
基于改进重构损失函数的生成对抗网络图像修复方法*
2023-12-13 03:56叶晓文章银娥
赣南师范大学学报 2023年6期
叶晓文,章银娥,†,周 琪
(1.赣南师范大学 数学与计算机科学学院,江西 赣州 341000;2.赣东学院 信息工程系,江西 抚州 344000)
0 引言
图像修复[1]是指对存在破损的图像进行修复,主要是通过提取未破损区域的信息来进行修复.图像修复技术在现实生活中也有着广泛的应用,首先可以用来对破损的老旧照片进行修复,可以用来修复破损的文物、壁画和建筑,还可以应用在图像编辑[2]、图像重建[3]、图像增强[4]等.由于破损图像存在着复杂结构和破损面积大等问题,因此图像修复是非常具有挑战性的任务.
近年来,卷积神经网络[5]得到了广泛的发展和应用,越来越多人开始使用卷积神经网络来处理图像修复任务,并且都取得了不错的成就.随着自编码器[6]模型的提出,图像修复任务变得更加有效率,使用编码器对破损图像进行特征提取,随后使用解码器对提取的图像信息进行解码,可以得到修复好的图像.随着生成对抗网络[7]的提出,越来越多的研究者使用其来处理图像修复任务,生成对抗网络优势在于可以生成大量的高质量的图像,PATHAK等[8]首次将生成对抗网络和自编码器结构相结合起来提出了基于卷积神经网络的上下文编码器的图像修复算法,修复效果要好于早期的传统图像修复算法,但是仅使用了对抗损失和重构损失两种损失函数,并且正常的重构损失没有对不同区域的修复效果给予不同的关注度,所以修复效果并不是很理想.为了取得增强局部的修复效果,IIZUKA等[9]对判别器进行改进,提出了同时使用全局判别器和局部判别器的方法,使用全局判别器来保证修复图像的全局一致性.同样的孙劲光等[10]也提出了全局与局部属性一致的图像修复模型,使用全局和局部判别器来进行保证图像的全局与局部的一致性,这两种方法在两个判别器都使用了重构损失,同样也是没有考虑到正常重构损失函数对不同区域修复效果没有给予不同的权重,从而不能很好的引导生成器进行修复.李海燕等[11]提出一种基于双网络及多尺度判决器的图像修复算法,使用多个不同尺度的判别器,来提高图像的纹理粒度,其在每个尺度的判别器上都使用了重构损失,没有考虑到对于没有修复好的区域需要得到更大的关注度.YAN等提出了一种以u-net[12]为主要网络结构的shift-Net[13]图像修复算法,虽然修复效果取得了进一步的改进,但是依然存在过度平滑的问题,其除了使用了重构损失和对抗损失,还使用了指导损失,指导损失是真实图像经过编码器第L层后的特征与需要修复图像经过解码器倒数第L层后的特征之间的重构损失.姜艺等[14]提出一种边缘指导图像修复算法,第一阶段对破损图像进行边缘修复,二阶段使用修复的边缘修复图像进行内容修复,其使用了对抗损失、重构损失和风格损失[15],风格损失是通过预先训练的VGG网络[16]分别对修复图像和真实图像提取高级语义特征图,然后求出特征图的格拉姆矩阵,最后计算真实图像和修复图像的格拉姆矩阵之间的重构损失,用来衡量图像的风格相似性,但是其使用的重构损失同样没有考虑对于没有修复好的区域给予更高的权重.
针对现有的图像修复算法使用的重构损失没有考虑对不同区域的修复效果给予不同的权重的问题,提出了一种基于改进重构损失函数的生成对抗网络图像修复算法.改进后的损失函数,可以帮助模型更加关注修复效果不好的区域,提升修复效果,减少伪影和模糊现象,同时在网络模型的编码器和解码器中引入多尺度稠密卷积模块,可以帮助模型更加有效的提取和利用特征,减少梯度消失问题.跳跃连接处使用的是残差空间注意力模块,可以让模型在获取更大的感受野,同时在参数量不变的情况下,提升像素间的相互依赖.
1 相关理论基础
1.1 生成对抗网络
生成对抗网络[7]的提出主要是用于图像的生成,具有优越的图像生成能力.近年来,许多研究者将生成对抗网络用于图像处理领域,并且取得了卓越的成就.生成对抗网络是由生成器和判别器组成,生成器的功能是用来绘制图像,生成器绘制好图像后会交给判别器.判别器的输入是真实图像和生成器绘制的图像,它的功能是判断出图像是有生成器绘制的,还是真实图像,如果是真实图像判别器会判断为真,如果是生成器绘制的图像,判别器会判断为假.判别器将判断结果作为损失传给生成器,生成器根据损失来调整参数后继续绘制图像.最终的结果是随着生成器绘制图像能力和判别器的判断能力不断增强,生成器绘制的图像已经是真假难辨.
