
面向作战决策智能体的融合赋权评估方法*
2024-04-24 09:20张人文陈希亮赵春宇
火力与指挥控制 2024年2期
张人文,赖 俊,陈希亮,赵春宇
(陆军工程大学指挥控制工程学院,南京 210007)
0 引言
当前,世界新军事变革加速演进,利用强化学习技术训练智能体进行作战智能决策,成为作战领域的研究热点。美军“深绿”计划、“空战演进”项目等都是作战智能决策领域的典型应用[1-3]。通过耦合专家知识,而后在数据驱动下使用强化学习方法进行训练,获得符合战场环境需求的作战决策智能体,指挥员及参谋人员能够及时评估作战计划,验证作战构想,完善作战方案,使作战筹划、作战实施阶段指挥机构人员从繁重的手工作业和脑力劳动中得到解放,提升应对战场态势变化的效率,加速“观察-判断-决策-行动”循环[4],获得战场优势。
通过强化学习方法训练出合适的智能体后,能否对智能体决策效果进行合理评估是判断模型可用性的关键。智能体效果评估的重点在于衡量智能体决策是否达成作战目的、完成作战目标,是智能体能力评估的核心内容,也是辅助指挥员选择作战方案的重要依据[5]。然而,目前在作战智能决策领域,虽然实际应用于智能体训练的强化学习方法较多,但对智能体训练效果评估开展的研究仍然较少,大多仅简单依靠胜率等单一指标。欧微等通过构建兵棋决策效果评估模型,实现对决策效果的快速准确评估[5];方伟等从评估决策的有效性、实时性、鲁棒性3 个维度,对航空兵智能决策模型的评估方法进行了分析[6];郑华利等从系统工程角度出发,开展作战辅助决策模型构建与评估通用方法的研究,提出辅助决策模型评估分级的一般流程与方法[7];韩超通过建立评估指标体系,应用深度学习方法对作战推演中智能博弈对抗算法水平评估模型进行研究[8],上述研究虽侧重点不一,但均未涉及强化学习智能体评估,无法满足作战决策智能体的评估要求。
由于训练算法与硬件算力等条件的限制,目前应用强化学习算法对作战决策智能体进行训练时,大多采取与预先设定好行动规则的对手进行仿真对抗的方式。而胜率作为对战结果的直接体现,被许多研究者用来作为评估智能体的依据。但考虑战场的高度复杂性及作战进程的不确定性,规则型对手具有较高局限性,容易造成智能体对训练环境的过拟合,且智能体有可能出现胜率较高但决策动作或效果不符合实际的战术要求的情况,因此,仅靠胜率这一单一指标难以对智能体训练效果进行全面的量化评估。
在评估领域,目前得到较多应用的方法是通过构建评价体系并对各指标赋予相应权重的综合评价法,如基于主观权重的层次分析法(analytic hierarchy process,AHP)、Delphi 法等,基于客观权重的CRITIC 法、熵权法等[9-12]。但单一方法存在主客观差异,具有一定的局限性。在解决较为复杂的评估问题时,研究者往往对多种方法综合使用。
