
基于Swin Transformer生成对抗网络的图像生成算法
2024-02-28 08:18省海先
小型微型计算机系统 2024年1期
王 军,高 放,省海先,张 宇
(沈阳化工大学 计算机科学与技术学院,沈阳 110142)
0 引 言
图像生成是计算机视觉与图形学的基本研究方向之一,其任务是通过生成模型来合成预期图像.如何产生高分辨率、高质量的图像是一个困扰计算机图形学领域研究者的问题.近年来,随着硬件设备的不断更新,算力不断增强,基于深度神经网络的生成模型--生成对抗网络(GAN)[1,2]也在快速发展.
GAN在2014年由Goodfellow等[3]人首次提出,这是一种无监督学习方法,基本思想源自博弈论,其结构由一个生成器和一个判别器组成,二者通过对抗学习的方式训练,目的是学习观测数据样本的分布并生成新的数据样本.近年来,生成式对抗网络的研究和应用不断获得成功,已经成为当前深度图像生成领域研究的热点.它被广泛应用于计算机视觉领域,如超分辨率任务SRGAN[4],风格迁移任务Cycle GAN[5]等,并且在这些任务中,GAN均表现出比传统模型更优的效果.但是,GAN也存在训练不稳定、梯度消失、模式坍塌等问题.
NVIDIA研究员2017年提出了StyleGAN[6],通过一种渐进增大的方式训练GAN,从低分辨率开始逐步添加新的层次,从而在训练进展中增加更精细的细节.这种训练方式既加快了训练速度,又能增加训练的稳定性,从而能够制作出前所未有的质量的图像.2019年也是NVIDIA研究员提出了改进的StyleGAN[7],主要解决StyleGAN存在的液滴伪像问题和切变不变性问题;并提出感知路径长度作为一种评价图像质量的指标,感知路径长度越低生成器性能越好.NVIDIA在2019年在GTC大会的时展示最新AI艺术生成对抗网络GauGAN2[8],结合了分割映射、图像修复和文本到图像生成功能,使其能够根据文本和手绘,来创建逼真的艺术,可从文本生成精确风景图,生成更多种类以及更高品质的图像.但其应用了Nvidia Selene超级计算机,并且使用1000万张高品质风景图进行训练,受到资源限制一般研究者无法复现.StyleGAN-XL[9]利用强大的神经网络先验和渐进式增长策略,成功地在ImageNet上训练最新的StyleGAN3生成器,将StyleGAN扩展到大型多样化数据集,并首次在 ImageNet 下生成分辨率为10242的图片.以上NVIDIA对GAN的改进提升了性能,达到了前所未有的效果,但是其依赖于巨大的计算量,消耗了令人难以想象的资源和电力,训练效率低.StyleGAN网络需要在多个显卡的设备上进行训练,为了更好的适应大众单显卡的设备,本文提出在一块显卡的终端设备上进行训练的模型,没有采用StyleGAN这种复杂的网络.
生成对抗网络使用对抗性学习方法进行训练,可以在不借助外在条件约束的情况下达到最优效果,但优化过程面临着一个很大的挑战:即如何平衡生成器和判别器的性能,最终收敛在全局最优点.具有高精度的鉴别器可能产生具有很少信息的梯度并导致模式崩溃问题,但弱鉴别器不能更好地引导生成器提高其学习能力.针对模型不收敛和模式坍塌的问题,本文将Swin Transformer机制[10]引入到判别器中提高判别能力,并使用自注意力[11,12]代替卷积神经对生成器加以改进,提出一种基于Swin Transformer的生成对抗网络——STGAN(Swin Transformer Generative Adversarial Network),旨在平衡生成器和判别器性能,解决模型训练不稳定性、训练效率低等问题.具体从以下几个方面进行改进:
1)针对生成图像缺乏远距离像素之间的关系问题,在生成网络中加入自注意力模块,捕捉全局的信息来获得更大的感受野解决长距离依赖问题.
2)在判别网络中引入Swin Transformer机制,将注意力的计算限制在每个窗口内,减少了全局注意力计算量,降低训练的成本,提高训练效率.
3)在生成网络中使用谱范数规范化[13],能够更好地将模型与训练数据进行拟合,并且采用Wassertein 距离[14]作为网络的距离衡量方式有效地解决梯度消失/爆炸的问题.
1 相关内容
1.1 生成对抗网络
GAN是一种基于深度学习的图像生成技术[15],它由两个部分组成:生成器和判别器.生成器是一种生成模型,用来学习真实图片的概率分布从而生成以假乱真的图片.判别器是一种判别模型,用来识别真实图片和生成的假图片并判别生成器的输出和真实数据概率分布的相似情况.生成器的输入是一定长度的随机噪声;输出是一张假的图片.判别器的输入是真实图片和生成的假图片;输出是一个范围在0到1之间的标量,输出的标量值越大,对应生成的图片更加真实.生成器和判别器形成动态的对抗训练,最终模型收敛在纳什均衡点.
生成对抗网络原理如图1所示:随机向量作为生成器的输入数据产生一个新的向量fake,同时从数据集中随机选择一张图片转化为向量x.fake或者x输入判别器后,判别器经过计算输出一个0到1之间的数值,该数值表示输入图片为真实图片的概率,真图片概率为1,假图片概率为0.

