
基于超图嵌入和有限注意力的社会化推荐
2024-02-28 08:18傅晨波陈殊杭胡剑波潘星宇俞山青
小型微型计算机系统 2024年1期
傅晨波,陈殊杭,胡剑波,潘星宇,俞山青,闵 勇
1(浙江工业大学 网络空间安全研究院,杭州 310023)
2(浙江工业大学 信息工程学院,杭州 310023)
3(北京师范大学 计算传播学研究中心,广东 珠海 519087)
4(北京师范大学 新闻传播学院,北京 100875)
0 引 言
近年来,随着互联网在人们生活中的日益普及,推荐系统已成为人们在信息消费过程中不可缺少的工具.然而,传统的推荐系统存在着很多不足,如冷启动[1]、数据稀疏[2]等问题导致的推荐性能下降.特别是近年来随着用户对个人隐私越来越重视,获取相对完整有效的信息变得越来越困难,也使得数据稀疏成为当前推荐系统面临的主要问题.
为了缓解因数据稀疏导致的推荐精度降低[3],研究者们在原有的数据基础上引入目标用户的社交信息[4],例如,SoRec社会化推荐[5].除了用户的社交信息外,用户历史行为信息也是一种有效的扩充手段[6],这主要是因为人类的行为轨迹(线上或线下)往往具有潜在的规律性,使得人们的行为轨迹呈现高预测性[7,8].例如,基于位置的社交网络的兴趣点推荐模型引入了用户的历史行为信息[9].但是,如何高效地引入补充信息仍然是亟待解决的挑战.
此前的社会化推荐算法往往是基于启发式或者建模用户的社会化过程.但是由于启发式算法的稳定性和鲁棒性较差[10],而基于建模的算法则需要大量的专家知识[11],使得这些社会化推荐算法实现过程繁琐且迁移性较差.因此,研究者们提出使用图嵌入算法来学习数据的结构化特征[12],从而更高效地引入补充信息来提升推荐的性能.传统的图嵌入只专注于学习单一数据域下的特征,忽略了不同数据域的特征,从而导致图嵌入在多数据域的特征表征任务中效果较差.因此,在处理多数据域的特征任务时往往采用超图嵌入[13].但是现有的大部分超图嵌入算法在学习不同层级、不同细粒度的特征时还存在一定的难度[14].
此外,图嵌入算法虽然可以有效地学习数据的拓扑特征,但是却避免不了原始数据的噪声引入问题.例如,对于用户的社交信息而言,由于人的注意力有限[15,16],在社交关系中用户受到的影响主要来自于其关注度较高的好友[17],因此引入不经常联系的朋友信息就会对算法产生一定的负面的影响.但是高效精准地定量计算用户与好友间的关注度并不容易.其中一种朴素的方法是从用户的好友中筛选相似度较高的好友,如通过皮尔逊相关系数、余弦相似性[18]等方法来度量好友相似度.但当用户的评价记录的缺失值较多时,这些度量方法就会失效[19].
针对上述的挑战,本文在引入社交信息的基础上进一步引入了用户的历史行为信息,并关注于用户的有效好友,提出了SRBHL(Social Recommendation Based on Hypergraph embedding and Limited attention)模型以进一步地缓解目标用户数据的稀疏问题:
一方面,为了克服原有超图嵌入无法有效地学习不同层级、不同细粒度的特征,本文引入了Yang等人[20]提出的LBSN2Vec超图嵌入模型,该模型构建了一张包含用户社交信息和历史行为信息的超图,并基于滑动窗的随机游走等算法来提取该超图中的多元信息,从而得到了更细粒度的用户特征向量.
另一方面,为了避免引入原始数据的噪声对下游算法产生影响,本文将超图嵌入所得的特征向量通过简化后OLA-Rec[19]的用户关注度算法来筛选目标用户的有效好友.并将有效好友的信息结合下游算法为用户进行推荐.本文提出的方法具有相对良好的独立性,可以在此基础上选择不同的下游算法来作用于不同的社会化推荐任务.
