
Label Recovery and Trajectory Designable Network for Transfer Fault Diagnosis of Machines With Incorrect Annotation
2024-04-15 09:37BinYangYaguoLeiSeniorXiangLiSeniorNaipengLiandAsokeNandi
Bin Yang ,,, Yaguo Lei , Senior,, Xiang Li , Senior,,Naipeng Li ,,, and Asoke K.Nandi ,,
Abstract—The success of deep transfer learning in fault diagnosis is attributed to the collection of high-quality labeled data from the source domain.However, in engineering scenarios,achieving such high-quality label annotation is difficult and expensive.The incorrect label annotation produces two negative effects: 1) the complex decision boundary of diagnosis models lowers the generalization performance on the target domain, and 2) the distribution of target domain samples becomes misaligned with the false-labeled samples.To overcome these negative effects,this article proposes a solution called the label recovery and trajectory designable network (LRTDN).LRTDN consists of three parts.First, a residual network with dual classifiers is to learn features from cross-domain samples.Second, an annotation check module is constructed to generate a label anomaly indicator that could modify the abnormal labels of false-labeled samples in the source domain.With the training of relabeled samples, the complexity of diagnosis model is reduced via semi-supervised learning.Third, the adaptation trajectories are designed for sample distributions across domains.This ensures that the target domain samples are only adapted with the pure-labeled samples.The LRTDN is verified by two case studies, in which the diagnosis knowledge of bearings is transferred across different working conditions as well as different yet related machines.The results show that LRTDN offers a high diagnosis accuracy even in the presence of incorrect annotation.Index Terms—Deep transfer learning, domain adaptation, incorrect label annotation, intelligent fault diagnosis, rotating machines.
I.INTRODUCTION
Deep transfer learning has been reported to leverage the diagnosis knowledge gained from analyzing well-studied machines (source domain) to diagnose issues in other related machines (target domain) [1].By this, the users do not need to train a diagnosis model by massive labeled data in the target domain, but could reuse the model from the source to the target [2].Therefore, this is a promising tool to achieve fault diagnosis of machines with respect to the fact that few labeled data are available in engineering scenarios.
The applications of deep transfer learning to fault diagnosis have captured the attention of both researchers and engineers[3].The relevant achievements can be divided into two phases.In the early phase, deep neural networks are constructed to learn features from both the source and target domain data.The cross-domain feature distributions are further adapted to make the diagnosis model work well in both the source and target domains.For the distribution adaptation,some distance metrics, such as maximum mean discrepancy(MMD) [4]-[7] and correlation alignment (CORAL) [8], are commonly used.Another commonly-used approach for the feature distribution adaptation is the generative adversarial network (GAN) [9]-[11].Notably, research in [12] has shown that GAN can essentially reduce the Jensen-Shannon divergence of the feature distribution.In the recent phase, the research regarding transfer fault diagnosis has been developed to adapt sub-class feature distributions [13]-[15].For example, the clustering or pseudo-label algorithms are used to search for the potential clusters of unlabeled target domain samples, and then the distribution adaptation is implemented among these clusters across domains [16].Such refined adaptations are superior to the previous phase through the validation of many transfer fault diagnosis tasks, e.g., the transfer across different working conditions and across different yet related machines.
The aforementioned success of deep transfer learning-based fault diagnosis is largely attributed to the collection of highquality labeled data from the source domain.The pure labels make the diagnosis model learn precise diagnosis knowledge,i.e., the relationship between the monitoring data and the health states of machines [17].In engineering scenarios, however, it is difficult to annotate a large number of source domain data with high-quality labels [18].To explain this, we analyze the usual label annotation ways in machinery fault diagnosis as follows.1) The disassembly and inspection make it possible to annotate data accurately, but they are time-consuming and expensive.The frequent downtime meanwhile causes a huge economic loss, especially for large equipment,such as gas turbines and shield machines.On the other hand,the disassembly may produce false labels in certain scenarios.In a bearing manufacturing base, for example, it is assumed that a quality inspector finds a defect on the outer race of a testing bearing through disassembly, and thus annotates the collected data as the fault.If the bearing rollers do not pass through the defect during the running, the data should be actually annotated as the normal condition rather than the fault.2) The human annotation relies on expert knowledge to analyze the collected data, such as the judgments relying on auditory sense or touch sense.Thus, the label annotation quality is associated with work experience and subjective factors of the annotators.Unskilled annotators would make incorrect judgments, and the increasing work intensity and inactive emotion also enhance the risk of incorrect label annotation.3) Compared with the human annotation, software annotation is a more efficient way to achieve labels, especially for a large number of monitoring data.The label quality is affected by software accuracy.For the signal processing-based software,the accuracy is related to the distinguishability of the extracted fault features as well as the effectiveness of thresholds among different fault types.It is usually difficult to annotate the incipient fault data accurately due to the unclear boundary.For the intelligent diagnosis-based software, the accuracy is subject to the performance of the used diagnosis models.The limited number of available data usually hinders the application of intelligent diagnosis models.
The source domain data with incorrect label annotation will reduce the performance of deep transfer learning-based fault diagnosis.This affects two aspects.First, the diagnosis model becomes overfitting on the source domain samples that are incorrectly annotated, as shown in Fig.1(a).The complex classification boundary of diagnosis models misrecognizes the target domain samples, although the sample distributions are well-adapted across domains.Second, some target domain samples in Fault A, as shown in Fig.1(b), are misaligned with the source domain samples that are incorrectly annotated as Fault B after the distribution adaptation.As a result, the diagnosis model from the source domain will result in low accuracy on the target domain.
To overcome the above problems, a label recovery and trajectory designable network (LRTDN) is proposed for transfer fault diagnosis when the incorrect annotation occurs in the source domain.The LRTDN is expected to reconstruct the labels of source domain samples as well as the adaptation trajectories across domains, removing the effects of incorrect annotation on the deep transfer learning-based fault diagnosis.In this article, we make the following contributions.
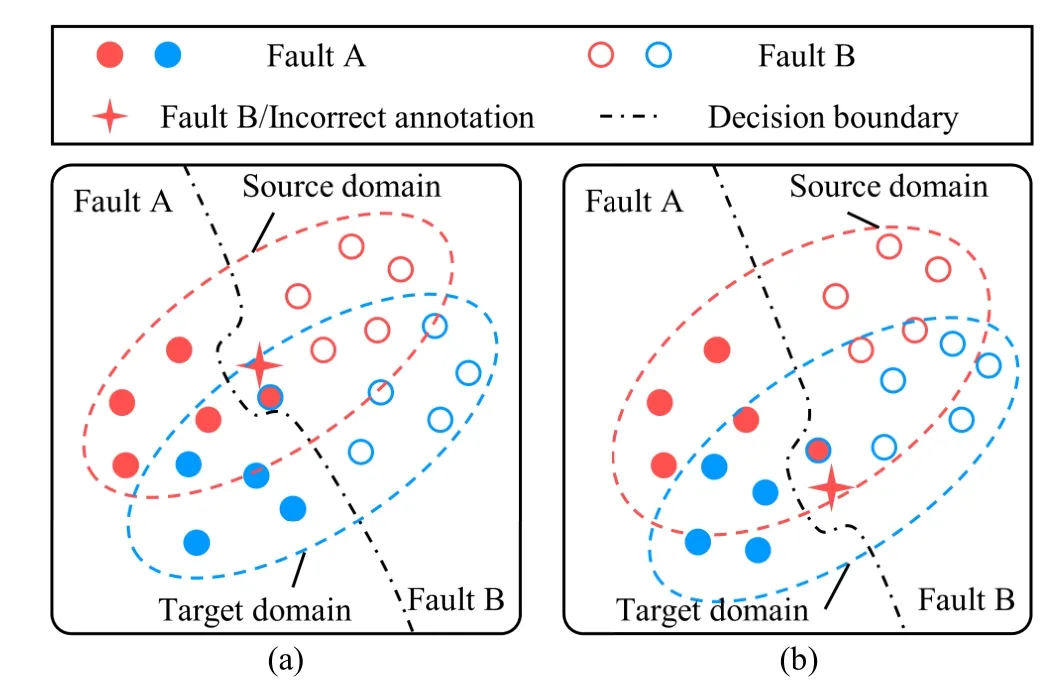
Fig.1.Simulation of negative effects of incorrect label annotation on the deep transfer learning-based fault diagnosis: (a) Overfitting on incorrectly annotated source domain samples; (b) Misaligned with the distribution of incorrectly annotated source domain samples.
