
一种基于BP神经网络的完井液污染类型识别方法
2023-12-31 04:02程鑫张太亮杨兰平阳清正白毅
石油与天然气化工 2023年6期
程鑫 张太亮 杨兰平 阳清正 白毅
1.西南石油大学化学化工学院 2.中国石油集团川庆钻探工程有限公司钻井液技术服务公司
在油田目的层钻井过程中,完井液会不同程度地受到盐水、残酸等的污染,从而恶化完井液性能。由于现场对污染类型的判断不准确,常规的处理方法是提高完井液抗温性或降低其黏度,但反复处理后完井液性能仍不能恢复,因此,需要一种能够在现场准确而快速地识别完井液污染类型的方法。
由于目前国内外针对完井液污染识别问题的研究不多,故只能借鉴作为完井液前身的钻井液的污染识别方法,其污染识别方法主要分为观察法和仪器法。例如,艾加伟[1]发现钻井液受污染后呈暗黑色、滤饼虚厚且伴随针孔等。这些现象都具有较强的经验性,且完井液大多会添加深色的处理剂,使得观察法不适用于完井液污染识别;徐晨阳等[2]利用钻井液污染前后的粒径分布和Zeta电位的不同来判断钻井液污染情况,室内仪器检测法虽同样适用于完井液,但现场实验中可能因缺少大型仪器而降低污染识别的效率。
在过往对完井液污染问题的研究中,开展了许多针对完井液污染机理的研究基础。例如:吴涛等[3]研究发现,过多的盐水侵污油基钻井液会使分散液滴易聚集,降低泥浆乳液稳定性,导致泥浆黏度提高;王志龙等[4]研究发现,有机盐钻井液体系在饱和盐水加量超20%(质量分数)后,其黏度、动切力均降低50%以上,且密度持续降低,认为盐水侵污主要表现为稀释作用。根据这些理论,可知完井液的污染具有不同性能数值表现,故而可使用机器学习识别分类。
本研究利用完井液进行盐水、残酸污染实验,对比其流变性能差异,由K-means聚类订正数据集的污染等级标签。建立BP神经网络污染类型的识别模型,用交叉验证法检验模型准确率,为完井液污染识别方法提供了新思路。
1 实验部分
1.1 原料与仪器
水基完井液取自023-H1井、JT-1井,密度分别为1.75 g/cm3、2.28 g/cm3;油基完井液取自mx133井、oil1.8井,密度分别为1.42 g/cm3、1.80 g/cm3;配液用水为实验室蒸馏水;化学试剂为无水氯化钙、氯化钠、六水氯化镁、浓盐酸(均为分析纯),成都市科隆化学品有限公司。
