
面向动态毁伤概率和目标价值的武器目标分配方法
2024-04-24 09:20林雕,朱燕,杨剑
火力与指挥控制 2024年2期
林 雕,朱 燕,杨 剑
(1.陆军指挥学院,南京 210045;2.解放军61175 部队,南京 210046;3.信息工程大学,郑州 450052)
0 引言
武器目标分配(weapon target assignment,WTA)是指通过选择一种合理的方案将武器或武器平台合理的分配给目标,通常以实现对目标最大毁伤效能或打击最大效费比为目标函数[1]。该问题于20世纪50 年代,由MANNE 在研究弹道导弹防御问题中首先提出,自此广泛应用于地面防空、舰艇防空、地对地打击、空对空打击等不同作战背景下的武器目标分配[2]。武器目标分配本质上属于一种组合分配问题,随着武器和目标数量的增大,其解的数量呈指数级增加,属于一个NP 完全(non-deterministic polynomial complete)问题[3]。传统的武器目标分配算法包括整数规划法、蚁群算法、粒子算法[4-11]等方法。
近年来,由于强化学习(Q-learning)在ATARI[12]游戏和AlphaGo 等问题上表现出强大的学习和决策优化能力,得到了广泛关注。深度强化学习的“动作选择”与组合优化中离散决策空间内的决策变量优选具有天然的相似性,使得其成为一种较好的组合优化解决方法[13]。此外,深度强化学习的“离线训练、在线决策”的特点,赋予了其在线快速求解组合优化问题的潜力。因此,应用强化学习快速求解大规模武器目标分配问题成为一种较优方案,且出现了部分相关文献[14-16]。文献[14]针对集群多目标分配问题,提出了一种基于强化学习的求解方法,通过设计奖励函数,将多目标分配的约束条件纳入到强化学习的建模中,并在小规模问题上验证了所提方法在求解武器目标分配问题上的时效优势性。面向静态条件下武器目标分配的强化学习建模,文献[15]提出了一种基于DQN 的导弹反舰求解方法。其中,状态空间表示为当前已发射导弹和舰队毁伤状况,动作空间表示为所有可选舰船目标,奖励函数设置为发射导弹后增加的毁伤数值。针对反导火力分配问题,文献[16]提出了在武器、目标类别数量固定条件下的深度强化学习建模方法,验证了所提模型在不同武器目标数量条件下的有效性。