本文以作战决策智能体评估这一问题为切入点,充分考虑智能体的战场环境适应性及智能体训练的方法手段,通过建立作战决策智能体评估指标体系,采用融合主客观权值的融合赋权法及逼近理想解排序法(TOPSIS)[13]对智能体效果进行打分排序,评估智能体训练效果,避免仅采用胜率作为单一指标的局限,为解决该类评估问题提供支撑。
1 作战决策智能体评估指标体系
作战决策智能体是使用计算机技术解决军事决策问题的典型应用。因此,构建评估指标体系时,必须充分考虑模型应用场景,结合智能体使用的强化学习方法特点,突出智能体可靠性及作战决策能力,并依据战场环境各要素对智能体影响程度形成综合评估指标。
作战决策智能体评估指标体系包括战术、技术两大因素,主要涵盖作战决策能力等主观指标及智能体训练效率等客观指标,包括作战决策有效性、作战意图实现性、作战环境适应性、智能体训练效率、智能体训练体系及智能体训练方法,如图1 所示。
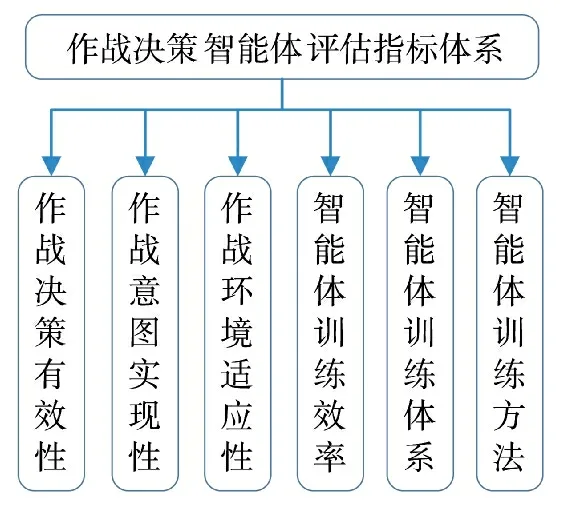
图1 作战决策智能体评估指标体系Fig.1 Operational decision-making agent evaluation index system
以上为第一层次指标,第二层次指标具体构成如下。
1.1 作战决策有效性评估指标
决策有效性是反映智能体决策效果的评估指标,主要包括装备效能发挥水平、威胁评估水平、战中临机处置水平、战术效果等。
装备效能发挥水平是反映智能体发挥武器装备效能的指标,如智能体控制的坦克能够在战场进行机动、开火,做到发现对手、歼灭对手;威胁评估水平是反映智能体面对敌方威胁时主动进行态势评估的指标,即面对复杂战场态势时,智能体能够作出决策,首先消灭对自身威胁程度最大的对手,例如武装直升机面对敌方主战坦克和防空车辆时,应根据战场形势作出判断,是否首先摧毁敌防空车辆;战中临机处置水平是反映智能体对敌方偷袭、预备队投入战场等未知情况能否进行高效决策的能力指标,体现智能体全流程决策能力;战术效果是反映智能体决策是否具备战争艺术的指标,智能体可通过强化学习技术掌握如穿插、迂回等战术手段,应用于作战决策。
1.2 作战意图实现性评估指标
意图实现性是反映作战决策智能体功能实现情况的指标,即能否实现作战意图、完成作战任务、达到作战目的,主要包括智能体在仿真环境进行验证时的胜率、兵力生存时间、智能体的战场损耗率、对敌方毁伤率等。
胜率是体现智能体能否战胜对手的重要指标。即在仿真战场环境下,智能体与规则型对手或人类对手进行对战取得胜利的场次比率;兵力生存时间是智能体在战场整体生存能力的体现,在主动投入战斗的情况下,智能体能够有效牵制敌方,保存自己消灭对手,达成战术目标;战斗损耗率是智能体决策结果的直接体现,例如,达成同等战术目的的情况下,“杀敌一千自损七百”的智能体比“杀敌一千自损八百”的决策效果好;对敌方毁伤率与战斗损耗率相反,反映同等战斗单元歼灭敌方兵力情况。