JK-50B型超声波清洗器,合肥金尼克机械制造有限公司;GJS-B12K型高速搅拌器,青岛同春石油仪器有限公司;HTD-D6S六速旋转黏度计,青岛恒泰达机电设备有限公司;PHS-3CU型pH计,上海越平科学仪器(苏州)制造有限公司;NB-1型泥浆比重计,武汉格莱莫检测设备有限公司;GRL-BX3型滚子加热炉,青岛恒泰达机电设备有限公司;GGS42-A2型高温高压滤失仪,青岛恒泰达机电设备有限公司。
1.2 污染源的配制
地层盐水质量浓度配比为:Cl-4.21×104mg/L,Ca2+1.6×104mg/L,Mg2+800 mg/L,总矿化度7.241×104mg/L。室内采用CaCl2、MgCl2·6H2O、NaCl配制地层盐水。
根据现场返排液取样分析结果,其残酸质量分数约为5%。室内配制质量分数为5%的盐酸溶液,以模拟残酸。
1.3 污染后完井液性能测试
测试的方法参考GB/T 16783.1-2014《石油天然气工业 钻井液现场测试 第1部分:水基钻井液》。量取2/3高速搅拌杯体积的完井液,记录质量。再根据污染源在完井液中的质量占比,量取第1.2节中的污染源(地层盐水、残酸)加入高速搅拌杯中,进行老化前(BF)与老化后(AF)的性能测试,其老化条件为170 ℃、热辊16 h。
1.4 实验数据的组成及预处理
1.4.1实验数据的组成
4种完井液数据共有112组,具体分布见表1。表2所列为完井液受污染的特征因素。由表2可知,每组完井液数据样本特征从流变、老化、滤失、井名及受污染情况5个方面共统计了25个特征因素。所有完井液数据样本构成数据集,用于训练的原始数据集见参考文献[5]。
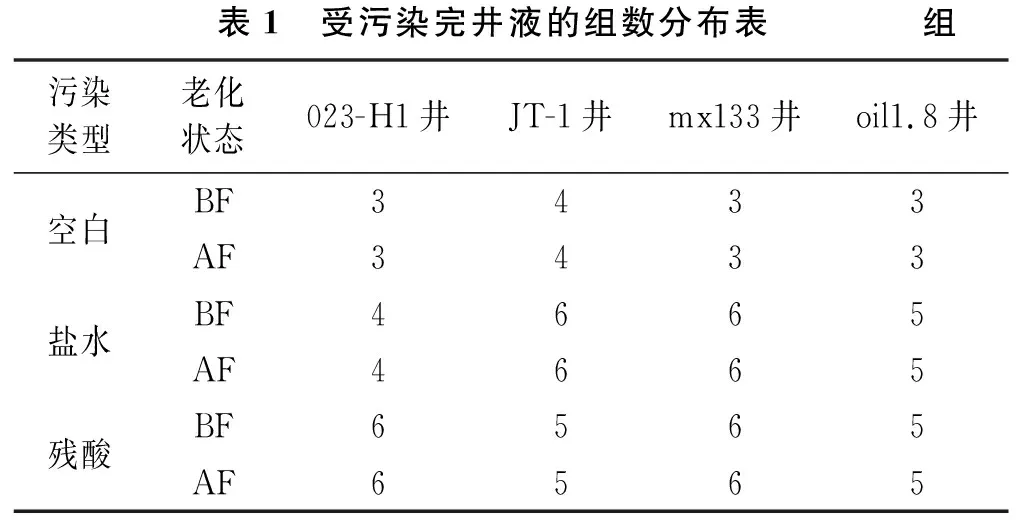
表1 受污染完井液的组数分布表 组污染类型老化状态023-H1井JT-1井mx133井oil1.8井空白BF3433AF3433盐水BF4665AF4665残酸BF6565AF6565

