
中文阅读中预视阶段和注视阶段内词汇视觉编码的过程特点:来自消失文本的证据*
2017-02-01 02:28刘志方张智君
心理学报 2017年7期
刘志方 张智君 潘 运 仝 文 苏 衡
(1宁波大学心理学系暨研究所,宁波 315211)(2浙江大学心理与行为科学系,杭州 310028)(3贵州师范大学心理学系,贵阳 550003)(4山西师范大学心理学系,临汾 041004)
1 引言
视觉信息是文字识别的必要依据,阅读中读者通过一系列的注视和眼跳识别不同位置上的文字,由于眼跳过程中不能获取视觉信息,而每个注视点上所获的视觉信息也完全不同,因而读者必须在有限的时间内将视觉信息转换成稳定的编码,方能保障词汇识别和阅读理解的正常进行(Pollatsek,Reichle,&Rayner,2006;Reichle,Liversedge,Pollatsek,&Rayner,2009)。对于此问题,有研究发现,英语阅读中,每个注视词汇呈现大约60ms后消失,将不再影响句子阅读时间(Liversedge et al.,2004),且在此情况下依然可以发现词频属性影响对目标词汇的注视时间(Rayner,Liversedge,White,&Vergilino-Perez,2003)。上述结果意味着,英语读者能够快速地将注视词汇(词 n)的视觉信息转换成为稳定视觉编码,进而保障随后的词汇识别过程。Rayner,Liversedge和White(2006)同样考察了英语读者对预视词汇视觉信息编码的过程特点,结果发现,注视词n持续60ms后,词n+1的视觉信息消失会严重影响句子总阅读时间,这意味着英语读者不能同时编码词n与n+1两个词汇的视觉信息。
中文阅读中的文字识别过程同样也存在视觉编码问题。稳定的证据表明,中文阅读中的文字识别过程与西文阅读中的文字识别过程具有普遍的一致性,中文读者也是以词为单元识别汉字、理解文本(Bai,Yan,Liversedge,Zang,&Rayner,2008;Blythe et al.,2012;Shen et al.,2012;Bai et al.,2013;Li,Gu,Liu,&Rayner,2013;白学军等,2011;沈德立等,2010)。考虑到绝大多数的中文词由两个汉字组成,因而考察双字词视觉编码特点,更能代表中文阅读中视觉编码过程特点。国内研究者采用同样范式(消失文本范式),以双字词为单元考察青年中文读者对注视词汇(词 n)的视觉编码问题,结果发现,注视词n 持续约55ms后,词n视觉信息消失不影响句子总阅读时间,这意味着青年中文读者能够与英语读者一样快速地对词 n进行视觉编码(刘志方,张智君,赵亚军,2011;刘志方,翁世华,张锋,2014)。不过,并不能根据这些结果直接断定中文阅读中的视觉编码机制类同于英语阅读。英语是拼音文字的典型代表,而中文则代表另一种逻辑类型的语言(张学新等,2012),因而两种语言阅读中的视觉编码过程可能有所不同。
随后多项研究表明,中、英语阅读中视觉信息的编码过程确实存在差异。比如,相关证据表明,延迟时间为55ms或者稍微较长时,词n+1上两个汉字消失并不影响青年中文读者的总阅读时间(刘志方等,2011);这与英语阅读中得到的结果不一致(Rayner et al.,2006)。由此可知,若以词为单元衡量,青年中文读者在一次注视中所能编码的视觉信息的范围广于青年英语读者。考察注视词汇(词 n)视觉编码的发展与年老化研究也都揭示了中、英文间的区别。具体而言,英语阅读中发现,相同延长时间下,注视词汇消失对儿童、老年读者阅读效率的影响与其对青年读者句子总阅读时间影响程度基本相当,从而并未发现视觉编码能力的年龄差异(Blythe,Liversedge,Joseph,White,&Rayner.2009;Blythe,Häikiö,Bertam,Liversedge,&Hyönä,2011;Rayner,Yang,Castelhano,&Liversedge,2010)。而中文阅读中却发现,儿童和老年读者要比青年读者需要更长的时间去完成注视词汇视觉信息的编码过程(刘志方等,2014;闫国利,刘妮娜,梁菲菲,刘志方,白学军,2015)。由此可知,中文阅读中词汇视觉信息的编码过程有其特殊性。
中文文字识别过程对视觉信息的依赖性较重,这个特点可能是导致两类语言阅读中的视觉编码过程存在差异的潜在原因。有证据显示,中文文字语义信息的通达路径不同于拼音文字,中文读者可以从字面直接激活词的语义信息,较少依赖语音中介作用;而拼音文字读者则需要通过语音中介激活语义(Zhou &Marslen-Wilson,2000;Perfetti,Liu,&Tan,2005)。张学新等人(2012)还发现,在双字词视觉信息呈现 200ms后,会出现反映整词词形加工性质的脑电模式,他们由此推测,中文是种更加切底的视觉性文字。阅读过程研究则发现,视角大小能够调节中文读者的阅读知觉广度,视角增大会导致阅读知觉广度变小,此现象在拼音文字阅读中不存在(Rayner,1998;Yan,Zhou,Shu,&Kliegl,2015)。还有阅读发展方面的证据显示,拼音文字儿童的阅读能力主要与其语音意识(phonological awareness)有关,而决定中文儿童阅读能力的主要因素则是正字法意识(orthographic awareness)(Tan,Spinks,Eden,Perfetti,&Siok,2005)。综合可知,相对于拼音文字阅读,中文文字识别过程涉及较多视觉性加工。
中文词汇视觉编码过程的特异性(相对于拼音文字)还可能与词内汉字加工的独立性有关。拼音文字读者完全基于词汇单元分布、转移注意资源,识别字母以及理解文本,因而他们以词汇单元针对字母视觉信息进行单阶段的编码过程,而编码一旦完成便可以保证词汇识别和阅读理解的正常进行(Pollatsek et al.,2006;Yang &McConkie,2004;Reilly &Radach,2006;Schad &Engbert,2012;Schotter,Reichle,&Rayner,2014)。但相对于拼音文字阅读中字母加工,汉字加工能够在一定程度上独立于其所在词汇的加工过程(申薇,李兴珊,2012)。在实际阅读中,组成目标词汇的汉字的字频既能影响目标词汇的注视时间,也能影响目标词左侧词汇的注视时间(Yan,Tian,Bai,&Rayner,2006;Ma,Li,&Rayner,2015),这些研究都很好地验证了“多字词识别必须经历汉字加工环节”的假设(Li,Rayner,&Cave,2009;李兴珊,刘萍萍,马国杰,2011),但对于“中文阅读中是否还存在以汉字为单元的视觉信息编码环节”,目前则尚无研究探讨。除此之外,中文读者基于词汇单元理解文本,阅读中存在切分现象(Bai et al.,2008,2013;白学军等,2011;沈德立等,2010),以及词汇判断任务中可见反映双字词词形加工的脑电成分(张学新等,2012),也都意味着中文阅读中也可能存在词汇性质的视觉编码,然而,目前为止直接检验上述可能性的实证研究却比较缺乏。
