
一种适用于小RAM 和ROM 嵌入式设备的动态组字系统
2024-04-12 09:01葛炳仑GEBinglun
价值工程 2024年8期
葛炳仑GE Bing-lun
(西交利物浦大学,苏州 215123)
0 引言
随着当代计算机技术和汉语言文字处理技术的不断发展和进步,人们对于汉字的输入和显示逐渐有了更多新的追求。例如,随着屏幕制造技术的进步,嵌入式设备的屏幕尺寸和显示性能已经有了较为明显的进步。传统的单色点阵字体已经无法满足当今时代的需求。同样地,对于汉语言信息处理,传统的GB-2312 字库很难显示一些人名和地名中的生僻字,如“赵孟”、“岗站”等。据不完全统计,全国有超过6 000 万人的名字中包含了生僻字。[1]这就需要有相应的Unicode 字库的支持。目前市面上的绝大多数Unicode 字库都采用了TrueType 或OpenType 矢量格式。虽然可以实现任意尺寸的抗锯齿渲染,但占用空间大,所需的算力较高,不适用于存储空间和内存空间受局限的嵌入式设备。同样地,相应字体转换来的位图字体也需要大量的存储空间,且需要为每个尺寸生成单独的字体文件,占用了太多不必要的空间。因此,有必要引入动态组字技术实现更低的存储空间占用及运算时间消耗。
1 已有的汉字显示技术概述
1.1 位图字体显示法
位图字体是历史最为悠久的计算机字体,也被称作光栅字体或点阵字体。它的结构简单、显示快速,因此也是在嵌入式系统中所使用最多的字体格式。然而,它的缺陷也比较明显。首先,对于不同尺寸的汉字,需要分别为其准备字体文件。也就是说,将造成极大的空间浪费。其次,对于抗锯齿字体,它需要更多的空间占用。例如,如果抗锯齿需要16 个灰度,则其所占用的存储空间是黑白字体的4 倍。但是对于其他的矢量格式,则不需要额外的存储空间。
1.2 矢量字体显示法
矢量字体又称轮廓字体,这是目前应用最广的汉字显示技术,它存储了每个汉字的图像矢量轮廓。因此,它相较于位图字体有更多的优点。例如,矢量字体不需要为每个不同尺寸的字形单独占用存储空间,只需要储存一次就可以绘制出不同尺寸的中文字形。此外,它也不需要更多的存储空间就能实现抗锯齿渲染。但是,尽管有一些针对于嵌入式设备的优化[2],但矢量字体仍然需要大量的存储空间占用。这是因为对于汉字,矢量字体需要冗余地存储不必要的衬线等部分,这占用了大量的存储空间。因此,矢量字体对于嵌入式汉字字形的显示并不是最佳方案。
1.3 动态组字显示法
