
融合共现和语义信息的药对提取方法研究及应用*
2024-04-16 13:18胡孔法
世界科学技术-中医药现代化 2024年1期
唐 静,杨 涛,2,朱 垚,胡孔法,4**
(1.南京中医药大学人工智能与信息技术学院 南京 210023;2.江苏省中医药健康养生技术工程研究中心南京 210023;3.南京中医药大学第一临床医学院 南京 210023;4.江苏省中医药防治肿瘤协同创新中心南京 210023)
药对,又称对药、兄弟药、姊妹药,在临床上的构成搭配相对固定,是中药复方配伍中最简单、最基本和最常见的用药形式[1]。药对按照一定规则进行配对,例如除单药外的“六情”理论,在临床实践中,将疗效或性能相近的药物联合使用,通过相使、相须、相杀、相畏等配伍作用关系,使其达到一定的增效减毒等效用。药对,是单味中药到方剂应用的过渡环节,是方剂配伍规律研究的切入点,是中药复方所含规律性特征与辨证施治的内涵体现[2]。深入理解药对之间蕴含的配伍规律,对剖析方剂的构成以及明确方义大有裨益,例如通过研究探析“方书之祖”张仲景方药的对药组合,从而得出阴阳相配、寒热相配、气血相配、补泻相配、散敛相配等归类[3],掌握其使用药对的思想方法,从而进一步指导临床实践。不仅益于古方的挖掘应用,更为创新中药、创组新方奠定基础并提供理论支撑。随着现代医药学的发展,对于药对的研究越来越深入,例如“当归-黄芪”“三七-丹参”等[4],也在从证明“药对的有效性”转为“为何有效”“如何更有效”,可见药对所蕴含的价值举足轻重。
药对不是一成不变的,也不是每一首方剂都可使用一个药对[4]。药物的组配规律仍会有新的发现,如何利用现代技术快速筛选出潜在药对,如何对药对进行多角度、深层次的分析挖掘,为药对的提取提供方法支撑,是中医药传承与今后研发的重要研究课题之一。
目前,药对的研究已逐渐深入,除了在理论、临床、实验方面的研究,还有计算机方法的研究,例如数据挖掘技术主要针对于中医症状间、用药间的规律[5]。在方剂学中主要使用的方法有关联规则法[6](如Apriori、Fp-growth、Eclat 等)、聚类分析、分类算法等,利用文献和数据库数据,例如《伤寒论》、临床门诊数据等,挖掘潜在的药对或药物组合,在病-证-症-方-药、复方配伍规律、类方等研究中有着广泛前景。刘娟等[7]运用关联规则的方法将源自《中医大辞典》中的1046首脾胃方,从数据关联层面证实了例如“白术-茯苓”等已知药对的常用性,并发现了未知药对“陈皮-山楂”等,为探索临床研究发展之路提供思路。