
(5)
式(5)中,p(xi)表示正确分布,q(xi)表示预测分布。 实际上交叉熵度量的是预测值和真实标签值之间的信息损失, 其与KL散度的表达式见式(6)
=-H(p)+H(p,q)
(6)
显然, 只有当q(xi)=p(xi)时,DKL(p‖q)有最小值, 这意味着预测的结果越接近越好。
2 结果与讨论
2.1 实验数据
高光谱图像采集系统如图3所示, 采集设备是SOC710便携式可见/近红外成像光谱仪, 其光谱范围为400~1 000 nm, 光谱分辨率为4.687 5 nm, 共128个波段, 图像像素为696×520。 原始高光谱图像采用ENVI 5.3软件进行数据格式转换, 并截取感兴趣区域。

图3 高光谱图像采集系统示意图
实验采用的小麦种子是从河南、 山东两省选取出的8类优质小麦, 如表1所示。 首先, 收集图像数据。 为了确保每个样本上光谱数据能够最好地展示出来, 采集了每个小麦种子的背面(小麦种子的凸面)和正面(小麦种子的凹面)数据。 从每个小麦种子品种中采集60个样本, 每个品种样本共采集120张图片。 选取了8个品种的小麦种子, 共获得960个高光谱图像数据, 尺寸为696×520×128, 如图4所示。
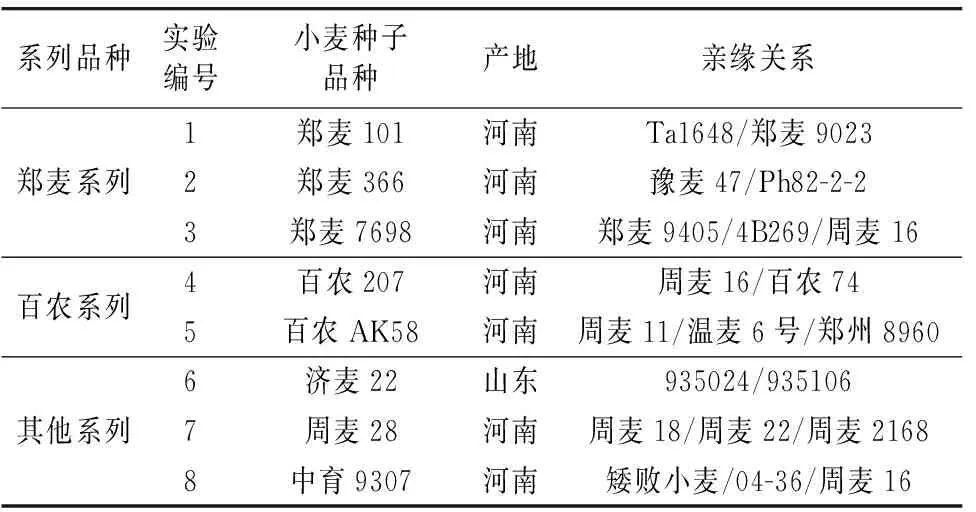
表1 小麦品种信息表

图4 小麦种子部分光谱波段示意图
2.2 收敛分析
计算机具体配置为AMD Ryzen 7 3700X 8-Core CPU、 16GB运行内存、 NVIDIA Geforce GTX 1650 super显卡、 4GB显存。 软件环境为在64位Windows 11下的Python3.6和torch-gpu-1.10.1。
训练模型时, 为了防止模型过拟合, 全连接层使用Dropout, 即在全连接层中的节点有20%的概率为0。 使用Adam优化器, 基于分类结果选择了最优学习率0.01, 并使用指数衰减学习率, 以在后期获取更加稳定的模型。 采用批量训练的方法, 设置批量大小为36。 经过120次迭代后, 损失率趋于稳定。 如图5所示, 模型训练中的收敛曲线在前30次迭代中迅速下降; 经过80次迭代后, 模型的损失值稳定且趋近于0, 表现出良好的性能和稳定性。
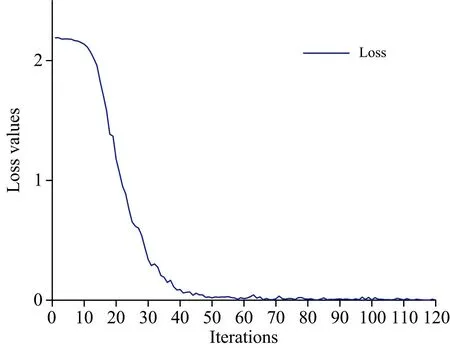
图5 AMCNN的收敛曲线
2.3 多分类评估
按照“训练集∶测试集=9∶1”的原则进行随机划分, 选取support vector machine (SVM)[22]、 K-nearest neighbor (KNN)[23]、 stochastic gradient descent (SGD)[24]、 random forest (RF)[25]四类机器学习模型和dual convolutional neural network (DCNN)[26]、 residual networks (ResNet)[27]、 hybrid spectral net (HybridSN)[28]三类深度学习模型, 共7类作为对比模型, 评价指标使用F1-sorce、 Recall、 Precision和Accuracy的加权平均来进行验证。 Accuracy为分类结果正确的样本(包括正负样本)占所有样本的比例。 Precision表示分类出的正确的正样本占所有分类结果为正样本的比例。 Recall表示分类结果正确的正样本占所有正样本的比例。 F1-sorce由Precision和Recall共同决定。 以上指标的值越高, 模型分类效果越好。 分类结果如表2所示。

