
基于机器学习的煤层气产能标定智能算法及影响因素分析
2024-03-07 14:08宋洪庆都书一杨焦生王玫珠张继东朱经纬
工程科学学报 2024年4期
宋洪庆,都书一,杨焦生,王玫珠,赵 洋,张继东,朱经纬
1) 北京科技大学土木与资源工程学院,北京 100083 2) 大数据分析与计算技术国家地方联合工程实验室,北京 100190 3) 中国石油勘探开发研究院,北京 100083
煤层气是一种重要的非常规能源. 高效开发利用煤层气不仅可以提高煤炭资源回收率,而且可以缓解煤矿开采中存在的大量安全问题,带来巨大的经济效益和社会效益[1]. 煤层气产能是开采现场的一个关键参数,是评价一个煤层气区块开采潜力的重要指标,而单井产能标定是对每口井的最大产气能力进行科学地评估[2]. 世界范围内,众多学者开展了煤层气产能的相关研究. Guo 等[3]基于自行研制的实验装置,在设计的渗透率和压力组合下,对煤层气联产进行了物理模拟,为煤层气叠加体系的高效开发提供理论和技术支持. 郭肖等[4]针对多煤层气储层中的多尺度、多区域、多介质复杂流动问题,建立了多煤层气藏全过程气-水两相耦合流动模型,采用数值方法对耦合模型进行求解,建立了多煤层气藏层系划分流程和判定准则. 郭广山等[5]为揭示影响相邻煤层气井组以及同一井组间产能差异控制因素,探讨了产能类型,日产气均值和日产水均值等参数的差异性,并从地质控制因素、工程工艺控制因素和排除管理因素出发,详细剖析了资源条件、井身质量、压裂工艺等对煤层气产量的控制作用,为煤层气井产量控制因素分析提供了理论依据. Stopa 与Mikołajczak[6]考虑煤层气地层中气水两相流过程,提出了一种新的煤层气储层两相流动数学模型,并基于生产数据进行历史拟合,结果表明,该模型可作为煤层气两相产能预测的有效工具. 绝大多数传统煤层气井产能研究,或通过繁琐的理论推导,或采用复杂的数值模拟,且大都给出了一定的简化、限制条件,对于煤层气开发具有相应的参考价值,但难以广泛适用于煤层气开采现场.
近年来,人工智能已呈现井喷式发展[7],且在石油行业中的应用越来越多[8-9]. Wang 等[10]通过建立深度神经网络,并利用Xavier 初始化、Dropout 技术和Sobol 分析等方法,对页岩油累产量进行了预测并研究了各影响参数的重要性. Du 等[11]提出了一种利用机器学习评价油田井间连通性的方法,通过建立三维卷积神经网络,结合动态生产数据反演井间连通性,为常规油藏和非常规油藏的二次开发提供了有效的指导. Meng 等[12]使用了人工神经网络、随机森林(Random forest, RF)、支持向量机和极端梯度增强四种流行的机器学习算法,对页岩气吸附进行了预测. Song 等[13]采用数值模拟技术获取所需数据集,并利用多种机器学习方法预测储层垂向非均质性,结果表明,机器学习方法在非均质性预测方面表现优异. Hu 等[14]采用灰色关联分析和BP 神经网络的方法,对煤层气井压裂产量进行了预测及评价. Anifowose 等[15]利用多种机器学习技术并采用两种地震测井综合数据预测了油藏渗透率. 由此可见,油气行业众多问题可以利用AI 技术有效解决,然而,就作者所了解到的而言,基于机器学习方法并利用煤层气实际监测参数进行产能标定的研究仍有欠缺.
本文基于我国山西沁水盆地某区块煤层气井的实际静态储层数据与动态生产数据,结合现场开采经验,提出基于生产井史的煤层气井产能计算公式;通过产能计算公式计算煤层气单井产能,并与相应井的地质、生产、特征数据形成机器学习数据集;利用100 口煤层气井完整的数据集,建立深度神经网络(DNN)、支持向量机(SVR)以及随机森林模型(RF)三种机器学习智能算法进行训练,预测煤层气单井产能并分析不同排采天数的生产数据对标定产能准确性的影响,比较三种机器学习模型的预测结果;最后利用预测决定系数最高的DNN 模型及敏感性分析方法,分析了排采前期的动态参数和静态参数对产能的重要性程度.本文提供了一种适用于尚处于开采前期煤层气井的产能标定机器学习方法.
