
结合领域知识的影视文本关键词提取算法研究
2022-10-31 13:26刘嘉恩
北京石油化工学院学报 2022年3期
王 芳,刘嘉恩,李 晶
(北京石油化工学院信息工程学院,北京 102617)
关键词是由单个词或词组构成的一个具有重要意义的词语表达[1],反应文档的主题思想和主要内容。除学术论文包含关键词外,网络中的海量文档并没有关键词。提取关键词能帮助读者快速地掌握一篇文本的主题;高效、准确、快速地提取关键词,有助于满足人们对信息质量的核心要求;要进行海量文档的信息检索,首先需要解决的就是文档关键字的自动提取。因此,关键词提取是文本挖掘领域一个重要分支,广泛应用于文档索引、摘要生成、文本分类和信息检索等领域。
关键词提取技术的研究起步较早,至今已经历50多年的发展历程,国内外学者已经进行了很多颇有价值和成效的研究[2-3]。根据是否需要有标注的训练数据,将已有方法分为有监督和无监督2类:有监督的关键词提取技术需要有标注数据,将关键词提取转化为是否为关键词的分类问题,采用机器学习的方法构建分类模型,包括基于统计机器学习和基于深度学习的方法[4-6];无监督的关键词提取方法无需标注数据,基于图和话题等技术对候选词进行排序[7-9],提取排序靠前的词作为关键词。
已有研究大多关注于关键词特征及提取模型设计,针对特定领域的关键词提取研究较少。诸多领域内的文本数据通常都呈现出词语专业性强、缺乏文本标注(无监督)的特点,导致这些领域内的关键词提取较为困难。韦婷婷等[6]针对中文专利关键词,设计了一种融合长短期记忆(LSTM)神经网络和逻辑回归模型的关键词抽取方法,解决了传统方法难以发现低频、长尾关键词的问题;毛立琦等[10]针对风险领域文本,提出基于领域自适应的领域文本关键词提取模型。相关研究忽略了领域知识对关键词提取的作用。
因此,笔者基于图的无监督关键词提取技术,以影视领域文本(如影讯、影评等)为例,研究如何结合领域知识辅助关键词提取。针对其词汇领域性强、影视名称较长等特点,构建影视领域词表用作分词词表,避免分词错误造成的关键词误判;利用影视知识库中影视名、演员、导演等丰富的语义知识,结合候选词共现信息构建候选词关系图;基于影视知识库计算候选词语义相似性,与经典的图排序算法PageRank[11]、TextRank[12]和PositionRank[13]相结合,优化候选词排序,从而更有效地实现无监督影视领域文本关键词的自动提取任务。
1 影视领域知识挖掘
研究领域知识对关键词提取的作用,首先需要构建领域知识。采用知识图谱的方法构建影视领域知识图谱MKG=(V,E)[14],其中V是影视知识图谱的节点集合,由影视名称、角色、导演、演员等影视领域实体构成;E={(vi,rk,vj)│vi,vj∈V,rk∈R}为影视实体关系集合,每一个实体关系是一个三元组(vi,rk,vj)表示vi和vj之间存在关系rk,其中R为实体关系类型集合,如演员“吴京”和“长津湖”电影存在主演关系,形式化地表示为三元组(“吴京”,主演,“长津湖”)。影视领域知识图谱MKG的构建主要包括3部分:影视领域关系类型定义、影视领域实体抽取和影视领域关系抽取。
以豆瓣影视网站为数据源,首先定义实体关系类型为R={“影视剧”,“明星”,“角色”,“导演”,“编剧”,“主演”,“类型”,“别名”,“饰演”};其次采用结构化信息抽取的方式提取影视领域实体和实体关系,如图1所示。

图1 影视领域知识抽取网页信息示意图Fig.1 Web page information extraction for domain knowledge of film and television
基于Python语言利用Scrapy网络爬虫框架提取豆瓣影视网站的结构化网页信息,所有提取的三元组构成关系集合,所有三元组中的实体构成实体集合,所构建影视领域知识图谱示意图如图2所示。
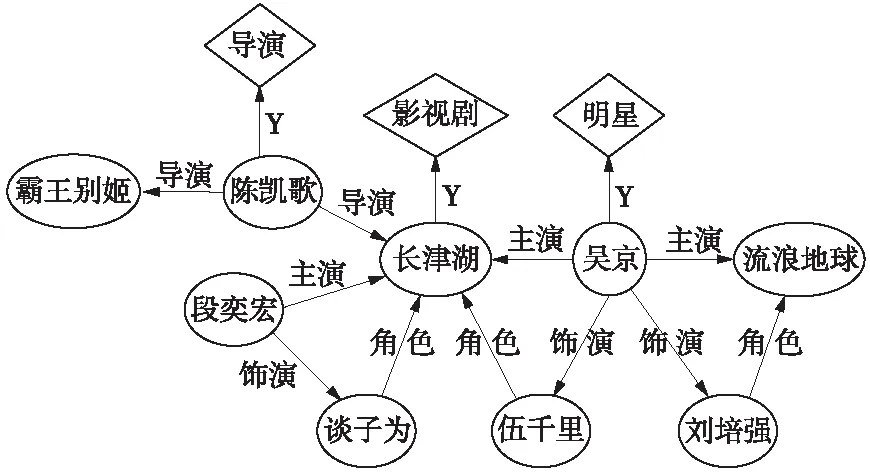
图2 影视领域知识图谱MKG中的实体-关系示意图Fig.2 Samples of entity-relationships in MKG
2 影视文本关键词提取模型
针对影视文本设计关键词提取的模型框架如图3所示。模型主要包含候选词生成、词网络构建和关键词排序3个模块。

