
细粒度情感和情绪分析中损失函数的设计与优化
2024-03-26 02:39叶施仁AliMDRinku
中文信息学报 2024年1期
叶施仁,丁 力,Ali MD Rinku
(常州大学 计算机与人工智能学院,江苏 常州 213164)
0 引言
情感分析[1]是自然语言处理领域的重要问题,广泛应用于舆情分析和内容推荐等方面。早期的情感分析任务,仅要求输出句子或者文章的正面或者负面的两种情感极性,近年来,出现了一些多样化的任务,如细粒度情感分析[2],方面级情感分析[3]等,使预测的难度显著提升。
与用极性表示的情感分析相比,情绪分析[4]任务拥有更多多样化的标签。如Ekman[5]将情绪划分为六种基本情绪;Plutchik[6]将情绪划分为八种基本情绪,并通过情感轮盘将更多情绪来插入这八种基础情绪中。近年来,很多情绪分析的数据集逐步扩展到多标签任务[7],即一个样本可以有多个标签,也可以没有标签。这种改变是合理且必要的,因为一段文字可以表现出多种情绪,也可以不带情绪。
对文本分类问题,深度学习模型常见的方法是使用预训练的上游模型,在下游任务中进行微调,并通过独热向量计算多分类交叉熵损失(对于多分类任务)或多个二分类交叉熵损失(对于多标签任务)。然而这种方式在细粒度分类任务上显得过于粗糙了。独热向量计算多分类交叉熵损失时,损失值事实上只与正确标签有关(因为仅有正确标签对应的概率被计算)。在多标签任务中,独立计算每个标签的二分类交叉熵。它们都忽略了标签间的相关信息。
在细粒度情感分析中,正例和负例标签往往不是正交的,如非常积极的样本错误地标记成积极,其错误的程度显然应该比标记成消极,或者非常消极小许多,同时区分非常积极与积极的难度也远大于区分非常积极与非常消极。对情绪分析问题,如图1所示,这11类情绪标签之间存在显著的正相关和互相关。因此,我们应该考虑设计适当的损失函数把类别标签之间的相关性体现出来。在计算机视觉领域,流行的方式是通过Ranking loss[8]、Margin loss[9]、Contrastive loss[10]、Triplet loss[11]等成对优化方式度量样本之间的距离。