First, a semi-supervised learning strategy is presented to address the overfitting of the diagnosis model on incorrectly annotated samples.We construct a label anomaly indicator by comparing the feature similarity and the gradient direction of incorrectly annotated samples with other pure-labeled samples.Such an indicator is expected to evaluate whether the samples have incorrect labels, and further modify their abnormal labels.Training the diagnosis model by using the modified labels may lower the complexity of the classification boundary.
Second, we design the adaptation trajectories with respect to the false-labeled samples by the optimal transport (OT) theory.The designed trajectories may increase the cost of moving target domain samples to false-labeled samples in the source domain.In this way, abnormal adaptation trajectories are avoided.As a result, the target domain samples are expected to be only aligned with the pure-labeled samples.
The rest of this article is organized as follows.Section II reviews the related works and summarizes the difference from LRTDN.Section III formularizes the transfer diagnosis task and the OT theory.Section IV details the proposed LRTDN,and its performance is demonstrated via two cases shown in Section V.The conclusions are enclosed in Section VI.
II.RELATED WORK
A. Unsupervised Domain Adaptation
This article refers to the unsupervised domain adaptation(UDA) tasks in machinery fault diagnosis, where the source domain is fully labeled and the target domain is unlabeled [2].To achieve knowledge transfer across domains, existing works use deep learning to get high-level features, and further reduce feature distribution discrepancy during the training of deep networks.For example, the deep domain confusion (DDC)reduces the MMD of learned features [19], achieving some early successes in the field [3], [20].The domain adversarial neural network (DANN) is proposed to solve the domain shift through the GAN [21], which pioneers another main branch for transfer fault diagnosis [3], [20].Through the OT theory,recent works build a similar logic to the DDC, yet aim at more exquisite adaptation [22].The refined adaptation methods are the major developments in current research, where both the marginal and conditional distribution shifts are concerned with sub-class features [16].Subdomain adaptation methods like deep joint distribution optimal transportation (DeepJDOT) [23] achieve state-of-the-art results for knowledge transfer in unsupervised settings.The above success is achieved based on the assumption that the source domain samples have high-quality label annotation, which is difficult to be true in reality.Meanwhile, the cross-domain distribution alignment lacks controllable adaptation directions.Differently from existing works, this article is expected to explore the label recovery approach for the incorrectly annotated source domain samples and design the trajectories for domain adaptation, addressing issues from the UDA with incorrect annotation.
B. Learning From Incorrectly-Annotated Datasets
The incorrect annotation is an active issue for the training of discriminative models.Three types of methods are widely concerned [24].First, scholars target robust architectures like adding a noise adaptation layer at the top of the deep network to discover the label transition matrix from the truth to the false [25].This method family cannot identify false-labeled samples, and thus is invalid for some tasks subject to a large ratio of incorrect annotation.The adjustment of training loss is the second solution against false-labeled samples in the source domain, where the importance of abnormal samples is reduced during the training of discriminative models [26].The cumulated error drawn from false adjustment is the main problem of these methods.Currently, the sample selection strategy is a main branch of deep learning subject to incorrect annotation[27].The multi-head networks [28] are built to distinguish false-labeled samples from the whole if certain indicators,such as the sample loss, are larger than the given threshold.It is noted that the threshold greatly affects the performance of sample selection, but it is usually set manually.The above works do not concern the distribution discrepancy between the training and testing datasets.In contrast, we propose to address problems arising from the cross-domain along with incorrect annotation in the source domain.The proposed method is also expected to provide a promising way to automatically learn the threshold for sample selection.
C. UDA Against Incorrect Annotation
Some exploratory works have been developed for the UDA in the presence of incorrect annotation in the source domain.For example, collaborative unsupervised domain adaptation(CoUDA) is proposed by Zhanget al.[29] to add a noise adaptation layer in two identically configured networks, and the cross-domain discrepancy is corrected by adversarial learning.Transferable curriculum learning (TCL) sets a curriculum to reweight the adversarial loss of GAN [30].In this method, the discriminator loss serves as the indicator for falselabeled sample selection in the source domain.Reference [31]presents the noisy universal domain adaptation (NUDA), in which the divergence of two classifiers is optimized for sample selection.Existing works only select the pure-labeled source domain samples to train the discriminative models, but ignore the positive contribution of false-labeled sample distributions.Moreover, the sample selection threshold setting relies on expert experience.In contrast, this article presents a semi-supervised learning strategy, where the false labels of source domain samples are expected to be recovered so that they could also train the models together with other purelabeled ones.A new indicator that is associated with the feature similarity and gradients is presented for a more reliable sample selection, and the threshold is self-trained without manual settings.In addition, this article extends the OT-based domain adaptation family to the case of incorrect annotation,which provides more controllable adaptation performance than the GAN-based way in existing work.
III.TRANSFER DIAGNOSIS TASKS AND BASIC THEORY
A. Diagnosis Task Description

B. OT Theory

IV.THE PROPOSED METHOD
To achieve the distribution adaptation against incorrect annotation, this article presents LRTDN for the transfer fault diagnosis of machines.The architecture of LRTDN is shown in Fig.2.It includes three parts, i.e., the dual-view residual network, the annotation check module, and the OT module with modified adaptation trajectories.They are detailed in the following subsections.
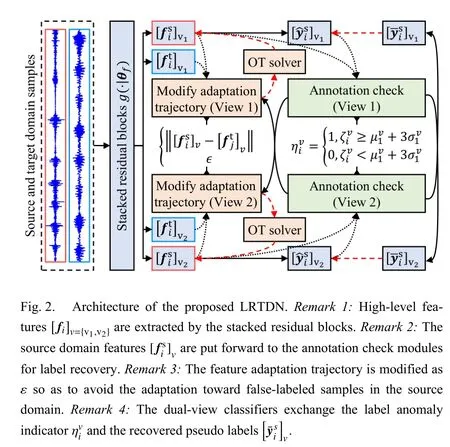
A. Dual-View Residual Network
Deep learning networks can learn high-level features from the source and target domain samples through the hierarchical model.Such a multiple layer-wise architecture is reported to be beneficial to distribution adaptation.In this article, a deep residual network is constructed for the cross-domain feature extraction as well as the recognition of machinery health states.As shown in Fig.2, the residual network consists of two kinds of layers.Multiple residual blocks are stacked to learn high-level features, and two perception networks are identically configured for health state recognition with different views.The architecture parameters are listed in Table I.It is noted that the parameters are shared for cross-domain samples.