动态组字技术在中文信息处理发展史上有着很长的历史。在1985 年,朱邦复等人就曾对此进行过研究[3]。朱邦复的动态组字方案基于仓颉输入法,利用对汉字部件位图的变换实现对位图中文字体的动态生成。但是由于他的系统完全由8080 汇编编写,移植性很差,并且只支持繁体中文的生成,目前已经退出了市场。此外,在日本,大东文化大学的上地宏一等人开发的“影KAGE”汉字字体自动生成系统[4]、东京大学的田中哲朗等人开发的“和田研”部件合成的汉字骨架字体生成系统(见图1)[5]等也对动态组字技术作出了尝试。由于其使用了LISP 语言进行迭代生成,因此对于内存空间的占用较大,并不十分适用于嵌入式系统。此外,这两个系统也只能生成单一风格的字体,局限性较高。近年来,随着深度学习技术的发展,可以利用它生成高质量的不同风格的动态组字字体。但是由于其需要大量的算力,无法在嵌入式设备上运行。
2 IDS 字形描述数据库及部首存储格式
1999 年9 月,Unicode 发布3.0 版本,定义表意文字描述序列(Ideographic Description Sequence,缩写为IDS)和表意文字描述符(Ideographic Description Characters,缩写为IDC)。IDC 共12 描述符(U+2FF0 至U+2FFB),如表1所示。IDS 的语法比较简单,只要求三元IDC(U+2FF2 和U+2FF3)后面必须有3 个IDS,二元IDC(U+2FF2 和U+2FF3 以外的其他IDC)后面必须有2 个IDS,IDS 中除了IDC 以外必须是一元CJK 字符。IDS 还有2 个长度限制:序列长度不可超过16 个Unicode 编码;如果没有表意文字描述符作为间隔,构成序列的部件或者偏旁不能超过6个。IDS 支持递归算法,应注意递归深度和逆向扫描长度[6]。
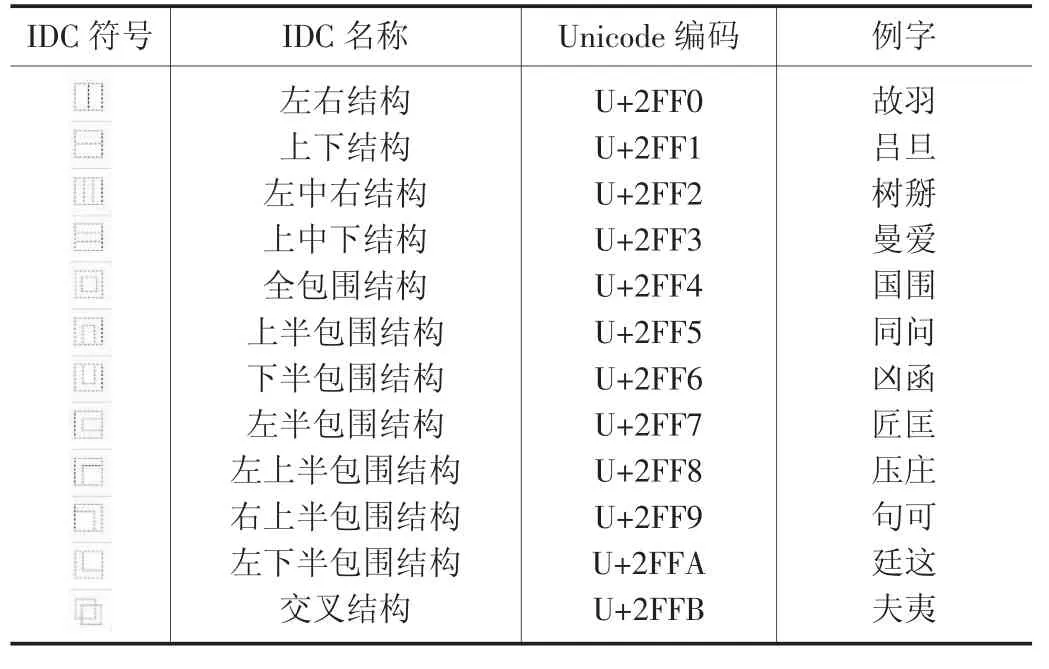
表1 IDC 编码表
本系统将字形存储部分分为两部分,分别是IDS 字形描述数据库以及部首笔画结构数据库。
2.1 IDS 字形描述数据库
由于本系统需要考虑在嵌入式设备上运行,因此需要优化时间和空间效率。该数据库是一系列二进制文件,分为索引头和IDS 数据两部分。
以中日韩统一表意文字扩展区A 区的汉字为例,索引头的结构为:
<uint32:Index><uint8:Length>
如果要读取“打汇”的IDS 数据,则程序将读取uint32 ExtA['打汇'*5] 开始的uint8 ExtA['打汇'*5+1]个字节的数据。
2.2 部首笔画结构数据库
类似地,系统以类似IDS 字形描述数据库的结构存储部首笔画结构数据库中的数据。为了节约空间占用,部首笔画数据库以二进制格式存储。它的BNF 形式描述为:
radical::=<width><height>
<variantsNumber>{<variant>}
