结合局部全局特征与多尺度交互的三维多器官分割网络
2024-03-20 10:31柴静雯李安康张浩马泳梅晓光马佳义
中国图象图形学报 2024年3期
柴静雯,李安康,张浩,马泳,梅晓光,马佳义
武汉大学电子信息学院,武汉 430072
0 引言
中国癌症病患人数和死亡人数逐年上升,已成为主要死因之一。高度适形放射治疗是常用的癌症治疗方法,该方法精准匹配辐射外形和标靶器官外形,但这非常依赖于对癌组织和周边多个危及器官(organ at risk,OAR)解剖结构的精确分割(盛荣军等,2023)。
三维医学图像多器官分割是指将三维医学图像中多个不同的器官或者病灶区域划分出来,是医学图像分析领域中关键的技术之一。深度学习因其强大的特征表示能力,近年来大量应用于医学图像的临床研究(陈弘扬 等,2021),而基于深度学习的三维医学图像多器官分割方法具有耗时短、水平一致性高的优点,已经成为该领域中的主要研究方向(周涛 等,2021)。视觉Transformer(vision Transformer,ViT)(Dosovitskiy 等,2021)因突破了卷积神经网络(convolutional neural network,CNN)局部视野的固有限制而成为最新的研究热点,大量基于CNN 和ViT 的深度神经网络模型被开发出来(Shamshad 等,2023),并获得当时的最佳结果。然而,现有三维医学图像分割方法常忽略多尺度架构(Hatamizadeh 等,2022b)或是通过限制ViT 的注意力计算范围来实现多尺度(Cao 等,2023),因此丧失了ViT 在长距离关联提取上的优势;此外,现有方法中局部和全局的特征提取器往往在不同尺度上串行连接,而并未在同尺度中并行执行(Huang 等,2023),使得局部特征和全局特征的交互受限。
为使得网络能够在不同尺度间进行信息交互,本文提出LoGoF(local-global-features fusion)编码器,并在其基础上构建端到端三维医学图像多器官分割网络M0;此外,引入多尺度交互(multi-scale interaction,MSI)模块和注意力指导(attention guidance,AG)结构,为M0 在不同尺度特征中引入空间先验,最终提出用于三维医学图像多器官分割的LoGoFUNet(local-global-features fusion UNet)网络。经过定性和定量分析,该方法在3 个公开数据集上的分割性能均优于其他二维或三维先进算法,且泛化性能较好,最后本文开展了充分的消融实验,以证明LoGoFUNet模块设计的合理性。
1 方 法
1.1 LoGoF编码器
LoGoF 编码器旨在于同一特征尺度下同时捕获三维医学图像的局部细节和全局关联,因此采用局部和全局的双分支结构来提取特征,下面本文将介绍LoGoF编码器的构建思路。
1.1.1 局部特征提取手段
幽灵卷积(Han 等,2020)认为自然图像卷积过程中部分特征图的产生过程可以用相对简单的线性映射完成,由此可在不影响特征提取性能的前提下降低性能消耗,因此本文希望引入幽灵卷积作为低耗的局部特征提取器。标准幽灵卷积的特征提取过程可以简单表述为
式中,Iin表示输入特征,Iout表示输出的幽灵卷积特征,*表示卷积操作,fst和fsp分别表示标准卷积和深度可分离卷积,⊕表示通道维度上的拼接操作,BN()表示批归一化(batch normalization BN),ReLU表示ReLU(rectified linear unit)函数。