图1 SemEval18数据集中标签的相关性
情感分析和情绪分析数据集的另一特点是不同类别的样本数差别非常大。如广泛使用的SemEval18数据集[12],在其包含的6 838条推特文本中,频率最高的3个标签累计出现7 623次,频率最低3个标签累计出现1 418次,其最低和最高的平均频次相差5.4倍,如图2所示。在GoEmotions数据集[13]中,在其包含的58 011条推特文本中,频率最高的3个标签累计出现54 713次,频率最低3个样本标签出现2 773次,其最低和最高的平均频次相差19.7倍。
数量庞大的头部标签往往主导了训练过程,甚至导致头部标签上的过度学习。相比之下,尾部标签占比很低,难以得到足够的训练,导致尾部标签上的分类准确率往往不及头部标签。
针对情感分析和情绪分析中普遍存在的标签不独立、分布不均衡的问题,我们借鉴计算机视觉领域中的Circle loss[14]方法。将梯度衰减(Automatically Down-weight)、成对优化(Pair Optimization)、添加余量(Margin)三种深度学习模型优化的损失函数。通过衰减因子平衡数据集中标签的长尾分布,并根据标签的情感/情绪距离,调整超参数余量(Margin),使模型能够学习标签间的距离信息。在不对学习模型进行任何改变的前提下,仅仅通过损失函数的优化,在细粒度情感分析和情绪分析数据集上多个评价指标获得了性能提升,从而验证本文提出的损失函数优化是有效的。
1 相关工作
1.1 深度学习在情感分析与情绪分析方面的进展
基于大规模预训练模型[15],下游任务中通过修改模型结构、调整学习目标、多任务学习[16]等方式来处理细粒度情感/情绪分析任务是当前的主流方法。
Balikas等人[17]使用基于循环神经网络(Recurrent Neural Network,RNN)的多任务模型,同时在二分类和多分类任务上训练模型。在两个任务上都取得了性能提升。Yang等人[18]提出了基于方面的情感分析的多任务学习模型(LCF-ATEPC),该模型同步学习提取方面词和推断方面词极性。结果显示,在常用的方面级情感分析数据集SemEval-2014 task4 Restaurant和Laptop数据集中实现了方面术语提取(Aspect Term Extraction,ATE)和方面极性分类(Aspect Polarity Classification,APC)的性能提升。
Yin等人[19]提出了SentiBERT,在BERT模型的基础上结合了上下文表示法和二元依存解析树来捕捉语义构成。Park等人[20]提出一种多维度的情绪探测模型,模型学习从 NRC-VAD 词典(Mohammad等人[21])获得的标签词的 VAD (Valence, Arousal, and Dominance)分数,并同时预测句子的情绪标签。
Tian等人[22]修改了语言模型的预训练目标,引入了情感知识增强预训练(Sentiment Knowledge Enhanced Pre-training,SKEP),借助自动挖掘的知识,SKEP 进行情感掩蔽并构建三个情感知识预测目标,从而将词、极性和方面级别的情感信息嵌入到预训练的情感表示中,在细粒度情感分析中表现出改进的性能。Suresh等人[23]提出知识嵌入注意 (Knowledge-Embedded Attention,KEA),使用来自情感词典的知识来增强 ELECTRA 和 BERT 模型的上下文表示。
1.2 文本分类中样本标签不均衡
对于数据集标签的不平衡,常用的方法有对数据集进行重采样和调整损失函数的权重。
重采样可分为欠采样和重采样两个方向。对数据集中出现频率较高的标签样本,欠采样方法是随机删除部分样本。但深度学习模型通常需要更多的训练样本。因此,多数工作中对数据集中出现频率较低的样本进行重采样。
简单的重采样直接把数据集中出现频率较低的样本复制多次,来扩充和平衡数据集。更加流行的做法是在重采样中对数据进行一定的变换。图像领域常对图像进行裁剪、缩放、镜像、拼接等操作[24]。自然语言处理领域一般使用同义词替换、随机插入、使用深度学习模型翻译后再回译等[25]。
针对这一问题,深度学习常用的方法是根据样本比例对损失函数的权重进行调整。与简单重采样类似,简单的梯度调整也存在一定的缺陷,如过大的梯度会影响模型的收敛。
在计算机视觉领域,Lin等人[26]提出了Focal loss损失函数,提出了一种损失函数的设计思路。
Focal loss会根据模型输出概率的大小,动态地调节损失函数中的权重,对易分样本的权重进行衰减,从而令模型更关注于难分、未充分学习的样本。
FL(pt)=-(1-pt)γlog(pt)
(1)
其中,
(2)
γ为超参数。实验表明,γ取2时,模型性能最好。
当样本标签y=1时,模型的输出p接近于真值(ground truth),系数(1-p)γ接近于0,对梯度的衰减力度就比较大,从而抑制模型在易分样本上的过度学习。