联合作战条件下,随着战场空间向全域多维延伸,战场容量不断扩大。无人机、无人车、无人艇等新型作战武器的列装,使得战场动态目标数量陡增。敌我对抗过程中,武器对目标的毁伤概率并非一成不变。例如,随着武器与目标的相对位置、相对速度等参数的变化,对应的毁伤概率通常会随之改变[8]。基于此,面向大规模、动态条件下的武器目标分配问题,本文提出了一种基于深度强化学习的武器目标分配方法,以实现对动态毁伤概率和目标价值条件下的武器目标快速分配求解。
1 武器目标分配问题
假设有m 个武器和n 个目标,武器i 对目标j的毁伤概率为Pij(对应毁伤概率矩阵表示为P),目标的威胁程度为Vj(对应威胁度矩阵表示为V)。根据武器和目标的分配情况可构建一个m*n 的分配矩阵X
在上述分配矩阵条件下,其对应的总毁伤为:
武器目标分配的目标函数表示为:
其解空间大小为nm,即每个武器有n 种选择(n个目标中的一个),随着问题规模的增大,其解空间呈指数增长。对于动态条件下的武器目标分配问题,其毁伤概率矩阵为P 和威胁度矩阵V 并非一成不变,通常随着武器和目标状态的变化而改变。
2 基于深度强化学习的武器目标分配
2.1 深度强化学习模型
强化学习是一种试探、评价与更新的过程,智能体根据感知的当前状态,执行特定的动作,环境在接收该动作后,产生相应的奖励信号,同时根据动作产生相应的环境变化;智能体在观测到新的环境信息和奖励信号后,根据特定的目标对策略进行调整,如此反复迭代实现对策略的优化。基于强化学习的武器目标分配建模基本思路,是将武器目标分配问题看作多阶段序列决策问题,每一步决策完成对一个武器的目标分配,当完成所有武器的目标分配后,即完成一轮序列决策。对于m 个武器,从第1 个武器开始分配到第m 个武器完成分配即完成1个回合(episode),其对应的动作价值函数为:
其中,Ri为第i 步决策对应的奖励值,γ 为奖励对应的折扣因子。对应的动作价值函数更新方式如下:
其中,α 为学习率。
对于深度强化学习,即构建一个深度网络Q(s,a,w)来对Q(s,a)进行估值,如下页图1 所示。

图1 深度强化学习网络结构示意Fig.1 The network structure of the deep reinforcement learning
为防止出现单网络DQN 结构中出现的“过估计”问题,本文采用双网络结构的DQN 模型(double DQN)[17],设置评估网络Q(s,a,we)与目标网络Q^(s,a,we)两个结构相同且共享参数的深度强化学习网络,来增强网络的稳定性。double DQN 对应的单样本损失函数为:
对应的评估网络参数更新方式为:
其中,B 和|B|分别为模型每次训练对应的批量样本及其大小,α 为学习率。