本文的主要贡献如下:
1)本文结合超图嵌入和有限注意力提出了SRBHL模型,该模型通过学习用户不同层级和细粒度的信息(社交信息和历史行为信息)来补充目标用户数据.此外,该模型通过排除目标用户无效好友的影响,提升了下游推荐算法的精度.
2)本文在3个真实数据集上与基线推荐算法进行了性能评估实验,实验结果表明结合SRBHL模型后的推荐算法相比于基线算法具有更加优越的推荐准确度.
3)此外,本文还展开了鲁棒性实验,并给出了模型最优性能表现下的各个超参数的取值范围.
1 相关工作
1.1 社会化推荐
近几十年以来,互联网和社交软件的兴起极大地改变了人们的社会交流方式,使得人们的行为模式出现了新的变化,如个人的行为模式相比于过去更容易受到其社交好友的影响[21],Weng等人[22]发现有社交联系的用户更可能具有相似的兴趣,Tang等人的研究[23]表明有信任关系的用户在对物品的评级上可能更类似.这些现象在社会学中也可以找到类似的理论,如社会影响[24]和同质性[25].基于这些理论,社会化推荐使用用户的社交关系作为新的推荐来源来提升推荐系统的性能,例如Jamali和Ester[26]基于“用户潜在的特征向量依赖于用户的社交关系”的假设提出了一种矩阵分解模型SoMF;Fan等人[27]使用图神经网络整合用户的社会关系信息到推荐系统中.
然而,有研究者指出此类的社会化推荐系统只是简单的利用了用户间直接的好友关系,并认为社会关系存在异质性,即用户的社会关系不只是由简单单一的好友关系,而是各类社会关系的组合[28];用户的社会关系也应包括间接的弱相互联系(如一个社交团体中,无好友关系的用户间的联系),用户也会受到弱相互联系的影响.基于此类理论,研究者们提出了新的社会化推荐系统:如Wang等人[29]通过对用户项目进行更细粒度的分类,将社会科学中的强弱联系整合到社会化推荐中;Lang等人[30]在TrustSVD算法中加入了用户隐式的信任信息,以此为用户进行推荐.
1.2 行为轨迹可预测性
在现实生活中,人类的行为轨迹往往具有潜在的规律性.例如,Song等人[8]指出,人类的行为轨迹平均可具有高达93%的可预测性.近年来越来越多的研究者开始研究人类行为的模式及模型,如De Montjoye等人[31]发现不同用户的行为轨迹具有高度的独特性,Song等人[32]发现人们同时具有探索未知地点和返回熟悉地点的倾向;Simini等人[33]使用一个“无参数”的辐射模型来预测区域间的人口流动性,Han等人[34]使用层次化的交通模型来预测人们的出行轨迹.人类行为的高规律性和社交关系的结合也为推荐系统带来了新的思路,如利用目标用户朋友的历史行为信息补充原目标用户缺失数据,以缓解推荐算法的数据稀疏问题[6,9].
1.3 超图嵌入
图的表达可以更好地反映现实数据中的结构化特征,如社团结构等[35].因此如何在结构数据中学习到有效的图表征成为目前的研究热点.其中图嵌入作为可以自动学习图表征的重要方法之一,能有效地学习到图的结构信息并以向量化表示,为下游算法提供支撑.现有的图嵌入方法大部分是基于图中的节点共现关系来实现的,根据嵌入学习过程可以大致分为两类:基于因子分解的方法[36-38]和基于图采样的方法[39-41].
基于因子分解的方法一般利用相似性度量函数(如皮尔逊相关系数、余弦相似性[18]等)来度量图中节点间的相似度,将其存储为相似矩阵,最后使用矩阵分解技术(如SVD[18]等)对该相似矩阵进行分解.例如,Cao等人[36]提出的GraRep使用低维向量表示出现在图中的节点向量,将图的全局结构信息集成到学习过程中;Ou等人[37]提出的HOPE模型在有向图中将嵌入分为两部分,即源嵌入和目标嵌入,进而可以保留大规模有向图的高阶近似性,并能够捕获非对称传递性.
