
基于CHMM和SSA-SVM模型的高速铁路道岔设备健康状态评估方法
2023-12-01 11:13王彦快米根锁王宇峰王朋雨
铁道学报 2023年11期
王彦快,米根锁,张 玉,王宇峰,王朋雨
(1.兰州交通大学 铁道技术学院,甘肃 兰州 730070;2.兰州交通大学 自动化与电气工程学院,甘肃 兰州 730070;3.国网甘肃省电力公司 电力科学研究院,甘肃 兰州 730070;4.国网甘肃省电力公司 定西供电局,甘肃 定西 743000)
随着中国高速铁路(以下简称“高铁”)的快速发展,对列车的运营安全和效率提出了更高的要求,也随之给铁路信号设备的运营维护带来更大挑战。道岔作为铁路信号设备中最关键的基础设施之一,其故障数约占铁路信号设备故障总数的40%以上,其中90%以上为机械故障[1]。因此,对道岔状态进行监测,及时掌握其当前健康状态,并制定合理的维修策略,是减少道岔故障、提高其可用性的重要手段。
目前我国铁路现场主要采用“计划修”和“故障修”相结合的道岔维护模式:维护人员通过信号集中监测系统(Combined Signal Monitoring,CSM)监测道岔实时状态,定期浏览道岔转辙机动作电流、功率曲线等参数,周期性地对现场运行中的道岔进行检测与维护,确保道岔工作状态良好;当道岔发生故障报警后,结合CSM的监测数据,依据专业知识和工作经验定位道岔故障类型,辅助维修。该维修方式下,故障诊断准确率较低,劳动强度较大,且易造成“欠维修”和“过维修”,其维修存在局限性[2]。
为改变现有道岔维修方式,国内外学者从道岔故障诊断和设备退化两方面开展了相关研究。道岔故障诊断是对已故障道岔定位其故障类型,而对潜在故障或故障趋势并未涉及,无法完成道岔“故障修”向“状态修”的转变。设备退化方面,文献 [3]采用SOM-BP混合神经网络方法对道岔设备退化状态进行识别,准确率达到95.56%;文献 [4]通过Hausdorff距离分别计算道岔电流、功率曲线与正常曲线之间的相似度,实现道岔健康状态评估及故障检测,解决了现有故障诊断方法需要大量样本数据对算法支撑的问题;文献 [5]建立基于SVDD的道岔转换故障检测和健康指标评估模型,实现对道岔设备的健康管理。上述文献均为道岔状态退化研究提供了有力依据,但是原始道岔曲线样本数据中的正常数据和异常数据数量比例不平衡,而且采用的特征指标选取及处理方法无法全面反映出道岔的故障特点及趋势。
针对以上问题,本文以我国高铁大量采用的ZDJ9型电动转辙机为例,从CSM中获取道岔功率曲线,包括道岔正常转换功率曲线、不同退化状态下的道岔功率曲线和道岔故障功率曲线,建立道岔功率曲线样本数据库;提取样本数据的时域、频域、经验模态分解(Empirical Mode Decomposition,EMD)奇异值熵等三方面的特征值,组成样本数据的特征向量,并采用核主成分分析(Kernel Principal Component Analysis,KPCA)法对高维特征指标进行选择与处理,构建道岔特征指标样本数据库;建立道岔退化状态划分连续隐马尔可夫模型(Continuous Hidden Markov