曾珉等[8]、甘德成等[9]、姜平等[10]、张伟健等[11]基于关联规则和聚类分析等算法对核心药物组合与组方规律进行分析,获得新的关键组方思路,从而探寻疾病治疗的用药规律;姚鉴玲等[12]提出一种融合组合赋权、聚类、决策、评价等算法用于配方设计及评价;Wang 等[13]通过利用SVM 对方剂效果进行了分类预测,从而证实“君臣佐使”的方剂结构与药物间的关联;又或是基于中医药类传承平台对药对进行提取[14]等。
目前研究者对中药配伍规律挖掘方法的选择上具有局限,研究模式相似,多利用关联规则算法进行核心用药的挖掘,或是对高频药物进行聚类分析其类别功效等。然而,关联规则分析结果存在大量冗余规则,聚类算法未能全面考虑药物重要特性对方剂的影响,分类算法对于归纳方剂蕴含知识存在不适用问题[15]等。考虑到方剂数据所蕴含的不单是统计规律,更应结合文本语义特征进行分析,例如方剂中各药物间的排序、文本语义间的关系。
语义信息,也称意义信息,在维基百科中,语义信息是指有意义的数据提供的信息,关注的是词、短语、符号等之间的关系;在自然语言处理中,即上下文信息,也就是指一个词与其周围词之间的关联。对语义信息的计算,即解释自然语言句子各部分(词、词组、句子、段落、篇章)的含义。处方数据并非属于严格的语义范畴,有着索引、语调、情态(《语言学纲要》);处方数据由索引(药物)构成,通过研究词与词之间的关系,研究文本的语义信息,即中药处方中每味药物之间的关系。语义具有领域性特征,不属于任何领域的语义是不存在的[16],已经学习到人类语言含义的系统可以做一些诸如回答有关世界事物的问题,即通过学习一些将意义反映到语言形式中的知识,可以使系统具有解答相关领域问题的能力[17]。中药方剂文本是名老中医将经验以语言文本形式反映的知识,有着巨大的价值,也存在着相关领域的语义特征。如果忽视对方剂内部语义或词序信息的考量,会错失一些重要信息。丁侃[16]在梳理归纳中医古籍知识时考虑到语义异构,运用中医语义元数据描述知识单元内容特征,同时,语义也具有表达性。通过引入语义维度,可以在语义空间上表示药物词语,方便计算机处理,除此以外还可以为后续研究提供便利,例如:对词语维度进行降维,在一定程度上可以减少噪音、方便可视化观察词语间的关系等。目前在图像的识别与多目标跟踪、自然语言处理的命名实体识别等有着较为广阔地应用,例如衡红军等[18]对文本进行编码标记,通过语义特征与句法特征等对语句关系的客体位置做出预测标记,从而完成了三元组的提取。
