
基于鼠脑海马位置细胞与Q学习面向目标导航
2019-04-24 06:12何洪军
生物信息学 2019年1期
方 略,何洪军
(中国电子科技集团公司第二十一研究所,上海 200030)
1971年Dostrovsky和O’Keefe在位于鼠脑海马结构区域中发现了一种具有空间特异性放电特征的神经元细胞-位置细胞[1]。该细胞是鼠脑海马结构中的主要神经元,当大鼠自由运动到环境中的某一特定位置时,相应位置细胞会发生最大化放电活动,将位置细胞发生最大化放电活动所对应区域称为该位置细胞的“位置野”。人类大脑中同样发现了类似于大鼠位置细胞特性的细胞存在[2-3]。随着对位置细胞进一步生理学研究发现,位置细胞放电活动在大鼠面向空间目标导航发挥着关键作用,该细胞放电活动受环境因素影响。因此,研究外部环境对位置细胞放电活动影响,并将其和啮齿类动物空间导航联系起来具有重要意义。
1 模型生理学依据
位置细胞被发现以来,许多学者对该细胞进行了相关研究,由此提出了大量的位置细胞模型,主要包括有基于高斯函数的位置细胞模型[4],基于竞争学习位置细胞模型[5],基于独立成分分析位置细胞模型[6],基于自组织映射位置细胞模型[7]和基于卡尔曼滤波位置细胞模型[8]等。然而,以上所提到的模型并没有将外部线索(如视觉、嗅觉等)对位置细胞放电活动影响考虑在内。因为生理学实验研究发现将视觉线索移除后,位置细胞放电活动会发生强烈变化,位置细胞位置野变得不稳定,这就暗示了视觉线索对于位置细胞位置野的形成和位置野的稳定性具有重要影响[9]。在缺乏视觉线索的情况下,许多研究学者认为路径积分作为一种额外的机制使得大鼠能够在空间环境中自由导航[10]。然而,Save等人的实验表明当大鼠处于黑暗环境中进行自由导航时,单一的路径积分不足以维持位置细胞位置野的稳定性[11]。如果没有额外的视觉线索,随着大鼠自由探索环境,路径积分会导致大鼠在方向和距离上产生很大的累积误差。因此,这就需要通过来自于外部环境中具有稳定位置信息(视觉线索)的参考物来校正从而减小误差[12]。