Model,CHMM),将退化特征样本数据划分为不同的退化状态,并在此基础上,构建麻雀搜索算法(Sparrow Search Algorithm,SSA)优化支持向量机(Support Vector Machine,SVM)算法的道岔设备健康状态评估模型,实现道岔健康状态的综合评估;最后验证提取道岔功率曲线样本数据的时域、频域、EMD奇异值熵三方面特征指标,以及采用KPCA降维方法的合理性;分别与使用GridSearch-SVM、GA-SVM、PSO-SVM算法建立的道岔设备健康状态综合评估模型的评估结果进行对比,验证基于CHMM和SSA-SVM的高铁道岔设备健康状态评估方法的可行性和精准性。
1 ZDJ9型电动转辙机
在现场通过CSM监控并记录道岔转换过程中的有关数据,实时掌握道岔动作过程中转辙机的电流曲线和功率曲线等参数,其中功率曲线不仅能够反映道岔转换时的电气特性,更能体现道岔在动作过程中所受阻力大小和机械性能[6]。为此,本文选择功率曲线数据建立样本数据库。
1.1 ZDJ9型转辙机功率曲线
在CSM中,通过道岔监测模块监测到的道岔正常转换功率曲线见图1。图1中,道岔转换过程功率曲线分为解锁、转换、锁闭等3个阶段。在解锁过程中,1道岔启动继电器(DQJ)励磁吸起,道岔动作曲线开始记录,2DQJ转极,功率曲线骤然产生尖峰,尖峰值为650~1 080 W,道岔启动电路接通,道岔动作开始;在转换过程中,功率曲线较平滑,功率值大小与参考曲线大体相同;在锁闭过程中,当动作的尖轨密贴于基本轨,道岔锁闭后,自动开闭器接点转换,同时断开启动电路,接通表示电路,断相保护器无电流通过,使保护继电器落下,又因1DQJ处于缓放状态,启动电路仍有两相电流,产生200 W左右的曲线小台阶,直到1DQJ缓放结束,功率为0 W[7]。
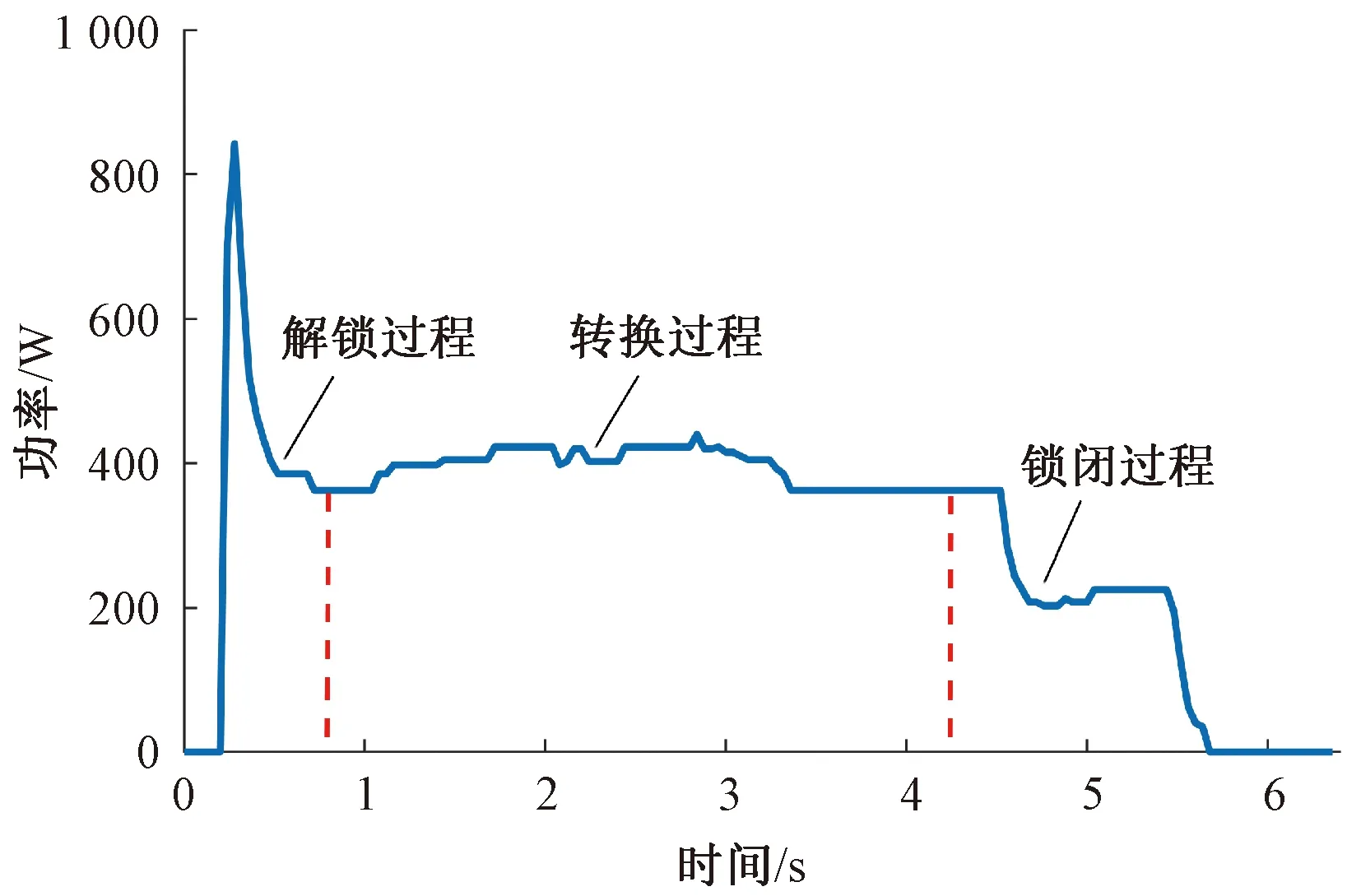
图1 道岔正常转换功率曲线
1.2 道岔全寿命周期状态分析
通过分析道岔转换功率曲线,结合现场道岔故障原因及设备退化规律,将道岔全生命周期的整个状态划分为正常状态、退化状态和故障状态3个等级。道岔全寿命周期状态曲线见图2。由图2可知,在正常状态下,设备运行正常,状态监测值在正常范围,故障发生概率较低;在故障状态下,设备性能恶化,已发生故障,必须及时安排检修;从道岔正常状态的退化起始点开始至故障点的生命周期为退化状态,表现在道岔转换功率曲线上,虽然解锁、转换、锁闭3个过程曲线完整,但是往往表现出功率幅值、波动幅度、动作时间等不同的退化特点,所以需要及时精准地评估出当前道岔状态,以提醒维修人员采取相应的维修措施。
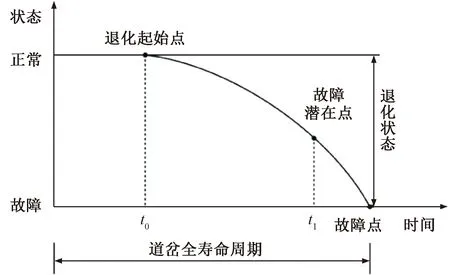
图2 道岔全寿命周期状态曲线
1.3 道岔设备健康状态评估
高铁道岔设备健康状态评估的技术路线见图3。图3中,整个过程主要包括:道岔特征指标样本数据库的建立、道岔退化状态划分CHMM模型构建、道岔健康状态评估SSA-SVM模型构建,以及高铁道岔设备健康状态评估功能实现。
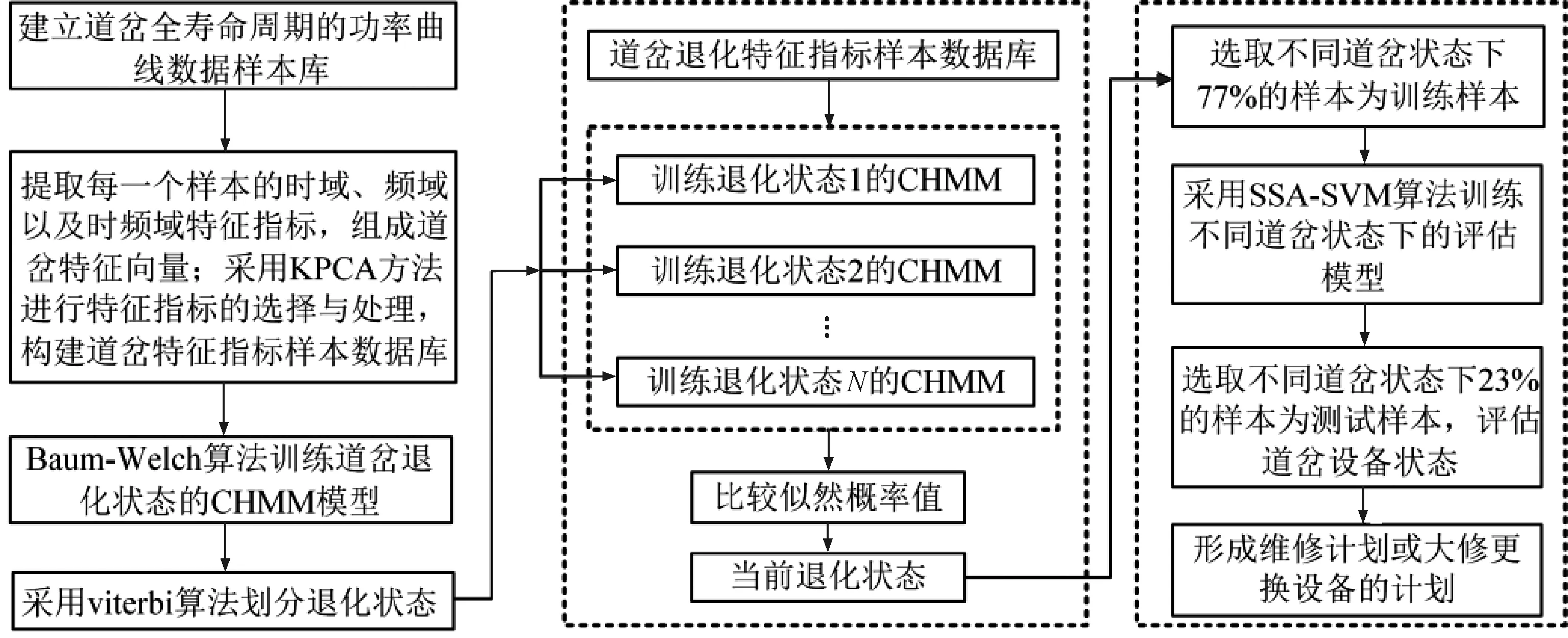
