
基于特征选择技术的情感词权重计算
2016-10-10 08:20吴金源冀俊忠赵学武吴晨生杜芳华
北京工业大学学报 2016年1期
吴金源,冀俊忠,赵学武,2,吴晨生,杜芳华
(1.北京工业大学计算机学院多媒体与智能软件技术北京市重点实验室,北京 100124;2.南阳师范学院软件学院,河南南阳 473061;3.北京市科学技术情报研究所,北京 100048)
基于特征选择技术的情感词权重计算
吴金源1,冀俊忠1,赵学武1,2,吴晨生3,杜芳华1
(1.北京工业大学计算机学院多媒体与智能软件技术北京市重点实验室,北京 100124;2.南阳师范学院软件学院,河南南阳 473061;3.北京市科学技术情报研究所,北京 100048)
在文本情感分析中,情感词典的构建至关重要,然而目前这方面的研究大多集中在简单的词语极性判别上,有关情感词的权重赋值研究较少,且已有的权重赋值方法基本上都需要人工辅助来选取基准词,这给实际应用带来很大的困难.针对此问题,提出了一种自动的基于特征选择技术的情感词权重计算方法.首先提出了词语情感权重与文本情感倾向的相关假设;然后针对情感分类,结合二元分类的特性改进了信息增益(information gain,IG)和卡方统计量(chi-square,CHI),将特征选择技术应用于情感词权重计算.实验结果表明:将计算所得的带情感权重的情感词库用于文本情感分类能够提升分类精度.
文本情感分类;情感词典构建;特征选择;权重计算
当今越来越多的网民喜欢在各种网络平台上发表言论,对商品、电影、新闻事件等表达主观看法,言论中包含的信息量越来越大.这些评论中包含了诸如肯定或是否定的情感信息,其中蕴涵着一些潜在价值.面对这样的情感文本信息,基于主题的传统分类技术已不能有效地对其进行挖掘,于是情感分析(sentiment analysis)应运而生了.
文本情感分类是情感分析的一个研究热点,它将倾向积极、肯定和赞扬等正面的文本看作正例,将倾向消极、否定和批评等负面的文本看作负例,对于词语的情感判别同样如此.文本情感分类的主要研究途径有2种[1]:基于情感信息统计的分类和基于机器学习的分类.无论采用哪种途径,由于文本组成的最小粒度是词,因此充分利用词语的情感极性信息对提高文本情感分类精确度至关重要.可见,情感词典构建是一个相当基础而且重要的工作.目前有关情感词库构建的研究比较多,研究的思路主要有3种.
一是基于语料的方法.该方法主要是基于一个大的语料库,对词语进行统计分析,从而挖掘出词的极性特征.具体的流程是:首先根据人工判定的一些正面词和负面词来设置一些基准词;然后基于充分大的语料或者是网络搜索引擎,统计非基准词和基准词的共现信息并计算它们的相似度;最后根据相似度判别一个词的正负极性.点互信息(point mutual information,PMI)[2]是其相似度计算的最经典的方法.例如,朱嫣岚等[3]通过计算待定词汇和HowNet中已标注正负极性的词汇间的相似度来确定待定词汇的极性.徐琳宏等[4]构建的中文情感词汇本体库[4]基于PMI计算词语的情感程度.该方法首先人工选取一些带情感程度(分为5个等级)的基准词,然后基于语料集计算待定词和每个基准词的PMI值,将其中与之互信息PMI值最大的基准词的程度作为待定词的情感程度.
二是基于语义词典的方法[5].它以现有的语义词典(中文主要是HowNet和同义词林,英文主要采用WordNet)为基础,先利用同义词等信息计算词语之间的相似度,再判别词语的正负极性.如柳位平等[6]以HowNet情感词语集为基准,从中选取褒贬明显的词作为基准词,采用知网的语意相似度计算公式计算待定词汇和基准词之间的相似度,从而确定词语的极性和权重.Esuli等[7-8]利用WordNet语言资源,定量分析确定了每个词在不同注释下的正负情感及权值,构建了情感词典SentiWordnet.