证据显示,汉字层面的加工处于词汇加工的早期,主要发生在预视阶段,而词汇层面的加工则应主要发生在注视阶段(Ma et al.,2015;苏衡,刘志方,曹立人,2016;刘志方,张智君,杨桂芳,2015);因而分别考察词n+1与词n视觉信息编码过程特点可检验“中文阅读中是否存在基于汉字单元与基于词汇单元两种视觉编码过程?”。然而,综观以往研究不难发现,这些研究都是以整个词汇为单元组织消失文本实验。比如,刘志方等人(2011)以双字词为单元,考察词n+1与词n视觉编码的所需时间问题;还有研究整词为消失单元,考察词 n视觉编码能力的年龄发展与老化问题(闫国利等,2015;刘志方等,2014)。这些研究所获的结果都不能说明,在相应呈现时间内,读者所完成的视觉编码是词汇水平的视觉编码,还是汉字水平的视觉编码。阅读中多字词识别若是仅基于汉字视觉编码,那么消失文本对总阅读时间的影响受到消失汉字位置、消失汉字数量的调节;否则则说明多字词识别主要基于整词视觉编码。本研究重新组织两项消失文本实验分别操控词n+1和词n内消失汉字的位置、数量、及其延迟时间;考察不同阶段内(预视阶段和注视阶段)词汇视觉编码的过程特点,以检验上述假设。
2 实验一:预视阶段内的字词视觉编码特点
实验一操控词n+1上消失汉字的位置、数量及其延迟时间,观察不同延迟时间、不同消失条件影响句子总阅读时间的差异特点,进而推测预视阶段内词汇视觉信息编码的依据单元。实验假设:若及时消失条件对总阅读时间的影响程度与消失汉字位置和消失汉字数量有关,以及读者提取不同位置上汉字视觉信息所需时间不同,都说明读者以汉字为单元编码预视阶段内词汇的视觉信息;否则则说明读者以整词为单元编码预视中词汇的视觉信息。
2.1 被试
宁波大学 40名大学本科生被试阅读延迟时间为0ms的分实验条件,另外36名大学本科生被试阅读延迟时间为60ms的分实验条件。这76名被试中有男生26人、女生50人。所有被试的视力或矫正视力正常,他们之前均未参加过任何类似眼动实验。实验结束后可获得20元报酬。
2.2 实验材料
所有的实验句子均是由7个或者8个双字词组成。10名未参与实验的本科生对实验材料进行难度和通顺性评定,评定后选取 80个句子为正式实验材料,这些句子的平均通顺性为6.48(7点评定,分值越高表示越通顺),平均难度为 1.84(7点评定,分值越低表示越简单)。实验句子中有27个句子带有理解判断题,以筛选被试是否认真阅读句子。
2.3 实验设计
实验采用 2(延迟时间:0msvs
60ms)×4(消失方式:不消失vs
词n+1上左侧字消失vs
词n+1上右侧字消失vs
词n+1消失)混合设计,其中延迟时间为被试间变量,消失方式为被试内变量。词n+1上左侧字消失条件是指在当注视点落在词n上0ms或者60ms后,词n+1上左侧字消失(句子中的每个词汇均为双字词);词 n+1上右侧字消失是指在当注视点落在词n上0ms或者60ms后,词n+1上右侧字消失;词n+1消失是指在当注视点落在词n上0ms或者60ms后,整个词n+1(两个汉字)消失。以上各个消失条件中,读者对注视词汇进行再注视不会导致消失的汉字或词汇重新出现,当注视点落在其他词汇上时消失的文字立即重现,电脑再次执行相应的消失程序导致其他词汇上汉字消失,各呈现条件的详细举例见图1。考虑到“与呈现刺激电脑屏幕的涮新率有关的系统延迟”,相应字、词消失条件中的实际延迟时间约多于电脑程序中所设置时间约 15ms,因此实验中消失文本的实际延迟时间约为15ms和75ms(下同)。
图1 实验一控制条件和各消失文本条件举例(“*”代表注视点,下同)
实验句子与消失方式间平衡方法为:首先,将80个实验句子随机划分成4组,每组中包含20个实验句子;然后,在 4组实验句子中按照拉丁方排序方式分布不同呈现条件,这样共生成4个实验文件。实验文件1中的各组句子与消失方式间的组合为:组1(1~20句)以不消失的方式呈现,组2(21~40句)以词n+1左侧字消失方式呈现,组3(41~60句)以词n+1右侧字消失方式呈现,组4(61~80句)以词n+1消失的方式呈现。实验文件2中各组句子与消失方式间的组合为:组1以词n+1消失的方式呈现,组2以不消失的方式呈现,组3以词n+1左侧字消失方式呈现,组4以词n+1右侧字消失方式呈现。实验文件3中各组句子与消失方式间的组合为:组1以词n+1右侧字消失方式呈现,组2以词n+1消失的方式呈现,组 3以不消失的方式呈现,组 4以词n+1左侧字消失方式呈现;实验文件4中各组句子与消失方式间的组合为:组1以词n+1左侧字消失方式呈现,组2以词n+1右侧字消失方式呈现,组3以词n+1消失的方式呈现,组4以不消失的方式呈现。由上述描述可知,每个实验文件中包括的句子完全相同。每个被试完成其中一个文件内的实验,完成每个实验文件的被试数量相等,这样 4个实验文件就可以在被试间平衡。每个实验文件中的80个句子(无论以何种消失方式呈现)都是按照随机顺序被逐个呈现。
2.4 实验仪器和实验程序
采用加拿大 SR公司生产的桌面式 Eye Link 1000型眼动仪并记录被试的眼动。该型设备采样频率为 1000 Hz,注视精度 0.15°,空间分辨率小于0.01°。呈现材料电脑的属性如下:刷新频率为 60 Hz、屏幕19英寸、分辨率1024×768。被试距离呈现实验材料屏幕为45cm,单个汉字视角为1.32°。被试进入实验室后戴好头盔并固定头部。呈现指导语后校准眼动仪,校准结束后,进入实验练习阶段,被试熟悉实验流程后,进入正式实验阶段。实验过程中,主试时刻监视眼动仪,并在任何需要的时候重新校准眼动仪。实验持续大约25 min。
2.5 结果
研究通过检查各消失条件影响词汇加工的程度差异推测词汇视觉编码的依据单元。消失条件下的句子中所有字、词都被消失文本技术所处理,而成功识别句子所有词汇才能保障阅读完成,因此句子总阅读时间是衡量词汇视觉编码特点重要参考指标(总阅读时间是阅读句子时所产生的所有注视和眼跳持续时间之和)。与此同时,鉴于词汇兴趣区区域的眼动指标能反映词汇加工过程(词汇视觉编码是词汇加工过程的组成环节,也是后期词汇加工的基于依据),因而还分析 4项词汇兴趣区眼动指标:1)平均总注视时间(所有词汇上总注视时间的均值,总注视时间是指落在特定词汇上所有注视点持续时间之和);2)平均凝视时间(所有被注视过词汇的凝视时间的均值,凝视时间是第一遍阅读中在目标词汇兴趣区内所有注视点持续时间之和,离开目标词汇兴趣区后再次进入兴趣区的注视点不在考虑范围内);3)跳读概率是指第一遍阅读中被跳读的词数与句子的总词数之间的比率;4)回视次数是由右侧词汇兴趣区出发落入左侧词汇兴趣区的眼跳次数。
被试对 27个句子理解的正确率均超过 90%,且各条件间差异不显著(p