基于图采样的方法主要是通过随机游走从图中提取相似的样本节点,然后优化一个可以重构节点间的相似性的映射函数,使得学习到的节点表示能有效地重构图中的节点相似性.例如,Grover和Leskovec提出的node2vec[39]通过将节点映射到低维特征空间,再对二阶随机游走产生的节点社区进行采样来学习节点嵌入;Hussein等人[40]提出的JUST模型在随机游走技术上应用Jump和Stay策略来选择最优路径,从而避免了游走时需要先验知识的问题.
然而,之前的模型往往使用简单的同质图或者二分图来表征原信息,它们只能编码节点间单一的简单关系,这种单一的关系并不能有效编码现实世界中更为错综复杂的关系.基于此,超图嵌入被提出用于处理节点间的拓扑关系[13].其中,超节点表示各类实体、超边表示各类实体间的多元关系,使得超图可以更准确地刻画异构图中复杂实体关系.例如,超图可以同时编码用户节点与物品节点间的购买关系以及用户节点和商店节点间的签到关系[14].但是,大部分超图嵌入模型只能从存在超边的特定节点上提取信息[42-44],无法从节点或超边的自身特征中提取信息[14].因此,Yang等人提出了LBSN2Vec超图嵌入模型[20],该模型可以更为全面地提取节点以及相应超边中的有效信息,并作用于相关的推荐.
1.4 有限注意力
作为社会学领域的学术名称[45],有限注意力最早在2013年被Kang等人引入用于解决社会化推荐的问题[46].他们指出,在真实世界中,人们的注意力都是有限的,且用户对其好友或者物品的注意力是不同的.于是Kang等人提出了LA-LDA模型[47],利用注意力分数给不同的物品赋予不同的权重以提升算法的性能.但是这些研究却忽略了数据中内生的干扰信息,如关注度较低的好友数据.这些干扰信息的引入不仅会劣化模型的性能,还会增加模型运算所需要的时间.如何找到有效好友成为提升算法性能的一个方向.为此,Wang等人[19]提出了OLA-Rec模型,通过考虑有效好友来排除干扰信息.遗憾的是,OLA-Rec模型在计算用户的好友关注度时只考虑了用户的单层社交信息,而忽略了用户其他信息的相关性,如历史行为等.因此,本文结合超图嵌入和有限注意力提出了OLA-RBHG模型,通过学习用户的多元特征以缓解数据稀疏问题,并过滤了原始数据中的噪声,从而更有效地提取了用户的信息.
2 SRBHL模型
本节提出了SRBHL模型,该模型主要由超图嵌入模块和有限注意力模块组成.其中,超图嵌入模块可以有效地学习到超图的向量表征;有限注意力模块使用该向量表征进行关注度的计算,最终得到有效好友和相应的关注度.最后,本文给出了SRBHL模型的整体架构图,并分析论证了SRBHL模型与OLA-Rec模型的区别与联系.
2.1 超图嵌入
2.1.1 超图生成
为了同时表征用户的行为特征和社交特征,此处的超图生成部分区别于传统的超图生成方法,即分别使用同质图、超图来构建用户的社交网络和行为事件.具体步骤如下:首先将用户作为节点、用户的好友关系作为连边来构建用户的社交网络;其次,将用户的行为事件作为超边添加在相应的用户节点上,相应事件的属性作为超边内的节点,从而允许不同超边间的重叠现象,即不同行为事件间可以具有相同属性,进而可以编码不同行为事件间的高阶关系.
图1展示了5个用户间的社交关系以及他们相应的历史行为信息.例如,1号用户有两个社交好友;该用户曾有过购物、餐饮等历史行为信息,其中包含了用户具体行为发生的时间、地点等属性.此外,需要注意的是,不同数据集中的用户历史行为信息存在较大差异,如果数据集中用户的历史行为信息过少,那么生成的超图将会退化为普通的同质图.