1.2 图像修复中常用的损失函数
图像修复常用的损失函数有重构损失、感知损失[15]和风格损失[15].其中重构损失是衡量两张图像像素的差距.公式1是重构损失函数的公式,其中Itrue表示真实图像,Igf表示生成的修复后的图像.
Lr=‖Igf-Itrue‖1
(1)
但是仅仅依靠普通的重构损失并不能很好指导修复,这时就需要使用了感知损失和风格损失,感知损失是通过预先训练好的Vgg16网络模型[16]分别提取真实图像和修复图像的高级语义特征,然后计算真实图像和修复图像的高级语义特征的重构损失来指导图像进行修复,衡量的是真实图像和修复图像在高级语义上的相似性.感知损失其公式如公式2所示,其中Ψm表示通过VGG16网络的pool1、pool2,pool3层后提取的高级语义特征图,在这里N的值是3,表示需要通过VGG16网络分别对修复图像和真实图像提取三个高级语义特征图,并计算它们之间的重构损失,然后将三个重构损失求和得到感知损失.
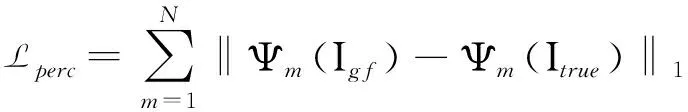
(2)
风格损失是用来衡量两张图像之间的风格相似程度,其计算方法是在感知损失计算重构损失之前,先计算每个特征图的格拉姆矩阵,其公式如公式3所示,其中G表示对高级语义特征图构建格拉姆矩阵.
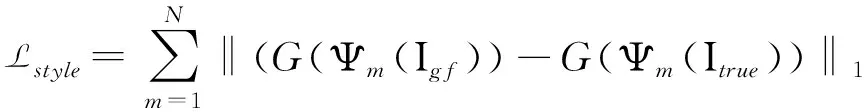
(3)
2 本文方法
2.1 生成器
生成器是基于u-net网络结构,结构图如图1所示,特征图顶部的尺寸,底部的是通道数量.破损图像首先进入到多尺度稠密卷积模块进行下采样,随后进入到8个残差块中提取深层次特征信息,接下来使用多尺度稠密卷积模块进行上采样,并且引入了带有空洞残差空间注意力模块的跳跃连接,最后输出修复好的图像,顶部的数字表示的是特征图经过处理后的尺寸,底部的数字是特征图经过处理后的通道数,本文方法的判别器使用的是文献[13]中的判别器.修复后的图像会与真实图像进行对比,计算损失大小,同时修复后的图像会放入到判别器判断真假,然后将损失传回给生成器进行参数调整.
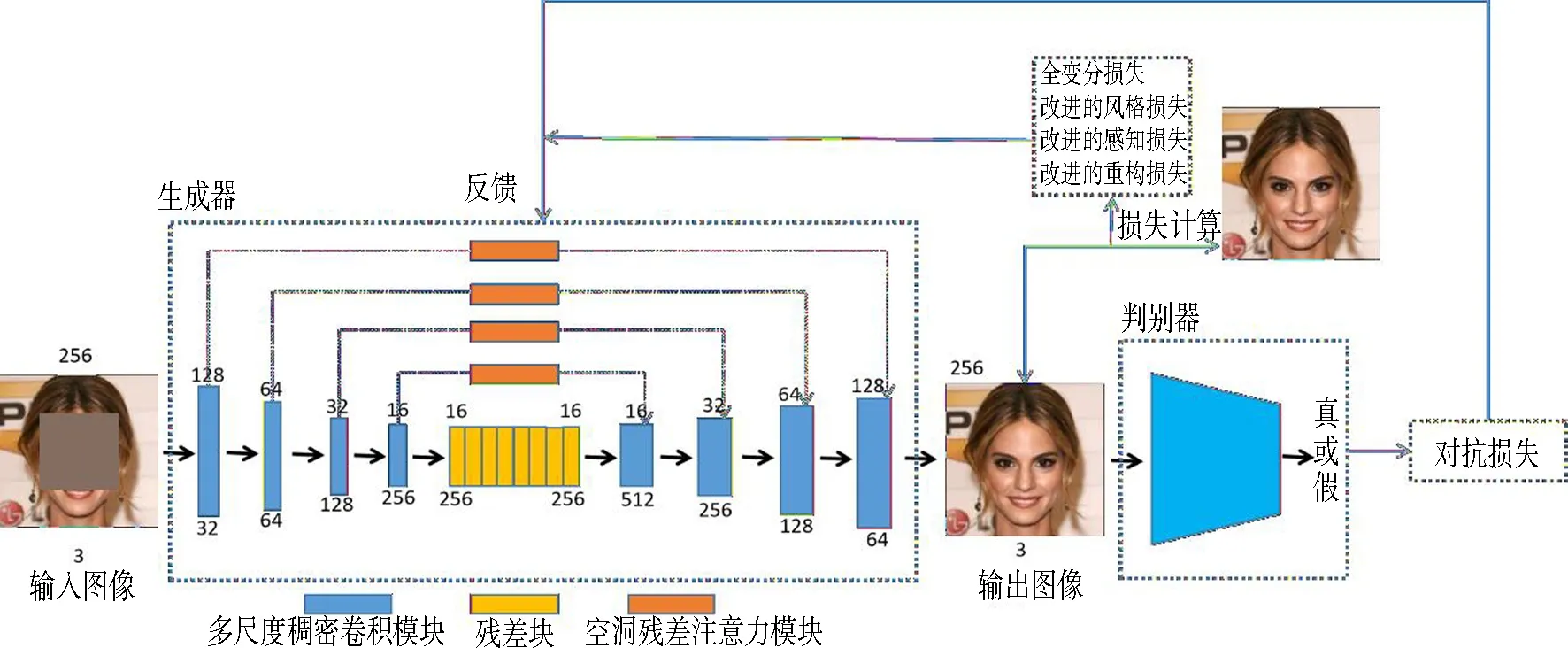
图1 生成器网络结构图
2.2 多尺度稠密卷积模块
