
对抗环境下的智能兵棋系统设计及其关键技术*
2024-04-24 09:20孙宇祥李原百赵俊杰周献中
火力与指挥控制 2024年2期
孙宇祥,李原百,周 胜,赵俊杰,周献中*
(1.南京大学控制科学与智能工程系,南京 210093;2.南京大学智能装备新技术研究中心,南京 210093)
0 引言
近年来人工智能技术突飞猛进,尤其在智能博弈对抗领域取得了一系列的关键进展。2016年,AlphaGo 与李胜石进行了一场万众瞩目的围棋大战,最终人工智能AlphaGo 以4∶1 的结果完胜人类,一时间掀起了社会上的广泛热议,推动了人工智能技术的又一次发展浪潮[1-2]。随后,AlphaGo的研制团队DeepMind 趁热打铁,在《星际争霸》游戏上进一步取得明显突破,研制成功AlphaStar[3]。中国腾讯AI Lab 利用深度强化学习技术,在《王者荣耀》游戏虚拟环境中构建“觉悟AI”,开发高扩展、低耦合的强化训练系统,使得“觉悟AI”能够具有进攻、诱导、防御、欺骗和技能连续释放的能力[4]。
智能博弈系统虽然取得了显著成就,但是依然有很多问题亟待进一步研究。虽然人工智能的概念早在1956 年就被提出,但是由于计算机性能的不足以及理论基础的缺失,人工智能还远远没有达到可以挑战人类思维的地步[5]。随着对于智能化研究的逐渐深入,各种算法的实现以及在围棋上Alpha-Go 的出现[6-7],对智能博弈系统进行智能化研究已经是一种趋势。智能辅助决策是制约智能博弈系统升级换代的瓶颈问题,是一个不容忽视甚至是需要争分夺秒去解决的问题。由于智能博弈系统特点,深度学习和强化学习的算法效果依然有很大的提升空间。这里以最经典的博弈系统“兵棋推演”为例,简述基于强化学习的智能博弈系统的构建思路及仿真验证。
本研究设计的算法模型为设计适用于复杂环境的智能兵棋系统提供了思路:建立智能兵棋系统通用的体系架构,并针对每个模块进行功能解释。针对智能兵棋系统的核心模块,建立智能决策算法模型,通过典型实验环境来验证建模思路。其中,智能决策模型以A3C 算法为代表的强化学习驱动,进而从原理和实践上,验证了智能决策算法模型在智能兵棋推演系统的可行性。
1 智能兵棋系统环境建模
1.1 智能兵棋系统构成要素设计
智能兵棋系统的组成必然包括了基本的构成要素,为了保障兵棋系统的正常输入-输出及智能博弈的有序推进,兵棋系统中应包括兵棋系统棋子、兵棋系统地图、兵棋系统对抗规则及兵棋系统想定4 个基本要素。
1.1.1 兵棋系统棋子
在兵棋系统里面,棋子的用途是表示实际博弈单元,可以代表博弈中的游戏单元,也可以以编队为基本单位,并且需要注明游戏单元的相关参数,比如单位编号、单元数量、攻击能力、防护能力、机动力值等主要信息。
1.1.2 兵棋系统地图