2.2 面向武器目标分配的深度强化学习建模
基于强化学习的武器目标建模关键在于设计恰当的状态、动作以及奖励函数。
状态:表示为大小等于(m+1)*n 的一维向量,其中,前m*n 个元素表示为(1-pij)xij,(i∈[1,m];j∈[1,n]),后n 维为目标的价值vj(j∈[1,n]),此处设计的思路是基于式(2)将毁伤概率pij与对应分配情况xij的联合算子(1-pij)xij作为状态的特征描述,其取值为1 或者(1-pij)。1 对应于武器i 未分配给目标j,1-pij对应的是武器i 分配给了目标j。同时,将目标的价值也作为特征一并纳入到状态的向量表示中,以此适应目标价值矩阵变化的情况。
动作空间:动态空间A 大小等于目标的数量n。动作即为在某一时刻可从n 个目标中选择其中的一个,将当前武器分配给该目标。
奖励函数:奖励函数表示为两个状态转换前后的毁伤变化,即
不同于针对固定毁伤概率与目标价值的强化学习模型训练,此处的目标是获得可应对动态毁伤概率与目标价值的强化学习模型。为此,需要以动态变化的毁伤概率和目标价值数据集{(P1,V1),(P2,V2),…,(PK,VK)}作为训练的输入集,以此生成多个不同的初始状态和对应的状态转移方式。综上,完整的基于Double DQN 的武器目标分配算法如算法1 所示。

算法1:基于DON 的武器目标分配算法初始化经验回放存储D 的大小为N初始化训练数据集大小为K随机初始化动作价值函数的评估网络Q 的权重值we随机初始化动作价值函数的目标网络的权重值wt For episode=1,2,...,M do For k=1,2,...,K do读取一组毁伤矩阵Pk 和目标价值矩阵Vk根据εk=εend+(εstart-εend)*e(-1*k/εdecay),生成εk For t=1,2,...,m,从D 中随机抽样|B|个样本do初始化武器目标分配矩阵(m*n)为全零矩阵对起始状态s0 进行初始化以概率εk 选择一个随机动作at否则,令at=argma xatQ(st,at,wt)执行动作at,计算得到奖励Rt 和状态Si+1将(Si,at,Rt,Si+1)存储到D 中令yj=Ri,若回合在第i+1 步停止Ri+γmax■■■■■■■■■■■ai+1 Q^(si+1,ai+1,wt),其他情况执行梯度下降算法更新we(参见式(8))每完成C 步迭代,令Q^=Q End for End for End for
3 仿真实验与分析