1.3 作战环境适应性评估指标
环境适应性是反映作战决策智能体适应环境能力的评估指标,即避免智能体对训练环境的过拟合,具备遂行不同作战背景下进行决策的泛化性。主要包括战场环境适应性、我方兵力布势适应性、敌方兵力布势适应性等。
战场环境适应性反映智能体对不同地理位置、不同作战时间等的适应情况;我方兵力布势适应性、敌方兵力布势适应性,分别反映智能体对我方、敌方兵力规模及初始位置的适应情况。
1.4 智能体训练效率评估指标
智能体训练效率是反映作战决策智能体实际应用性价比的评估指标,即智能体是否能够在较短时间内完成训练、面对新情况时能否接续训练进行能力提升及算力资源需求。主要包括智能体训练耗时和智能体训练资源耗费等。
智能体训练耗时是智能体评估的客观指标,若智能体虽效果较好,但训练时长超出人们的可接受范围,则不具备较好的应用性;同理,智能体训练资源耗费也是评估智能体训练性价比的客观指标,若训练所需的硬件资源(如显卡算力,以NVIDIA GeForce RTX 3080 为97MHash 的基准计算)过多,不具备实际可操作性,则无法进行应用,成为“空中楼阁”。
1.5 智能体训练体系评估指标
智能体训练体系是反映作战决策智能体训练流程、步骤合理性的评估指标。由于作战决策智能体采用强化学习特别是多智能体强化学习技术,训练智能体时常遇到的冷启动、探索与利用、奖励稀疏等问题也需要恰当处理。主要包括训练流程合理性、训练体系创新性[14-16]、强化学习算法运用等。
训练流程合理性是反映训练各阶段内部及各阶段之间是否衔接顺畅、有效的指标,如智能体训练时应该先易后难,使用规则耦合等方式对智能体训练初期进行引导,采用知识驱动等方式提高训练效果;体系创新性是反映训练过程创新特色的指标,如设置更有效的探索利用参数、设计新的奖励函数等;强化学习算法运用是反映智能体训练算法质效的指标,训练时可以选择MAPPO、QMIX、MADDPG 等主流算法并改进优化,筛选符合需求的算法,提升智能体的决策能力。
1.6 智能体训练方法评估指标
智能体训练方法是反映作战决策智能体训练手段先进性、合理性的评估指标。主要包括对手抽样方式设计、自我学习提升、综合方法设计与运用等。
对手抽样方式设计是衡量对抗环境下智能体训练方法优劣的典型评价指标,在战场激烈对抗条件下,挑选训练对手是一个重要环节,面对太强的对手,智能体常被击败,较难学习,面对太弱的对手,智能体轻松获胜,无法提升;自我学习提升是智能体决策能力提升的新颖方法,采用类似“左右互搏”的手段,能够在获得训练数据的同时,寻找自身漏洞,减轻强化学习智能体策略遗忘现象的影响;综合方法设计与运用是反映智能体训练方法综合性能的指标,如使用联盟训练[17]、种群训练[18]等综合方法,尝试突破智能体策略循环的限制,提升智能决策性能。