为使得幽灵卷积在局部特征提取上具有更好的性能,需对其进行一些改进:首先,由于景深信息的缺失,相比自然图像,医学图像特征图之间具备更多的线性映射关系,因此本文将标准幽灵卷积中fst和fsp中的输出通道数从1∶1 调整为1∶3;其次,将幽灵卷积中所有的BN 转换为层归一化(layer normalization,LN),这是因为已有工作(Liu 等,2022)证明BN可能对模型的泛化性产生不利影响;最后,将幽灵卷积中所有的ReLU 替换为GeLU(Gaussian error linear unit),以解决ReLU 在负梯度下突然归零的问题。综上,LoGoF 模块局部分支采用的改进幽灵卷积运算可表示为
式中,Ilo表示幽灵卷积的局部特征图输出,该模块的局部特征提取方式如图 1所示。
1.1.2 全局特征提取手段
标准ViT 通过密集的自注意力运算来获取图像的长距离依赖关系,该自注意力运算可表示为
式中,H、W和D表示每个方向上的patch 数量,Iabc表示在任意位置(a,b,c)上(a∈{1,…,H},b∈{1,…,W},c∈{1,…,D})的自注意力,qabc表示在任意位置(a,b,c)上的查询向量,khwd和vhwd表示在任意位置(h,w,d)上的键向量和值向量。位置编码pq、pk和pv是可学习的表示查询向量的维度,用于收缩数据范围。需要注意的是,为方便表述,以上阐述忽略自注意力的多头特性。
ViT 自注意力计算中的亲和度计算需要消耗很大的计算资源,然而在三维医学图像分割中,不同个体的同一个分割目标相对位置基本固定,因而常规ViT 的注意力运算在医学分割中具有较大的资源冗余。受到Al-Shabi 等人(2021)的启发,本文将ViT的全局自注意力计算按照三维轴向拆分为3 个低计算复杂度的面自注意力计算。以垂直于H(height)轴的面WD(width-depth)上的自注意力计算为例,计算可表示为
类似ViT 中的标准Transformer 块(如图 2(a)),利用3 个面自注意力运算来构建一个FTB(facial Transformer block),其结构如图 2(b)所示。图中FTB运算可表示为
式 中,Iin表 示FTB 结构的输入,FSA_WD(⋅)、FSA_HD(⋅)和FSA_HW(⋅)分别表示WD 面、HD 面和HW 面上的自注意力运算函数、和分别表示各个面自注意力模块的输入和输出相加的结果,MSA(·)表示ViT 中的多头自注意力模块。MLP(·)表示ViT 中的多层感知机层。经过LoGoF 模块的全局分支,可得到全局特征图Igo。
1.1.3 特征增强和融合
经过LoGoF 模块,局部特征和全局特征被单独提取,首先对其施加空间注意力(Woo等,2018)和通道注意力(Hu 等,2018),以充分发挥其优势。经过注意力增强后,局部和全局特征间已经存在较大差别,这种差异会阻碍神经网络的特征识别。为平滑并融合两种特征,提出了一种特征融合模块(feature fusion module,FFM),如图3所示。
该模块的主要思想是通过不同分支间交叉相乘来增强差异特征的学习。这里假设将通过通道注意力增强的全局特征记为,通过空间注意力增强的局部特征记为,之后通过提取各自分支的主要特征并与其他分支的特征权重进行交叉相乘,从而得到经过融合的全局特征和局部特征,最终通过拼接操作得到特征融合模块的输出If,具体为