兵棋系统地图的主要功能是模拟实际地理情况,需要真实反映平原、公路、山地、丛林湖泊、海洋、河流等地理条件与作战场景[11]。目前主流的绘制地图途径有多种,一种是将实际的地理环境测绘出来,并依照比例尺缩放后进行还原,还有一种是将地图网格化,进行一定程度上的抽象。由于网格化的地图既易于机器进行理解,又能较好地还原实际地理条件与对抗场景,而按比例尺缩放的地图不便于机器理解,因此,电子化兵棋系统的地图一般选择网格化的地图,在这种情况下,网格化地图中的网格又被称作为棋格,兵棋系统双方棋子行动的最小单元就是棋格,地理条件与对抗场景模拟的最小单元也是棋格。其原因是能够与真实情况更加贴近。在真实的对抗环境中,对抗单位并不会被格子形状限制移动规则,而是可以360°选择方向。因此,为了与真实情况贴近,网格形状应支持棋子有尽可能多的移动方向。正三角形、正方形与正六边形可以无间隙覆盖整个平面,这三者作为棋格时可以选择的移动方向数分别为3、4、6,因此,现阶段网格化的地图基本上都采用六边形作为网格的形状[9]。
1.1.3 兵棋系统对抗规则
如果说棋子和地图是兵棋系统的血肉和骨架,那么兵棋规则就是博弈的灵魂,是大量博弈对抗问题研究成果的集中反映,所有棋子的移动和地图的使用都离不开兵棋规则[10]。规范兵棋推演并使其变得有序是规则的主要作用,规则能够使参与兵棋推演的双方,在一套明确具体的规定之下进行机动和对抗等一系列行动。兵棋规则内容的制定主要有两个渠道:从过往的历史经验中总结,或者从抽象的模拟数据中总结。在绝大多数情况下,兵棋规则分为两部分,一是推演规则;二是裁决规则[11],这两部分规则的使用范围以及作用效果不尽相同。推演规则侧重于规范博弈的行为,进行如何博弈的说明,比如棋子的攻击规则,棋子的机动规则,棋子上车下车规则,棋子隐藏掩蔽规则等,这些都属于博弈推演规则。而裁决规则侧重于明确棋子交战的对抗裁决依据,对作战过程中双方棋子造成伤害进行裁决,最终确定交战过程结束后双方力量的战损情况以及作战的胜负情况[12]。
1.1.4 兵棋系统想定
想定的主要内涵是对推演的态势情况、双方对抗目标、对抗行动计划以及进程发展等情况的提前设想,有企图立案想定、基本想定、补充想定的划分。需要明确的是,兵棋推演的想定需建立在棋子、地图和规则上,对想定背景进行描述,给定初始对抗的态势、博弈目标、研究计划等,且对行动先后手、推演次数以及最终胜负的评判依据等进行明确。
1.2 推演基本规则设计
规则在博弈对抗中是限制和规范棋子行为的一套体系,会很大程度影响路径选择和博弈过程,在规则体系内作出的决策是决定推演胜负的重要因素[13]。因此,智能兵棋系统的设计必然是以基本规则的支撑为基础的,本文以兵棋推演系统为例,通过程序函数把相应的基础功能封装为相应的基础功能函数,通过基础功能函数的调用,进而实现智能兵棋的算法,最终实现智能引擎的建立,其主要功能函数如下。
1.2.1 移动函数
初始化出发位置,在想定中进行赋值,计算每个棋子的x,y 坐标,获取周围六角格的坐标,进而在获取的六角格坐标中选择一个坐标进行赋值,然后进行坐标移动,移动方向包括东、西、东北、西北、东南、西南、静止7 个方向。移动过程有机动力损耗,具体损耗值参考机动力损耗表,以坦克棋子为例。每回合每单位坦克具有2.5 单位的机动力值。