作战决策水平是指挥艺术的重要体现。因此,设计评估体系时,需要充分考虑不同技战术指标对智能体决策过程合理性与结果合理性的影响。体现结果合理性的指标方面,充分利用智能体客观数据反映决策效果;体现过程合理性方面,运用指挥机构人员的主观能动性,可通过集体研究赋分的方式反映智能体决策的战术效果及战术合理性。将底层指标通过主客观不同方式融合进入作战决策评估过程,形成底层指标内部独立、上层指标外部融合的整体,提升评估体系的合理性,如图2 所示。

图2 作战决策智能体评估指标体系示意图Fig.2 Operational decision-making agent evaluation index system diagram
2 基于融合赋权-TOPSIS 综合评价法的评估建模过程
2.1 融合赋权过程
为了解决各类评估问题,人们对具有不同特点的赋权方法进行了大量研究。但不同方法的特点也导致了一定的局限性,如主观赋权方法难以精确量化客观指标,同样,客观赋权方法无法反映主观因素影响。为全面反映评价过程,本文采用主客观评价方法分别对相应指标进行赋权,而后融合进评估体系的融合赋权方法。通过区分主客观因素求取权重的方式,使不同的赋权方法分别反映指标自身特点,体现权值的合理性。
2.1.1 主观赋权
层次分析法是一种典型的主观赋权方法,能够将定性分析和定量计算相结合,反映评估人的主观意图。在作战决策智能体评估指标体系中,许多指标如作战决策有效性、作战环境适应性、智能体训练体系、智能体训练方法等指标带有一定的主观性,难以精确地进行量化,使用层次分析法可以较好的发挥优势,反映主观因素影响,继而确定指标权重。
层次分析法的主要步骤[19]如下:
1)分析评估问题影响因素及内部关联,确定评估目标,建立指标体系。
2)构造判断矩阵。采用两两比较的方式,对各个指标间的相互重要性进行赋值。判断矩阵J 中,aij表示第i 个元素ai相对第j 个元素aj的相对重要性,可采用1~9 标度法。
由各元素相对重要性向量:
可得相对重要性权重向量W:
3)对判断矩阵进行一致性检验。主要是对判断矩阵中的逻辑矛盾进行检查,保证逻辑合理。
引入一致性指标CI,表达式为:
一致性比率为:
其中,RI 为平均随机一致性指标。一般认为,当CR小于0.1 时,判断矩阵通过一致性检验,且该值越小则一致性越理想。
2.1.2 客观赋权