B. Annotation Check Module
There are incorrectly annotated samples in the source domain.If the samples are directly used to train the dual-view network, the classification boundary will be overfitting on the incorrectly annotated samples.A solution to this problem is to search for the incorrectly annotated ones and then reconstruct their labels.To approach this goal, the dual-view network is first pre-trained by a very limited number of pure-labeled samples in the source domain, and the loss function is shown as follows:

The similarity of the gradient direction is calculated by
whereL(·,·) is the cross-entropy loss function.From (6) and(7), the label anomaly factor is constructed as

TABLE I ARCHITECTURE PARAMETERS OF THE DUAL-VIEW RESIDUAL NETWORK

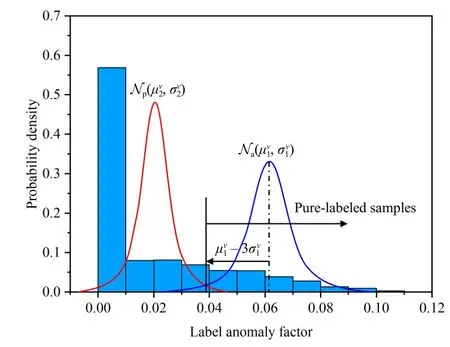
Fig.3.Explanation of label anomaly indicator based on GMM.
The constructed residual network is configured with two classifiers.Since the classifiers have different parameters and recognition abilities, they can filter diverse types of incorrectly annotated samples.To co-enhance the ability of such two classifiers, their judgments of incorrectly annotated samples are exchanged with each other [28].By such an exchange procedure, the one-hot labels of incorrectly annotated samples are modified as follows:

The above loss function consists of two terms.The first term is to minimize the entropy of source domain samples,which includes the cross-entropy loss of pure-labeled samples and the information entropy of false-labeled ones.The second term is to minimize the KL divergence of the predicted label distributions by the dual-view classifiers [35].This is expected to hold the diversity of classifiers.
C. Distribution Adaptation With Modified Trajectories
During the adaptation procedure, the distribution of target domain samples will be misaligned with that of the incorrectly annotated samples in the source domain.To solve the problem, it is necessary to implement adaptation selectively with the pure-labeled samples.Through the OT theory, we can design the trajectories of feature distribution adaptation across domains by the following steps.

Second step:Design the adaptation trajectories.According to (1), the distance of cross-domain samples describes the cost of converting distributions.The smaller the distance of crossdomain samples is, the less the cost of the distribution adaptation will be.Thus, the OT theory tends to select the trajectories that bring small costs in the distribution adaptation [32].Through this basic rule, we can modify the adaptation trajectories of cross-domain samples.To be specific in Fig.4, the distance between the target domain samples and the incorrectly annotated samples is increased to be more than the distance associated with pure-labeled samples.Thus, the cost of adaptation is enhanced along the trajectories toward the label anomaly samples in the source domain.As a result, the adaptation could avoid the distribution alignment of target domain samples on incorrectly annotated samples.For the view, the modified adaptation trajectories between theith source domain sample and thejth target domain sample are designed by
where ε is the constant to control the cost of adaptation across domains, and ε →+∞ if theith source domain sample is incorrectly annotated.Since (2) maps the features into a normalized hypersphere, ε is set as 10 in this article.
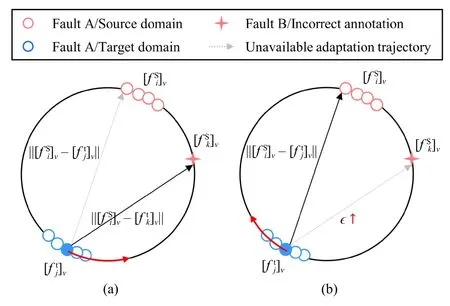
Fig.4.The explanation of distribution adaptation trajectories with respect to Incorrect annotation: (a) Before the adaptation trajectory modification;(b) After the adaptation trajectory modification.
Third step: Calculate the OT divergence of cross-domain features.The OT theory is to search for the optimal policy that minimizes the cost to thoroughly convert the distributions across domains.The optimal policy can be solved by
whereviandujare respectively the probability masses of theith source domain sample and thejth target domain sample.It is assumed to be sampling with equal probability, and thus for∀i∈{1,2,...,n˜s},j∈{1,2,...,nt}, one initializesvi=1/n˜sanduj=1/nt.Equation (14) can be solved by the Sinkhorn algorithm [36].From (1), the OT divergence is calculated by
D. Training Process
According to (5), (11) and (15), the proposed LRTDN is trained through the following two steps.
In the first step, the dual-view residual network is trained by using a very limited number of pure-labeled samples in the source domain.The optimization objective is shown as
where θ represents the training parameters of the dual-view residual network.In the second step, the network is trained by
where λ is a tradeoff parameter to balance the semi-supervised learning and the distribution adaptation across domains.At the training from scratch, the incorrectly annotated samples are not searched from the dataset.The indicator shown in(9) is inaccurate in modif[ying trajecto]ries.Therefore, λ is changed by following 2u/1+exp(-κt)-u, whereinuis the upper bound, κ controls the changing rate, andt=1,2,...is the increasing iterations [37].Equations (16) and (17) are interactively trained via Adam algorithms, and the parameters are updated by
where η1and η2are the learning rates.The training process is detailed in Algorithm 1.
从数学表达式上看,珠子总数和珠垫面积之间的关系似乎很复杂,但是从绘制的函数图像(见图9)中可以看出,函数关系近似表现为简单的线性关系,随着珠垫面积的增加,珠子总数量是呈直线增长的.
V.CASE STUDIES
A. Case I: Transfer Fault Diagnosis of New-Energy Vehicle Bearings Across Different Working Conditions
1)Dataset Description
The proposed method is demonstrated on the data collected from the power assembly bearing test rig of new-energy vehicles.As shown in Fig.5, the test rig includes the driving motor, the supporting bearings, and the testing bearings with the designation of 6208.There are five health states in the testing bearings, and they are the normal condition (N), the inner race pitting fault (IF), the outer race pitting fault (OF),the roller pitting fault (RF), and the cage crack fault (CF).Considering the varying working conditions of new-energy vehicle bearings, we change the driving motor speed as 4000 r/min, 5000 r/min, 6000 r/min, 7000 r/min, and 8000 r/min,respectively.A hydraulic system produces a radial load of 5 kN and an axial load of 0.9 kN on the testing bearings.The accelerator is mounted on the house of the testing fixture, and the sampling frequency is 25.6 kHz.A total of 2500 samples are collected under each motor speed setting, and the samples are balanced to be distributed in every health state.Each sample consists of 1200 sampling points.

