
一种基于词袋模型的大规模图像层次化分组算法
2014-11-08 06:58刘培桢姜文涛周锋飞
应用光学 2014年5期
钱 钧,杨 恒,刘培桢,姜文涛,周锋飞
(西安应用光学研究所,陕西 西安710065)
引言
随着光电技术和互联网的高速发展,人们可以很容易地获取大规模场景的图像数据,因此从大规模图像集合去恢复三维场景结构的需求和应用也就应运而生[1-4]。但是由于获取图像的传感器参数不同,拍摄视场和角度不同,图像集合中不但包含多个不同场景内容的图像,还包含噪声污染、模糊抖动甚至错误图像。因此,对杂乱无序的图像集合进行预处理,将内容关联的图像进行分组,不但有助于用户快速组织和掌握图像内容,也是场景三维重建的前提条件和关键步骤。但是在无序宽基线条件下,如何进行高效的图像分组是一项极具挑战的任务。
许多学者根据不同的应用提出了各种各样的图像分组算法。常用的思路是先在图像集合中进行两两图之间的特征匹配,求出图像间的相似度度量,再根据相似性度量矩阵对图像进行分组合并。美国华盛顿大学和微软联合开发的Photo Tourism[1]系统是一个基于大规模图像的3D重建和浏览系统,该系统可以对输入图像自动分组,并在组内进行摄像机标定和3D场景的重建。Photo Tourism系统的分组算法也是采用一种穷尽匹配策略,首先对每两幅图像之间用最近邻搜索算法进行特征点匹配,生成一个以图像为节点,以图像间匹配数量为权重的全连通图;然后,将匹配特征数量小于阈值的图像连接关系断开,得到最终的图像连接分组关系。Simon等人[2]在获得所有图像对间精确特征匹配的基础上,借鉴聚类思想构造目标函数,采用迭代优化该目标函数的方法对图像数据库进行分组聚类。Zheng等人[3]以图像中的目标区域为单元,构造出一个区域连接图。最后,采用汇聚聚类算法(agglomerative clustering)将这些目标区域进行聚类,从而得到图像之间的分组聚类。Zeng等人[4]提出了一种利用模拟退火优化算法进行图像分组的策略,通过构造目标函数,并采用模拟退火优化算法求解该目标函数的极值,以完成图像分组。Kang等人[5]则是针对大规模图像集合先建立一个图像样本空间,并在这个空间中定义了全局的索引特征。这样每幅图像在样本空间中,按照是否包含全局索引特征表示为一个二进制序列;然后,利用信息熵理论对二进制序列进行聚类。Chum等人[6]则采用随机数据挖掘技术来进行图像分组,其核心算法是先随机找出一些图像作为种子,采用最小哈希算法找出他们的闭集作为一个分组;然后再在剩余的图像中找图像种子,进行哈希索引进行分组,直到所有的图像都进行了分组。Chen等人[7]则通过对图像中提取的特征进行分析,找出最具区分力的特征集合,然后通过这些特征找出最具代表性的图像,再以这些代表图像去和数据集合中的其他图像进行匹配,从而完成整个图像集合的聚类。
已有的这些分组算法都是通过两两图像间的最近邻特征匹配,或者是利用全局特征聚类对图像进行分组,当图像规模很大时,这些算法的时间复杂度都非常高,不利于实际应用。针对这个问题,有学者使用并行计算GPU技术对计算流程进行加速[8]。而本文则从算法设计角度出发,提出了一种层次化的图像分组算法,目的是增加分组准确性的同时提高分组速度。首先,采用词袋模型(bag-of-words,BOW)对杂乱无序的图像集合进行粗分组。BOW算法早期是用来文档搜索的,后被研究人员引入到图像搜索领域[9-11]。对一幅参考图像,通过BOW算法可以非常快速地从大规模数据库中找出与这幅图像内容相似的图像。BOW算法的关键是要把一幅图像根据其提取出来的特征向量集合,映射为一个超高维的视词向量(visual word vector)。这样,图像与图像之间的相似性度量就转换成视词向量之间的相似性度量了。为了减少视词向量的量化误差,本文提出了一种多路量化(multiple paths quantization,MPQ)方法,可以有效减少量化误差,从而提高图像粗分组的准确性。然后,对每一个类别,再使用特征匹配方法,并引入一种仿射不变量(面积比)的约束条件,来去除那些明显不满足条件的错误匹配,以增加特征匹配精度,从而可以获得更加精细化的图像分组结果。
1 基于视词向量的粗分组
基于BOW模型的图像间相似度计算方法,并不是直接使用图像中的特征向量匹配作为图像间相似度度量,而是将这些特征量化到一个超高维的视词向量空间,每一幅图像对应一个视词向量,而相似的图像具有相似的视词向量。在搜索过程中使用倒排文件(inverted file)数据结构来存储图像的视词向量,计算图像间相似度,可以大幅度提高图像检索的效率。然而,这类算法由于特征量化造成的信息损失较大,使得图像间相似度的准确性较低。
图1是采用字典树算法[9]进行特征量化时,在树的某一层上产生量化误差的原因。点A到D表示聚类中心,点1,2,3表示待量化的特征向量,实线表示聚类中心A到D定义的边界。特征点1,2,3由于彼此近邻,本应该被量化至同一个叶子节点上,即在当前层应该被分配到同一个节点,但是按照字典树的量化规则,它们被分配到了不同节点,最终导致它们会有不同的量化结果。