三是结合前2种思路的混合方法.如周咏梅等[9]提出了一个SLHS构建过程,首先收集并整理几个常用的情感词库;其次利用HowNet获取中文情感词的英文词语义元组,并通过文献[7]构建的SentiWordNet查询每个英文义元的同义词集合;然后求取这些同义词集合的平均情感程度,作为每个义元的情感权重;最后计算每个中文情感词对应的义元组的平均权重,即得到了最终的中文情感词的情感权重.
上面的方法大都是需要人工选取基准词和赋权值,结果不具有稳定性,而且没有充分利用训练集文本的情感信息.常用的基于统计的特征选择方法一般会对特征进行评价和排序,以反映特征的重要程度.因此,文本提出了一种不需要设置基准词,基于特征选择技术的情感词权重计算方法.在分析情感词情感程度与文本情感倾向关系的基础上,针对情感分类对特征选择方法信息增益(information gain,IG)和卡方统计量(chi-square,CHI)作了一些改进,并将之应用于情感词权重计算.最后的实验结果表明,利用此方法计算所得的带情感权重的情感词库有利于情感分类,能够提升分类精度,因此文中提出的方法是合理有效的.
1 相关工作
1.1特征选择方法
特征选择是一种常用的维数约减方法,它根据特征的重要度从原始特征集中选取最重要的特征,是文本分类的一个预处理过程.为了介绍方便约定如下符号:t为特征;{c1,…,ci,…,ck}为类别集合;k为训练集的类别数;A为出现特征t且属于类别ci的文档数;B为出现特征t但不属于类别ci的文档数;C为不出现特征t但属于类别ci的文档数;D为不出现特征t且不属于类别ci的文档数;N为训练集中总的文档数,N=A+B+C+D.
1.1.1文档频率
文档频率(document frequency,DF)[10]方法的基本思想是:统计计算每个词的文档频率值,根据预先设定最小文档频率值和最大文档频率值来去除和保留特征,如果特征t的文档频率值在最小和最大阈值之间,则保留t,否则去掉.
这种方法实现起来比较简单,适用于大规模数据集,但是最小阈值可能设定得不合理,并且低频词不全是噪音词,导致一些包含类别信息的重要特征被去除,会影响分类性能.
1.1.2信息增益(IG)
IG[11]能够度量特征包含类别信息的多少,一个特征词的信息增益为该特征出现前后的信息熵之差,通常会对某一文档、类别或是整个数据集来计算.根据IG方法的定义,特征的信息增益越大,表示该特征对于分类越重要.
针对某个具体的类别ci,特征t的信息增益为
1.1.3卡方统计量(CHI)
CHI[10]能表征2个变量间的相关性,兼顾特征存在与不存在时的情况.根据CHI的定义可知,特征与类别的CHI值越大,这个特征就越重要.
对于某个具体类别ci,特征t的CHI统计值为
特征t对于整个训练集的CHI值的计算方式有2种:根据特征与每个类别的CHI值,一是计算其与所有类别的加权平均值,二是计算其最大值.2种计算公式为
基于统计的特征选择方法还有很多,如互信息(mutual information,MI)、期望交叉熵(expected cross entropy,ECE)、几率比(odds ratio,OR)和基尼指数等.
1.2情感词典构建方法
1.2.1基于语料库的方法
这里主要介绍基于PMI的方法,它是一种经典的利用语料库的方法.互信息能够刻画2个变量之间的相关性,假设有2个特征word1和word2,它们之间也可以计算互信息值,此时称为点间互信息,记为PMI(word1,word2),计算公式为
其中:P(word1)和P(word2)分别是word1和word2单独出现的概率;P(word1&word2)是词语word1和word2共同出现的概率.PMI(word1,word2)越大,word1和word2相关性越强.基于PMI计算并判别词语极性的方法称为语义取向点互信息(semantic orientation point mutual information,SOPMI).该方法首先从词库中选取一些有代表性的词作为基准词,其中包含等数量的n个正面词poswords(词语记为Pwordi,i∈[1,n])和n个负面词negwords(词语记为Nwordi,i∈[1,n]).
对于一个特征词 word,它的 SO-PMI计算公式为
词语的极性判定规定如下:
SO-PMI(word)>0时,词语word为正面词;
SO-PMI(word)=0时,词语word为中性词;
SO-PMI(word)<0时,词语word为负面词.