表1 不同地形机动力损耗Table 1 Loss of maneuverability at different terrains
1.2.2 射击奖励积分函数
对敌方棋子进行射击,获取敌方棋子的坐标,进而判断射击后敌方棋子是否存在,如果存在且坐标对应符合敌方棋子坐标,即获得相应的奖励积分,否则不得分。
1.2.3 射击函数
获取棋子的坐标位置,通过调用可视函数判断是否可对敌方棋子进行观察,如果观察到可以射击的距离,根据敌方与距离设定打击效果。并且射击会受随机数影响,以模拟对抗的随机性。射击受到距离、地形、通视、随机性等方面的影响,通过在随机数上体现,具体如表2 所示。

表2 射击规则Table 2 Shooting rules
1.2.4 获取相邻坐标函数
输入棋子x,y 坐标,代表六角格的坐标,输出list 列表,以列表形式表示周围六角格坐标。
1.2.5 查询两个六角格之间的距离
输入x0,y0,x1,y1为int 的坐标,表示起点六角格坐标和终点六角格坐标,输出表示两个六角格之间的距离。
1.2.6 获取棋子状态信息函数
通过函数获取棋子的当前坐标以及回合机动状态。
1.2.7 检查棋子能否观察对方棋子
输入对方棋子状态信息,可观察对方棋子输出true,不可观察输出false。整个智能兵棋的对抗规则是红蓝双方进行对抗,双方棋子可进行机动、遮蔽、直瞄射击以及间瞄射击,其中,机动是指输入x,y 坐标,代表相邻六角格的坐标,输出效果,棋子进行移动;遮蔽是保证棋子进入隐蔽状态,不利于被攻击;直瞄射击是输入敌方棋子所在坐标,输出相应射击效果,射击敌方棋子;输入x,y 代表目标六角格坐标,输出效果,间瞄目标六角格。
1.2.8 裁决规则
裁决规则。每次射击后进行裁决,根据结果选择:无效,损毁,压制。每个坦克分队有3 个班组,损毁结果从1~3 中选择。如果压制后,则会使对方棋子无法移动和射击一回合,下回合恢复正常。
每局推演完毕后,一方总分=任务完成分+参数A×战果分(损伤分+打击分),并且判断胜负。设置一个参数A,调整任务分和战果分占总分的比例。因为任务分占比高时,和战果分占比高时算法模型算出效果不同,前者结果的胜率高,后者结果的战损比高。目前对于当前研究来说,胜率是最重要的评价因素,所以任务完成分占比较高。
1.3 智能博弈推演引擎核心接口设计
1.3.1 环境加载接口
智能兵棋接口应包括环境加载模块,保证每次加载对抗想定可以启动相关环境。
1.3.2 环境重置接口
该接口保证在每个episode 中可以重置环境,重新开始推演,并返回观测值。在强化学习算法中,智能体需要不断地尝试,累积经验,然后从经验中学到好的动作。一次尝试我们称之为一条轨迹或一个episode。每次尝试都要到达终止状态。一次尝试结束后,智能体需要从头开始,这就需要智能体具有重新初始化的功能。函数reset()就是这个作用。
