
基于人工智能方法的隧道塌方风险预测研究
2024-03-18 01:32刘志锋陈名煜吴修梅魏振华
水力发电 2024年3期
刘志锋,陈名煜,吴修梅,魏振华,3
(1.东华理工大学,江西 南昌 330013;2.江西省地质环境与地下空间工程研究中心,江西 南昌 330013;3.江西省水信息协同感知与智能处理重点实验室,江西 南昌 330099)
0 引 言
塌方事故在隧道施工过程中的发生概率频繁且危害严重,不仅会破坏工程环境,延误施工进度,更有可能造成人员伤亡和不良的社会影响。因此,有必要对隧道塌方成因进行分析并预判风险发生的可能性进行研究。张晨曦等[1]采用层次分析法及多层次模糊综合决策确定法预测隧道塌方事故的可能性等级;牟新伟等[2]提出了TSP203和理想点法相结合的综合评价体系,对隧道塌方风险进行预测;吴晓松[3]采用文献分析法及专家调查归纳法得出隧道塌方风险要素,通过解释结构模型和贝叶斯网络构建塌方风险预测模型,实现塌方风险定量评估;王婧等[4]建立风险评估指标体系,并通过可变模糊评价法评估得出岩山隧道工程的塌方风险等级;周浩宇等[5]运用理想点法建立隧道塌方风险预测模型,通过非线性计算得出塌方风险等级;仝跃等[6]基于普氏平衡拱理论,应用Monte-Carlo方法和数值分析法对塌方风险进行定量化分析预测;蔡宁过[7]提出了基于属性识别模型的隧道塌方风险评估方法;詹金武等[8]开发了基于模糊数学的山岭隧道塌方风险评估系统;赵雪等[9]基于人工蜂群优化支持向量机回归法预测隧道塌方风险;陈航等[10]运用BP神经网络的构建原理,对隧道塌方机理进行了深入研究。
以上研究大多以传统评估方法为主,多采用模糊数学主观加权法,具有较强的主观性。人工智能方法可快速处理和分析复杂数据,发现并提取出数据中的隐藏关联和趋势,并通过学习和优化算法,作出更准确的预测,同时还可以自动执行繁重、重复或耗时的任务,提高工作效率。为此,本文在已提出确定隧道塌方风险评估指标方法的研究基础上,着重研究人工智能预测方法对塌方风险进行研究,构建随机森林、径向基函数神经网络和BP神经网络模型对隧道塌方风险进行预测。同时,采用粒子群算法对BP神经网络模型进行优化,以期使预测结果更加客观、准确。
1 隧道塌方风险评估指标体系的建立
本文对国内外246起隧道塌方事故进行统计和分类,同时查阅《公路桥梁和隧道工程施工安全风险评估制度及指南解析》等文件,对隧道塌方的风险因素进行辨识,完成指标的分级量化工作。根据各指标特点及对塌方的影响规律,确定隧道塌方风险评估指标体系为围岩级别A1、降水及地下水A2、偏压A3、特殊不良地质A4、开挖跨度A5、埋深A6、开挖扰动A7、支护设计A8、施工质量A9、超前地质预报A10、主观因素A11和其他A12共12个评估指标。将评估指标划分为Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ、Ⅵ等6个等级,从低到高表示各评估指标引起塌方风险的可能性,得到隧道塌方预测的样本数据集。量化后的部分样本数据见表1。