Algorithm 1 The Training Process of LRTDN Xs Input: A small number of pure-labeled samples , labeled source domain samples with partially incorrect annotation, unlabeled target domain samples.˜Xs Xt Xt θ∗Output: Predicted labels of and the well-trained model.Initialize the parameters.t=1,2,...,T θ For epoch do Xs/*Pre-train the network by using pure-labeled samples */m Xs 1: Draw mini-batch samples from randomly.gθ ←∇θLpsc 2: Calculate the gradient.3: Update.t>ξ θ ←θ-η1·Adam(θ,gθ)4: If do/*Adapt cross-domain feature distributions*/5: Calculate the label anomaly factors by (8).6: Fit a GMM model to obtain indicators shown in (9).n ˜Xs Xt 7: Draw mini-batch samples from and randomly.8: Reconstruct labels for source domain samples in a batch through(10), and calculate loss by (11).9: Design the adaptation trajectories by (13), and obtain the OT divergence of domain-pair samples in a batch by (15).gθ ←∇θ[Ls+λLda]Ls 10: Calculate the gradient.θ ←θ-η2·Adam(θ,gθ)11: Update.12.End If End θ∗ Xt Return the fine-trained parameters and the predicted labels of through (4).

Fig.5.Test rig of power assembly bearings of new-energy vehicles.
The proposed method is verified on the transfer diagnosis tasks across different motor speeds.The symbol Ts-tis used to represent a certain task.For example, T4-5indicates that the transfer is conducted from the motor speed of 4000 r/min to the speed of 5000 r/min.To verify the proposed method on incorrect annotations, part of the source domain samples are incorrectly annotated by following a label transition function in Table II.In this article, τ is set as 30% to simulate incorrect annotation scenarios in the source domain.
2) Ablation Settings
The proposed LRTDN is compared with four ablation versions to verify the submodules.Version 1 only trains the dualview ResNet with the incorrectly annotated samples in the source domain, and then tests the model performance on the target.Version 2 removes the modules of annotation check and trajectory modification when compared with the proposed method (Version 5).Version 3 has the capability of label checking and correcting but has no access to distributionadaptation.Version 4 cannot relabel the incorrect annotation samples in the source domain, and only modifies adaptation trajectories during the OT-based adaptation.All the ablation versions of the proposed method are verified on tasks T4-5and T5-4.The results of ten repeat trials are recorded in Table III.In every trial, we randomly select only one sample in each health state in the source domain as the pure-labeled ones to help distinguish other incorrectly labeled samples.Moreover,25% of the unlabeled samples in the target domain are randomly selected to train the models, and the rest are left to test the generalization performance of the models.

TABLE II LABEL TRANSITION FUNCTION IN CASE I
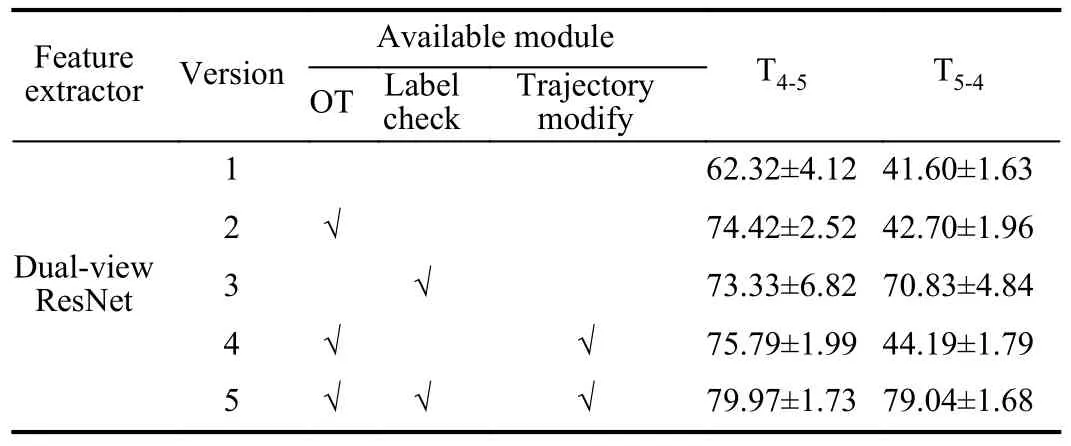
TABLE III DIAGNOSIS ACCURACY (%) OF TARGET DOMAIN SAMPLES WITH ABLATION SETTINGS ON TASKS T4-5 AND T5-4 [MEAN ± STANDARD DEVIATION]
From the results shown in Table III, Version 1 has the lowest accuracy on the given two tasks.Version 2 obtains higher accuracy than Version 1 with the help of OT-based distribution adaptation.However, due to the negative effects of the incorrect annotation in the source domain, it obtains lower accuracy than the proposed method, especially on task T5-4.Version 3 greatly improves the accuracy on task T5-4when compared with Versions 1 and 2, which explains the effectiveness of the constructed annotation check module.The comparison between Versions 2 and 4 indicates that the modified trajectory in distribution adaptation improves the transfer performance.In the given tasks, however, the incorrect annotation greatly affects the decision boundary of the diagnosis model.Maybe this is the reason why Version 3 obtains better results than Version 4 on task T5-4.Among all the ablation settings,the proposed method (Version 5) has the best results (the mean accuracies of 79.97% and 79.04% respectively on tasks), and thus it is valid and effective.
To explain the effectiveness of the proposed method, Fig.6 plots the diagnosis accuracies of the source and target domain samples with the training epoch.According to Fig.6(a), the accuracy of source domain samples approaches 100% in the training process of Version 1.Due to the incorrect annotation in the source domain, it is inferred that the decision boundary of the diagnosis model is overfitting on the false-labeled samples.By this, the diagnosis accuracy of the target domain samples reaches 66.9%.In Fig.6(b), the proposed method could check and relabel the source domain samples.Thus, the accuracy of the source domain approaches 70% because the overfitting problem on the false-labeled samples is relieved in the source domain.As a result, the diagnosis accuracy of target domain samples reaches 79.8%.