1.3.3 环境渲染接口
在每次的step 里面,env.render()会刷新画面。render()函数在这里扮演图像引擎的角色。一个仿真环境必不可少的两部分是物理引擎和图像引擎。物理引擎模拟环境中物体的运动规律;图像引擎用来显示环境中的物体图像。其实,对于强化学习算法,该函数可以没有。但是,为了便于直观显示当前环境中物体的状态,图像引擎还是有必要的。另外,加入图像引擎可以方便调试代码。
1.3.4 动作随机选择接口
env.action_space.sample()返回一个action 的随机sample,即随机在动作空间里面选择一个动作,保证动作选择的随机性,防止局部最优。
1.3.5 执行动作接口
env.step(action)强化学习算法执行动作,需要返回动作执行后的状态信息,根据贝尔曼方程需要返回状态、回报值等。兵棋推演状态空间可定义为位置状态坐标X 和Y,同时包括棋子的实时状态(机动、隐蔽、设计)形成兵棋推演的状态空间。其中,棋子可机动方向为南、北、东北、西北、东南、西南以及静止7 个状态,分别定义为0~6;棋子在其中一格的射击状态为射击或者未射击,因此,这样就可以为采用深度强化学习技术提供必须的基础要求。
2 智能兵棋推演系统体系框架构建
本文设计的智能兵棋系统对抗环境如图1 所示,主要由六角格代表具体地形。地形高程越高则颜色越深,黑色代表二级公路,红色代表一级公路,阴影代表城镇居民地,利于隐蔽。
图1 智能兵棋系统想定展示Fig.1 Intelligent strategy system schematic display
智能兵棋推演系统主要有基础支撑层、仿真平台层及典型应用层3 层结构组织。智能兵棋推演平台的整体架构,主要以AI 兵棋模型系统和数据库为支撑,以棋子管理、地图编辑、想定编辑、推演控制、辅助决策、态势显示、数据管理、分析评估为仿真平台具体功能,以智能推演引擎接口支撑兵棋推演平台两类典型应用,如图2 所示。

图2 智能兵棋推演系统框架Figa2 Framework of intelligent strategy wargame system

图3 DQN,A3C,PPO 实验结果对比Fig.3 Comparison of experimental results of DQN,A3C and PPO
数据库系统主要由目标态势数据、装备性能数据、交战裁决基础数据集毁伤裁决修正数据组成。目标态势数据负责对抗态势目标数据进行获取,在获取对方态势数据后,为后续输入数据进行处理做准备[14]。我方装备性能数据包括对我方棋子的性能指标数据进行赋值,并作为智能决策的数据支持。对抗裁决基础数据用于评估博弈对抗双方在对抗后的结果,并引入随机数据值。裁决规则是实施兵棋推演的基本准则和核心,是对过去作战经验的总结和归纳。兵棋推演中裁决规则是根据历史数据并结合概率统计学原理设计的裁决方法和规定。毁伤裁决修正数据用于博弈对抗结束后,相关结果的进一步修正。