1.1.4 构建特征编码器
本节构造局部全局特征融合(LoGoF)编码器。LoGoF 模块的整体结构如图4(a)所示,全局分支采用FTB 运算并对其输出施加通道注意力,局部分支采用三维幽灵卷积操作并对其输出施加空间注意力。经过特征增强后,网络将全局特征和局部特征一同馈入特征融合模块进行特征融合,得到LoGoF模块的输出。通过将LoGoF 模块的两个分支拆分开来,可形成两个单独可用的编码器Lo 模块和Go 模块,如图4(b)(c)所示。由于特征类型单一,这些编码器中均不包含特征融合模块。
1.2 多尺度网络M0
基于1.1.4 节提出的3 种特征编码器来构建多尺度的三维医学图像多器官分割网络M0。为充分利用卷积滤波器的细节捕获能力和ViT 的全局特征关联捕获能力,本文将M0网络设计如图5所示。
在网络顶层(编码器1),本文仍采用一个标准3 × 3 × 3 卷积滤波器,先将图像映射到隐藏维度并最大程度地从原图提取细节;在浅层仅设置一个Lo编码器2,以最高的特征分辨率来提取目标细节;在中间层设置LoGoF 编码器3 和LoGoF 编码器4,充分利用图像局部和全局的融合信息;在深层仅设置一个Go编码器5,以获取网络深层最抽象的语义特征。
1.3 三维医学图像多器官分割网络LoGoFUNet
1.3.1 多尺度交互(MSI)
为了建立多尺度特征之间的信息交互,本文针对M0 网络设计了一个多尺度交互模块如图6 所示。其输入为M0 中4 层编码器输出的不同尺度的特征图I2,I3,I4,I5。首先,各个尺度下的特征图将分别按照4 × 4 × 4 和2 × 2 × 2 的标准切分为细粒度和粗粒度的patch,之后每一个灰色框内部的所有patch 将进行信息交互。在图6中,patch 块中不同的颜色表示该patch 块在原图像的所属部分。经过自注意力交互后,网络可将细粒度和粗粒度的patch添加到原始特征图中,获得带多层交互的特征输出
为了更直观地展示多尺度交互模块的作用,本文可视化展示了Synapse 数据集中的肝脏部位在多尺度交互中的情况,如图7所示。
以绿色遮罩部分的图像块为例,粗粒度切分将肝脏某个位置切分出来,而细粒度切分对肝脏在该位置进行了更精细的切分。经过多尺度交互后,不同尺度的轮廓和细节信息均产生了交互,因而可以更好地定位和分割器官。
1.3.2 注意力指导结构(AG)
在M0网络中,浅层大尺度特征图包含丰富的细节信息fd、较少的语义信息fs和细粒度的全局关联信息fg,而深层小尺度特征图具有较少的细节信息fdd、较多的语义信息fss以及粗粒度的全局关联信息fgg。为了保持多尺度下对同一器官的注意力,可以利用在fd上学习到的空间注意力来指导fdd和fss的空间注意力,而为了借助对上层细部间关联的注意力来提升下层粗部间关系的提取效果,可以利用在fg上学习到的通道注意力来指导fgg的通道注意力。具体来说,本文在M0 网络的编码器2—编码器5 上应用AG 结构,如图8 所示。图中蓝色箭头和黄色箭头分别代表通道AG 函数和空间AG 函数。由于编码器2只有局部分支且编码器5 只有全局分支,因此其AG路径只有一条。
1.3.3 LoGoFUNet
将MSI 模块和AG 结构引入M0 网络之后,即可得到三维医学图像多器官分割网络LoGoFUNet,其总体结构如图9所示。
2 实 验
2.1 数据集划分
为了验证LoGoFUNet 的有效性,本文在3 种公开数据集上进行了验证。