>0.05),表明被试均认真阅读句子。删除实验过程中出现意外的数据(比如,阅读某句子时被试咳嗽、和被试连续按键导致句子被跳过的情况),剔除数据在 3个标准差之外的数据,总计有1.7%的原始数据被剔除。随后采用lme 4包构建线性混合模型在 R中分析各项指标(Baayen,Davidson,&Bates,2008;Bates,Maechler,&Bolker,2011;Barr,Levy,Scheepers,&Tily,2013)。根据研究目的确定数据分析原则:首先,分别对比两种延迟时间(0ms与60ms)下各消失文本条件与控制条件在总阅读时间方面的差别;然后,进一步澄清与控制条件有所差异的消失文本条件内部数据的差异模式。根据眼动指标的操作性定义与以往研究背景可知,句子总阅读时间和词汇平均总注视时间反映较为完整的词汇识别过程,平均凝视时间反映第一遍阅读中的词汇加工过程,跳读概率仅反映第一遍阅读中的词汇预视加工情况,回视次数则反映首次注视时词汇加工的不完整性(Rayner,1998;Reichle,Rayner,&Pollatsek,2003;Reichle,Pollatsek,&Rayner,2006;Engbert,Longtin,&Kliegl,2002;Engbert,Nuthmann,Richter,&Kliegl,2005)。鉴于读者阅读消失文本会采用权衡注视点数量和注视持续时间的眼动策略,这种策略会导致平均凝视时间、跳读概率和回视次数不能灵敏地反映研究问题(Liversedge et al.,2004;刘志方等,2011,2014),而平均总注视时间尽管能够较少受到眼动策略的影响,其与句子总阅读时间也有较高的相关,但这项指标中并未包括眼跳持续时间,而证据显示眼跳过程中词汇加工过程并未中止(Pollatsek et al.,2006),因而相对来说,句子总阅读时间反映词汇加工过程最为可靠。故本研究主要参照“总阅读时间”做出推论,基于词汇兴趣区域的眼动指标将作为辅助性证据被呈现。总阅读时间结果见图2,词兴趣区内眼动指标见表1。
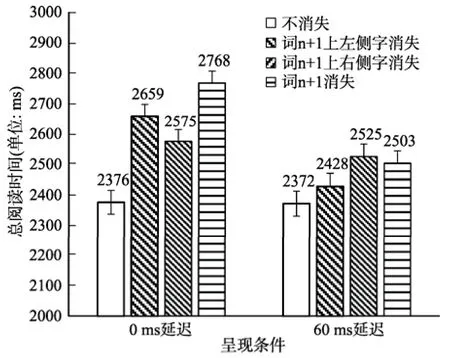
图2 实验一各消失条件下总阅读时间的均值与标准误
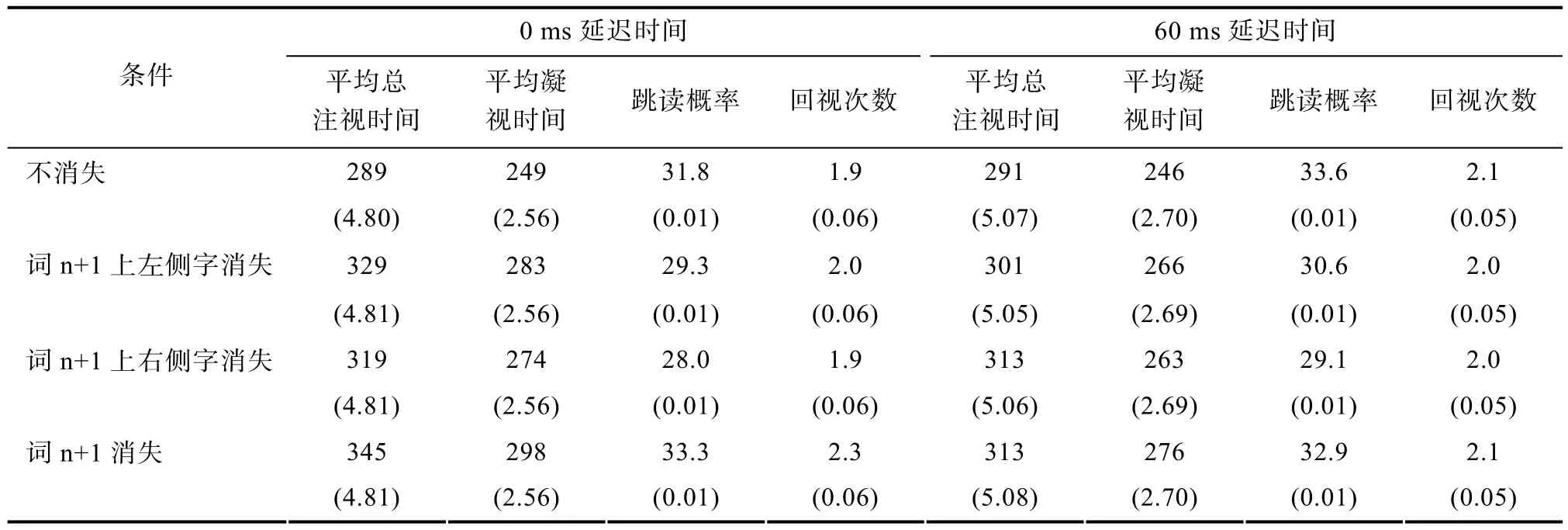
表1 实验一各消失条件下词汇兴趣内眼动指标的均值和标准误
对比实验一0ms延迟时间下的各消失文本条件与不消失条件下的总阅读时间可以发现,所有消失条件都显著高于不消失条件,b
s>
201,SE
s<
46,t
s >4.42,p
s <0.05;词n+1上左侧字消失条件与词n+1上右侧字消失条件之间的差异边缘显著,b=
88,SE=
45,t=
1.94,p
=0.05;词n+1消失显著大于词n+1上左侧字消失条件和词n+1上右侧字消失条件,b
s>
100,SE
s<
46,t
s >2.25,p
s <0.05。对比实验一60ms延迟时间下的各消失文本条件与不消失条件下的总阅读时间可以发现,词n+1上左侧字消失条件与不消失条件之间差异不显著,b=
61,SE=
46,t=
1.32,p
>0.05;词n+1消失条件和词n+1上右侧字消失条件显著多于不消失条件,b
s>
132,SE
s<
47,t
s >2.85,p
s <0.05;词n+1消失条件与词 n+1上右侧字消失条件之间差异不显著,b=
21,SE=
46,t=
0.47,p
>0.05。实验一0ms延迟时间的各消失文本、不消失条件之间词汇兴趣区眼动指标的对比结果如下:(1)平均总注视时间:所有消失条件都显著高于不消失条件,b
s>
30,SE
s<
6,t
s >5.39,p
s <0.05;词n+1上左侧字消失条件与词n+1上右侧字消失条件间的差异不显著,b=
10,SE=
6,t=
1.75,p
>0.05;词n+1消失显著大于词 n+1上左侧字消失条件和词n+1上右侧字消失条件,b
s>
15,SE
s<
6,t
s >2.76,p
s <0.05。(2)平均凝视时间:所有消失条件都显著高于不消失条件,b
s>
25,SE
s<
4,t
s >7.90,p
s <0.05;词n+1上左侧字消失条件显著大于词n+1上右侧字消失条件,b=
9,SE=
3,t=
2.74,p
>0.05;词n+1消失条件显著高于词n+1上左侧字消失条件和词n+1上右侧字消失条件,b
s>
14,SE
s<
4,t
s >4.45,p
s <0.05。(3)跳读概率:词n+1上左侧字消失条件和词n+1上右侧字消失条件显著少于不消失条件,b
s<−
2.54,SE
s<
0.6,t
s <−3.85,p
s <0.05;词n+1消失条件显著大于其他条件,b
s >1.53,SE
s<
0.7,t
s >2.31,p
s <0.05;词n+1上左侧字消失条件和词 n+1上右侧字消失条件间的差异不显著,b=
1.16,SE=
0.7,t=
1.77,p >
0.05。(4)回视次数:词n+1上左侧字消失条件、词n+1上右侧字消失条件与不消失条件之间的差异都不显著,b
s<
0.08,SE
s>
0.06,t
s<
1.32,p
s>
0.05;词n+1消失显著高于不消失条件,b=
0.42,SE=
0.06,t
=6.59,p
<0.05。实验一60ms延迟时间的各消失文本、不消失条件之间词汇兴趣区眼动指标的对比结果如下:(1)平均总注视时间:词 n+1上右侧字消失条件和词n+1消失条件都显著大于不消失条件,b
s>
22,SE
s<
6,t
s >3.87,p
s <0.05;词n+1上左侧字消失与不消失条件之间差异不显著,b=
11,SE=
6,t=
1.88,p
>0.05;词n+1上右侧字消失条件与词n+1消失条件之间差异不显著,b=
0.01,SE=
6,t=
0.003,p >
0.05。(2)平均凝视时间:所有消失条件都显著高于不消失条件,b
s>
17,SE
s<
4,t
s >5.47,p
s <0.05;词n+1上左侧字消失条件与词n+1上右侧字消失条件间差异不显著,b=
3,SE=
3,t=
0.90,p
>0.05;词n+1消失条件显著高于词n+1上右侧字消失条件和词n+1上左侧字消失条件,b
s>
10,SE
s<
4,t
s >3.31,p
s <0.05。(3)跳读概率:词n+1上左侧字消失、词 n+1上右侧字消失条件都显著少于不消失条件,b
s<−
2.99,SE
s<
0.6,t
s <−4.46,p
s <0.05;词 n+1消失条件与不消失条件差异不显著,b=−
0.6,SE=
0.6,t
=−0.89,p
=0.37;词n+1上左侧字消失条件显著多于词n+1上右侧字消失条件,b=
1.50,SE=
0.7,t=
2.33,p<
0.05;词n+1消失条件显著高于词n+1上左侧字消失条件和词n+1上右侧字消失条件,b
s>
2.41,SE
s<
0.7,t
s>
3.67,p
s <0.05。(4)回视次数:词n+1上左侧字消失条件显著少于不消失条件,b=−
0.13,SE=
0.06,t=−
2.04,p<
0.05;词 n+1 上的右侧字消失、词n+1消失条件与不消失条件之间差异不显著,b
s<
0.06,SE
s>
0.06,t
s<
0.9,p
s>
0.05。2.6 讨论
实验一通过考察词n+1上不同位置、不同数量汉字消失对总阅读时间的影响,检验预视阶段内针对相应词汇视觉信息进行编码的过程特点。有两项主要发现:
首先,当词 n+1中的汉字及时消失时,不同的消失条件对总阅读时间的影响程度完全不同,各个消失条件之间也差异显著。具体而言,词n+1上的左侧字消失对句子阅读时间的影响程度甚于词n+1上的右侧字消失;词 n+1中两个汉字同时消失(词n+1消失)对阅读的影响程度甚于两个单字分别消失的条件(词n+1上左侧字消失条件和词 n+1上右侧字消失条件)。上述结果说明,在及时消失情况下,各个消失条件对句子总阅读时间的影响受到消失汉字位置、与消失汉字数量的调节作用。词汇兴趣区域的眼动数据则方便从细节上揭示了各消失条件在不同程度上影响总阅读时间的具体原因。由表1可见,各消失条件对平均总注视时间、平均凝视时间的影响模式与其影响总阅读时间的模式基本一致。整个词n+1消失导致更高的跳读概率,该条件下读者通过增加回视次数弥补跳读对词汇识别的影响;词n+1上左侧字消失条件和右侧字消失条件并未增加跳读和回视,这两个单字消失条件下平均凝视时间都显著少于词n+1消失条件,这种模式能够解释它们对总阅读时间和平均总注视时间的影响程度低于词n+1消失条件。综上可知,延迟时间为 0ms的消失文本的实验结果说明,预视阶段内的读者以汉字为单元编码词n+1的视觉信息。