模型系统主要以强化学习驱动的智能决策算法为基础,是智能博弈推演系统的核心[15],包括了红方指挥AI 模型、蓝方指挥AI 模型、红方行动AI模型、蓝方行动AI 模型、辅助决策分析模型及环境综合作用模型。基于兵棋的基本要素组成,兵棋推演系统主要包括地图编辑子系统、棋子编辑子系统、规则编辑子系统、想定编辑子系统、推演筹划管理子系统,推演导调控制子系统、兵棋态势显示子系统、兵棋推演命令子系统8 个子系统。
2.1 地图编辑子系统
地图编辑子系统是针对每个想定所对应的对抗区域,导入规定格式的数字地图或文本地图,并对相关地貌和地物进行量化处理。根据地图比例尺和六角格大小等兵棋设计要求,系统能对想定所对应的作战区域进行地形量化。量化的地形信息能为各种作战行动的裁决,提供所需数据支撑。
2.2 棋子编辑子系统
棋子编辑子系统是对单位棋子、地物棋子、注记棋子进行编辑,棋子分辨率最小定为单兵、单件重火器,单兵的武器装备可叠加,棋子可合并、分解,即一个棋子分解为多个棋子、多个棋子合并为一个棋子。
2.3 规则编辑子系统
规则是兵棋推演事件裁决的依据,兵棋的特点之一就是具有非常具体、细致且各不相同的规则,正是这种规则体系使得兵棋可将军事专家的经验来建模模拟,因此,在处理各种关系和裁决方面的处理将主要体现为不同规则组合与使用。规则编辑子系统能够对裁决表和裁决流程进行编辑。兵棋规则均为开放式,可快速更改,在裁决过程中,可依据裁决结果查找对应的交战规则,此外,还应考虑玩家对棋子数据的影响。
2.4 想定编辑子系统
想定编辑子系统用于容纳各种对抗样式、各个对抗层级的各个推演想定,并可以灵活地进行编辑。
2.5 推演筹划管理子系统
推演筹划管理子系统用于推演开始前在兵棋地图进行量算作业,分析判断推演环境、推演任务、推演力量情况,在分析判断的基础上,确定推演目标、推演编成、态势配置、推演计划等。
2.6 推演导调控制子系统
推演导调控制子系统能够为导裁人员提供兵棋推演管理之外的其他导调控制功能支持,导裁人员可以对当前正在推演的所有推演进程进行监控。
2.7 兵棋态势显示子系统
态势显示模块用于对兵棋推演的态势进行可视化,方便博弈者清晰地了解当前态势。
2.8 兵棋推演命令子系统
兵棋推演命令子系统主要包括兵棋推演命令下达、命令纠错、命令预裁决、命令排序、命令显示、命令报表等功能。
3 智能决策模型设计
随着强化学习技术的不断发展,现有强化学习技术范式已从基于海量数据的样本学习模式,逐渐向自主学习进化模式转变,在小样本或无样本环境下采用“左右互搏”技术[16]。本章设计基于强化学习的智能决策模型,从而实现智能兵棋系统的自主决策和自主博弈对抗。设计的智能兵棋推演系统包括了强化学习算法选择模块,可以自主选择所使用的智能算法,从而进行智能决策。需要对仿真环境的状态变量空间与动作变量空间进行筛选,得到适用于算法输入、输出的状态空间S={s1,s2,...,sn}和动作空间A={a1,a2,..,am}。智能算法包括基于DQN 算法驱动、基于A3C 算法驱动和基于PPO 算法驱动3种典型类型,为验证算法可行性,本文实验所使用的蓝方是正常版本的规则AI 进行测试。