<componentsNumber>{<components>}
variant::=<position><codePoint>
components::=<type>(
<dataHanzi>|
<dataLine>|
<dataCurve>
)
dataHanzi::=<codePoint><xyInit><xyFinl>
dataLine::=<xyInit><xyFinl>
dataCurve::=<xyInit><xyMedi><xyFinl>
codePoint::=<uint8><uint8><uint8>
<width>::=<uint8>
<height>::=<uint8>
<variantsNumber>::=<uint8>
<componentsNumber>::=<uint8>
<position>:==<x><y>
<xyInit>:==<x><y>
<xyMedi>:==<x><y>
<xyFinl>:==<x><y>
<x>::=<uint8>
<y>::=<uint8>
<type>::=<uint16>
3 笔画生成
个汉字笔画大致可分为两部分,骨架和衬线。我们可以将每个汉字的骨架视为它的基本,而印刷字体比如宋体和仿宋体都有衬线附着于笔画的骨架上以提高阅读效率和可辨认度。黑体可以视为一种只有骨架而没有衬线的特殊字体。因此,本系统在绘制笔画时将分别处理其笔画和衬线。
汉字有四种基础笔画:横、竖、撇、点。其中,这些基础笔画又可以分为主笔形和附笔形。折是一种特殊的笔画类型,包含有很多种复合笔形。因此,在程序中主要处理这四种基础笔画及其复合笔形的绘制方法。
3.1 横和竖
这是两种最基础的笔画,可以视作是一条线段及其附属衬线。系统将绘制一个矩形,并将衬线附加到矩形上。
3.2 撇和点(捺)
我们可以应用二次贝塞尔曲线来拟合这两种笔画的轨迹。
根据以下步骤,我们可以绘制出这两种笔画:
二次贝塞尔曲线的插值公式为:
其中:P0为起始点,P1为控制点,P2为终止点,t 为补偿系数,一般取0.2。
①利用该公式,我们可以计算出在该曲线上连续的点的水平座标。
②接下来我们可以将每个点为(0,0),求它下一个点的极座标(分别是第i 个点和第i+1 个点)。
③并在当前点为中心,分别向x 轴的正方向和负方向平移Bold(i)的距离,得出点p1和p2。
④对于这两个点,以当前点为中心旋转θ。
⑤将这两个点的座标放到轮廓数组中。
⑥以顺时针顺序分别连接轮廓数组中的点矢量,形成笔画轮廓。
其中,Bold 函数决定了轮廓的粗细变化。我们可以利用一个Sigmoid 回归函数来拟合具体的字体,如宋体或仿宋体。