研究发现,当大鼠在某一空间环境中自由探索该环境空间时,鼠脑海马结构中的各位置细胞会在各自对应的空间位置处发生最大化放点活动,即在各位置处产生相对应的“位置野”[13]。大鼠对空间环境自由探索完成后,在大鼠脑内形成了其对所处空间环境的认知地图,该认知地图是各位置细胞“位置野”联合表征得到的。认知地图表征空间环境,研究发现单凭该认知地图并不能够使大鼠来正确的预测其下一时刻的运动方向,即不能够完成面向空间环境某一目标导航的任务。随着研究不断深入,研究者发现大脑控制中心内侧前额叶皮层(Medial prefrontal cortex, mPFC)与海马之间的动态联系是大鼠正确预测其下一刻运动方向的关键所在[14-15]。大脑前额叶皮层中最主要的神经细胞是运动神经元,该神经元与大鼠的空间运动息息相关[16-17]。鼠脑海马中最主要的神经元细胞是位置细胞。大脑腹侧被盖区 (Ventral tegmental area, VTA)里主要存在的神经元细胞是多巴胺能神经元(Dopaminergic neurons)[18-19],该神经元细胞与奖励预测误差信号相关。它能够将接收到的信息传输至伏隔核 (Nucleus accumbens, NA)。研究发现大鼠脑海马中的信息主要传输至伏隔核,伏隔核和前额叶皮层之间的信息传递方式是双向纤维投射[20]。即伏隔核从海马接收空间环境信息,从大脑腹侧被盖区接收奖励预测误差信息,通过与前额叶皮层相互作用来正确预测大鼠下一时刻的运动方向。 