第1 个数据集是Synapse 腹部多器官分割数据集,该数据集包含30 幅腹部CT(computer tomography)扫描图像以及它们的分割金标准,本文仅在目前最佳方法(state of the art,SOTA)常用的8 个器官上评估本文的方法,即主动脉、胆囊、左肾、右肾、肝脏、胰腺、脾脏和胃。为防止过拟合,实验随机抽取12 幅作为测试样本,剩余18 幅进行10 次增广得到18+18 × 10共198幅训练样本。
第2 个数据集是SegTHOR(segmentation of thoracic organ at risk)(Lambert 等,2020)胸部多器官分割数据集,该数据集包含40 幅胸部CT 扫描图像以及它们的分割金标准,本文在金标准包含的4 个器官上评估了本文的方法,这些器官是:食管、心脏、气管和主动脉。为防止过拟合,实验随机抽取10 幅作为测试样本,剩余30 幅进行6 次增广得到30+30 ×6共210幅训练样本。
第3 个数据集是ACDC(automatic cardiac diagnosis challenge)挑战赛数据集,其中包含100 幅MRI(magnetic resonance imaging)扫描图像以及它们的分割金标准,金标准中包含3 个器官,即左心室、右心室和心肌。类似地,本文按照随机生成的列表对数据集进行划分,且不进行增广,由于每个样本包含两幅CT 图像,因而训练、验证和测试样本数量分别为140幅、20幅和40幅。
2.2 损失函数
医学图像分割任务中,Dice损失函数(Dice loss)是常用的损失函数,相比交叉熵损失函数(cross entropy loss,CELoss),Dice 损失函数从整体目标形态上监督网络分割质量,相比交叉熵损失函数更易优化,收敛更快。然而,在处理多目标分割任务时,网络对部分像素的错误预测会令整个Dice 损失值产生大幅度的变化,导致训练不稳定。因此,本文使用Dice 损失和交叉熵损失结合的加权损失函数,具体为
式中,Ldi(⋅)和Lce(⋅)分别表示Dice 损失函数和交叉熵损失函数,C表示需要分割的器官总类别数,V表示像素总数,和Yv,c分别表示c类别器官中的像素v的预测值和金标准值,α,β为可学习的参数。
2.3 实施细节和评估指标
对于Synapse 数据集,本文定量对比了一些2D方法:V-Net(Milletari 等,2016)、DARR(domain adaptive relational reasoning)(Fu 等,2020)、R50 U-Net、U-Net(Ronneberger 等,2015)、R50 Att-UNet、Att-UNet(Oktay 等,2018)和R50 ViT,定量和定性对比了另一些2D 方法TransUNet(Chen 等,2021)、SwinUNet(Cao 等,2023)、AFTer-UNet(Yan 等,2022)、MISSFormer(Huang 等,2023)、ScaleFormer(Huang等,2023)和3D 方 法UNETR(UNet Transformers)(Hatamizadeh 等,2022b)、SwinUNETR(Hatamizadeh等,2022a)。
对于SegTHOR 数据集,本文定量和定性对比了一 些2D 方 法TransUNet、SwinUNet、AFTer-UNet、MISSFormer、ScaleFormer 和3D 方 法UNETR、SwinUNETR。