图3 高铁道岔设备健康状态评估的技术路线
2 道岔特征指标提取和选择
2.1 道岔特征指标提取
为更全面反映道岔功率曲线具有的退化及故障特征,结合道岔转换过程中解锁、转换、锁闭等3个过程的功率曲线特点,分别提取每个过程的时域、频域、时频域特征指标。
2.1.1 时域特征指标提取
由于不同的道岔故障类型在道岔功率曲线的解锁、转换、锁闭过程中的表现具有不同的特点,故需要分别提取以上3个过程的时域特征指标,见表1[8]。
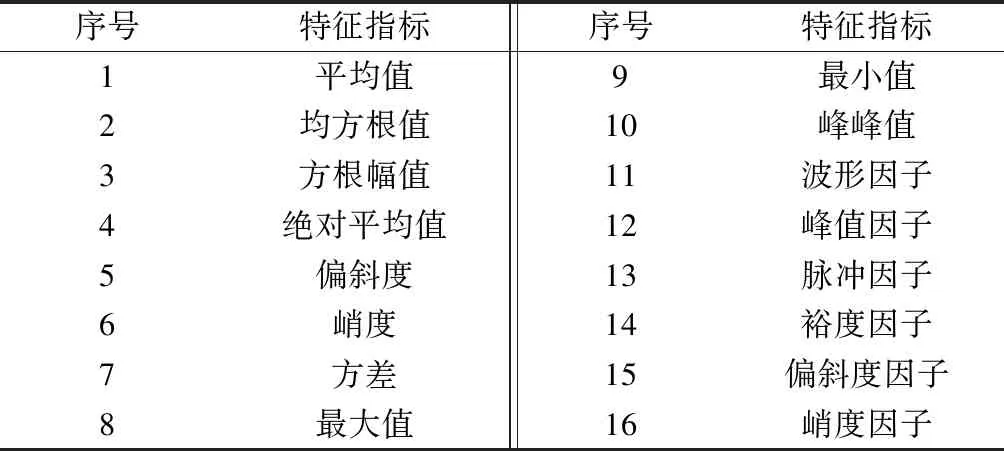
表1 时域特征指标
2.1.2 频域特征指标提取
通过分析道岔典型故障功率曲线的特点得出故障现象表现在功率曲线的某个小区域,若仅仅计算时域特征指标,可能会忽略功率曲线的故障小区域,而在功率信号的频谱中,频率分量会相应地改变。假设一个道岔功率曲线数据样本序列为{pf},经快速傅里叶变换(FFT)后得到的幅值序列为{Af},相角序列为{θf},其中f∈[1,160]。每一个道岔功率曲线数据样本需提取的频域特征指标见表2[9]。
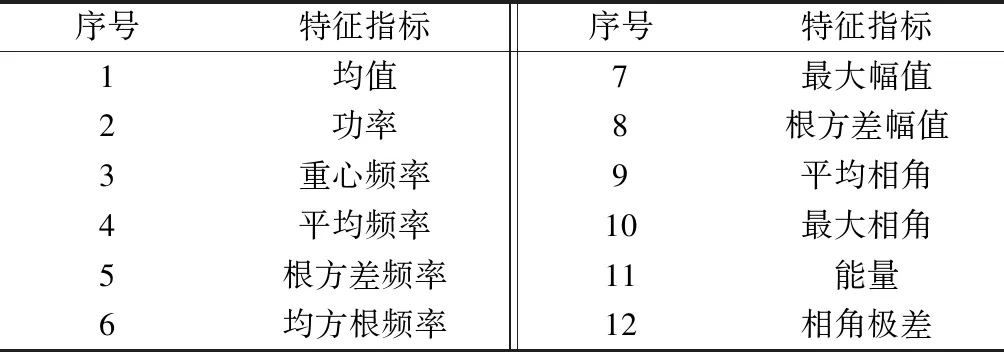
表2 频域特征指标
2.1.3 时频域特征指标提取
为全面反映道岔功率曲线的非线性信号特征,利用EMD分解道岔功率曲线得到特征向量矩阵,基于奇异值分解和信息熵理论构建奇异值熵作为时频域特征指标[10]。该方法不仅能够有效提取故障信号微弱的特征,而且不需选取基函数,具有自适应性较强等优势。
1)EMD方法及特征向量矩阵
将道岔功率信号x(t)中曲线数据的波动或道岔退化趋势逐级分解,得到由多个本征模态函数(Intrinsic Mode Function,IMF)分量xd(t)和一个余项r组成的表达式,即
( 1 )
xd(t)为x(t)中从高频到低频不同频段的成分,由于在每一个IMF分量中又包含道岔功率信号中突变的故障信息,所以可由n个IMF分量组成的初始特征向量矩阵C表示x(t)的特征,即
( 2 )
2)奇异值熵[12]
根据奇异值分解原理可得
C=UΛVT
( 3 )
式中:U、V分别为(n+1)×(n+1)阶、m×m阶正交矩阵,m为每个IMF分量的数目;Λ为对角矩阵,主对角元素λ1、λ2、…、λ(n+1)为矩阵C的奇异值,且满足λ1≥λ2≥…≥λ(n+1)≥0。
设gd、vd分别为U、V的列向量,则式( 3 )可等效为
( 4 )
式中:λd为矩阵C的第d个奇异值。为定量描述信号时频成分和复杂度,引入奇异值熵Y,其定义为
( 5 )
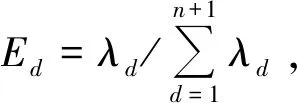
2.2 道岔特征指标选择
由于通过计算原始道岔功率曲线的时域、频域、EMD奇异值熵组成的高维特征指标向量,其特征指标之间存在大量的冗余数据和空间相关性,在模型训练时,复杂度较高,稳定性较差,故本文选用KPCA对道岔高维特征指标进行选择处理。具体实现过程为:采用非线性映射核函数将样本数据映射在高维特征空间,进行零均值处理后得到新核矩阵;计算新核矩阵的特征值、特征向量以及方差贡献率,按照从大到小的顺序排列,并对方差贡献率归一化;将样本点投影在特征向量上,根据累计目标方差贡献率的大小提取前几个主成分,从而建立道岔特征指标样本数据库[13]。