其次,消失条件延迟时间为 60ms的情况下,词n+1上左侧字消失条件不再影响句子的总阅读时间,但词n+1消失和词n+1上右侧字消失条件都在相同程度上影响句子总阅读时间,这个结果说明词n+1上不同位置上汉字消失对总阅读时间的影响程度随延迟时间变化的趋势不同。各消失条件对平均总注视时间的影响模式与其影响总阅读时间的模式在大体上相同;词n+1上左侧字消失条件和右侧字消失条件对平均凝视时间的影响程度都低于词n+1消失条件,前两者同样都导致较少跳读概率和回视次数,但词n+1右侧汉字消失条件导致更少的跳读概率。综合对比各项数据可知,词n+1上右侧汉字消失相对更少的跳读使其句子总阅读时间和词汇平均总注视时间高于词n+1上左侧汉字消失和控制条件,词n+1消失条件则通过增加回视方式导致较高句子总阅读时间和词汇平均总注视时间。总之,延迟时间为 60ms的消失文本实验结果再次证明,预视阶段内的读者以汉字为单元编码词 n+1的视觉信息。
3 实验二:注视阶段内字词视觉编码特点
实验二操控词n上消失汉字的位置、数量及其延迟时间,检验注视阶段内词汇视觉信息编码的依据单元。实验假设:若词n不同位置汉字及时消失对总阅读时间的影响程度与消失汉字位置和消失汉字数量有关,以及读者提取词n上不同位置上汉字视觉信息所需时间不同,都说明注视词汇的视觉信息编码过程主要基于汉字单元;否则则说明针对该词汇视觉信息的编码过程主要基于词汇单元。
3.1 被试
宁波大学 80名大学本科生作为被试参加了本次实验(40名被试阅读延迟时间为0ms的分实验条件,另外40名被试阅读延迟时间为60ms的分实验条件),其中男生25人、女生55人。所有被试的视力或矫正视力正常,他们之前均未参加过任何类似眼动实验。实验结束后可获得20元报酬。
3.2 实验设计
实验设计同样也为两因素混合设计,延迟时间为被试间变量,消失方式为被试内变量。变量“消失方式”包括四种:不消失、词n上注视字消失、词n上非注视字消失、词 n消失)。词 n上注视字消失条件是指在当注视点落在词n上0ms或者60ms后,词 n上的正被注视的汉字消失(句子中的每个词汇都是由两个双字组成),当注视点离开正被注视的汉字后消失的汉字重现,对消失汉字的再注视不会导致消失汉字重现。词n上非注视字消失条件是指在当注视点落在词n上0ms或者60ms后,词n上的未被注视的汉字消失,当注视点离开正被注视的汉字后消失的汉字重现,对注视汉字的再注视同样也不会导致消失汉字重现。词n消失条件是指在当注视点落在词n上0ms或者60ms后,构成词n的两个汉字一并消失,当注视点离开词 n后消失的两个汉字重现,对词n的再注视不会导致消失的两个汉字重现。以上各个消失条件中,当注视点落在其他词汇上时,电脑再次执行相应的消失方式。各消失条件的详细举例情况见图3。实验材料与实验条件间的平衡方式,以及实验句子的呈现顺序都与实验一相同。

图3 实验二控制条件和各消失条件举例示意图
3.3 实验材料、实验仪器和实验程序
实验材料、实验仪器和实验程序同实验一。
3.4 结果
所有选用的因变量眼动指标、数据剔除标准都与实验一相同,删除的原始数据占总数据的 1.9%,实验二同样参照“总阅读时间”做出推论,词汇兴趣区域的眼动指标(平均总注视时间、平均凝视时间、跳读概率和回视次数)也是作为辅助性证据被呈现。总阅读时间结果见图4,词兴趣区内眼动指标见表2。
对比实验二0ms延迟时间下的各消失文本条件与不消失条件下的总阅读时间可以发现,所有消失条件都显著高于不消失条件,b
s>
167,SE
s<
48,t
s >3.51,p
s <0.05;各个消失条件之间差异都不显著,b
s<
36,SE
s>
47,t
s<
0.73,p
s>
0.05。对比实验二60ms延迟时间下的各消失文本条件与不消失条件下的总阅读时间可以发现,所有消失条件与不消失条件间差异都不显著,|b
s|<
40,SE
s>
44,|t
s|<
0.51,p
s >0.05。实验二0ms延迟时间的各消失文本、不消失条件之间词汇兴趣区眼动指标的对比结果如下:(1)平均总注视时间:所有消失条件都显著高于不消失条件,b
s>
24,SE
s<
7,t
s >4.07,p
s <0.05;各个消失条件之间差异都不显著,|b
s|<
10,SE
s>
6,|t
s|<
0.85,p
s >0.05。(2)平均凝视时间:各个消失条件的平均凝视时间都显著高于不消失条件,b
s>
14,SE
s<
4,t
s >4.40,p
s <0.05;词n上注视字消失条件和词n上非注视字消失条件都显著大于词 n消失条件,b
s>
7,SE
s<
4,t
s >2.19,p
s <0.05;词n上注视字消失条件和词n上非注视字消失条件之间差异不显著,b=
2,SE=
3,t=
0.72,p
>0.05。(3)跳读概率:词n上注视字消失条件和词n上非注视字消失条件都显著少于不消失条件,b
s<−
2.24,SE
s<
0.7,t
s <−3.24,p
s <0.05;词n消失条件与不消失条件之间差异不显著,b=
1.01,SE=
0.7,t
=1.46,p >
0.05;词n上注视字消失条件和词n上非注视字消失条件之间差异不显著,b=
0.4,SE=
0.6,t=
0.68,p
>0.05。(4)回视次数:词n上注视字消失条件、词n上非注视字消失条件与不消失条件之间的差异不显著,b
s<
0.18,SE
s>
0.65,t
s<
0.27,p
s>
0.05;词n消失显著高于不消失条件,b=
0.23,SE=
0.06,t
=3.56,p
<0.05。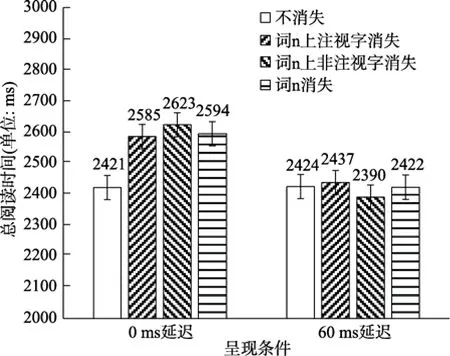
图4 实验二各消失条件下总阅读时间的均值与标准误
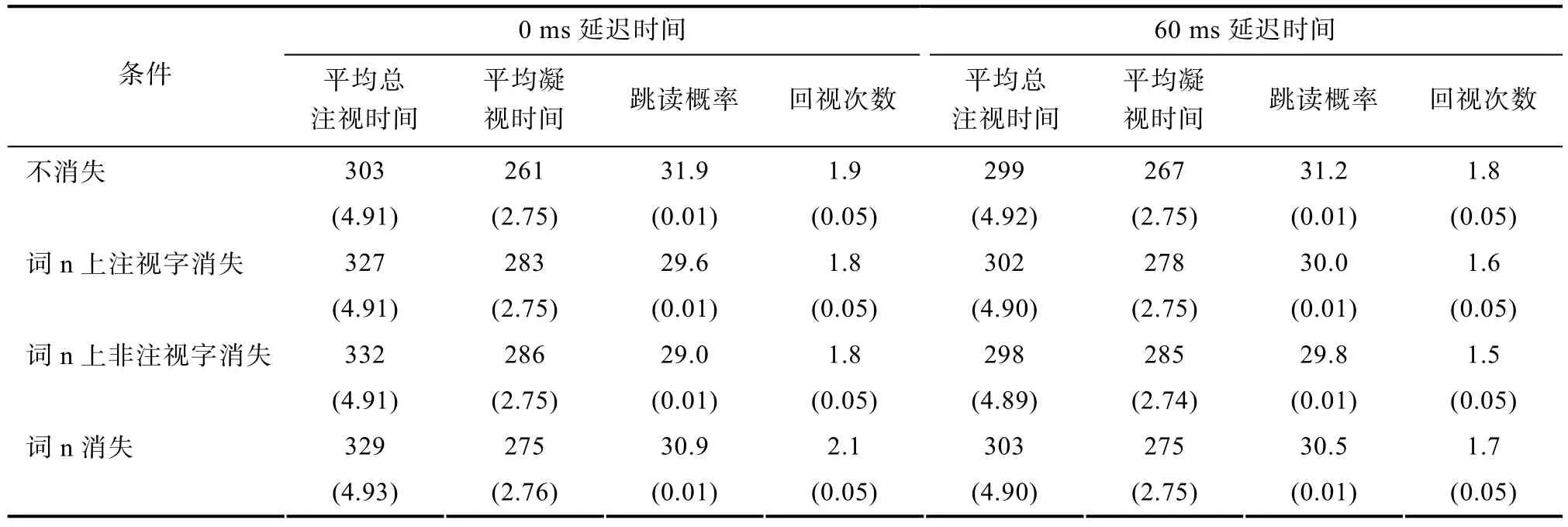
表2 实验二各消失条件下词汇兴趣内眼动指标的均值和标准误
实验二60ms延迟时间的各消失文本、不消失条件之间词汇兴趣区眼动指标的对比结果如下:(1)平均总注视时间:所有消失条件都与不消失条件之间差异不显著,|b
s|<
4,SE
s>
5,|t
s|<
0.65,p
s >0.05。(2)平均凝视时间:各个消失条件的平均凝视时间都显著高于不消失条件,b
s>
9,SE
s<
4,t
s >2.56,p
s <0.05;词n上非注视字消失条件显著大于注视字消失条件,b=
7,SE=
3,t=
2.10,p
<0.05;词 n上非注视字消失条件显著大于词 n消失条件,b=
9,SE=
3,t=
2.97,p
<0.05;注视字消失条件和词n消失条件之间差异不显著,b=
3,SE=
3,t=
0.87,p
>0.05。(3)跳读概率:所有消失条件与不消失条件间差异都不显著,|b
s|<
1.2,SE
s>
0.
4,|t
s|<
1.77,p
s >0.05。(4)回视次数:注视字消失条件和词n上非注视字消失条件显著少于不消失条件,b
s<−
0.17,SE
s<
0.07,t
s<−
2.95,p
s<