此外,词语的SO-PMI值还常被用于度量情感词的情感程度.
1.2.2基于语义词典的方法
基于HowNet的词语极性判别方法是一种基于电子词典的方法,同上面的方法类似,也是计算特征词与基准词之间的相似度来判别极性.不同的是,基于PMI的方法是基于语料统计词语共现来计算的,而此方法是基于一个现有的语义词典来实现的.知网是清华大学创建的一个很大的知识体系,在2007年开始发布“情感分析用词语集beta版”,总共有17 887个词.这个词典被广泛应用于情感分析工作.
WordNet是一种基于认知语言学的英语词典,按照单词的意义组成了一个“单词的网络”,是一个覆盖范围宽广的英语词汇语义网.名词、动词、形容词和副词各自被组织成一个同义词的网络,每个同义词集合都代表一个基本的语义概念,并且这些集合之间也由各种关系连接.
1.3文本情感分类算法
1.3.1简单的情感分类方法
简单的基于情感词极性累加的方法(naive andsentiment words polarity accumulation based algorithm,NP),是一种无监督的方法,其主要思想是:首先依据已有的情感词库对测试文本进行分词处理,文本用词组成的向量来表示.
假设文本为d,词为wordi,那么d=(word1,…,wordi,…,wordh),词的正负极性值为Valuei∈{1,-1}.一个词的极性值为1,表示词为正面词,否则相反.文本d的倾向函数f定义为
文本的极性判定规定如下:
f(d)>0时,文本d为正例;
f(d)≤0时,文本d为负例.
1.3.2朴素贝叶斯情感分类算法
朴素贝叶斯情感分类算法(naive Bayesian cate gorization algorithm,NB)[12]是一种依赖训练集的方法.该方法利用情感词在正向和负向类训练语料中出现的频率作为情感词出现的概率,最后用最大后验概率确定待判别文档的极性.
假设 d为带判别文档,d由特征词{t1,…,tj,…,th}组成.根据贝叶斯准则可以得到文档d属于类别ci的后验概率为
式中:ci∈{+,-};+表示正向类别;-表示负向类别;P(ci)为类别ci文档数占训练集的比例.对于每个类别,P(d)在式(9)中是一个定值,关键在于P(d| ci)的计算.为了简化计算,该方法假定每个特征对分类的影响独立于其他特征,所以 P(d|ci)=可以采用下面的公式进行估算:
依次计算文档d属于每个类别的概率,那么依据贝叶斯决策理论可以确定文档d所属的类别为
2 情感词情感权重计算新框架
目前,对于情感词典构建的研究主要局限在简单的词语极性判别,即只将情感词判别为正面词(褒义词)或者是负面词(贬义词).为了更好地利用情感词进行情感分析,在获得词库后可以采取一些方法给情感词赋权重以描述它们的情感程度.文献[4]等情感词权重的计算依赖于基准词,权重计算的准确度受限于基准词的选择及基准词情感程度的设定,并且这种只利用词语的共现信息存在不足.情感语料库训练集包含的文本都具有正负类别信息,这些信息对于情感词的情感程度确定也是非常有益的.
因此,本文提出一种自动获取词语情感程度的方法,此方法不再需要人工设定基准词,而是充分利用语料的情感类别信息,这样获得的情感权重更适用于文本的情感分类.词库采用台湾大学的NTUSD极性情感词库.下面首先提出情感词情感权重与文本情感倾向的相关假设,然后结合分析一些经典的特征选择方法,将特征选择技术拓展应用到情感词的权重赋值上.应用特征选择技术给情感词赋权重的流程如图1所示.
2.1词语情感权重与文本情感倾向的相关假设
对于一个富含情感信息的文本进行情感分析时一般会重点关注情感词.这些情感词不只是具有正面或者负面这2种特性,它们还具有不同的情感程度.例如,“很好”和“还行”这2个词的褒义程度就不一样,如果它们分别出现在2个商品评价信息中,出现“很好”的评论是正面评价的可能性会很大,而出现“还行”的评价是正面评价的可能性就没那么大了.因此,情感词的情感权重(代表情感程度)对文本情感分类也非常重要.普遍认同下面的假设,可以称之为词语情感权重与文本情感倾向的相关假设:
1)含有高权重正面词的文本比含有低权重正面词的文本属于正例的概率要大;
2)含有高权重负面词的文本比含有低权重负面词的文本属于负例的概率要大.
