
融合匹配特征的立体图像颜色校正方法
2024-02-28 08:18朱文婧范媛媛陈羽中
小型微型计算机系统 2024年1期
朱文婧,范媛媛,陈羽中,2
1(福州大学 计算机与大数据学院,福州 350105)
2(空间数据挖掘与信息共享省部共建教育部重点实验室,福州 350105)
0 引 言
在双目立体图像拍摄过程中,受摄像机参数设置和摆放位置、拍摄环境光源分布变化以及拍摄物体表面漫反射等因素的影响,不同视点的摄影机捕获到的同一场景的图像可能存在着颜色和亮度差异.立体图像对之间存在的颜色差异不仅会影响与颜色一致性相关的后期任务,还会影响后续深度信息的重建[1-3].颜色校正算法通过颜色映射关系来消除图像组之间的颜色差异,使颜色失真的目标图像具有与参考图像一致的颜色分布.作为一项重要的图像预处理技术,颜色校正已经在立体图像/视频颜色校正[4-8]、多视点视频颜色校正[9-11]、图像拼接/融合[12-17]等领域取得了广泛的应用.
颜色校正方法的研究重点在于颜色映射函数的设计,根据颜色映射函数数量的不同,可以将颜色校正方法分为全局颜色校正方法和局部颜色校正方法两大类.
全局颜色校正方法对目标图像中的所有像素使用同一个颜色映射函数进行颜色校正.早期方法中的全局颜色映射函数来自于简单的统计信息.比如,Reinhard等人最早提出的全局颜色迁移方法[18]利用Lab颜色空间中的通道不相关性,分别使用标准差和平均值对目标图像的各个通道进行颜色转换.Xiao等人通过引入协方差矩阵直接在RGB颜色空间中进行全局颜色迁移,规避了空间转换造成的额外时间开销[19].Pitie等人基于累积概率密度函数对目标图像进行颜色校正[20].另外,还有一些全局颜色校正方法基于参考图像与目标图像之间的直方图或累积直方图计算全局颜色映射函数.比如,Yao等人提出的梯度保留颜色迁移算法[21],通过建立拉普拉斯金字塔同时最小化直方图和梯度误差,以保持校正结果的图像细节不变.
这些全局颜色校正方法运行效率普遍较高,但由于全局颜色映射函数数量单一,只关注图像的全局颜色信息,缺乏对局部信息的关注,因此无法为颜色校正提供像素级别的对应关系.这导致了这类方法在对颜色和纹理细节丰富的图像进行颜色校正时,容易造成校正结果局部颜色不一致的问题,无法得到令人满意的结果.
针对全局颜色校正方法存在的缺陷,局部颜色校正方法被提出.局部颜色校正方法划分和匹配参考图像和目标图像之间的对应区域,对不同区域中的像素计算不同的映射函数.比如,Park等人提出的基于矩阵分解的颜色迁移方法[22]利用图像分割和SIFT(Scale-Invariant Feature Transform)特征点[23]进行区域匹配并根据各区域的匹配特征点计算局部颜色映射函数.Zheng和Niu等人提出的基于匹配和优化的颜色校正方法[4]通过SIFT Flow匹配左右视图特征得到密集立体匹配图,并将其结合全局颜色校正结果得到初始校正结果,接着将颜色校正转换为二次能量最小化问题进行求解,得到优化后的最终结果.但该方法使用的SIFT Flow的计算和优化过程耗时较长,并且当左右视图视差变化过大时,初始结果中的结构变形难以得到合理优化.为此,Niu等人在此基础上加入引导滤波,提出视觉一致性立体图像颜色校正方法[5],该方法虽然能够提高校正结果的结构一致性,但引导滤波却降低了校正结果的清晰度.为了避免结果清晰度的降低,Niu等人提出了基于抠图的结构一致图像颜色校正残差优化方法[6],将颜色校正定义为目标图像与校正结果图像之间的残差优化问题,通过软抠图的方式优化初始化结果残差,在维持图像清晰度的同时保证了校正图像的结构不变.Fan等人提出的基于深度残差优化的立体图像颜色校正方法[7]使用神经网络优化MO[4]的初始校正结果,耗时过长的初始化步骤导致该方法的整体效率并未得到大的提升.Zheng等人提出基于视差注意力的端到端立体图像颜色校正方法[8],使用视差注意力机制匹配左右视图特征,将初始化与优化步骤统一于一个卷积神经网络之中.该方法运行效率高,但由于视差注意力搜索方向的限制,匹配精度受场景变化影响大,应用范围受限.