鉴于此,本文提出一种在词频分析的基础上,从语义角度对潜在药对做进一步筛选的算法。引入语义维度,将处方中每味药物作为一个词,使用自然语言处理过程中的词嵌入技术,能够将药物词文本映射到语义向量空间,用向量的形式表示药物词汇,向量中也包含词与词之间的关系,用以研究文本的语义信息,即中药处方中每味药物之间的关系。以条件概率作为筛选药对的依据之一,同时结合方剂中药物间的语义信息,以语义相似度为另一评价指标,对潜在候选药对进一步筛选提供依据。
1 融合共现和语义信息的药对提取算法
1.1 相关定义
1.1.1 向量内积
向量的内积,也被称为向量的数量积,或点乘。对两个向量做点乘运算,即对两向量的对应位先相乘后求和。利用点积可计算对应余弦值,点积及余弦值一般可用于相似性度量。一般训练时使用内积作为相似度可以保留词的频率信息。对于n维向量的内积定义如下:
1.1.2 共现概率比
共现是指单词i 与单词j 在一定范围内共同出现的次数。共现概率是指单词j 出现在单词i 上下文的概率。共现概率比是指共现概率的比率[19],其定义如下:
式(2)中:ω ∈Rd表示d 维词向量,∈Rd表示单词i 与单词j 的上下文词向量;式(3)中:Pij为单词j 出现在单词i 上下文的概率。同时共现概率比的值是有一定规律的,且该规律可通过词向量呈现[19-20],对上述共现概率比进行向量差分与点积表示可得:
因此共现概率矩阵中所蕴含的信息可以通过词向量表示,即该值能够反应词向量之间的相关性见表1。
1.2 算法流程
扫描规范化的方剂数据集,每一行作为一条独立的处方数据文本输入,同时输入的还有最小出现频次counts、维度vector、阈值min1、min2,min1 主要采用条件概率的方法初步筛选药对,min2 主要是基于语义信息用于语义相关的药对提取。根据输入数据集统计任意两味药物共同出现的次数,没有则记为“0”,有则进行累加操作,以此构建协同共现矩阵来计算药物间的条件概率见图1a。因考虑到筛选药对的双向关联程度,故以药物双方各自为条件,将两条件概率采用乘法计算方式获取双向的关联信息,并以min1为界筛选出潜在候选药对。与此同时,构建基于窗口的词-上下文协同矩阵并与上述协同矩阵取共现交集,并构建字典、生成词向量,此时各药物可由数字化向量进行表示见图1b;以药物向量之间的内积计算其相似度并将结果进行排序,以min2为界筛选出候选药对并与前者筛选结果取交集,筛选出相同的药物组合作为潜在药对。算法核心步骤如下表2所示。
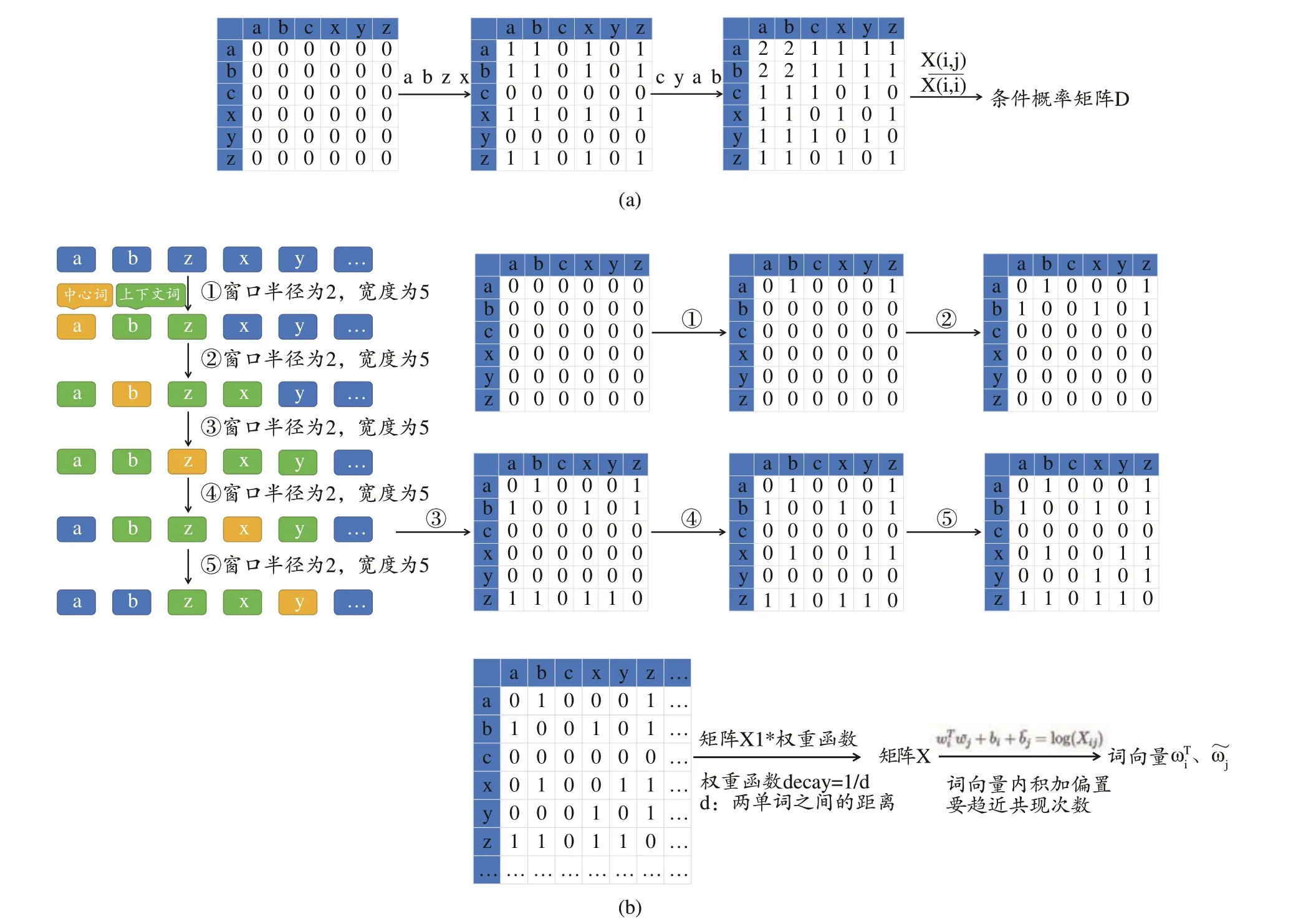
图1 算法示意图