为验证所提深度强化学习武器目标分配方法,在打击毁伤概率和目标价值动态变化条件下的性能和效率,通过仿真实验对深度强化学习模型进行训练和测试,并通过对比实验,验证训练所得模型相较于粒子群和随机分配方法的优势性。
3.1 实验数据集
实验设定武器目标数量为50∶20,采用随机生成毁伤矩阵和目标价值矩阵的方式,模拟中等毁伤概率条件下的动态武器目标分配情况。其中,毁伤概率和目标价值均以0.1 为间隔,分别在[0.5,0.8]和[0.4,0.7]之间随机取值。随机生成2 000 组毁伤和目标价值矩阵作为训练数据集(即算法1 中的K=2 000),为判断模型训练的收敛情况,随机生成100 组毁伤和目标价值矩阵作为强化学习的验证集。
3.2 DQN 的模型训练
基于DQN 的实验中设置两层全连接神经网络,每一层的神经元大小为100,折扣因子γ=0.9。其中,εstart=0.9,εend=0.05,εdecay=K*β=2 000*0.3=600。随机选定测试集中3 个验证样本,绘制其整体毁伤随着训练回合的变化情况,如图2 所示,并绘制100个样本对应的平均整体毁伤随着训练回合数变化情况。由训练曲线可知,在训练的前期整体毁伤概率得到了快速的提升。对单个样本,其整体毁伤在后期的震荡幅度较平均整体毁伤的震荡幅度较大。总体而言,所提模型基本可在100 个回合内实现较快收敛。
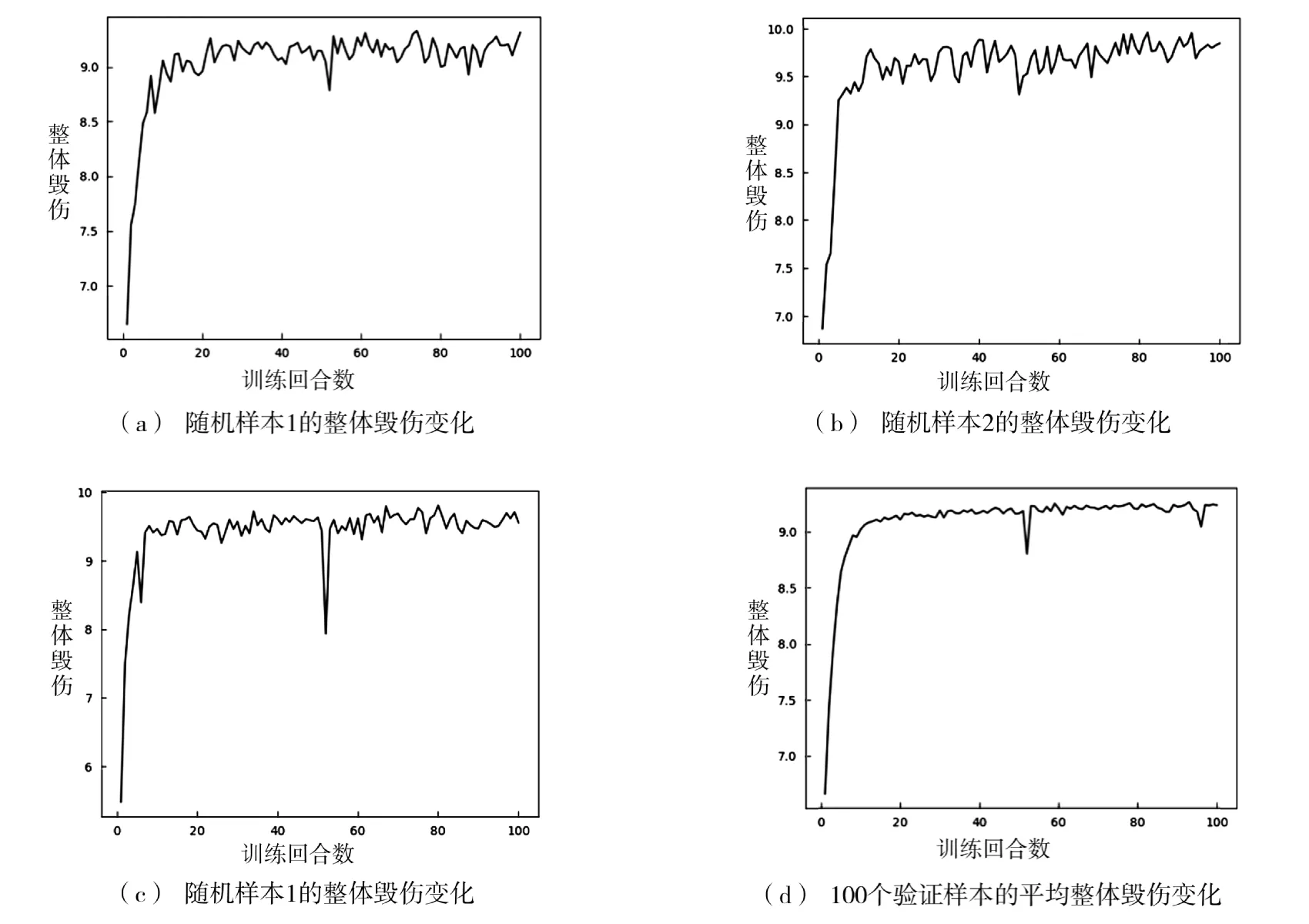
图2 整体毁伤与训练回合变化关系图Fig.2 The change of the total damage with regard to the training episode
3.3 模型测试与对比实验
为对上述训练所得模型进行测试,基于相同毁伤概率和目标价值取值范围,随机生成4*100 个毁伤概率和目标价值矩阵作为测试数据集,用于对所提方法进行测试。为进一步验证模型的优势性,采用基于粒子群[9]和随机分配两种武器目标分配方法作为对照。其中,基于粒子群的方法中粒子群数量和迭代次数分别设置为500 和50。基于随机分配方法中,每一个武器随机从20 个目标中选择一个作为打击目标。以4 组测试集的平均整体毁伤概率和平均计算时间为指标对3 种方法进行比较,实验结果如表1 所示。较基于粒子群的方法,本文方法在平均计算时间上具有显著优势,其武器目标分配方案的整体毁伤效率计算,在验证集2~4 上均高于粒子群方法。较随机分配方法而言,本文方法和粒子群方法在平均整体毁伤的计算结果上均具有明显优势。相较于本文方法和粒子群方法,由于随机分配法计算简单,其在计算时间上最快。