与全局颜色校正方法相比,局部颜色校正方法对不同区域细节的关注提高了其对颜色纹理复杂图像的处理能力,但这类方法在颜色校正性能上的提升通常以牺牲运行时间为代价:一方面,局部颜色校正方法为了提供更加精细的匹配关系,需要在特征匹配步骤上花费更多的时间;另一方面,由于图像分割、特征匹配算法的引入以及多个映射函数的作用对校正的稳定性造成了影响,大部分局部颜色方法需要对初始结果进行后续优化,以解决校正结果中的区域颜色不一致以及无匹配或误匹配区域结构变形的问题.
为了解决现有的全局颜色校正方法和局部颜色校正方法存在的颜色校正效果和时间效率不平衡问题,本文提出了一种融合匹配特征的立体图像颜色校正方法(Stereoscopic image Color Correction based on Matching features Fusion,SCCMF),使用卷积网络替换传统方法中费时的左右视图稠密特征匹配以及繁琐的初始结果优化步骤,从而高效地实现精准的立体图像颜色校正.本文SCCMF方法利用基于视差注意力机制的颜色校正网络与基于光流的图像匹配网络获取立体图像左右视图之间的密集像素对应关系,设计图像融合网络优化校正结果.具体地说,先通过基于视差注意力机制的颜色校正网络得到初始校正图,接着使用基于光流的图像匹配网络计算初始校正结果到参考图像的光流,得到光流匹配目标图.初始校正结果能够提高光流网络计算光流的准确性,光流匹配目标图弥补了视差注意力机制对垂直视差和细节匹配的不足,两个网络相辅相成,共同提高左右视图特征匹配的准确性和稳定性.最后由图像融合网络融合参考图像、目标图像、初始校正图和光流匹配目标图的特征得到最终校正结果,融合模型采用残差训练的方式,引入感知损失、逐像素损失和多层级结构相似性损失,在保持校正结果清晰度的同时,进一步地提高其与参考图像之间的颜色一致性以及与目标图像之间的结构一致性.实验结果证明了本文提出的立体图像颜色校正方法的有效性、稳定性和高效性.
1 本文方法
本节介绍本文提出的融合匹配特征的立体图像颜色校正方法.如图1所示,本文方法主要由视差注意力颜色校正网络(Parallax Attention based Stereoscopic image Color Correction,PASCC)[8]、基于光流的图像匹配网络和图像融合网络3个模块构成,输入为参考图像(左视图)和待校正的目标图像(颜色失真的右视图),输出为目标图像的校正结果.校正过程如下:
1)首先,将参考图像和待校正的目标图像输入PASCC网络,PASCC网络通过视差注意力机制对左右视图进行特征匹配和颜色校正,得到初始校正图.本文将在1.1节介绍PASCC网络;
2)接着,将初始校正图和参考图像作为预训练光流网络FlowNet2.0[24]的输入,计算初始校正图到参考图像的光流,接着根据该光流,使用变形层(Warping layer)对参考图像进行图像变形得到光流匹配目标图.由于初始校正图与参考图像之间的大部分亮度差异已经得到了PASCC网络的修正,因此,使用初始校正图计算得到的光流要比直接使用目标图像计算的光流更加准确.1.2节将对这一阶段展开更进一步地描述;
3)最后,将前两阶段得到的初始校正图、光流匹配目标图与参考图像、目标图像共4张图像一起作为图像融合网络的输入.图像融合网络先使用编码器分别提取4张图像的特征,接着对提取到的4张特征进行特征融合,最后通过解码器进行图像重建得到最终的校正结果.融合模型的详细结构将在1.3节中说明.
1.1 视差注意力颜色校正网络