情感词的情感程度可以由人工设定,但是人的精力有限,每个人对这种强弱程度的判断也存在偏差,而且在不同的语境中一个词的权重往往是变化的,所以人工设定情感词的权重值的方法存在缺陷,不利于情感分类.
特征选择作为文本分类的一个预处理过程,可以用来刻画一个特征对于分类的重要程度.对于文本情感分类,可以将其看成二元分类:正面类和负面类.类似地,可以基于特征选择函数计算特征与正负类别的相关度,以此来度量情感词的情感权重.
如果对于正例类别,2个正面词word1和word2经过特征选择函数的计算得到的值分别为value1和value2,文本a中有词word1,文本b中有词word2,若value1>value2,且只考虑这2个词对a和b的类别判定,则a比b属于正面类别即正例的概率要大.这种认识和上面的假设非常契合,因此,情感词的特征选择函数值的大小能够反映情感词的情感程度强弱.
2.2基于IG的情感词权重计算
特征对于某个类别的信息增益值可以度量特征包含该类别信息的多少.计算一个特征对于训练集的信息增益公式如式(2)所示,它计算并汇总了特征与所有类别的信息增益值,适合于多元分类.而情感分类中一般只有正类和负类2个类别,因此需要对传统的IG方法进行一些改进.
1)不再计算特征与所有类别的特征选择函数值,只注重特征与目标类别的关系,这样更适用于情感分类这样的二元分类.
2)情感词库分为正面情感词库和负面情感词库,分别计算正面特征对于训练集中正例类别的信息增益值和负面特征对于训练集中负例类别的信息增益值.
假设正面词库为 tPos,包含的特征词为{tP1,tP2,…,tPi,…,tPm},负面词库为tNeg,包含的特征词为{tN1,tN2,…,tNi,…,tNn};正负类别分别为c+,c-.那么正面词tP和负面词tN的信息增益计算公式为
计算完每个特征对目标类别的信息增益值后,将正面词库和负面词库中的词按照信息增益值从大到小排序.依据前面的介绍,需要给信息增益值大的特征赋予较大的权重,信息增益值较小的词赋予较小的权重.因此,可以根据排序后情感词的位置前后衡量词的情感程度.假设正面词库有m个词,负面词库有n个词,正面情感词的权重范围设定为0~10,负面词的权重范围为-10~0,那么正面词库中信息增益值排名(排名从1开始)为i的正面词tPi和负面词库中信息增益值排名为j的负面词tNj的权重W的计算公式为
2.3基于CHI的情感词权重计算
卡方统计也是一种经典的特征选择方法,特征和类别的卡方统计量可以表征它们之间的相关性.在式(3)中,当AD-BC≤0时代表特征和类别负相关[13].在考虑正面词对正面类别时,当出现负相关情况时,卡方统计值度量文本包含该特征时不属于正面类别的概率,这与正面词在正面类别文本中的作用是相违背的,所以这种负相关程度越大,卡方统计值应越小.考虑负面词对负面类别亦是如此.所以需要对CHI方法进行改进.仍然是将正面特征和负面特征分开计算,改进后的公式为
在采用改进的CHI进行特征选择后,余下的步骤同2.2节.
2.4融入情感权重的情感分类算法
前面1.3节介绍了2种情感分类算法NP和NB,本节将基于这2种算法,融入情感权重信息形成新的情感分类算法NP-W和NB-W,这2种方法将被用于测试情感权重的有效性.
2.4.1NP-W算法
将情感权重信息融入NP方法后,不再利用词的极性信息,而是利用权重信息Wi.那么,文本d的情感倾向计算函数f'(d)为
同样,文本的极性判定规定为:f(d)>0时,文本d为正例;f(d)≤0时,文本d为负例.
2.4.2NB-W算法
将情感权重信息融入NB方法后,P(d|ci)的计算公式为
式中 ci∈{+,-}.文本的极性判定规定如下:P(+|d)>P(-|d)时,d属于正例;P(-|d)>P(+|d)时,d属于负例.