3 CHMM模型
假设道岔退化特征指标样本序列为O=(o1,o2,…,oT),对应的道岔退化状态序列为q=(q1,q2,…,qT),基于CHMM的道岔退化状态确定训练模型ρ[14]为
ρ=(k,h,π,A,B)
( 6 )
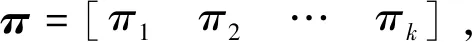
根据式( 6 ),道岔退化状态CHMM划分模型的构建步骤如下:
Step1CHMM模型训练。采用Baum-Welch算法,该算法是采用最大期望算法的原理,通过极大似然对数值反映训练模型与实际模型的接近程度,其值越大越接近。具体实现过程为:不断迭代训练参数,每一步迭代分为求期望和极大化2个步骤,直到CHMM模型收敛,保存最优参数。
Step2退化状态数确定。为确定道岔退化状态等级,通过已知的道岔退化特征指标样本序列和已训练好的CHMM模型,采用Viterbi算法找到一个合理的隐状态序列解释该观测序列。
Step3当前退化状态确定。采用前向-后向算法计算观测序列在给定CHMM模型下的似然概率值lg(P(O|λ)),并比较各模型下的似然概率值,确定所有样本所属退化状态。
以上涉及到的Baum-Welch、Viterbi、前向-后向算法的详细推理过程见文献 [15]。
4 SSA-SVM模型
为能够准确地对高铁道岔设备健康状态进行评估,本文在对道岔退化状态划分的基础上,建立基于SVM算法的道岔设备健康状态评估模型。SVM算法在解决小样本、非线性、模式识别等问题方面具有很大优势,符合道岔设备状态评估特点,同时考虑到SVM模型的泛化能力受惩罚因子c和核函数半径g的影响较大[16],故本文引入SSA算法优化SVM模型中的参数c和g,以提高SVM的评估准确率。
4.1 SSA算法原理
SSA算法由Xue和Shen在2020年提出,是一种新型群体智能优化算法[17],通过模拟麻雀觅食与反捕过程获得最优参数c和g,与其他群体智能优化算法相比,该算法全局搜索能力强,收敛速度快,精度高,而且稳定性好。
SSA算法的实现原理为:将在觅食过程中的麻雀分为发现者、加入者和侦察者3种类型,通过利用它们之间的关系及麻雀在遇到捕食者之后的反应而达到优化搜索的目的[17-18]。
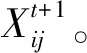
1)发现者的位置更新
发现者搜索能力强,可引导整个种群搜索和觅食。发现者的位置更新式为
( 7 )
式中:t为当前迭代次数;N为最大迭代次数;α为(0,1]之间的随机数;G为服从正态分布的随机数;L为1×j维、元素均为1的矩阵;R2为预警值,R2∈[0,1];SN为安全值,SN∈[0.5,1]。
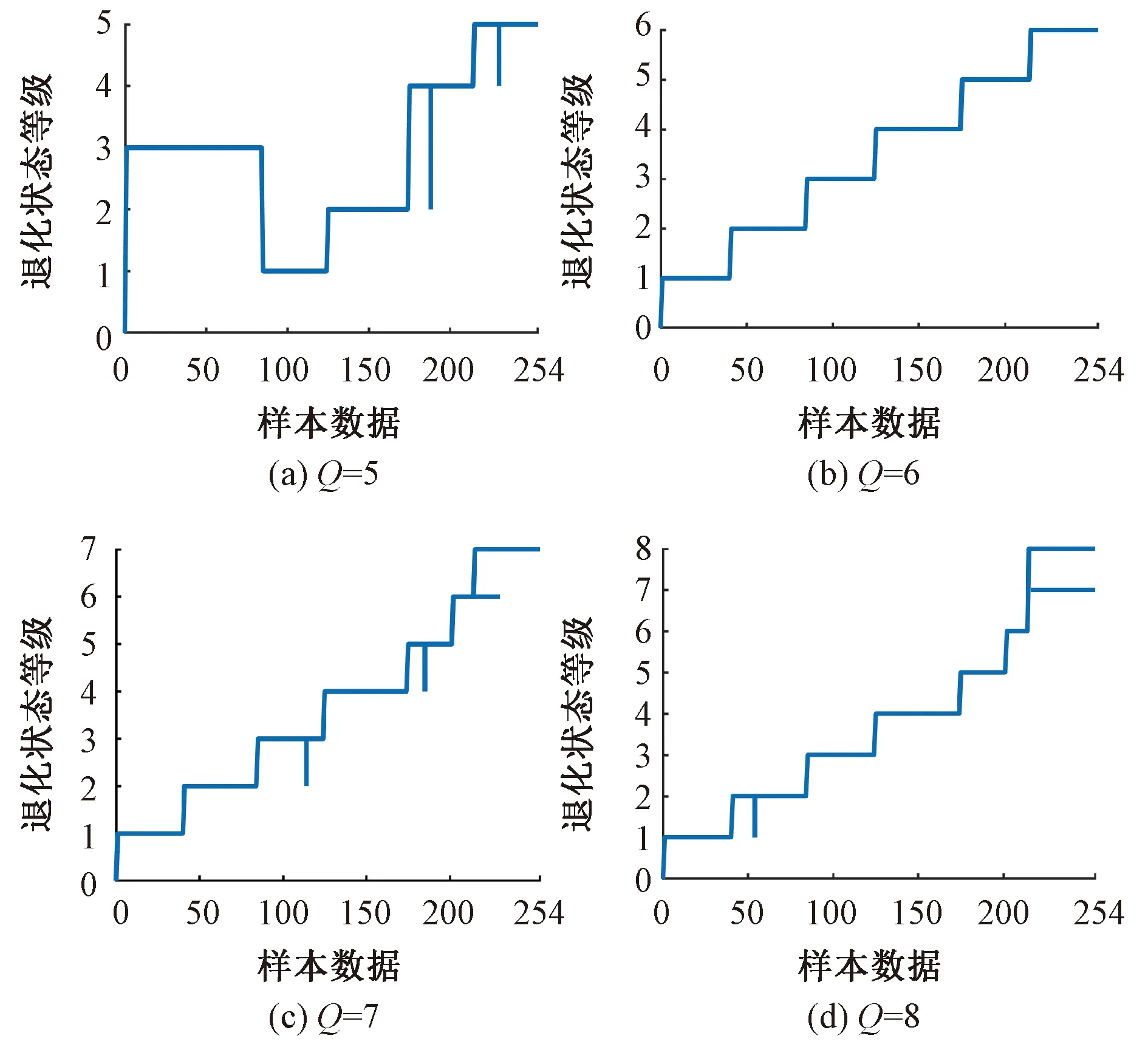
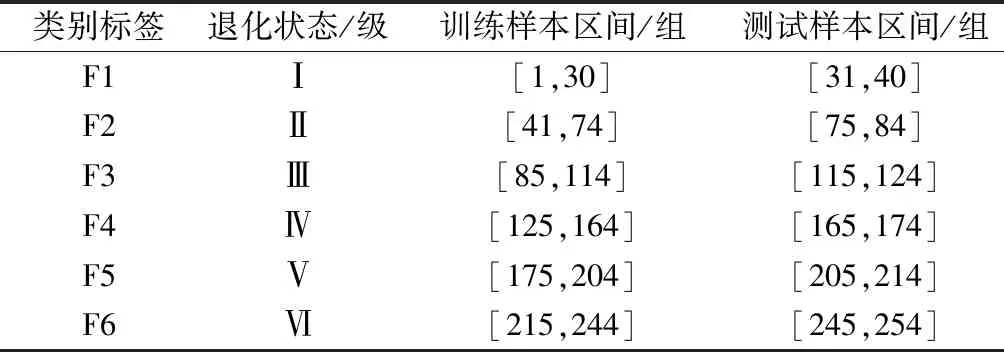
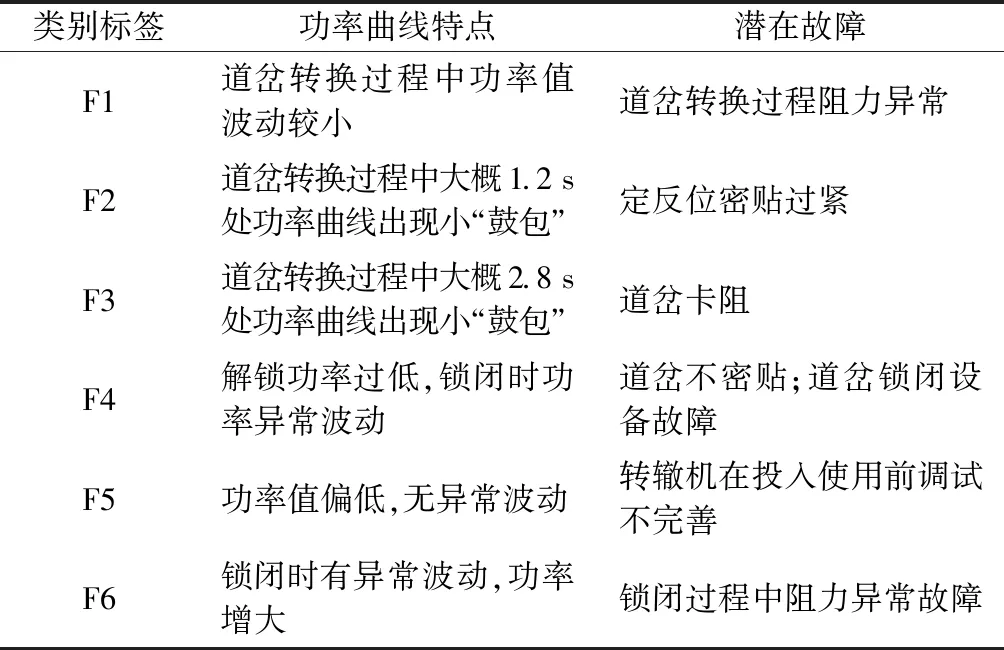