视差注意力机制[25]能够捕获双目立体图像全局对应关系.视差注意力颜色校正网络PASCC利用该机制替换传统预处理中的立体图像稠密匹配,在学习左右视图对应关系的同时实现目标图像颜色校正,具有一定的灵活性和泛化性.视差注意力机制的应用前提为图像对只存在水平视差,因此其只在水平方向(极线方向)上为每个像素搜索最佳匹配点,这一特性虽然提高了搜索的速度,但是当图像对不止存在水平视差时,由于无法在水平方向上搜索到对应的像素,左右视图对应关系的学习将会受到影响,导致错误的颜色校正.为此,本文方法在PASCC网络校正结果的基础上,引入光流计算弥补视差注意力机制的不足,实现更加精准的立体图像像素匹配.
1.2 基于光流的图像匹配网络
基于光流的图像匹配网络的输入包括参考图像和PASCC初始校正图,先使用光流网络计算参考图像与初始校正图之间的光流,接着根据该光流变形参考图像,输出光流匹配目标图.接下来具体介绍该阶段的相关内容.
光流(Optical flow)形成于目标对象的运动、成像物体(如摄像机)的运动或两者之间的相对运动,表示处于运动状态的目标对象在成像平面上的像素运动的瞬时速度.光流的计算需要满足两个假设:一是时间连续或目标对象运动幅度较小,即在短时间内同一目标对象不会出现大的位移;二是亮度恒定不变,即同一目标对象的亮度不会随着时间变化.双目立体图像可以看作是摄像机进行细微的水平运动产生的光流,满足假设1.而对于假设2,由于颜色失真的目标图像和参考图像之间存在亮度差异,无法满足该假设,直接使用它们作为光流网络的输入将会影响光流计算的准确性.为了满足假设2,需要尽可能地减少光流网络输入图像之间的亮度差异,本文方法使用经PASCC网络校正得到的初始校正图替代目标图像与参考图像进行光流估计,从而提高光流估计的准确率.在满足了上述两个假设后,就能够直接为光流计算网络选择预训练过的模型,而不需要用失真的立体图像对重新训练模型.本文选择预训练的FlowNet2.0作为光流计算网络,该模型最快能以140fps的速度得到与传统算法精度相当的稠密光流计算结果,保证了本文方法的高效性和准确性.图2直观地展示了不同输入对光流计算网络精度的影响,其中,图2(a)为目标图像(失真类型为亮度+60),图2(b)为PASCC初始校正图,图2(c)为理想目标图像,图2(d)、图2(e)、图2(f)分别为参考图像和图2(a)、图2(b)、图2(c)输入预训练FlowNet2.0得到的可视化光流图.可以看到,与使用目标图像计算的光流(d)相比,由初始校正图计算的光流(e)在整体和细节上都更加接近由理想目标图像计算的光流(f),这得益于初始校正图(b)已经对目标图像(a)中的颜色失真进行了一定程度地修正,在图像整体亮度上更加接近理想目标图像(c).
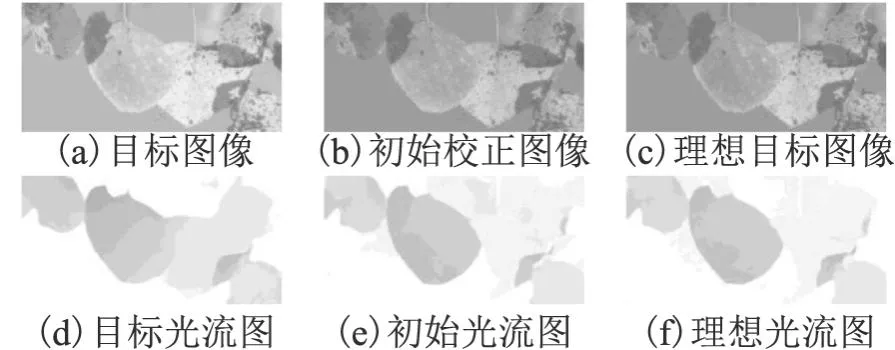
图2 不同输入得到的可视化光流图对比Fig.2 Comparison of visual optical flow images obtained from different inputs
光流估计与视差注意力机制类似,通过为每个像素搜索其在另一张图像上特征相似度最高的像素作为最佳匹配点,实现像素级别的图像间稠密特征匹配.不同的是,光流估计的搜索空间不受视差方向的限制,能够同时搜索水平和垂直方向的对应像素点,从而提高特征匹配的准确性和稳定性.
假设某个位于立体图像左视图中的像素(x,y)在右视图中的最佳匹配点为(x′,y′),则点(x,y)的光流为:
(u,v)=(x′-x,y′-y)
(1)
其中,u和v分别表示像素(x,y)发生水平位移和垂直位移的变化率.
定义参考图像为Iref,初始校正图为Iinit,初始校正图Iinit到参考图像Iref的逆向光流(backward flow)为Finit→ref,则点(x,y)的光流可以表示为:
(u,v)=Finit→ref(x,y)
(2)