1 数据选取与处理
1.1 煤层气井数据的选取
沁水盆地某区块地处山西省东南部,横跨临汾、晋城两市,是我国沁水煤层气田重点开发区块之一. 本文采用该区块下100 口压裂直井的实际静态储层数据和动态生产数据用于分析研究,其井位分布如图1 所示. 其中,储层数据包括:井位坐标、煤层埋深、孔隙度、测井渗透率、压后渗透率、煤层厚度、含气量、地层压力以及见气时间,共8 个参数. 地质条件的优劣在一定程度上决定着煤层气井产能的大小,其数据隐含了煤层气井产能的信息[16-17]. 选取的储层数据中包含了测井渗透率与压后渗透率,通过压裂前后渗透率的变化,可以在一定程度上反映压裂施工对煤层气井产能的影响. 本文选取的100 口煤层气井孔隙度和测井渗透率较低,压裂效果明显,埋深较浅、煤层厚度大、含气量较高.

图1 100 口煤层气井井位分布Fig.1 Well location distribution of 100 CBM wells
煤层气不同于常规天然气,其在煤层中的储集主要依赖于吸附作用[18],其开采需经历解吸过程. 开采初期通常要进行排水降压,当储层内部的压力低于解吸压力时,甲烷气从煤表面解吸出来,通过扩散进入割理裂缝形成气泡,最终渗流流入井筒完成开采[19]. 因此,煤层气解吸—扩散—渗流过程直接影响着煤层气井的产量,提取这一过程的数据特征对于分析煤层气井产能有着重要的影响,但实际这一过程中的参数,如解吸压力,往往不易获得. 动态产气、产水及压力数据包含了煤层气解吸—扩散—渗流的动态特征[20-22]. 在煤层气相关研究中,已有学者将产气、产水及压力等数据共同作为AI 模型的输入,实现产量的高精度预测[23-25].另外,Xu 等[26]基于多元长短时记忆神经网络(MLSTM NN)模型预测煤层气产量时,证实了加入产水和压力作为辅助输入数据的预测准确率比仅使用历史产气量作为输入的模型精度高. 因此,本文选取了3 个开采现场日常监测的动态生产数据:日产气、日产水和井底流压,用来引入煤层气解吸—扩散—渗流信息. 本文选取的100 口煤层气井,每口井已开采时间为8 a 左右. 详细的静动态数据信息如表1 所示.

表1 100 口煤层气井静动态数据Table 1 Static and dynamic data of 100 CBM wells
1.2 数据的清洗与归一化
开采现场记录的数据存在误差,人为采取某些措施(如停机检修、气量调整等)也会导致煤层气井相关动态数据产生奇异点,为数据引入噪声. 如图2 所示,66 号井在第2172 d 的产气量高达2577 m3,但并不符合该井产气曲线的生产趋势. 因此,对数据奇异点进行清理对于后续数据特征提取是必要的. 本文通过计算该动态数据点与全部动态数据算数平均值之比来定义异常比值系数,并根据油藏专家经验设定阈值,清洗相应动态数据. 对于某口煤层气井,定义:

图2 66 号煤层气井产气曲线与奇异点分布Fig.2 Gas production curve and singularity distribution for CBM well 66
其中, ε为比值系数;为第n个动态数据第i天的值;为该井第n个动态数据所有天的平均值. 本文采用的动态数据包括日产气、日产水及井底流压. 结合开采现场专家经验,设定日产气的阈值为2.5,即若某天的产气量大于该井日产气均值的2.5 倍,则该天的产气量将被视为奇异值清洗掉.考虑到煤层气开井排水降压的物理过程,前期井底流压及产水量较高符合物理规律,又由于该区块煤层气井最晚见气时间约为270 d,本文选定对见气后稳定三个月,即排采365 d 后的日产水与井底流压奇异值进行清洗,设定阈值为10.
