
基于ε-SVR的风筛式清选装置清选性能预测研究
2018-04-12 00:55梁振伟李耀明魏纯才王建鹏
农机化研究 2018年4期
梁振伟,李耀明,周 全,马 征,魏纯才,王建鹏
(江苏大学 现代农业装备与技术教育部重点实验室,江苏 镇江 212013)
0 引言
收获机械的清选性能评价是多目标、多层次、多因素的,评价关系是模糊非线性的,至今没有一种统一的确定预测模型。以往建立的关于清选预测模型主要运用回归分析法[1]及人工神经网络法[2]等,都是基于传统的经验风险最小化原则(ERM),对于大样本能给出较好的结果;但传统的试验研究需要耗费相当多的人力物力,同时在具有小样本的清选性能预测中,ERM原则并不能保证期望预测风险最小化。为此,拟借助在统计学习理论的基础上发展的分支支持向量机(Support Vector Machine,SVM)建立精度高、泛化能力强、随机波动性小的清选性能预测模型。
支持向量机方法属于机器学习理论发展的最新阶段,首先是着眼于解决分类(模式识别)问题,通过引入不敏感损失函数ε的概念,也可以解决线性与非线性函数的回归问题[3]。SVM的核心是基于VC维理论和结构风险最小化的原则,优点是可专门针对有限样本,其目标是得到现有信息下的最优解,算法最终转化为一个对偶寻优问题,得到的将是全局最优解。它避免了人工神经网络等方法的网络样本需求大、结构选择、过学习和欠学习、局部极小等问题。
以油菜联合收获机的清选装置为研究对象,运用支持向量模型,描述其清选性能输出与多个清选参数输入之间的关系,具有算法复杂度与样本维数无关等优点[4]。因此,探讨将支持向量机理论引入清选装置的清选性能研究中具有重要意义。
1 支持向量机的理论基础
支持向量机训练的实质为求解一个带有界约束和线性等式约束的凸二次规划问题。首先,通过非线性变换将输入空间变换到一个高维空间,甚至是一个无限维空间;然后,在这个高维空间求解。其中,非线性变换是通过核函数K的方法来实现的。选取SVM模型ε-Support Vector Regression (ε-SVR),给出一系列样本数据点,即{(x1,z1),…,(xi,zi)}。其中,xi∈Rn为n维的输入向量,而zi∈R1为输出向量。标准的支持向量机的回归模型由Vapnik于1995年提出[5],即
其中
Qij=K(xi,xj)≡φ(xi)Τφ(xj)
式中ω—函数系数;
C—惩罚参数;
ε—不敏感损失函数;