图1 用户的社交网络和行为事件Fig.1 Social network and behavioral events of users
为了构建出超图,首先,本文基于用户的好友关系构建出社交网络;其次,根据用户的历史行为信息,本文在相应用户节点上添加其对应的行为超边.其中,行为超边中包含了行为的时间、地点和事件等超节点.最终,本文可以得到如图2所示的构建后的超图(局部),它能够较好地反映了用户的社交特征和自身的行为特征.

图2 超图生成示意图Fig.2 Schematic diagram of hypergraph generation
2.1.2 基于滑动窗的随机游走
为了有效地从生成的超图中同时提取用户的社交信息和相应的历史行为信息,LBSN2Vec使用了一种基于滑动窗的随机游走算法[20]来提取信息.具体的做法为,算法在社交网络上随机游走,同时对每个游走到的用户节点采样相应的超边和当前用户为中心的滑动窗口下的好友边.此外,使用可调参数控制游走的好友边和超边的比例,从而得到最终的样本训练集.后续的超图嵌入可以基于提取到样本训练集来得到用户的特征向量.公式(1)~公式(3)分别表示游走到的所有边的数量、好友边的数量和用户行为边的数量.
Es=2W
(1)
Efr=2Wα
(2)
Ebe=2W(1-α)
(3)
其中,W为滑动窗口的单侧长度,α为可调超参数.
相较于一般的随机游走算法,基于滑动窗的随机游走采样算法可以有效地同时提取好友边和超边的特征,并在采样这两种边时可以最大程度地保留各自的独立性.此外,该算法还可以尽可能采集到更多用户的节点特征,提高特征的提取效率和完整性.具体的游走过程如图3所示.假设窗口的单侧宽度W大小为2,游走一个用户节点时需要分别采样当前窗口下的好友边和当前用户相应事件所对应的超边,并使用α来控制好友边和超边的比例.采样完成后再继续游走到下一个用户节点,重复上述步骤,直至所有用户节点游走完成.
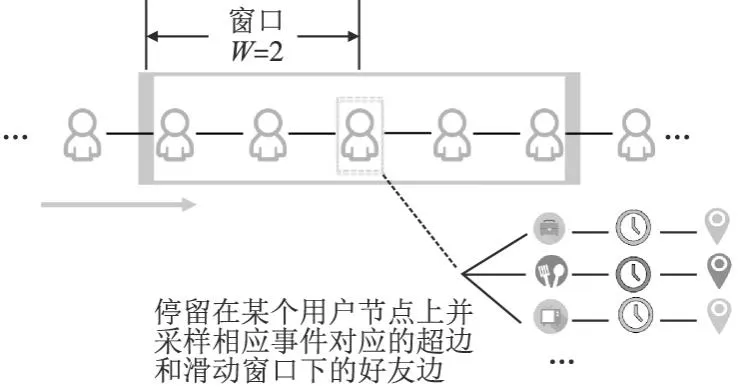
图3 基于滑动窗的随机游走示意图Fig.3 Schematic diagram of random walk based on sliding window
2.1.3 特征向量生成
为了得到用户信息的向量表达,本文从2.1.2小节中得到的游走路径中提取信息,再最小化目标用户的特征向量与最佳拟合向量之间的余弦距离来得到所需要优化的目标函数.其中公式(4)为优化目标函数,公式(5)为最佳拟合向量.
(4)
(5)

LBSN2Vec采用负采样技术[48,49]来更进一步地提升拟合效果和加快学习进程,其中负样本节点的定义为未和当前节点共现在同一游走路径中的节点.更新后的优化目标函数如下:
(6)
σ表示负样本数,EVN[1-cos(vN,vb)]表示[1-cos(vN,vb)],vN表示负样本节点向量.对公式(6)的目标函数使用随机梯度下降算法,在多次迭代后,本文可以得到LBSN2Vec图嵌入之后的节点向量表示V.
(7)
(8)
公式(7)和公式(8)为随机梯度下降算法中对应的向量梯度.
2.2 有限注意力
虽然超图嵌入模块可以有效地提取到数据的拓扑特征,但是却避免不了原始数据的噪声(如不常联系的朋友等)引入问题.因此,本文使用基于有限注意力的用户关注度算法得到用户间的关注度.
