
基于ZYNQ平台的图像分类加速器设计与实现
2024-02-28 08:18周扬维尹震宇张飞青徐光远徐福龙
小型微型计算机系统 2024年1期
周扬维,尹震宇,王 军,张飞青,徐光远,徐福龙
1(沈阳化工大学 计算机科学与技术学院,沈阳 110142)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
3(辽宁省国产基础软硬件工控平台技术研究重点实验室,沈阳 110168)
0 引 言
随着中国制造2025战略的逐步推进,智能制造业不断发展,工厂中的生产制造过程也正变得越来越智能化和自动化[1].在智能制造的过程中,工件种类多且工件外观相似度较高,依靠传统分拣方式存在速度慢、准确率低的问题.因此,设计一种快速、准确的工件分类方法并将其应用于智能产线上具有重要意义.
目前,基于机器视觉的图像分类技术已经逐步成为受工业界重点关注的技术之一.卷积神经网络作为其重要算法,被广泛应用于智能制造、自动驾驶和图像识别等领域[2-5].近年来,随着研究的不断深入,为了提高分类的精度,网络模型的层数也在不断增加,但是更深的网络深度使得网络的参数量越来越大,对硬件资源的需求也越来越高,难以部署到资源受限的嵌入式平台[6].本文针对智能产线上传统分拣方法速度慢、准确率低、不能满足智能化生产要求的问题,采用机器视觉技术解决工件的快速分类问题,将摄像头采集的工件图像输入到部署在ZYNQ嵌入式平台上的卷积神经网络中,以实现快速分类的功能.
本文的主要工作内容总结如下:1)提出一种参数量较少的图像分类模型SortNet网络,在保证图像分类准确率的同时减少了模型的参数量,降低了神经网络硬件化过程中对嵌入式平台硬件资源的要求,减小了在嵌入式平台部署图像分类模型的难度;2)设计了一种集图像采集、图像分类和分类结果显示一体化的图像分类加速器,将图像采集模块、显示控制模块以及SortNet网络中计算并行度高的部分以寄存器传输级(Register Transfer Level,RTL)语言的方式部署到ZYNQ平台的FPGA上,提高了图像分类的速度;3)提出一种卷积与激活函数同构化的处理单元(Convolution and Activation Function Isomorphism Processing Element,CAFI-PE)和基于流水线的数据调用方法(Pipeline-based Data Calling Method,PDCM)),增加了网络的并行度,减少了卷积运算所占用的时间;4)针对实际生产过程中的工件分类任务,制作了工件图像数据集,并将设计的图像分类加速器在工件图像数据集上进行了实验.经实验验证,本文提出的图像分类加速器能在保证较高分类准确率的同时提高分类的速度,且功耗较低.
1 相关工作
近年来,图像分类技术在机器视觉领域发展迅速,在人工神经网络的背景下,基于卷积神经网络的图像分类技术逐渐成为各领域关注的热点.张哲益等人提出一种基于脉冲卷积神经网络稀疏表征的场景分类方法[7],该方法能够对遥感图像进行稀疏表征,并实现场景分类,但该方法目前仅能应用于静态遥感图像的分类;蒋健等人提出了一种多卷积神经网络融合算法[8],用以解决卷积神经网络分类准确率不高的问题,并将其用于医学图像分类,但该研究使用的是标准数据集,而且数据集的数据量较少,与实际的医学图像存在一定的差异,因此这项算法在应用中仍需进一步完善;Singh等人针对恶劣天气下水果图像分类效果差的问题,提出了一种基于Ⅱ型模糊的水果图像改进方法[9]来提高天气退化水果图像的可视性,但此方法未能部署到嵌入式平台,且便携性不高.