该模型等价于

近似的回归模型可以表示为
2 清选试验
2.1试验装置
油菜脱出物清选试验是在DF-1.5型物料清选仿真与控制装置上进行的,试验装置的结构简图如图1所示。
清选装置采用风筛式的结构,主要由离心风机、振动筛、机架、传动系统和传感器等组成。离心风机、振动筛分别由调速电机驱动,转速可以无级调节。试验台由曲柄连杆机构带动筛箱运动,曲柄为偏心轮型,通过曲柄半径的调节来实现筛箱振幅的变化。
2.2试验材料
清选试验使用的物料是油菜脱出混合物,主要成分为果荚壳、籽粒、短茎秆及轻杂质。为尽可能接近田间收获状态,所用物料都是刚从田间收割后经脱粒的脱出物,各成分所占比例为:果荚壳50%~53%,籽粒32%~34%,短茎秆8%~10%,轻杂质6%~8%。
2.3试验方案与结果
通过对风筛式清选装置清选机构及试验条件的分析,选择曲柄半径、曲柄转速、风机转速、出风口倾角、筛孔直径作为试验因素,分别用A、B、C、D、E表示。试验主要考察清选参数对清选效果H(包括清选含杂率F和清选损失率G)的影响,结合清选参数的最优值,每个参数设定3个水平数值,按照正交表L27(313)开展正交试验,试验方案及结果如表1所示。
为了研究样本容量大小对ε-SVR预测模型的影响并与BP模型进行比较,试验次数较多。在保证模型有意义的前提下,并不需要测定27组,可适当减小样本容量。
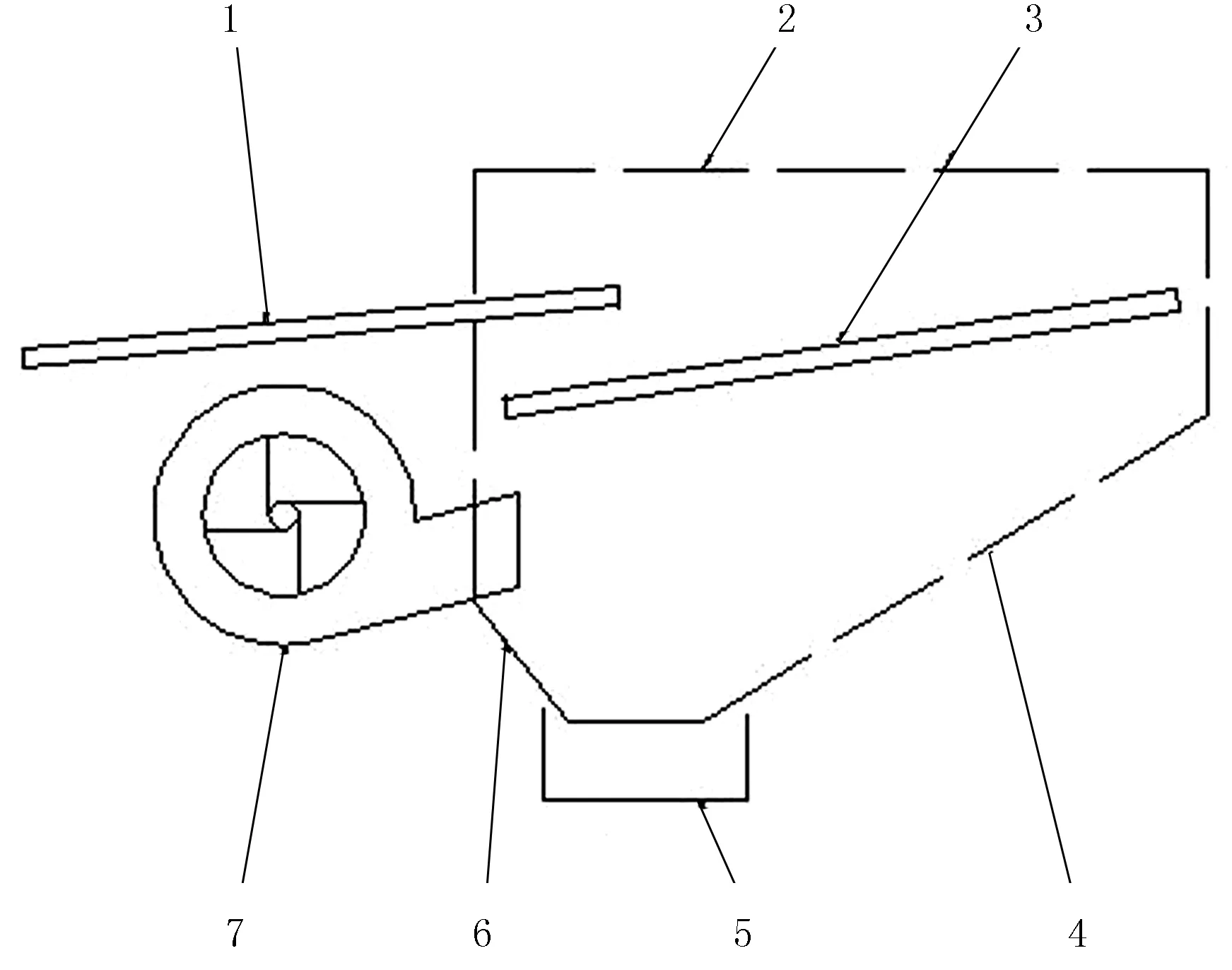
1.抖动板 2.罩壳3.振动筛 4.后滑板 5.集粮箱 6.前滑板 7.离心风机