3.1 状态输入
在智能兵棋环境状态输入为当前我方棋子可以观察到的(Obs)observation,该Obs 以列表形式输入强化学习算法的神经网络,用于训练神经网络并得出估计值。对于强化学习需要输入兵棋全局的Obs,本文以r(si)表示,包括棋子周围高程、棋子周围地图类型、双方棋子剩余血量、双方的数量、双位置信息、夺控点位置信息、棋子是否通视,全局状态观察量r(s)=r(si)∪r(s2)∪…∪,即所有局部状态观察量的并集,如表3 所示。

表3 状态信息设置Table 3 Tatus information settings
3.2 算法驱动过程
在本文设计的智能兵棋博弈平台中,设计的算法为采取分布式执行、集中式训练的A3C(asynchronous advantage actor-critic)行动决策算法框架。A3C 算法是由Google DeepMind 在2016 年提出的,用于解决连续控制问题的一种深度强化学习算法。该算法延续了传统的Actor-Critic 框架,即Actor 用于选择动作,Critic 用于评估状态价值,在此基础上采用了多线程异步更新的训练方法,即在多个CPU 核心上并行执行训练任务,从而加速整体的训练过程,提升了训练效率和稳定性。
如图4 所示。多智能体训练时采用集中式学习训练Critic 与Actor,使用时Actor 只需知道局部信息即可执行。记棋子为agenti(i=1,2,...,n)。局部状态观测量是每个棋子能够观察到的态势信息集合。每个Critic 网络的输入会将对应棋子的动作AI 以及行动后的全局状态观测量考虑在内,且每个棋子都拥有自己的奖励值。每个棋子的Actor 网络更新时,Critic 网络输出的状态估计差值会输入进行更新,以此来调整Actor 网络。
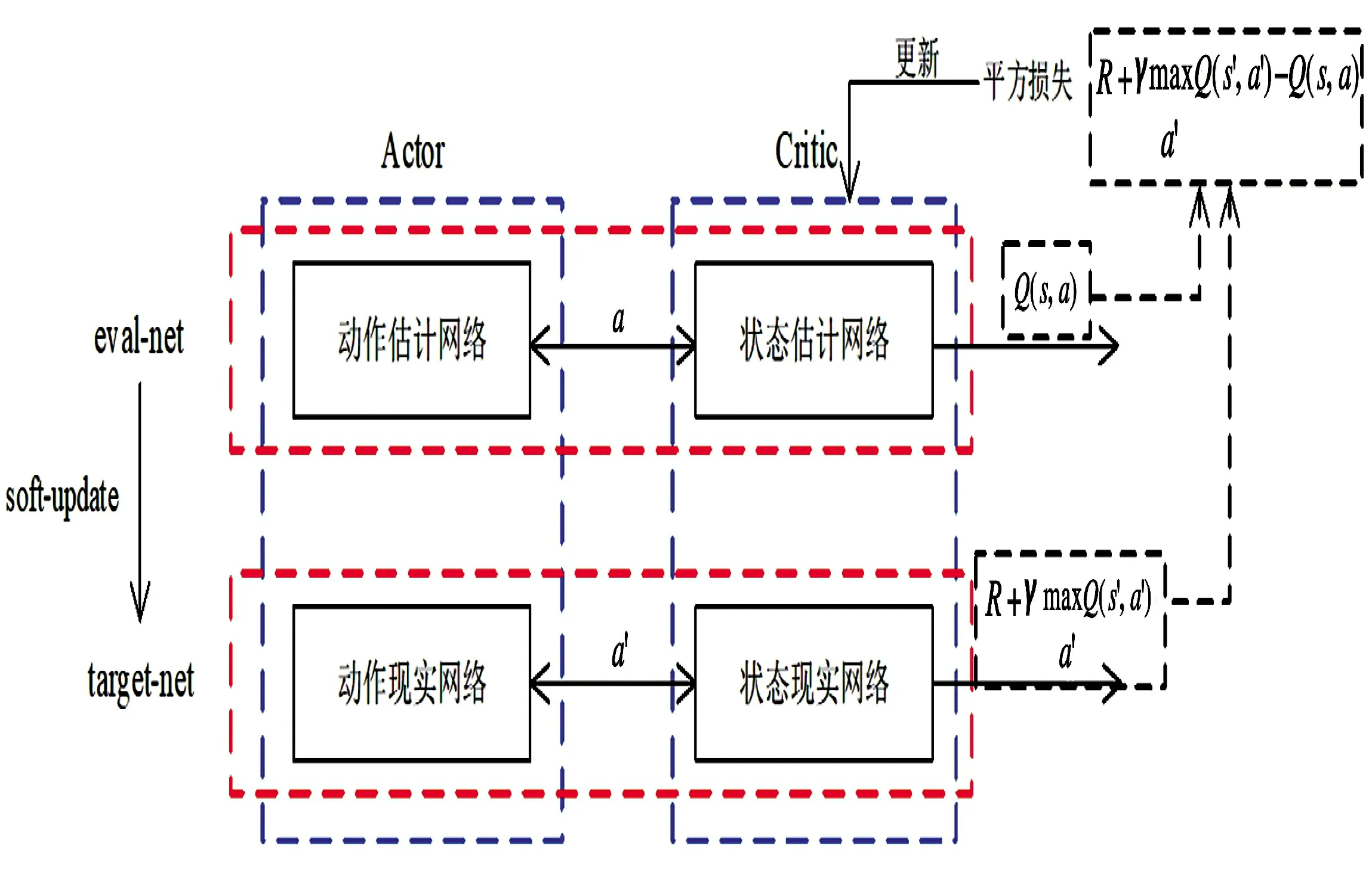
图4 强化学习AC 框架Fig.4 Reinforcement learning AC framework
同时,本文在实验时对每个智能体训练多个策略,并基于所有策略的整体效果进行优化,以提高A3C 算法的稳定性及鲁棒性。实验中的每个Actor和Critic 都有一个eval-net 和一个target-net。Critic的状态估计网络生成的Q 值和状态现实网络生成的贝尔曼方程计算出来的值进行相减,计算出loss值,再利用loss 值反向更新Critic 网络参数,再利用Critic 反向指导优化Actor,最后利用Actor 进行动作输出。更新Actor 网络的目的在于调整动作输出的概率,使其朝着得到更高价值的方向调整。
3.3 动作输出