图1 生成对抗网络结构图Fig.1 Generate adversarial network structures
原理见公式(1):
fake=G(z)
(1)
score=D(G(z),0) or D(x,1)score∈(0,1)
(2)
式中D为判别器,G为生成器.
原始生成对抗网络模型的优化函数表示为公式:
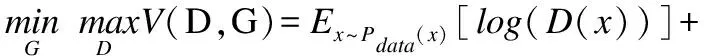
(3)
式中Pdata(x)为真实数据的分布,Pz(z)为噪声分布.
判别器模型的优化函数表示见公式(4):
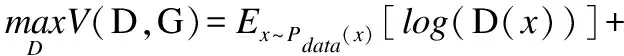
(4)
判别器损失函数使用交叉熵损失函数计算损失,进行梯度反向传播.其中D(x)表示判别器对真实样本进行判别,判别结果越接近于1则真样本预测结果越好.而对于生成的样本G(z),判别器的判别结果D(G(z))越接近于0则优化效果越好.预期目标是得到最大的总数值,也就是最大化目标函数.
生成器模型的优化函数表示见公式(5):
(5)
在完成判别器的优化后,需要对生成器进行优化.只要让判别的结果D(G(z))接近于1就可以了.预期目标是得到最小的总数值,也就是最小化目标函数.
1.2 Swin Transformer模型
Swin Transformer是一种带移动窗口的自注意力模型.使用划分窗口的方法将自注意力的计算限制在一个局部的窗口中,同时使用滑窗机制增加了相邻窗口之间的联系,这种方式在获得近乎全局注意力能力的同时,又将计算量从图像大小的平方关系降为线性关系,大大地减少了运算量,提高了模型推理速度;另外通过特征融合的方式,每次特征抽取之后都进行一次下采样,增加了下一次窗口注意力运算在原始图像上的感受野,从而对输入图像进行了多尺度的特征提取,进行特征图分层计算.
Swin Transformer模块是该模型的主要组成部分,一个Swin Transformer模块由一个基于Shifted Window的多头自注意力模块MSA、一个两层中间带有GELU非线性激活函数的多层感知机MLP组成.在每个MSA和MLP之前,还应用了一个归一化层LN,并在每个模块之后都应用了一个残差连接.如图2所示,连续的两个Swin Transformer块的计算过程见公式(6)~公式(9):
(6)

图2 Swin Transformer模块结构图Fig.2 Swin Transformer module structure
(7)
(8)
(9)