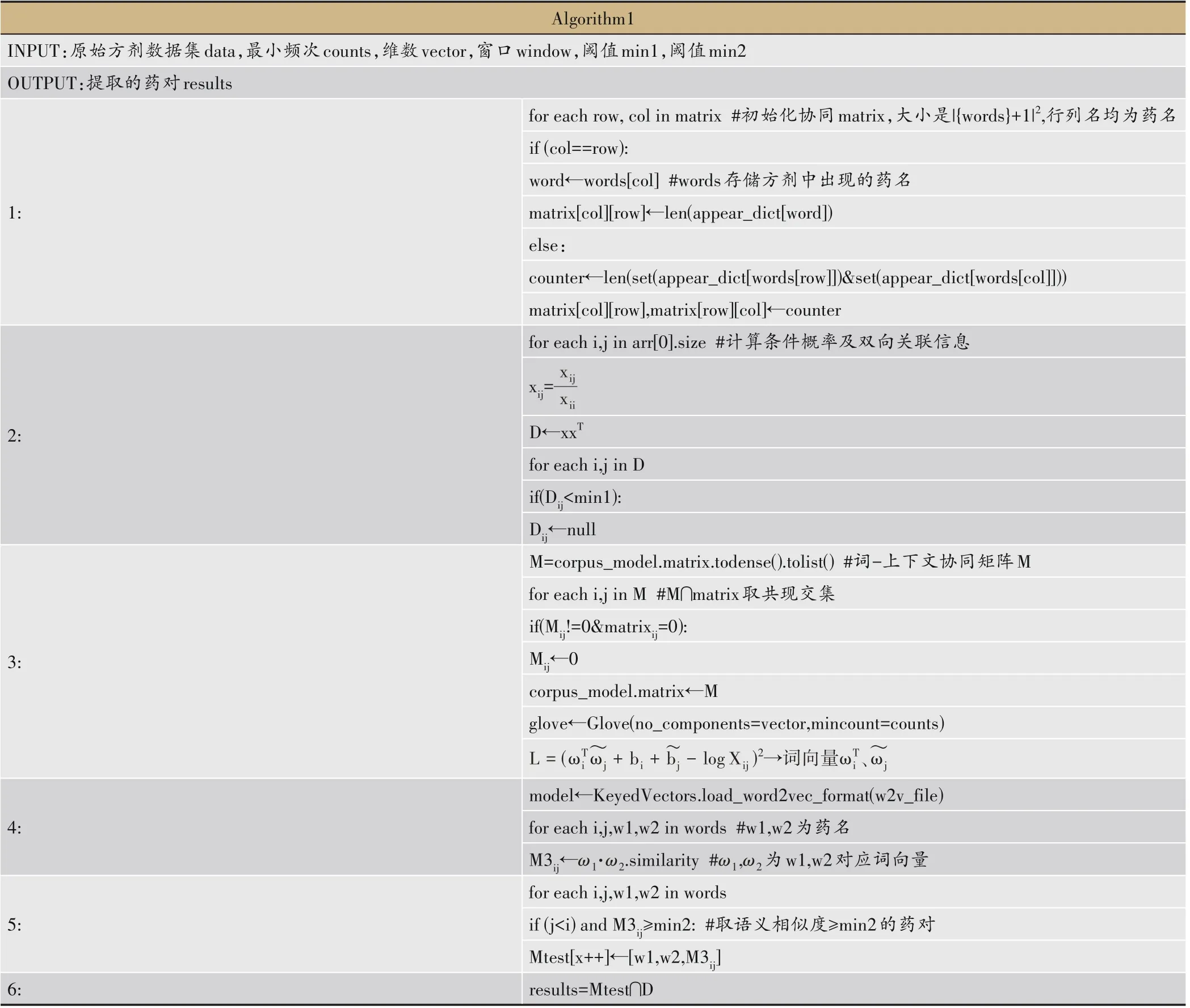
表2 算法核心步骤
2 实验及结果分析
2.1 数据来源及数据预处理
本文肺癌临床数据来源于由国医大师周仲瑛传承工作室提供的周仲瑛教授门诊诊治肺癌患者的处方用药数据。按照数据预处理步骤,参照《中华本草》《中国药典》等对处方数据中的中药名称进行规范化处理,例如:纠正错别字、统一药物名称等。经处理共得到1090条处方数据,371味中药,处理后的数据每一行作为一条处方记录,每条记录中不同药物以空格间隔。
2.2 实验设置
为了验证本文所提算法的有效性及实用性,将本算法提取结果与经典的数据挖掘算法Apriori 进行比较。
①按照2.2 中算法流程进行实验,构建共现矩阵计算任意两味药物间的条件概率,以此获得两者间的关联关系从而筛选出潜在候选药对;通过设置不同的配置参数,例如最小频次counts、维数vector 以及阈值参数min1、min2 观察不同参数下结果数量的变化,选择合适的参数筛选出潜在药对。②利用Apriori 算法提取潜在的药物关联规则,为保证实验的对照与均衡性原则,Apriori 算法的参数设置与①中提及的最小频次counts 有关,因此会依照counts 结果设置该算法的最小支持度。③最后结合中医理论总结上述发现的潜在药对并评价实验结果。
2.3 实验结果
2.3.1 融合共现和语义信息的药对提取算法实验结果
(1)设定阈值min1 自0.0 至1.0,步长0.1,并以min1 的阈值区间作为横坐标,初步筛选的药对数作为纵坐标,得到以阈值min1为指标的药对分布情况见图2a;考虑到语义信息提取药对时,各变量对结果的影响,诸如药物出现的最小频次数目、生成语义向量的维度大小等因素,本算法采用固定词向量方法计算药物向量(原始方法是通过在共现矩阵中随机采集一批非零词对作为训练数据进行初始化词向量,存有一定的随机性与不可复现性),以相似度≥90%,即min2=0.9 为例,以选取频次数目及维度大小尽可能小、且筛选结果趋于稳定为原则,以初步筛选药对数作为纵坐标,以药物语义维度作为横坐标,得到基于语义信息的药对数目变化情况见图2b。
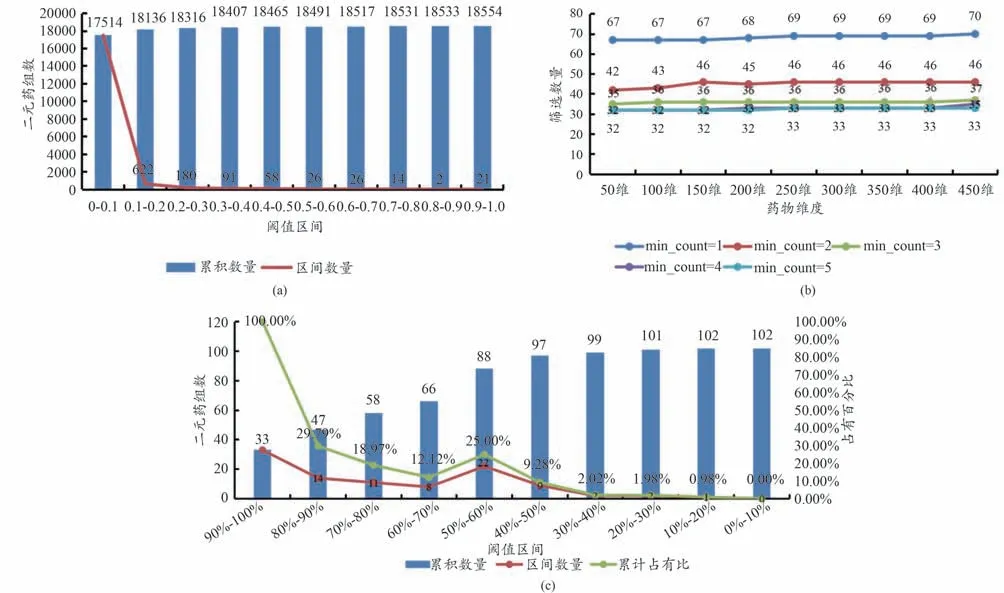
图2 实验阈值设置