在实际应用中,对于字号较小的情况可以直接用直线连接这些点。如果在字号较大的情况下,可以采用B 样条曲线以尽量使轮廓平滑。
3.3 复合笔画
如表2 所示,复合笔画可以被看作是多个基本笔画的结合。其中,我们可以发现这些基本笔画相交的地方,衬线融合成了一个衬线。因此,在绘制过程中需要计算出笔画交点,在删除原有的衬线之后在该位置绘制一个新的衬线。
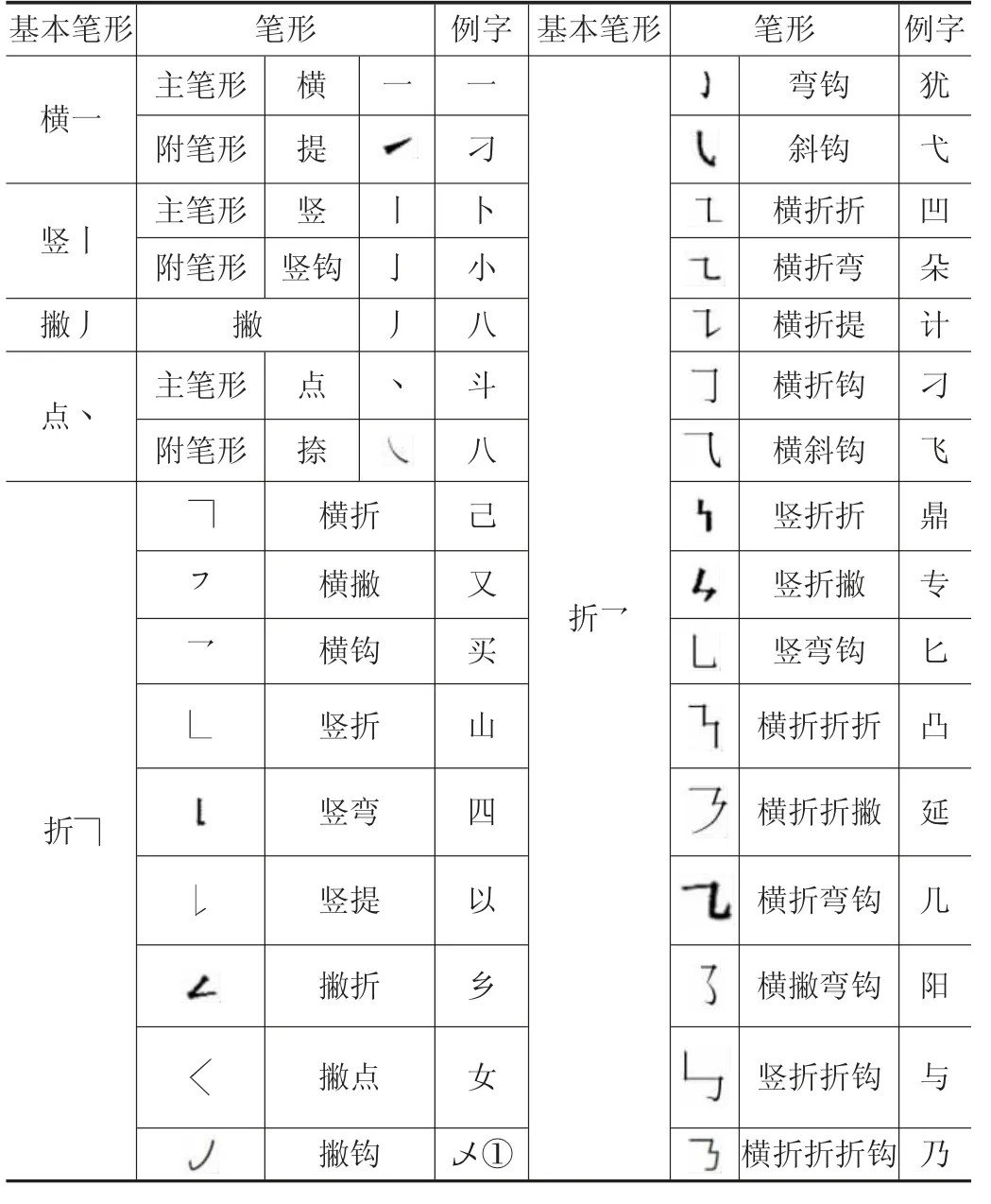
表2 现行汉字笔形表[7]
3.4 优化处理
为了保证字形最后生成效果的美观性,本系统在笔画生成完毕后检查每个笔画周围1/64 范围内的填充情况。如果周围已经有了笔画被绘制,则将减小衬线大小或笔画粗细。
由于这种优化处理需要更多的计算量,因此它是可选的。
4 实例分析
4.1 测试环境
采用了ESP32-S3-N16R8 单片机运行该系统。这款单片机的ROM 容量为16MB,RAM 容量为8MB。
由于测试所使用的SimSun 字体大于本单片机ROM容量,因此我们将其存储到了TF 卡上。这造成了显著的拖慢。
4.2 测试结果
图2是本系统的渲染结果,其中红色的部分是衬线。

图2 本系统的渲染结果图
图3是在16*16 分辨率下优化的显示结果,可以发现它的横和竖具有更高的辨识度。

图3 优化显示结果图
表3所示为本系统运行的系统资源占用情况对比。

表3 系统资源占用情况对比
分析可见,本系统在存储空间方面表现良好,尤其适用于ROM 空间小的嵌入式系统。而矢量字体由于其体积原因,需要额外的TF 卡适配器来存储,将提升制造成本。同时,这也将减慢其运行速度。对于位图字体,每个尺寸的汉字都需要单独的字体文件,这将大大浪费宝贵的存储器空间。
在内存占用方面,只需要128kB 以内的内存就能运行此系统,同样优于TrueType 字体。值得注意的是,位图字体由于其特性,使用时几乎不需要内存占用,速度也是最快的。也就是说,在极低性能的嵌入式场景下,本系统仍然无法取代位图字体。
猜你喜欢
智能计算机与应用(2021年6期)2021-12-17
——识记“己”“已”“巳”
小学生学习指导(低年级)(2020年12期)2021-01-16
综艺报(2020年21期)2020-11-30
学生天地(2020年14期)2020-08-25
娃娃乐园·综合智能(2020年2期)2020-03-12
电脑爱好者(2019年17期)2019-10-30
小天使·二年级语数英综合(2018年10期)2018-10-15
创新作文(小学版)(2017年5期)2017-05-13
小雪花·成长指南(2014年10期)2014-10-31
移动一族(2009年3期)2009-05-12