Swin Transformer的提出解决了Transformer模型从自然语言处理领域应用到计算机视觉领域应用[16]的两大挑战:视觉实体变化大和计算图像像素全局自注意力所需计算量大.通过不断地调整每一层感受野的大小来产生分层特征图,能够更好地建模不同尺寸的物体,同时Swin Transformer在计算自注意力阶段具有线性复杂度.目前该模型已经在图像分割、目标检测等领域霸榜,让计算机视觉研究者们看到了Transformer完全替代CNN的可能性.
2 基于Swin Transformer的生成对抗网络
本文提出的基于Swin Transformer的生成对抗网络(STGAN)由两部分构成:第1部分是引入注意力机制和谱范数规范化的生成网络,第2部分是引入Swin Transformer机制的判别网络.
2.1 STGAN模型结构
2.1.1 生成网络
STGAN的生成网络模型结构如图3所示,采用4层逆卷积神经网络进行上采样.首先将100维的噪声作为生成网络的输入,经过第1个CSBR模块入进行上采样得到(512,4,4)的特征图,再经过第2个CSBR模块进行上采样后得到(256,8,8)的特征图,经过第3个CSBR模块进行上采样后得到(128,16,16)的特征图,将其送入自注意力模块进行计算,与原始只用卷积的模型不同,引入自注意力模块计算特征图中每个向量间的相关性,捕捉全局的信息来获得更大的感受野解决长距离依赖问题.之后再经过一个CSBR模块对特征图进行上采样,将得到的(64,32,32)特征图再进行一次自注意力的计算,进行自注意力计算不改变特征图的尺寸.最后再经过一次逆卷积操作并使用Tanh激活函数,输出64×64像素的三通道图片.
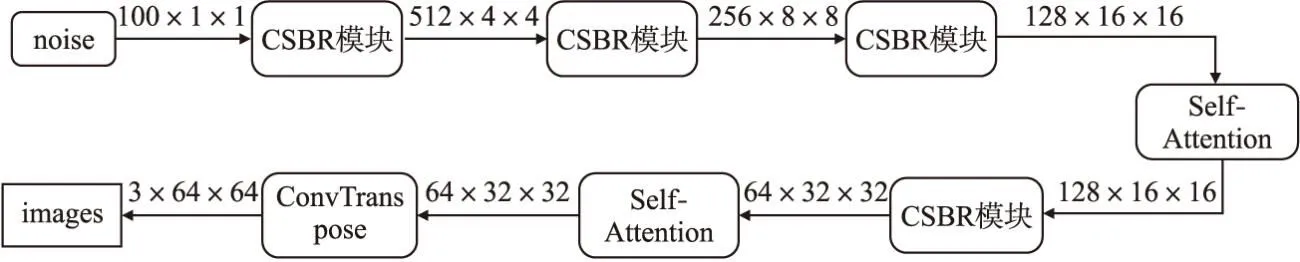
图3 生成器网络结构图Fig.3 Generator network structure
CSBR模块结构如图4所示,该模块由逆卷积、谱范数规范化、批量规范化和Relu激活函数组成.其中,在生成网络中加入谱范数规范化,引入利普希茨连续性约束,使神经网络对输入扰动具有较好的非敏感性,从而使训练过程更稳定、模型更容易收敛.

图4 CSBR模块结构图Fig.4 CSBR module structure
在生成网络最后两次上采样后加入自注意力机制,自注意力机制在某种程度上可以增加感受野,扩大感受范围,使模型能尽可能把握全局的特征,而不是图像中的局部特征,从而生成更加逼真的图像.自注意力机制的计算过程如图5所示,可以表示为公式10,其中Q是查询向量,K是键向量,V是值向量,“·”表示点积运算.
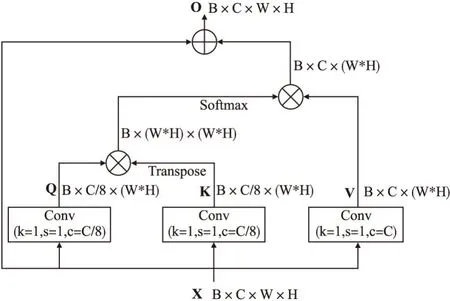
图5 Self-Attention机制结构图Fig.5 Self-Attention mechanism structure