3 实验与分析
3.1实验设计
特征选择是文本分类的一个重要的预处理过程,能够对高维数据进行有效的维数约简.不仅如此,它还可以计算特征对于分类的重要程度.本实验拟基于特征选择技术设计一种情感词的情感权重计算方法,具体的实验流程如图2所示.
1)利用情感分类的训练文本集和已有的极性情感词库(词的正负极性确定,但是无权重),基于特征选择技术给训练集中出现的情感词赋权重,生成一个带权重的情感词库.
2)为了测试权重的有效性,可以将权重信息融入现有的一些文本情感分类方法,通过实验分析其效果.
为了验证基于特征选择技术的权重赋值的方法的有效性,实验中特征选择方法有3种:DF特征选择方法、2.2节设计的基于IG改进的方法和2.3节基于CHI改进的方法.DF特征选择方法相对比较简单,是一种不太精确的特征选择方法,相对来说IG和CHI对特征的重要程度衡量比较准确.根据前面的假设理论,更好的特征选择方法给情感词赋的权重更准确,那么将之用于情感分类得到的分类效果也就越好.
实验的测试部分,会选取1.3节和2.4节中的情感分类算法.依据融入权重信息前后分类方法的效果对比,验证基于特征选择技术所赋的权重的合理性和有效性.
3.2数据集
情感词库采用比较权威的NTUSD极性情感词库.情感分类语料采用的是中科院谭松波博士收集整理的一个较大规模的实际商品评价语料,包括5个数据源,分别是从当当和京东获取的书籍评论,从携程获取的酒店评论,以及从淘宝和京东获取的电脑评论.每个数据源包含正负文本各2 000篇,分别随机选取200篇作为测试集,其余的作为训练集.基于NTUSD情感词库对训练集中的文本进行分词处理,最后得到了包含1 420个正面词和2 493个负面词的有效词典.需要对这些总共为3 913个情感词进行权重赋值.
3.3性能评价指标
正确率P、召回率R和F1值3种度量已被广泛用于分类效果评价[1].对于类别ci∈{+,-},它们的计算公式为
式中:bi是测试集中ci类的文档数;ai是其中被正确判断为ci类的文档数;di是应属于ci类的文档数.F1值综合考虑了正确率和召回率,能更全面地反映分类效果的优劣.因此,本实验将采用F1值来评价情感分类的效果,结果分析中会给出5个单独数据集以及整个数据集的F1测度,包括正类F1值、负类F1值和平均F1值.
3.4实验结果与分析
情感词的权重计算分别采用了DF、改进的IG 和CHI三种方法,生成了3个不同的带权重的情感词库.
3.4.1NP和NP-W实验对比
表1给出了NP和融入权重信息后的NP-W两种方法的实验结果.NP-W(DF)表示采用的词库是用DF特征选择方法计算生成的,NP-W(IG)和NPW(CHI)对应的带权重的情感词库为改进的IG和CHI分别计算得到的.每个数据源分别给出了负类和正类的分类准确率P、召回率R和F1测度.例如,当当书籍数据集用NP算法分类,负类的准确率、召回率和 F1测度分别为0.758 1、0.815和0.785 5,正类的准确率、召回率和F1测度分别为0.800 0、0.740 0和0.768 8.
从表1可以看出,NP-W(IG)和NP-W(CHI)方法的效果明显好于NP,NP-W(DF)的效果比NP较好,但是提升的效果不如NP-W(IG)和NP-W(CHI)那么显著.

表1 NP和NP-W的情感分类结果Table 1 Sentiment classification results of NP and NP-W
图3显示了各种方法在5个数据集上的效果F1测度.图3(a)显示的是负类上的结果,图3(b)显示的是正类上的结果.从柱状图不难发现,无论是哪个数据集,也无论是正类还是负类,NP-W(IG)和NP-W(CHI)方法的F1值都明显地大于NP方法的F1值,这充分说明了采用改进的IG和CHI方法给情感词库赋权重的合理性.