数据的归一化处理可以消除数据之间的量纲影响,同时可以提升模型训练时的收敛速度和精度[27],因此本文采用最大最小标准化对数据进行归一化处理. 对于第k个参数进行归一化处理,公式为:
其中,Tk为参数T中第k个参数的原始数据,为对应Tk归一化后的数据,Tmin和Tmax分别为参数Tk数据序列中的最小值和最大值.
1.3 机器学习数据集
煤层气产能受到地质参数、工程施工、生产制度控制、现场管理等众多因素的影响,但所有影响最终都会反映到产气量、井底流压等生产监测数据上. 井的日产气曲线能直接体现井的产气特征[28],井底流压也是包含产能信息的重要参数[29]. 另外,已有研究表明流压降低速率的快慢对于煤层气产能具有影响[30]. 本文结合以上考虑及现场经验,提出了基于生产井史的煤层气单井产能计算公式.公式为:
其中,Q为单井产能值,m3·d-1;N为天数,取值为该井的稳产期天数;为该井日产气量降序排列前N天的日产气平均值,m3·d-1;Pe为地层压力,MPa;Pc为该井的临界解吸压力,MPa; β为区块流压降速,表征一个区块正常生产过程中的流压降低速率,MPa·d-1,其值由开采现场给定.
本文机器学习模型的输出为煤层气单井产能,由公式(3)计算得到. 输入数据包括储层数据、生产数据与特征数据. 储层数据为井位坐标、煤层埋深、孔隙度、测井渗透率、压后渗透率、煤层厚度以及含气量,生产数据包括排采前期的日产气、日产水和井底流压数据. 生产数据是动态的,因此需要考虑输入排采前期多长时间的数据. 本文考虑开井后365、730、1000 以及1365 d 四个时间点分别进行探究. 特征数据为排采前期天数的日产气均值、日产水均值以及井底流压均值,用来表征生产数据的影响. 由此形成的四个机器学习数据集分别命名为数据集a、数据集b、数据集c 和数据集d. 四个数据集划分训练集和测试集的比例都是9:1,整体工作流程如图3 所示.

图3 整体工作流程图Fig.3 Overall workflow
2 机器学习模型
2.1 深度神经网络
深度神经网络(Deep neural network, DNN)是多层感知器结构,包括输入层、隐藏层以及输出层,其利用节点之间的相互连接进行信号的传输,信号传输过程中权重与阈值的调整则由误差反向传播算法进行优化. 误差反向传播算法在网络前馈传播的基础上,计算预测结果与真实结果之间的误差值,然后从最后一层到第一层反向传播该误差进行网络的权值与阈值调整.
对于一个M维输入、H维输出的K层深度神经网络,其前馈计算过程为[31]:
网络输入:
输入层:
隐藏层:
输出层:
网络输出:
其中,a(l)表示l层神经元的输入信号;W(l)表示l-1层到l层的权值矩阵;b(l)表示l层网络阈值;z(l)表示l层神经元的状态;fl(·)表示l层神经元的激活函数,yH表示第H个输出参数.
前馈过程完成后,计算网络前馈输出结果与真实结果之间的误差值J(W,b),并采用优化算法,如梯度下降算法(式(11~12)),优化神经网络权重值与阈值,使目标函数J(W,b)最小化.
其中,W(l)和为网络更新前后l-1层到l层的权值矩阵;b(l)和为更新前后l层网络阈值; α为参数的学习率.
为了充分提取生产数据包含的煤层气解吸—扩散—渗流过程信息,本文首先利用三个神经网络分别拟合产气、产水、井底流压,之后再与7 个储层数据以及3 个特征数据相结合,最终输出该煤层气井产能,网络结构如图4 所示.