(3)
特别地,由于正向变形(forward warping)会造成像素重叠和匹配区域空洞的问题,因此本文选择反向变形(backward warping)作为图像变形的实现方式.本文在基于光流的图像匹配网络中,使用双线性采样层(bilinear sampling layer)[26]实现参考图像的反向变形和无匹配区域的空洞填充.
1.3 图像融合网络
本文使用的图像融合模型基于U-Net图像分割模型[27]设计,模型的详细结构信息如表1所示,其中,ReflectionPad表示参数为2的反射填充,LeakyReLU的泄漏因子为0.02,BN(Batch Normalization)为批量标准化,[]表示参数dim为1的矩阵拼接,TransposeConv表示卷积核为5×5的反卷积.

表1 图像融合模型的详细结构Table 1 Detailed structure of image fusion model

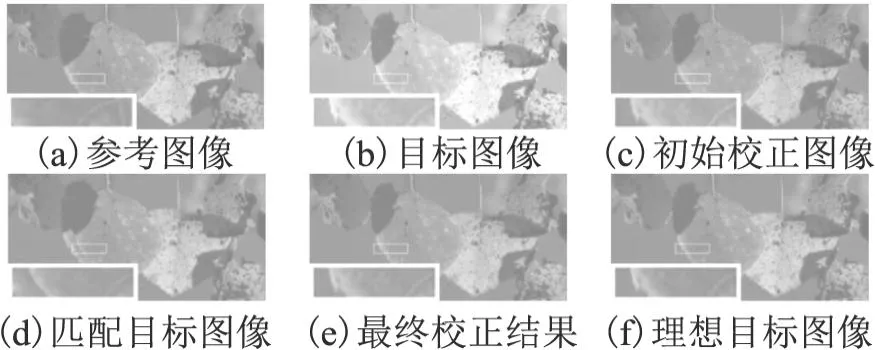
图3 图像融合网络输入图像与输出图像示例Fig.3 Example of input images and output images of image fusion network
1.4 损失函数

本文使用在ImageNet数据集上预训练的VGG19的5个激活层(relu1_1、relu2_1、relu3_1、relu4_1、relu5_1)的特征进行距离度量,得到校正结果图像Iresult与参考图像Iref之间的感知损失,公式如下:
(4)
其中,φi(I)表示图像I输入预训练VGG19网络时第i层激活层的特征,Ni表示第i层中的总元素数.
与感知损失计算方式类似,本文提取预训练VGG19网络4个激活层(relu2-2、relu3-4、relu4-4、relu5-2)的特征进行风格损失计算,具体公式如下:
(5)


(6)
其中,H和W分别为图像的高和宽,I(x,y)表示图像I在坐标点(x,y)处的像素值.
MS-SSIM损失提高不同尺度下图像的结构相似程度,其计算方法用公式表示如下:
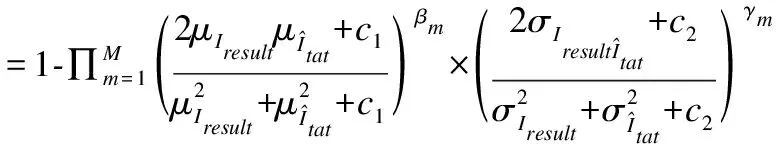
(7)