Focal-loss提出后,获得了广泛的关注与研究,不少文章也提出了自己的Focal loss变体。如Cui等人[27]提出类平衡损失(Class Balanced Focal Loss),根据类平衡项(Class Balanced Term)进一步加权Focal loss,以平衡数据集中样本分布的不均衡。Wu等人[28]更进一步地提出分布平衡损失(Distribution Balanced Loss),聚焦于多标签中的标签共现,首先去除标签共现的冗余信息,再将更低的权重分配给益于分类的实例。Huang等人[29]将多个Focal loss变体应用在多个多标签文本分类数据集上。在尾部标签的分类上,取得了显著的成果。
多标签学习中除了标签种类的分布不均衡,跨数据集间标签数量也有巨大差异。如SemEval18数据集中,41.80%的样本有两个标签,31.87%的样本有3个标签,14.80%的样本有1个标签。而在GoEmotions数据集中,82.68%的样本有1个标签,15.00%的样本有两个标签,2.1%的样本有3个标签。
Li等人[30]将医学图像领域的Dice Loss应用于自然语言处理任务,在广泛的数据不平衡自然语言处理任务上性能提升显著。Dice Loss基于索伦森-骰子系数(Sorensen-Dice Coefficient)或特沃斯基索引(Tversky Index),对误报和漏报的重要性相似,并且不易受数据不平衡问题的影响。
Bénédict等人[31]提出的SigmoidF1-loss是一个近似于Macro-F1分数的损失函数。其首先对模型输出使用Sigmoid函数处理,然后计算F1分数。结果显示SigmoidF1-loss在训练时对于随机梯度下降是平滑且易于处理的,自然地近似于多标签度量,能够很好地估计标签的分布。在多个指标上,SigmoidF1-loss在一个文本和三个图像数据集上的表现优于其他损失函数。
1.3 标签间的相关性
在情感分析和情绪分析中,将标签间的相关性引入模型也是一个重要的研究方向。Alhuzali等人[32]将多标签问题转换为跨度预测问题(Span-Prediction),通过BERT模型学习标签间的相关性。Suresh等人[33]通过引入对比学习损失,与不太相似的负例相比,对容易混淆的负例加权。Wang等人[34]提出了一个通用框架,用于从给定的情感分类数据集中学习情感空间中情感类别的分布式表示,情感空间表示比语义空间中的词向量能更好地表达情感关系。
Diera等人[35]使用了一个简单的多层感知机(Multi-Layer Perceptron,MLP)模型,在多个多标签任务上取得了与BERT、DistilBERT、HiAGM等先进模型相当的结果,但在GoEmotions数据集上多层感知机的性能大幅度落后于基于BERT的模型。这表明在细粒度分类领域,标签间关系是模型设计中不可忽视的因素。
度量学习常用于样本间具有相似性的数据集。比如在人脸识别领域中,人脸照片之间具有较高的相似度,但任务需要辨别出照片中不同人脸所属的人。常见做法是假设特征分布在超球面上如式(3)所示。
(3)
其中,x和μ都经过单位化处理,并且不添加线性层中常见的偏置项。x和μ计算内积,即在计算高维空间中单位向量的相似度。对不同分类的样本,球面上分布有不同的特征中心。大部分工作在此基础上添加超参数余量(Margin),使得类内分布更加紧凑,类间距离更大。如SphereFace[36]、CosFace[37]、ArcFace[38]。
2 损失函数设计
2.1 Circle loss取值的调整
在细粒度情感和情绪分类中,引入适当的梯度衰减和余量是有必要的。Sun等人[14]提出的Circle loss不仅统一了多分类损失和多标签损失,还仅通过引入一个参数,同时将梯度衰减和余量加入到了损失函数中。本文在损失函数设计方案中使用Circle loss在训练阶段引入梯度衰减和余量,并在实验过程中根据研究领域的特点微调了Circle loss的取值范围和取值方式。
Sun等人从统一的相似度配对优化角度出发,使用类别标签学习和样本对标签学习两种基本学习范式,提出了统一的损失函数如式(4)所示。
(4)
其目标是最大化类内相似度sp和最小化类间相似度sn,式中K和L分别为正标签和负标签的数量。
当正标签K取1,缩放系数γ取1时,损失函数退化如式(5)所示。
(5)
即为基于相似度度量的多分类交叉熵损失函数。
而当有多个正标签、多个负个标签时,则式(3)与Yeh等人[39]提出的LCA(Label-Correlation Aware)损失相类似如式(6)所示。
(6)
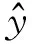
本文在式(3)的基础上引入梯度衰减和余量如式(7)、式(8)所示。
(7)
其中,
(8)

