
数字贸易对消费者行为的影响研究
2024-05-04 03:35徐晨旸
中国商论 2024年7期

摘 要:本文选取2022年抽样的淘宝数据进行分析与挖掘,并基于K-means算法对买家进行聚类分析,初步筛选出疑似刷单行为的买家和卖家。在剔除这些用户后,又利用回归分析法分析卖家获得评价、信用评价体系、卖家店铺等级对销量的影响;采用LSTM算法对销量数据的时间序列进行预测;通过Apriori关联规则算法找到买家与卖家和商品之间的关联。其中,在卖家获得评价对销量的影响中,建立奖励函数来描述好评和差评的影响,结果显示奖励函数与销量呈正相关关系。在信用评价体系对销量的影响中,服务和发货对销量的影响较大。卖家店铺等级,则无明显关系。预测的销量数据虽没有较好的结果,但给出了合理的解释。关联结果显示,买家与卖家和商品之间有一定的联系,本研究仅供参考。
关键词:数字贸易;数据挖掘;聚类分析;回归分析;时间序列;关联规则
本文索引:徐晨旸.<变量 2>[J].中国商论,2024(07):-085.
中图分类号:F063.2;F742 文献标识码:A 文章编号:2096-0298(2024)04(a)--04
随着科技的发展、移动互联网的普及和数据传输速率的提高,网络对人们生活的影响日益显著。越来越多的人习惯于网络购物,作为电商平台的佼佼者——淘宝,发展规模和电商数据可谓是惊人。过去十年,淘宝注册用户从2010的3.7亿上升至2022年的8亿。在此背景下,海量数据的背后有着不可估量的价值。如何挖掘、利用数据已成为各个行业、企业竞争的焦点。本文从数据预处理、数据挖掘、总结与展望,这三步来对2022年抽样的淘宝数据进行分析与挖掘。
1 数据预处理
1999年,Pyle首次提出并强调了数据预处理在数据挖掘过程中的重要性,并阐述了数据预处理过程在数据挖掘中占据了60%的时间[1]。
本文的参考数据来自四个文件,dsr.csv(以下简称四项评分表)、user.xls(以下简称卖家信息表)、trans.csv(以下简称详细交易表)、rate.txt(以下简称卖家评价表)。其中,参考数据是从2022年4月10日到2022年10月10日的抽样数据。
本文先进行了数据假设,再对上述四个文件进行了消除噪声、缺值数据处理、数据类型转换等四个操作[2]。数据预处理并不代表之后的数据不再处理,只是進行了初步的处理,而后对得到的疑似刷单行为的买家和卖家也进行了处理。
1.1 数据假设
本文做如下假设:
(1)详细交易表中买家购买的数量是一个整体,不考虑具体时间前后的影响,即先有了评价、四项评分,才有了卖家的销量。
(2)卖家评价表中的0代表卖家获得了中评,对其他买家的影响微乎其微,在考虑评价对销量的影响时,这部分数据予以剔除。
(3)由于抽样数据的不完整性,关联数据表之后,对有评价无销量或者空缺数据的数据,本文认为是系统原因造成的无效数据予以剔除。