在嵌入式平台部署卷积神经网络方面,吴健等人提出了一种基于FPGA的加速方法[10],来解决卷积神经网络在嵌入式平台部署需要消耗大量计算资源以及计算复杂度高等问题,该方法利用参数重排、乒乓缓存、相邻层数据合并以及多通道传输等策略来减少数据传输所产生的时延;陈禹等人设计了一种基于卷积神经网络的图像分类识别方案[11],用以实现低功耗的图像分类识别,该方案具有较好的通用性好且功耗较低,适合应用于边缘计算环境中;龚豪杰等人提出了一种卷积并行加速架构[12],用以提升嵌入式平台上卷积神经网络的速度和能效,该研究利用卷积层和批量归一化(Batch Normalization,BN)层融合算法降低了计算的复杂度,并通过层融合的分片设计,减少了片上存储的资源消耗;潘坤榕等人为解决当前主流深度学习算法卷积神经网络中计算量最大的卷积层的计算问题,提出了在Xilinx高层次综合开发(High Level Synthesis,HLS)集成开发环境下的设计思路和优化方法[13],利用HLS开发门槛低、开发周期短的优势设计了参数固定且具备通用性的卷积计算模块;Park等人将经典网络LeNet-5实现在嵌入式SoC平台上[14],并使用了一种循环平铺的技术来优化设计,达到了比桌面或嵌入式平台上的其他传统实现方案更高的单位能耗吞吐量.但上述研究都是基于HLS实现的,虽缩短了开发周期,但此类实现方式对硬件资源和时序的控制能力较低,灵活性较差,且容易生成一定的冗余逻辑.
本文在前人研究的基础上,设计了一种基于ZYNQ平台的图像分类加速器.首先,提出一种参数量较少、准确率较高的图像分类模型SortNet,减小了在ZYNQ嵌入式平台部署卷积神经网络的难度;针对卷积神经网络在嵌入式平台运行速度慢的问题,将图像采集、分类结果显示以及图像分类模型中并行度较高的部分部署到ZYNQ平台的FPGA上,并将其应用于智能产线中的工件分类场景中,最终实现了快速、准确和低功耗的工件分类.
2 系统设计与实现
2.1 轻量化图像分类模型SortNet网络设计
本文通过研究经典网络模型AlexNet的网络结构[15],结合一系列改进方法提出了一种参数量更少、准确率更高的图像分类模型SortNet,其网络结构如图1所示.

图1 SortNet网络结构Fig.1 SortNet network structure
其中,SortNet网络前4层均采用卷积+激活函数+池化的结构,卷积层使用5×5和3×3两种尺寸更小的卷积核代替大卷积核,可以在保证感受野不变的前提下减少卷积层的计算量;采用修正线性单元(Rectified Linear Unit,ReLU)作为激活函数,以增加网络的非线性和稀疏性,同时可以更好地避免出现梯度消失的现象;池化方式选用最大池化,以最大程度地保留图像特征;在SortNet的第5层引入全局平均池化,用以对整个网络的结构做正则化并防止过拟合现象的出现,且能达到直接降维、减少网络参数的效果;最后一层使用全连接层,以完成自适应特征学习及分类过程.本文根据实际分类需要将输出类别数设为10.
2.2 图像分类加速器设计
2.2.1 总体框架设计
本文所提出的基于ZYNQ平台的图像分类加速器整体硬件架构如图2所示.其中,可编程逻辑(Programmable Logic,PL)端,即ZYNQ平台的FPGA部分,主要负责图像的采集控制和预处理、分类结果的显示控制,以及SortNet网络中的并行计算;处理器系统(Processor System,PS)端,即ZYNQ平台的ARM部分,主要负责对整个图像分类加速器进行控制和调度.PL端包含图像采集模块、SortNet网络、显示控制模块以及相关的数据通路;PS端包含摄像头寄存器配置模块、SD卡启动配置模块、串口输出控制模块、VDMA配置模块以及存储读写控制等模块.