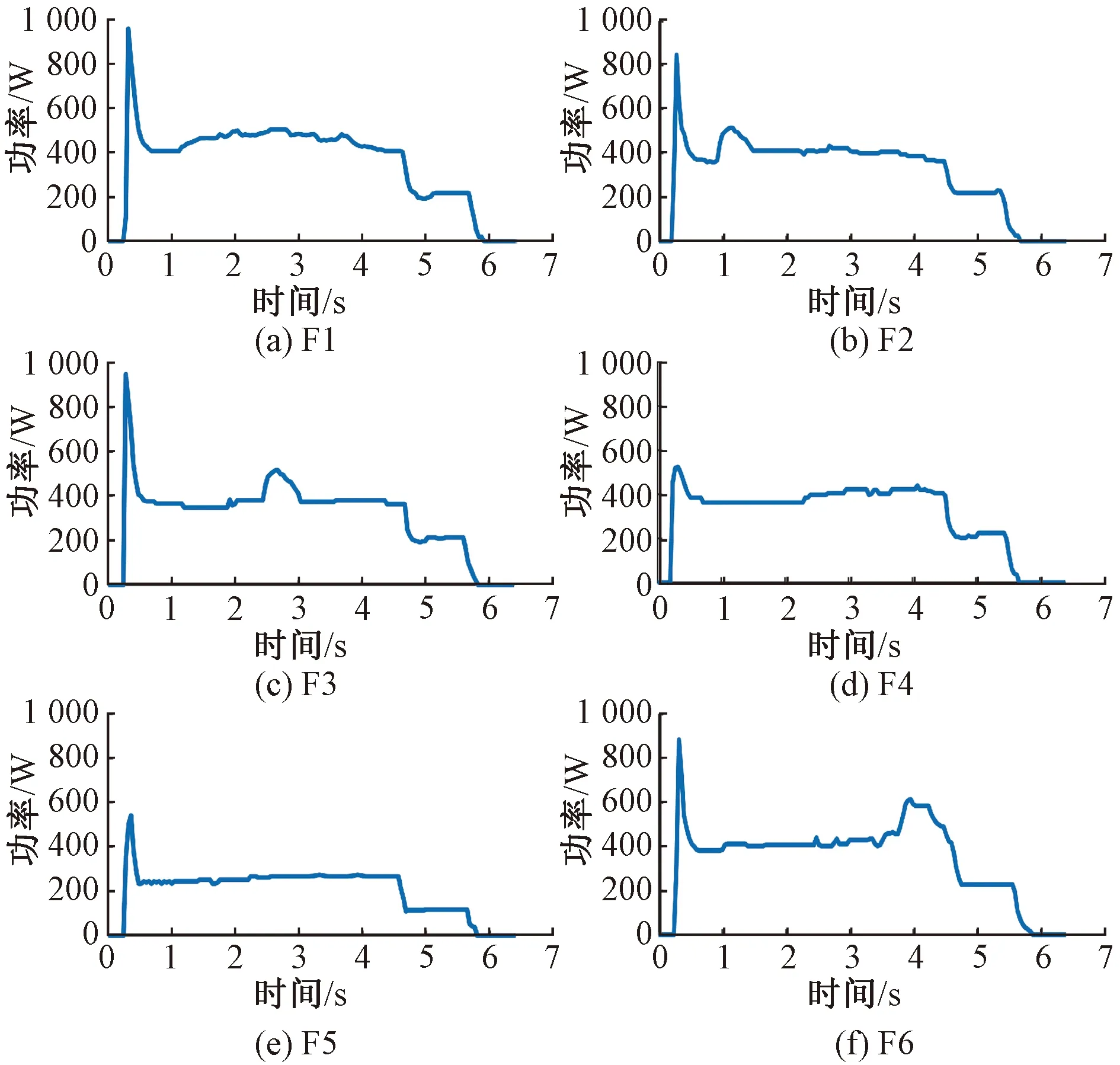
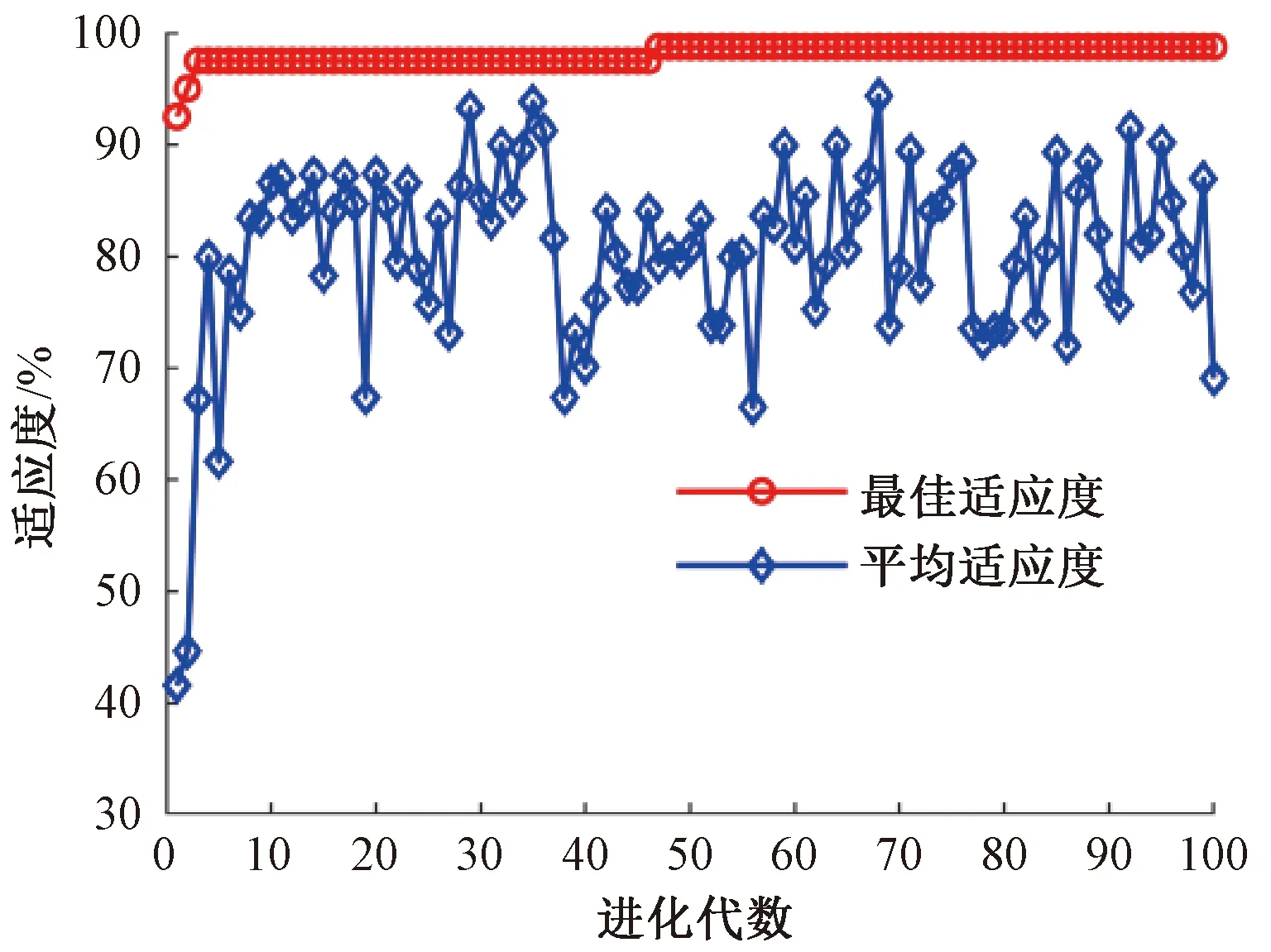
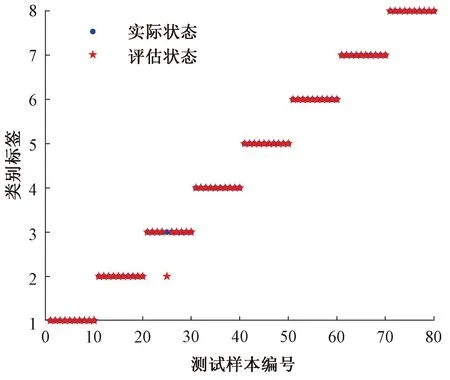
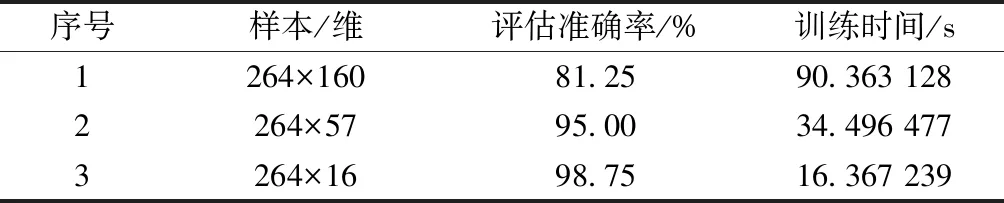
当R2 2)侦查者的位置更新 侦查者通过监视发现者以提高自身捕食率,当遇天敌威胁时,发出预警信号,种群做出反捕食行为。侦查者的位置更新式为 ( 8 ) 式中:Xg为当前全局最优位置;β为步长调整参数,为服从均值为0、方差为1的正态分布的随机数;K为麻雀移动方位,K∈[-1,1];fw为全局最差适应度;fg为全局最优适应度;fi为i个体的适应度;ε为最小常数,以避免分母为零。 当fi≠fg时,表示该麻雀在种群的边缘带活动,易被捕食者发现而受到袭击;当fi=fg时,表示该麻雀位于种群的中心位置,且已察觉到被袭击的危险,需要迅速向其他区域的麻雀靠拢。 3)跟随者的位置更新 除发现者和侦查者之外,其余的麻雀均为跟随者,主要通过跟随发现者搜寻食物以获得更好的适应度。跟随者的位置更新式为 ( 9 ) 式中:Xw为全局最差位置;Xp为全局最优位置;A为1×j维矩阵,各元素随机赋值为1或-1,且满足A+=AT(AAT)-1。 当i>n/2时,表明第i个跟随者未搜索到食物,存活率低,需前往其他区域搜寻食物,以提高自身适应度。 SVM算法原理见文献 [19]。采用SSA算法优化SVM状态评估模型的参数c、g的流程见图4。评估模型的优化步骤如下: 图4 评估模型的优化流程 Step1初始化SSA参数。 Step2通过计算个体适应度fi,选出最优适应度fg和其所对应的位置X(c,g)。 Step3选取分类错误率最小的适应度函数,计算得到适应度,并按从大到小的顺序选取前pNum只麻雀(占种群数量的60%~70%)作为发现者,根据式( 7 )更新发现者的位置;随机选取sNum只麻雀(占种群数量的5%~10%)作为侦查者,根据式( 8 )更新侦查者的位置;其余均为跟随者(占种群数量的15%~20%),根据式( 9 )更新跟随者的位置。 Step4根据麻雀种群当前的状态,更新整个种群所经历的最优位置X(bestc,bestg)和最优适应度fg,训练SSA-SVM模型。 Step5判断算法运行是否达到收敛条件,若是,循环结束,将最优结果X(bestc,bestg)输入SVM状态评估模型;否则返回Step2。 以某铁路局管辖车站采用的ZDJ9型电动转辙机所驱动的道岔为研究对象,共获取344条道岔功率曲线,其中包含254条不同退化状态下的道岔功率曲线、50条道岔正常转换功率曲线以及40条道岔故障功率曲线。道岔正常转换的时间为6 s左右,采样间隔为40 ms,采样点数为150。在做数据处理时,在曲线数据点后补零至时间点为6.4 s,若故障动作时间超过6.4 s,则截取曲线前6.4 s的数据,最终每条功率曲线采集160个数据点组成一个样本。其中,解锁过程为0~0.6 s,共采集15个数据点;转换过程为0.64~4.4 s,共采集96个数据点;锁闭过程为4.5~6.4 s,共采集49个数据点。 