结合上述介绍的4种损失,图像融合模型的总损失函数如下:
L=λ1Lperceptual+λ2Lstyle+λ3LL1+λ4LMS-SSIM
(8)
其中,λ1、λ2、λ3和λ4分别表示感知损失、风格损失、L1损失和MS-SSIM损失的权重.实验中,将各损失权重分别设置为:λ1=1,λ2=1000,λ3=100,λ4=100.
2 实验结果与分析
本节介绍本文提出的融合匹配特征的立体图像颜色校正方法的实验设置和细节,通过对比实验和损失函数实验来验证本文方法的有效性.
2.1 实验数据集
本文实验使用的数据集包括Flickr1024数据集[31]、Middlebury数据集[32]和ICCD2015数据集[33],其中,ICCD2015是图像颜色校正方法常用的数据集.由于只有ICCD2015数据集包含失真图像对,因此使用Adobe Photoshop CS6对Flick1024和Middlebury数据集中的立体图像右视图进行颜色修改,将修改后的右视图作为目标图像用于颜色校正,颜色失真处理同ICCD2015数据集,如表2所示,共有6种失真类型,且每种失真类型包括3种修改粒度.因此,每处理一对立体图像就可以得到18张目标图像.将经过颜色处理的Flickr1024数据集的训练集(包含14400张待校正目标图像)作为本文实验使用的训练集,该数据集中的立体图像质量高且涵盖场景丰富,有助于提高立体图像颜色校正模型的泛化能力.模型测试集则包括经过颜色处理的Flickr1024测试集(包含2016张待校正目标图像)、Middlebury数据集(包含1224张待校正目标图像)和ICCD2015数据集(包含324张待校正目标图像).

表2 ICCD2015数据集中的颜色失真类型与粒度Table 2 Color distortion types and granularity in ICCD2015 dataset
2.2 实验细节
本文模型基于Pytorch框架,Pytorch版本为0.4.0,Python版本为3.6.2,实验环境如下:操作系统为Ubuntu16.04,处理器为Intel(R)Xeon(R)CPU E5-2620 v4 @ 2.10GHz×6,显卡为Nvidia Tesla P100 16G×2,CUDA版本为8.0.61.融合模型使用Adam优化器进行优化,批次大小设置为16,将初始学习率设置为1×10-3,最小学习率设置为1×10-4,训练时学习率每隔20 epoch减半,最终将训练130 epoch的模型用于测试.对于PASCC模型,本文实验按照工作[8]中介绍的实验设置进行训练.
为了丰富训练数据的多样性从而增强模型的泛化能力,在融合模型的训练过程中使用数据增强策略.具体地说,先将图像短边缩放至400像素,等比缩放长边,接着采用相同随机数的裁剪方法将各组图像对裁剪成128×128的尺寸作为输入.
为了方便不同方法对比校正结果,测试时等比缩放测试集图像,将其长边缩放至512像素,等比缩放短边.
2.3 评价指标
为了评估本文所提出的方法的有效性,本文使用18种图像质量评价指标来进行不同颜色校正方法的性能评估,包括:MSE[34]、MAD[35]、iCID[36]、PSNR[33]、SSIM[37]、VSI[38]、CSVD[33]、GSIM[39]、FSIM[40]、UQI[41]、GSM[42]、OSS[43]、IFS[44]、FSIMc[40]、DSS[45]、DSCSI[46]、CSSS[47]和PSIM[48],其中,MSE、MAD和iCID 3个指标数值越小越好,其余指标数值越大越好.
2.4 对比实验
2.4.1 客观质量评价
为了验证本文SCCMF方法的颜色校正性能,本小节使用18种图像质量评价指标进行客观校正效果评估,并与12种先进的颜色校正方法进行对比,包括GCT[18]、GCT-CCS[19]、ACG-CDT[49]、GPCT[21]、CHM[50]、PRM[51]、GC[52]、ICDT[20]、MO[4]、VC-ICC[5]、MROC[6]和PASCC[8].同时,为了验证PASCC校正模型与基于光流的图像匹配模块结合对于融合模型的有效性,本小节设计MF方法进行对比实验,即针对基于光流的图像匹配网络,不使用PASCC模型的初始校正结果替换目标图像,直接将目标图像和参考图像作为光流计算网络的输入,得到光流和光流匹配目标图.注意,MF方法和SCCMF方法使用的图像融合模型结构一致,模型的输入均为4张图像.由于实验数据集中存在理想目标图像(无失真的右视图),因此直接用其与各颜色校正方法的结果进行比较,计算指标.Flickr1024数据集和Middlebury数据集上的客观质量评价结果分别如表3和表4所示,最好的性能分别用粗体及单下划线、下划线和双下滑线表示.