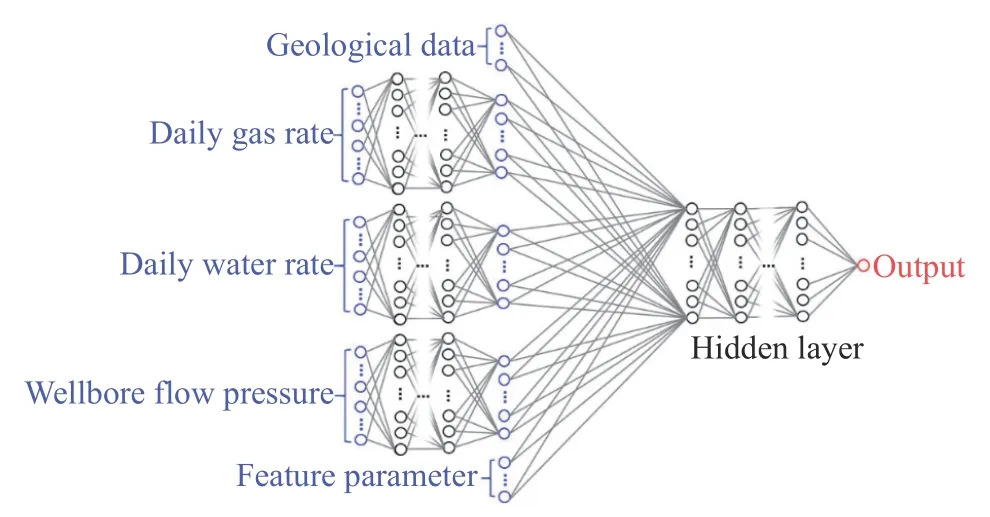
图4 深度神经网络结构Fig.4 Structure of the deep neural network
相较于传统的神经网络结构模型,该新模型创新性地将地质参数和特征参数作为输入层加入到神经网络结构模型中从而增加模型的泛化能力和对复杂实际地质环境的预测能力;同时,由于传统产量数据和地质参数数据量的巨大差异,会导致数据体结构的维度不一致的问题从而降低模型的预测精度,因此本神经网络结构模型通过动态数据提取,智能地将动态数据和静态数据维度保持一致,从而提高了深度神经网络的泛化能力和预测精度.
2.2 支持向量回归机
支持向量机(Support vector machine, SVM)是以统计学理论为基础的有监督学习算法,由Vladimir N.Vapnik 在1963 年提出[32]. 支持向量回归机(Support vector regression, SVR)是SVM 应用于回归问题的拓展,适合解决小样本、非线性和高维度数问题.SVR 的基本思想是构造一个最优超平面,使得数据集样本到该最优超平面的距离误差最小.
对于给定的训练集数据:
其中,xi为训练集中第i个输入数据,yi为第i个输出数据,R 为实数集. 若为线性回归问题,则基于训练集寻找超平面(ω,b):
使得f(x)与y尽可能地接近,式中, ω 和b为待定参数. 支持向量回归机容忍f(x) 与y之间最多有|ϕ|的偏差,即当且仅当f(x) 与y的距离大于 φ时才计算损失,形成了f(x)为中心,宽度为 2φ的隔离带.第i个样本点的损失值计算公式为:
其中,C为惩罚因子. 通过构建拉格朗日函数,并根据对偶原理、卡罗需-库恩-塔克条件(KKT)条件可得
2.3 随机森林
随机森林是在以决策树为基学习器并使用Bagging 集成的基础上,引入随机属性选择的集成学习算法,其既可以用于分类问题又可以用于回归问题[34]. 随机森林为使集成中的E个基学习器尽可能地相互独立,采用自助采样法(Bootstrap sampling)在原始数据集中随机有回放地采取E个数据子集,并用单个数据子集独立地训练一个基学习器,最后将E个基学习器集成. 通过自助采样法训练的基学习器可能见到一些数据多次,另一些数据可能一次也没有见到[35],未使用过的数据在后续的训练过程中可用作验证集以评估随机森林的泛化能力. 因此随机森林在做预测时会有较强的稳定性. 另外,随机森林在属性选择时,会在当前结点的d个属性中随机选择一个包含k(1 ≤k≤d)个属性的子集,然后再从这个属性子集中选择一个最优属性用于划分[36]. 这可能使得基学习器之间的差异性进一步增大,以增强随机森林的泛化能力.
当随机森林解决回归问题时,常采用简单平均法获得最终的输出结果:
其中,H(x)为随机森林输出数据,E为基学习器个数,hi(x)为第i个基学习器的输出数据.