0.05;注视字消失条件和词n上非注视字消失条件之间差异不显著,b=−
0.11,SE=
0.06,t
=−1.81,p >
0.05;词 n 消失与不消失条件之间差异不显著,b=−
0.06,SE=
0.06,t
=−1.59,p >
0.05。3.5 讨论
实验二检验词n上不同位置、不同数量汉字消失对总阅读时间的影响,进而推测注视阶段内字词视觉编码过程特点,有两项主要发现。
首先,词n上的汉字及时消失(延迟时间为0ms的消失条件)都会影响句子总阅读时间,且所有的消失条件对总阅读时间的影响程度完全相同。基于词汇兴趣区的眼动数据揭示,读者阅读词n上单字消失(词n上注视字消失和词n上非注视字消失)条件句子时的眼动策略不同于词n消失条件。具体而言,读者阅读词n上单字消失条件时,采用“增加词汇凝视时间、减少跳读”的策略;而阅读词n消失时则采用“有限地增加词汇凝视时间、并与此同时增加跳读和回视次数”的策略完成阅读。不过在平均总注视时间上未发现消失条件间的差异,表明两类不同的眼动策略最终导致相同的结果,也即是,词汇兴趣区内的眼动数据辅助性地揭示了“所有的消失条件都在相同程度上影响总阅读时间”的原因。
其次,词n上汉字消失的延迟时间达到60ms后,所有消失条件都不影响总阅读时间,这个延迟时间下词n消失不影响句子阅读时间与以往的研究结论一致(刘志方等,2011,2014)。词汇兴趣区眼动数据同样揭示:尽管阅读词n上非注视字消失条件句子时的眼动策略不同于阅读词n消失条件和词n上注视字消失条件句子时的眼动策略(相对于后两种消失条件,读者更加倾向于采用“增加词上凝视时间,与此同时减少跳读和回视”的眼动策略完成词n上非注视字消失条件的句子阅读,见表2上的数据);但各消失条件在词汇上的平均总注视时间没有差异。由此可见,60ms延迟时间的消失文本实验结果并不支持“读者提取词 n上不同位置上汉字视觉信息所需时间不同”的假设。综合0ms延迟时间和60ms延迟时间的消失文本实验结果可以确定,读者以整词为单元编码词n的视觉信息。
4 总讨论
阅读过程中,读者必须将文本的视觉信息转化稳定的编码才能最终保证词汇识别和阅读理解的正常进行(Pollatsek et al.,2006;Reichle et al.,2009)。消失文本范式是考察阅读中视觉编码过程的有效范式。借助该范式,研究者对英语阅读和中文阅读中的词汇视觉编码过程进行广泛研究,这些研究提示中文阅读和英文阅读中的词汇视觉编码存在较大差异。本研究通过两项消失文本实验分别考察预视和注视阶段内中文阅读中的词汇视觉编码特点,以探查中文阅读中的视觉编码过程的语言特殊性特点。
鉴于消失文本会改变阅读中的眼动策略,两项实验通过检查各消失条件影响总阅读时间的差异模式探究主题。两项证据可排除“消失文本影响句法与理解层面上信息加工而导致总阅读时间变化”的可能性:1 研究采用极为简单、通顺容易理解的句子作为实验材料,且消失条件都不能改变句子的原有句法结构,这样就尽可能地减缩了句法、理解对实验结果的影响。2 句法与理解层面上信息加工发生较晚,若消失条件对之影响主导总阅读时间的变异源,那么词n上汉字消失条件中总阅读时间应该高于词n+1上汉字消失条件,但两项实验结果与上述预测的趋势相反。由此可见,消失条件主要通过影响词汇加工,进而延长总阅读时间。
4.1 中文阅读中字词视觉编码的阶段性特点
实验一检验读者编码词n+1视觉信息的过程特点。以往的研究显示,词n+1延迟55ms后消失不会影响句子总阅读时间(刘志方等,2011)。实验一中60ms延迟时间消失文本条件的实际延迟时间达到75ms 左右,而结果却显示,该延迟时间下词 n+1整体消失,与词n+1上右侧汉字消失都会影响句子总阅读时间,词汇兴趣区内眼动指标结果也与上述趋势相同。视角因素应该是导致本研究与以往研究结果不一致的重要因素。本研究中汉字呈现视角大于以往研究(刘志方等,2011),而根据以往研究可知,中文阅读知觉广度受到视角大小的影响,视角越大阅读知觉广度越小(Yan et al.,2015),与此同时,证据显示从中央凹区域开始到副中央凹区域内的文字加工速度逐渐降低(Schad &Engbert,2012;Schotter et al.,2014),这样句子中汉字呈现视角变大同样会导致词n+1远离视觉加工速度较快的中央凹区域,因而本研究扩大单个汉字视角就为发现,较长延迟时间下词 n+1消失依然影响总阅读时间,以及对词n+1上不同位置上汉字进行视觉编码所需时间有所差异做好铺垫。
实验一发现:(1)阻碍词n+1上汉字的视觉编码消极影响总阅读时间,及时消失的汉字距离注视点越近,消失汉字数量越多,其对阅读的影响就越为严重;(2)词n+1上左侧汉字视觉信息持续75ms将不影响阅读中的字词识别过程,而词n+1上右侧汉字视觉信息持续75ms仍不能保证阅读中的字词识别过程。对于此结果所能够揭示问题而言,存在两种可能。从直观上看,尽管上述结果与假设“读者基于汉字单元编码词 n+1的视觉信息”的预测一致;但如果读者可基于单个汉字联想或启动出整个双字词汇(Devlin,Jamison,Matthews,&Gonnerman,2004),且基于词汇上左侧汉字联想出整词的难度低于基于右侧汉字联想出整词的难度,那么“基于整词编码词 n+1视觉信息”的假设同样可以解释上述结果。不过,根据以往文献可知(Devlin et al.,2004),读者对词汇的凝视时间内不足以导致联想或启动过程发生作用,除此之外,实验二发现消失条件对总阅读时间的影响不受消失汉字数量的调节,这些证据都可以排除“由单个汉字联想到词汇导致此结果”的可能。由此可见,实验一表明不同位置上汉字视觉编码在词汇识别中所起的作用不尽相同,读者编码完成词n+1内不同汉字视觉信息的时程也不相同。
以往研究证实,阅读中双字目标词汇的整词特点(比如词频、背景对之的预测程度)对注视时间的影响在一定程度上独立于其内汉字特点的影响作用(Yan et al.,2006;Li,Bicknell,Liu,Wei,&Rayner,2014),这意味着至少在注视阶段存在整词单元的编码。实验二操控注视词内(词 n)汉字的消失方式及其延迟时间,从视觉加工角度进一步检验上述可能,结果发现:(1)词n上汉字及时消失对总阅读时间的影响不受消失汉字数量与消失汉字位置的调节;(2)词n上任何汉字视觉信息持续75ms都不影响阅读中的字词识别过程。上述结论也得到基于词汇兴趣区域内眼动数据结果的进一步支持,无论读者是否能够通过未消失的汉字联想出整个词汇,按照“以汉字为单元进行编码”假设都会预测,词n上单个汉字消失对总阅读时间的影响程度应低于整个词 n消失条件,因而实验二提示,中文读者以词为单元编码词n的视觉信息。综合实验一和实验二的结果可以确定,预视阶段内的文字视觉编码主要是基于汉字单元,而对注视阶段内文字视觉编码则主要是以整词为单元。
4.2 中文阅读中字词视觉编码过程的语言特殊性
中文读者编码词n和词n+1视觉信息所依据基本单元的差异提示中文阅读文字编码过程存在阶段性特点。这种阶段性特点与拼音文字有较大差异,拼音文字阅读中,读者只有将词汇视觉信息编码形成稳定的表征就能保证词汇的正常识别加工(Pollatsek et al.,2006;Reichle et al.,2009),拼音读者基于词汇单元识别字母、字母加工受制于其所在词汇的加工,这意味着其基于词汇单元编码文本视觉信息(Schotter et al.,2014;Schad &Engbert,2012),可见拼音文字的视觉编码过程是个单一阶段的过程,而中文阅读过程中同时存在基于汉字单元(主要针对预视范围内的字词)和基于词汇单元(主要针对正在被注视词汇)的视觉信息编码过程,这意味着中文阅读中的视觉编码过程至少是双阶段的过程,中文书面语言加工的这个特点在一定程度上与李兴珊等人提出的“中文阅读中的文字识别存在汉字层面和词汇层面两个加工阶段”的观点相吻合(Li et al.,2009;李兴珊等,2011)。