表3 Flickr1024测试集中2016张目标图像的对比结果Table 3 Comparison results of 2016 target images in the Flickr1024 test set

表4 Middlebury数据集中1224张目标图像的对比结果Table 4 Comparison results of 1224 target images in the Middlebury dataset
通过分析表3和表4中的指标数据发现,在Flickr1024测试集中,本文提出的SCCMF方法除了在SSIM和VSI指标上略低于PASCC排名第二,在其余16个指标上都排名第一;在Middlebury数据集中,SCCMF方法在所有的18个指标上都排名第一;在这两个数据集中,与PASCC方法相比,本文SCCMF方法在MSE、MAD、PSNR、IFS、DSS、DSCSI和CSSS这7个指标上的提升较为明显.指标数据证明了本文SCCMF方法的有效性.特别地,SCCMF模型只在Flickr1024训练集上进行训练,却同样在Middlebury数据集上表现最优,这证明了SCCMF方法具有优秀的泛化性能.
此外,在表3和表4中可以看到,直接使用目标图像计算光流的MF方法的性能虽然略逊于SCCMF方法,但是与PASCC方法相比也有一定的提升,综合表现排名第二.具体地说,在Flickr1024数据集中,MF在GSIM指标上与SCCMF并列第一,在SSIM、VSI和FSIM指标上和PASCC差距微弱,排名第三,在其余14个指标上排名第二;在Middlebury数据集中,MF的PSIM指标和SCCMF一起排名第一,SSIM指标排名第三,但与排名第二的PASCC差距微弱,其余16个指标均排名第二.这些证明了PASCC校正模型与基于光流的图像匹配模块结合的结构的有效性,二者彼此之间能够互相增益,共同提高颜色校正的性能.
ICCD2015数据集中的图像截取自视频前后帧,不是标准的双目立体图像对,因此该数据集中的图像对视差方向不固定且部分场景变化较大.ICCD2015数据集上的客观质量评价结果如表5所示,最好的性能分别用粗体及单下划线、下划线和双下滑线表示.
分析表5指标数据发现,在Flicker1024测试集和Middlebury数据集上性能良好的PASCC方法在ICCD2015数据集上性能下降明显,与表现最好的MO、VC-ICC和MROC等方法在大多数指标上都有着较大的差距,只在PSIM指标上排名第三.对比PASCC方法,本文SCCMF方法在各个质量评价指标上都有很大的提升,其中,SCCMF方法在GSIM、GSM、OSS、DSS和PSIM上排名第一,在FSIM和IFS两个指标上排名第二,在VSI和FSIMc指标上排名第三.这证明了SCCMF方法通过在PASCC方法的基础上引入光流网络加强像素匹配,以及使用融合模型进一步优化结果的设计,能够弥补视差注意力机制仅在水平视差方向上搜索对应关系的不足,提高不同应用场景下颜色校正性能的稳定性.在IC-CD2015数据集中,MROC方法有7个指标排名第一,8个排名第二;VC-ICC方法则有5个指标排名第一,8个排名第二.综合来看,该数据集中MROC方法表现最佳,VC-ICC方法次之,而SCCMF方法与VC-ICC方法的性能也具有可比性.但是一方面,MROC和VC-ICC方法基于ICCD2015数据集设置初始化阈值,虽然在该数据集上表现良好,但在另外两个数据集上的表现却有所欠缺;另一方面,MROC和VC-ICC方法使用SIFT Flow算法获得匹配图像,牺牲了时间效率,而SCCMF方法基于卷积神经网络实现,可以利用GPU加速,大大减少了时间成本.有关时间复杂度的对比和分析将在2.4.3节中具体介绍.
2.4.2 主观视觉效果对比
本节将SCCMF方法同12种颜色校正方法进行主观视觉效果对比.本文SCCMF方法能够很好地处理3种修改粒度的六种颜色失真类型,图4、图5和图6分别展示了SCCMF方法对亮度、RG通道和色度3种颜色失真类型的校正性能.为了便于观察对比,在图4至图6中使用方框圈出并放大图像中颜色校正效果对比明显的区域.