大鼠面向目标的导航任务神经生理学依据是海马位置细胞与伏隔核神经元之间与奖励信号相关的突触调节, 伏隔核进一步将信息投射至大鼠前额叶皮层来实现大鼠正确预测下一时刻运动方向。大脑前额叶皮层中主要是运动神经元。海马中主要是位置细胞。基于此,利用位置细胞、运动神经元构建一种前馈神经网络模型,采用Q学习算法来实现大鼠面向目标导航任务。
2 方 法
2.1 视觉线索感官输入
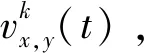
(1)
其中k表示的是四个不同颜色所标记的墙面,t表示的是时间。
考虑到实际因素,在视觉感知信息输入中添加一定的噪声信号,假定大鼠在空间环境中自由跑动时对于长距离估计会产生一定的误差。由公式(2)描述:
(2)
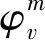

图1 实验环境Fig.1 Experimental environment
本文中,构建了一个由输入层、位置细胞、运动神经元(动作细胞)和输出层所组成的前馈神经网络模型来实现大鼠面向目标导航任务,前馈神经网络模型如图2所示。
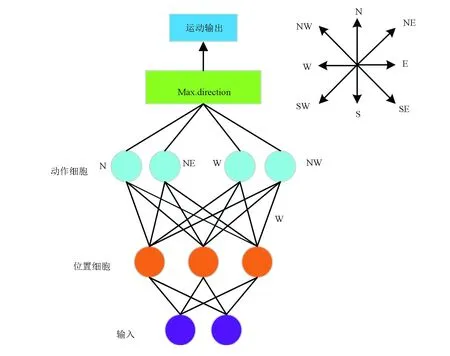
图2 前馈神经网络模型Fig.2 Feed-forward neural network model
2.2 位置细胞模型

(3)
其中,u是服从[0,1]之间均匀分布的随机值,v=0.5和σ=0.2。位置细胞放电率见公式(4),随机初始化权值,针对某一特定视觉输入信息通过竞争学习会激活位置细胞。
第i个位置细胞放电率由高斯函数表征[21],由公式(4)来描述:
(4)
其中,σf=0.07表示的是位置细胞位置野宽度。前馈神经网络模型中权重值调整依据胜者为王机制。即针对某一特定视觉输入信息,获胜的位置细胞神经元χt与该特定视觉输入信息之间权重值会进行相应调整,其余权重值不变。基于竞争学习获胜的位置细胞神经元χt用公式(5)来描述:
(5)
获胜神经元权重值按照公式(6)改变:
(6)
其中,0<α<<1代表的是学习效率因子。
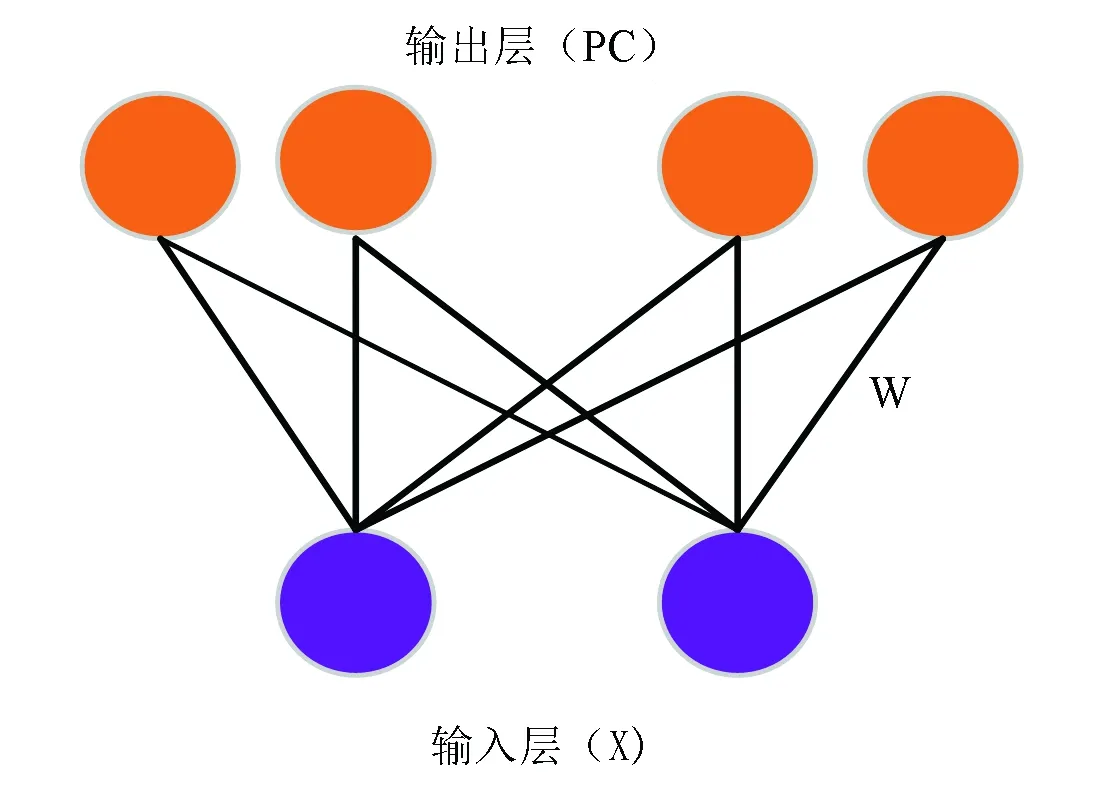
图3 位置细胞模型Fig.3 Model of place cells
2.3 目标导航任务
某一特定视觉输入信息通过竞争学习算法激活某些位置细胞神经元,激活位置细胞神经元与运动神经元通过Q学习算法可以得到大鼠下一时刻的运动方向。 大鼠在空间环境中不断学习直至能找到任一起始位置到目标位置之间导航的最短路径为止,大鼠空间导航示意如图4所示。使用如图1所示的实验环境,该实验环境的四面墙被不同颜色(黑色、紫色、红色和蓝色)所标记。大鼠运动的起始位置如图4中蓝色圆点标记所示。目标点位置如图4中红色正方形所示。当大鼠刚进入到实验环境中时,它是在随机探索环境的过程中找到目标位置(如图4中黑色虚线所示)。当大鼠经过长时间的学习后,就能够快速实现起始位置到目标位置的最短路径导航。
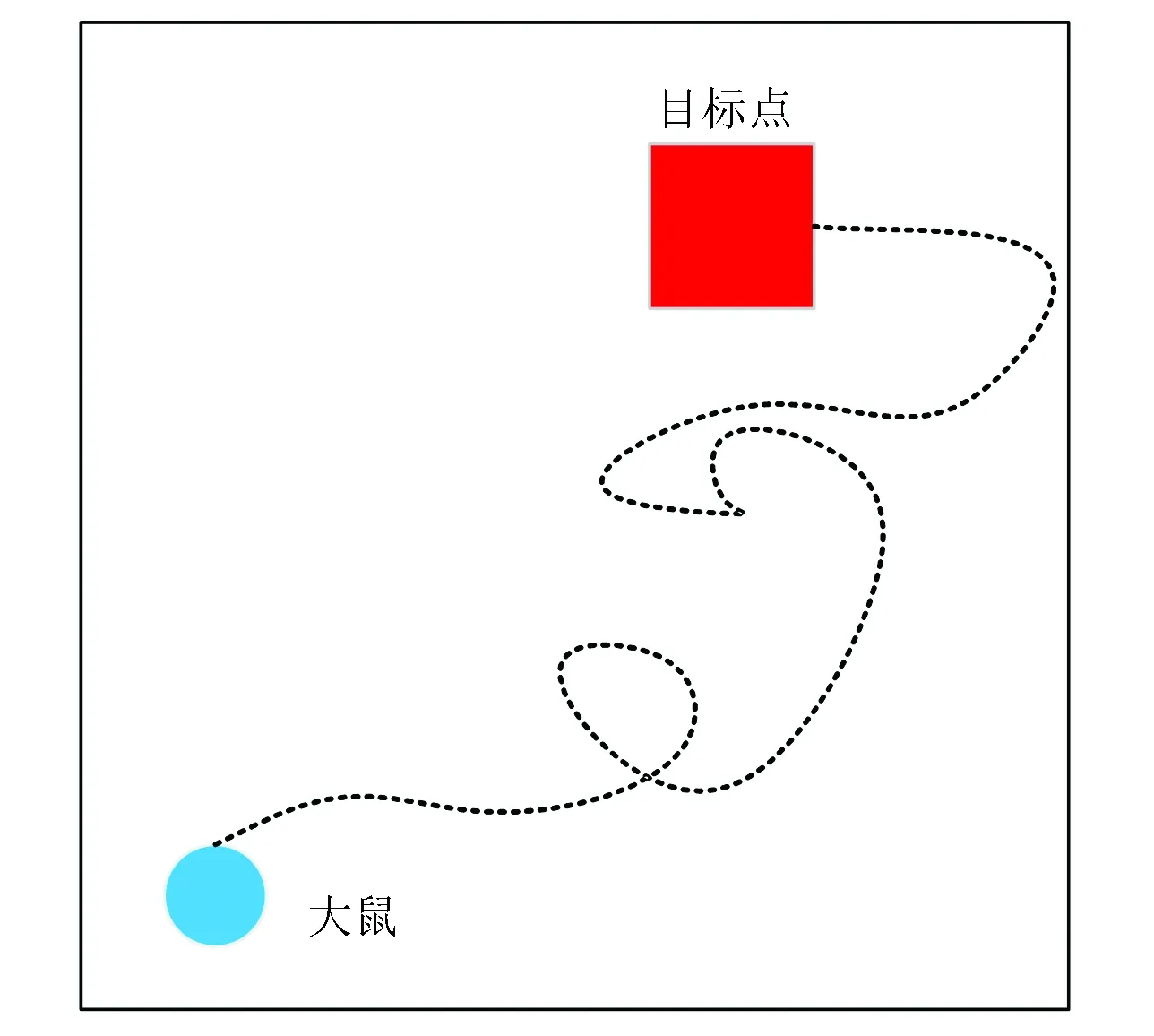
图4 大鼠空间导航示意图Fig.4 Schematic diagram of spatial navigation in rat’s brain
注:彩图见电子版:http://swxxx.alljournals.cn/ch/index.aspx.(2019年第1期).
本文中使用Q学习算法对大鼠空间导航进行研究。该算法应用在如图5所示的两层前馈神经网络模型中,位置细胞作为两层前馈神经网络的输入层,分别与8个运动神经元连接(该8个运动神经元分别代表8个不同方向(北(N),东北(NE),东(E),东南(SE),南(S),西南(SE),西(W),西北(NW))。通过Q学习算法计算得到以上8个方向的Q值,Q值最大的方向就是大鼠下一时刻的运动方向。大鼠向正西和正东的运动由公式(7)和(8)来描述:
Δx=±(Δs+c·ψx)
(7)
Δy=c·ψy
(8)
其中,Δs=500 表示的是大鼠步幅大小,ψx和ψy是服从[-1,1]均匀分布的随机值,c=100表示的是噪声幅值。负号代表大鼠向正西运动,正号代表大鼠向正东运动。同样的,大鼠在西南和东北方向的运动由公式(9)和(10)来描述:
(9)
(10)
当大鼠随机探索空间环境的过程中运动到某一位置时计算所得Q值是0时,大鼠在当前位置下一时刻的运动方向是不确定,它在当前位置保持方向不变的概率为1-pk,在当前位置选择一个新方向运动的概率为pk=0.25。当计算的Q值不为0时,大鼠的下一时刻的运动方向由Q值来确定的。

图5 由输入层(位置细胞)、运动神经元构建的前馈网络模型示意图Fig.5 Feed-forward network model of the input layer (place cells) and motor neurons
位置细胞到动作细胞学习机制是Q学习算法。简便起见,将t时刻第i个位置细胞放电率由公式(11)来描述:
(11)
其中,i=1,…,Q,Q=500表示的是神经网络模型中位置细胞总数。
由公式(12)来定义动作值函数:
(12)
其中,Γi,a表示的是第i个位置细胞与运动神经元a之间的连接权重值。根据Reynolds所提及的使用平均Q学习规则[22]。即按照公式(13)更新t时刻真正产生动作at的权值Γi,at。
Γi,at=Γi,at+β(δmaxaA(rt+1,at+1)+Rt+1-Γi,at)Ψi(rt)
(13)
其中,β=0.7表示的是学习率,δ=0.7表示的是折减系数,R表示的是奖励。将奖励函数Rt由函数(14)来描述:
(14)
3 实验结果
实验过程是大鼠刚进入到实验环境中时,它是在随机探索环境的过程中找到目标位置。当大鼠经过长时间的学习后,就能够快速实现起始位置到目标位置的最优路径导航,实验结果如图6、图7、图8和表1所示。本次实验中大鼠一共进行了40轮实验。图6是前20轮实验结果示意图,图7是后20轮实验结果示意图。由图6和图7可以很直观的看出在前8轮实验中大鼠由于刚进入到一个比较陌生的环境中,它只能随机的去探索目标位置,其运动轨迹是随机的,当它经过一段的时间学习后对其所处空间环境有了学习认知,便能够从第9轮实验开始找到从起始位置到目标位置的最优路径。图8是40轮实验过程中每轮实验大鼠到达目标位置所需步数示意图,由该图也能很直观的看出从第9轮实验开始大鼠能够找到从起始位置到目标位置的最优路径。表1是大鼠基于Q学习面向目标导航迭代次数与到达目标位置所需步数对应关系表。由该表能够直观的看出前8轮实验中由于大鼠随机探索环境,此时它到达目标位置所走步数是随机的没有规律可循的,当经过一段时间学习后,它到达目标位置的步数是基本稳定的,由表1可知从第9轮实验开始,大鼠到达目标位置所走步数大约为20步。
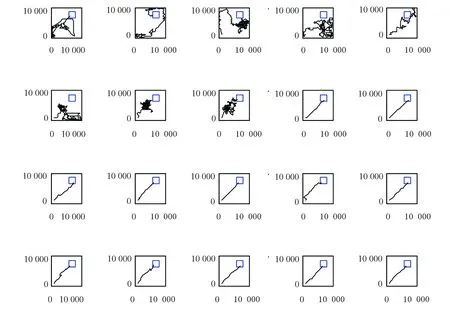
图6 大鼠前20次运行轨迹Fig. 6 Trajectories of the rat’s paths from the first 20 runs
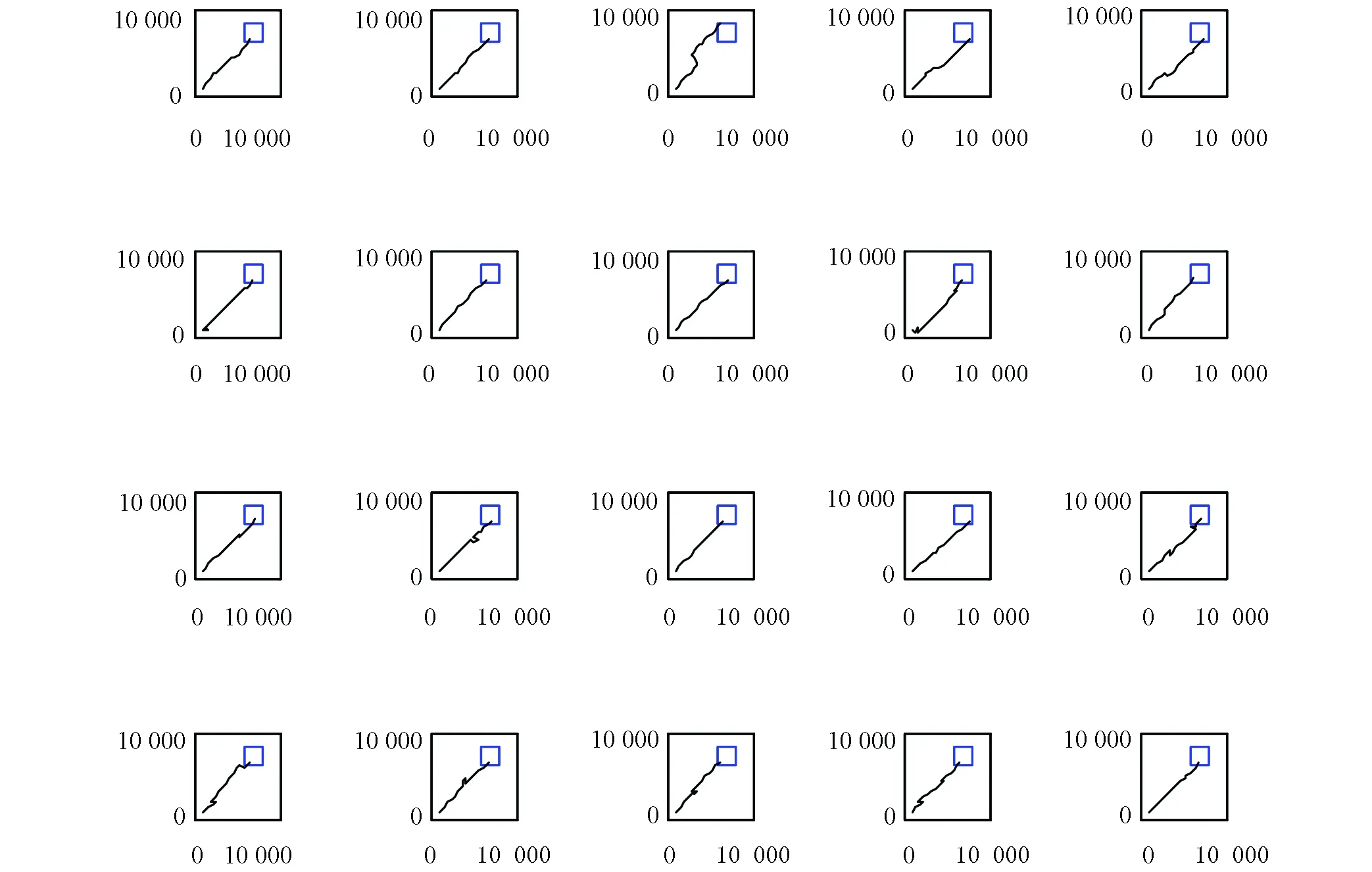
图7 大鼠后20次运行轨迹Fig. 7 Trajectories of the rat’s paths from the last 20 runs