从编码方式看,尽管视觉信息可被平行、自动获取,但将文字视觉信息转换成为稳定编码则必须需要注意资源参与(Pollatsek et al.,2006),以往研究发现英语词n+1延迟60ms消失与其及时消失在相同程度上影响总阅读时间,显示注意资源以串行方式在相邻词汇上转移,这意味英语读者以串行方式编码词汇(Reichle et al.,2009)。然而,以往中文消失文本阅读研究则发现,中文词 n+1延迟约 60ms后消失则不影响总阅读时间(刘志方等,2011),本研究则发现词n+1左侧汉字延迟75ms消失后消失不影响阅读效率,视角因素能够解释“为何词n+1右侧汉字延迟75ms消失后消失会影响总阅读时间”,按照串行加工假设,注意不能在注视开始的前75ms内由词n转移至词n+1,因而本结果同样说明中文阅读中的注意资源并行地分布在相邻词汇上。由此可见,对于中文文字视觉编码方式的语言特殊性问题而言,英语读者采用序列方式对多个词汇进行视觉编码,他们在编码词n视觉信息时不能对词n+1视觉信息进行编码(Rayner et al.,2006;Reichle et al.,2009);而中文读者是以并行的方式编码词n+1上汉字的视觉信息,中文读者在编码词n视觉信息的同时能够编码词n+1的视觉信息,尽管这种编码仍停留在汉字层面上,但这显示中文书面文字编码机制的特殊性。
证据显示,一旦拼音文字视觉信息转换成为稳定的视觉编码,便可保证词汇的正常识别,可见拼音文字的词汇加工在有限的时间内(约为 55ms)依赖于视觉信息(Pollatsek et al.,2006)。而综合本研究的两项实验结果可知,中文词汇识别对视觉信息的依赖较为严重。理由是,根据实验一与以往研究结果可知,通常情况下中文读者可在注视词n的时间形成针对词n+1上两个汉字视觉信息的较为稳定的编码产品(刘志方等,2011);然而实验二发现,注视词(词 n)上的汉字及时消失仍会影响总阅读时间,这意味预视阶段内所完成的汉字视觉编码并不能够支撑随后的、注视阶段内的词汇识别过程,中文读者仍需要在注视阶段继续编码相应的视觉信息,以形成词汇层面上的编码,进而保证阅读理解正常进行。中文阅读中文字视觉信息的编码过程存在先后两个阶段。这种特点也说明相对于拼音文字阅读中词汇识别过程,中文阅读中的词汇识别过程对视觉信息依赖程度较重。
综上可知,本文揭示中文阅读中文字视觉信息的编码过程存在以下特点:1中文阅读中的字词视觉信息编码是个双阶段的编码过程,2读者能够并行编码汉字视觉信息但却只能逐个获取词汇水平上的视觉编码,3整个词汇加工过程对视觉信息的依赖较重。总的来说,这些特点说明,相对于拼音文字(比如英语),中文读者识别词汇的加工过程较为特殊,且中文是种更加切底的视觉性文字(Zhou&Marslen-Wilson,2000;Perfetti et al.,2005;Yan et al.,2015;张学新等,2012)。当然,本研究不能穷尽表达中文书面语言认知的语言特殊性特点,其他方面的语言特殊性特点仍需要广泛研究。
4.3 中文阅读中字词视觉编码过程的语言普遍性
研究中文阅读任务中的视觉信息编码过程的语言特殊性,有利于最终了解其内部机制,并反馈到认识人类普遍的阅读行为机制中。中文阅读中词汇视觉编码过程符合语言普遍性规律也主要表现在汉字加工与词汇加工两个层面。对于中文阅读而言,尽管大都研究将中文词汇对应拼音文字的词汇,而不是将单个汉字对应单个字母或者字母组合(马国杰,李兴珊,2012),但可以确定的是,多字词中的单字与拼音文字中的字母都属于“词汇”单位的下级构成,从这个意义上讲两者有较大的共同之处。拼音文字阅读中所产生的共识是,读者是以平行的方式加工词汇内部的字母(Schad &Engbert,2012;Schotter et al.,2014)。而本研究结果提示,中文阅读中的汉字视觉编码过程亦是遵循并行加工原则,由此可知,词汇下级符号单元的识别加工方式问题上,中文阅读基本符合语言普遍性规律。而本研究所揭示的词汇识别层面上的语言普遍性特点主要是,中文与拼音文字阅读中都存在基于词汇单位的视觉编码过程(Pollatsek et al.,2006)。从获得词汇层面上视觉编码的方式来看,中文阅读与英语阅读相似,也即是两种语言的读者都是以序列方式获取词汇层面上的视觉编码。
理解中文阅读中的文字识别机制问题,必须兼顾中文的语言特殊性及其普遍性特点。本文从视觉编码角度探究上述问题,结果显示中文读者以并行方式编码多个汉字的视觉信息,但词形视觉编码只能以序列的方式获得。目前有假设模型认为,中文多字词识别中包含汉字与词汇两个加工阶段,读者并行地加工词内多个汉字,但却以串行的方式识别词汇(Li et al.,2009;李兴珊等,2011)。视觉编码是文字识别加工必经的首要阶段,本研究揭示的词汇视觉编码过程特点符合上述模型的假设,这就将关于字词加工方式的观点推演至视觉编码层面;本研究显示中文文字识别加工对视觉信息的依赖性较重,这些发现对验证和发展中文阅读字词识别模型都有重要的参考价值。对于词汇方式(并行加工还是串行加工?)问题而言,一种折中的观点认为,词汇加工的早期阶段以并行方式进行,而在晚期则遵循串行的方式(Engbert et al.,2005)。本研究发现,预视阶段中文读者并行编码词内汉字,注视阶段才能逐个实现对整词的视觉编码,这显然为调和串行与并行加工之争提供了证据。当然,对于中文阅读中词汇加工的语言特殊性与普遍性主题而言,仍需要大量的深入研究。
5 结论
中文阅读中对特定词汇进行的视觉编码可被区分成两个阶段:预视中读者针对词汇进行其内部汉字的视觉编码,注视中读者针对词汇进行整词视觉编码。
Baayen,R.H.,Davidson,D.J.,&Bates,D.M.(2008).Mixed-effects modeling with crossed random effects for subjects and items.Journal of Memory and Language,59
(4),390–412.Bai,X.J.,Meng,H.X.,Wang,J.X.,Tian,J.,Zang,C.L.,&Yan,G.L.(2011).The landing positions of dyslexic,age-matched and ability-matched children during reading spaced text.Acta Psychologica Sinica,43
(8),851–862.[白学军,孟红霞,王敬欣,田静,臧传丽,闫国利.(2011).阅读障碍儿童与其年龄和能力匹配儿童阅读空格文本的注视位置效应.心理学报,43