2.4 评价指标
本文选取决定系数(Rsquared,R2)、平均绝对误差(Mean absolute error, MAE)、均方根误差(Root mean square error, RMSE)三个指标来评价机器学习模型预测结果的准确性.
其中,U为数据集总样本数,为数据集中第i个样本点的真实值,为机器学习模型对第i个样本点的预测值,为所有的平均值.
3 结果分析与讨论
3.1 单井产能计算公式准确性评估
由于开采条件复杂及工程施工等原因,煤层气实际的产气曲线并不总是可以较为明确地划分出产量上升、稳产和产量递减阶段. 因此,本文对100 口井的稳产期进行整体衡量,确定该区块煤层气井的平均稳产期为1000 d,即每口井的稳产期天数N都取值为1000 d. 另外,本文选取的煤层气井所在区块的区块流压降速 β为0.01 MPa·d-1.
本文以煤层气井产气曲线上最大日产气量为标准并定义波动系数来评估单井产能计算公式的准确性. 公式为:
其中, λ为波动系数;Zlabel为单井产能计算公式计算值,MPa·d-1;Zprod为该井最大日产气量,MPa·d-1.若计算值与最大日产气量越接近,则波动系数 λ越趋于0. 本文选取的100 口煤层气井的波动系数分布如图5 所示,图中两条黑色实线标出了±25%范围,红色方形点代表落在±25%范围内的井,蓝色菱形点代表落在±25%范围外的井. 可以看出,100口煤层气井的波动系数围绕在黑色虚线λ=0上下,绝大部分井的波动系数在±25%范围内.
各波动系数分布范围的井数及其所占百分比如表2 所示. 可以看出,±10%范围内的井有43 口,即40%以上的井的波动系数位于区间[-0.1,0.1]内;分别有72%和84%的井的波动系数在±20%及±25%范围内,只有16 口井的波动系数离λ=0较远,分布在±25%范围外. 因此,基于生产井史的单井产能计算公式能够较高精度地计算该区块已开采时间较长的煤层气井产能.
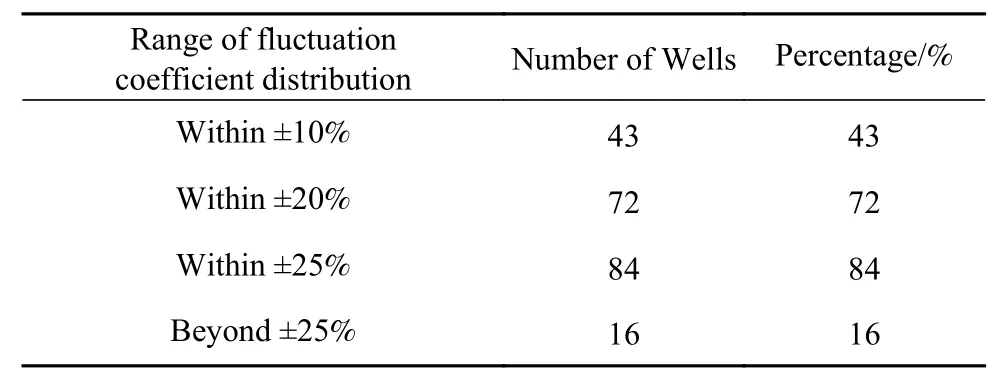
表2 波动系数分布范围及井数占比Table 2 Range of fluctuation coefficient distribution and percentage of wells
3.2 产能值预测结果分析
神经网络模型中隐藏层神经元个数对模型的最终预测效果有着重要的影响[37],考虑到储层数据与特征数据的数量级,用来拟合产气、产水、井底流压的三个神经网络输出单元数都选为10. 此外,神经网络模型训练迭代次数为200,学习率为10-4,批尺寸(Batch size)为11;支持向量回归机的核函数为RBF,惩罚系数为9.6;随机森林的树个数(Number of trees)为37,最大特征(Max feature)为50.