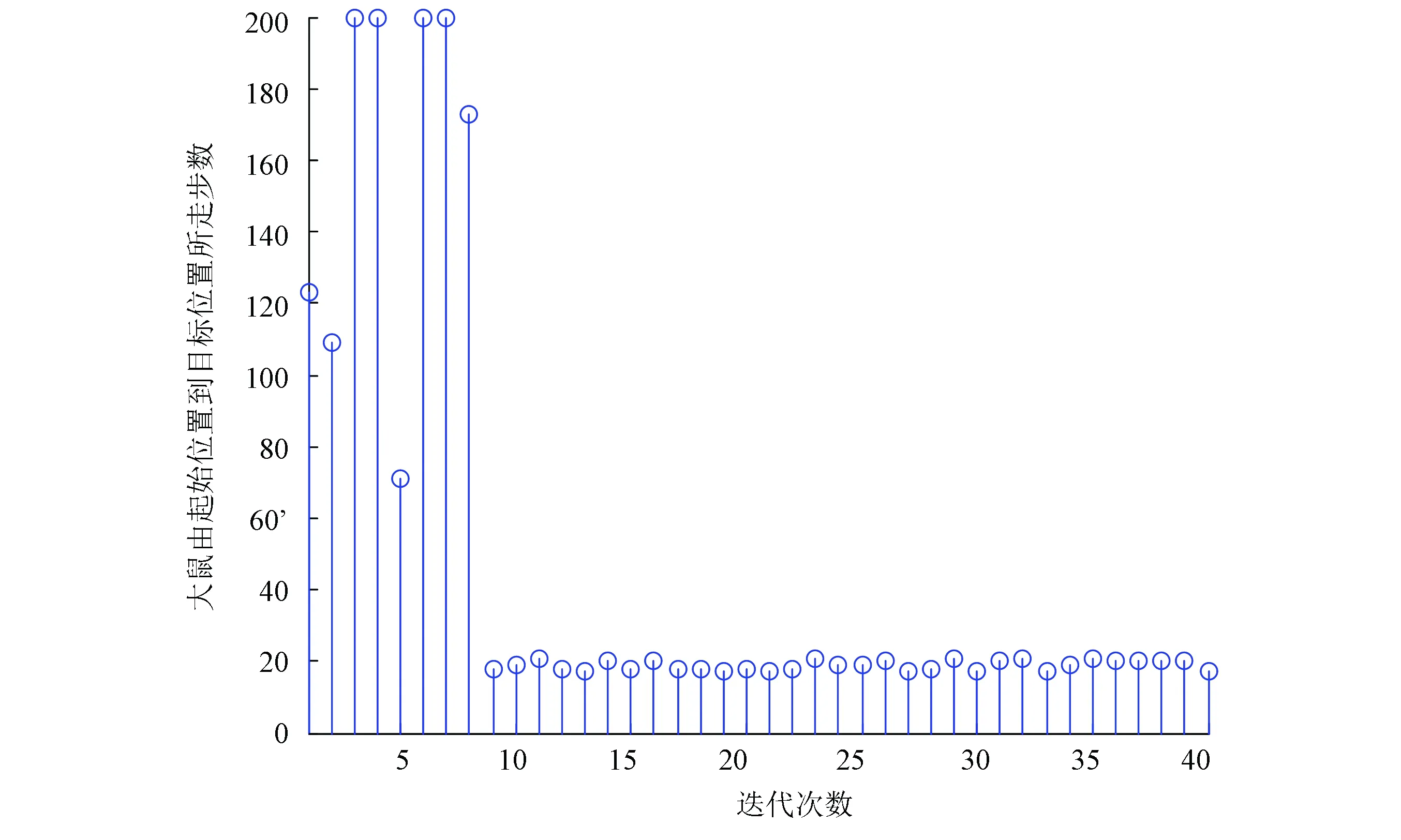
图8 大鼠到达目标位置所需步数示意图Fig. 8 The number of steps needed to reach the target position for the rat
4 结 论
强化学习算法主要是应用于解决学习类任务当中,针对仿生学上又主要分为两类,一类是用于鼠脑海马仿生导航中[23-26],另一类是仿生机器人在某一特定空间环境中通过强化学习来认知所处空间环境,进而与环境交互执行相关动作[27-30]。本研究充分表明了基于位置细胞、运动神经元来构建一种前馈神经网络模型,采用Q学习算法能够快速实现大鼠面向目标导航任务。

表1 大鼠基于Q学习面向目标导航迭代次数与到达目标位置所需步数对应关系Table 1 Corelation between the number of iterations of the good-oriented navigation based on Q learning and the number of steps needed to reach the target position
猜你喜欢
大科技·百科新说(2021年1期)2021-03-29
考试与评价·高二版(2020年2期)2020-09-10
动漫界·幼教365(中班)(2020年8期)2020-06-29
现代装饰(2018年5期)2018-05-26
中外医疗(2015年16期)2016-01-04
中国生化药物杂志(2015年4期)2015-07-07
弹箭与制导学报(2015年1期)2015-03-11
郑州大学学报(医学版)(2015年2期)2015-02-27
中国实用医药(2015年36期)2015-02-01
中医研究(2013年9期)2013-03-11