CRITIC (criteria importance though intercriteria correlation)法是一种典型的客观赋权方法,通过利用数据计算评估指标的标准差和相关系数,反映指标间的对比强度及冲突性[20]。该方法不需要大量的计算,能够兼顾指标之间的变异性大小和相关性,是一种比熵权法和变异系数法效果更好的方法。
CRITIC 法的主要步骤[21]如下:
假设现有P 个评价指标,N 共个评价样本,形成数据矩阵M:
1)数据无量纲化处理
一般使用正向化或逆向化处理,对于正向指标(指标的值越大越好):
对于逆向指标(指标的值越小越好):
2)计算指标变异性
通常使用标准差体现指标变异性:
其中,Sj表示第j 个指标的标准差。
3)计算指标冲突性
通常使用相关系数体现指标冲突性:
4)计算指标的综合信息量
5)得到各指标权重系数
2.1.3 融合赋权
在作战决策智能体评估指标体系中,既有主观性指标,又有客观性指标,难以单独通过某种特定赋权方式完整地反映各指标的特点。因此,与组合赋权[22]不同,本文采用基于主客观赋权结合的融合赋权方法。融合赋权的具体含义为:对于作战决策有效性(A)、作战环境适应性(B)、智能体训练体系(E)、智能体训练方法(F)等4 类主观性指标所属的第二层次各指标采用层次分析法进行赋权;对于作战意图实现性(C)、智能体训练效率(D)等2 类客观性指标所属的第二层次各指标使用CRITIC 法进行赋权,而后分别融合进入评估指标体系。不同赋权方法内部独立,外部融合,能够体现方法优势,提高赋权合理性、科学性,如表1 所示。

表1 融合赋权方法示例Table 1 Examples of fusing weight method
对于作战决策智能体评估指标体系所属的第一层次6 类指标,结合指标特点,采用层次分析法进行主观赋权。
2.2 融合赋权-TOPSIS 综合评价法
TOPSIS(technique for order preference by similarity to an ideal solution)法又称逼近理想解排序法,广泛应用在方案评估问题中,能够充分利用原始数据信息,准确反映出各方案之间的差距和优劣[23]。
TOPSIS 法主要步骤如下:
1)将原始数据正向化
将极小型指标、中间型指标、区间型指标统一转化为极大型指标,形成数据正向化矩阵。
2)将正向化矩阵标准化
消除量纲影响,对正向化矩阵进行标准化,可采用如下方式:
其中,Zij表示标准化后的元素值。
对于n 个待评价对象,m 个评估指标,标准化矩阵Z:
3)计算得分
定义最大值Z+:
定义最小值Z-:
则第i 个评价对象带权重的正理想解为:
则第i 个评价对象带权重的负理想解为:
第i 个评价对象的得分为:
根据得分的大小即可判断方案的优劣,进而进行评价及筛选。
3 作战决策智能体效果评估分析实例