与文献[14] 中Circle loss不同的是,本文将优化目标从sp→1和sn→0扩大到sp→1和sn→-1。Circle loss应用在计算机视觉问题,相似度为0表示两张图片是不相似的,但很难说两张图片是相反的(相似度为-1)。而在情感和情绪分类中,是完全可以描述标签间的对立关系(如非常积极和非常消极,开心和生气),优化目标设计为sp→1和sn→-1更为合理。对文本分类问题,尽管常见的向量空间模型中相似性只在0与1之间,但是对类别标签,我们可以把这种对立关系的标签考虑成相似性为-1,则有优化目标扩展到-1。
同时,本文选择用Sigmoid函数作为衰减函数,与文献[14]中Circle loss使用的线性衰减方式相比,在优化目标sp→1和sn→-1时,如图3~图5所示。

图3 两种损失函数的优化梯度对比
图3(a)为原始的Circle loss梯度图,横轴为sn,纵轴为sp,参数m取0.75,箭头方向表示梯度的优化方向,长短表示梯度的大小。
图3(b)为使用Sigmoid函数作为衰减函数的圆形决策边界梯度图,横轴为sn,纵轴为sp,参数d取0.25,箭头方向表示梯度的优化方向,长短表示梯度的大小。
在这样的参数选择下,它们拥有同样的优化目标sp>0.25和sn<-0.25。

图4 两种损失函数的梯度曲面对比


图5 两种损失函数的梯度曲线对比

2.2 损失函数的推广和讨论
通常,机器学习中把正确或者错误分类的正例和反例分别称为TP(True Positive)、TN(True Negative)、FP(False Negative)和FN(False Negative)。损失函数的设计原则是TP和TN尽可能多,而FP和FN尽可能少。损失函数包含的项应该与正确分类或者错误分类数量具有单调性的,并且是平滑的。
我们将式(3)改写为如式(9)所示。
(9)


此时,可将式(3)简记如式(10)所示。
(10)
与准确率的计算公式对照,可认为Circle Loss是在优化准确率。
更一般地,只要TP′、TN′、FP′、FN′是恰当定义的(正比于模型在TP、TN、FP、FN四个指标上的输出),可以设计出与各种评价指标同形的损失函数。如式(11)~式(13)所示。
• 召回损失:
(11)
•F1损失:
(12)
• Jaccard损失:
(13)
更进一步,我们甚至可以不依照现有的公式,只要优化目标单调保序,令TP′、TN′更大,FP′、FN′更小,如式(14)、式(15)所示。
都是有意义的组合。
本文使用如下公式作为损失函数,在实验中取得了最优结果如式(16)所示。
(16)
其中,
在多标签任务中,仅用准确率作为评价指标是不够的,更优的做法是让模型学习接近Jaccard系数和F1值。如式(16)所示,本文通过在损失函数中加入的FP′、FN′项,令模型学习到的分布更接近与真实数据集的分布。
3 实验
我们选择三个常用的情感分析和情绪分析语料库来验证本文提出的损失函数的有效性,分别为细粒度情感分类数据集SST-5[40],细粒度情绪分类数据集GoEmotions和SemEval18。实验旨在验证本文的损失函数能够在多个复杂数据集上提升主干网络的性能。
我们使用RoBERTa[41]作为模型的主干网络,它是基于BERT模型的改进模型。我们通过Python中的HuggingFace库[42]加载和实例化预训练完成的RoBERTa-base和RoBERTa-large模型。
本文实验所用机器配置为处理器AMD Ryzen 3600,显卡NVIDIA RTX 3090,内存32 GB,操作系统windows 10。Python版本3.8.5,Pytorch版本1.9.0+cu111。
3.1 SST-5数据集
SST-5是一个细粒度的情感分析任务,数据集由句子和情感极性组成。情感极性分为非常消极,消极,中性,积极,非常积极五类。任务是由给出的句子预测出正确的情感极性。
在我们的实验中,使用AdamW优化器,模型的参数r=d,d=0.3,学习率设置为1.5e-6,RoBERTa的最大句子长度设置为256,RoBERTa-base模型词向量长度为768,RoBERTa-large模型词向量长度为1 024。准确率为多次实验结果中验证集上损失函数值最小的模型在测试集上的平均值(取随机种子为2 022递减)。
如表1所示,文献[19] 把RNN当作基准,长短时记忆网络(Long Short Term Memory Network, LSTM)的工作,基于BERT的模型的准确率提高了很多。表中第(8)、第(11)项来自文献[41],是骨干网络RoBERTa的结果;此前的最好结果是来自文献[43]的第(12)项,其使用一个复杂度为O(N2D)的下游模型链接骨干网络来抽取情感信息。结果表明对于细粒度情感分析任务,Circle loss能够有效提升模型的准确率。