表1 量化后的部分样本数据
隧道塌方风险预测的样本数据共300条,其中包含246条塌方样本数据和54条未塌方样本数据,每条样本记录中包括12个特征因子和1个分类标签,特征因子为选取的12个隧道塌方评估指标,每条数据的分类标签为塌方预测结果,分类结果有塌方和不塌方。试验时将样本数据打乱,设置训练集与测试集的比值为8∶2,240条样本作为训练集,60条样本作为测试集。
2 隧道塌方风险评估模型
在机器学习领域,人工智能常用方法包括决策树、支持向量机、神经网络等。本文选用随机森林算法、径向基函数神经网络、BP神经网络和粒子群算法优化BP神经网络构建评估模型,对隧道塌方风险进行预测。
2.1 随机森林算法
随机森林(Random Forest,RF)是一种集成学习算法,工作原理是对训练数据进行随机抽样,通过构建多个决策树模型,将其合并实现分类预测,提高整体的预测准确性。由于每个决策树都是基于不同的随机抽样数据集构建的,因此可以减少模型的方差,提高模型的稳定性和准确性[11]。随机森林算法还可以评估特征的重要性,通过计算特征在决策树中的采用频率和划分质量,得到每个特征对分类结果的贡献程度。
试验过程为:①数据集处理。采用mapminmax()函数对输入数据进行归一化处理,再将数据集矩阵转置以适应模型。②建立随机森林模型。采用TreeBagger()函数构建随机森林模型。③设置超参数。将决策树数目设置为50,最小叶子数设置为1。④训练模型。采用训练集训练随机森林模型,建立样本数据集中特征和标签之间的关联。⑤模型预测。采用训练好的随机森林模型对测试集进行预测,并生成塌方预测结果。
RF模型的误差曲线见图1。从图1可知,随着决策树数目的增加,随机森林算法在训练集上的误差不断降低,当决策树数目为20时,RF模型的误差曲线趋于平稳;当决策树数目为38时,模型的误差为0.033,此时模型的预测性能最好。图2为RF模型隧道塌方风险各评估指标对于预测结果输出的重要性。