具体的计算步骤为:
(9)
(10)
(11)
其中βiu、λk为中间变量,τ是一个非负的超参数,用于计算中间变量βiu,Vi、Va为用户i和u的特征向量,k为用户的好友总数,γiu为用户i对好友u的关注度.
首先根据超图嵌入所得的特征向量来计算用户与其好友之间的欧式距离,再根据公式(9)计算中间参数βiu.在实验中,将λ和γ初始化为1/|F(i)|,|F(i)|为用户的好友总数,再依据公式(10)和公式(11)迭代来更新λ和γ,迭代的循环条件为λk>βi,k+1和k≤|F(i)|.当循环结束后,可得到用户之间的相关系数矩阵γ.本文进一步筛选出关注度γiu大于等于0的有效好友,并将有效好友的信息结合下游算法对用户进行推荐.
算法1.SRBHL 算法
输入:用户集合Users、超参τ、用户的朋友矩阵F,其中Fiu表示用户i的朋友u、生成的超图G.
输出:用户的最优好友数k、用户的好友关注度γi.
1.V←LBSN2Vec(G)
2.k←0
3. for eachiinUsersdo:
4. for eachuinF(i) do:
6. endfor
7. asecnding(βi)/*表示对βi中元素进行升序排序*/
8. endfor
9.λi←βi,1+1
10. whileλk>βi,k+1andk≤|F(i)|
11.k←k+1
13. end
14. for eachiinUsersdo:
15. for eachuinF(i) do:
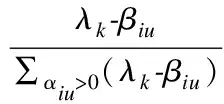
17. endfor
18. endfor
总而言之,本文提出了一种自动缓解数据稀疏和去除噪声的SRBHL模型,通过输入用户的社交数据和行为数据,即可输出用户的有效好友以及相应的注意力分数.区别于OLA-Rec模型通过手工提取特征的方式,SRBHL模型使用超图嵌入来自动地提取用户特征向量,不仅引入了用户多个数据域下的特征(社交特征、历史行为特征),还缓解了手工提取特征可能引入的误差.
SRBHL模型的本质是一种缓解数据稀疏和去除噪声的特征工程,因而其应用场景广泛,可与其他需要社交信息的推荐模型相结合,继而作用于下游诸多不同的推荐场景,如评分预测、兴趣点推荐等.模型的具体流程如图4所示:首先使用LBSN2Vec对超图嵌入后提取到每个用户的特征向量,随后利用有限注意力模块计算用户对其相关好友的有限注意力,并将注意力分数大于零的有效好友以及相应的注意力分数传入下游的推荐模块.其中,有限注意力模块后用户颜色深浅代表着注意力分数的高低,颜色越深,注意力分数越高.

图4 SRBHL模型整体架构图Fig.4 Overall architecture diagram of SRBHL model
3 实验及结果分析
在本节中,本文将提出的算法(SRBHL)与当前流行的5种基线推荐算法在3个真实数据集上进行比较,证明了SRBHL模型的优越性.此外,由于SRBHL与OLA-Rec模型中并未包含具体的推荐模块.因此,在本节中,本文将SRBHL、OLA-Rec模型分别与GraphRec[27]推荐算法结合后,再与其他5种基线算法进行比较.
3.1 实验设置
3.1.1 评估方法
本节使用了均方根误差(RMSE)和平均绝对误差(MAE)两类误差来评估最终的模型效果.
(12)
(13)

为了更全面地评估模型的性能,本文还引入了召回率和F1分数作为评估的指标.
(14)
(15)
(16)
其中,S(K)表示测试集中推荐给用户的前K个物品,S(u)表示测试集中的用户已经评分过的物品数.