表1 sst-5上不同模型的准确率 (单位: %)
3.2 SemEval18数据集
SemEval18数据集来自于SemEval-2018 Task 1。任务是给定一个推特文本,对其标注若干个情绪标签,而这种情绪标签总计有11种。
我们按照SemEval18给定的训练集、验证集和测试集来评估我们的模型。评价标准有三个指标,Jaccard系数,micro-F1(MiF1),macro-F1(MaF1)。其中,Jaccard系数被定义为预测标签和真实标签交集与它们的并集之比。F1值的计算由精确率和召回率组成,micro-F1给予每个样本相同的权重,而macro-F1给予每个类别相同的权重。
实验使用AdamW优化器,模型的参数r=12,d=0,学习率设置为1e-5,RoBERTa最大句子长度设置为128,各个评价指标为多次实验结果中验证集上损失函数值最小的模型在测试集上的平均值(取随机种子为2 022递减)。
如表2所示,编号(1)~(8)的实验列出了这个测试集上的经典结果和最新的结果。在骨干网络RoBERTa-base 上使用uni-loss损失函数(9)得到的结果比最新的结果(8)要差一些,已经具有不错的结果。这是由于uni-loss在优化过程中是正例和负例成对优化的。我们在骨干网络RoBERTa-base上使用带有衰减和余量的sig-loss(10),实验显示优于最新的结果(8)。