在负类上NP-W(DF)和原始的NP的效果接近,在正类上NP-W(DF)的效果虽然优于NP,但是却比NP-W(IG)和NP-W(CHI)差了不少,主要有2个原因:首先,DF特征选择方法本身不如 IG和CHI,与针对情感分类进行改进的IG和CHI相差就更远,导致赋予特征的权重不够准确,所以效果不理想.其次,对于一个情感文本,NP方法通过简单地比较正负特征的多少来判别类别,而数据集中正面词比负面词少(正面词1 420个和负面词2 493个),因此NP方法较其他方法更倾向于负类,导致NP在正类上的效果很差,这是不合理的.
图4显示了上面4种方法在数据集正负类上的平均F1测度结果.平均F1值是计算负类和正类F1值的平均值.从图4可以看出,融合权重后,无论是在5个单独的数据集上,还是在整个数据集上,都能提升情感分类的效果.NP-W(IG)和NP-W(CHI)依旧取得最好的效果,NP-W(DF)的平均F1值也总是高于NP,这表明了NP-W(DF)虽然在负类上没提高多少效果,但是整体上却有较为明显的提高.
3.4.2NB和NB-W结果分析
表2给出了NB和融入权重信息后的NB-W两种方法的实验结果.从表2可以看出,基于朴素贝叶斯的情感分类方法相比前面简单的情感词统计方法效果要好很多,尤其是其正类和负类的分类效果接近,说明该方法没有类别倾向性,算法的设计比较合理.式(10)中P(tj|ci)也同样计算了特征词在各类别中的出现概率,相当于也给特征赋了一个权值,因此效果相比NP有所提升.融入权重信息后,效果也都得到了提升,再次说明了特征选择技术能够有效地应用于情感词权重计算.
图5显示了基于NB的4种方法在5个数据集上的F1测度结果.NB-W(DF)方法在正类上的效果较差,主要原因是DF特征选择方法倾向于高频词,而数据集中负面词较多,所以经过DF特征选择计算后,负面词的权重赋值相对较大,因此会在一定程度倾向于负类.不难发现,NB-W(DF)方法在负类上的效果比NB方法好一些,也是该方法倾向于负类的一个表现.
图6为4种方法在数据集正负类上的平均F1测度结果,在整个数据集上NB-W(DF)方法的平均F1值接近NB方法,NB-W(IG)和NB-W(CHI)相对NB方法提升了3%,效果较为明显.
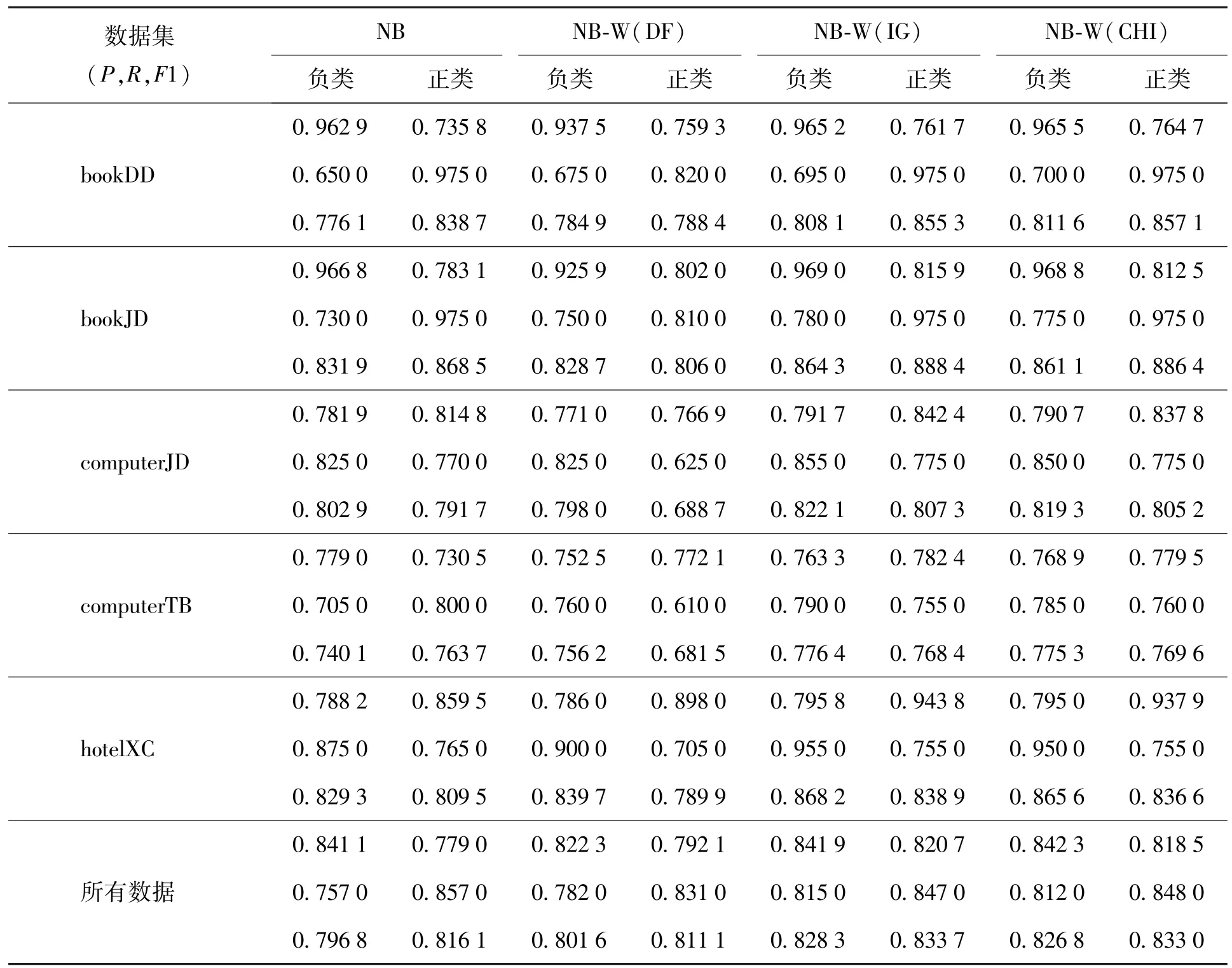
表2 NB和NB-W的情感分类结果Table 2 Sentiment classification results of NB and NB-W
4 结论
1)将特征选择技术拓展应用于情感词的权重计算,从而能够构建带情感权重的情感词库.实验结果表明:该方法是合理有效的,不仅能实现情感词权重的自动计算,而且将计算所得的带情感权重的情感词库用于文本情感分类,能够有效提升分类精度.