3.1.2 数据集介绍
实验共选取了3个真实数据集,具体描述如下:
Yelp-2018数据集:该数据集(https://www.yelp.com/dataset)收集了美国最大的点评网站Yelp的信息,一共包含了163万位用户的个人信息,19万条餐馆信息,668万条用户评论以及相关的评价指标(如useful、funny等).本文对整个Yelp数据集按城市进行分类,最后选出了用户数量差别较大的Urbana和Phoenix两个城市作为实验的数据集,即Yelp-Urbana和Yelp-Phoenix.
Epinions数据集:该数据集是从Epinions官网完整爬取下来的有关商品评论的轻量数据集(https://www.epinions.com.html),一共包含了18088名用户、261649个商品和764352条评论及评分数据.
数据集中极端用户的存在可能会对最终的实验结果产生负面影响.因此,为了消除极端用户对算法的干扰,本节删除了好友数量过少和过多的极端用户.具体操作为:反复删除当前网络中度值低于3(朋友数量极端少)和高于2000(朋友数量极端多)的用户节点并更新删除后的社交网络.在实验中,本文将数据集80%~20%分离:即将数据集中的80%作为训练集,剩余的20%作为测试集.本文也采用了10折交叉验证的方法作为评估方式:即重复实验10次,取10次结果的平均值作为最终的结果.
最后,本文将预处理后数据集的基本统计特征整理成表,如表1所示.

表1 数据集基本信息统计表Table 1 Basic information statistics table of the datasets
3.1.3 比较模型说明
本文比较了SRBHL模型和5种基线推荐方法,介绍如下:
SRBHL+GraphRec:本文提出的模型;
SoCune[50]:从用户反馈中提取隐含、可靠的社交信息,并为每个用户识别Top-k个语义好友,再将语义好友的信息融入MF和BPR框架;
GraphRec[27]:分别嵌入用户网络和物品网络后得到用户特征向量和物品特征向量后拼接成最终的特征向量,再使用MLP来完成评分预测任务;
SoMF[51]:采用矩阵分解技术,将信任传播机制纳入基于模型的社会化推荐方法;
DeepSoR[52]:提出了一个基于深度神经网络的模型,从社会关系中学习每个用户的非线性特征,并整合到概率矩阵分解中;
OLA-Rec[19]+ GraphRec:基于有效好友算法来得到用户的最优好友及最优关注度来进行社会化推荐.
在具体的实验中,为了更好地体现基于有效好友的模型与其他基线模型的区别,本文为SRBHL和OLA-Rec方法分别引入GraphRec作为下游推荐算法.在具体的算法实现中,只需要将SRBHL或OLA-Rec处理后的数据传入GraphRec算法即可,其余的基线方法与其原论文的实现方式相同.所有的基线方法选取参数的方法与原论文一致.
3.2 实验结果
本节比较了包括SRBHL模型在内的6种模型在3个真实数据集上性能差异,同时还对SRBHL模型的3个参数(窗口单侧宽度W,比例参数α和超参τ)进行了鲁棒性实验.
3.2.1 RMSE&MAE
SRBHL模型与其他5种模型在3个真实数据集上的RMSE和MAE性能比较结果如图5所示.可以观察到,对于RMSE和MAE,显式地引入社交网络信息的GraphRec、SoMF等模型在这3个数据集上的性能优于未显式引入社交网络信息的SoCune模型.这也说明了显式引入用户社交网络的信息有助于提升模型的性能.此外,一方面需要注意到,在Epinions数据集中,由于该数据集相对较为稀疏,SoCune等未消除数据噪声的模型效果相对较差,而消除数据噪声的OLA-Rec和SRBHL模型的性能较于其他数据集有了较大的提升;另一方面,在对比了两个基于有效好友的模型(OLA-Rec和SRBHL)后,本文发现加入了超图嵌入的SRBHL模型在性能上优于OLA-Rec模型,这一结果充分体现了LBSN2Vec超图嵌入较于手工设计的特征更可以有效构建原始网络的整体模型.进一步地,在其余两个数据集中,由于用户历史行为信息充足(如评分的时间、此次评分行为的funny数、cool数、useful数等),因而在引入了这些信息后,可以发现SRBHL模型的性能优于OLA-Rec模型的性能.这一结果表明了引入额外的用户历史行为信息有助于提升推荐算法的性能,从而提升后续计算用户的有效好友的准确度,进而提升了模型的性能.