(4)产品类型是影响消费者购买决策的一个不可忽视的因素[3]。在考虑评价对销量的影响时,忽略产品类型的影响,也不考虑搜索引擎以及广告等对销量的影响,只考虑评价这个单因素。
(5)买家只购买一位卖家或几位卖家的商品且购买的数量超过100将视为恶意刷单用户。
1.2 消除噪声
买家的四项评价指标为0到5的整数[4],本文将四项评分表中商品得分进行了四舍五入处理以消除数据收集过程中的系统误差。自此本文得到处理后的详细交易表。
1.3 缺值数据处理
由于四项评分表的四项评价指标(服务、发货、物流、商品得分)存在缺值,需要对其进行数据处理。常见的方法有:插值法、回归法、统计估计法等。该表中除物流得分缺值约占24.2%外,其他三项占比不高,服务得分缺值约占2.2%、发货得分缺值约占2.3%、商品得分缺值约占0.9%。对于缺少两项及以上的数据因为只占1.09%左右,本文予以剔除。本文将物流得分作为自变量y,其他三项作为因变量x1、x2、x3进行多元线性回归[6]。由实验结果可得,y=0.2479x1+ 0.5919x2+0.145x3,然后用此回归方程来填补只缺物流得分的记录条。F值为529030,P值近乎为0,说明回归的模型较好。自此本文得到处理后的四项评分表。
1.4 数据类型转换
根据淘宝卖家店铺20个等级,本文将卖家信息表中的等级替换成相应数字,如:1星级为1,1钻为6,1皇冠为11,2红冠为17。而本身信用得分为0的商家,售出的商品为0,予以剔除。信用得分小于等于3的商家替换成0[5]。自此本文得到处理后的卖家信息表。
2 数据挖掘
2.1 聚类分析
模式识别也叫模式分类,可以分为监督模式识别与非监督模式识别。本文根据样本特征将样本聚成几个类,使属于同一类的样本在一定意义上是相似的,而不同类之间的样本则有较大差异[7]。这种非监督模式识别也称为聚类。
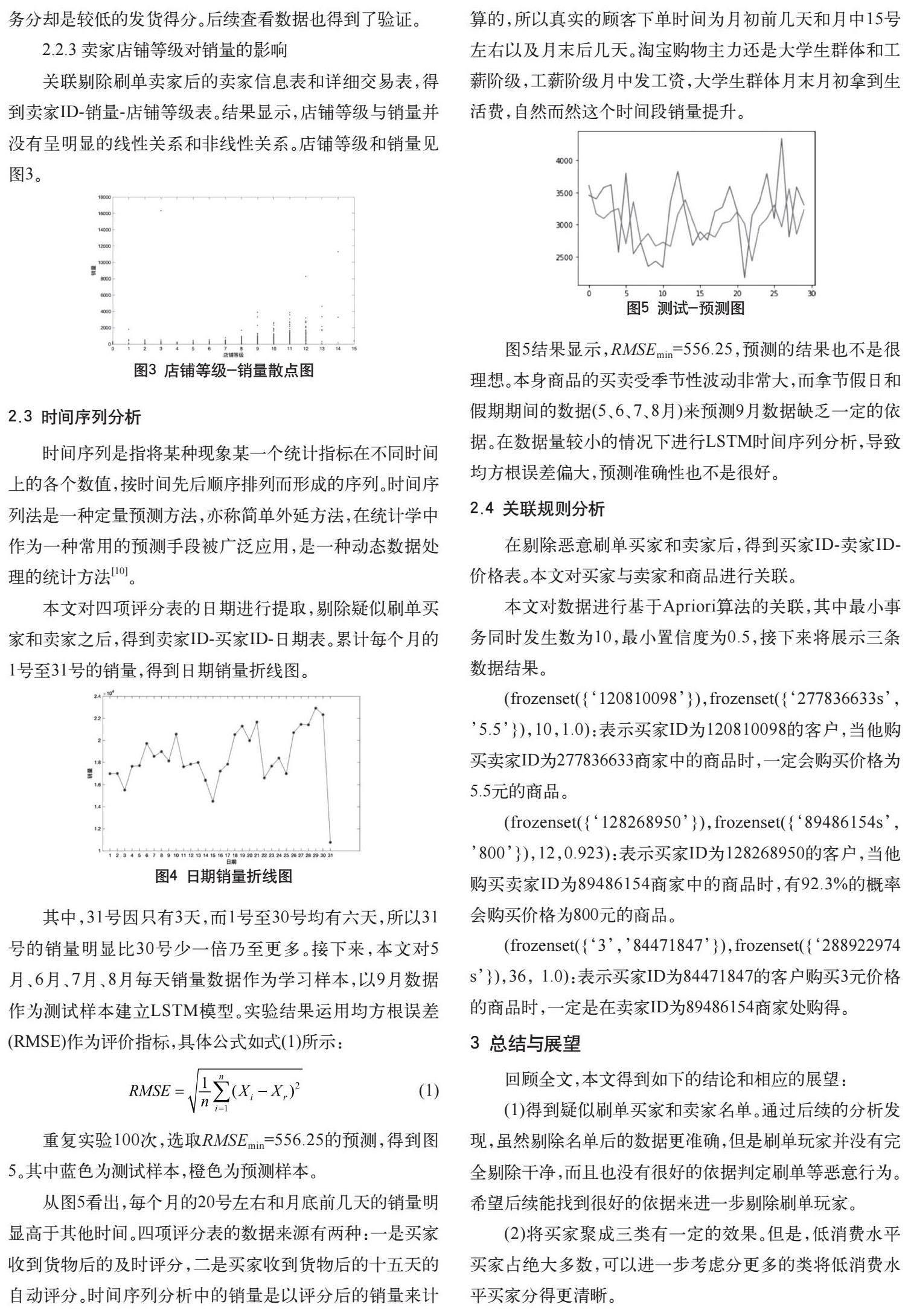
本文对详细交易表的买家、总费用、购买数量三列数据进行了聚类分析,旨在对买方网络进行分类,根据其消费水平大致分为三类:低、中、高消费水平。本文一共选取了637192位买家进行基于K-means的聚类分析。
图1 聚类结果
结果显示位为低消费水平,254位为中消费水平,6004位为高消费水平。其中蓝色、绿色、红色分别为低、中、高消费水平的质心。
2.2 回归分析
本文对数据进行说明,回归分析中的销量数据均指剔除刷单买家后详细交易表中买家购买的数量,而不是卖家信息表和详细交易表中的总销量。且本文假设,具体的时间前后对销量无影响。
2.2.1 卖家获得评价对销量的影响
剔除刷单卖家后,关联卖家评价表和详细交易表,剔除评价为0的数据后,发现部分数据,卖家获得了评价但是并没有销量,予以剔除。接下来,文章对8094位卖家进行分析。
对于好评和差评,本文建立简单的奖励函数g(ID,x1,x2) = a1x1+a2x2。其中,ID为卖家ID,x1为好评数量,x2为差评数量,a1+a2=1。若好评对销量的影响更显著,则x1>x2。