表2 完井液受污染的特征因素统计序号特征类特征因素详情12345678910111213141516流变Φ600:六速流变仪Φ600测试值,mPa·sΦ300:六速流变仪Φ300测试值,mPa·sΦ200:六速流变仪Φ200测试值,mPa·sΦ100:六速流变仪Φ100测试值,mPa·sΦ6:六速流变仪Φ6测试值,mPa·sΦ3:六速流变仪Φ3测试值,mPa·sG':Φ600搅拌、静置10 s,3 r/min转速下读最大值G″:Φ600搅拌、静置10 min,3 r/min转速下读最大值表观黏度(AV):0.5×Φ600塑性黏度(PV):Φ600-Φ300动切力(YP):AV-PV动塑比(YP_PV):YP/PV初切力:0.5×G'终切力:0.5×G″流性指数:描述流体流动现象的无量纲参数稠度系数:流体流动的视黏度无量纲参数17老化老化状态:BF、AF18高温高压滤失量(HTHP):高温高压30 min滤失量×2,mL19滤失pH值:高温高压滤液的pH值20滤饼厚度:高温高压滤饼厚度,mm21井名:完井液的名字22完井液配方类型:油基、水基23密度:完井液密度2425完井液受污染情况污染源质量分数:污染源占完井液的质量分数,%污染源类型:0空白组,1盐水污染,2残酸污染
1.4.2预处理方法
(1) 标准化与缺失值填补:为消除量纲对模型的影响,对原始数据集中数值型特征应用Z-Score标准化[6];对数据缺失点进行填“0”处理[7],取数值均值。
(2) 定性变量处理:完井液污染定性分为空白样本、盐水污染样本和残酸污染样本,本研究用“0空白组”标记空白样本,“1盐水污染”标记盐水污染样本,“2残酸污染”标记残酸污染样本,完成数据集的标签定性变量转化;采用独热向量法将定性因素特征转化为定量数值特征[8],完成数据集文本型特征变量转化;数据集需要处理的定性特征包含井名、类型、老化状态。
1.5 模型建立与参数选择
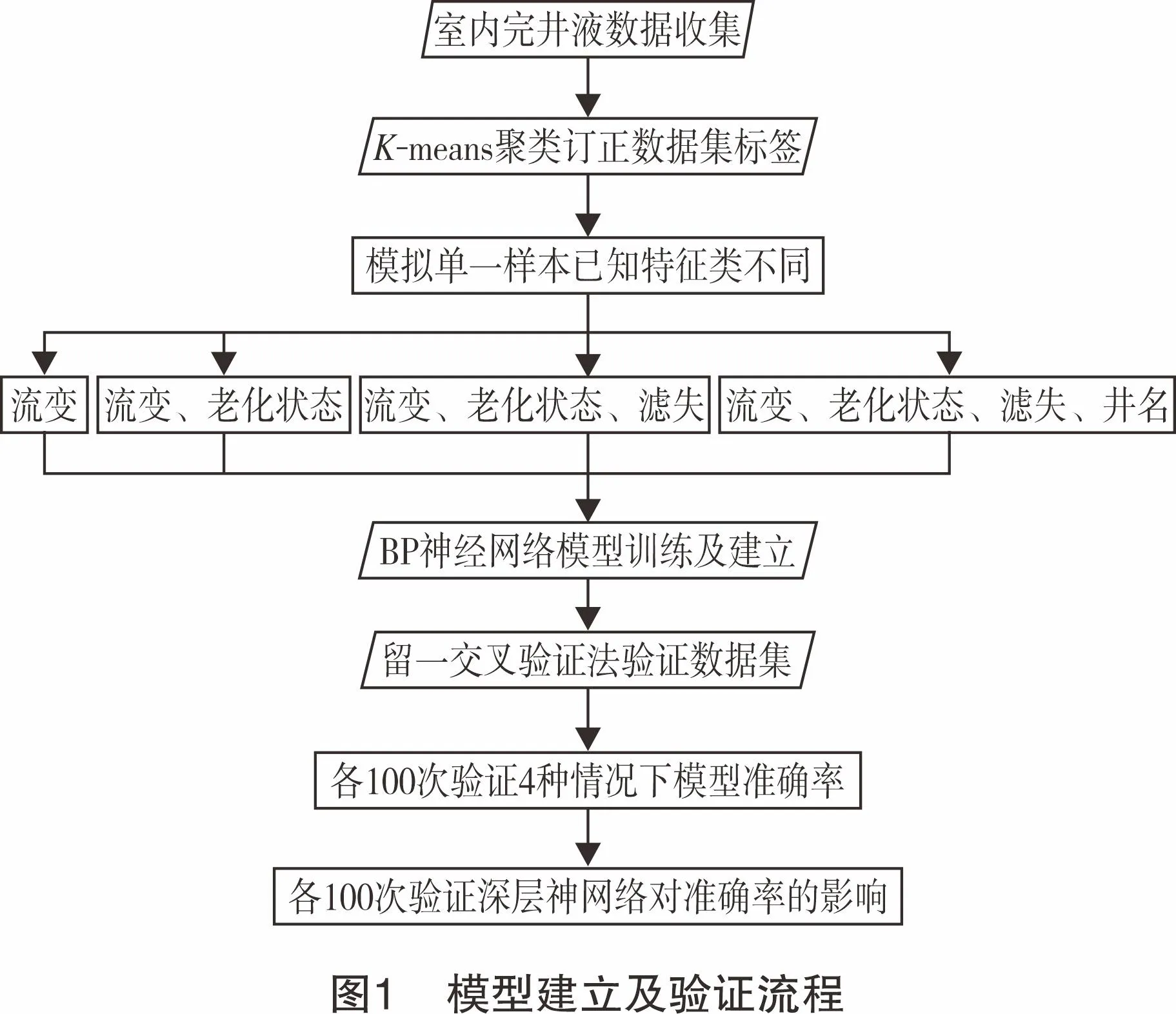
对4种不同密度的水基、油基完井液进行盐水、残酸污染室内试验。通过K-means聚类订正数据集的污染等级标签,选取不同特征、隐层,分别建立BP神经网络污染类型的识别模型。由留一交叉验证法检验模型分类准确率,模型建立流程如图1所示。
1.5.1K-means聚类参数选择