编码器和解码器使用的是多尺度稠密卷积模块,在多尺度稠密卷积块中引入了空洞卷积,在参数量不变的情况下可以获取多个尺度的特征图,将多个尺度的特征图进行特征融合,得到多尺度特征图,多尺度稠密卷积模块的网络结构图如图2所示,图中的Conv后的数字依次是卷积的卷积核大小、步长、填充和扩张率.特征图从左侧开始输入,假设其通道数为C,首先特征图需要分别经过两个卷积核大小为3步长为2的卷积和ReLU激活函数,这时特征图的大小减半,特征图的通道数增加为2C,这个卷积的作用是改变特征图的尺寸大小. 接下来特征图会分别经过四个空洞卷积,卷积核大小为3步长为1,然后在经过BatchNorm2d和ReLU激活函数,空洞卷积的扩张率大小分别为1、2、4、8,空洞卷积用来获取多尺度的特征信息,这时特征图通道数不变和尺寸不变.空洞卷积可以在不增加参数量的情况下,增加网络的感受野.然后通过concat将多个感受野的特征图按照箭头方向进行堆叠,堆叠后的特征图从上到下通道数依次是4C、6C、8C.之后多尺度特征再分别经过三个卷积核大小为3,步长为1的卷积,这时特征图的通道数都变成2C.后面的卷积也是做类似的操作,最后一个concat将5个不同感受野的特征图堆叠到一起,特征图通道数变为10C,最后将特征图放入到卷积核大小为1,步长为1的卷积和LeakyReLU激活函数后,特征图最终的通道数变为2C,这样就完成了一次下采样,得到的特征图尺寸为原来的一半.上采样也是同样的网络模型,只是将开始的两个卷积换成卷积核大小为4,步长为2的反卷积,每次上采样后得到的特征图尺寸是原来的两倍.
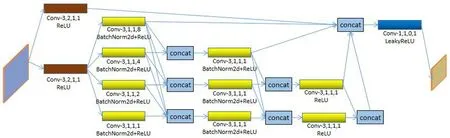
图2 多尺度稠密卷积模块网络结构图
2.3 空洞残差空间注意力模块
跳跃连接中的空洞残差注意力模块网络结构图如图3所示,conv表示卷积,其中的数字依次是卷积核大小、步长、填充和扩张率,特征图M1首先经过三个卷积和LeakyReLU激活函数,得到特征图M2,其尺寸和通道数不变.随后特征图依次进入到卷积核为1和卷积核为3的卷积中,其中卷积核为3卷积的扩张率分别是1、2、4、8,卷积核为1的卷积可以帮助降低参数量,空洞卷积用于扩大感受野.之后将4个提取到不同感受野信息的特征图堆叠起来,此时的通道数变为原来的4倍.随后通过卷积核为1的卷积将通道数变回原来的1倍,再经过LeakyReLU激活函数.最后通过卷积核为1的卷积道数变为1,再经过Sigmoid激活函数,将特征图限制在0-1之间,得到空间权重特征图M3.随后将空间权重特征图M3乘以特征图M2得到带注意力的特征图M4,最后将M1与M4相加再经过LeakyReLU激活函数,得到最终的残差空间注意力特征图.