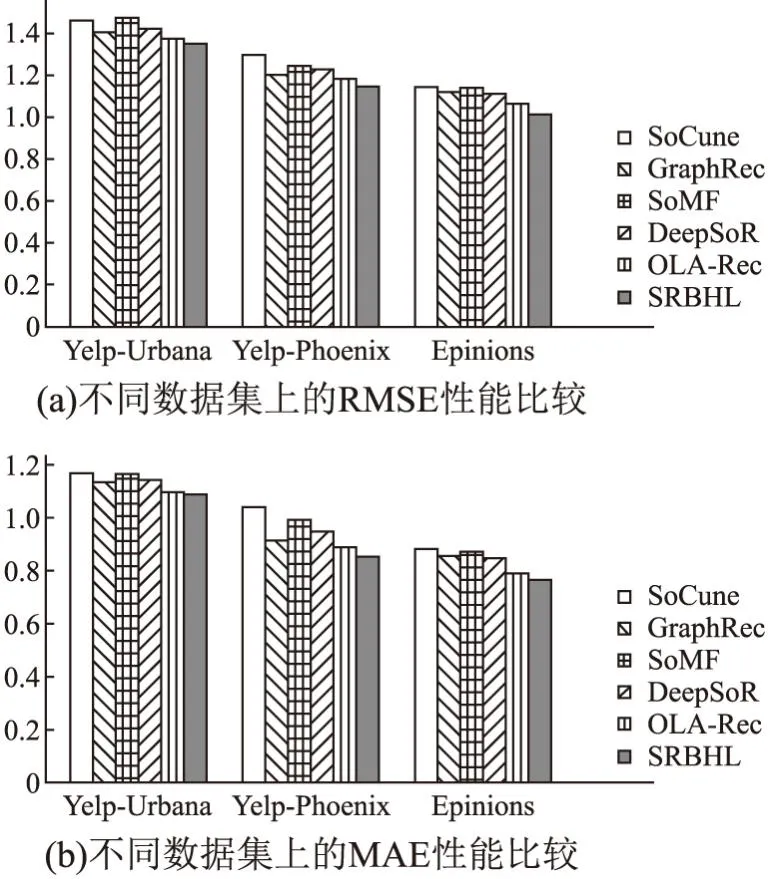
图5 不同数据集上的RMSE&MAE性能比较Fig.5 RMSE&MAE performance comparison on different datasets
3.2.2 Recall@5 &F1@5
SRBHL模型与其他5种模型在3个真实数据集上的召回率Recall@5和F1@5结果如图6所示.一方面,对比两个基于有效好友的模型(OLA-Rec和SRBHL)与其他模型,3个数据集上的实验结果都说明了引入消除数据集中的噪声数据的确能提升推荐算法的性能.另一方面,对于OLA-Rec和SRBHL模型,实验结果表明使用超图嵌入的SRBHL模型在性能上优于OLA-Rec模型,不仅再次说明了超图嵌入技术可以更有效地提取数据集中的有效信息,从而提升推荐的性能;还说明了用户行为信息与用户的社交信息同样可以作为推荐系统额外的信息来源.

图6 不同数据集上的Recall@5 &F1@5性能比较Fig.6 Recall@5 &F1@5 performance comparison on different datasets
3.2.3 窗口单侧宽度对模型的影响
为了探究滑动窗的窗口宽度变化对模型的影响,本文在Yelp-Urbana数据集上对不同窗口单侧长度下的模型进行了实验,结果如图7所示.在对比这几组数据后,结果表明窗口单侧宽度的大小对实验模型的推荐性能而言没有太大影响.但图7也说明对于窗口单侧宽度较小的组来说(W=2),其模型的效果劣于窗口单侧宽度大的组,这一结果说明了滑动窗的窗口宽度的增加在一定程度上可以提升模型的效果.换言之,宽度过小的滑动窗无法有效地提取用户的社交信息.然而,在实验中,随着窗口单侧宽度的增加,程序所运行的时间也依次增加.在综合考虑了程序运行时间和推荐性能后,本文认为6至8之间的窗口单侧宽度较为合适.