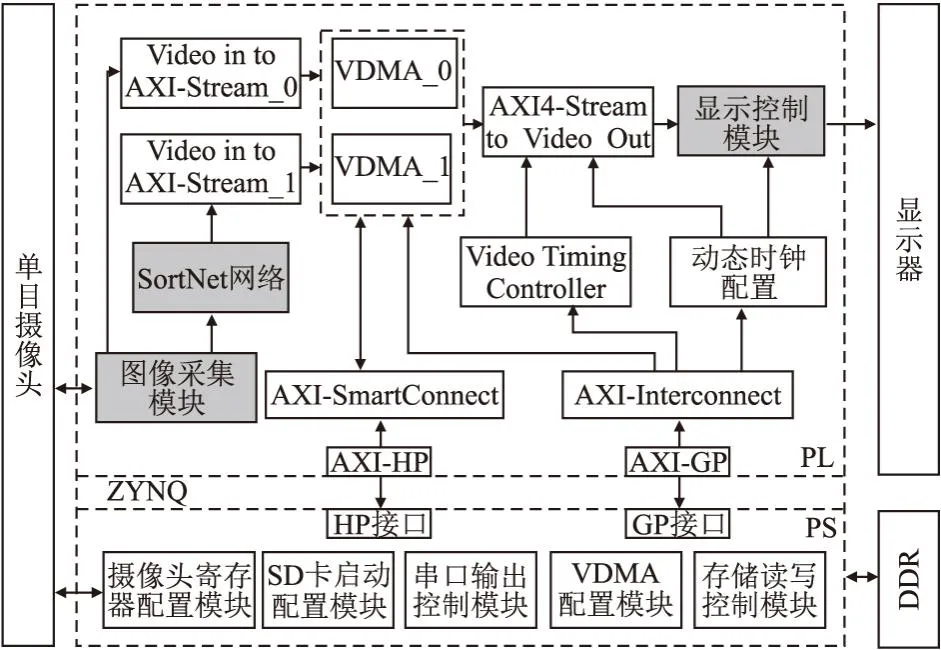
图2 加速器整体硬件架构Fig.2 Overall hardware architecture of accelerator
本文设计的图像采集模块负责接收单目摄像头采集到的16位彩色图像数据并对其进行灰度化预处理;SortNet网络对预处理后所得到的灰度图像进行数据缓存和图像分类,并将处理得到的分类结果输出至AXI数据通路;显示控制模块则将由AXI数据通路传输而来的分类结果以字符和文字标签的形式显示在显示器上;摄像头寄存器配置模块对单目摄像头的寄存器进行配置并配合图像采集模块实现对摄像头图像采集的控制;SD卡启动配置模块对SD 控制器进行配置,其读写通道采用独立的双缓冲FIFO执行读和写操作,可使图像分类加速器脱离集成开发环境(Integrated Development Environment,IDE)环境独立运行,提高了图像分类加速器的便携性;串口输出控制模块用于接收SortNet的分类结果并打印信息;VDMA配置模块用于实现AXI4-Stream接口与AXI4接口之间的高带宽接入,且能够实现双缓冲以及多缓冲机制;存储读写控制模块用于对DDR存储器地址分块,以提高访存效率.同时,本文使用了AXI4-Lite接口来传输分类结果,使用了两个基于AXI总线的VDMA IP核来进行数据流的传输,分别将其配置为16位数据通路和32位数通路.其中16位数据通路用于向PS端传输数据,32位数据通路用于向PL端的SortNet网络传输数据.部署在ZYNQ平台上的SortNet网络硬件架构如图3所示,主要包含片上缓存模块、参数预存模块、卷积与激活函数同构化处理单元(包含乘法器阵列、加法树以及ReLU函数)、最大池化模块、FIFO、全局平均池化模块以及全连接模块.