图6 判别器网络结构图Fig.6 Discriminator network structure
Attention(Q,K,V)=Softmax(Q·KT)·V
(10)
2.1.2 判别网络
与生成网络结构相反,STGAN的判别网络采用三阶段的Swin Transformer模块,其模型结构如图 6所示.首先将64×64像素的三通道照片作为判别网络的输入,对其进行分块操作并添加相对位置编码,原来张量的维度是(64,64,3),经过分块操作之后,每个张量的维度的大小就变成了(16,16),尺寸缩小了4倍,通道数增大了16倍,将张量通道维度上进行拼接,得到的张量的大小就变成了(16,16,48).第1阶段,在进入Swin Transformer模块之前还需进行线性嵌入,即使用卷积将张量通道数48维映射到96维,张量维度是(16,16,96),经过Swin Transformer模块计算窗口注意力,输出和输入维度保持不变.之后进入第2阶段,首先做两倍的下采样缩小分辨率,并调整通道数从而形成不同尺寸的特征图,构建层级的Transformer,因此,网络可以学习多尺寸的特征信息;之后再经过Swin Transformer模块得到(8,8,192)的张量.在第3阶段完成后,得到(4,4,384)的张量,将其展开成6144维向量,输入全连接层使用Sigmoid激活函数将输出限制在0~1之间,用来表示真实图片的概率.
2.2 基于移动窗口的自注意力计算
为了方便计算图像的自注意力,采用在局部窗口内计算自注意力,窗口以非重叠的方式均匀地分割图像.虽然这种方式虽然很好的解决了内存和计算量的问题,但是窗口与窗口之间无法进行信息交互,达不到全局建模的效果,限制了模型的能力.
本文提出的STGAN模型采用基于移动窗口的方式进行自注意力的计算,先使用划分窗口的方法将自注意力的计算限制在一个局部的窗口中,与这一过程相对应的是Swin Transformer模块中的W-MSA;然后使用滑窗机制增加了相邻窗口之间的联系,与这一过程相对应的是Swin Transformer模块中的SW-MSA.计算过程分为:特征图移位和自注意力掩码两部分.
2.2.1 特征图移位操作
首先对图像进行分块和常规的窗口划分,如图7所示,左边的特征图有4个窗口(每个窗口有4×4个小块),在移动窗口后得到9个窗口,这种移位窗口的方式,使得相邻的窗口可以进行信息交互.但是移动后窗口数量增加,而且每个窗口的大小也不是完全相同,这种方式无疑增加了自注意力计算复杂度.为了方便计算各窗口自注意力,本文采用一种掩码的方式计算注意力.

图7 循环位移Fig.7 Cyclic slide
2.2.2 自注意力掩码
采用掩码的方式进行自注意力的计算,其目的是在不增加计算复杂度的同时计算出移动窗口后各窗口的自注意力值.让一个窗口中不同的区域之间能用一次前向过程就能把自注意力就算出来,而相互之间都不干扰.具体过程如图8所示.
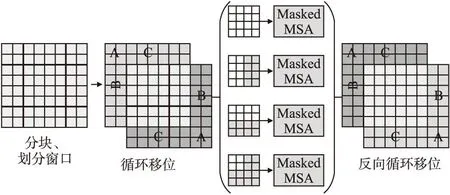
图8 窗口划分和掩码设置Fig.8 Window partition and Mask settings
STGAN判别模型使用循环移位和掩码操作的方式,以64×64分辨率的图片为例,划分窗口大小为4×4,循环移位步长为2,如图2所示,在W-MSA内进行常规的自注意计算,之后对特征图进行循环移动,在SW-MSA内进行带掩码的自注意力计算.这种做法,既保证了移动窗口后窗口的数量保持不变,也保证了每个窗口内的块数量不变,实现了一次前向计算过程就能计算出所有窗口自注意力值,同时增多了局部窗口间的信息交互,增大了感受野,更好地提高了网络的学习能力.
2.3 STGAN模型训练
2.3.1 损失函数
与原始GAN不同的是,STGAN网络采用Earth-Mover(EM)距离取代Jensen-Shannon(JS)距离[17]计算损失值,并在判别模型加入梯度惩罚将判别模型的梯度限制在一定范围内.结合传统GAN,EM距离和梯度惩罚,STGAN的目标函数表达式可以表示为公式(11):
(11)
其中,Pr表示的是真实数据的分布,Pg表示由模型产生出来的产生出来的分布,表示梯度,λ表示惩罚权重,Uniform[0,1]表示0到1的均匀分布.
2.3.2 超参数设置
为了使STGAN模型达到最优效果,训练时超参数设定为:使用Adam优化器[18],其中β1=0.5,β2=0.9,生成器和判别器使用相同的初始学习率α=0.0001,判别器每迭代5次则更新迭代1次生成器,并且训练过程中采用warmup技术[19],随着迭代次数的增加,学习率逐渐减小,最小学习率设置为0.000001,Batchsize大小设置为256,另外使用EM距离作为损失函数,并引入梯度惩罚,惩罚权重λ为10.模型训练伪代码如算法1所示.
算法1.STGAN
定义:最大迭代次数为N;批量大小为m
for n=1 → N do//n表示迭代次数
Sample m examples {x1,x2,…,xm} from dataset;
Sample m noise samples {z1,z2,…,zm} from Gaussian distribution;