表2 AMCNN模型与其他分类模型分类结果
整体而言, AMCNN网络在所有指标上均显著优于其他模型, AMCNN网络的Accuracy为97.92%, 比机器学习的Accuracy高约1.04%~3.13%, 比其他深度学习模型的Accuracy高约2.08%~3.13%, 改善了小麦高光谱分类的效果。 而且AMCNN算法表现也很突出, 整体结果可以看出, 在样本比较少时, 由于深度学习依赖于大量数据集, 在整个测试集上表现并不突出, 而机器学习能够在这种情况下表现出其优势, 本文提出的AMCNN由于综合了高光谱的空间和光谱信息, 能够在训练集数量较少的情况下表现出较高的分类准确率。
AMCNN网络模型测试集样本分类的混淆矩阵如图6所示, 分析能够得出, AMCNN网络模型对8种小麦种子的品种鉴别准确率均超过了90%, 其中郑麦101、 郑麦366、 百农AK58、 济麦22、 周麦28的鉴别准确率最高为100%, 原因是这5个品种的小麦种子与其他品种的小麦种子在亲缘关系上无交集, 因而特征存在较大差异, 易于鉴别。 郑麦7698和百农207的鉴别较差, 且与中育9307三者之间存在错误鉴别样本, 原因是这三者不仅产地相同, 且都是由周麦16杂交获得。

图6 测试集中AMCNN模型的分类混淆矩阵
2.4 消融研究
为证明本方法中每个模块的有效性, 对提出的网络进行消融实验, 包括无注意力模块(-w/o AM)、 无BN层(-w/o BN)以及无三维卷积(-w/o 3DCNN)和无二维卷积(-w/o 2DCNN)。 评价指标包括F1-sorce、 Recall、 Precision和Accuracy的加权平均。 每次修改一项, 其余参数设置与原网络保持一致, 以进行公平比较, 消融结果如表3所示。
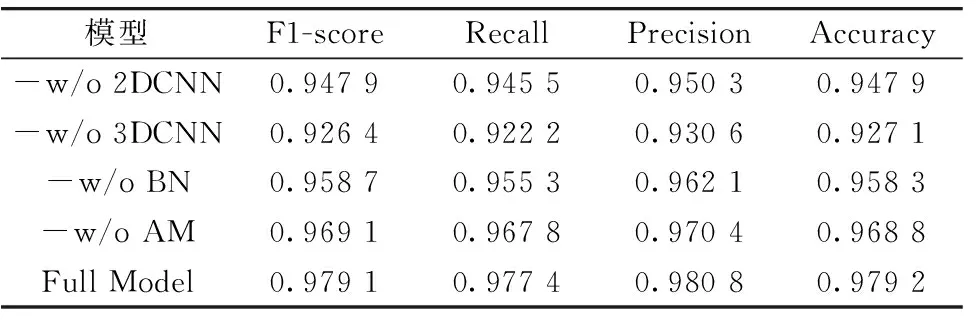
表3 消融实验
相较于无二维卷积的模型, 无三维卷积的模型分类准确率下降了5.21%。 这是由于光谱的“同谱异物性”和“同物异谱性”造成的。 实验结果表明, 三维卷积的引入改进了模型, 提高了分类精度。 这是因为高光谱图像具有很强的波段相关性, 通过在不同特征图上的滑动卷积运算, 可以更好地提取每个图像的特征, 有助于提高分类模型的精度。 无BN层和无注意力模块的分类准确率相较于原网络分别下降了2.08%和1.04%, 说明BN层和注意力模块影响着网络, 能有效提高分类效果。
3 结 论
提出了一种AMCNN模型, 利用高光谱成像技术对小麦种子进行无损鉴别, 结合三维卷积和二维卷积, 引入注意力机制模块, 能够在样本数量较小的情况下进行分类, 且准确率能达到97.92%, 在7类对比实验中取得了较好的结果, 证明了本文提出的网络模型的可行性和有效性。
尽管本文提出的网络可以提高小样本数据的分类精度, 但在对一些多样化种子进行分类时, 由于年份、 产地不同, 可能会导致模型泛化能力不足。 近年来, 迁移学习技术用于改善深度神经网络模型泛化能力, 但在基于深度卷积神经网络的高光谱种子品种鉴定领域仍然有待试验, 需要进一步进行研究。 在未来的工作中, 我们将扩大小麦种子的种类和数量, 以验证我们的AMCNN模型。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国光学(2015年5期)2015-12-09
食品工业科技(2014年23期)2014-03-11
电视技术(2014年19期)2014-03-11