表2 SemEval18评价指标 (单位: %)
对比标准的uni-loss损失函数(9),我们提出的损失函数sig-loss在Jaccard系数、micro-F1、macro-F1值上均取得了显著的提升[(如(10)和(11)],其中Jaccard系数和macro-F1的假设检验p<0.05,micro-F1的假设检验p<0.01,均在统计学上显著。由于sig-loss中梯度衰减和余量是一同出现的,形成圆形的决策边界。假如只考虑其中一项,就会破坏其设计结构。如果两项一起去掉,sig-loss将退化成uni-loss。
多分类中常用的二元交叉熵(Binary Cross Entropy,BCE)损失,将每个标签看成一个二分类问题,输出“是”或者“不是”。这种优化方式忽略了标签之间联系的学习。最新的结果[表2中的(8)]来自文献[32],使用了二元交叉熵损失和文献[39]提出的LCA损失联合训练。其使用的LCA损失,正是基于正例和负例成对优化来学习标签间的联系。
如文献[29]所示,Focal loss引入的梯度衰减能够动态调节梯度的分配,在标签长尾分布的情况下,能够有效地提升模型的性能。
Circle loss中同样带有梯度衰减,实验结果也显示在更加重视类别均衡的macro-F1分数上,RoBERTa-base+sig-loss领先于基线模型RoBERTa-base+uni-loss。
此外,如果使用规模更大的RoBERTa-large作为主干网络,维度从768维提升到1024维,会取得更好的效果。
3.3 GoEmotions数据集
与SemEval18数据集相比,GoEmotions含有更多样本、更多的标签种类。其样本数量达到5万条,共有27个情绪标签和1个中性标签,并已被开发者划分为训练集、验证集和测试集。我们仍然使用Jaccard系数,micro-F1,macro-F1三个指标来评价结果。
实验使用AdamW优化器,模型的参数γ=12,d=0.2,学习率设置为1e-5,RoBERTa最大句子长度设置为128,各个评价指标为多次实验结果中验证集上损失函数值最小的模型在测试集上的平均值(取随机种子为2 022递减)。
如表3所示,我们使用带有衰减和余量的RoBERTa-base+sig-loss和作为基线模型的RoBERTa-base+uni-loss与其他相关工作中的结果进行比较。结果在Jaccard系数、Micro-F1、Macro-F1值上均取得了显著的提升,其中Jaccard系数、Micro-F1、Macro-F1的假设检验p<0.01 ,在统计学上显著。
基于二元交叉熵损失的模型最终的阈值确定依赖于在验证集上取不同的阈值对模型进行测试。在模型的训练过程中,阈值对模型没有任何影响。而在sig-loss中,可以将余量取为阈值。假设基于二元交叉熵损失的模型最终阈值选定为0.2而不是0,而模型事实上训练时的决策边界是0,这恰恰说明在决策边界上,模型并不能很好地区分正例和负例,将阈值取为0时,会出现大量误判,导致评价指标降低。sig -loss中引入的余量参数,把阈值作为模型训练中的一个超参数,参与到模型的训练中来。模型取更大的阈值,不仅仅是最后的判定上更严格,在训练时,正例和负例会获得更大的类间距离和更小的类内距离,这有利于模糊样本的判定。
3.4 消融实验
我们选取了SemEval18数据集中两对高相关性的标签,计算在选定其中一个标签的情况下,模型在另一个标签上的准确率。如表4中anger-disgust列,表示选择测试集中有anger标签的数据,计算模型在disgust标签上的准确率。结果显示,用本文2.2节中的方式调整后的损失函数能够有效提升标签相关时的准确率。

表4 相关标签间的准确率 (单位: %)
表5中,我们计算了模型在SemEval18数据集中出现频率最低的5个标签上的Jaccard系数,micro-F1,macro-F1。结果显示,与基线模型相比,用本文2.2节中的方式调整后的损失函数能够有效提升模型在尾部标签上的性能。

表5 尾部标签的评价指标 (单位: %)
4 结论
考虑到情感和情绪分析数据集中标签广泛存在的分布不均衡、标签之间具有相关性的现象,我们使用Circle Loss针对性地引入了梯度权重衰减、配对优化、度量学习的方法,并推广了Circle Loss的计算公式。其中,梯度权重衰减动态地调节梯度的分配,在标签长尾分布的情况下,能够有效地引导模型学习稀少、难分的样本;配对优化与二分类交叉熵相比,能够隐式地学习标签之间的相关性;针对难分标签,使用度量学习中的余量,加宽决策边界,令正例和负例获得更大的类间距离和更小的类内距离,使样本更容易区分。Cirlce Loss可视为优化模型的准确率,在多标签分类中,仅优化准确率还不足以使模型达到最优,我们的推广公式可以灵活地优化各种指标,如召回值、F1值、Jaccard系数等。
在多个测试集上的实验表明,仅仅通过改进损失函数,获得的结果比最新的经典方法有所提升,说明了本文构造的损失函数是有效的。
特别地,我们设计的损失函数没有使用多目标优化的方式,而是将多种优化方式在一个损失函数中体现,减少了超参数的数量。该损失函数的框架与具体学习任务无关,可能适用各种深度学习模型。在多分类任务上验证本文所提出的损失函数的有效性和性能,是我们将来工作的重点。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
数学小灵通·3-4年级(2021年5期)2021-07-16
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
今日农业(2019年15期)2019-01-03
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
计算机工程(2015年8期)2015-07-03