1)时域特征指标提取结果分析 根据表1中列出的16个时域特征指标,分别计算344个道岔功率曲线样本解锁、转换、锁闭过程的时域特征指标。由于不同的道岔退化及故障状态在3个过程的功率曲线表现出不同的特点,部分时域特征指标对退化类型的分析并不敏感,例如所有样本的峭度因子值区分度不大,每个阶段的平均值与绝对平均值数值存在相似性,所以需要对各项指标的变化趋势以及指标间的关系进行分析。最终选出解锁过程14个指标(删除最小值、峰峰值、峭度指标,增加最大值与第15个采集点数据的差值)、转换过程15个指标(删除峭度指标)、锁闭过程17个指标(增加最大值与最小值的差值),建立344×46维的时域特征指标。 2)频域特征指标提取结果分析 根据表2所示的频域特征指标,对344个道岔功率曲线样本数据采用FFT变换得到功率曲线的各段频谱,提取12个频域特征指标。由于最大相角、能量特征指标对退化及故障状态不敏感,需删除,最终建立了344×10维的频域特征指标。 3)时频域特征指标提取结果分析 以图1所示的道岔正常转换功率曲线数据为例,EMD分解后的前4个IMF分量波形见图5。由图5可见,道岔功率信号细微的变化经过EMD分解后,随着频率由高到低减小,信号能量依次减弱。 图5 道岔正常转换功率曲线数据EMD分解结果 通过对IMF分量进行信号重构并进行奇异值分解,结合信息熵理论计算344组道岔功率曲线样本的EMD奇异值熵,绘制出EMD奇异值熵散点,见图6。由图6可见,由于采集数据来源于不同组的道岔,而且道岔健康状态不同,信号的复杂程度不同,其EMD奇异值熵区分明显。 图6 EMD奇异值熵散点 通过计算道岔功率曲线样本数据的时域、频域、EMD奇异值熵特征指标,并对其进行初步选择后,建立344×57维的特征指标样本。对样本数据标准化后进行KPCA降维,选取累计方差贡献率大于95%作为目标降维量选取的标准,其中8维能够代表87.78%以上的原始信息,11维能够代表约92.12%以上的原始信息,16维可代表95.62%以上的原始信息,故前16个主成分即可满足要求。经KPCA降维后的16个主成分的贡献值散点见图7。由图7可见,第1主成分对应的贡献最大,从第1主成分至第16主成分的贡献依次减小。 图7 16个主成分的贡献值散点 1)道岔退化状态区段划分模型构建 采用道岔退化状态下功率曲线的特征指标样本训练CHMM模型,其中训练样本的道岔退化状态,是在研究典型道岔故障类型的基础上,在CSM中调取已故障道岔从正常工作到发生故障期间的多组功率曲线,根据该道岔的工作时长以及道岔从退化至完全发生故障的时长,并结合道岔维修记录和现场专家经验等设置的。参考文献 [3]中的研究成果,将隐含状态数目Q设置为5~8,采用Viterbi算法进行解码,将254×57维的退化特征样本数据划分为不同的区间范围。隐含状态的划分见图8。 图8 隐含状态的划分 由图8可见,当Q=5、7、8时,区段划分结果出现交叉重叠的现象,说明这部分数据可以划分到2个区段,显然对道岔实际退化状态的划分不符合实际情况;而当Q=6时,254组退化样本被划分到6个不同的区段,能够很好地反应出道岔性能由轻微退化到严重退化的整个规律,同时也验证了文献 [3]的结果。