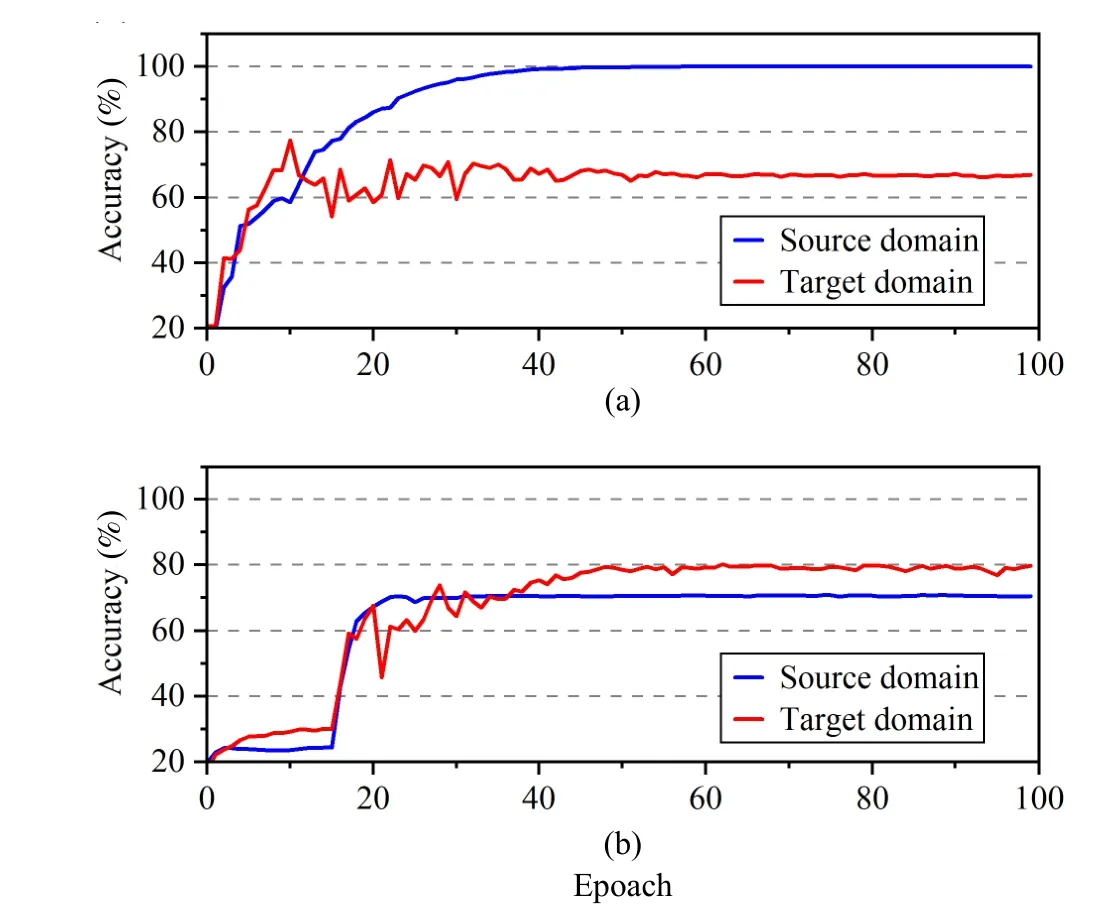
Fig.6.Comparisons of diagnosis accuracies with the training epoch for the task T4-5: (a) Version 1; (b) Version 5.
The sample labels in the source domain are compared when using the diagnosis models in Versions 1 and 5.In Fig.7(a),the labels of source domain samples are incorrectly annotated by the label transition function with τ=30%.The proposed method could relabel the source domain samples, and the results are shown in Fig.7(b).Most of the source domain samples are correctly relabeled.Only the samples from IF and OF are difficult to be addressed, which is related to the similarity between samples from these two health states.Therefore, the proposed method obtains lower diagnosis accuracy in these two states.
The performance of the proposed method is compared with those of other methods, including the intelligent diagnosis without domain adaptation: the standard ResNet; the UDA methods: DDC [19], DANN [21], DeepOT [22], and DeepJDOT [23]; the semi-supervised domain adaptation (SDA)method: the deep targeted transfer learning (DTTL) [16]; the UDA against incorrect annotation: TCL [30], CoUDA [29],and NUDA [31].The methods are respectively demonstrated on 20 tasks, which are created by the inter-combination of datasets drawn from different motor speeds.For fair comparisons, each method is constructed under the same backbone of domain-shared ResNet, and the architecture parameter settings follow Table I.In every task, we randomly select 25% of unlabeled target domain samples to help train the diagnosis models together with the source domain samples, and the rest are used for diagnosis performance testing.Note that DTTL is available when the target domain has one-shot labeled samples as the anchors.Therefore, we randomly select one sample from each class, and their labels are available during the model training.All the comparison methods are conducted by ten repeat trials for each task.The statistical results of diagnosis accuracy on the target domain samples are recorded in Table IV.
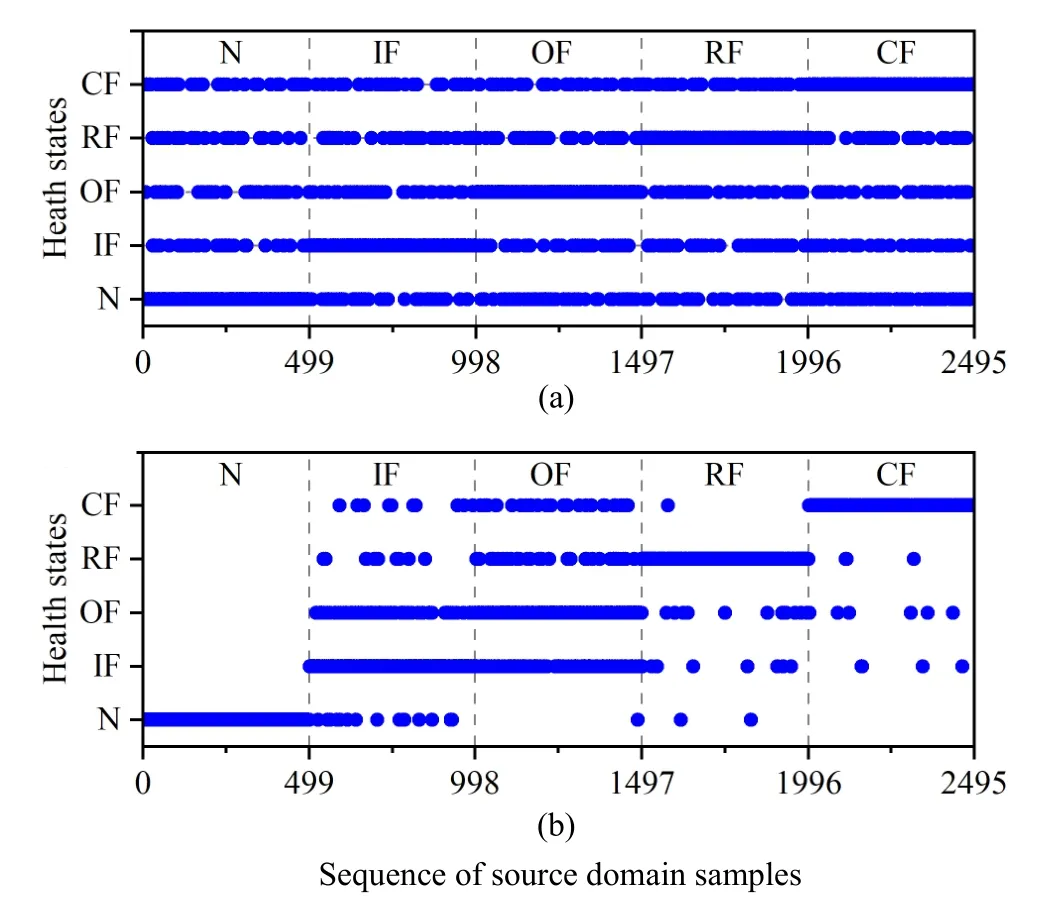
Fig.7.Comparisons of sample labels in the source domain during the training process for the task T4-5: (a) Version 1; (b) Version 5.