从图2a可以看出:采用条件概率的方法初步筛选药对时,随着阈值区间的增大,对应的潜在候选药对数量急剧减小,在区间[0.4,0.5)间内所拥有的药对数达58对,且后续区间的曲率变化逐渐平缓,截至区间[0.4,1.0)拥有的药对数达到147对。从图2b可以看出:当最小频次为1、3、4时,在维度为450时初步筛选结果仍有波动;当最小频次为5时筛选的结果与最小频次为3和4时的结果在数量上差距不大,且从250维开始筛选结果也是趋于稳定的状态。由此将上述相结合进一步进行筛选,可以得到融合共现与语义信息的不同语义阈值区间上的药对分布情况见图2c;从图2c 可以看出:在语义相似度区间[50%,60%)内得到的结果占目前已出现结果的比例较高,截至区间[50%,100%)拥有的药对数达到88 对,以上述阈值区间分布作为横纵坐标轴,以区间内筛选药对的数量为竖轴,可以得到药对的分布情况见图3,图中节点大小表示为数量大小各截面代表含义如图示所示。图3 中从2 个不同视野观察药对分布区间并将药对出现位置投射至底面便于观察,从中可以看出以语义相似度50%为截面能够获得大部分结果药对,故从包含药对数量层面考虑,推荐使用语义相似度50%作为min2的参数。
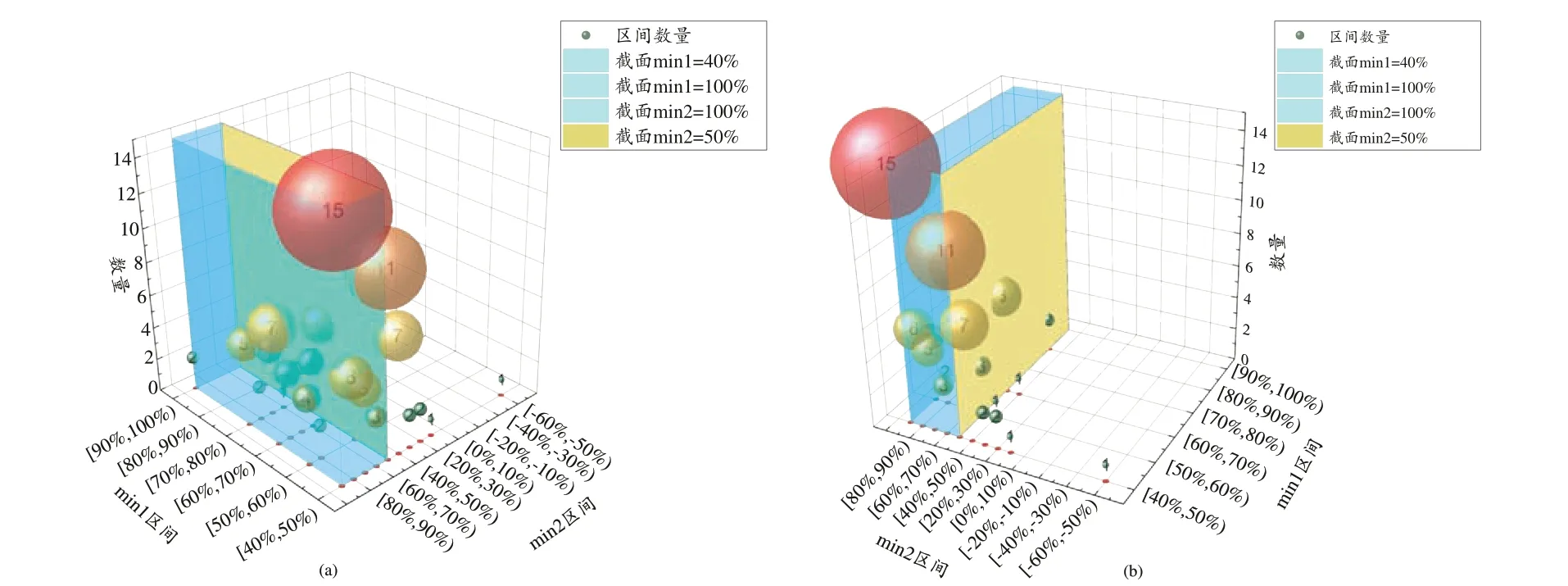
图3 药对分布
综上,通过设置配置参数最小频次counts=5、维数vector=250、阈值min1=0.4、min2=0.5,计算药物之间的相似度,并与前者候选药对结合评判,总结可以得到潜在药对结果共88对。
(2)按上述算法流程进行实验,筛选得出潜在药对,例如“北沙参-南沙参”“炒麦芽-炒谷芽”“焦神曲-焦山楂”等,前20项见表3。为了直观展示筛选结果绘制了药物网络图见图4a 及经PCA 降维后的3 维药物散点图见图5a,图中结点颜色由蓝至红表示药物的频次,频次越高越偏红,越低越偏蓝。
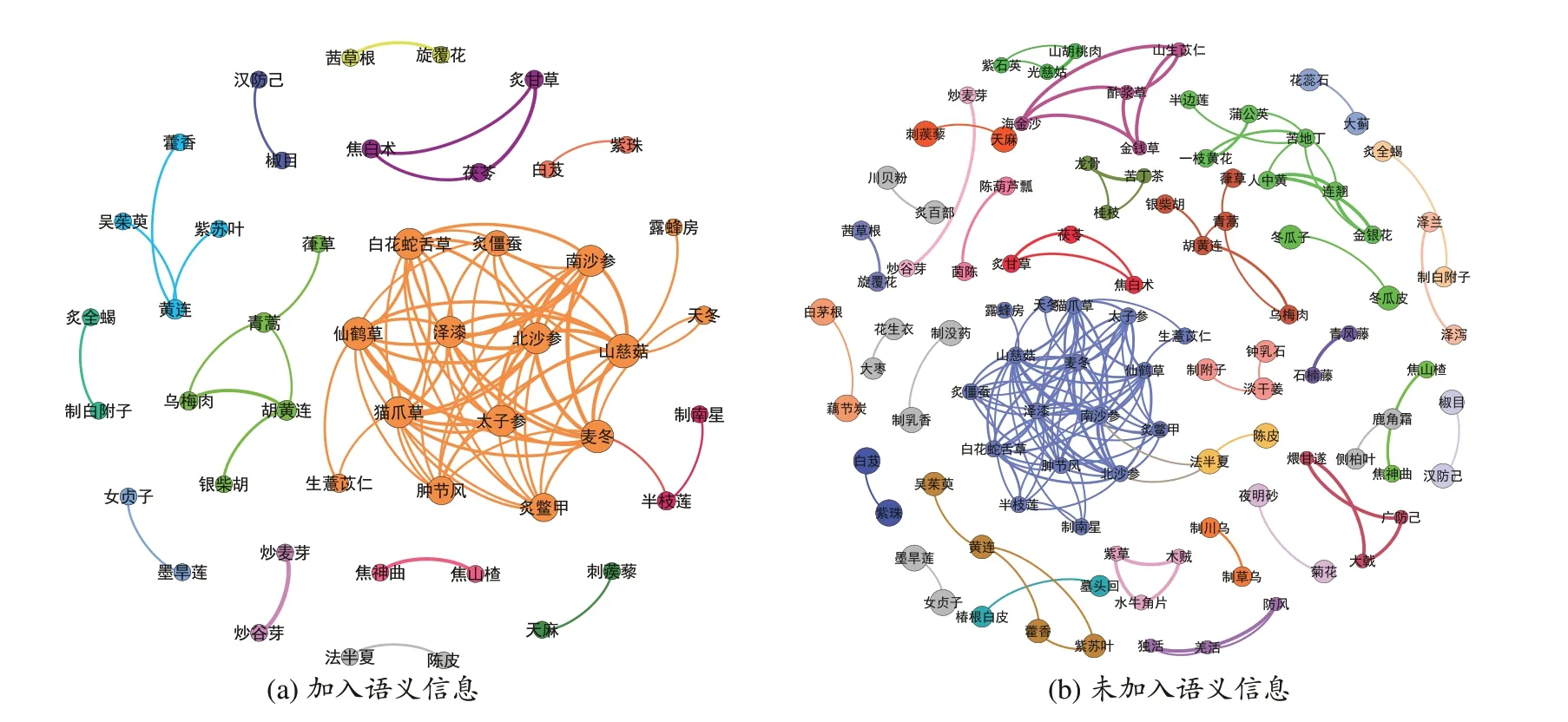
图4 药对网络图
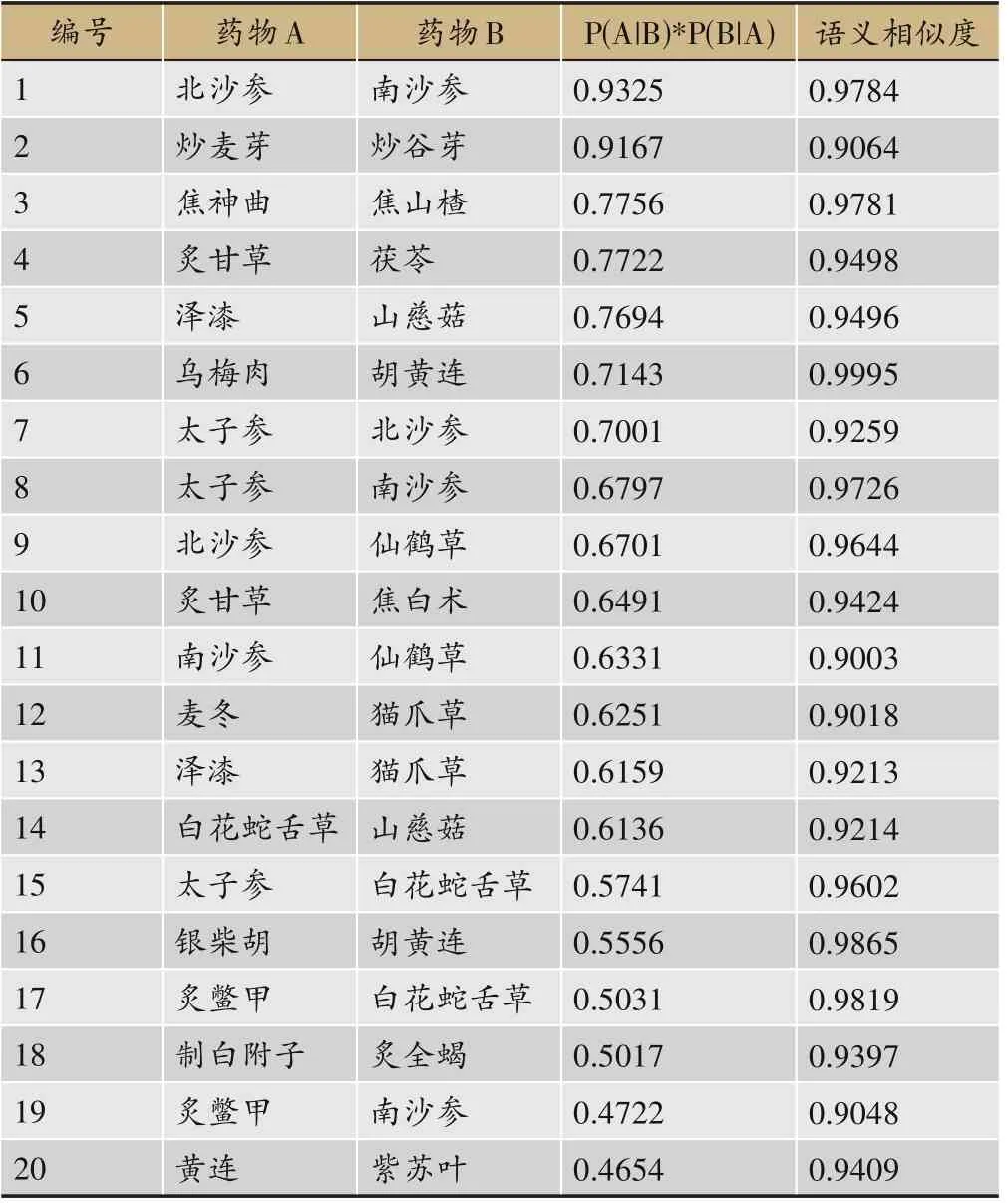
表3 潜在药对Top20(加入语义信息)
为了实验的完整性与直观比较进行消融实验。只考虑基于统计学习理论条件概率的方法进行实验,前20 项结果见表4,对应药物网络图见图4b,在考虑到药对相互之间的关联关系后筛选得到147对药对信息,提取的信息均为药对信息,但筛选数量仍较多,依旧需进一步人工筛选研究对象。同时以药物在各药方中出现的位置为维度信息,构建药物向量,同样经PCA降维后形成的散点图见图5b。