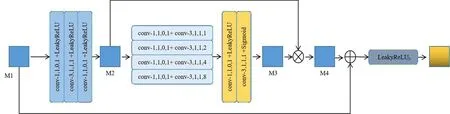
图3 空洞残差空间注意力模块网络结构图
2.4 损失函数
重构损失是用来衡量两张图像之间的像素距离,通过两张图像对应坐标像素点的差值相加得到,不管差值的多大都是用这样的方法去计算差值,而在图像修复中,需要的是对没有修复好的区域进行修复,这时就需要更加重构损失较大的区域,对于修复好的图像和真实图像之间的像素差值如果不进行加权处理,损失就不能很好的指导生成器进行图像的修复,这里对重构函数进行改进,让重构损失能够对修复不够好的区域给予更多的关注,来指导生成器对修复效果差的区域给予更多的关注度.改进方法是将修复后的图像和真实图像平均分割成N×N块,然后分别求出分割块的重构损失,将所有分割快的重构损失求和后除以块的数量计算出平均重构损失.将每个分割快的重构损失与平均重构损失作对比,如果重构损失大于平均重构损失,则对这一块的重构损失进行加权处理,加权公式为如公式4,如果重构损失小于平均重构损失则继续使用未加权的重构损失.
Lw-recon=W×L+Sigmoid(L)
(4)
改进的重构损失公式如公式5所示,Lw-recon是改进的重构损失,PatchW表示分割加权运算,N表示分割系数,W表示权重系数,Itrue表示真实图像,Igf表示生成的修复后的图像.
Lw-recon=PatchW(N,W,Igf,Itrue)
(5)
改进后感知损失的定义如公式6所示.
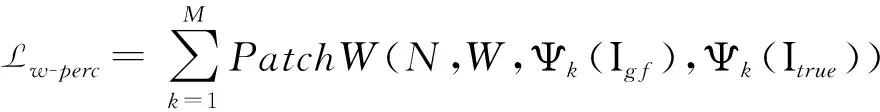
(6)
改进后的风格损失也是将其中的重构损失换成改进的重构损失,其定义如公式7.
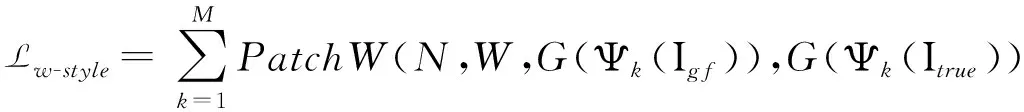
(7)
对抗损失可以用来优化网络参数,降低对抗损失,增强修复图像的纹理和结构一致性,对抗损失函数定义如公式8,pgf代表生成器生成数据的分布,ptrue代表真实数据的分布,表示期望.
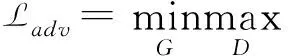
(8)
全变分损失[17]可以用于改善修复后图像的平滑度,增强掩膜边界的平滑性,改善伪影问题.其定义如公式9所示,p,q是像素点坐标.
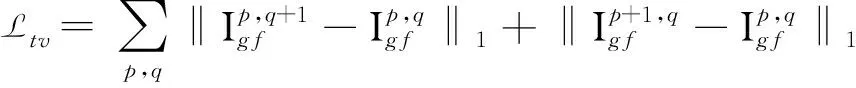
(9)
总的损失函数定义如公式10.
Ltotal=λadvLadv+λreconLw-recon+λpercLw-perc+λstyleLw-style+λtvLtv
(10)
3 实验
3.1 数据集与运行环境
本文使用人脸公开数据集CelebA[18]进行实验.CelebA数据集包含了202599张人脸图像,随机抽取其中的20000张图像用来训练,然后在剩余的图像中随机抽取1000张用于作为测试集.
训练集和测试集图像经过处理后得到256×256大小的图像,输入生成器的图像大小为256×256,其中训练和测试使用的是128×128的中心掩膜来模拟破损区域.训练集进行30次循环,训练时Batchsize大小设置为4,使用的是Adam优化器.实验损失函数的参数设置为λadv=0.2,λrecon=10,λperc=1,λstyle=120,λtv=0.01,学习率为2×10-4.