从图2可知,围岩级别A1、降水及地下水A2、开挖扰动A7、超前地质预报A10等因素对于隧道塌方预测结果的影响较大,在隧道施工过程中需重点关注。图3为RF模型预测结果。对预测结果进行排序处理后,直观可得模型在训练集上的预测准确率达到100%,在测试集上的预测准确率为81.67%。

图1 RF评估模型误差

图2 RF模型评估指标重要性
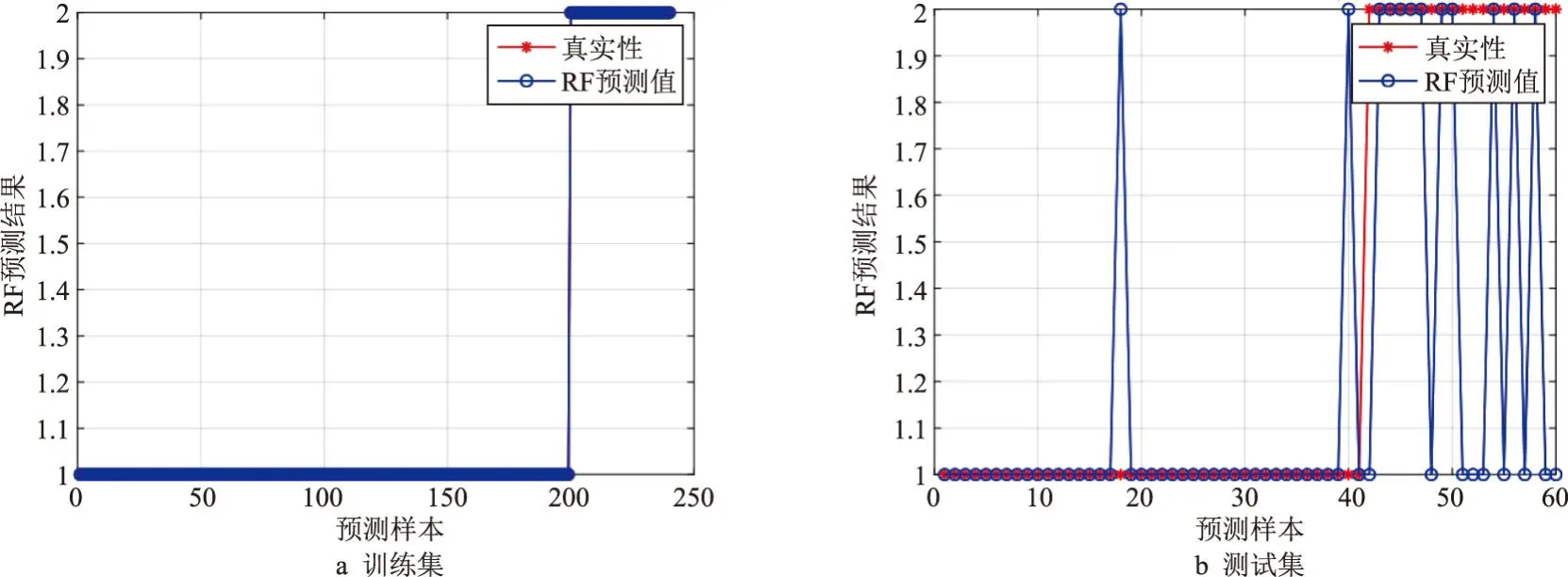
图3 RF评估模型预测结果
2.2 径向基函数神经网络
径向基函数神经网络(Radial Basis Function Neural Network,RBFNN)是一种适用于分类预测问题的人工神经网络模型。RBF神经网络由输入层、隐藏层和输出层组成[12]。输入层接收数据特征,并传递给隐藏层;隐藏层中的神经元采用径向基函数作为激活函数,通过计算输入数据与各个神经元之间的欧氏距离确定神经元的激活程度;输出层将隐藏层的激活结果进行加权汇总,通过激活函数将结果映射到合适的输出范围内,得到最终的分类预测结果。由于径向基函数的特性,RBF神经网络在处理不同类别之间的非线性边界时表现出较好的局部适应性,能有效地处理复杂的分类问题。同时,RBF神经网络在训练过程中,隐藏层的参数可以通过聚类算法快速确定,从而大大减少了训练时间。
径向基函数神经网络预测隧道塌方风险的算法步骤主要为:①导入数据,对训练集和测试集进行划分并做归一化处理,将数据归一到同一量纲上,减少噪声和提高精度;②创建径向基网络,设置径向基函数扩展速度为50;③训练完神经网络后采用sim函数进行仿真预测;④再对预测的结果进行反归一化处理,得到真实值;⑤计算相关误差指标,绘制图形。径向基函数神经网络模型结构为12-240-2,见图4。图5为RBFNN评估模型预测结果。从图5可知,模型在训练集上的预测准确率达到97.08%,在测试集上的预测准确率为83.33%。