序号因素A/mmB/r·min-1C/r·min-1D/(°)E/mm结果F/%G/%H/%1222608202062.24.483.1122222858602561.95.303.3603223109003061.457.533.8824262608603062.655.653.8145262859002061.754.852.9906263108202562.25.313.4507302609002562.56.644.1568302858203062.055.523.4389303108602061.67.063.78410222608202081.751.471.68311222858602581.752.341.986

续表1
3 参数建模
3.1模型的建立
由表1可知:试验有2个因变量F和G。采用权重系数法可将两个因变量转化为单个因变量H=t1F+t2G。根据经验以及经济效益,取权重系数t1=0.6,t2=0.4。在ε-SVR模型中,将总样本分为训练样本和测试样本两类。训练时以A、B、C、D、E作为输入,期望输出是对应H值。
采用支持向量机建立预测模型必须先选择合适的核函数。采用RBF(Radial Basic Function)核函数往往能够得到较好的拟合结果,且收敛速度较快,核参数g主要影响样本数据在高维特征空间中分布的复杂程度[6-7]。在训练数据前,先对原始样本进行数据规格化,并记录在相应的映射关系中,缩放范围为[0,1];在训练完毕后,对需要预测的数据再进行反归一化。缩放的目的主要是在核计算中,会用到内积运算或exp运算,不平衡的数据可能造成计算困难。
3.2回归预测ε-SVR参数ε、c、g的选择
ε-SVR算法的参数是指在求解对偶问题时需要预先设定的参数,包括惩罚参数c、不敏感损失函数ε及核参数g。ε-SVR模型中的参数基于交叉验证(Cross Validation,CV)的意义下寻参,常见的CV的方法有Hold-Out Method、 LOO-CV和K-CV等。第1种方法将原始数据随机分成两组,不能交叉验证;第2种方法集合所有样本用于训练模型,计算成本较高;第3种方法能避免“过学习”以及“欠学习”状态,K均分的组数一般大于等于2(标准K=10)。
采用CV方法进行参数优化的整体思路是:让c和g在一定范围内取值,对于取定的参数值,将训练集作为原始数据集,利用K-CV方法得到此组c和g下训练集验证均方误差MSE(Mean Squared Error),最终取使得训练集验证MSE低的一组c和g的取值作为最佳参数。
在CV意义下,用非启发式的网格划分(GridSearch Method)寻找最佳c和g值能搜索到全局最优解;但在参数较多或取值范围较大时,采用GA或PSO等启发式算法,CV意义下的MSE作为适应度函数。启发式算法不要求目标函数的凸性和目标的可微性,可以不必遍历格内的所有参数点,也能找到全局最优解。GA和PSO优化和初始值选取有关,每次优化的数值是上下浮动的,结果取其平均值。
不同模型清选性能比较如表2所示,清选性能预测对比如表3所示。表2和表3采用表1中1~25组的试验数据为训练集,其余26~27组为测试集,分别采用了BP神经网络、grid(cg)、ga(cg)和pso(cg)方法进行清选性能预测模型对比。利用GridSearch方法时,设定ε为定值,粗略估计c和g参数的范围分别为2-20~220,粗略选择的bestc=602 248.763 1,bestg=0.001 286,得到粗略选择的等高线图如图2所示。