蔟类数K由肘部法则确定[9];聚类迭代退出条件为蔟类中心不再发生变化[10];可视化方法用Python从sklearn.decomposition库引入PCA算法将特征降维至2维。
在室内实验中,已知每个数据样本的污染类型和污染物的质量占比,需要将污染物质量占比较小且完井液性能变化也较小的数据样本划入“0空白组”。但由于缺乏对完井液受污染等级分类的评价标准,所以将K-means聚类算法作为一种统一的划分标准。
1.5.2BP神经网络参数选择
模型训练中数据迭代次数为3 000次/轮;学习率设置为0.15;隐层激活函数为ReLu函数和SoftMax函数[11];反向传播的规则为交叉熵损失(CEL)与随机梯度下降(SGD);隐层节点数目根据Kolmogorov定理确定[12]。
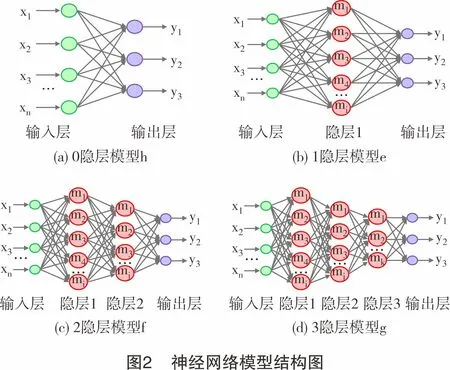
模拟完井液异常后,测量单一样本特征,判断污染类型。探究数据样本特征对BP神经网络分类准确率的影响。根据特征获取的难易程度将数据特征分为4类:第1类特征“流变”(表2中序号:1~16),完井液基本属性测量简易快速;第2类特征“老化”(表2中序号:17),非室内实验不容易界定;第3类特征“滤失”(表2中序号:18~20),测量耗时且不易快速获取;第4类特征“井名”(表2中序号:21~23),容易出现记录缺失或多种完井液共用井名。将这4类特征逐级叠加,分别训练对应的BP神经网络模型,且模型均采用同参数的3层网络结构,不同特征类训练的模型对应表3所列内容。由留一交叉验证法对比各个模型的分类准确率[13],即使用112组中任意111组数据样本判断剩余的1组数据样本的污染类型,并统计当轮112个单一样本数据分类的准确率。该模型将进行100次留一交叉验证,收集每次交叉验证的准确率。对比模型a、b、c、d(均为1个隐藏层数)的准确率,优选出准确率最高的模型a。

表3 不同特征类训练的BP神经网络模型模型编号输入特征类模型a模型b模型c模型d流变流变+老化流变+老化+滤失流变+老化+滤失+井名