由于刷单以及恶意评价屡见不鲜,购物人群并没有那么在意口碑。鉴于此,本文假设好评和差评对销量的影响相同,即a1=a2=0.5,并算出每个卖家的奖励得分。最终,本文得到卖家ID-奖励得分-销量表。
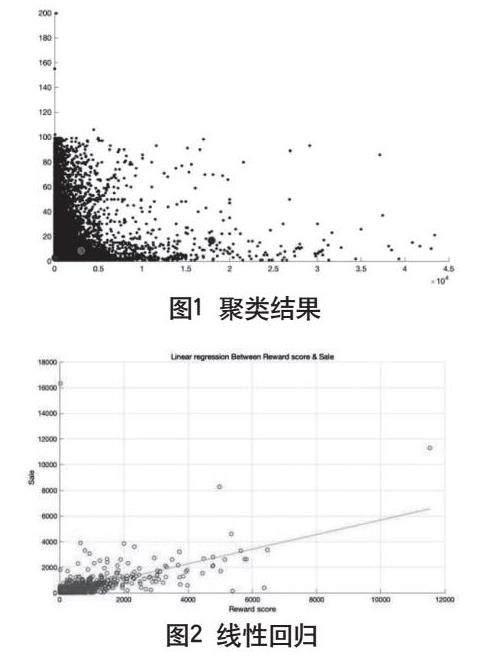
以奖励得分作为自变量,销量作为因变量进行线性回归分析,得到线性回归方程:y(销量)=5.8793+0.5694×奖励得分。线性回归图见图2。
图2 线性回归
方程通過F和T检验,R2为0.458。R2过小,存在着欠拟合的现象。接下来,对其进行多项式回归而R2反而减小。因此本文并没有对其修正,一方面疑似刷单卖家并没有剔除干净(异常点并不能完全剔除),另一方面卖家数量比较多,采样的数据不全而且分布并不理想。光从图像上观察,本文认为结果已在接受范围内了。
2.2.2 信用评价体系对销量的影响[8]
本文得到详细交易表所有卖家9264家的总销量和10842家卖家的平均四项信用评价体系。两者根据卖家ID关联得到7677名卖家ID-销量-服务-发货-物流-商品表。
当四项评分作为自变量,销量作为因变量进行回归分析时见表1,自变量都落入拒绝域。此时模型不是太好。
本文使用AIC法则来选择最优模型,得到最优的模型是将服务和发货得分引入模型。新方程通过F和T检验,得到回归方程:y(销量)=598.9469+30.4838×服务得分-146.3415×发货得分。从方程上来看,销量与服务呈正相关,与发货得分成反比。更好的解释是,有部分人觉得产品和服务并没有问题,于是产生了销量,发货和物流有一定的关系,很多人将两者混淆起来[9],并且发货和物流没有建立完整的体系,所以得分低很好理解。于是,有了销量、高服务分却是较低的发货得分。后续查看数据也得到了验证。
2.2.3 卖家店铺等级对销量的影响
关联剔除刷单卖家后的卖家信息表和详细交易表,得到卖家ID-销量-店铺等级表。结果显示,店铺等级与销量并没有呈明显的线性关系和非线性关系。店铺等级和销量见图3。
图3 店铺等级-销量散点图
2.3 时间序列分析
时间序列是指将某种现象某一个统计指标在不同时间上的各个数值,按时间先后顺序排列而形成的序列。时间序列法是一种定量预测方法,亦称简单外延方法,在统计学中作为一种常用的预测手段被广泛应用,是一种动态数据处理的统计方法[10]。
本文对四项评分表的日期进行提取,剔除疑似刷单买家和卖家之后,得到卖家ID-买家ID-日期表。累计每个月的1号至31号的销量,得到日期销量折线图。
图4 日期销量折线图
其中,31号因只有3天,而1号至30号均有六天,所以31号的销量明显比30号少一倍乃至更多。接下来,本文对5月、6月、7月、8月每天销量数据作为学习样本,以9月数据作为测试样本建立LSTM模型。实验结果运用均方根误差(RMSE)作为评价指标,具体公式如式(1)所示:
重复实验100次,选取RMSEmin=556.25的预测,得到图5。其中蓝色为测试样本,橙色为预测样本。
从图5看出,每个月的20号左右和月底前几天的销量明显高于其他时间。四项评分表的数据来源有两种:一是买家收到货物后的及时评分,二是买家收到货物后的十五天的自动评分。时间序列分析中的销量是以评分后的销量来计算的,所以真实的顾客下单时间为月初前几天和月中15号左右以及月末后几天。淘宝购物主力还是大学生群体和工薪阶级,工薪阶级月中发工资,大学生群体月末月初拿到生活费,自然而然这个时间段销量提升。
图5 测试-预测图
图5结果显示,RMSEmin=556.25,预测的结果也不是很理想。本身商品的买卖受季节性波动非常大,而拿节假日和假期期间的数据(5、6、7、8月)来预测9月数据缺乏一定的依据。在数据量较小的情况下进行LSTM时间序列分析,导致均方根误差偏大,预测准确性也不是很好。
2.4 关联规则分析
在剔除恶意刷单买家和卖家后,得到买家ID-卖家ID-价格表。本文对买家与卖家和商品进行关联。
本文对数据进行基于Apriori算法的关联,其中最小事务同时发生数为10,最小置信度为0.5,接下来将展示三条数据结果。
(frozenset({‘120810098}),frozenset({‘277836633s, 5.5}),10,1.0):表示买家ID为120810098的客户,当他购买卖家ID为277836633商家中的商品时,一定会购买价格为5.5元的商品。
(frozenset({‘128268950}),frozenset({‘89486154s, 800}),12,0.923):表示买家ID为128268950的客户,当他购买卖家ID为89486154商家中的商品时,有92.3%的概率会购买价格为800元的商品。
(frozenset({‘3,84471847}),frozenset({‘288922974 s}),36, 1.0):表示买家ID为84471847的客户购买3元价格的商品时,一定是在卖家ID为89486154商家处购得。
3 总结与展望
回顾全文,本文得到如下的结论和相应的展望:
(1)得到疑似刷单买家和卖家名单。通过后续的分析发现,虽然剔除名单后的数据更准确,但是刷单玩家并没有完全剔除干净,而且也没有很好的依据判定刷单等恶意行为。希望后续能找到很好的依据来进一步剔除刷单玩家。
(2)将买家聚成三类有一定的效果。但是,低消费水平买家占绝大多数,可以进一步考虑分更多的类将低消费水平买家分得更清晰。
(3)本文建立的奖励得分与销量呈线性正相关关系,奖励得分越高,销量越高。R方太小,模型存在欠拟合现象,后期应进一步对恶意刷单行为进行剔除。如今,口碑影响力越来越大,差评占的比重也越来越大,商家更应该提高商品质量以减小差评在评价中的比例来提高奖励得分,最终影响销量。
(4)服务得分和发货得分分别与销量成正比和反比。大家对四项评分太过于武断、主观,甚至存在较多的缺失数据。对于淘宝,应该建立更加完善和激励的四项评分体系。对于商家,应该提升服务水平。