The standard ResNet removes the dual-view classifiers in the proposed method, and it obtains an average accuracy of 49.57%, which is greatly lower than the proposed method.On the other hand, this is compared with the results shown in Version 1 in Table III.The lower accuracy of the standard ResNet on tasks T4-5and T5-4further verifies the effectiveness of the dual-view classifiers used in the proposed method.DDC reduces the distribution discrepancy of cross-domain features by using the MMD, but it ignores the negative effects of falselabeled samples in the source domain.This method obtains an average accuracy of 52.21% on the given diagnosis tasks.DANN applies GAN to achieve the transfer fault diagnosis.Although the feature distribution is adapted by adversarial training, the incorrect annotation in the source domain reduces the performance of the source domain model on the target domain.Thus, some similar results (55.10%) to DDC could be found.DeepOT reduces marginal distribution discrepancy of cross-domain samples via the OT divergence.Since it cannot adapt feature distributions along the designed adaptation trajectories, some target domain samples are misaligned with incorrectly annotated samples in the source domain.It obtains an average accuracy of 58.69% on the given tasks, which is higher than DDC and DANN.This explains its superiority in the transfer diagnosis tasks to conventional adaptation theories.DeepJDOT reduces the joint distribution discrepancy of cross-domain samples with the help of pseudo-label-basedmethod.Thus, it obtains better results than DeepOT on certain tasks, such as T4-5and T5-6.Affected by the false-labeled samples in the source domain, the classification boundary is overfitting so that the generated pseudo labels are false to guide the adaptation towards forked directions.Maybe this is the reason why DeepJDOT gets a lower average accuracy than DeepOT.DTTL uses a very limited number of labeled samples in the target domain to guide the distribution adaptation,achieving higher diagnosis accuracy (61.56%) on given tasks than other UDA methods.However, it also has no capability to handle incorrect annotation problems in the source domain.The designed adaptation trajectories do not avoid the directions towards false-labeled samples in the source domain, and thus make partial target domain samples misaligned.Meanwhile, the overfitting model to be transferred for the target domain further reduces the diagnosis performance.As for the UDA against incorrect annotation, TCL uses the discriminator loss to reweight the training of GAN-based transfer diagnosis models.The model overfitting and distribution misalignment problems that are drawn from the false-labeled source domain samples could be alleviated, obtaining the improved accuracy of 69.36%.Due to the manual settings of the judgment threshold, the quality of source domain sample selection is lower than the proposed method.In CoUDA, the noise adaptation layer is added to relieve the model overfitting on false-labeled samples in the source domain.However, it is difficult to train a reliable label transmit matrix from the truth to the false, which removes the benefit of the noise adaptation layer on certain tasks, such as T6-4and T8-4.NUDA optimizes two independently-configured classifiers, in which the source domain samples with lower loss are selected to train the net.There are similar problems to TCL.Moreover, this method ignores the distribution of false-labeled source domain samples during the training process.The proposed LRTND could check and further relabel the source domain samples so that the false-labeled ones are also available to train the decision boundary of diagnosis models.Moreover, LRTND modifies the adaptation trajectories of cross-domain features compared with other OT-based transfer diagnosis methods.Therefore, it achieves an average accuracy of 79.9%, which is the best one among all the methods.
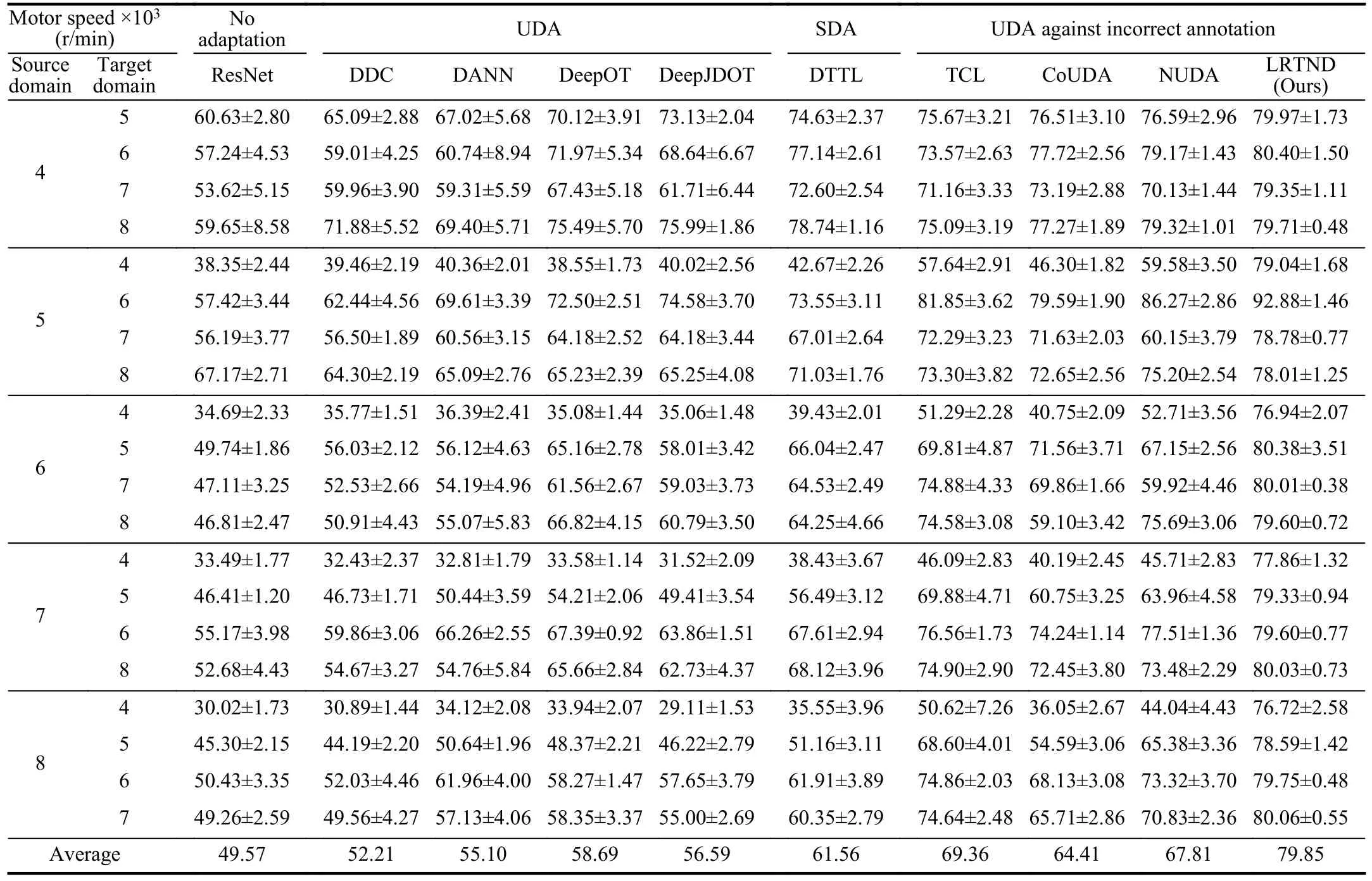
TABLE IV DIAGNOSIS ACCURACY (%) OF TARGET DOMAIN DATASETS BY USING DIFFERENT METHODS [MEAN ± STANDARD DEVIATION]
4) Discussion: Number of Pure-Labeled Samples
From (6) and (7), the pure-labeled samples in the source domain are used to search for other incorrectly annotated ones.In previous subsections, we are mainly concerned with an extremely worse condition, in which only one source domain sample in each health state is pure-labeled.To discuss the effects of the number of pure-labeled samples, we take the transfer diagnosis task T4-5for example, and gradually increase the number of pure-labeled source domain samples by 25.For each setting of the pure-labeled samples, the proposed method is conducted for ten repeat trials, and the results of the incorrect label ratio and the diagnosis accuracy of the target domain are shown in Fig.8.