254组退化样本数据划分结果见表3。 表3 254组退化样本数据划分结果 2)道岔退化状态分析 结合表3中列出的254组退化样本数据划分结果,分别选取每一级退化状态下的第一个样本,绘制出完整的道岔功率曲线,见图9。结合现场调研情况,总结出该6种典型退化类型道岔功率曲线特点,见表4。 表4 道岔设备典型退化类型 图9 6种典型道岔退化状态功率曲线 5.5.1 参数优化 在Matlab中,初始化SSA参数,设置最大迭代次数为100,种群数量为20,c、g的优化范围均为[1×10-5,1×103],交叉验证折数为5,安全值为0.6,发现者所占比例为70%,加入者所占比例为20%,侦查者所占比例为10%;在由道岔正常、退化、故障等共8种状态组成的344×16维样本中,抽取每一种状态的后10组样本组成80×16维的测试样本,其余264×16维样本为训练样本。结合图4以及4.2节的优化步骤,采用SSA算法优化SVM的惩罚因子c和核函数半径g,最终得到最优参数X(bestc,bestg)为X(22.732 1,0.391 98),最佳适应度fg高达98.75%。该模型的最佳适应度曲线和平均适应度曲线见图10。 图10 最佳适应度曲线和平均适应度曲线 5.5.2 状态评估模型测试 将最优参数X(22.732 1,0.391 98)输入至SSA-SVM状态评估模型中,得到80×16维测试样本的实际状态和评估状态,见图11。图11中,纵坐标1~6分别为表3中的道岔退化状态Ⅰ~Ⅵ级,纵坐标7、8分别为道岔正常状态和道岔故障状态。由图11可见,SSA-SVM的评估模型中,80组测试样本中仅有1组数据出现错误,道岔健康状态识别正确率达到98.75%,退化状态识别正确率达到98.33%,高于文献 [3]中基于SOM-BP算法模型的道岔退化状态识别结果。 图11 测试样本的实际状态和评估状态 5.5.3 状态评估结果分析 1)分别采用264×160维道岔功率曲线数据训练样本、降维前的264×57维特征指标训练样本以及经KPCA降维后的264×16维特征指标训练样本训练SSA-SVM模型,并输入对应样本的80组测试样本进行评估,3种样本的道岔健康状态评估结果见表5。 表5 3种样本的道岔健康状态评估结果 由表5可见,3种样本的道岔状态评估结果表明,经KPCA降维后的样本具有较高的评估准确率,而且模型训练时间最短,满足对道岔设备健康状态评估实时性的要求;同时验证了提取道岔功率曲线样本数据的时域、频域、EMD奇异值熵等三方面特征指标,以及采用KPCA降维方法的合理性。 2)采用264×16维特征指标训练样本分别训练GA-SVM、GridSearch-SVM、PSO-SVM 等3种方法的高铁道岔设备健康状态评估模型,采用80×16维特征指标测试样本进行评估,并与本文方法进行对比,4种评估模型的道岔健康状态评估结果见表6。 表6 4种评估模型的道岔健康状态评估结果 % 表6评估结果表明:在获得最佳优化参数的前提下,4种评估模型中SSA-SVM模型的健康状态评估准确率最高,其中正常、故障状态的评估准确率均为100%;6种退化状态下,Ⅰ、Ⅱ、Ⅲ易出现错误识别,Ⅳ、Ⅴ、Ⅵ的识别正确率均为100%。