2)文中改进的IG和CHI可能不是最适合的特征选择方法,未来可以展开的工作之一是研究并设计更加适用于情感词权重赋值的特征选择方法.另外,NTUSD词库总共约有1.1万个词,此次实验只对其中的3 913个词进行了权重赋值,是因为选取的5个评价语料集无法涵盖NTUSD词库中的所有词.如果想要完成所有词的权重赋值,构建一个更完整的带权重的词库,可以选取更多的情感语料库.不过,通过不同的语料集计算得到的情感词库可能存在重叠词,且这些词的权重在不同语料中也可能不尽相同,此时这些词的权重计算也将是一个未来的研究内容.
[1]赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(8):1834-1848. ZHAO Y Y,QIN B,LIU T.Text sentiment analysis[J]. Journal of Software,2010,21(8):1834-1848.(in Chinese)
[2]TURNEY P,LITTMAN M L.Measuring praise and criticism:inference of semantic orientation from association [J].ACM Trans on Information Systems,2003,21(4):315-346.
[3]朱嫣岚,闵锦,周雅倩,等.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006,20(1):14-20. ZHU Y L,MIN J,ZHOU Y Q,et al.Semantic orientation computing based on HowNet[J].Journal of Chinese Information Processing,2006,20(1):14-20.(in Chinese)
[4]徐琳宏,林鸿飞,潘宇,等.情感词汇本体的构造[J].情报学报,2008,27(2):180-185. XU L H,LIN H F,PAN Y,et al.Constructing the affective lexicon ontology[J].Journal of the China Society for Scientific and Technical Information,2008,27(2):180-185.(in Chinese)
[5]ANDREEVSKAIA A,BERGLER S.Mining WordNet for a fuzzy sentiment:sentiment tag extraction from WordNet glosses[C]∥McCarthy D,Wintner S.Proc of the European Chapter of the Association for Computational Linguistics(EACL).Morristown:ACL,2006:209-216.