探究不同深度BP神经网络对分类准确率的影响。再次训练新模型,全部使用模型a输入的特征类训练模型。为防止出现模型过拟合[14],再次训练的模型h隐藏层为0层(见图2(a))、模型e隐藏层为1层(见图2(b))、模型f隐藏层为2层(见图2(c))和模型g隐藏层为3层(见图2(d))。对比模型e、f、g、h的准确率,优选出最佳BP神经网络的隐层数目。
2 实验结果与讨论
2.1 数据差异性分析
不同井受盐水梯度污染的流变性关系图如图3所示,轻度盐水污染下的流变性稳定,表明水基、油基完井液对盐水污染均有一定的缓冲能力,水基完井液的黏度会逐渐降低,而油基完井液的黏度则会逐渐增加[15-16]。图4所示为不同井受残酸梯度污染的流变性关系图。由图4可知:水基、油基完井液均对残酸具有敏感性,质量占比仅0.5%的残酸就可使流变性数值增长1.5~2.0倍;当残酸质量占比为0.5%~3.0%时,高密度完井液黏度迅速下降,而低密度完井液黏度出现一段稳定数值的“平台期”后迅速下降;残酸质量占比继续增大,水基完井液受稀释作用,其黏度逐渐减小,而油基完井液黏度则持续增大。
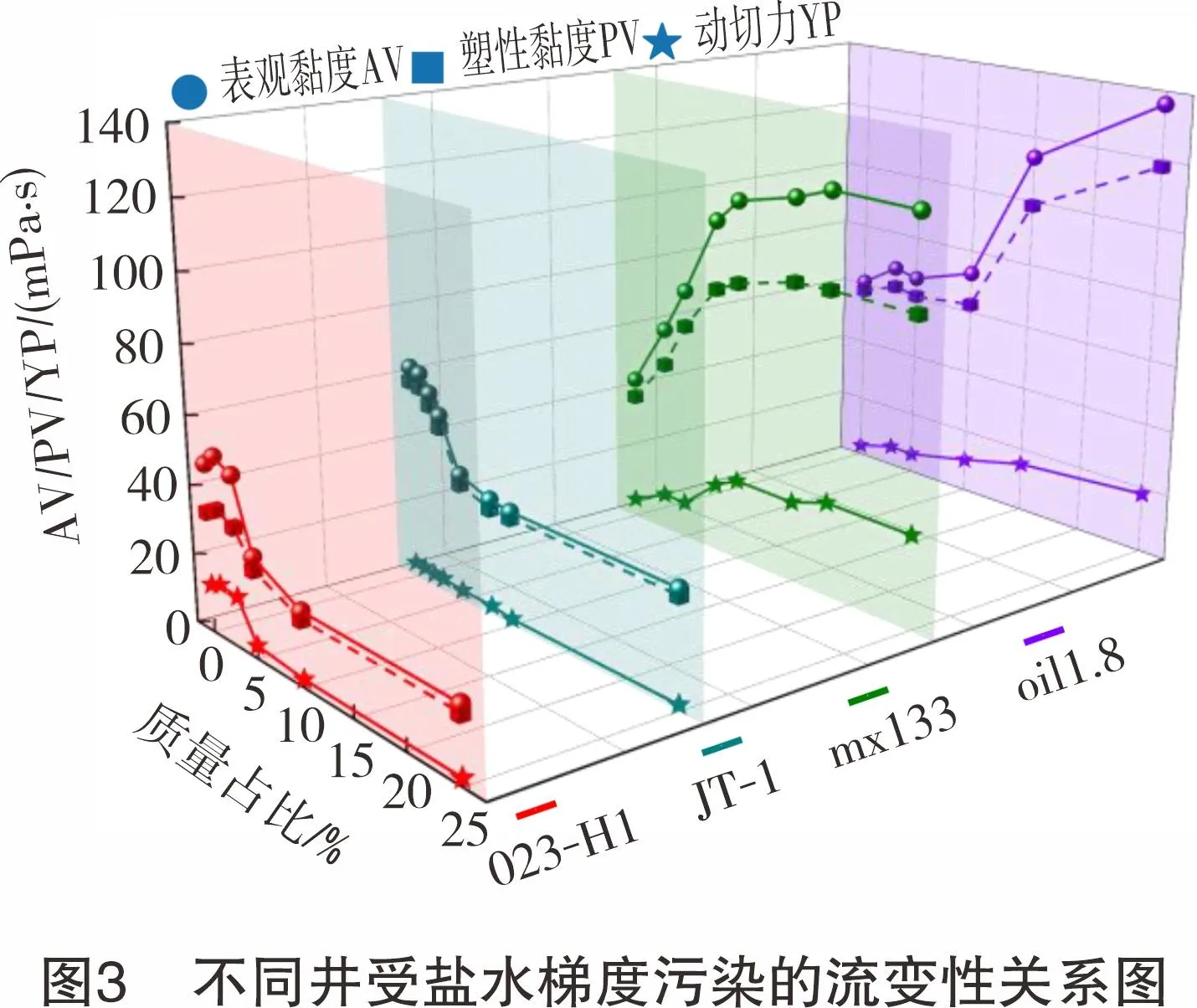
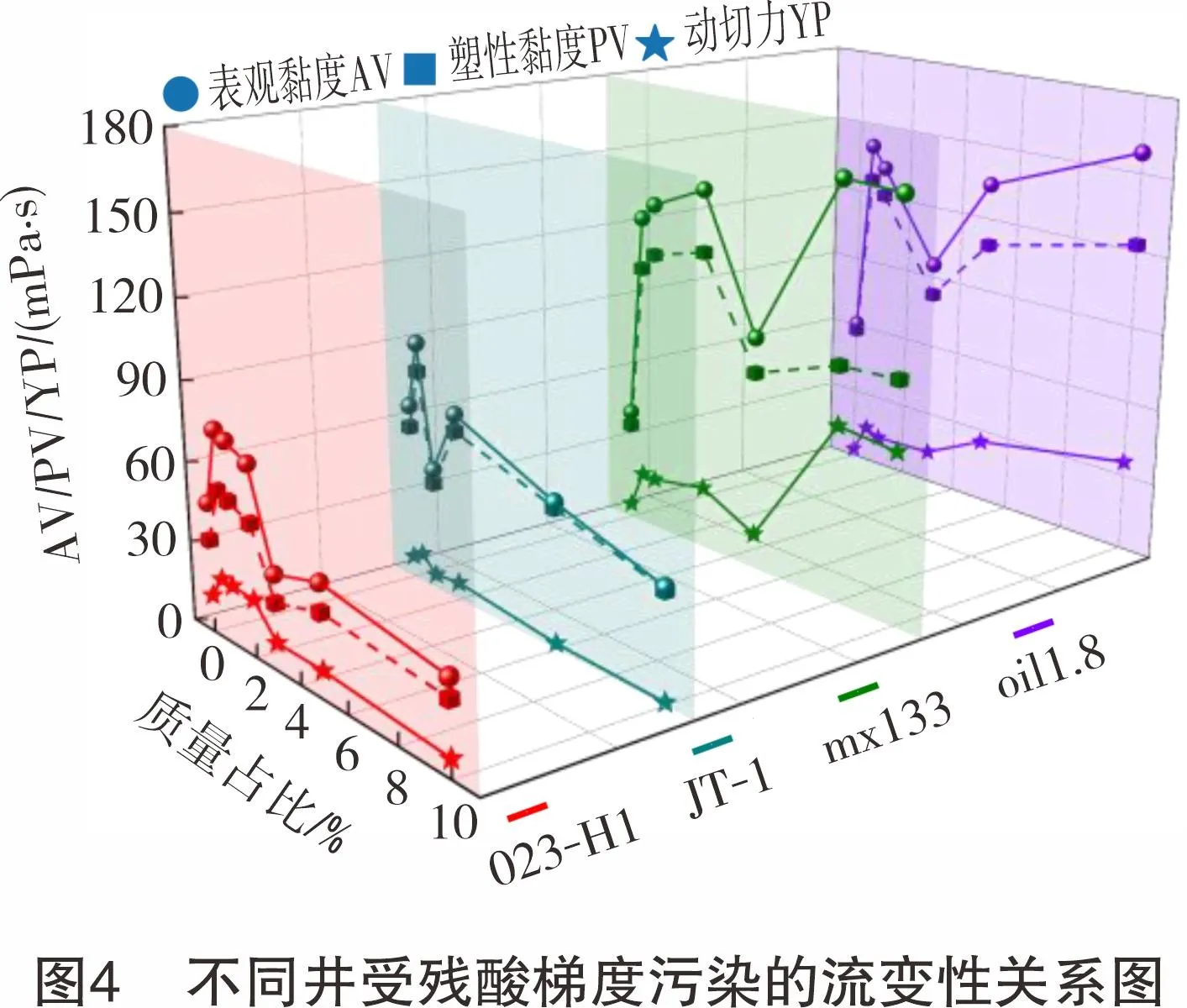
每添加一种不同质量占比的污染源后测量完井液的性能得到数据样本,而不是在同一次测量中连续添加污染源后进行测量,体现了数据的独立性。同类型的完井液在受到盐水或残酸污染后均有相同的流变性变化趋势,不同类型的完井液在受到污染后流变性差异显著,体现了数据的同分布性。流变性作为本研究数据构成的主体,满足建立模型数据尽量独立同分布的要求。
2.2 污染等级聚类分析
2.2.1K-means聚类算法的运用对象
并非任意质量占比的污染源都会使完井液性能发生较大变化,因完井液存在抗污染的缓冲机制[17],所以一定程度内的污染可作“0空白组”。K-means聚类将“同类条件的样本”进行最适合的类别分类[18],为每组样本订正污染源类型的标签。同类条件的完井液样本参考表4,需将预处理的完井数据分为16组进行K-means聚类。

表4 完井液样本的同类条件井名污染源类型老化状态023-H1井JT-1井地层盐水BFmx133井oil1.8井残酸返排液AF
2.2.2污染等级的聚类分组