图1 字典树产生量化误差示意图Fig.1 Quantization error caused from lexicographic tree
本文提出一种多路量化算法(multiple paths quantization,MPQ)来进行特征量化,以减少量化误差的影响。MPQ算法的具体步骤见算法1,在每一层不是只选择一个最近邻节点,而是选择M个最近邻节点,在下一层通过比较k×M个聚类中心再选出M 个最近邻节点,直到叶子节点所在的层,最后选出一个最近邻节点作为量化结果,具体过程见算法1。MPQ算法通过增加候选节点个数M(M>1),在一定程度上减小了量化误差的风险,从而提高了量化精度。

算法1 MPQ量化算法
在特征量化后,每幅图像便映射成视词空间的一个高维向量,再用倒排文件组织视词和图像之间的映射关系,这样可以快速地计算视词向量之间的距离,得到图像间的相似度。两两图像之间的相似度可以表示为相似度矩阵Mn×n的形式。获得矩阵Mn×n是非常高效的,在本文的实验中,对于n=1 249幅图像只需要2s就可以计算得到相似度矩阵中的所有数值。
最后,采用视图-生成树算法对矩阵所表示的加权图进行分割,先将两幅相似度最高的节点(图像)加入树,然后加入一幅和树中已有节点相似度最高的节点,直到再没有余下的节点和树中节点相似度超过给定阈值,这样就生成了一棵树。将这棵树的节点从整个图像节点中移除,在剩下的节点集合中重复这个过程,直到数据节点集合为空,或者再也找不出两幅图像节点之间相似度大于给定阈值为止。这样生成的这些树就是对整个图像集合的划分,一棵树就是一个分组结果,而将那些独立的节点视为污染图像,系统将自动去除它们。
2 基于仿射不变量约束的细化分组
为了进一步提高图像分组的准确性,还需要对每个分组进行更加精细化的处理。这时候可以利用特征向量匹配来提高图像间相似性度量,因为特征向量所包含的信息要比其量化值丰富得多,但是特征向量间的最近邻搜索的效率较低,系统响应时间过长。
本文提出的方案是首先利用前面步骤中的量化结果来进行特征匹配;然后,给出了一种利用仿射不变量(面积比)的约束条件去除误匹配的方法。首先,特征之间的初始匹配由量化结果决定,即认为具有相同量化值的特征之间是匹配的。算法2给出了具有相同量化值的特征匹配的实现细节。接着,利用面积比这个仿射不变量进一步去除误配,算法3给出这一步骤具体实现的细节。去除误配后,剩余的内点数量可以作为图像间增强的相似度度量。最后,再次使用最小生成树算法对组内图像重新分割。精细分组过程使得原来的粗分组结果更加准确和细致,其结果是:可能会去除组内那些相似度低的图像,也可能改变原先组内图像间连接拓扑关系,甚至会将原来的分组关系再次分割成更加精细的小组。