图4 Flickr1024数据集的视觉对比示例(目标图像失真类型为亮度+90)Fig.4 Example of visual contrast for Flickr1024 dataset(target image distortion type is luminance+90)

图5 Middlebury数据集的视觉对比示例(目标图像失真类型为RG通道+90)Fig.5 Example of visual contrast for Middlebury dataset(target image distortion type is RG channel+90)

图6 ICCD2015数据集的视觉对比示例(目标图像失真类型为色度+60)Fig.6 Example of visual contrast for ICCD2015 dataset(target image distortion type is chroma+60)
图4为Flick1024数据集中的颜色校正结果对比示例.观察图4可以发现,GCT、GCT-CCS、PRM和GC4种方法的校正结果整体颜色和理想目标图像存在很大的偏差;ACG-CDT、VC-ICC和MROC方法校正结果中的左侧楼房颜色偏暗,且后两种方法在方框圈出的窗户上方存在比较明显的噪点;GPCT和PASCC方法校正得到的窗户右边框部分泛白;MO方法校正结果中的窗户存在纹理结构变形;CHM方法校正得到的云朵颜色存在偏差;ICDT方法的校正结果在天空出现了伪影,云朵的伪影尤其严重;而本文SCCMF方法的校正结果不仅在整体颜色上与理想目标图像保持一致,还在细节的颜色和纹理上与其最为接近.
图5为Middlebury数据集中的颜色校正结果对比示例.通过图5可以发现,GCT-CCS和PRM方法校正结果的整体颜色与理想目标图像不一致;GPCT和ICDT方法的校正结果中噪声明显;MO方法校正结果中右下角多面体出现结构变形;只有PASCC和SCCMF方法正确且清晰地还原条纹的颜色和纹理,但PASCC方法对条纹上方区域的校正效果却明显不如SCCMF方法.本文SCCMF方法不仅能够校正目标图像的颜色,还能恢复其因颜色失真而丢失的纹理细节.
图6为ICCD2015数据集中的颜色校正结果对比示例,特别地,由于该数据集中的图像对来自视频前后帧,因此参考图像和目标图像的场景变化较大.分析图6可以发现,PRM方法校正结果整体颜色错误;13种方法中,只有PASCC和SCCMF方法正确校正了手套的颜色;13张校正结果中,只有VC-ICC、PASCC和SCCMF方法校正结果中的墙上贴图的整体颜色和理想目标图像接近,但VC-ICC方法模糊了贴图的细节,PASCC方法对贴图左下角的校正不如SCCMF方法,颜色偏浅.本文SCCMF方法在非立体图像对的应用场景中也能正确地校正目标图像的颜色,使其颜色和结构都尽可能地接近理想目标图像.
2.4.3 时间复杂度对比
本小节讨论本文提出的SCCMF方法的时间复杂度.CPU实验运行环境为3.00GHzntel(R)Core(TM)i5-9500F CPU and 8.00 GB存储器的PC机.本文方法的时间复杂度实验环境设置同2.2节中的介绍.
挑选90张大小为512×320的目标图像,计算单张校正时间来进行时间复杂度分析,其中,对比方法包括全局颜色校正方法GCT、GCT-CCS、ACG-CDT、GPCT、CHM和ICDT,局部颜色校正方法PRM、GC、MO、VC-ICC、MROC和PASCC.
分析表6数据可知,本文SCCMF方法0.37s的平均运行时间(包括PASCC方法的0.24s,FlowNet2.0的0.09s,图像融合模型的0.04s)优于部分全局颜色校正方法(ACG-CDT和ICDT)和大部分局部颜色校正方法(除GC和PASCC).结合2.4.1节的客观质量对比结果和2.4.2节的主观视觉对比,证实了本文方法能在保持高时间效率的同时获得更高质量的颜色校正结果.