(3)为了实验的准确性,请国医大师周仲瑛传承工作室专家对最终药对筛选结果进行药对标引,根据标引结果,以阈值区间作为横坐标,以区间内“是药对”的比率作为竖轴,得到累计区间“是药对”比率见图6a。同时对结果标注,分布见图6b,标注原则为:“确实药对”,即按照周老同类相须理论与异类相使理论标引;“同方药组”,即参照异类相使关系;“共现药物”,即同类相须部分是周老按照现代药理研究划归同类的药物。从图6a 可以看出,在语义相似度区间[90%,100%)内得到“是药对”的结果准确性比例较高,随着语义相似度区间的扩大,有发现新的药对,但准确率逐步下降。故从准确率层面考虑,推荐使用语义相似度90%作为min2的参数,总结可以得到潜在药对结果共33对,其中是药对占有23对。
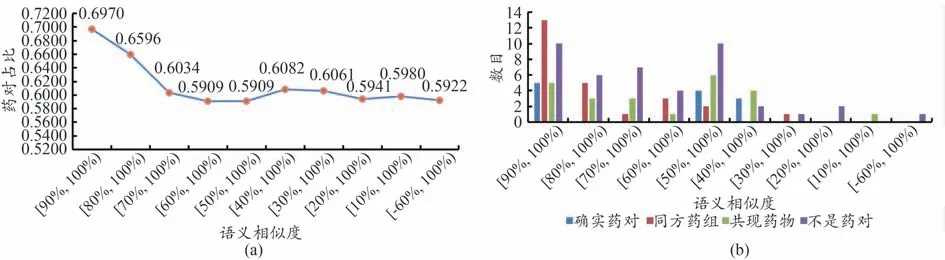
图6 药对结果
此外,从图6b 可以看出,“是药对”中“同方药组”在语义高阈值区间出现频次较多,此为方剂中的药对,例如四君子汤中的白术、茯苓、甘草等组合;“确实药对”“共现药物”在区间[90%,100%)也占有一定比率。例如由女贞子与墨旱莲组成的二至丸,黄连与吴茱萸构成的左金丸等均为“确实药对”;而“共现药对”是周老所使用的不同抗肿瘤药物,例如泽漆与山慈菇、太子参与南沙参、北沙参等,为后续进一步研究周老用药配伍规律可做参考。
2.3.2 Apriori算法实验结果
为保证本实验使用数据频次的一致性,设置最小支持度为0.0045,仅考虑“1-项集”,得到关联规则共12 766 条。设定置信度自0.0 至1.0,步长0.1,并以置信度的阈值区间作为横坐标,得到的关联规则数作为纵坐标,得到关联规则分布情况见图7;以支持度与置信度分布为第一第二顺序,位于前10 的关联规则见表5。由于关联规则存在由前项指向后项的方向关系,故绘制网络图时采用带有箭头指向的有向图见图8。
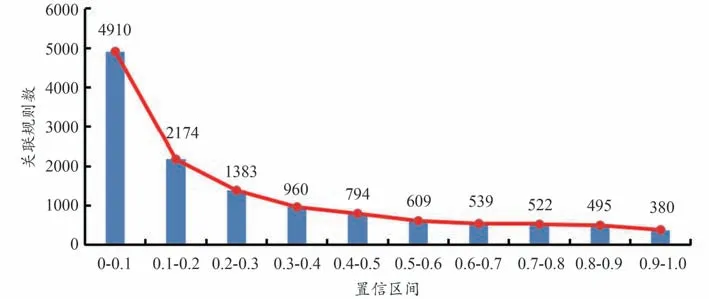
图7 关联规则分布情况
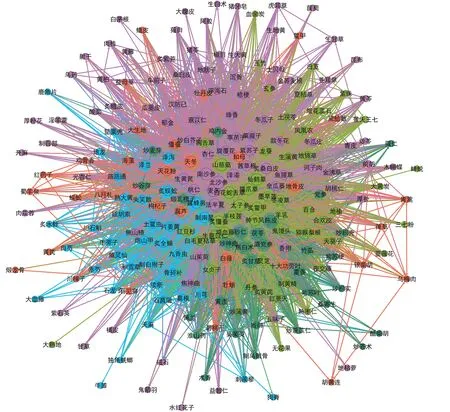
图8 Apriori药对网络图 (min Sup=0.045)
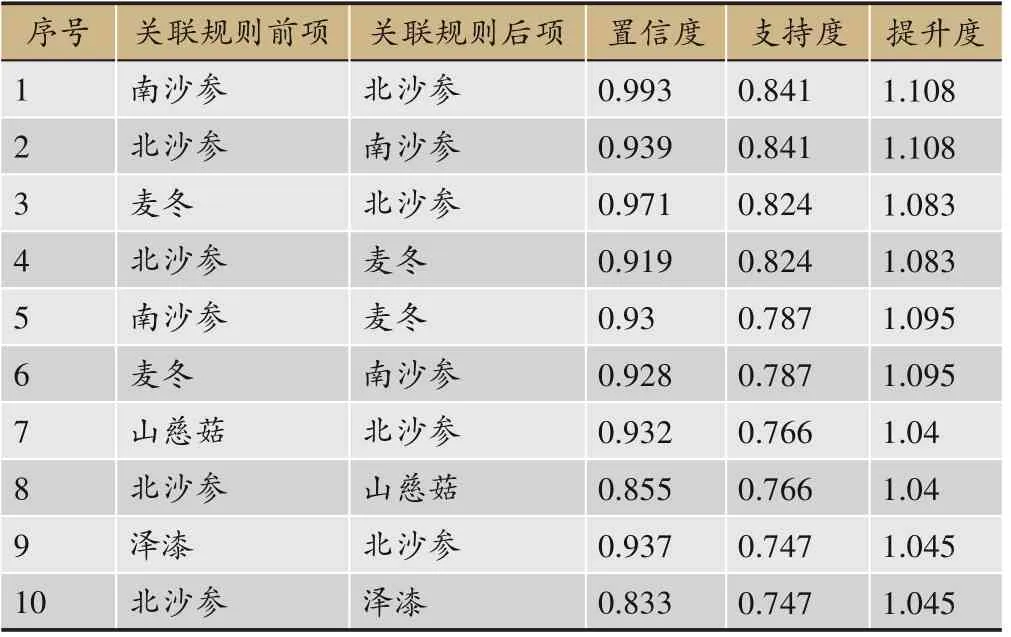
表5 Apriori算法关联规则药对提取结果(Top10)(min Sup=0.0045)
从图7 与图8 可以看出:在保障频次范围区间的同时,Apriori 算法所挖掘出的关联规则数量较多,若增设置信度的条件为(0.9,1.0]仍有380 条关系,若扩大置信度范围,所含关联规则数将成倍增长,且需要人工比对整理;对于大样本数据,整体网络复杂,不便于后续研究的观察与分析。