为提高聚类迭代效率,肘部法则遵循剔除以下特征:分组用过的特征(如第2.2.1节中特征)、缺失值过多的特征(如HTHP、滤饼厚度特征)、特征值相同的特征(如污染源类型特征)。
盐水污染的肘部法则如图5所示,由图5可知,4种完井液老化前后数据均在K=2时具有较好的聚类效果。其K-means聚类结果根据污染梯度由小到大排列分为“空白组(●)”和“污染组(■)”两类(见图6),并订正盐水污染数据样本的标签为“0空白组”和“1盐水污染”(见表5);残酸污染的肘部法则如图7所示,4种完井液中仅有oil1.8井的老化后在K=2时数据具有较好的聚类效果,其余数据组均在K=3时具有较好的聚类效果,其K-means聚类结果根据污染梯度由小到大地排列为“空白组(●)”“中度污染组(▲)”和 “重度污染组(★)”3类,如图8所示。统一将残酸中度、重度污染归为一类,订正残酸污染数据样本的标签为“0空白组”和“2残酸污染”(见表6)。
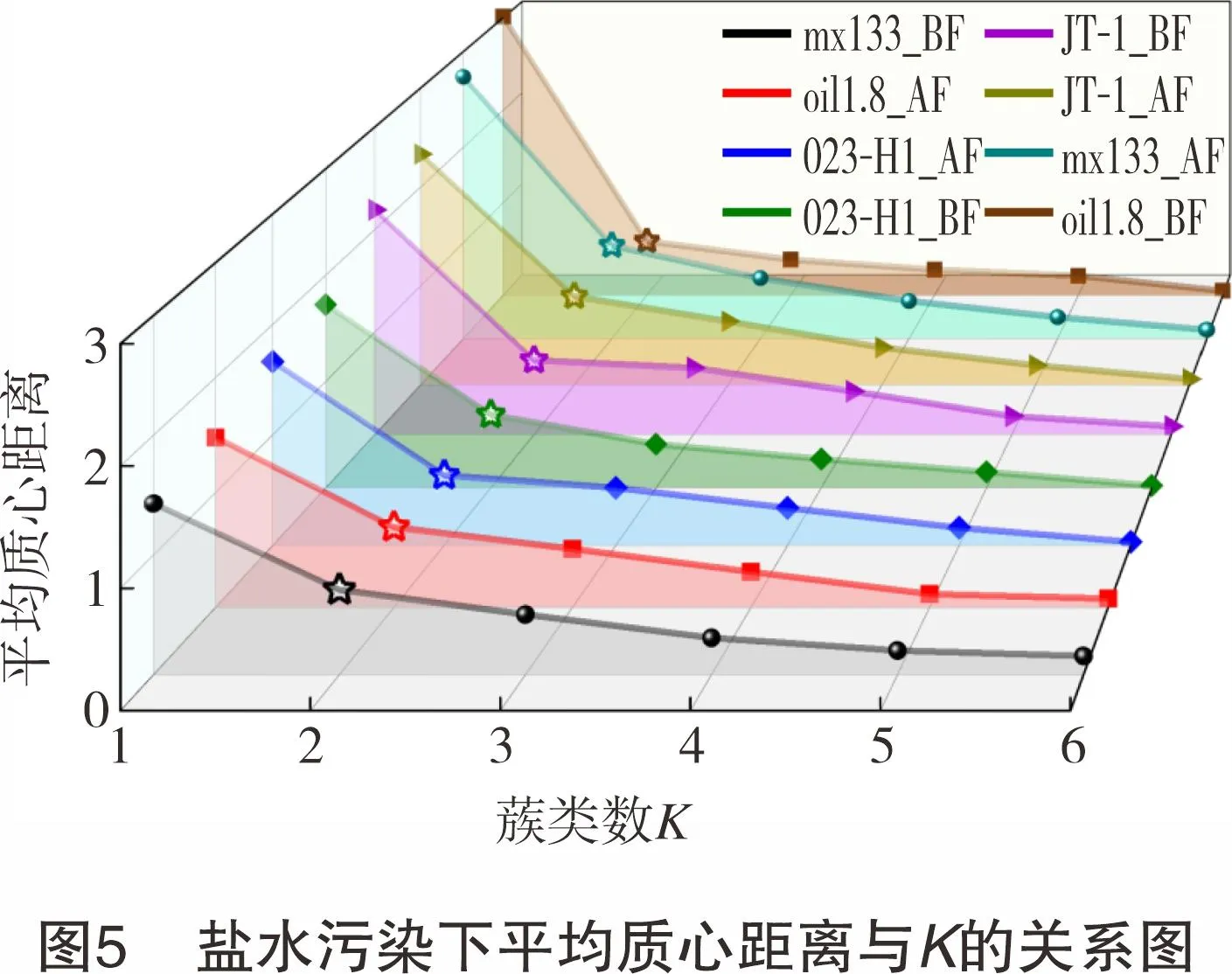
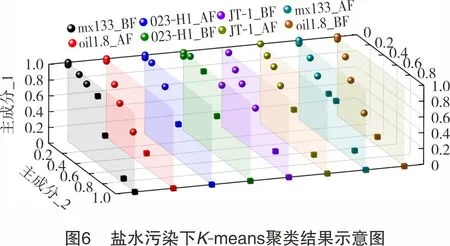

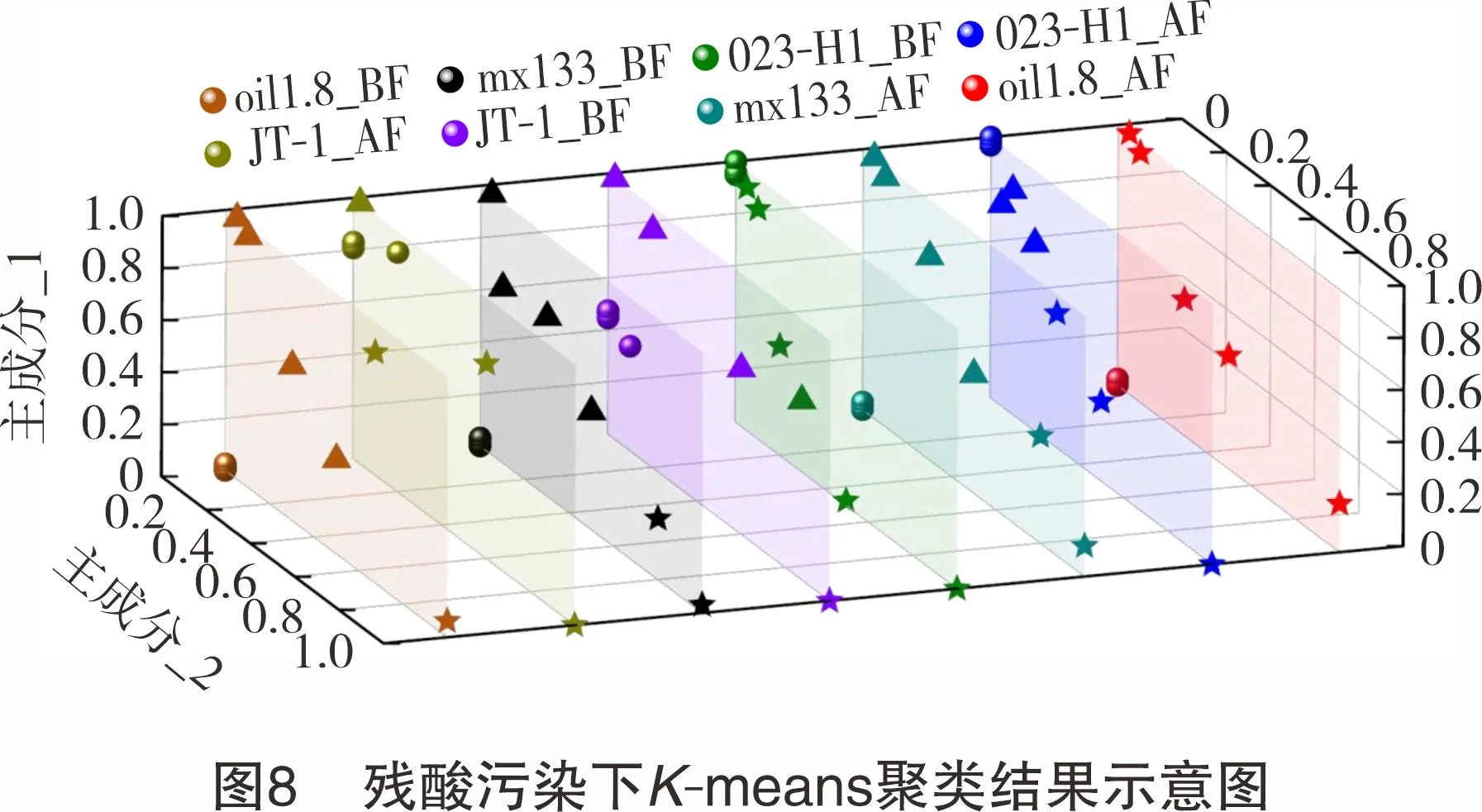
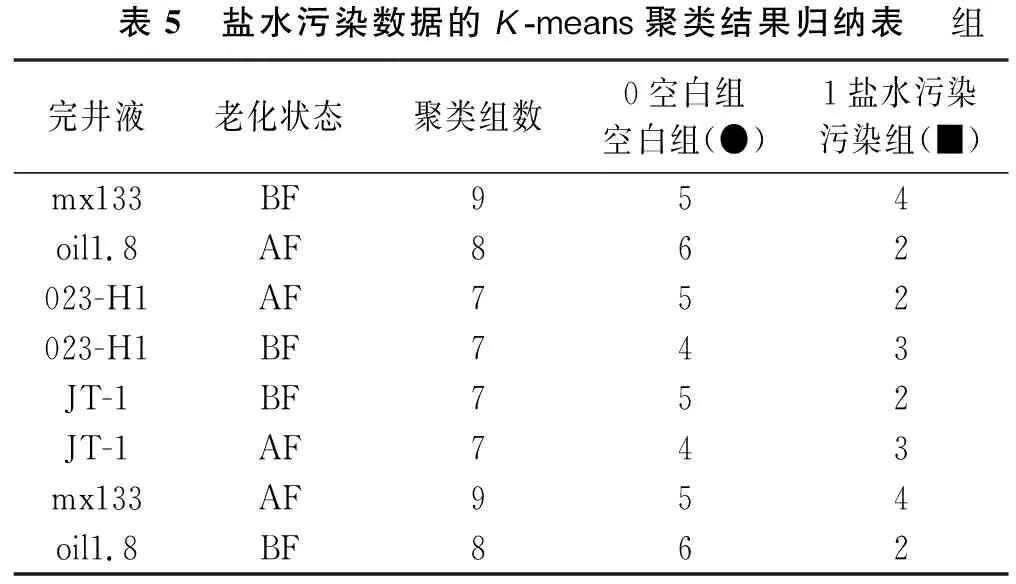
表5 盐水污染数据的K-means聚类结果归纳表组完井液老化状态聚类组数0空白组空白组(●)1盐水污染污染组(■)mx133BF954oil1.8AF862023-H1AF752023-H1BF743JT-1BF752JT-1AF743mx133AF954oil1.8BF862
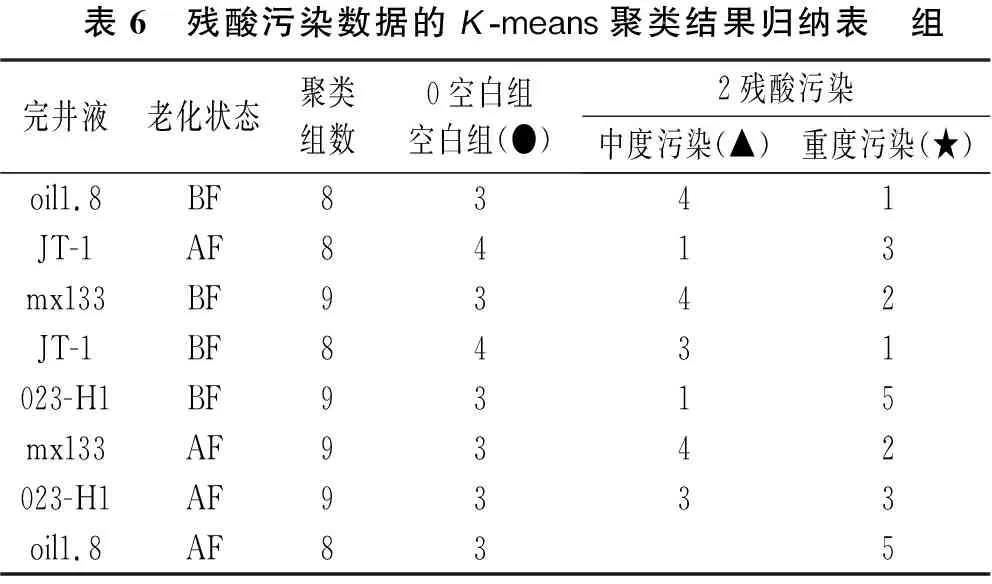
表6 残酸污染数据的K-means聚类结果归纳表 组完井液老化状态聚类组数0空白组空白组(●)2残酸污染中度污染(▲)重度污染(★)oil1.8BF8341JT-1AF8413mx133BF9342JT-1BF8431023-H1BF9315mx133AF9342023-H1AF9333oil1.8AF835
2.3 模型建立与检验
2.3.1不同特征类构建的BP神经网络模型