算法2 对于量化结果是第i个视词的特征匹配算法

算法3 仿射不变量约束
3 实验结果与分析
本文从互联网站上按照搜索关键词自动下载大量图像集合,设计了一个图像集合的自动分组系统,该系统不但可以使用户方便自动有效管理下载的大量无序图像集合,建立集合间的分组关系和集合内的排序关系,还能够为下一步的场景三维重建提供数据支撑。使用到的数据库是从图像共享网站Flickr上下载的1 249幅关于西安钟楼(Bell-Tower)的图像数据库。实验在普通PC机环境上运行,其配置是Intel双核CPU E6750@2.66GHz和2 G内存。算法程序采用VC6.0编写。
3.1 Bell-Tower数据库分组结果及分析
Bell-Tower数据库包含1 249幅图像,部分图像见图2所示。可以看出,这样一个数据库包含不少污染图像,例如许多游客把在钟楼附近的商店里所拍摄的图像上传到网站上后,也会把图像标记为Bell Tower。

图2 Bell-Tower数据库中的部分图像实例Fig.2 Image examples from Bell-Tower database
从整个数据库中一共提取出867 352个SIFT图像特征点,使用这些特征训练了一个5层10分支的字典树,然后先进行粗分组,共有293幅图像被系统当作污染图像去除,将保留下来的956幅图像分成14个组。图3(a)给出了一个粗分组的示例。在精细分组阶段,对每个组内的图像采用增强的相似度准则重新分组,其结果可能是一些弱相关的图像被系统排除,或者是组内生成树的连接关系被重新确定,甚至会划分出更加精细的分组。图3给出一个粗分组被重新分割成2个更加精细分组的例子。图3(a)中的图像看上去彼此相似,因为它们都包含楼塔、房屋和街道这些景物。但实际上这些图像包含了两个不同的场景。精细分组结果如图3(b)和3(c)所示,在组3(b)中出现的楼塔建筑实际上是西安市中心的鼓楼,而出现在组3(c)中的塔楼建筑才是钟楼,这两个建筑以及周边环境确实有些类似。
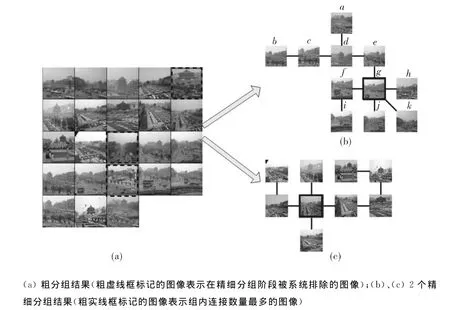
图3 粗分组结果被划分成2个更加精细分组Fig.3 Two refined groups divided from coarse grouping results
在精细分组阶段之后,一共有874幅图像被保留下来,共分成17个组别。图4给出其中5个分组的部分图像例子。为了评价提出算法的分组性能,预先采用手工的方法对图像集合进行了标记。标记方法对拍摄钟楼建筑的不同方位、不同的街道视景,甚至拍摄时间是白昼还是黑夜都进行了区分。这些标记可以用来评价系统的分组性能。图5给出了系统不同阶段,图像分组的查准率-查全率(precision-recall)曲线。可以看出,精细分组过程确实可以显著提高粗分组精度,同时在精细分组阶段,使用约束条件比不使用约束还能获得更高的分组精度。

图4 层次化分组算法在Bell-Tower数据库上的5个分组结果Fig.4 5 grouping results of Bell-Tower database by hierarchical grouping algorithm