[6]柳位平,朱艳辉,栗春亮,等.中文基础情感词词典构建方法研究[J].计算机应用,2009,29(11):2882-2884. LIU W P,ZHU Y H,LI C L,et al.Research on building Chinese basic semantic lexicon[J].Journal of Computer Applications,2009,29(11):2882-2884.(in Chinese)
[7]ESULI A,SEBASTIANI F.Sentiwordnet:a publicly available lexical resource for opinion mining[C]∥Proc of LREC.Genoa:LREC,2006:417-422.
[8]BACCIANELLAS,ESULIA,SEBASTIANIF. Sentiwordnet 3.0:anenhancedlexicalresourcefor sentiment analysis and opinion mining[C]∥Proc of the LREC.Valletta,Malta:European Language Resources Association,2010:2201-2204.
[9]周咏梅,杨佳能,阳爱民.面向文本情感分析的中文情感词典构建方法[J].山东大学学报(工学版),2013,43(6):2-33. ZHOU Y M,YANG J N,YANG A M.A method on building Chinese sentiment lexicon for text sentiment analysis[J].Journal of Shandong University(Engineering Science),2013,43(6):2-33.(in Chinese)
[10]YANG Y,PEDERSON J O.A comparative study on feature selection in text categorization[C]∥ Proc of the 14th International Conference on Machine Learning.San Francisco:Morgan Kaufmann,1997:412-420.
[11]QUINLAN J R.C4.5:programs for machine learning [M].LosAltos,California:MorganKaufmann Publishers,Inc,1993:17-26.
[12]LEWIS D D.Naive Bayes at forty:the independence assumption in information retrieval[M]∥ Machine learning:ECML-98.Berlin:Springer,1998:4-15.
[13]裴英博,刘晓霞.文本分类中改进型CHI特征选择方法的研究[J].计算机工程与应用,2011,47(4):128-130. PEI Y B,LIU X X.Study on improved CHI for feature selection in Chinese text categorization[J].Computer Engineering and Applications,2011,47(4):128-130. (in Chinese)
(责任编辑 吕小红)
Weight Calculation of Emotional Word Based on Feature Selection Technique
WU Jinyuan1,JI Junzhong1,ZHAO Xuewu1,2,WU Chensheng3,DU Fanghua1
(1.Beijing Municipal Key Laboratory of Multimedia and Intelligent Software Technology,College of Computer Science and Technology,Beijing University of Technology,Beijing 100124,China;2.School of Software,Nanyang Normal University,Nanyang 473061,Henan,China;3.Beijing Institute Science and Technology Information,Beijing 100048,China)
It is very important for the text sentiment analysis to build an emotional dictionary.However,most of current researches in this area focus on the words’polarity discrimination.Researchers rarely study the weight assignment of emotional words,and methods on this already existed mostly need to select benchmark words through artificial ways.Using artificial ways brings great difficulty in practical application.To solve this problem,an automatic weight calculation approach of emotional words based on feature selection technique was proposed.Firstly some related assumptions between the emotional weight of words and the emotional tendency of texts were proposed;Then,centered around sentiment classification,the properties of binary classification was combined to improve information gain(IG)and chi-squarec(CHI);Finally,the improved feature selection methods to calculate the weight of emotional words were usesd.Experimental results show that using the emotion dictionary with the calculated weights in text sentiment classification can greatly improve the classification accuracy.
text sentiment classification;construction of emotion dictionary;feature selection;weight calculation
TP 181
A
0254-0037(2016)01-0142-10
10.11936/bjutxb2015040085
2015-04-29
国家自然科学基金资助项目(61375059)
吴金源(1988—),男,助理工程师,主要从事文本挖掘,机器学习方面的研究,E-mail:wjy9595@qq.com
冀俊忠(1969—),男,教授,主要从事机器学习、Web智能方面的研究,E-mail:jjz01@bjut.edu.cn
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
少儿画王(3-6岁)(2020年4期)2020-09-13
动漫界·幼教365(大班)(2020年7期)2020-06-26
现代计算机(2019年30期)2019-12-11
电脑爱好者(2017年5期)2017-05-04
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
微型计算机(2009年4期)2009-12-23