图4 RBFNN评估模型结构

图5 RBFNN评估模型预测结果
2.3 BP神经网络
BP神经网络(Back Propagation Neural Network,BPNN)是一种深度学习模型,其原理基于反向传播算法,通过多层的神经元网络构建复杂的非线性关系,包含输入层、隐藏层和输出层[13],见图6。输入层接收特征数据,隐藏层提取特征,输出层用于进行分类预测。每个神经元都与相邻层所有神经元相连,并且具有可调节的权重值。BP神经网络可以通过调整网络结构和学习参数适应不同的数据分布和复杂的分类问题,并且利用多个计算单元并行计算,提高模型的计算效率。

图6 BP神经网络结构
对样本数据进行归一化处理后,设计BP神经网络结构,确定隐藏层节点数m的公式,即
(1)
式中,n为输入层节点数;o为输出层节点数;k的取值范围,为1~10之间的整数。由于隧道塌方风险评估指标确定为12个,因此BPNN评估模型的输入层节点数为12;塌方预测输出结果为1(塌方)或2(不塌方),因此输出层节点数为2。将输入层节点数和输出层节点数代入式(1)计算可得,隐藏层节点数的选取范围为4~10。后经测试,设置隐藏层节点为6时,模型具有较高的准确率和良好的误差精度。因此,确定BP神经模型的网络结构为12-6-2,见图7。
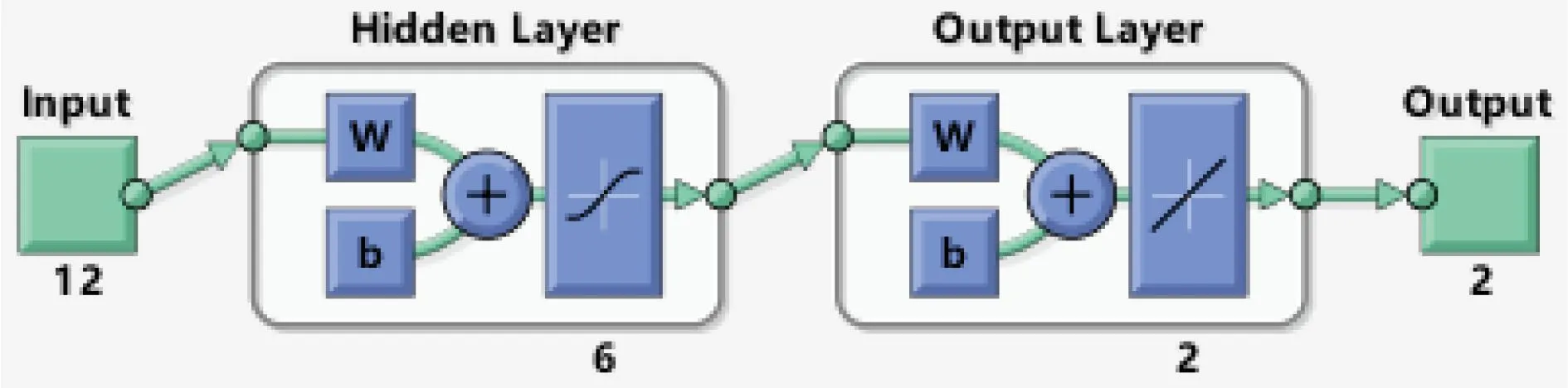
图7 BPNN评估模型结构
建立初始网络模型后,设置主要训练参数如下:最大迭代次数设置为1 000次,目标训练误差设置为10-6,学习率设置为0.01。仿真试验后,BPNN评估模型训练到第4次时具有最佳性能,此时的均方误差值不再下降,为0.064 675。图8为BP神经网络评估模型的预测结果。从图8可知,模型在训练集上的预测准确率为90.83%,在测试集上的预测准确率为86.67%。

图8 BPNN评估模型预测结果
2.4 粒子群算法优化BP神经网络模型
为解决BP神经网络模型在实际预测中容易陷入局部最小值的问题,同时提高模型的塌方风险预测准确率和性能,采用粒子群算法(Particle Swarm Opti-mization,PSO)对BP神经网络模型进行优化。PSO是一种群体协作的智能搜索算法,模拟了鸟群或鱼群等生物群体在寻找食物或逃避敌害时的行为。通过粒子群算法的全局搜索能力,可以自适应地调整搜索策略,找到合适的权重和偏差[14],以优化BP神经网络的分类预测性能。PSO-BPNN算法流程见图9。

图9 PSO-BPNN算法流程
首先导入隧道塌方样本数据,划分训练集和测试集并进行归一化处理,选用BP神经网络模型结构及参数,经反复测试后,粒子群算法的最优参数设置见表2。

表2 粒子群算法的最优参数设置
仿真试验后,PSO-BPNN评估模型的最佳适应度收敛曲线见图10。从图10可知,随着粒子群迭代次数不断增加,算法适应度值逐渐降低,在迭代到第18次时适应度值收敛到最小。此时,模型训练到第7次时具有最佳性能,训练均方误差为0.080 439。图11为PSO-BPNN评估模型的预测结果。从图11可知,模型在训练集上的预测准确率为94.58%,在测试集上的预测准确率为93.33%,优化后的评估模型相比其他模型具有更高的预测准确率。
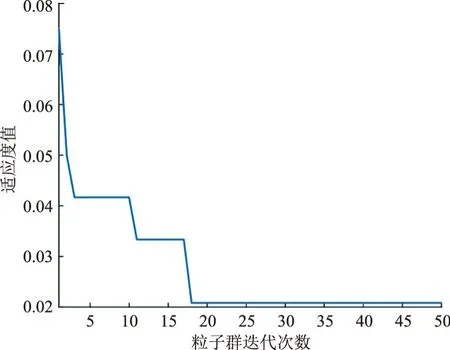
图10 粒子群算法的最佳适应度收敛曲线
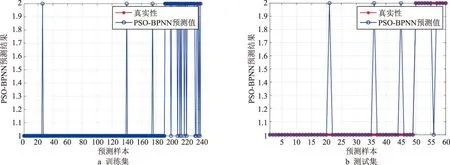
图11 PSO-BPNN评估模型预测结果
3 模型对比与分析
3.1 混淆矩阵
混淆矩阵(Confusion Matrix)常用于分类模型性能评估,展示分类模型的预测结果与真实标签之间的差异。在混淆矩阵中,行代表真实标签的类别,列代表模型预测的类别。对于二分类问题而言,混淆矩阵通常是1个2×2的矩阵。RF、RBFNN、BPNN、PSO-BPNN模型预测结果的混淆矩阵见图12。图12中,1代表预测结果为塌方,2代表预测结果为不塌方,在测试集60个样本中:

图12 各评估模型预测结果的混淆矩阵
(1)RF评估模型对塌方结果的预测准确率为81.67%。真实标签为塌方的2个样本被预测为不塌方,真实标签为不塌方的9个样本被预测为塌方,真实标签为塌方的39个样本和真实标签为不塌方的10个样本均预测正确。
(2)RBFNN评估模型对塌方结果的预测准确率为83.33%。真实标签为塌方的3个样本被预测为不塌方,真实标签为不塌方的7个样本被预测为塌方,真实标签为塌方的41个样本和真实标签为不塌方的9个样本均预测正确。
(3)BPNN评估模型对塌方结果的预测准确率为86.67%。真实标签为塌方的3个样本被预测为不塌方,真实标签为不塌方的5个样本被预测为塌方,真实标签为塌方的48个样本和真实标签为不塌方的4个样本均预测正确。
(4)PSO-BPNN评估模型对塌方结果的预测准确率为93.33%。真实标签为塌方的3个样本被预测为不塌方,真实标签为不塌方的1个样本被预测为塌方,真实标签为塌方的46个样本和真实标签为不塌方的10个样本均预测正确。
3.2 准确率
各塌方风险预测模型的准确率见表3。从表3可知,经试验测试后选取最优参数的各基本模型中,BPNN评估模型的预测准确率最高,为86.67%;对该模型采用粒子群算法进行优化后,PSO-BPNN模型的准确率提高到了93.33%,此时,模型在该数据集上具有较好的塌方风险预测能力。

表3 各模型预测准确率 %
3.3 F1值
F1值是衡量二分类模型的精确度指标,兼顾了精确率和召回率[15],范围在0~1之间,越接近1模型的性能越好,反之则越差,相关计算公式为
(2)
(3)
(4)
式中,P为精确率;R为召回率;TP表示预测结果中的真正类(预测正确且预测结果为不塌方);FP表示预测结果中的假正类(预测错误且预测结果为不塌方);FN表示预测结果中的真负类(预测错误且预测结果为塌方)。
由测试集混淆矩阵计算得出各评估模型的F1值见表4。从表4可知,各评估模型中PSO-BPNN模型的F1值最高,为0.833,优化后的模型性能有了明显提升,验证了通过粒子群优化算法调整BP神经网络的参数,可更好地提高BP神经网络模型的泛化能力和适应性,使隧道塌方风险预测效果更好。

表4 各评估模型的F1值
4 结 语
本文以隧道塌方风险为研究对象,在收集整理国内外塌方事故案例的基础上,基于人工智能预测方法,分别采用随机森林算法、径向基函数神经网络、BP神经网络模型、粒子群算法优化后的BP神经网络模型,建立了隧道塌方风险评估指标体系,并对比各模型在隧道塌方风险预测中的准确率及模型性能。结果表明,PSO-BPNN模型的性能最佳,预测效果最好,大大减少了评估结果的主观性,为隧道塌方风险研究提供了新的研究思路。
由于收集整理的隧道塌方事故案例有限,本文的样本量较少,后续将继续扩充样本量,进一步完善塌方风险预测模型和算法。
猜你喜欢
工程建设与设计(2021年11期)2021-07-28
建材发展导向(2021年6期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
车迷(2018年11期)2018-08-30
中国交通信息化(2018年5期)2018-08-21
海峡姐妹(2018年3期)2018-05-09
水利水电工程设计(2017年1期)2017-05-17
公民与法治(2016年10期)2016-05-17