(8),851–862.]Bai,X.J.,Liang,F.F.,Blythe,H,I.,Zang,C.L.,Yan,G.L.,&Liversedge,S.P.(2013).Interword spacing effects on the acquisition of new vocabulary for readers of Chinese as a second language.Journal of Research in Reading,36
(S1),S4−S17.Bai,X.J.,Yan,G.L.,Liversedge,S.P.,Zang,C.L.,&Rayner,K.(2008).Reading spaced and unspaced Chinese text:Evidence from eye movements.Journal of Experimental Psychology:Human Perception and Performance,34
(5),1277−1287.Barr,D.J.,Levy,R.,Scheepers,C.,&Tily,H.J.(2013).Random effects structure for confirmatory hypothesis testing:Keep it maximal.Journal of Memory and Language,68
(3),255–278.Bates,D.,Maechler,M.,&Bolker,B.(2011).LME4:Linear mixed-effects models using S4 classes.R Package Version 0.999375–39.Retrieved from http://CRAN.R-project.org/package=lme4
Blythe,H.I.,Häikiö,T.,Bertam,R.,Liversedge,S.P.,&Hyönä,J.(2011).Reading disappearing text:Why do children refixate words?Vision Research,51
(1),84−92.Blythe,H.I.,Liang,F.F.,Zang,C.L.,Wang,J.X.,Yan,G.L.,Bai,X.J.,&Liversedge,S.P.(2012)Inserting spaces into Chinese text helps readers to learn new words:An eye movement study.Journal of Memory and Language,67
(2),241–254.Blythe,H.I.,Liversedge,S.P.,Joseph,H.S.S.L.,White,S.J.,&Rayner,K.(2009).Visual information capture during fixations in reading for children and adults.Vision Research,49
(12),1583–1591.Devlin,J.T.,Jamison,H.L.,Matthews,P.M.,&Gonnerman,L.M.(2004).Morphology and the internal structure of words.Proceedings of the National Academy of Sciences of the United States of America,101
(41),14984–14988.Engbert,R.,Longtin,A.,&Kliegl,R.(2002).A dynamical model of saccade generation in reading based on spatially distributed lexical processing.Vision Research,42
(5),621–636.Engbert,R.,Nuthmann,A.,Richter,E.M.,&Kliegl,R.(2005).SWIFT:A dynamical model of saccade generation during reading.Psychological Review,112
(4),777–813.Li,X.S.,Bicknell,K.,Liu,P.P.,Wei,W.,&Rayner,K.(2014).Reading is fundamentally similar across disparate writing systems:A systematic characterization of how words and characters influence eye movements in Chinese reading.Journal of Experimental Psychology:General,143
(2),895−913.Li,X.S.,Gu,J.J.,Liu,P.P.,&Rayner,K.(2013).The advantage of word-based processing in Chinese reading:Evidence from eye movements.Journal of Experimental Psychology:Learning,Memory,and Cognition,39
(3),879–889.Li,X.S.,Liu,P.P.,&Ma,G.J.(2011).Advances in cognitive mechanisms of word segmentation during Chinese reading.Advances in Psychological Science,19
(4),459–470.[李兴珊,刘萍萍,马国杰.(2011).中文阅读中词切分的认知机理述评.心理科学进展,19
(4),459–470.]Li,X.S.,Rayner,K.,&Cave,K.R.(2009).On the segmentation of Chinese words during reading.Cognitive Psychology,58
(4),525–552.Liu,Z.F.,Wen,S.H.,&Zhang,F.(2014).Analysis of age characteristics on visual coding in Chinese reading:Evidence from eye movements.Psychological Development and Education,30
(4),411−419.[刘志方,翁世华,张锋.(2014).中文阅读中词汇视觉编码的年龄特征:来自眼动研究的证据.心理发展与教育,30
(4),411−419.]Liu,Z.F.,Zhang,Z.J.,&Yang,G.F.(2015).Test the activation model of transforming characters to words in Chinese reading:Evidence from delay word-boundary effects.Acta Psychologica Sinica,
48(9),1082–1092.[刘志方,张智君,杨桂芳.(2015).中文阅读中的字词激活模式:来自提示词边界延时效应的证据.心理学报,48(9),1082–1092.]