表2 不同模型清选性能比较

表3 清选性能预测结果对比

图2 粗略选择对应的等高线图
MSE取值范围约为0.48~1e-007,1e-007对应的c和g值较佳,可以缩小参数的选择范围。1e-007主要集中在两个区域:c为2-2~210,g为22~210,c为2-2~210,g为2-5~23。其中,预测性能较好的为第1组,取其精细选择的参数建立相应的模型bestc=0.770 711,bestg=4,ε=0.01。
采用ga(cg)方法的参数为:bestc=1.842 2,bestg=546.867 9,ε=0.01;采用pso(cg)方法的参数为bestc=2.094 6,bestg=650.330 1,ε=0.01。其中,终止代数为200,种群数量为20。
3.3BP和ε-SVR对应预测性能比较
BP神经网络主体模型采用多层前馈网络,其中隐藏层和输出层的神经元数分别取为8和1,隐藏层和输出层的激发函数分别设为tansig、purelin,训练算法设为trainlm。
由表2可知:ga(cg)、pso(cg)训练集模型的均方误差比BP模型降低了2个数量级,比grid(cg)降低了接近2个数量级。与BP模型相比,ε-SVR模型的相关系数较高。其中,pso(cg)模型的相关系数最高,接近1。
表3给出了4种方法构造测试集的预测结果,将实际得到的清选性能值与模型输出值进行对比,结果表明:ε-SVR预测性能优于BP预测。其中,ga(cg)和pso(cg)方法预测值的相对误差比BP预测低1个数量级。
3.4样本容量对ga(cg)预测性能的影响
一般认为,对于普通多元回归,虽然在n≥k+1时就可以得到参数估计值(n为样本容量,k为自变量的个数),但为了提高参数估计量的有效性,应使n≥30或n≥2k(部分文献要求n≥3k),因此将不满足这3个条件的一组样本界定为小样本[8]。以上述ga(cg)方法为例,建立相应的模型,选用RBF核函数来研究样本容量大小对回归预测精度的影响。图3、图4和图5中选用第27组作为测试集,1-26组为训练集。样本容量n依次取8,10,…,24,26。对应的测试集的MSE值如图3所示,不同样本容量对应的BP和ga(cg)训练模型MSE值如图4所示,不同样本容量大小对应的BP和ga(cg)预测值如图5所示。

图3 不同样本容量大小对应的ga(cg)测试模型MSE值Fig.3 Test Set Regression MSE of samples in different by ga(cg)

图4 不同样本容量对应的BP和ga(cg)训练模型MSE值Fig.4 Train Set Regression MSE of samples in different by ga(cg) and BP

图5 不同样本容量大小对应的BP和ga(cg)预测值
由图3可知:MSE值随着样本容量的增加而递减并逐渐向0逼近;在控制MSE值时,可根据实际适当减少试验的次数,在试验数据缺失较多时可采用ε-SVR的方法进行回归预测。
由图4可知:不同样本容量大小对应ga(cg)方法训练集模型的MSE值均显著低于BP模型,训练集模型对应的MSE值能维持在10-5,BP训练集模型对应的MSE值随样本容量的增加波动较大。
由图5可知:随着样本容量的增加,用ga(cg)方法得到的预测值能逐渐逼近真实值,且预测值较稳定;用BP方法得到的预测值并不稳定,且随机性较强。
4 结论
1)基于非启发式GridSearch 方法寻求SVR模型最佳参数c和g时,采用等高线图的方式表达,更具直观性;启发式GA和PSO寻优预测精度更高,能有效避免凭经验选取参数的随机性和BP的结构性选择。
2)采用支持向量机能较好地描述多个参数对清选性能的影响,所得预测数值稳定性更强,预测精度更高,能适应“小样本、贫信息”的数据分析,具有良好的工程应用价值。
参考文献:
[1]夏利利,李耀明,徐立章.二次响应曲面模型在联合收割机清选气流场预测中的应用[J].农机化研究,2009,31(2) :125-127.
[2]李耀明,林恒善,陈进,等.基于神经网络的风筛式清选气流场研究[J].农业机械学报,2006,37(7) :197-198.
[3]Gunn S R. Support vector machine for classification and regression[R]. Southampton, UK:ISIS-1-18, University of Southampton,1998.
[4]陈永义,俞小鼎,高学浩,等.处理非线性分类和回归问题的一种新方法(I)—支持向量机简介[J].应用气象学报,2004,15(3):345-354.
[5]Vapnik V N. The nature of statistical learning theory[M]. New York: Springer-Verlag,1995.
[6]张晓东,毛罕平,陈秀花.基于PCA-SVR的油菜氮素光谱特征定量分析模型[J].农业机械学报,2009,40(4):161-165.
[7]李盼池,许少华.支持向量机在模式识别中的核函数特性分析[J].计算机工程与设计,2005,26(2):302-304.
ID:1003-188X(2018)04-0026-EA
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
筑路机械与施工机械化(2020年7期)2020-08-20
领导决策信息(2018年16期)2018-09-27
中国商论(2018年22期)2018-09-10
价值工程(2017年19期)2017-07-12
数学学习与研究(2017年3期)2017-03-09
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