图3 结合领域知识的影视文本关键词提取模型框架Fig.3 The framework of the keyword extraction model based on domain knowledge
2.1 候选词生成
对于给定影视文本,生成候选关键词通常是关键词提取的第1步。由于中文字与字之间没有明细的分割标志,词长也各有不同,对中文文本进行有效分词是生成候选词的关键。影视领域文本包含大量影视领域专业词汇,如影视名、影视角色、演员及导演等名称词汇,特别是影视名称长短不一,现有分词器往往会对影视名称错误分词,间接造成候选关键词生成错误。如电影名称“肖申克的救赎”会被分成三个词“肖申克”、“的”、“救赎”。
针对这一问题,提取影视领域知识图谱MKG中的实体集作为影视领域专业词表,用作分词器的用户词典导入分词器,可很大程度上避免上述错误分词。选用张华平博士的ICTCLAS中分词系统来对影视文本进行分词处理,分词后的词汇首先经过词性过滤,去掉词性标注中不含“n”和“v”的词,如“d”代词,随后再经过停用词过滤,生成候选词集。
2.2 词网络构建
为了将基于图的排序算法应用于自然语言文本,需要构建表示文本的图。当前主流的文本图构建方法以词为网络节点[12-13],利用词共现(word co-occurance)构建图上节点的连接边。对于给定文本d构建图G=(V,E),其中V是文本d经分词处理后的候选词集,每一个候选词是图上的1个节点;图上2个节点vi和vj由边(vi,vj)∈E连接。节点vi和vj存在1条边,当且仅当2个节点在d中指定的词共现窗口W中同时出现。边(vi,vj)∈E的权重为节点vi和vj的共现次数。文本词网络图G可以是有向图也可以是无向图,Mihalcea等[12]的实验表明,用来表示文本的图类型对关键词提取结果没有显著影响。
上述方法在正规长文本的关键词提取中取得了不错的效果,但仅通过词共现建立图上节点的连接,忽略了词汇之间的语义关联。如在文本“以易烊千玺扮演的伍万里这个孩子的视角,重新观察战争,进入战争,学习战争。他在战争中成长起来的故事线,就是拎起《长津湖》整篇故事的主线。”中,演员“易烊千玺”和电影“长津湖”存在语义关系,但在文本中相隔较远,TextRank算法的词共现窗口N最大取值为10,无法为词“易烊千玺”和“长津湖”建立连接边。
基于上述思考,提出结合影视知识库改进词网络构建,在构建连接边时遵循如下2条规则:
(1)候选词vi和vj在影视文本d中指定的词共现窗口W中同时出现;
(2)候选词vi和vj在影视领域知识图谱MKG中存在语义关系,即存在三元组(vi,rk,vj)∈Emk。
具体实现中,首先基于词共现关系建立候选词图Gco,利用关联矩阵Mco=(Mcoi,j)|V|×|V|表示Gco,其中|V|表示文本d中的候选词个数,w(vi,vj)为2个节点在文本d中的共现次数:

(1)


(2)
(3)
2.3 关键词排序
图模型可以有效表示各节点间的关系和结构信息,在计算节点权重的过程中可以结合图的全局做出判断而不是依赖某几个特定节点的信息。以TextRank[12]和Positionrank[13]2种经典的基于图的关键词提取方法为例,介绍如何结合领域知识辅助关键词提取。
TextRank基本思想来源于谷歌的网页排序算法PageRank[11]。PageRank通过网页链接关系构建图模型,排序核心思想为:如果1个网页被很多其他网页链接到,说明这个网页很重要,其PageRank值也会相应较高;如果1个PageRank值很高的网页链接到另外某个网页,那么那个网页的PageRank值也会相应地提高。基于上述思想,设计了如下PageRank值计算公式:

(4)
式中:S(vi)表示网页vi的PageRank值,vi∈V={v1,v2,…,vn},网页之间存在链接关系;d为跳转因子(通常设置为0.85);In(vi)为链向vi的网页个数,即有向图中节点的入度;Out(vj)为节点vj链向网页的个数,即有向图中节点的出度。
在关键词提取算法中,网页被换成了关键词。TextRank把文本分割成若干组成单元(词语)并建立图模型,在PageRank基础上考虑边的权重,利用投票机制对文本中的重要成分进行排序,具体方法为:
S(vi)=(1-d)+
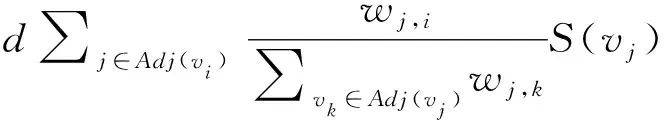
(5)
TextRank利用词共现信息计算边的权重,Adj(vi)表示节点vi的邻接节点集合,TextRank实验表明在关键词提取任务中图中的边是否有向对提取结果没有显著影响,wj,i表示vi和vj的词共现次数,即式(1)中的w(vi,vj)。
PositionRank在上述2种排序方法基础上,进一步考虑了词在文档中出现的位置和出现次数,认为在文档中出现位置靠前、出现频次较多的词更为重要。基于这一思想,优化排序公式如下:
(6)
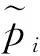

(7)
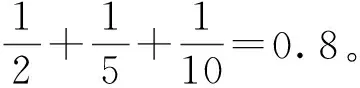
上述方法仅基于单篇文档的词共现信息和词位置信息进行排序,忽略了词汇之间存在的语义关系。利用影视领域知识图谱MKG中的语义关系,进一步优化图排序方法,在式(3)图节点相似度wi,j基础上,引入语义相似度smi,j,计算式如下:
smi,j=Jaccard(Adj(vi),Adj(vj))=
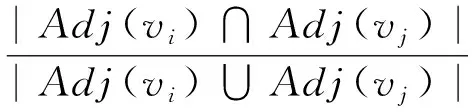
(8)
语义相似度计算方法可以根据实际应用调整。选取计算简单、实际应用效果较好的Jaccard相似度计算方法,根据2个节点的共同邻居度量节点相似度,共同邻居越多,节点越相似。将smi,j引入TextRank和PositionRank算法中,分别得到式(9)和式(10),用以计算结合语义相似度的关键词排序。
S(vi)=(1-d)+

(9)
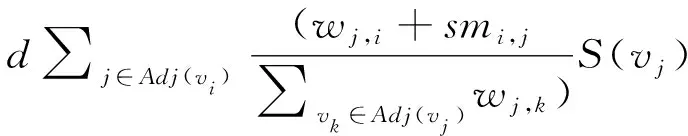
(10)
3 实验与分析
3.1 实验数据
为验证所提方法的有效性,基于影视领域知识图谱MKG,设计爬虫爬取豆瓣影视近2万篇影视文档,提取影视领域实体近1.7万,提取实体关系近3百万。为对所提方法进行有效评价,采用人工标注的方法构建实验数据集。利用八爪鱼、beautifulSoup等工具包在豆瓣影视讨论社区爬取影视评论,经过简单清洗格式后将原网页的各标签信息存储为JSON文件。选取200篇影视评论进行人工标注,为每篇文档标注5个关键词,标注好的关键词以“tag”为键添加到原有JSON文件以供后续处理,如图4所示。