输出动作在wargame 中,可以在执行动作后获取新的态势信息和回报值,进而反馈到Q 网络中,进一步更新网络参数。具体的输出动作包括移动、射击、静止和隐蔽,如表4 所示。

表4 动作信息表Table 4 Action information table
由于行动决策的不确定性以及开火对象的不确定性,且想定地图状态空间复杂,会使得训练的收敛速度较慢,很可能长时间难以取胜[17],导致大量无意义训练。针对以上环境的特性,本文对兵棋棋子的战术决策拟定了如图5 所示的详细战术决策规则,该规则AI 属于加强版的规则AI。本文基于综合规则和多智能体强化学习算法的决策生成机制,同时构建多智能体强化学习算法在对抗过程中的在线评估体系σ。当获取当前态势信息后,A3C 算法输出相对应的决策方案后,利用σ 来评估当前动作是否有效,如果大于σ 值则按照强化学习A3C 方法进行动作输出,如果小于σ 值则按照专家规则库中方案进行动作输出。σ 值计算包括Rwin获胜回报值,St1红方坦克存活分数,Gt1值红方夺取夺控点分数,Kt1值红方击毁对方坦克分数,Rwin获胜回报值,St2蓝方坦克存活分数,Gt2蓝方夺取夺控点分出,Kt2值蓝方修正系数击毁对方坦克分数,α1分别表示修正系数。通过计算得出σ,根据专家经验拟定选临界值,如果σ 超过临界值则选择强化学习A3C 决策算法,否则按照专家库规则进行动作选择。这样可以保证动作输出不会长期难以收敛,且避免了大量无意义的训练。

图5 智能体战术决策规则Fig.5 Tactical decision rules of agents

图6 智能兵棋推演系统推演效果Fig.6 Simulation effect of intelligent strategy simulation system
3.4 奖赏值设置
在强化学习中,奖励承担了监督训练过程的作用,智能体根据奖励进行奖励优化。在本文所讨论的仿真环境中,由于兵棋推演环境只针对动作进行规则判断以及交战决策,并不在发生机动或者交战之后提供任何奖励信息,只会在我方棋子到达夺控点或者全歼敌方棋子之后发送胜利信息或者敌方棋子到达夺控点或者我方棋子被全歼之后发送失败信息两种情况,也即在训练过程中的每一步都是无奖励的[18]。但是,这种情况会导致训练的过程大部分时间是没有奖励的,这种稀疏奖励会导致训练结果难以收敛,训练效率很低。本文针对这种情况,加入了额外奖励机制,即在棋子与夺控点距离越近则奖励值增加,距离夺控点越远奖励值减少,并且为了防止棋子无限移动难以收敛,本文对每移动一次即扣除微量的奖励值,防止无法收敛的情况。具体的奖励设置如下页表5 所示。
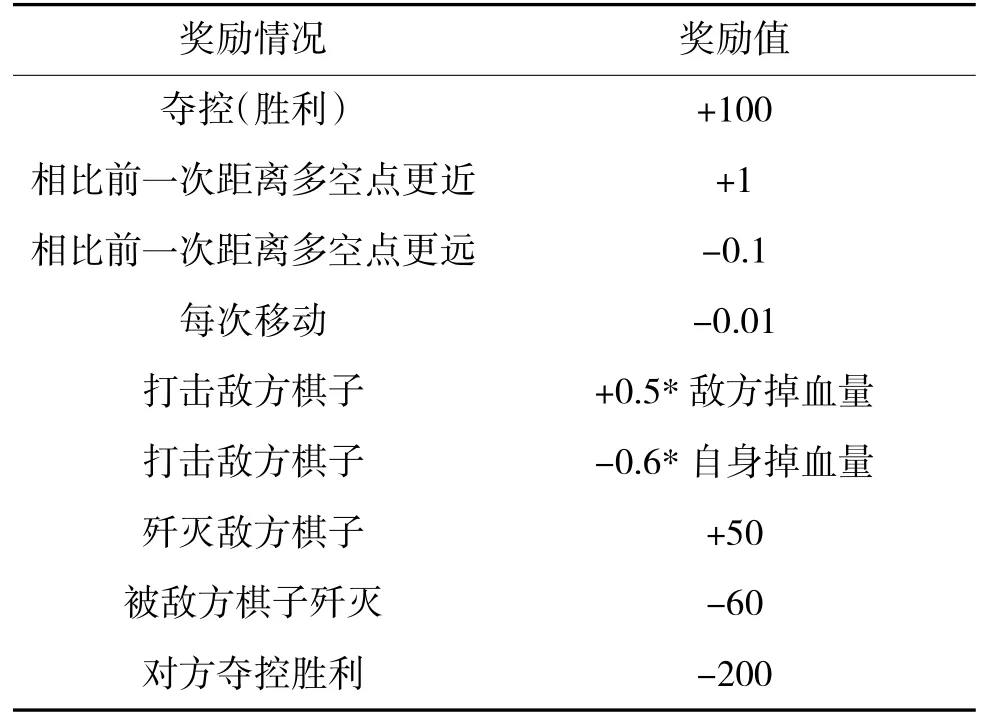
表5 奖励设置表Table 5 Reward setting table
4 智能兵棋推演系统仿真验证
本章结合本文的兵棋构成要素、兵棋规则、系统架构及智能决策模型构建智能兵棋推演系统,并在该系统进行智能博弈对抗,生成对抗数据,验证本文智能博弈系统的设计思路的可行性。