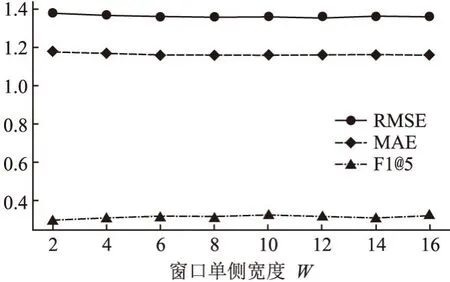
图7 推荐性能随窗口单侧宽度W的变化情况Fig.7 Recommended performance varies with the width W of one side of the window
3.2.4 比例参数对模型的影响
在本文模型中,比例参数α也是一个影响模型性能的重要参数.较大的α表示模型更关注于用户的社交特征,而较小的α表示模型更关注于用户的历史行为特征.当在极端的情况下,如α为0或者1时,模型则完全关注于历史行为特征或者社交特征.为了探究推荐性能随参数α的变化情况,本节在Yelp-Urbana数据集上进行了比例参数α的调整实验,最终结果如图8所示.

图8 推荐性能随参数α的变化情况Fig.8 Recommended performance varies with parameter α
图8表明当α在0.4附近时,模型性能达到最优.此外,还可以注意到,极端情况下(即当α为0或者1时)的模型性能表现不如同时引入历史行为信息和社交关系的模型.这也暗示了用户的历史行为信息和社交关系对于提升模型的推荐精度缺一不可.
3.2.5 参数τ对模型的影响
在有限注意力模块中,超参数τ的选取也会影响模型的性能,不同取值的τ会较大地影响好友关注度的计算结果.因此,为了模型后续合理的使用,本节需要给出τ的最优取值范围.因此,本节分别选取了数量级从10-2至104的7组不同大小的τ进行实验,实验结果如图9所示.

图9 推荐性能随参数τ的变化情况Fig.9 Recommended performance changes with parameter τ
图9很好的说明了参数的调整对模型性能的影响情况:当τ从10-2开始增加,模型的精度逐渐上升,并且τ为102附近时,模型达到了最优的性能,然而,当τ再增加时,模型的精度却开始逐渐下降.因此,本文认为参数τ在80-120附近取值较为合适.
4 总结与展望
本文提出了SRBHL模型,通过提取用户的社交信息和历史行为信息,结合超图嵌入及有限注意力得到有效好友的信息对用户进行推荐.该模型能够引入更多数据域下信息,并排除了噪声信息.在社会化推荐的算法应用中,本文考虑到用户社交注意力有限的情况下,为不同好友计算相应的关注度可以更精准地为用户进行推荐.此外,本文在3个不同大小的真实数据集上,比较了包括本文提出的SRBHL在内的6种模型的性能.实验结果表明SRBHL模型的效果优于所比较的基线模型.但是,本文的模型也存在不足之处:SRBHL模型对数据集的多元信息要求较高,当所有用户的多元信息都缺乏时,SRBHL模型较之基线模型,性能并没有显著地提升.因此如何提升SRBHL模型在信息不完整的数据集上性能将是本文后续将研究的重点之一.此外,由于超边的选择较为自由,是否用户所有的历史行为信息对于后续的超图嵌入都有帮助还依旧有待商榷,是否也存在类似的注意力,可以有助于筛选出用户有效的历史行为信息.因此,本文将基于这些思考,开展后续的研究.
猜你喜欢
英语世界(2023年6期)2023-06-30
意林彩版(2022年2期)2022-05-03
小雪花·成长指南(2022年1期)2022-04-09
第一财经(2020年4期)2020-04-14
小雪花·初中高分作文(2019年10期)2019-02-12
文苑(2018年17期)2018-11-09
杂文月刊(2017年20期)2017-11-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
小雪花·成长指南(2009年10期)2009-12-04