图3 SortNet网络硬件架构Fig.3 SortNet network hardware architecture
SortNet网络的工作过程为,在PL端时钟信号的驱动下,图像采集模块将预处理后的图像数据作为输入特征图缓存到片上缓存模块;卷积与激活函数同构化处理单元接收到卷积计算开始的信号后,内部行列计数器和数据地址计数器开始计数,从片上缓存中读取输入特征图图像数据;同时,参数地址计数器计数,并从参数预存模块中读取预存的权重参数,与读取的图像数据一同送入乘法器阵列中进行乘法运算;然后,将乘法器阵列运算得到的所有乘积与偏置数据相加得到卷积计算的结果;再经过ReLU激活函数进行非线性变换并送至最大池化模块;最大池化模块对经过非线性变换的结果进行比较,并将得到的最大值送入FIFO中作为下一轮卷积运算的输入特征图图像数据;经4次卷积运算后,全局平均池化模块将FIFO中的数据读出并进行平均数值计算,将得到的均值经VDMA的32位数据通路传输至DDR3存储器中;PS端根据映射的内存地址读取平均池化结果并将其传输至全连接层,经过全连接运算得到预测的分类结果并将其送入AXI-Lite总线对应的寄存器中,再传输至图像显示模块的数据接收端.
2.2.2 卷积与激活函数同构化处理单元设计
研究[15]表明,卷积神经网络中的卷积计算所消耗的时间最多,约占整个网络的90%~95%,而全连接层则消耗了大约5~10%的计算时间以及95%的参数规模.由此可见,卷积计算在整个网络中是耗时最多的.而卷积神经网络中卷积计算和激活函数是彼此联系又相互独立的两个部分,若在ZYNQ平台上对其直接进行硬件化设计,两者经综合后所得到的电路结构也是彼此独立的,这种独立的结构会消耗较多的硬件资源,同时还会增加整个网络运算的时间.本文提出了一种卷积与激活函数同构化的处理单元,将激活函数的运算过程与卷积运算过程进行融合,在每次卷积运算后直接进行激活运算.这种卷积与激活函数同构化处理单元在综合后所得到的电路是一个整体,在提高运算速度的同时还能节省部分硬件资源,其算法伪代码如表1所示.

表1 CAFI-PE算法伪代码Table 1 Pseudocode of the CAFI-PE
2.2.3 基于流水线的数据调用方法设计
流水线技术是一种计算机并行处理技术,它利用一系列可以并行工作的处理模块,把一个任务分成多个子任务,使每一个子任务分别在不同的处理模块中完成,从而大幅度提高处理的效率,早期在复杂的超大规模集成电路设计中已有应用.本文对前人在流水线技术研究[16]的基础上,设计了一种基于流水线的数据调用方法,使用流水线技术进行嵌入式平台上卷积神经网络中的数据调用,节省了卷积运算所占用的时间.
下面以224×224大小的输入特征图与5×5的卷积核进行卷积运算为例介绍这种数据调用方法.如图4所示,在时钟信号的驱动下,随着行列计数器的变化,地址信号不断累加,输入特征图的图像数据在时钟信号的下一个时钟周期到达.其中,本文设计了5个位宽为5的寄存器来缓存输入特征图的图像数据,第0号寄存器reg0[4:0]相较于输入特征图的图像数据延迟一个时钟周期进行数据调用,剩余寄存器相较于前一个寄存器延迟一个时钟周期进行数据调用.这样到第6个时钟周期时5个寄存器中可同时调用5×5大小的输入特征图,并且以后每个时钟周期都可调用同样大小的输入特征图图像数据,这样可以实现每个时钟周期进行一次卷积运算所需的数据调用,有利于提高卷积计算的并行度.相较于单寄存器调用图像数据,用以上基于流水线的数据调用方法对图像数据以及参数数据进行调用,可减少数据调用所占用的时间,进一步提高图像分类加速器的处理速度.