通过构建陆上合成分队进攻作战场景,将使用不同强化学习方法训练出来的6 个作战决策智能体与预先设置好的规则型对手进行对战,获得对战数据,对本文提出的融合赋权-TOPSIS 方法进行验证。
3.1 陆上合成分队进攻作战场景构建
本文构建了由红蓝双方展开遭遇对抗的陆上合成分队进攻作战场景。红方由3 个坦克排(各含4 辆坦克)、2 个武装直升机中队(各含4 架武装直升机)、1 个防空导弹排(含4 辆履带式防空导弹车)等兵力组成,使用强化学习算法训练,自主决策;蓝方兵力规模与红方对等,使用设定好的固定战斗规则,如图3 所示。

图3 红方坦克排Fig.3 Red tank platoon
作战场景构建基于Unity 平台,以C#作为开发语言,使用ML-agents 机器学习工具包,作战实体模型接入多智能体深度强化学习算法,用于作战决策仿真。实验基础硬件为Intel 512 G 固态硬盘,128 G内存,操作系统为Windows 10。不同智能体训练时,使用NVIDIA GeForce RTX 系列不同型号显卡,以便获取训练资源耗费的相关数据。
交战地域为三维仿真野战开阔地,红蓝双方于固定区域范围内生成兵力,但不设置固定起始位置。
以红方兵力运用为例,交战时,红方坦克排担负陆上突击任务,红方武装直升机中队担负空中突击任务,重点攻击蓝方坦克及履带式防空导弹车;红方履带式防空导弹车担负野战防空任务,重点抗击蓝方武装直升机。蓝方兵力运用相同。
交战时,双方主战装备首先进行战场态势感知,按仿真规则对敌方目标进行侦察,发现目标后自行判断是否具备开火条件,若条件具备,则对目标开火,否则进行战场机动。开火后继续攻击前进,在歼灭目标后继续搜索其他目标,直至歼灭敌方全部目标,如图4 所示。

图4 陆上合成分队进攻作战场景Fig.4 The simulation platform of Army synthesis unit’s offensive combat environment
3.2 作战决策智能体训练
预先训练6 个作战决策智能体,作为此次效果评估对象。
6 个作战决策智能体使用MAPPO、MADDPG 等不同核心算法进行训练。训练过程中,分别采用与规则型对手对战、自我博弈对战及随机对手抽样对战等多种方式,掌握作战决策能力。而后,通过改变兵力初始位置、临机增加敌方兵力等途径,进一步提升智能体适应战场环境能力,使决策能力符合,避免过拟合。
3.3 指标数据采集
评估时需采集评估体系的主客观指标。获得主观指标数据时,每个智能体分别与固定规则型对手进行10 次交战,交战时在部分轮次按一定规则改变敌我双方初始位置,战中适当增加蓝方兵力,观察智能体交战表现,作为主观指标的打分依据。获得客观指标数据时,每个智能体分别与固定规则型对手进行100 次交战,根据胜负场次计算胜率,生存时间、战损率、毁伤率以100 次交战的平均值计算。