图4 影视评论关键词标注数据截图Fig.4 Data screenshot of keywords annotation for film and television commentary
3.2 评价标准
采用准确率(Precision)、召回率(Recall)和F1值(F-Measure)衡量各算法的关键词提取效果。在关键词提取任务中,准确率即提取结果与答案的匹配度;召回率表示提取结果对于正确答案的覆盖程度;F1值则是考虑前两者的综合指标。3种评价标准的定义如下:
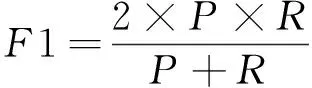
(11)
其中:S为算法提取的关键词集合;K为人工标注的关键词集合。
对于每一篇标注的影视文本,分别计算P、R和F1,最后分别加和求平均得到整体的准确率、召回率和F1值。
3.3 实验结果
将所选方法应用于影视文本关键词提取任务,与原始的TextRank和PositionRank方法进行对比,结合影视领域知识图谱MKG改进后的算法分别标记为TextRank+MKG和PositionRank+MKG。针对每一篇影视文本,经分词及与处理后,基于式(1)构建传统的候选词图,基于式(3)构建MKG改进后的候选词图;基于式(9)和式(10)计算改进后的候选词排序;基于式(5)和式(6)计算传统的词排序;最后取排序靠前的K个关键词作为关键词提取结果。实验数据中每篇文本有5个关键词,为此K分别取值1、2、3、4、5。实验结果如图5所示。
从图5中可以看出,将MKG引入图排序TextRank和PositionRank算法中,在准确率、召回率和F1各项评价指标中都有明显提升作用,说明领域知识对于关键词提取任务具有积极辅助作用。具体来看,TextRank方法在影视文本中效果明显优于PositionRank。分析原因,PositionRank是针对正规的学术论文设计的关键词提取方法,论述语句描述和位置信息作用明显。但影视评论文本较多为发表感想、看法类文字,不符合标准的论文写作顺序和结构,导致位置偏好在影视评论关键词排序中不起作用甚至可能造成干扰。
3.4 实验分析
为进一步分析MKG在引入词表、构建词图和词排序方面的细分作用,基于TextRank进行实验分析,设置对比实验:
(1)TextRank:不引入词表、基于式(1)构建传统的候选词图、基于式(5)进行关键词排序;
(2)TextRank+W:引入词表、基于式(1)构建传统的候选词图、基于式(5)进行关键词排序;
(3)TextRank+W+G:引入词表、基于式(3)构建传统的候选词图、基于式(5)进行关键词排序;
(4)TextRank+W+G+R:引入词表、基于式(3)构建传统的候选词图、基于式(9)进行关键词排序。
影视领域知识MKG在关键词提取中的作用分析结果如图6所示。从图6中可以看出,2~4三个阶段引入MKG相关知识均对关键词提取任务有积极作用;其次,领域词表的作用最为明显,引入影视领域词表的TextRank+W显著优于TextRank,准确率提升近10%;最后,在召回率指标中,TextRank+W+G提升效果明显,说明通过MKG引入影视语义关系,为词图节点增加语义边,有助于提升关键词提取召回率。

图5 影视文本关键词提取效果对比Fig.5 Keyword extraction effect comparison for film and television text
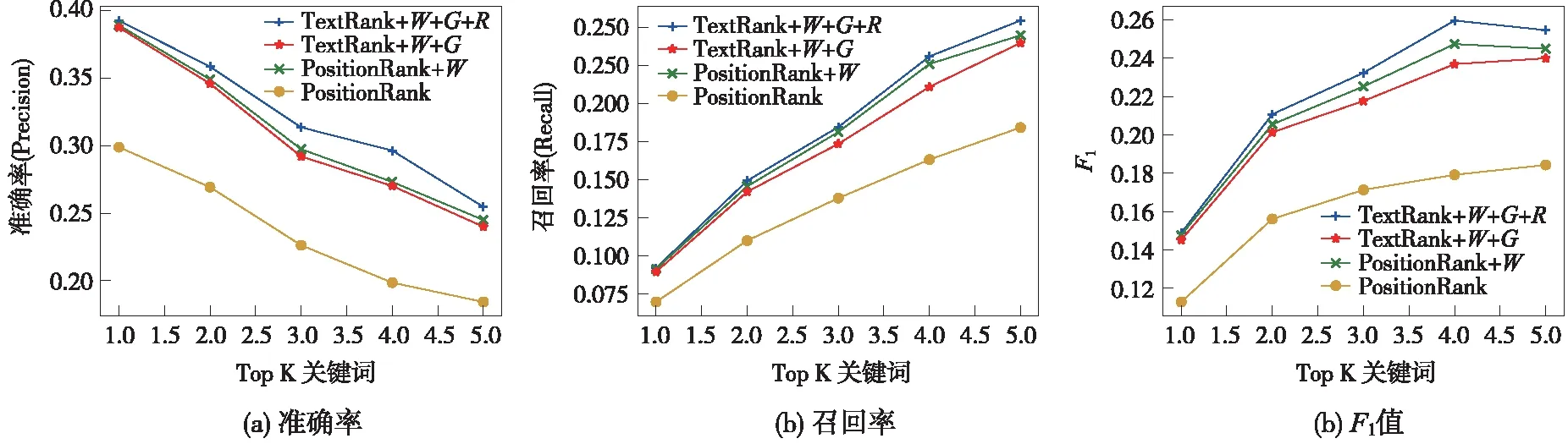
图6 影视领域知识MKG在关键词提取中的作用分析Fig.6 Analysis of the role of MKG in keyword extraction
4 结论
围绕影视领域文本展开结合领域知识的关键词提取算法研究。构建影视领域知识库,基于图排序算法,从改进分词、完善词图构建、优化词排序三方面提升影视文本关键词提取效果,实验结果表明所提方面有效。当前仅基于影视词汇在知识图谱中的共近邻关系计算语义相似度,没有考虑知识库全局网络结构信息,也没有区分不同关系类型,未来在语义相似度计算方面可做进一步优化研究。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
英语世界(2021年13期)2021-01-12
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
国家图书馆学刊(2016年2期)2016-10-09
电子测试(2015年18期)2016-01-14
图书馆建设(2012年3期)2012-10-23