图4 基于流水线的数据调用方法Fig.4 Pipeline-based data calling method
3 实验验证
3.1 工件图像数据集
为验证本文所提出的图像分类加速器的性能并针对工件分类任务实现快速的图像分类,本文制作了10分类工件图像数据集.首先,采集了智能产线中多种工件的原始图像数据;然后对原始图像数据进行数据清洗、归一化等预处理操作,并通过旋转、镜像等方式将工件图像增强至12000张,再对工件图像数据进行类别标注;最后,将扩充后的工件图像按照5:1的比例进行划分,即从工件图像中随机选取10000张图像作为训练集,并将剩余2000张图像作为测试集,最后将其保存为工件图像数据集.
3.2 实验平台及主要参数
本文使用自制的10分类工件图像数据集对SortNet网络进行训练及验证,网络训练平台的处理器型号为Intel(R)Xeon(R)Platinum 8255C,主频为 2.50GHz,内存大小32GB,GPU型号为NVIDIA GeForce RTX 2080Ti,开发环境为PyCharm 2020.1.
本文使用的嵌入式实验平台是Xilinx ZYNQ7100开发板,其主要参数如表2所示,该开发板采用的是ARM+FPGA的架构,ARM处理器型号为Dual-Core ARM Cortex-A9,FPGA芯片型号为XC7Z100-2FFG900I,实验中所使用的图像传感器为OV5640单目摄像头.
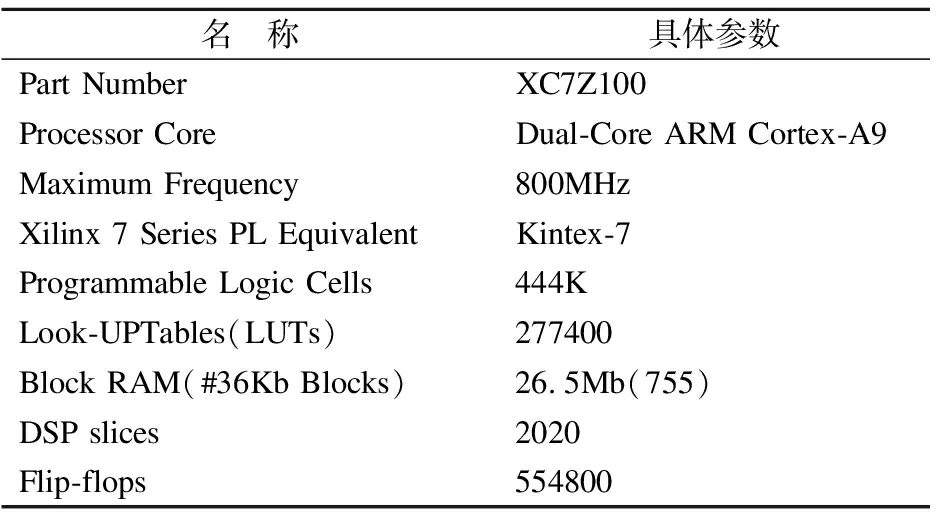
表2 ZYNQ 7100开发板主要参数Table 2 Main parameters of ZYNQ 7100
本文使用MatlabR2022对参数文件进行格式转换,并将转换后的参数文件部署到ZYNQ嵌入式平台;使用Vivado 2019.2软件进行RTL代码设计、综合和布局布线,并生成比特流文件;使用Vitis 2019.2进行图像分类加速器的流程控制以及调试,并使用ModelSim SE-64 2019.2对加速器各模块进行仿真.
3.3 SortNet网络训练及实验结果分析
为了验证本文所提出的图像分类网络对工件的分类能力,在自制的工件图像数据集上对SortNet网络以及经典网络模型AlexNet进行训练.两者在训练集及测试集上的图像损失及训练和测试准确率如图5所示.实验结果表明,随着网络迭代次数的增加,两种网络模型均达到了较好的收敛状态,网络模型的训练损失曲线呈现逐步下降状态.经多次实验统计以及计算,AlexNet网络的图像分类准确率约为95.51%,如图5(a)所示;SortNet网络的图像分类准确率达到了98.17%,如图5(b)所示,相较于AlexNet准确率提高了2.66%.