3.4 确定主观指标权重
邀请若干负责作战决策工作的参谋部门人员共同商讨,对各层次指标进行重要性比较,构造判断矩阵。
对于第1 层次指标,判断矩阵为:
可得第1 层次各指标权重为(保留2 位小数):ωM=(0.08,0.12,0.16,0.25,0.22,0.17)
对于第2 层次指标,判断矩阵为:
可得各主观指标权重为(均保留2 位小数):
ωA=(0.17,0.29,0.34,0.20)
ωC=(0.54,0.30,0.16)
ωE=(0.17,0.44,0.39)
ωF=(0.21,0.24,0.55)
3.5 确定客观指标权重
根据对战情况,获得6 个作战决策智能体的各项数据,如表2 所示。其中,兵力生存时间单位为s,训练耗时单位为h,训练资源耗费单位为MHash。

表2 6 个作战决策智能体演示数据Table 2 Demo data of 6 operational decision-making agent
经数据无量纲化处理,使用CRITIC 法获得客观指标权重为:
ωB=(0.17,0.16,0.54,0.13)
ωD=(0.46,0.54)
融合各项指标权重,可得评估体系整体权重,如表3 所示。
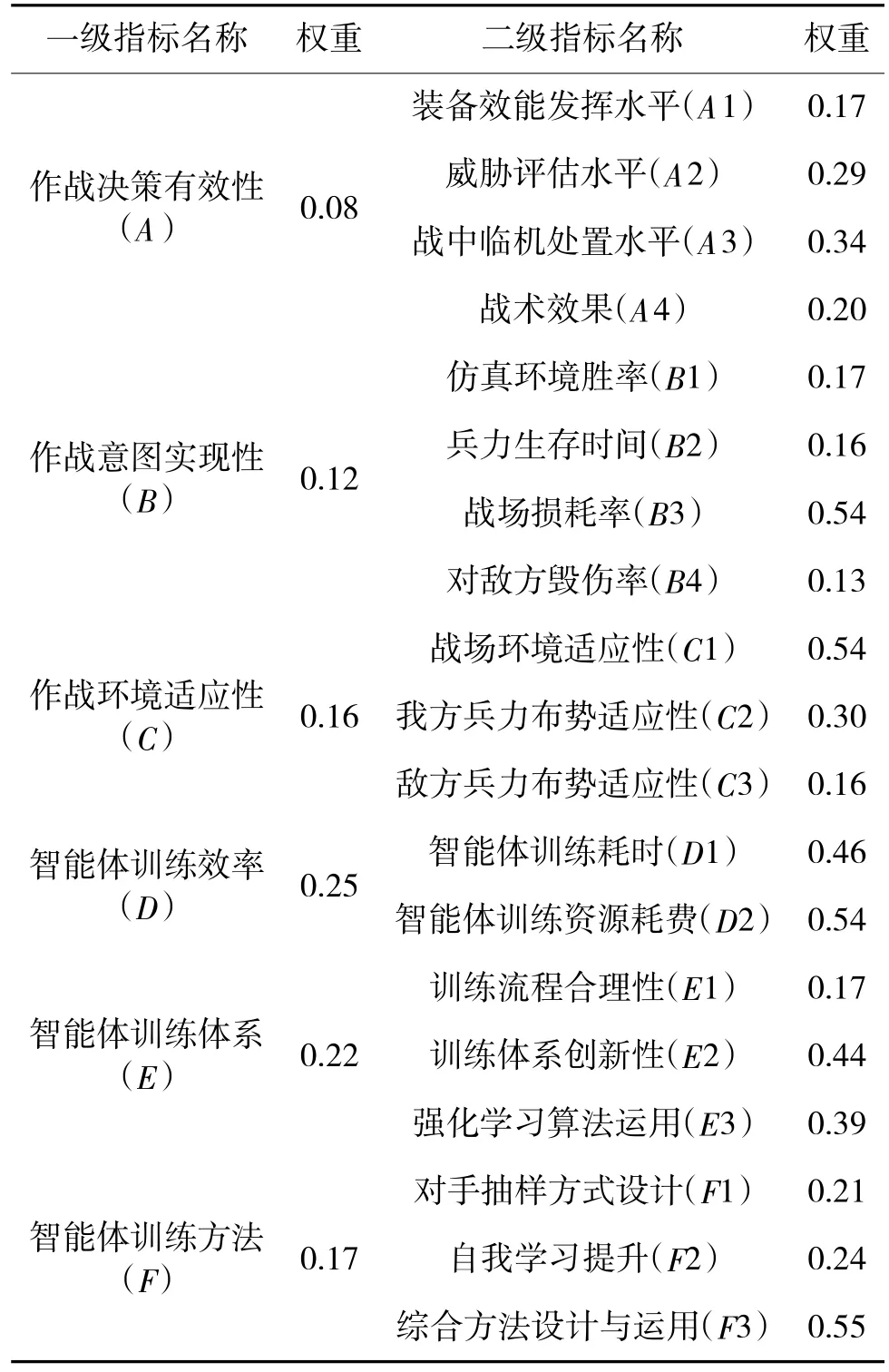
表3 各级指标权重Table 3 Weights of indicators at all levels
3.6 智能体决策效果评估与分析
根据现场演示情况,形成作战部门人员对6 个智能体效果的打分结果,各主观性指标满分以10分计(最高10 分,最低0 分,取整记录),具体如表4所示。
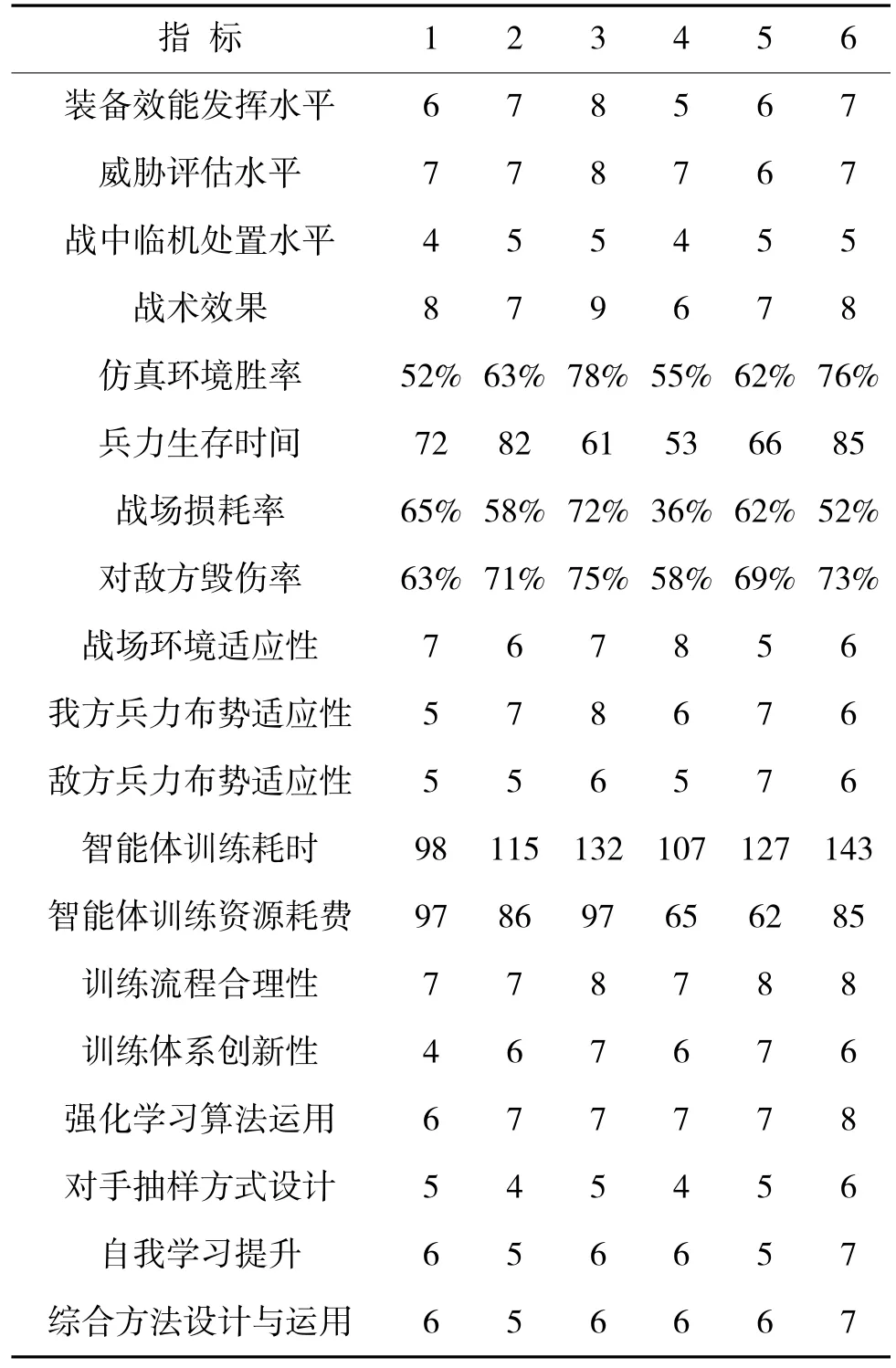
表4 各智能体指标得分及运行数据Table 4 Agents index score and operation data
采用TOPSIS 法,基于融合权重,对6 个智能体进行打分排序,结果如表5 所示。
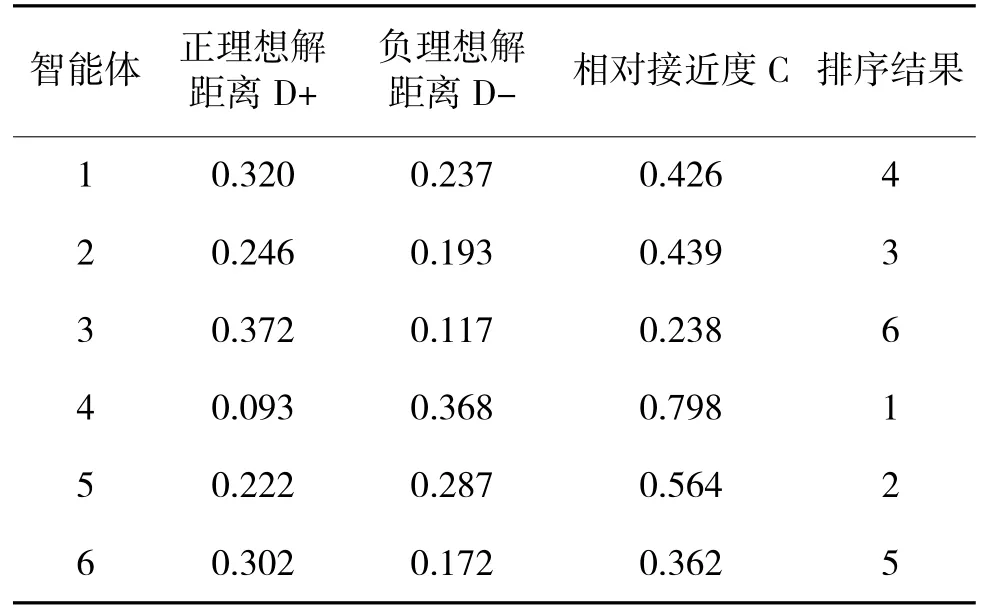
表5 基于融合权重-TOPSIS 法智能体评估结果Table 5 Agent evaluation results based on fusing weight-TOPSIS method