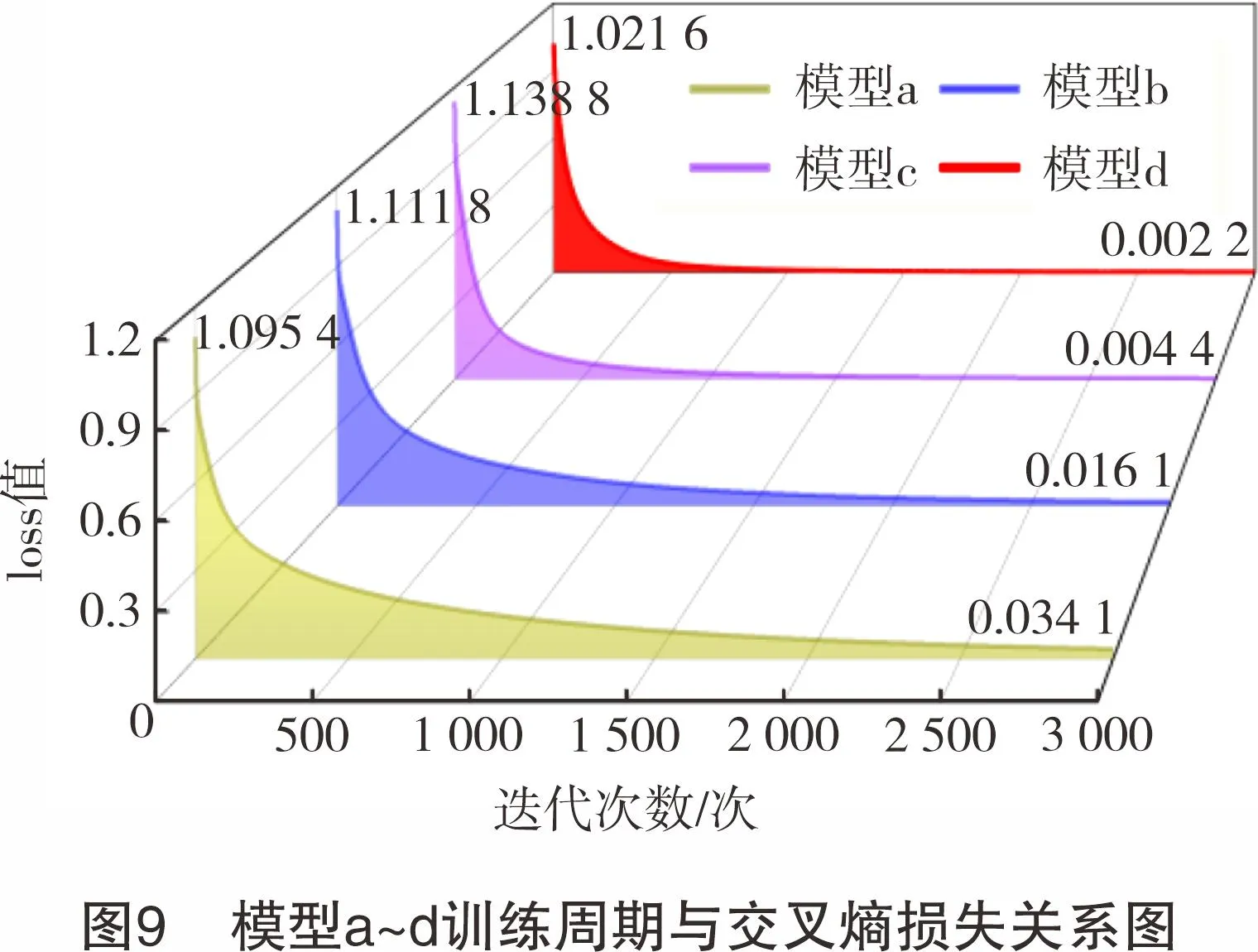
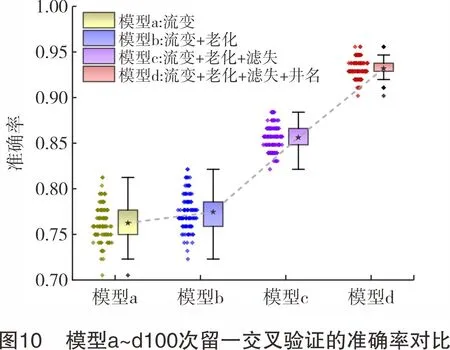
模型a、b、c、d使用第1.5.2节参数设置,将订正标签后的完井液数据集代入各模型,其初始交叉熵损失值(loss值)与迭代次数关系如图9所示。迭代次数为0时,通过BP神经网络计算其loss值。模型a、b、c初始loss值均在1.1波动,模型d初始loss值接近于1.0,表明模型d对数据集的初始拟合程度可能更好。经3 000次数据迭代后,所有模型loss值均下降值均比初始loss值下降了97.0%~99.8%,且无loss值曲线波动情况,说明4种模型在训练后均收敛,模型在完井液数据集上可用。对模型a、b、c、d分别进行100次留一交叉验证,各模型准确率如图10所示。随特征的逐类叠加,模型预测更加稳定、准确率升高,其中“滤失”“井名”特征类对准确率提升效果显著,使模型d的平均准确率达93.18%。
模型d具有最高的平均准确率,所以,在探究不同深度BP神经网络对分类准确率的影响时,将模型e、f、g、h固定输入“流变+老化+滤失+井名”特征类。
2.3.2不同隐藏层构建的BP神经网络模型
模型e、f、g、h使用第1.5.2节参数并固定输入特征类,但构建的隐藏层数目不同。其loss值与迭代次数关系如图11所示。迭代次数为0时,1隐层的模型e对数据集的初始拟合程度可能比没有隐层或者更多隐层数目的模型更好。经3 000次数据迭代后,模型h的loss值下降幅度缓慢,模型建立不理想,属于欠拟合状态[19]。模型e、f、g的loss值均相比初始loss值下降了96.7%,但模型g有loss值曲线波动的情况,可能出现过拟合或局部最优[20]。仅模型e、f在完井液数据集上表现较为理想。对模型e、f、g、h分别进行100次留一交叉验证,各模型准确率如图12所示。模型h无隐藏层属于一般线性分类,其100次预测准确率均在79.46%,说明一般线性分类并没有从数据集学习的能力。模型e、f、g的平均准确率分别为93.18%、92.49%、91.42%,随隐藏层数目的增多,模型学习能力增强,但模型准确率却逐渐下降。由此说明本研究完井液数据集特征并不复杂,不需要太多有学习能力的全连接层。隐藏层数增多引起模型过拟合,在未知的验证样本预测中丧失泛化性[21]。