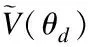
if(n % k==0)then//k 表示更新k次判别器之后更新一次生成器;
Sample another m noise samples {z1,z2,…,zm} from Gaussian distribution;
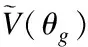
end if
end for
3 实验方法和结果分析
本节共分为3个部分,首先介绍实验环境和评价指标,然后分别给出STGAN在CelebA数据集[20]和LSUN数据集[21]上的性能并与最新的模型比较,从实验结果可以看出STGAN模型生成的图片具有非常高的自然度和逼真度,有效地提升了生成图像的质量和真实性.
3.1 数据集和实验环境
3.1.1 数据集介绍
为检验STGAN模型的准确性,分别在CelebA数据集中和LSUN数据集中开展对照试验.其中,CelebA是由香港中文大学公布的大型人脸属性的数据集,该数集共收录了10177位名人的202599个人脸图片.LSUN数集则是由加州大学伯克利分校于2015年公布的大型图像数据集,它包含10个场景类别和20个对象类别,总计约100万个标记图像.
3.1.2 实验环境介绍
本实验使用Pytorch深度学习框架进行实验,并在CUDA平台使用CUDNN加速库进行深度神经网络的训练.具体实验环境如表1所示.

表1 实验环境Table 1 Experimental environment
3.2 评价指标
在图像生成任务中,为了获得高质量的生成图像,需要对生成图像的质量进行度量.主要从两个方面考虑:一是图像本身的质量,图像是否清晰、内容是否完整、是否真实等;二是生成图像的多样性,生成的图像不能只是一种或几种类型的图像,而应该具有不同的风格和不同的类别.
本实验采用IS(Inception Score)和FID(Fréchet Inception Distance)两种评价标准从不同方面评估生成图片的质量.IS是生成图像领域最常用的评估指标之一,它客观地从图像的生成质量和多样性两方面进行评估.IS的计算公式为:
IS(G)=exp(Ex~pgDKL(p(y|x)‖p(y)))
(12)
其中,G表示生成器,E表示期望,x~pg表示x是从pg中生成的图像样本,DKL表示两分布间的KL散度,y表示合成图像的预测标签.IS得分越高,说明生产图像的质量越高,多样性越丰富.
FID也是该领域常用的指标之一,它用来描述两个数据集之间的相似性程度,FID值越小,则相似程度越高,模型效果越好.其计算公式表示为:
(13)
其中,xr,xg表示真实图像和生成图像,μxr,μxg表示各自特征向量的均值,∑xr,∑xg表示各自特征向量的协方差矩阵,Tr表示矩阵的迹(矩阵对角元素之和).
3.3 消融实验
为了验证本文模型改进的有效性,分别对判别器中Swin Transformer模块层数以及模型输入图像大小进行消融实验.表2、表3展示了迭代100个周期,使用相同的学习率和优化器所测得的实验结果.从中可以看出,本文提出的STGAN模型均取得好的表现,其中当模型输入图像大小为96×96时模型提升的效果最明显.

表2 判别网络层数消融实验结果Table 2 Discriminator layers ablation experiment results
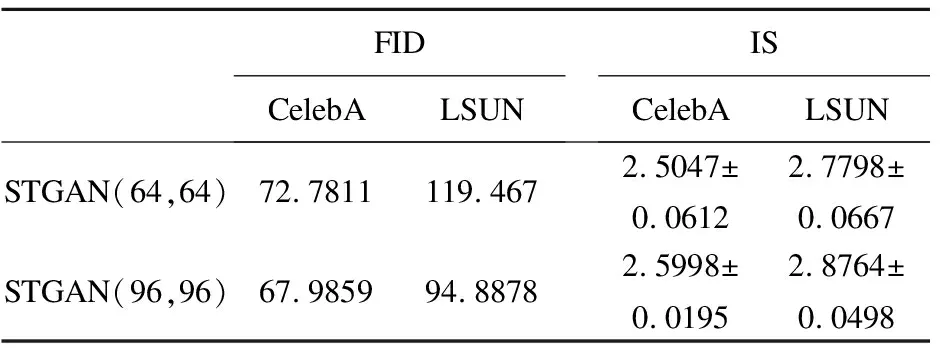
表3 模型输入大小消融实验结果Table 3 Model input size ablation experimental results
3.4 实验结果和分析
本实验使用的STGAN模型、原始GAN模型、Wasserstein GAN(WGAN)[22]模型以及Self-Attention Generative Adversarial Networks(SAGAN)[23]模型参数量如表4所示,原始GAN和WGAN模型参数一样,却别在于损失函数不同;STGAN模型的生成器和判别器参数量基本上相等,在一定程度上平衡了二者的学习性能.