(5)店铺等级与销量并没有呈明显的线性关系。淘宝店铺等级就呈现两头少中间多的规律。那时的买家也未过分关注店铺等级信息,导致分析的结果并没有明显的关系。
(6)时间序列分析的预测效果并不是很好。样本量不够多,且商品的交易受季节性波动较大,对更大的样本量可能会有较好的预测结果。
(7)实现买家与卖家和商品之间的关联,可以给用户推送相关联的卖家店铺的动态和推荐同价位的商品,以提高客戶满意度。本文并没有实现推荐算法,希望后续能将关联的结果与推荐算法相结合,以实现对买家集店铺、商品类型、价格于一体的推荐功能。
参考文献
郑跃平. 基于约束数据预处理的Web日志挖掘研究[D].福州: 福州大学,2006.
张治斌,刘威.浅析数据挖掘中的数据预处理技术[J].数字技术与应用,2017(10):216-217.
薛文怡. 电子商务在线口碑与观察性学习对产品销售的影响[D].天津: 河北工业大学,2016.
庞鑫. 基于演化博弈的淘宝网动态评分对卖家销量的影响研究[D].济南: 山东大学,2018.
小狼.五六折 全新的返利模式[J].电脑迷,2010(20):79.
刘锋,谭祥勇,何卓.函数性线性回归模型分析方法及其应用[J].重庆理工大学学报(自然科学),2015,29(11):135-138.
颜子寒,张正军,王雅萍,等.基于加权马氏距离的改进深度嵌入聚类算法[J].计算机应用,2019,39(S2):122-126.
韩旭芳. 基于开放API的电子商务个性化服务推荐研究[D].石家庄: 石家庄铁道大学,2011.
Sakurai Y , Papadimitriou S , Faloutsos C . BRAID: Stream mining through group lag correlations[C]// Proceedings of the ACM SIGMOD International Conference on Management of Data, Baltimore, Maryland, USA, June 14-16, 2005. ACM, 2005.
杨青,王晨蔚.基于深度学习LSTM神经网络的全球股票指数预测研究[J].统计研究,2019,36(3):65-77.
猜你喜欢
新财经(2019年8期)2019-06-27
北方经济(2019年4期)2019-04-20
社会科学(2019年3期)2019-03-29
价值工程(2019年3期)2019-02-18
中学课程辅导·教师教育(上、下)(2016年19期)2016-12-07
商(2016年32期)2016-11-24
软件工程(2016年8期)2016-10-25
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
企业导报(2016年8期)2016-05-31