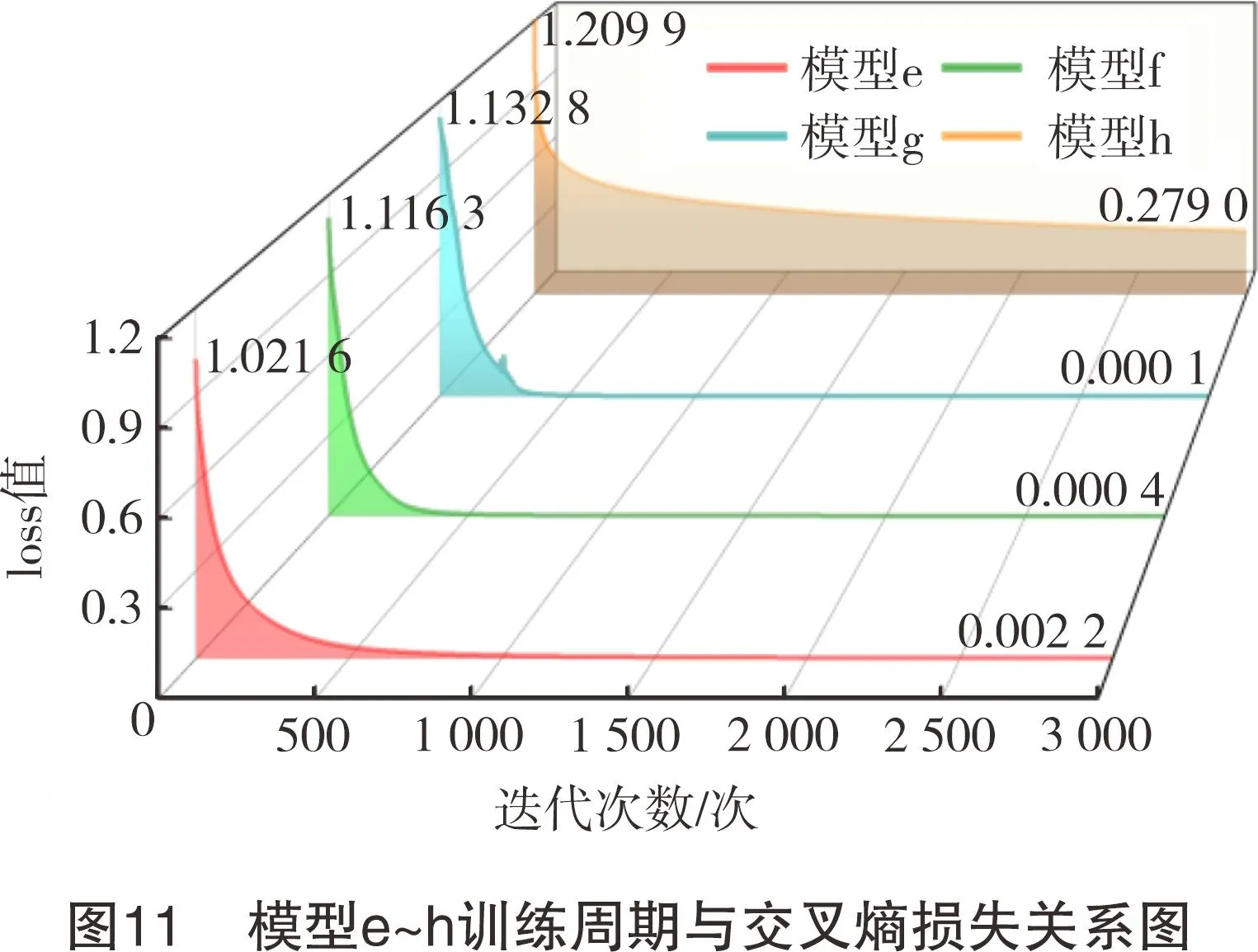
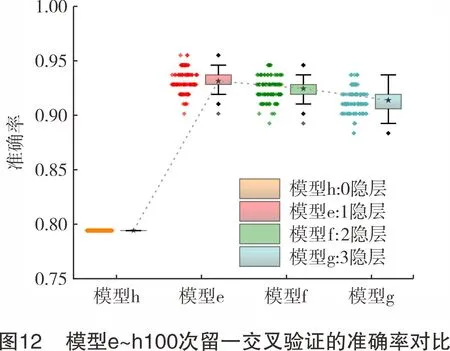
最终优选出包含特征“流变+老化+滤失+井名”与1隐藏层的BP神经网络模型作为完井液污染识别方法。
3 结论
(1) 完井液每添加1种质量占比的污染源后测量“流变、老化、滤失、井名”4类特征数据,来满足数据的独立性。同类型的完井液在受到盐水或残酸污染后均有相同的流变性变化趋势,不同类型的完井液在受到污染后流变性差异显著,体现数据同分布性。将流变性作为本研究数据构成的主体,以满足模型建立要求数据尽量独立同分布的前提。
(2) 建立BP神经网络需要每一个完井液数据样本具有污染类型标签。本研究没有污染程度划分标准,采用K-means聚类订正每一个数据样本的标签。数据输入前,对数值型特征采用Z-Score标准化,对文本型特征采用独热向量处理,以消除量纲的影响。处理完毕的数据可选取部分特征类建立不同隐层数目的BP神经网络模型。
(3) 探究了逐类叠加4种特征类训练不同BP神经网络模型,再由留一交叉验证法进行100次检验,以验证模型的分类准确率。在上一步最优模型的基础上,改变隐藏层数目,探究神经网络深度对准确率的影响。最终选择包含“流变+老化+滤失+井名”4类特征的数据样本建立1隐藏层的BP神经网络模型,其平均分类准确率达到93.18%。
猜你喜欢
中国石油大学学报(自然科学版)(2021年4期)2021-08-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
化工管理(2021年7期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
钻井液与完井液(2019年5期)2019-12-03
中国交通信息化(2018年5期)2018-08-21
腐蚀与防护(2018年7期)2018-08-06
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