想定描述:智能博弈兵棋系统主要分为红蓝两方,获胜规则是一方率先到达夺控点,或者击毁另一方所有坦克。六角格作为地图基本组成单位,每个六角格具有编号和高程,高程越高则颜色越深。红色实线代表一级公路,黑色实线代表二级公路。六角格中有阴影部分代表城镇居民地,坦克在城镇居民地中不利于对方发现,有利于隐蔽,提高生存率。
在博弈推演中,以红蓝双方对抗博弈进行推演。红方以强化学习算法为驱动,蓝方以加强版规则AI 驱动。以100 局为单位进行胜率统计,详细胜率如图7 所示。

图7 详细胜率Fig.7 The detailed win rate
在100 局的对抗过程中,以A3C 强化学习智能算法控制的红方胜率达到66%,以基于知识库的基于规则的蓝方胜率达到34%。红蓝双方对抗的细节分数展示如图8 所示。通过博弈对抗细节得分,可以更好地验证博弈系统设计的可行性。其中,存活分数红方为3 712 分,蓝方为4 009 分。到达夺控点得分红方为2 631 分,蓝方为1 461 分。击毁敌方棋子得分红方为632 分,蓝方为521 分。总体上以强化学习算法控制的红方AI 主要以夺取夺控点取得胜利,显示出强化学习算法更倾向于快速高效的获胜方式,而基于规则的蓝方AI 以打击对方取得获胜,总体上还是强化学习算法的方法更加具有优势。

图8 细节分数展示Fig.8 The show of detail scores
5 结论
智能博弈已成为当前研究的热点问题。本文以智能兵棋推演为例,详细介绍了智能兵棋推演系统的环境建模所需要的基本要求。分析构建智能兵棋系统所需要的基本要素以及兵棋推演基本规则,建立智能兵棋推演系统的核心引擎接口,建立智能兵棋推演系统体系框架。对于智能兵棋推演最核心的智能决策模型进行详细分析介绍,构建基于A3C 的强化学习智能推演引擎,通过A3C 的强化学习算法,验证了该智能博弈推演系统设计的可行性。本文工作可以为智能博弈对抗推演系统的构建提供一个可行路径,为智能博弈领域的研究提供基础性的工作参考,未来会在该智能博弈系统上,进一步研究强化学习算法的改进优化工作。备注:
本文依据的实验平台是团队自主开发的“先胜1 号”智能兵棋环境,如读者需要平台进行实验验证可联系第一作者。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
小学生学习指导(低年级)(2021年5期)2021-07-21
数学小灵通(1-2年级)(2020年11期)2020-12-28
数学小灵通(1-2年级)(2020年9期)2020-10-27
军事文摘(2020年19期)2020-10-13
铁道通信信号(2020年3期)2020-09-21
军事运筹与系统工程(2019年3期)2019-08-13
铁道通信信号(2018年8期)2018-11-10
军事运筹与系统工程(2018年4期)2018-03-26
军事运筹与系统工程(2018年2期)2018-02-16