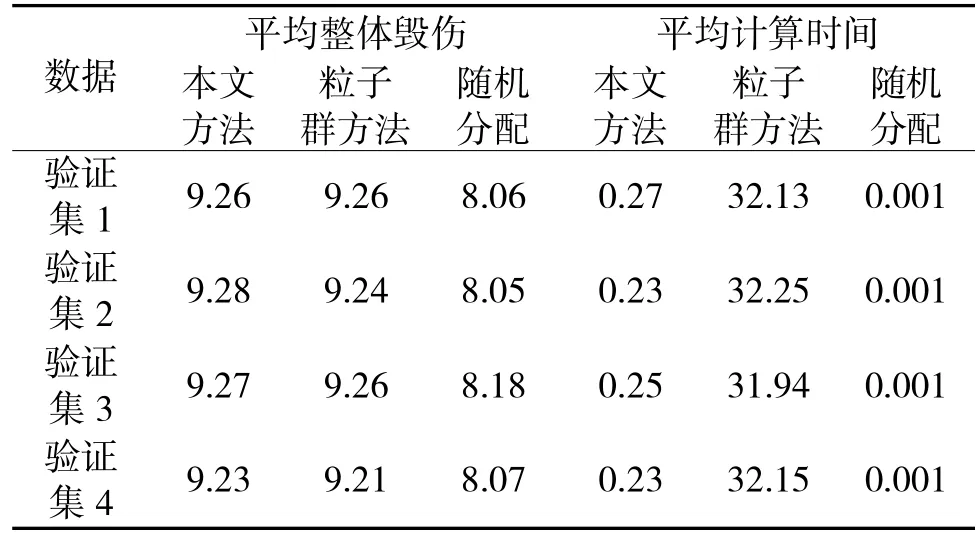
表1 基于4 组测试集的实验结果Table 1 The experiment results of the 4 test datasets
为进一步测试模型在毁伤概率和目标价值精度变化条件下的适用性,以0.05 为间隔分别在[0.5,0.8]以及[0.4,0.7]之间随机生成100 个毁伤概率和目标价值矩阵作为新的测试集。基于本文方法和基于粒子群的方法计算得到的整体平均毁伤分别为9.68与9.64,平均计算时间分别为0.26 s 和25.64 s,进一步证明了本文所提方法在毁伤概率和目标价值精度变化条件下仍具有较高的适用性。
综上,本文训练所得模型在动态变化的毁伤概率矩阵和目标价值条件下具有良好的适用性,且其总体武器目标分配方案和计算时间均优于基于粒子群的武器目标分配方法。
3.4 DQN 模型参数分析
DQN 模型训练中涉及多个参数配置,结合本文方法实际,选取训练样本集大小K 和Epsilon 衰减系数εdecay两个关键参数对其敏感性进行分析。
3.4.1 训练样本集参数设定
在3.2 节的基础上,保持其他参数和测试集不变的基础上,另设两组大小不同的训练数据集(K=1 000,K=3 000),采用相同的网络结构,进行100 个回合的训练。对应的整体毁伤变化曲线如图3 所示。由图3 可知,训练样本数量等于3 000 时,模型的前期收敛速度最快,样本数为1 000 时其前期的整体毁伤增速最慢。3 种训练样本条件下,基本可在100 个回合内实现训练的收敛。在样本数为3 000时,模型训练后期出现了一个显著毁伤底点,而在K=1 000 时则未见此现象。说明随着训练样本数量的增大,训练所得模型可能在局部范围出现欠拟合情况,导致收敛曲线震荡。
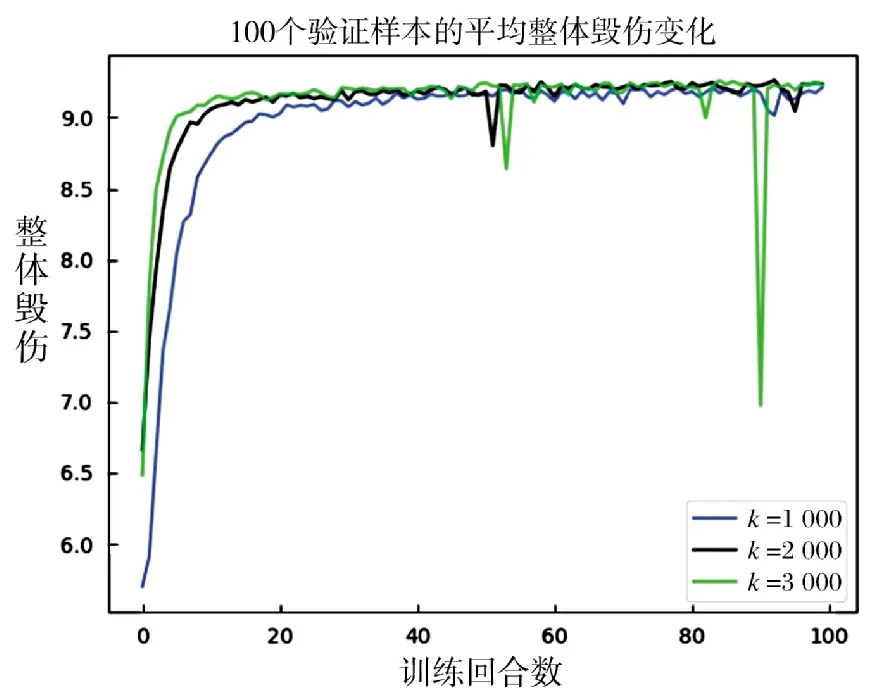
图3 3 种不同大小训练样本对应的平均整体毁伤变化Fig.3 Theaveragetotaldamagesofthreedifferenttrainingdatasets
3.4.2 系数设定
在以及训练样本K 一致的条件下,通过设定大小可控制Epsilon 的变化曲线。Epsilon 越大,选择随机动作的概率越大;Epsilon 衰减越快,意味着智能体可探索的空间越小。在原有的基础上,另设3 组系数,分别等于(对应的值分别为0.1,0.5,0.7)。4 组对应的衰减曲线如图4 所示。图中清晰展示了随着增大,Epsilon 的衰减速度变慢,且其在最后一个样本上的终止值也更大。