分别统计4种模型中错误识别的样本,第25个样本均出现错误评估,该样本分类后属于F3类退化状态Ⅲ,而错误评估为F2类退化状态Ⅱ,结合表4,对比F2和F3,这两类退化状态均由道岔转换过程阻力异常引起,表现在道岔功率曲线上,转换过程出现了功率“鼓包”,只是出现功率异常的时间点有所不同,这也是易出现错误识别的主要原因。针对以上问题,在今后的研究工作中,可以尝试其他算法提高道岔退化状态划分的精度,达到提高道岔状态评估准确率的目的。 1)本文通过计算功率曲线数据的时域、频域、时频域三方面特征指标,全面提取了道岔退化及故障特征,其中时频域特征指标采用EMD奇异值熵,不仅能够有效提取故障信号微弱特征,而且不需选取基函数,具有自适应性强等优势,获得了道岔的不同退化状态下的特征指标。 2)采用KPCA方法对道岔特征指标进行选择处理,消除了原始多维特征冗余信息,减少了模型训练时间,提高了道岔设备健康状态评估的实时性。 3)构建退化状态划分CHMM模型,将道岔退化过程划分为6个退化状态,较好地表征了道岔设备退化演变过程。 4)分别构建基于GA-SVM、GridSearch-SVM、PSO-SVM、SSA-SVM的道岔设备健康状态综合评估模型,输入测试样本,对比退化状态Ⅰ至退化状态Ⅵ、道岔正常状态、故障状态的评估准确率,验证了基于CHMM和SSA-SVM的高铁道岔设备健康状态评估方法的高评估准确率和可行性,为道岔设备日常维护、故障及时发现处理、维护维修计划制定提供一定的理论依据。4.2 SSA-SVM模型
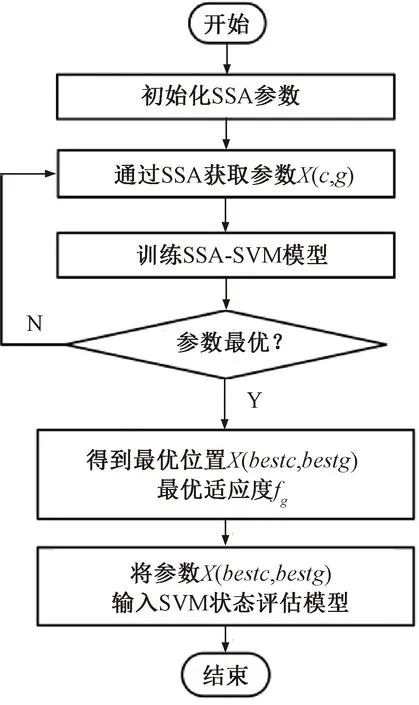
5 高铁道岔设备健康状态评估方法实现
5.1 道岔功率曲线样本数据库的建立
5.2 道岔特征指标提取结果分析
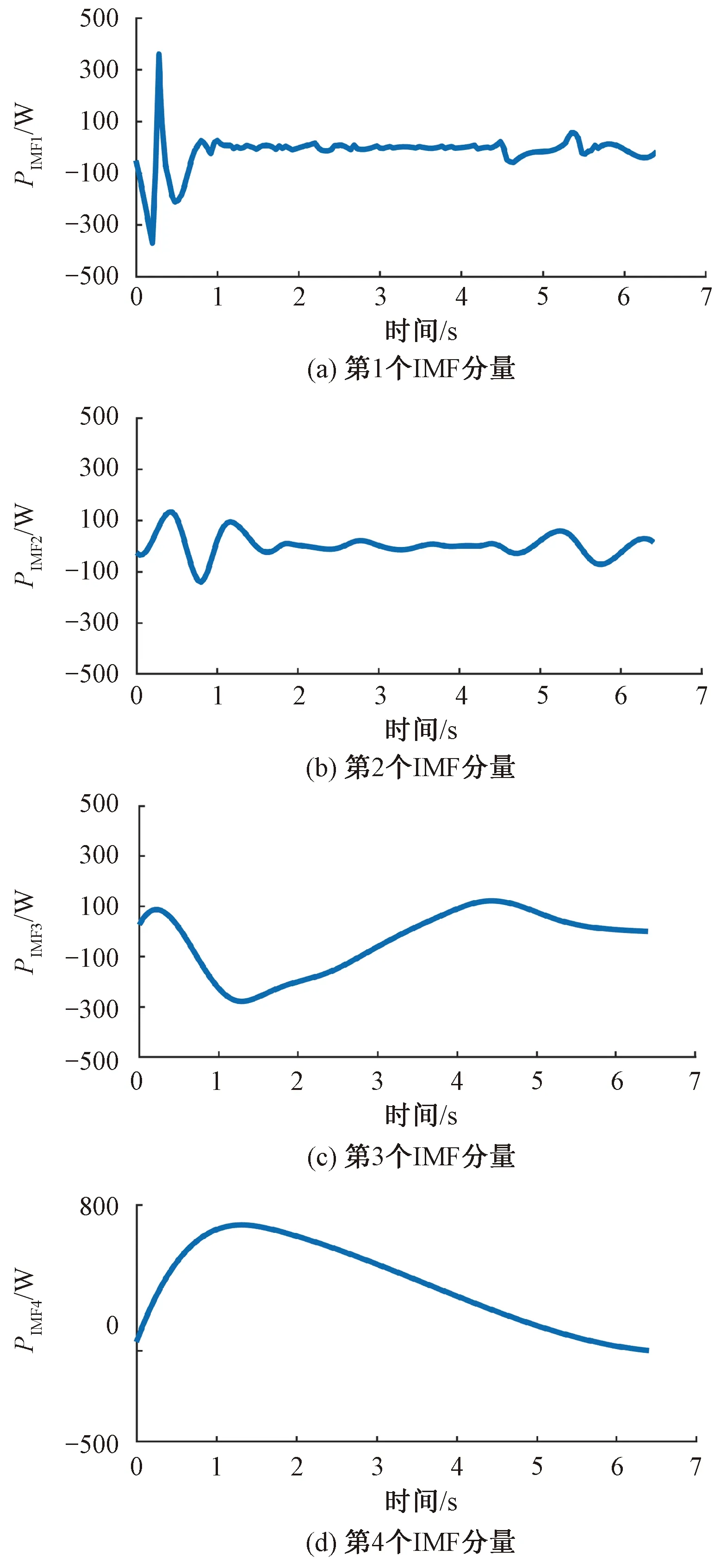
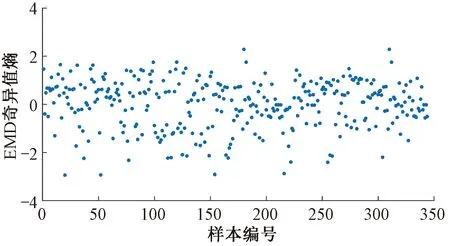
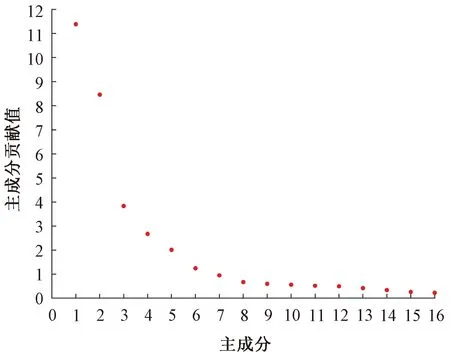
5.3 基于KPCA变换的道岔特征指标选择及结果分析
5.4 道岔退化状态划分CHMM模型的构建及结果分析
5.5 道岔健康状态评估SSA-SVM模型的构建及结果分析

6 结 论
猜你喜欢
中学生数理化·八年级物理人教版(2022年6期)2022-06-05
中学生数理化·八年级物理人教版(2022年6期)2022-06-05
中学生数理化·八年级物理人教版(2022年6期)2022-06-05
中学生数理化·高一版(2021年2期)2021-03-19
铁道通信信号(2020年10期)2020-02-07
中学生数理化·八年级物理人教版(2019年6期)2019-06-25
铁道通信信号(2019年3期)2019-04-25
铁道通信信号(2018年10期)2018-12-06
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