3.2 定性分析
本文方法分别与GLCIC[9]、Pconv[19]、Shift-Net[13]、CTSDG[20]4种算法进行对比实验.如图9所示,是4种算法对CelebA数据集的修复效果,从图1-4分别是带掩码的图像、GLCIC算法修复效果、Pconv算法修复效果、Shift-Net算法修复效果、CTSDG算法修复效果、本文修复效果和真实图像.
由图4可以看出,GLCIC的修复效果是在第2列,修复后图像有着明显的的伪影和模糊,特别是在眼睛和眉毛附近,修复效果很不理想.Pconv算法修复结果在第3列,可以看出其修复效果好于前面的算法,不过第一张眼镜的修复效果不理想,还有第三张的鼻子和嘴巴有些模糊,产生了粘连.Shift-Net算法修复效果在第4列,可以看出其修复效果也不是很好,第一张图像中的眼镜只修复好了一半,第二张和第三张图像的眼睛处出现了模糊和伪影现象,修复后的图像没有得到很好的修复效果.CTSDG算法修复效果在第5列,可以看出其修复效果在视觉上有了很大的提升,但是依然存在一些问题,比如第一张修复的图像虽然修复出了眼镜轮廓,但是在结构上还是不连贯,第二张修复图像除了额头上有一点伪影,整体的修复还是令人满意的.第三张修复的图像也达到了预期的修复效果,但是在图像左侧的眉毛处还是存在瑕疵.本文模型修复效果在第6列,可以看出修复图像已经达到了很好的视觉效果,和真实图像已经十分接近,没有出现明显的模糊现象,也没有很明显伪影现象,脸部细节得到了很好的修复,修复的整体效果也都优于对比算法.

图4 不同方法在CelebA数据集中心掩膜修复效果
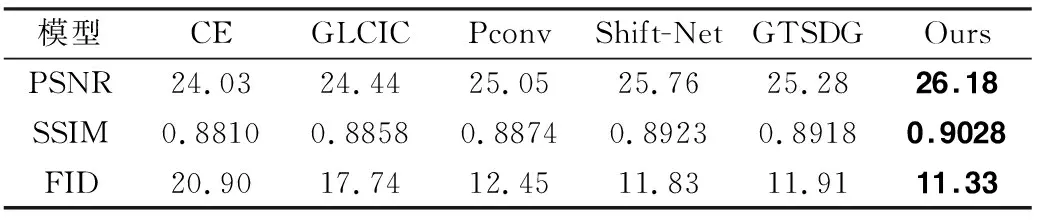
表1 在CelabA数据集在中心掩码上各算法修复对比
3.3 定量分析
本文对修复结果还通过峰值信噪比(Peak Signal to Noise Ratio)PSNR[21]、结构相似性(Structural Similarity Index)SSIM[22]和弗雷歇距离(Fréchet Inception Distance,FID)进行定量分析.峰值信噪比是用来检测修复图像和真实图像的细节修复效果,值越大表示修复效果越好.结构相似性衡量的是修复图像和真实图像之间结构的相似程度,值越大表示修复结果越好.FID计算的是修复图像和真实图像高维特征的相似程度,值越小说明越相似.
表1是在CelebA数据集上各算法在中心掩码上的性能指标,可以看出本文算法各项指标都取得了最好的效果,说明了本文算法无论在定性分析还是在定量分析上有要优于对比算法.
4 结语
本文提出了一种基于改进重构损失函数的生成对抗网络图像修复方法,对重构损失进行改进,可以指导网络对修复不佳的区域给予更多的关注度,提升修复效果.同时在编码器和解码器中引入多尺度稠密卷积模块,帮助模型在下采样时加强多尺度特征的提取,并且有助于加强特征的传递.跳跃连接处使用的是空洞残差空间注意力模块,扩大网络模型的感受野,加强了低维度特征的利用,提升修复质量.但是本方法还存在一些问题,对于面积比较大并且背景复杂的破损图像,其修复效果还有待提升,因此接下来的工作将继续对生成网络和判别网络进行改进,增强对大面积缺失的修复效果.
猜你喜欢
摄影世界(2022年1期)2022-01-21
数学小灵通·3-4年级(2021年5期)2021-07-16
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
今日农业(2019年15期)2019-01-03
知识经济·中国直销(2018年12期)2018-12-29
商周刊(2017年6期)2017-08-22
山东大学法律评论(2016年0期)2016-08-16
太空探索(2016年5期)2016-07-12
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