三种机器学习模型分别使用数据集a、数据集b、数据集c 和数据集d 训练后,测试的结果如图6 所示,图中平均R2为DNN、SVR 和RF 模型在测试时的R2平均值. 可以看出,使用数据集a 训练的模型在预测时效果较差,较多的点远离y=x线,三种机器学习模型的平均R2值仅有0.196,不能准确标定煤层气单井产能. 使用数据集b 训练的模型在测试时有了较大的提升,平均R2值提升到了0.688,但预测准确度仍然较低. 当使用数据集c 训练机器学习模型时,大部分煤层气井开始逐渐进入稳产期,生产数据包含了煤层气井排采前期较为完整的解吸—扩散—渗流特征,训练好的机器学习模型预测决定系数较高,三种模型预测平均R2值为0.828. 进一步增大生产数据的排采天数,可以看出,三种模型的平均决定系数增加到了0.873.

图6 机器学习模型在四类数据集上的预测结果. (a)数据集a;(b)数据集b;(c)数据集c;(d)数据集dFig.6 Prediction results of machine learning models on four datasets: (a) Dataset a; (b) Dataset b; (c) Dataset c; (d) Dataset d
三种机器学习模型的平均R2值随不同排采天数的生产数据变化如图7 所示,可以看出,从图中a点到b 点,所用时间增加1 a,平均R2值增加了0.492;从b 点到c 点,所用时间增加9 个月,平均R2值增加了0.14. 但从c 点到d 点,所用时间增加1 a,平均R2值仅增加了0.045. 从实际应用上分析,提前一年完成产能标定对于煤层气现场进行项目规划、工程施工等工作有着重要的影响. 因此,应选用数据集c 标定该煤层气区块产能. 另外,从图7中可以看出,4 个点连成的曲线呈对数式增长,前期随着生产数据排采天数的增加,平均R2值增长趋势明显,之后增长趋势减缓并最终趋于平稳.

图7 决定系数变化趋势Fig.7 Rrend of
比较三种机器学习模型在数据集c 上各自的预测效果,测试结果如图8 所示. 可以看出,DNN 模型在测试集上表现出了较好的效果,整体上DNN预测结果更接近于真实值.
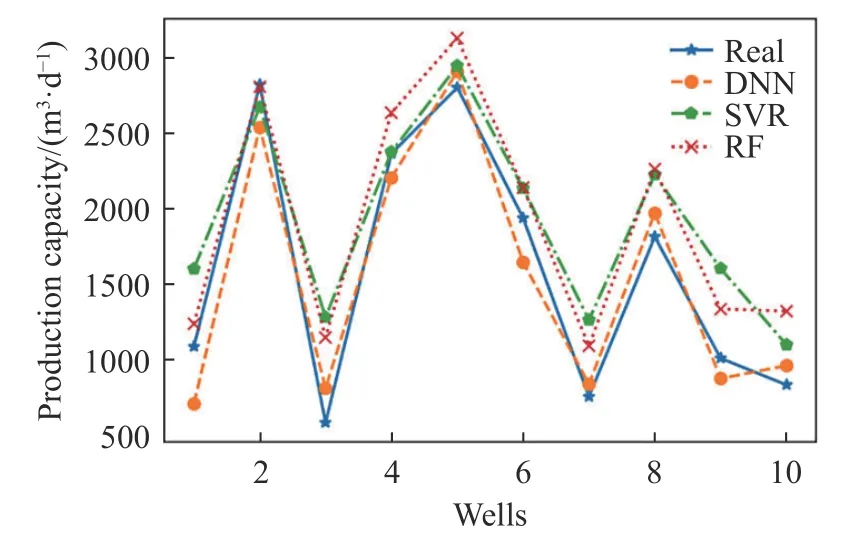
图8 三种机器学习模型在数据集c 上的预测结果Fig.8 Prediction results of three machine learning models on dataset c
定量分析结果如表3 所示. 从R2指标可以看出,DNN、SVR 和RF 模型在测试集上R2值分别为0.923、0.746 和0.816,DNN 模型决定系数均高于SVR 和RF. 另外DNN、SVR 和RF 在测试集上的MAE 值分别为194.44、348.28、311.92 m3·d-1,DNN模型的MAE 值比SVR 模型低了约44.2%,比RF模型低了约37.7%. 最后DNN 模型在测试集上的RMSE 值为214.66 m3·d-1,低于SVR 与RF 在测试集上的RMSE 值.