2.4 结果分析及讨论
从词频角度出发虽然考虑到了药物两两之间的双向关联关系,但面对全新的数据往往会筛选出大量的潜在候选药对(使用本文数据筛选出147对)。通过前20项结果与处方词频信息比对可知:若单从词频共现角度考虑,得出的结果容易受到小样本的影响,存在数据偏倚。考虑此因素并结合大数定律,在加入语义信息时从相对合适的角度设置最小词频以减少小样本概率的发生,同时可以缩减潜在药对范围。由于每味药对应众多化学成分、靶点信息等,在确立需要进一步研究的药对后,也需要一定的时间精力进行研究证明其有效性、安全性等,因此结合语义角度进行分析,合理地缩小潜在药对的范围是很有必要的。在药物数量上,加入语义信息的筛选结果涉及药物更少。临床处方往往有章可循,在处方中,各味药物由于在治疗用途和方剂构成、剂型上发挥的作用各异,通常会依据其作用性质按序排列,比如:君药、臣药、佐药、矫味药、赋型药等,故药物之间的顺序也存在着一定的联系。在中医处方数据中训练生成药物词向量,使得词向量获得适用于本数据的领域知识,即每一味药使用一定维数的向量表示,通过基于统计的文本相似度计算,以此表示药物之间的相似度,最终得到的共现结果具有词频与语义上的相似性。
从绘制的散点图对比可知:通过降维后的散点图对比可知加入语义信息后药物的分布比不加语义信息的分布更均匀,未加入语义信息的药物分布聚集情况更明显。且通过旋转角度,发现加入语义信息的药物分布在特定视角中存在可切分的范围划分。
与经典的关联分析算法比较可知:①关联规则的挖掘依赖于设置的支持度,即与药物出现频次数目有关,本实验使用数据的频次区间为[5,977],区间跨度大;当频次设置较低时,会有大量频繁项集产生,在保持较低频次时,各置信区间的结果数目最低有380条,与本文算法提取效果对比明显;当频次设置较高时,虽然得到结果数目会减少,但是对于低频药物,例如:炒麦芽(频次36)、炒谷芽(频次33)、乌梅肉(频次7)、胡黄连(频次5)等药物可能会被排除,不参与关联规则分析。对于频次跨度较大的数据,如何合理地设置支持度、置信度等参数需要人工调节比对。②关联规则结果存在冗余且输出为单向关系,如“南沙参→北沙参”“北沙参→南沙参”等,需要消耗大量的人工匹配整理时间。而若实验结果中存在A→B 却未存在B→A 的规则,对其结果也缺乏一定的可解释性,无法在关联规则层面确切说明其身为药对的价值,反而带来一定的局限性。此外,通过绘制对应的网络图发现从可视化角度,此算法结果涉及结点多且无法直接看出药物间的关系。通过上述对比,本文算法包含的频次范围更为宽泛,且考虑到药物间双向关联程度与药物文本语义间的相似度,从不同维度保证药对的有效提取。