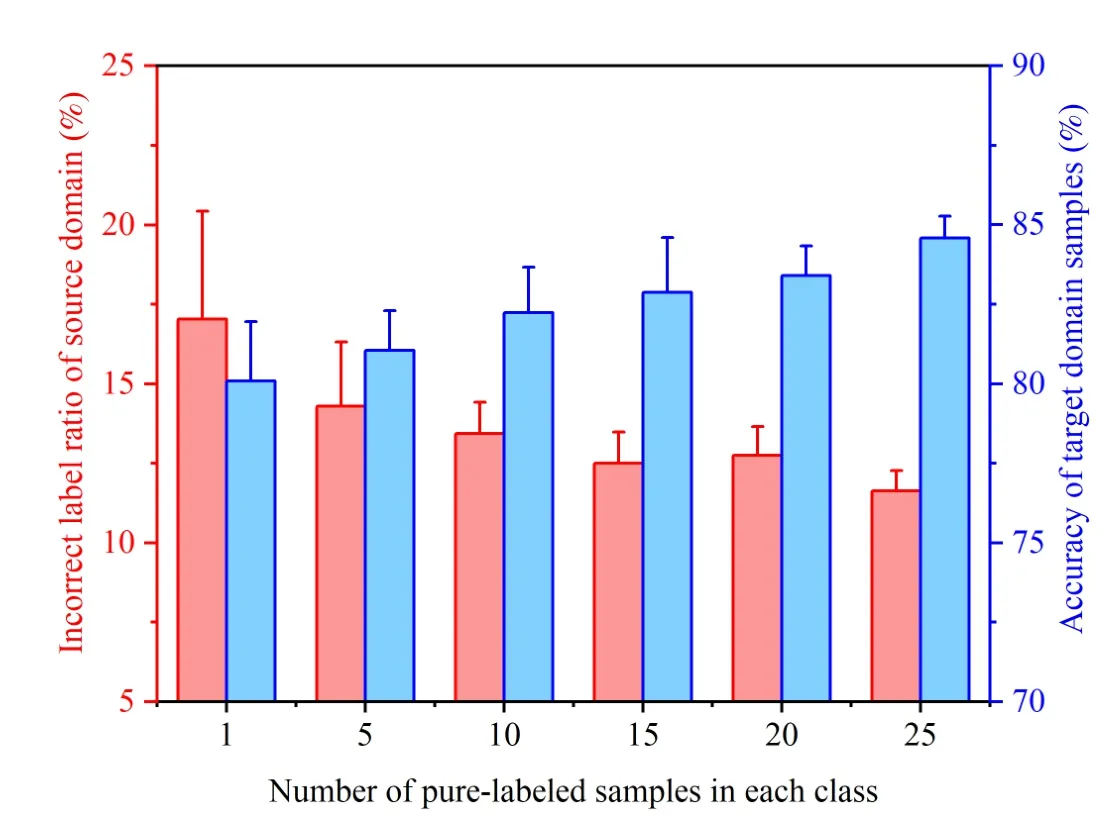
Fig.8.The incorrect label ratio of the source domain and the diagnosis accuracy of target domain samples for task T4-5 with respect to different numbers of pure-labeled samples in each class.
The incorrect label ratio of source domain samples drops off with the increase of pure-labeled samples in the source domain.Meanwhile, the diagnosis accuracy of target domain samples is increased from 79.97% to 84.59%.However, the source domain always holds about 10% of false-labeled samples, which are mostly drawn from the IF and OF states.This clue can be found in Fig.7(b), as the proposed method produces low recognition performance on IF and OF samples.Therefore, the proposed method loses the benefit if incorrectly annotated samples in the source domain are not well distinguished.The network constructed with expert knowledge may enhance the separability of different state samples.We will further attempt to enhance the represented feature enhancement method by embedding expert knowledge in future works.
B. Case II: Transfer Fault Diagnosis Across Different Machineused Bearings
1)Dataset Description
The proposed LRTND is further demonstrated on transfer fault diagnosis tasks across different machine-used bearings.The given two bearing datasets are detailed in Table V.
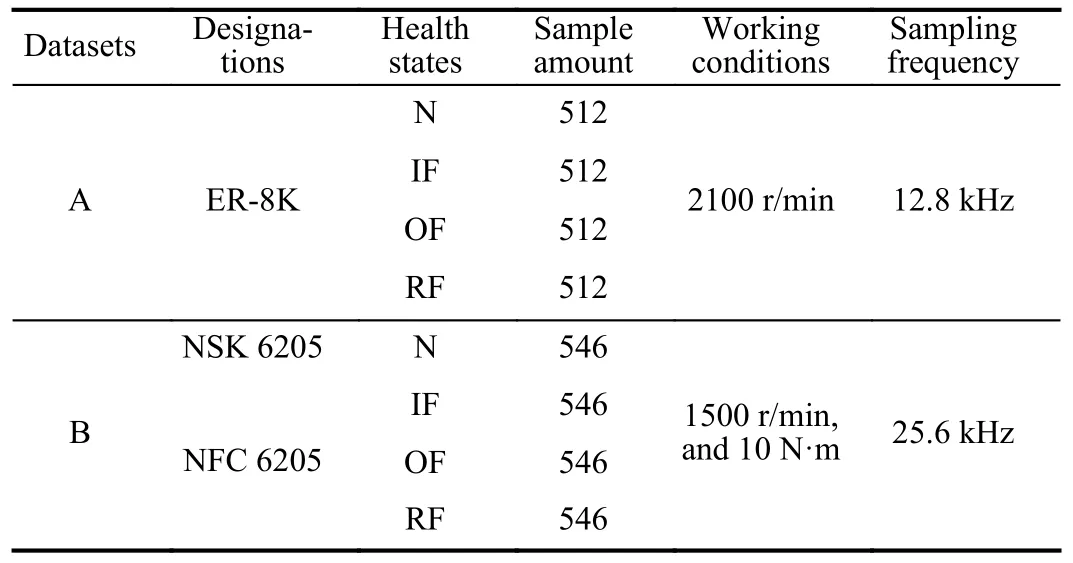
TABLE V DIFFERENT MACHINE-USED BEARING DATASETS

Fig.9.Picture of the rotor-bearing testing rig.
The dataset A is collected from a rotor-bearing testing rig that is shown in Fig.9 [38].The tested bearings (ER-8K)include four kinds of health states, i.e., N, IF, OF, and RF.During the testing, the bearings are respectively installed into the left end of the rotor.The motor speed is set as 2100 r/min.An accelerometer is mounted on the bearing house to collect vibration data under different health states, and the sampling frequency is 12.8 kHz.A total of 2048 samples are collected,which are balanced from every health state.
The dataset B is collected from a motor-driven-end bearing testing rig, as shown in Fig.10 [38].The tested bearings contain four kinds of health states.The designation of the normal one is NSK 6205.The experimenters make faults respectively on the inner race, the outer race, and the rollers of bearings NFC 6205.During the testing, the motor speed is set as 1500 r/min, and the magnetic eddy brake produces a torque of 10 N·m.The accelerometer on the motor house returns the vibration data from different bearing states at the sampling frequency of 25.6 kHz.There are 546 samples for every health state, and each sample contains 1200 sampling points.