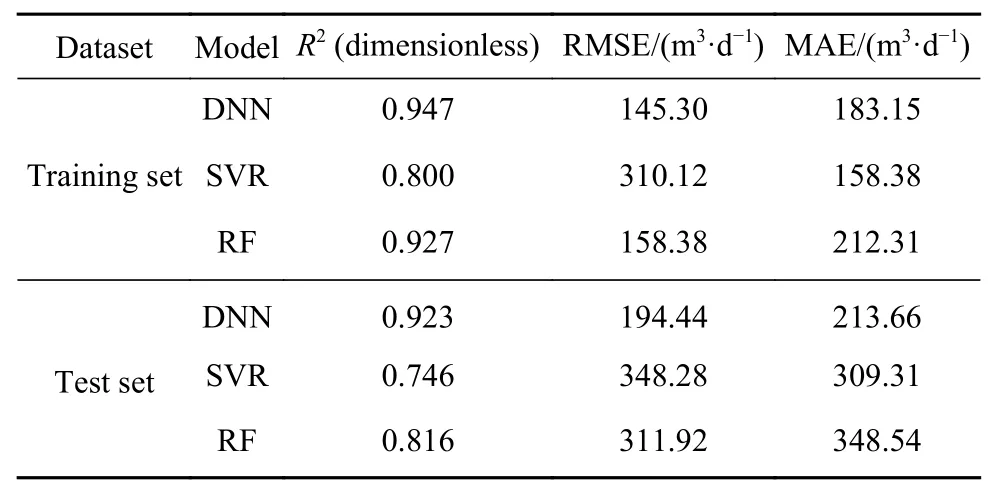
表3 机器学习模型评价指标值Table 3 Metric values of machine learning models
以上三个指标再次说明了:在数据集c 上,DNN能够高精度地预测煤层气产能,RF 次之,SVR 预测效果相对较差. 因为数据集c 输入的生产数据仅为排采前期1000 d,所以本文提供了一种适用于尚处于开采前期的煤层气单井产能标定智能算法.
3.3 产能单因素敏感性分析
在煤层气开采过程中,合理配置各项资源对于确保煤层气产量尤为重要[38]. 因此,探究产能对物理参数的敏感性,对于指导煤层气开发具有重要意义. Sobol 方法可以有效解决高度非线性模型中参数间相互作用引起的灵敏度问题,计算结果相对稳健可靠,是最具代表性的全局敏感性分析方法[39-40]. 因此,本文利用此方法,基于预测决定系数最高的DNN 模型,分析产能影响参数的重要性程度.
Sobol 方法的主要思想是将函数分解成多个递增项之和,通过采样计算参数对模型响应的总方差及各项偏方差,进而求得各参数的灵敏度[40];为探究各物理参数对煤层气产能的重要性,首先需要形成采样数据集. 对于一口煤层气井的采样数据集,本文将该井的井位坐标及生产数据保持不变,储层数据与特征数据在其自身值的1%波动范围内采样. 例如,该井煤层厚度为5 m,则其采样区间为[4.95, 5.05]. 为减小采样随机性对结果的影响,将每口井计算10 次后取算数平均作为该井的最终结果. 另外,本文统一分析产能对渗透率的敏感性,不区分测井渗透率与压后渗透率.
本文选取了6 口煤层气井的计算结果进行展示,其产能对影响参数的单因素敏感性如图9 所示. 图中横轴表示产能影响参数,P1 到P5 为地质参数(煤层埋深、孔隙度、渗透率、煤层厚度、含气量),P6 到P8 为特征参数(排采前期的日产气均值、日产水均值和井底流压均值). 纵轴表示各影响参数的权重值,其值为Sobol 算法计算出的一阶敏感性[41],反映各参数对煤层气井产能的重要性程度. 对于16 号井和37 号井,权重值最大的两项依次为P6(日产气均值)和P7(日产水均值);其次P5(含气量)和P8(井底流压均值)的权重值基本相等;最后,剩余的地质参数中,权重值从高到低依次为P3(渗透率)、P2(孔隙度)、P4(煤层厚度)以及P1(煤层埋深),说明3 个特征参数以及地质参数中的P5(含气量)、P3(渗透率)和P2(孔隙度)对这两口井的产能影响比较大. 对于29、33、40 以及49 号井,3 个特征参数对于产能的重要性程度都高于地质参数,且参数权重值最大的都是P7(日产水均值);地质参数中,29、33 和40 号井参数权重值最大的是P5(含气量),而49 号井参数权重值最大的是P3(渗透率).