图5 分类损失及训练、测试准确率Fig.5 Classification loss and training and test accuracy
接下来再对两个网络的参数量进行比较,SortNet和AlexNet网络参数量对比如表3所示.由表中数据计算可知,SortNet网络的参数量约为AlexNet网络的1/39,对硬件资源的需求大大减少,减小了在资源有限的嵌入式平台部署图像分类网络的难度.

表3 SortNet与AlexNet参数量Table 3 Parameters of SortNet and AlexNet
3.4 图像分类加速器性能测试及实验结果分析
本小节对基于ZYNQ平台的图像分类加速器的加速效果、所消耗的硬件资源、功耗进行测试与分析,并与PS端的图像分类方案进行数据对比.
3.4.1 加速效果测试与分析
本文设计的图像分类加速器运行在100MHz时钟条件下,来处理一张224×224大小的灰度图像.使用Vitis2019.2自带的Vitis Serial Terminal串口调试工具来测试基于ZYNQ嵌入式平台的图像分类加速器的实际分类速度,并与PS端的图像分类方案作对比,对比结果如表4所示.

表4 加速方案数据对比Table 4 Comparison of acceleration schemes
由实验结果可知,PS端的图像分类方案处理一帧图像所用的时间为322.9毫秒,即每秒能处理3.09帧图像;本文提出的图像分类加速器处理一帧224×224大小的图像所用的时间为24.4毫秒,即每秒能处理40.98帧图像,加速比约为13.26.
3.4.2 片上资源使用情况测试与分析
根据 Vivado2019.2 提供的综合报告对FPGA片上资源利用情况进行分析,表5为基于ZYNQ平台的图像分类加速器在ZYNQ7100开发板上片上资源的占用情况.

表5 FPGA资源使用情况Table 5 FPGA resource usage
在图像显示控制模块要预存部分标签数据,分别为尺寸大小为224×224的彩色图像标签数据以及尺寸大小为300×70的文字标签数据以供可视化输出,因此对BRAM资源的使用率较高,占用率为50.26%.另外,本文对输入特征图图像数据进行了灰度化预处理,且对权重和偏置参数值进行16位定点量化,因此在ZYNQ嵌入式平台部署SortNet网络及参数时对FPGA片上的计算与存储资源消耗较低,其中,LUT占用资源数为10404,DSP占用资源数为34,LUTRAM占用资源数为340.
3.4.3 系统功耗测试与分析
由Vivado2019.2提供的功耗分析报告可知,部署在ZYNQ嵌入式平台的图像分类加速器总功耗为2.305W.其中,静态功耗为0.268 W,在系统总功耗中占比12%,动态功耗为2.037W,在系统总功耗中占比88%.另外,该图像分类加速器中PS端处理器的动态功耗所占的比例较高,约为系统动态功耗的76%,而PL端的运行功率只有0.268W,功耗相对较低,能够满足工业环境下低功耗的要求.
4 总 结
本文设计了一种基于ZYNQ平台的图像分类加速器,并将其应用于智能产线的工件分类场景中.实验表明,该图像分类加速器在使用较少硬件资源的情况下,能够实现快速、准确的图像分类,且功耗较低.在下一步工作中,考虑将更大的网络硬件化到ZYNQ平台上,以实现更加复杂的图像识别与分类任务.
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
少先队活动(2021年6期)2021-07-22
制造技术与机床(2019年7期)2019-07-22
铁道通信信号(2018年2期)2018-04-18
现代机械(2018年1期)2018-04-17
电镀与环保(2016年3期)2017-01-20
少年博览·小学低年级(2016年5期)2016-05-14
焊接(2015年9期)2015-07-18
单片机与嵌入式系统应用(2014年9期)2014-03-11