Liu,Z.F.,Zhang,Z.J.,&Zhao,Y.J.(2011).The units saccade targeting based on and words procession style in Chinese reading:Evidences from disappearing text.Acta Psychologica Sinica,43
(6),608–618.[刘志方,张智君,赵亚军.(2011).汉语阅读中眼跳目标选择单元以及词汇加工方式:来自消失文本的实验证据.心理学报,43
(6),608–618.]Liversedge,S.P.,Rayner,K.,White,S.J.,Vergilino-Perez,D.,Findlay,J.M.,&Kentridge,R.W.(2004).Eye movements when reading disappearing text:Is there a gap effect in reading?Vision Research,44
(10),1013−1024.Ma,G.J.,&Li,X.S.(2012).Attention allocation during reading:Sequential or parallel.Advances in Psychological Science,20
(11),1755–1767.[马国杰,李兴珊.(2012).阅读中的注意分配:序列与平行之争.心理科学进展,20
(11),1755–1767.]Ma,G.J.,Li,X.S.,&Rayner,K.(2015).Readers extract character frequency information from nonfixated-target word at long pretarget fixations during Chinese reading.Journal of Experimental Psychology:Human Perception and Performance,41
(5),1409–1419.Perfetti,C.A.,Liu,Y.,&Tan,L.H.(2005).The lexical constituency model:Some implications of research on Chinese for general theories of reading.Psychological Review,112
(1),43–59.Pollatsek,A.,Reichle,E.D.,&Rayner,K.(2006).Tests of the E-Z Reader model:Exploring the interface between cognition and eye-movement control.Cognitive Psychology,52
(1),1–56.Rayner,K.(1998).Eye movements in reading and information processing:20 years of research.Psychological Bulletin,124
(3),372–422.Rayner,K.,Liversedge,S.P.,&White,S.J.(2006).Eye movements when reading disappearing text:The importance of the word to the right of fixation.Vision Research,46
(3),310−323.Rayner,K.,Liversedge,S.P.,White,S.J.,&Vergilino-Perez,D.(2003).Reading disappearing text:Cognitive control of eye movements.Psychological Science,14
(4),385−388.Rayner,K.,Yang,J.M.,Castelhano,M.S.,&Liversedge,S.P.(2010).Eye movements of older and younger readers when reading disappearing text.Psychology and Aging,26
(1),214–223.Reichle,E.D.,Liversedge,S.P.,Pollatsek,A.,&Rayner,K.(2009).Encoding multiple words simultaneously in reading is implausible.Trends in Cognitive Sciences,13
(3),115−119.Reichle,E.D.,Pollatsek,A.,&Rayner,K.(2006).E-Z
Reader:A cognitive-control,serial-attention model of eye-movement behavior during reading.Cognitive Systems Research,7
(1),4−22.Reichle,E.D.,Rayner,K.,&Pollatsek,A.(2003).The E-Z reader model of eye-movement control in reading:Comparisons to other models.Behavioral and Brain Sciences,26
(4),445−476.Reilly,R.G.,&Radach,R.(2006).Some empirical tests of an interactive activation model of eye movement control in reading.Cognitive System Research,7
(1),34−55.Schad,D.J.,&Engbert,R.(2012).The zoom lens of attention:Simulating shuffled versus normal text reading using the SWIFT model.Visual Cognition,20
(4-5),391–421.Schotter,E.R.,Reichle,E.D.,&Rayner,R.(2014).Rethinking parafoveal processing in reading:Serial attention models can explain semantic preview benefit andN
+2 preview effects.Visual Cognition,22
(3-4),309–333.Shen,D.L.,Bai,X.J.,Zang,C.L.,Yan,G.L.,Feng,B.C.,&Fang,X.H.(2010).Effect of word segmentation on beginners' reading:Evidence from eye movement.Acta Psychologica Sinica,42
(2),159–172.[沈德立,白学军,臧传丽,闫国利,冯本才,范晓红.(2010).词切分对初学者句子阅读影响的眼动研究.心理学报,42
(2),159−172.]Shen,D.L.,Liversedge,S.P.,Tian,J.,Zang,C.L.,Cui,L.,Bai,X.J.,… Rayner,K.(2012).Eye movements of second language learners when reading spaced and unspaced Chinese text.Journal of Experimental Psychology:Applied,18
(2),192–202.Shen,W.,&Li,X.S.(2012).The uniqueness of word superiority effect in Chinese reading.Chinese Science Bulletin,57
(35),3414–3420.[申薇,李兴珊.(2012).中文阅读中词优效应的特异性.科学通报,57
(35),3414–3420.]Su,H.,Liu,Z.F.,&Cao,L.R.(2016).The effects of word frequency and word predictability in preview and their implications for word segmentation in Chinese reading:Evidence from eye movements.Acta Psychologica Sinica,48
(6),625–636.[苏衡,刘志方,曹立人.(2016).中文阅读预视加工中的词频和预测性效应及其对词切分的启示:基于眼动的证据.心理学报,48
(6),625–636.]Tan,L.H.,Spinks,J.A.,Eden,G.F.,Perfetti,C.A.,&Siok,W.T.(2005).Reading depends on writing,in Chinese.Proceedings of the National Academy of Sciences of the United States of America,102
(24),8781–8785.Yan,G.L.,Liu,N.N.,Liang,F.F.,Liu,Z.F.,&Bai,X.J.(2015).The comparison of eye movements between Chinese children and adults when reading disappearing text.Acta Psychologica Sinica,47
(3),300−318.[闫国利,刘妮娜,梁菲菲,刘志方,白学军.(2015).中文读者词汇视觉信息获取速度的发展——来自消失文本的证据.心理学报,47
(3),300−318.]Yan,G.L.,Tian,H.J.,Bai,X.J.,&Rayner,K.(2006).The effect of word and character frequency on the eye movements of Chinese readers.British Journal of Psychology,97
(2),259–268.Yan,M.,Zhou,W.,Shu,H.,&Kliegl,R.(2015).Perceptual span depends on font size during the reading of Chinese sentences.Journal of Experimental Psychology:Learning,Memory,and Cognition,41
(1),209–219.Yang,S.N.,&McConkie,G.W.(2004).Saccade generation during reading:Are words necessary?European Journal of Cognitive Psychology,16
(1-2),226−261.Zhang,X.X.,Fang,Z.,Du,Y.C.,Kong,L.Y.,Zhang,Q.,&Xing,Q.(2012).Centro-parietal N200:An event-related potential component specific to Chinese visual word recognition.Chinese Science Bulletin,57
(13),1516−1532.[张学新,方卓,杜英春,孔令跃,张钦,邢强.(2012).顶中区 N200:一个中文视觉词汇识别特有的脑电反应.科学通报,57
(5),332−347.]Zhou,X.L.,&Marslen-Wilson,W.(2000).The relative time course of semantic and phonological activation in reading Chinese.Journal of Experimental Psychology:Learning,Memory,and Cognition,26
(5),1245−1265.猜你喜欢
新高考·高二数学(2022年3期)2022-04-29
新高考·高二数学(2022年3期)2022-04-29
中国典型病例大全(2022年7期)2022-04-22
青少年科技博览(中学版)(2020年7期)2020-08-06
计算机应用(2016年10期)2017-05-12
小学阅读指南·低年级版(2016年10期)2016-09-10
红领巾·萌芽(2016年6期)2016-05-14
求学·理科版(2015年10期)2015-11-04
中国计算机报(2009年27期)2009-04-27