对于ACDC 数据集,本文定量对比了一些2D 方法R50 U-Net、R50 Att-UNet、R50 ViT,定量和定性对比了另一些2D 方 法TransUNet、SwinUNet、AFTer-UNet、MISSFormer、ScaleFormer 和3D 方法UNETR、SwinUNETR。
在所有数据集上,LoGoFUNet 采用相同的训练设置:训练次数600 轮,批大小设置为1,采用AdamW 优化器进行参数更新,权重衰减设置为1 ×10-5,学习率初始值设置为1 × 10-4,并采用线性预热和余弦退火算法进行学习率更新,最后,采用Dice相似度系数(Dice similarity cefficient,DSC)和豪斯多夫距离(Hausdorff distance 95,HD95)评估实验结果。
2.4 公开数据集实验结果
2.4.1 Synapse数据集
Synapse 数据集上的实验结果如表1 所示。其中,“*”表示该方法重新训练的结果,其他数据则来源于其原论文,DSC 指标越大表示方法性能越好,HD95 指标越小表示方法性能越好。由表1 可知,在Synapse 数据集上,LoGoFUNet 相比于其他的SOTA方法,表现出最佳平均DSC 和最低的平均HD95,说明LoGoFUNet 在大小不一的整体型器官、长条形器官和片状器官的组合图像中能展现出最优秀的定位和分割水平。

表1 Synapse数据集对比实验结果Table 1 Comparison experiment results on Synapse dataset
为进行直观对比,本文从测试样本29 中抽取3个切片并形成对照组1、2和3,其分割结果的3D对照如图10 所示。从单个器官上来看,LoGoFUNet 在其中4 种器官中表现出最佳的平均DSC 水平,分别是肝脏(liver)、胰腺(pancreas)、脾脏(spleen)和胃(stomach)。值得注意的是,LoGoFUNet 在分割胰腺上的DSC(74.95%)大幅度超出其他对比方法中的最佳DSC(65.57%)。观察并对比对照组3中的红色方框可以发现,LoGoFUNet 能在保留胰腺上部断裂部分的同时尽可能捕获全局和局部信息,因而获得了最佳的胰腺器官分割效果。此外,LoGoFUNet 具备多尺度架构,既可以通过大视野合理利用周围器官的位置关系来定位小器官,又可以通过小视野捕获器官的细节,因此在胃和脾脏这种小尺寸的整体型器官上也获得了最佳的分割性能。在3D 对照组中,LoGoFUNet 的分割结果明显比其他2D 方法具备更平滑的边缘,也比其他3D 方法UNETR 和SwinUNETR具备更好的分割细节。

图1 局部特征提取方式Fig.1 Local feature extraction

图2 Transformer模块和FTB模块Fig.2 Transformer block and FTB block((a)Transformer block;(b)FTB block)

图3 特征融合模块Fig.3 Feature fusion module

图4 LoGoF模块、Lo模块和Go模块Fig.4 LoGoF module,Lo module and Go module((a)LoGoF module;(b)Lo module;(c)Go module)