图5 在不同阶段图像分组的查准率-查全率曲线比较Fig.5 Contrast of precision-recall curves in different image grouping stages
3.2 约束条件有效性验证
表1列出了对应图3(b)连接关系中图像对间特征匹配结果。图像之间的单对应矩阵采用RANSAC鲁棒估计算法进行估计,并作为验证特征间是否匹配的依据:如果投影误差小于或者等于3个像素,则认为特征之间匹配关系正确。从表1中可以看出,仿射不变量约束可以有效地去除误匹配,虽然这种弱约束条件也同时去除了少量正确匹配,但是特征匹配的精度得到了较大地提高,这有利于提供更加准确的图像相似度度量,从而获得性能更优的图像分组结果。另外,图6给出一个特征匹配的例子,可以看出上述约束明显地去除了许多误匹配。

表1 使用约束前后的特征匹配结果Table 1 Results of feature marching before and after using constraints

图6 使用仿射不变量约束去除错误特征匹配Fig.6 Removing incorrect feature marching by using affine invariant constraint
4 结论
针对大规模无序图像的自动分组应用,本文提出了一种层次化图像分组聚类算法。先采用词袋模型对无序图像集合进行粗分组;然后,在粗分组基础上,采用特征向量匹配的方法,获得图像之间更精确的相似度,从而完成图像集合的精细分组。实验结果表明,本文算法能够快速去除图像集合中大量的与内容无关的污染图像,并按照数据集合中不同图像场景内容对图像集合进行准确划分,同时还完成了图像组内的特征级匹配,这不但能够帮助用户迅速掌握图像集合内容,还可以为后续大规模场景的三维重建工作提供有效的基础数据。
[1] Snavely N,Seitz S,Szeliski R.Photo tourism:explo-ring photo collections in 3D[J].ACM Transactions on Graphics,2006,25(3),835-846.
[2] Simon I,Snavely N,Seitz S M.Scene summarization for online image collections[C]//In Proceedings of the International Conference on Computer Vision.USA:IEEE,2007:1-8.
[3] Zheng Y,Zhao M,Song Y,et al.Tour the world:building a web-scale landmark recognition engine[C]//In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Miami,USA:IEEE,2009:1085-1092.
[4] Zeng X,Wang Q,Xu J.Map model for large-scale 3dreconstruction and coarse matching for unordered wide-baseline photos[C]//In Proceedings of British Machine Vision Conference.Leeds,UK:BMVC Press,2008.
[5] Kang L,Wu L,Yang Y H,A novel unsupervised approach for multilevel image clustering from unordered image collection[J].Frontiers of Computer Science in China,2013,7(1):69-82.
[6] Chum O,Matas J.Large-scale discovery of spatially related image[J].IEEE Transactions on Pattern A-nalysis and Machine Intelligence,2010,32(2):371-377.
[7] Chen Xu,Das M,Loui A.An efficient framework for location-based scene matching in image databases[J].International Journal of Multimedia Information Retrieval,2012,1(2):103-114.
[8] Johnson T,Georgel P F,Raguram R,et al.Fast organization of large photo collections using CUDA[C]//European conference on Trends and Topics in Computer Vision.Pennsylvania.USA:Pennsylvania State University,2012:463-476.
[9] Nistér D,Stewénius H.Scalable recognition with a vocabulary tree[C]//In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.New York:IEEE,2006,2161-2168.
[10] Wang C Q,Zhang B C,Qin Z C,et al.Spatial weighting for bag-of-features based image retrieval[C].USA:Lecture Notes in Computer Science,2013:91-100.
[11] Wang F,Wang H,Li H,et al.Large scale image retrieval with practical spatial weighting for bag-of-visualwords[C].USA:Advances in Multimedia Modeling Lecture Notes in Computer Science,2013:513-523.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
铁道通信信号(2019年6期)2019-10-08
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
小学生导刊(低年级)(2017年1期)2017-06-12
雷达学报(2017年6期)2017-03-26
高中生学习·高三版(2016年9期)2016-05-14
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