肺癌是原发性支气管癌的简称,周老认为肺癌的主要病机为痰瘀郁肺,治疗大法以抗癌祛毒为基础,消癌解毒、化痰消瘀、益气养阴[21]。药对使用基于一定规则的两味药物,从而达到一定的增效减毒等效用,例如:白花蛇舌草的作用是清热解毒,在临床上经常与山慈菇等中药相配用以抗肿瘤;当痰毒明显,当化痰解毒,例如:山慈菇、炙僵蚕等。肺癌早期病位在肺,亦影响他脏,致脾胃功能不佳,故治疗时须调护脾胃。麦芽性味甘,平;归于脾、胃经。谷芽性味甘,温;归于脾、胃经。炒麦芽益气消食;炒谷芽偏于消食,用于不饥食少。两者皆有行气消食,健脾开胃之效。虽然使用频次较少但亦为有效药对。
综上所述,将词频与词向量结合考虑两两药物相互作用关系的同时,也从整体处方入手,探寻文本层面药对之间的作用关系,能够有效地缩小筛选研究潜在药对的范围。此外,本文在实验时暂未讨论Windows 窗口参数设置情况,Windows 的取值影响着中心词与周围词之间的共现频次,而中心词与周围词之间位置的关键是处方中各药物的顺序。相同药对在不同处方中的位置关系非一成不变,因此也影响着语义相似度。同时面对复杂处方,处方中药物的顺序与中心词周围半径的设置也有着重要研究价值,后续会进一步开展相关实验工作。
3 结语
本文通过对药对筛选的意义以及对以往数据挖掘方法的分析,发现常用的关联规则、聚类分析等方法的不足,提出了一种基于词频结合语义信息的新型药对发现算法,在词频层面确认潜在候选药对的范围,即其区分度不大的情况下,从另一层面语义信息考虑,进一步缩小范围,从而筛选出潜在药对以此进行更进一步的研究。本算法具有原理简单、易于实现等特点,本算法的提出可以为挖掘出大量潜在药对的进一步筛选提供思路,提高中药药对研究的效率,同时为挖掘用药规律提供方法学参考。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中国民间疗法(2021年1期)2021-04-20
中国民间疗法(2020年22期)2021-01-07
文苑(2020年6期)2020-06-22
当代陕西(2019年15期)2019-09-02
中成药(2018年6期)2018-07-11
学苑创造·A版(2018年11期)2018-02-01
长春中医药大学学报(2017年1期)2017-04-16
读者(2017年5期)2017-02-15
中国卫生(2016年11期)2016-11-12