图5 M0网络总体结构Fig.5 Overall structure of M0 model
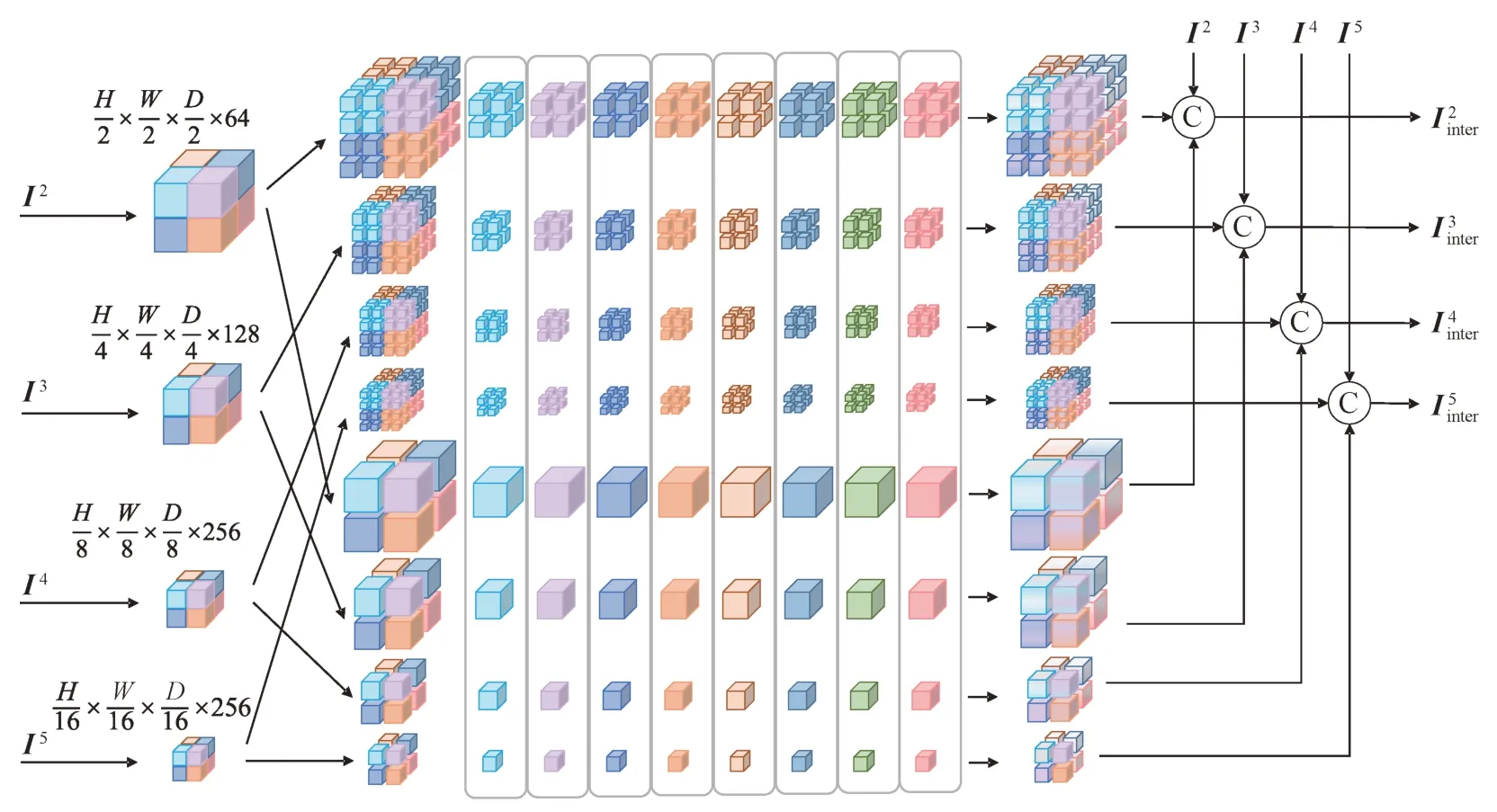
图6 多尺度交互模块Fig.6 Multi-scale interaction module
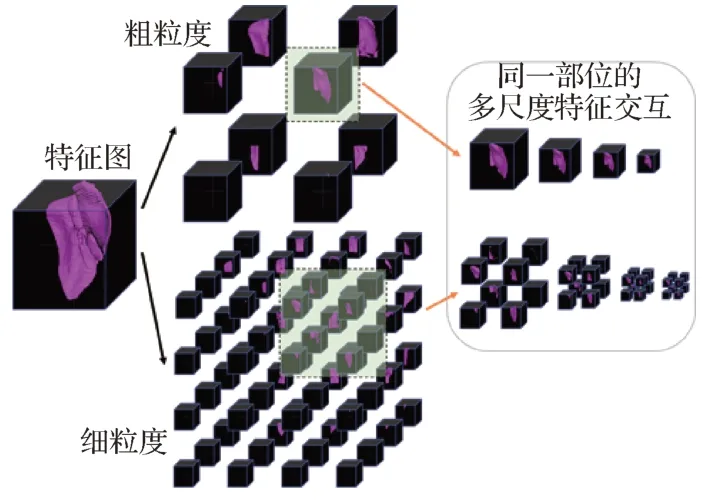
图7 多尺度交互可视化Fig.7 Visulization of the multi-scale interaction

图8 注意力指导结构Fig.8 Attention guidance structure
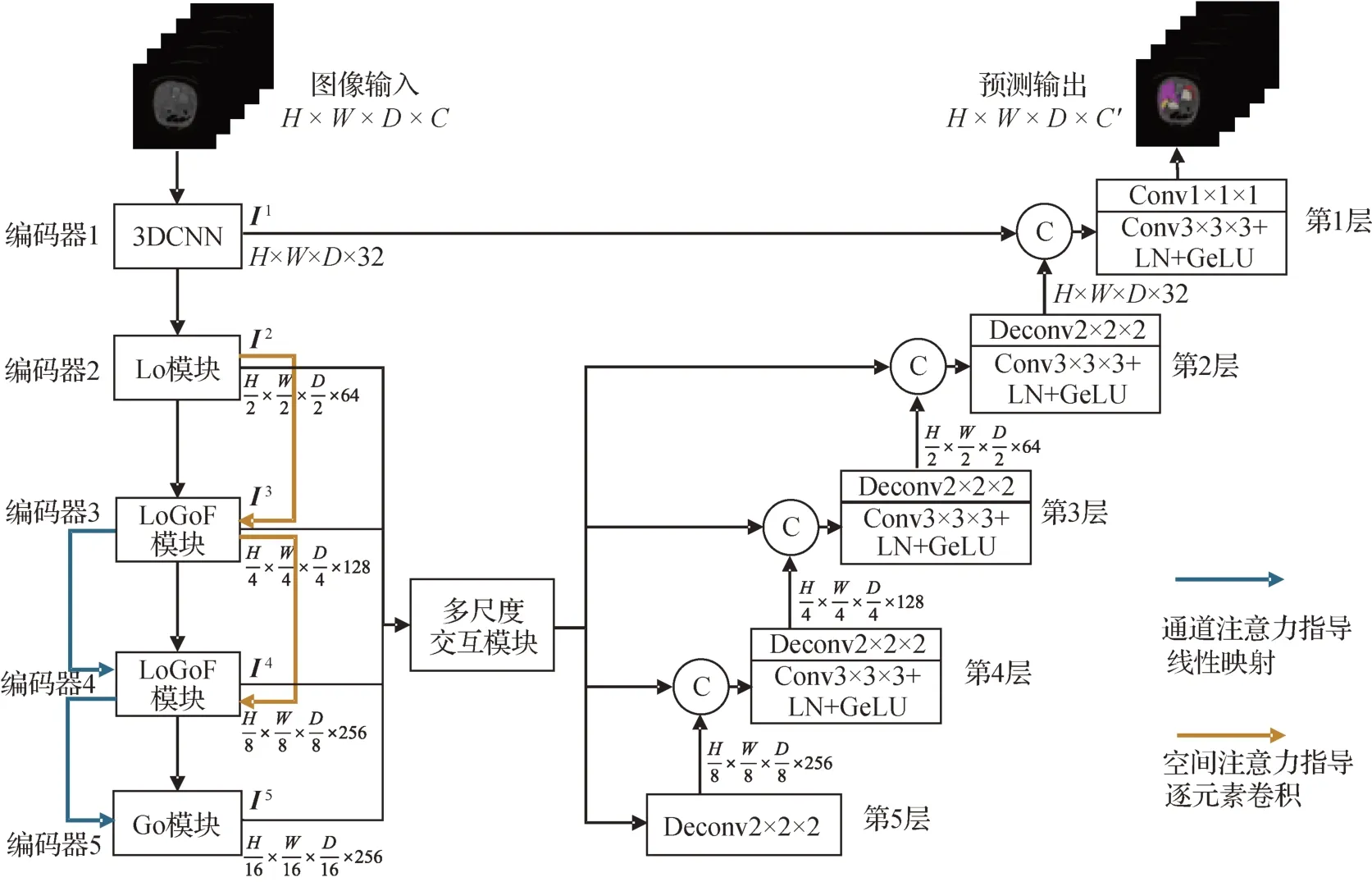
图9 LoGoFUNet网络总体结构Fig.9 Overall structure of the LoGoFUNet
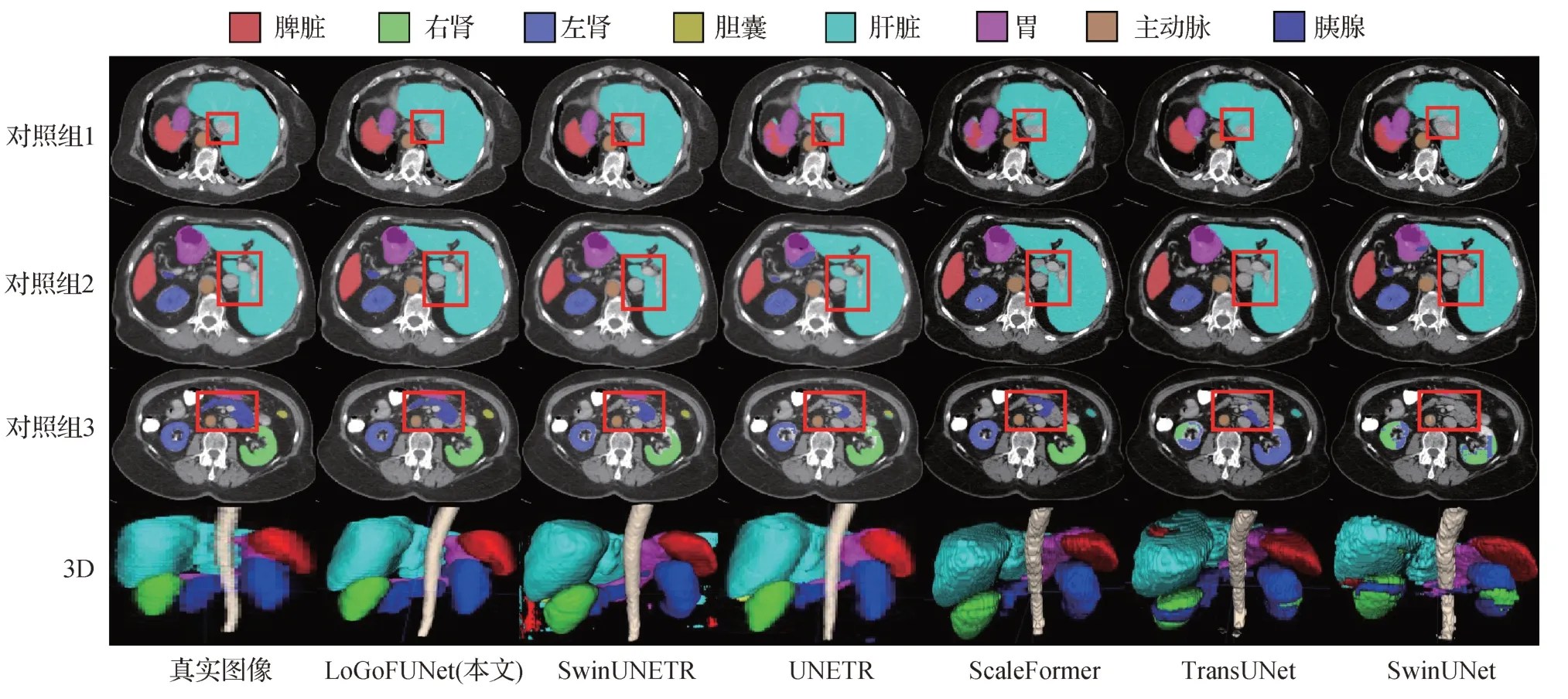
图10 Synapse数据集定性对比结果Fig.10 Qualitative comparison results of Synapse dataset
2.4.2 SegTHOR数据集
表2 展示了SegTHOR 数据集上的实验结果,观察可知,相比于其他方法,LoGoFUNet 在单个器官的平均分割结果指标上均优于对比方法,说明LoGo-FUNet 在整体型器官和长条形器官的组合图像中能完成精确定位和分割。为进行直观对比,本文从测试样本12中抽取3个切片并形成对照组1、2和3,其分割结果的3D对照如图11所示。

表2 SegTHOR数据集对比实验结果Table 2 Comparison experiment results on SegTHOR dataset
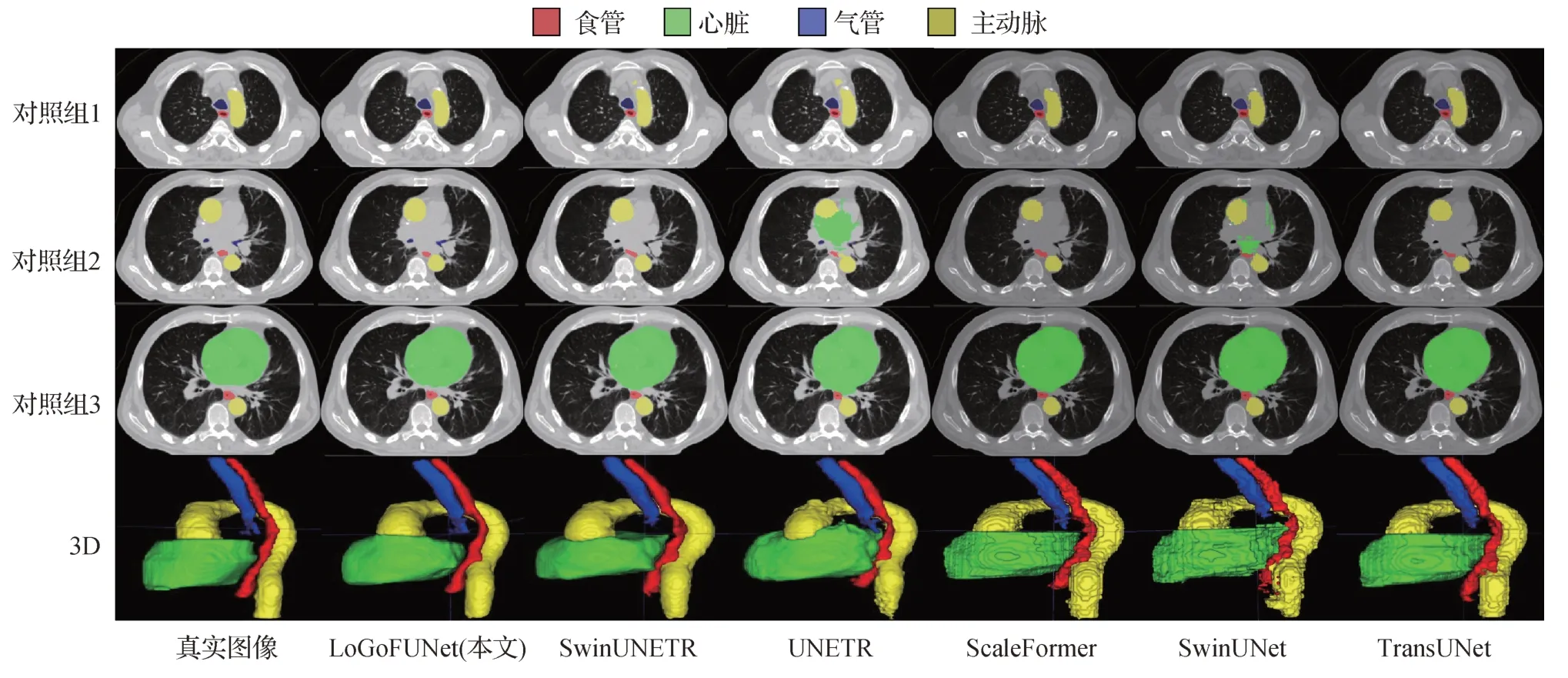
图11 SegTHOR数据集定性对比结果Fig.11 Qualitative comparison results of SegTHOR dataset
对照组1 展示的是位于主动脉上部边缘处的切片,观察可知对照中的2D 方法边缘锯齿感严重,且所有对比方法都存在一定程度的误分割,而LoGo-FUNet具备最精确的分割结果。
对照组2 展示的是气管底部边缘处的切片,在金标准中,气管底部存在分叉结构,因此该横截面切片中的分割结果应当存在分离的部分。由于心脏顶部和气管底部在垂直方向上重叠且跨越了周围的切片,UNETR 和SwinUNet 等方法均出现了误分割情况,只有LoGoFUNet 正确分割了该位置,并和金标准非常接近。此外,在气管底部位置处,食管受到了压缩,对照组2 中只有LoGoFUNet 的结果最符合金标准,其他方法分割的食管均被压得很扁。这也说明LoGoFUNet 能很好地捕捉多个长条形器官之间的位置关系,因而在气管、食管上分割性能较好。
对照组3 展示的是位于心脏器官上部边缘的切片,LoGoFUNet 最精确地捕获了心脏和周围器官的位置关系,而其他的网络对于食管和心脏的定位都过近。UNETR 虽然边缘平滑,但是由于不具备多尺度特征,对目标细节的分割性能明显较差,导致了相对较差的DSC 指标。SwinUNETR 具备多尺度结构,但无法很好地捕捉到心脏上下边缘范围和表面细节。相比之下LoGoFUNet的心脏分割结果具备光滑的边缘和接近金标准的上下部位置,展现出了最好的分割效果。