表6 平均运行时间对比表Table 6 Average runtime comparison table
2.5 损失函数实验
2.5.1 损失函数消融实验
为了验证本文方法使用的4种损失函数的有效性,本小节在Flicker1024测试集上组合损失函数进行消融实验,消融实验所有的设置与对比实验相同,使用MSE、DSCSI、CSVD、PSNR和SSIM作为图像质量评价指标.实验结果如表7所示,最好的性能用粗体及下划线表示,次优的性能用下划线表示.

表7 融合模型损失函数消融实验表Table 7 Fusion model loss function ablation experiment table
从表7中的指标数据可以发现,使用4种损失函数组合训练的融合模型性能最优,在MSE、DSCSI、CSVD和PSNR指标上排名第一,在SSIM指标上排名第二.效果次优的是LL1和LMS-SSIM两种损失组合训练的模型,在SSIM指标上排名第一,在其余4个指标上排名第二.因此,可以证明本文使用4种损失函数组合训练融合模型是最有效,能够最优化模型的性能.
2.5.2 损失函数权重实验
本节讨论本文方法使用的4种损失函数的权重设置对融合模型的影响.权重实验在Flickr1024数据集上进行,实验环境和设置与对比实验保持一致,使用MSE、DSCSI、CSVD、PSNR和SSIM作为图像质量评价指标.2.5.1节的损失函数消融实验已经证明了4种损失函数组合训练的有效性,因此,本节权重实验将感知损失的权重λ1、风格损失的权重λ2、L1损失的权重λ3和MS-SSIM损失的权重λ4的量级比例保持在λ1∶λ2∶λ3∶λ4=1∶1000∶100∶100,以保证4个损失的量级相同.实验结果如表8所示,其中,最好的性能用粗体及下划线表示,次优的性能用下划线表示.

表8 融合模型损失函数权重实验表Table 8 Fusion model loss function weight experiment table
通过观察表8数据可以发现,感知损失权重过大会导致融合模型性能的下降,而其余3个损失函数权重的变化对融合模型的性能影响不大.因此,可以证明本文实验λ1=1,λ2=1000,λ3=100,λ4=100的权重设置是可行的.
3 结 论
本文针对颜色校正性能和运行时间效率的平衡问题,提出了一种融合匹配特征的立体图像颜色校正方法,基于卷积神经网络高效地实现了高质量的立体图像颜色校正.在视差注意力颜色校正网络的基础上加入基于光流的图像匹配架构,以加强左右视图对应像素匹配的准确性和稳定性,弥补视差注意力机制对于垂直视差和细节匹配的不足.使用图像融合模型进一步提高校正结果与参考图像之间的颜色一致性以及与目标图像之间的结构一致性.在Flickr1024数据集、Middlebury数据集和ICCD2015数据集上的对比实验证明了本文提出的SCCMF方法的有效性.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小型微型计算机系统(2022年1期)2022-01-21
国学(2020年1期)2020-06-29
电光与控制(2018年10期)2018-10-13
天津大学学报(自然科学与工程技术版)(2018年6期)2018-05-30
数学物理学报(2017年6期)2018-01-22
摄影之友(影像视觉)(2017年1期)2017-07-18
现代计算机(2016年3期)2016-09-23
西部广播电视(2015年5期)2016-01-16
中国铁道科学(2014年6期)2014-06-21