由排序结果可知,虽然在演示中智能体3 胜率最高,各项战术指标得分也较高,但其战损率也相对较高,且训练耗时和资源耗费均最高,毁伤率与战损率超过1∶1,属于“不惜一切代价达成决策目的”,行为较激进,因此,综合评分较低;智能体4 胜率水平不高,但毁伤率与战损率达到1.6∶1,能够有效消灭敌人,且训练耗时和资源耗费均处于较低水平,综合评价最好;智能体2、智能体5 胜率接近,但智能体5 在反映强化学习方法的多项指标得分比智能体2 高,且使用的训练资源最少,训练时间适中,性价比较高。智能体1 训练体系创新性和强化学习算法运用两项指标得分较低,且毁伤率与战损率比值小于1,决策效果整体发挥不明显,但受训练时长不足的影响,决策能力有待提升;智能体6胜率与智能体3 几乎相同,毁伤率与战损率达到1.4∶1,其余指标也较好,但其训练耗时最高,达到智能体4 的1.34 倍,在战时遇到新情况新态势需重新训练模型时,训练耗时高是严重短板,因此,评分相对较低。
综合各指标数据,通过使用主客观方法分别对不同类型指标进行量化赋权,权值融合后进行打分排序,得到的6 个智能体评价结果,使其既反映智能体的决策战术性能,又反映智能体训练客观情况,提高作战决策智能体效果评估的科学性。
4 结论
本文针对作战决策智能体评估这一问题,从战术、技术等不同维度,构建了涵盖作战决策有效性、作战意图实现性、作战环境适应性、智能体训练效率、智能体训练体系和智能体训练方法等6 个方面的评估指标体系,设计了基于AHP-CRITIC 和TOPSIS 的融合赋权评估方法,并对6 个作战决策智能体实例进行评估分析,得到下列结论:
1)融合赋权方法能够科学有效反映不同类别指标特点。通过使用AHP 和CRITIC 方法分别对主客观指标进行赋权,各权值内部独立,外部融合,使评估指标的权值科学性、合理性得到科学反映,为后续评估奠定了基础。
2)在融合赋权的基础上,通过使用TOPSIS 方法对6 个作战决策智能体效果进行评估,能够有效避免以往智能体评估时仅依靠胜率这个单一指标的局限。在充分利用权值信息的基础上,发挥原始数据作用,准确地反映出智能体决策效果的差距和优劣,综合筛选出更优秀的作战决策智能体。
3)由于作战决策智能体的评估涉及因素众多,既有人工智能技术发展牵引的客观指标,也有作战决策艺术反映的主观因素,是一个新颖又复杂的评价问题。本文仅以综合评估为切入点,对该问题的解决方法进行初步探索,在赋值方法的选取、评价排序方法的优化等方面仍需进一步探讨。
猜你喜欢
中国西部(2022年2期)2022-05-23
纺织科学研究(2021年9期)2021-10-14
南大法学(2021年6期)2021-04-19
活力(2019年15期)2019-09-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
测控技术(2018年6期)2018-11-25
质量与标准化(2015年9期)2015-07-10
浙江人大(2014年5期)2014-03-20
世界科学(2013年11期)2013-03-11
中国合理用药探索(2011年9期)2011-03-20