2.4.3 ACDC数据集
ACDC 数据集上的实验结果如表3 所示。由表3 可知,LoGoFUNet 相比其他的方法,具有最高的平均DSC和最低的平均HD95,且在心肌和右心室器官上表现出最佳的DSC 结果。从网络结构来看,LoGoFUNet 具备细粒度的面自注意力结构,信息可以在矢状面和冠状面上的细粒度柱状token 间自由流通,因此在该数据集上的性能表现大大超越了其他3D 网络。为突出LoGoFUNet 的细粒度面自注意力的优势,本文选择性地可视化了ACDC 数据集中样本09、样本29 和样本46 的frame01。从可视化图12 中可以看出,LoGoFUNet 在量化性能上超越了对比方法的同时,其可视化结果的边缘细节也是最接近金标准的。

表3 ACDC数据集对比实验结果Table 3 Comparison experiment results on ACDC dataset

图12 ACDC数据集定性对比结果Fig.12 Qualitative comparison results of ACDC dataset
2.5 消融实验
2.5.1 M0网络设计
为探究LoGoFUNet中各个模块对网络性能的影响,在Synapse数据集上开展了消融实验,并在M0的基础上衍生了3个变体M1,M2和M3。M1将M0中的幽灵卷积替换为标准3 × 3 × 3卷积结构;M2将M0中的面自注意力替换为标准ViT自注意力;M3将编码器2—编码器5中的Lo模块和Go模块替换为LoGoF模块。
表4 展示了该消融实验的结果。其中,TSD(time spent during 100 epochs)表示训练100 轮次花费的时间,PC(parameters count)表示网络总参数量。由表4 可知,4 种网络最终的平均DSC 差别并不大,但M1、M2 和M3 相比M0,训练100 个epoch 花费的时间分别增加了约10.41%、12.25%和13.63%,总参数量增加了约9.03%、33.53%和35.47%。这表明LoGoF 模块已经基本弥补了局部和全局分支中采用“廉价替代”所带来的性能衰减,在不降低分割性能的前提下,有效减少了网络的参数量。

表4 网络设计对M0实验结果的影响Table 4 The impact on results of M0 design
2.5.2 多尺度交互和注意力指导结构
为探究多尺度交互和注意力指导的有效性,在3个数据集上展开消融实验。从M0上衍生出3个变体模型M6、M7 和M8,M6 代表仅添加注意力指导的M0,M7 代表仅添加多尺度交互的M0,M8 代表两者都添加的M0。在3 个数据集上的实验结果如表5—表7 所示。从表中可以看出,M6 通过添加注意力指导,在Synapse、SegTHOR 和ACDC 测试集上的平均DSC 相比M0 分别提升了0.45%、0.19%和0.07%,M7 通过添加多尺度交互模块,在3 个测试集上的平均DSC 相 比M0 分别提升了2.22%、1.52% 和0.76%,而添加两者之后的M8,在3个测试集上的平均DSC 相 比M0 分别提升了3.15%、1.73% 和1.68%。折线图13 展示了不同模型在3 个数据集上的DSC指标(×100)的直观对比。
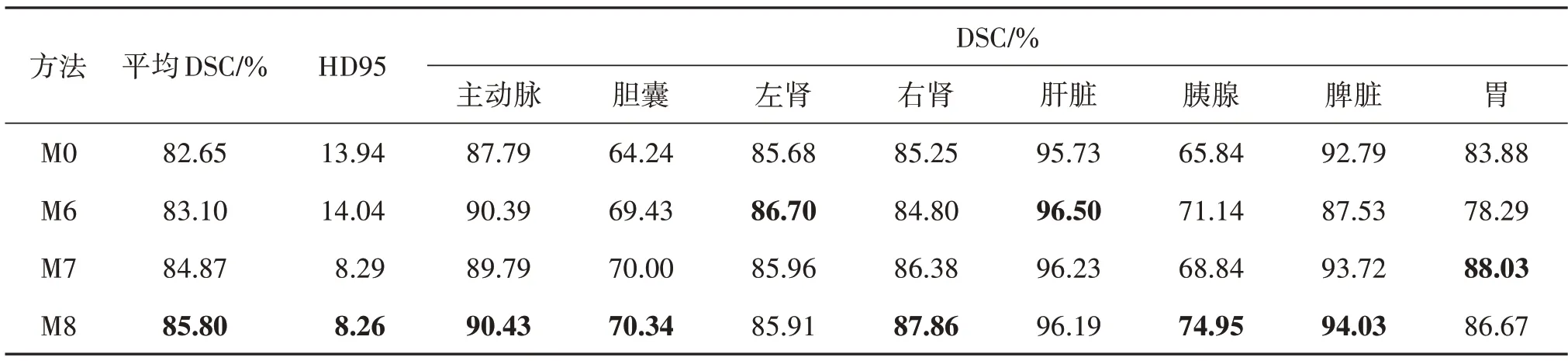