According to Table V, we create two transfer diagnosis tasks A →B and B →A, where part of source domain samples are randomly mislabeled by following a label transmit matrix shown in Table VI.In this case study, a serious ratio of incorrectly annotated samples, i.e., τ=30%, is concerned for the source domain.The proposed LRTND is expected to transfer diagnosis knowledge across different machines in the presence of incorrect annotation in the source domain.
2) Label Recovery and Diagnosis Results
Fig.11 presents the label recovery result of the proposed LRTND for task A →B.Before the label recovery, 30% ofthe source domain samples are assumed to be mislabeled.The proposed method could check them by the similarity and the moving gradient with other pure-labeled samples, and finally generate the reconstructed labels.From the result in Fig.11(b),the quality of generated labels is greatly improved.
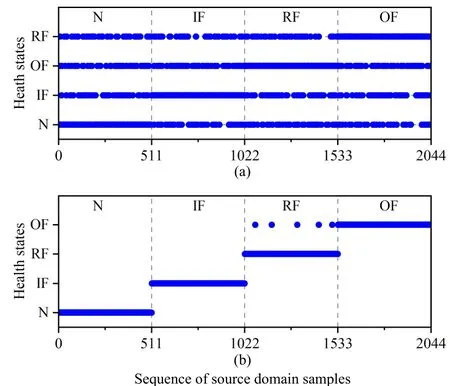
Fig.11.The source domain sample labels in the task A →B: (a) Before label recovery; (b) After label recovery.
We further compare the diagnosis performance of LRTND with other methods that are used in Case I.In every method,ten repeat trials are conducted respectively on tasksA →B and B →A.The statistical results are recorded in Fig.12.Among the given methods, the proposed LRTND obtains over 95% accuracy on the two tasks, which is the highest one.Due to the effects of domain discrepancy and the false-labeled samples, the standard ResNet has the lowest accuracy of about 30%.The UDA methods including DDC, DANN, DeepOT,and DeepJDOT could reduce the domain discrepancy, improving the transfer diagnosis accuracy.The SDA method-DTTLobtains higher results than UDA method with the help of oneshot labeled samples in the target domain.It even performs better than UDA against incorrect annotation on the given tasks.Since these methods have no capability to alleviate the negative effects from the false-labeled samples in the source domain, their performance are lower than that of the proposed method.For the overlapping and misalignment problems drawn from the incorrect annotation, methods like TCL,CoUDA, and NUDA design the transfer diagnosis models.However, their diagnosis accuracies are still lower than that of the proposed method due to the weak capability to check false-labeled samples and to adapt feature discrepancy.
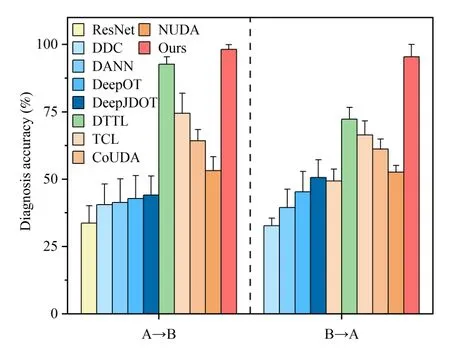
Fig.12.Comparisons of the diagnosis accuracy of target domain samples by using different methods.
3)Feature Visualization
To visually explain the effectiveness and superiority of the proposed method, we plot the learned features respectively through different UDA methods against incorrect annotation.The output cross-domain feature distribution of layer F2is directly associated with the final diagnosis accuracy because it is the highest one before classification, we take taskA →B for example.The feature dimension of cross-domain samples is reduced by the t-distributed stochastic neighbor embedding(t-SNE).After that, the source and target domain sample features are plotted on a plane, as shown in Fig.13.Note that the features of only one view or network are addressed if the methods have dual architectures.
As shown in Fig.13(a), the overfitting problem on falselabeled samples is relieved by TCL.However, the remaining discrepancy of the learned features hinders the high accuracy of transferring diagnosis model across domains, especially for the large difference in the RF samples.CoUDA adds the noise adaptation layer to avoid the effects of incorrect annotation on the feature distribution adaptation, but the lower capability to solve overfitting could be found in Fig.13(b) when compared with those of other methods.In NUDA, the source domain samples with the small loss are selected to train the diagnosis model, and thus Fig.13(c) presents an improvement to the overlapping on part of source domain samples.However, the remaining distribution discrepancy mainly reduces the transfer diagnosis accuracy.Compared with the existing works, the proposed LRTND presents a more powerful capability in the false-labeled sample checks, as shown in Fig.13(d).Moreover, the similarity of cross-domain features is obviously higher than those of other methods.The results visually verify the strong performance of LRTND in domain adaptation against incorrect annotation.This is the reason why the proposed LRTND obtains the highest accuracy in Fig.12.
VI.CONCLUSION

Fig.13.The learned features of target domain samples in Task A →B by using different adaptation methods against incorrect annotation.
This article presents LRTDN for the transfer fault diagnosis of machines when faced with incorrect label annotations.The method tackles this issue by constructing an annotation check module that is able to identify false-labeled samples in the source domain and correct their false labels.Additionally, the adaptation trajectories of cross-domain features are designed to be modified through OT theory.This adjustment can ensure that the features from the source domain align better with the target domain, improving the transfer diagnosis performance.The proposed LRTDN is validated by transfer diagnosis tasks in two scenarios, i.e., the transfer diagnosis of new-energy vehicle bearings under different working conditions as well as the transfer diagnosis across different machine-used bearings.The results obtained from these experiments demonstrate the superiority of LRTDN compared to other relevant methods.It successfully overcomes the challenges posed by overfitting and feature misalignment, which are prevalent when training with false-labeled source domain data.Consequently, LRTND achieves higher transfer diagnosis performance.
The article also emphasizes the importance of separability of different state samples for successful label reconstruction.We will continue future works to enhance the separability of represented features with the help of prior expert knowledge.
猜你喜欢
数学物理学报(2020年2期)2020-06-02
安顺学院学报(2020年1期)2020-04-05
小学科学(学生版)(2019年8期)2019-09-02
现代计算机(2019年6期)2019-04-08
江苏农村经济(2019年5期)2019-01-14
小学生导刊(2017年31期)2018-01-31
数学大王·低年级(2017年10期)2017-10-31
好孩子画报(2017年9期)2017-09-27
数学小灵通(1-2年级)(2017年3期)2017-04-16
读写算(上)(2015年6期)2015-11-07
 IEEE/CAA Journal of Automatica Sinica2024年4期
IEEE/CAA Journal of Automatica Sinica2024年4期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- When Does Sora Show:The Beginning of TAO to Imaginative Intelligence and Scenarios Engineering
- Goal-Oriented Control Systems (GOCS):From HOW to WHAT
- Digital CEOs in Digital Enterprises: Automating,Augmenting, and Parallel in Metaverse/CPSS/TAOs
- A Tutorial on Federated Learning from Theory to Practice: Foundations, Software Frameworks,Exemplary Use Cases, and Selected Trends
- Cybersecurity Landscape on Remote State Estimation: A Comprehensive Review
- Data-Based Filters for Non-Gaussian Dynamic Systems With Unknown Output Noise Covariance