表4 模型参数量Table 4 Amount of model parameters
3.4.1 CelebA数据集上的实验
在人脸生成任务中最常用的就是CelebA数据集,该数据集的图片尺寸是178×218像素,在本实验中先将每张图片经过中心裁剪之后再调整到64×64的大小,数据集的202599张照片全部用做训练集.
为了进一步验证本文提出模型的有效性,将STGAN模型与原始GAN模型、WGAN模型以及SAGAN模型在CelebA数据集进行对比实验.Batchsize大小为256,初始学习率为0.0001,模型迭代100个周期,将近80000次,时间各约12小时,使用Tensorboard工具对判别器损失值进行可视化,如图9所示,上面的曲线为SAGAN模型,下面的曲线STGAN模型,横轴表示迭代次数,纵轴表示损失值大小.为了更清楚观察损失值的整体变化趋势,对损失值做了平滑处理.可以清晰地看出,STGAN的损失值比SAGAN下降快并且最终稳定在0.06,比SAGAN损失值低了0.01.证明了在判别器中引入Swin Transformer机制可以加快模型收敛速度,降低判别器的损失.
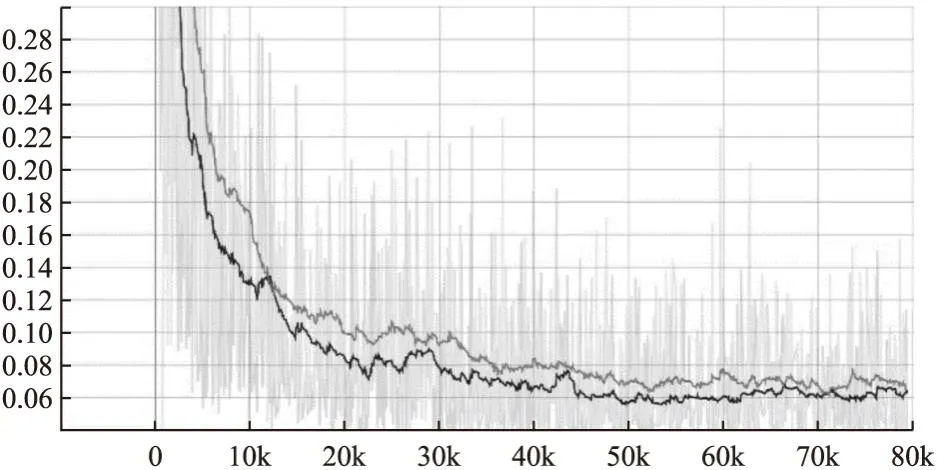
图9 CelebA数据集上SAGAN和STGAN的判别器损失变化图Fig.9 Variation graph of discriminator losses for SAGAN and STGAN on the CelebA dataset
图10展示的是STGAN模型在CelebA数据集上训练轮数分别为0,20,40,60,80,100所生成的人脸图像.训练轮数为0时,图像含有大量噪声,图像模糊,只能看出人脸的大概轮廓;当训练轮数为20和40时,出现图像扭曲,人脸左右不对称等问题,但图像比上一阶段清晰;当训练轮数达到60和80时,图像质量优于上一阶段,只有少数图像出现扭曲的问题;当训练次数达到100时,生成图质量清晰,种类不同.从整个训练过程生成图像可以看出,本文提出的STGAN模型生成图像的质量一直在提升,最终生成了高质量多种类的人脸图像,并且没有出现梯度消失,模式坍塌等问题.