图4 不同的epsilon decay 对应的衰减曲线Fig.4 The decay curves of four different epsilon parameters
在保持其他参数和测试集与3.2 节一致的条件下,利用4 组不同的对模型进行训练,对应100 个回合内的整体毁伤变化情况如图5 所示。由图5 可知,随着Epsilon 的增大,训练曲线震荡现象更加明显,可能是由于其探索空间变大而导致的。另外,Epsilon 的增大并未展现出对整体毁伤峰值的正向影响,说明强化学习过程中需要保持探索与利用之间的平衡,过度追求随机探索未必会提升模型的计算效果。
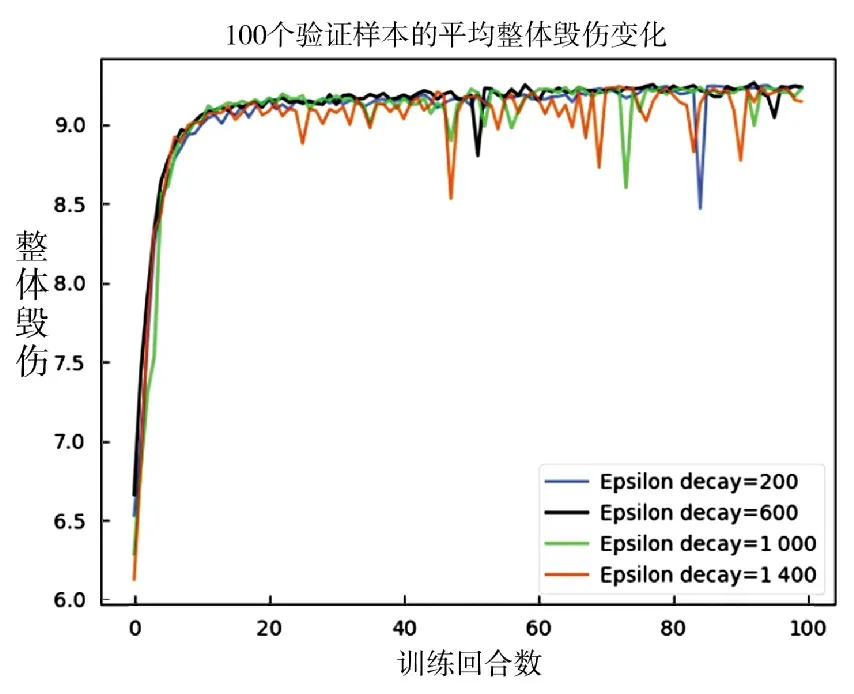
图5 不同epsilon decay 对应的整体毁伤变化Fig.5 The total damages with regard to four different epsilon decay parameters
4 结论
本文提出了一种基于深度强化学习的武器目标分配方法。该方法利用武器目标分配的毁伤函数,设计了一种简单高效的状态特征化描述方法。实验证明,该方法可有效应对动态毁伤和目标价值条件下的武器目标分配,且其目标分配的时间效率与总体毁伤优于基于粒子群的方法。下一步将从3个方向进一步深化研究:一是将所提模型整合到作战仿真、任务规划等信息系统中,实现对方法的工程化应用。二是研究在武器目标数量、毁伤概率、目标价值联合变化条件下的武器目标分配建模方法,进一步增强方法的可用性。三是研究引进Distri butional DQN、Noisy DQN 等改进版DQN 方法,提出对应的武器目标分配建模方法,以期进一步提高武器目标分配的效果和效率。
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
铁道通信信号(2020年9期)2020-02-06
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
经济技术协作信息(2018年30期)2018-11-22
小哥白尼·军事科学画报(2017年3期)2017-06-12
少儿科学周刊·儿童版(2016年2期)2016-03-19