表5 不同消融模型在Synapse数据集上的性能对比Table 5 The performance comparison of different ablation models on Synapse dataset
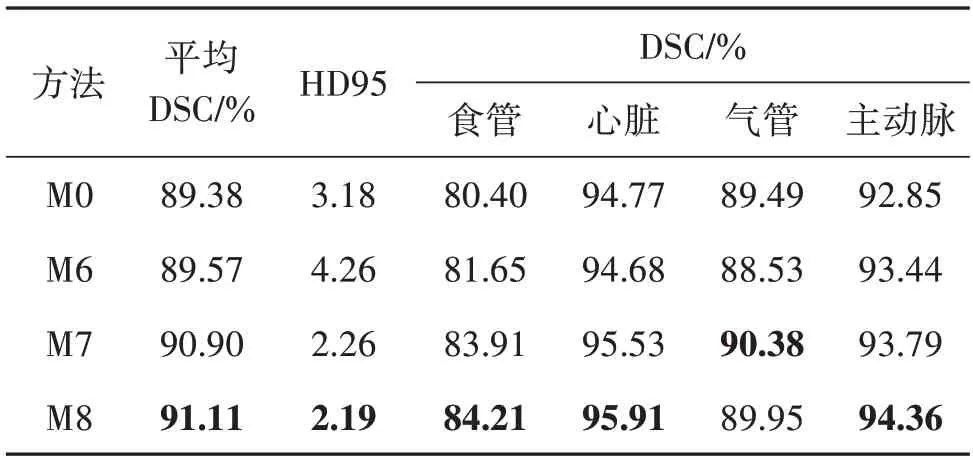
表6 不同消融模型在SegTHOR数据集上的性能对比Table 6 The performance comparison of different ablation models on SegTHOR dataset

表7 不同消融模型在ACDC数据集上的性能对比Table 7 The performance comparison of different ablation models on the ACDC dataset

图13 消融实验的数据集DSC值对比Fig.13 The DSC comparison of ablation experiments
该结果说明,多尺度交互模块和注意力指导结构均对网络分割性能有所提升,且前者带来的提升比后者更显著。
3 结论
为进一步提升三维医学图像多器官分割的性能,本文提出LoGoF编码器,用于在同尺度下用可接受的计算复杂度来融合CNN 和ViT 特征,并基于LoGoF 编码器构建出三维医学图像分割网络M0,该网络在不牺牲ViT 运算范围的前提下实现了网络的多尺度架构。此外,将多尺度交互模块和注意力指导结构引入M0网络,最终构建了LoGoFUNet。该网络继承M0的多尺度架构,能够在三维数据下直接建立多尺度特征之间的信息交互,从而有效提升多器官分割性能。
为验证LoGoFUNet在多器官分割任务上的有效性,本文选择Synapse、SegTHOR和ACDC 3个数据集进行实验,并对比多种2D 和3D 的医学图像分割方法。实验结果表明,相比于表现第2 的模型,LoGo-FUNet 在Synapse 和SegTHOR 数据集上的DSC 指标分别提高2.94% 和4.93%,HD95 指标分别下降8.55 和2.45,表明多器官分割性能的整体改善。尽管实验结果较为乐观,但LoGoFUNet 具有较高的计算复杂度和内存消耗,在训练过程中,即使将批大小设置为1,内存也几乎被占满(接近24 GB)。本文已尝试过使用更激进的轴向自注意力来替代面自注意力运算,尽管在减少参数量的同时基本维持了现有分割效果,但还不足以完全消解如此庞大的模型体量和随之带来的较为缓慢的推理速度。因此通过更合理的设计提升推理速度,降低内存消耗是未来的一个研究方向。另外,由于内存限制,本文提出的多尺度交互结构仅在两个粒度的token 之间进行信息交互,这可能会影响到分割目标尺度差异更大的某些特定数据集上的分割性能,因而引入更多粒度之间的特征交互以及通过其他手段消解由此带来的额外计算量也是未来的一个研究方向。
猜你喜欢
课堂内外·初中版(科学少年)(2023年10期)2023-12-10
娃娃乐园·综合智能(2023年3期)2023-03-24
流行色(2021年8期)2021-11-09
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
成都信息工程大学学报(2018年3期)2018-08-29
数学物理学报(2017年5期)2017-11-23
电子设计工程(2017年20期)2017-02-10
发明与创新(2016年26期)2016-08-22
电子器件(2015年5期)2015-12-29