图10 STGAN在CelebA数据集上不同训练轮数生成的图像Fig.10 Images generated by STGAN on the CelebA dataset with different number of training rounds
表5列出了STGAN模型、原始GAN模型、WGAN模型以及SAGAN模型在CelebA数据集上进行测试所取得的评估结果对比.结果表明,本文提出的STGAN模型IS值比原始GAN高了0.1925,比SAGAN模型高了0.0941,分别提高了8.3%和3.9%;其FID值比原始GAN模型低了21.0211,比SAGAN模型低了2.5266;相比之下,STGAN生成的图像质量更好,生成的图片和真实图片相似程度更高.

表5 CelebA数据集上不同模型的FID值和IS值Table 5 FID values and IS values for different models on the CelebA dataset
3.4.2 LSUN数据集上的实验
本实验使用LSUN数据集中教堂类别的数据进行训练,其中包括126227个训练图片和300个验证图片.该数据集图片尺寸大小不一,无法适应固定输入的网络,因此在加载图片时先对每张图片进行中心裁剪,尺寸为240×240,之后再调整到64×64的大小.
为了进一步验证本文提出模型的有效性,将STGAN模型与原始GAN模型、WGAN模型以及SAGAN模型在LSUN数据集进行对比实验.Batchsize大小为256,初始学习率为0.0001,在模型迭代100个周期将近50000次之后判别器的损失变化如图11所示,上面的曲线为SAGAN模型,下面的曲线为STGAN模型,为了更清楚观察损失值的整体变化趋势,对损失值做了平滑处理.可以清晰地看出,STGAN的损失值比SAGAN下降快,最终稳定在0.08,而SAGAN模型损失稳定在0.1.这个实验证明了将Swin-Transformer引入判别器中可以有效地降低判别损失、提高判别器的能力,从而对生成器产生更好的反馈.

图11 LSUN数据集上SAGAN和STGAN的判别器损失变化图Fig.11 Variation graph of discriminator losses for SAGAN and STGAN on the LSUN dataset
图12展示的是STGAN模型在LSUN数据集的教堂类别图像上训练轮数分别为0,20,40,60,80,100所生成的教堂图像.从整个训练过程可以看出,生成图片由模糊逐渐变得清晰,由残缺变得完整,经过100次训练后可以生成多种不同风格且清晰的教堂图片.由此可以说明,模型可以稳定的训练,并且没有出现模式坍塌、梯度消失、不收敛等问题.

图12 STGAN在LSUN数据集上不同训练轮数生成的图像Fig.12 Images generated by STGAN on the LSUN dataset with different number of training rounds
表6列出了STGAN模型、原始GAN模型、WGAN模型以及SAGAN模型在LSUN数据集上进行测试所取得的评估结果对比.结果表明,在LSUN数据集上WGAN模型性能最差;本文提出的STGAN模型IS值比原始GAN高了0.32,比SAGAN模型高了0.0343,分别提高了13%和1.24%,生成的图像质量更好;其FID值比原始GAN低了17.016,比SAGAN模型低了5.4476,生成的图片和真实图片相似程度更高.

表6 LSUN数据集上不同模型的FID值和IS值Table 6 FID values and IS values for different models on the LSUN dataset
通过在CelebA和LSUN数据集上分别与原始GAN、WGAN以及SAGAN模型进行对比实验,从实验结果可以看出,在两个完全不同的数据集上STGAN模型的性能都优于其它对比模型,生成的图片都具有非常高的自然度和逼真度,充分证明了本文提出的STGAN模型的有效性.
4 总结与展望
本文提出了一种基于Swin Transformer生成对抗网络的图像生成方法——STGAN.通过将Swin Transformer机制引入到判别器,不断地调整每一层感受野的大小来产生分层特征图,在减少计算量的同时增强判别器的判别能力.此外,为了平衡生成器和判别器的性能,将自注意力机制引入生成器并使用谱范数规范化,提高生成器的性能,从而提高生成图像的质量.通过在CelebA数据集和LSUN数据集上与SAGAN等模型的实验对比,表明STGAN模型的训练稳定性和生成图像的质量都有所提高.但本文依然存在生成图像的分辨率较小的问题,下一步需要对模型继续进行改进,以生成更高分辨率的图像.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
小雪花·成长指南(2022年1期)2022-04-09
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
新课程学习·中(2013年3期)2013-06-14
汽车与新动力(2012年1期)2012-03-25