图9 煤层气单井产能单因素敏感性Fig.9 Single-factor sensitivity of single CBM well productivity
将100 口井的参数权重值求算数平均,并计算各个参数所占的百分比,用来衡量整个区块产能影响参数的单因素敏感性[42]. 如图10 所示,分析区块参数的敏感性,可以看到,3 个特征参数P7(日产水均值)、P6(日产气均值)、P8(井底流压均值)依次占比17.54%、17.00%、13.91%,说明了产能预测模型对于这三个参数敏感性最高. P6(日产气均值)和P7(日产水均值)所占百分比基本持平且接近20%,说明排采前期日产气和日产水是影响区块产能最关键的两个因素. 另外,煤层气开采过程中,地层压力变化较为缓慢,井底流压在一定程度上反映了开采过程中生产压差的影响. P8(井底流压均值)占比13.91%,说明排采前期生产压差对于煤层气产能的影响比较大. 地质参数中,P5(含气量)、P3(渗透率)、P2(孔隙度)、P4(煤层厚度)以及P1(煤层埋深)依次占比12.72%、12.41%、11.56%、8.4%和6.42%,说明P5(含气量)、P3(渗透率)对煤层气产能的重要性程度较高. 相对而言,P2(孔隙度)、P4(煤层厚度)和P1(煤层埋深)对于煤层气产能影响较小.
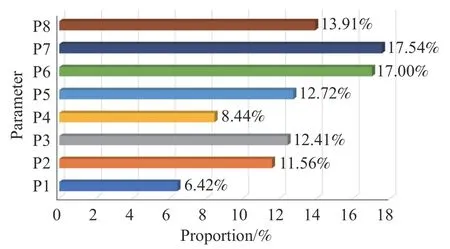
图10 煤层气区块产能单因素敏感性Fig.10 Single-factor sensitivity of CBM block productivity
综上所述,从单个影响参数上看,3 个特征参数对区块产能的重要性占比都高于5 个地质参数,说明单个排采前期动态参数对区块产能的影响大于单个静态参数. 从总体上看,特征参数共占比48.45%,地质参数共占比51.55%,两者分别约占48%和52%,说明排采前期动态参数和静态参数对产能的影响都较强.
3.4 产能双因素敏感性分析
进一步分析影响参数之间的交互作用对煤层气产能的重要性程度. 参数的二阶交互作用表征其共同作用对产能的影响程度,其值为Sobol 算法计算出的二阶敏感性[43],为产能的双因素敏感性.6 口煤层气井的双因素敏感性结果如图11 所示.图中横纵轴都表示产能影响参数,P1 到P8 各自对应的物理参数与单因素敏感性分析时一致. 图中右侧给出了权重指数,若图中小方块颜色越深,则权重指数值越大,表示对应横纵坐标两个影响参数的共同作用对井产能的影响越大. 可以看出,6 口井都是P1(煤层埋深)和P8(井底流压均值)的交互作用对产能影响最大,P3(渗透率)和P8(井底流压均值)的交互作用次之. 对于16、37 和49 号井,P2(孔隙度)和P6(日产气均值)的权重指数比较高,说明两者的交互作用对它们的产能影响较大,而40 号井的产能则对P1(煤层埋深)和P4(煤层厚度)的共同作用以及P5(含气量)和P8(井底流压均值)的共同作用比较敏感. 对于29 号井和33 号井,P1(煤层埋深)和P2(孔隙度)分别对其产能有较为明显的影响.

图11 煤层气单井产能双因素敏感性Fig.11 Two-factor sensitivity of single CBM well productivity
将100 口煤层气井的交互作用权重指数求算数平均,分析如图12 所示的区块产能影响参数的双因素敏感性[44]. 可以看出,对于该煤层气区块,P1(煤层埋深)和P8(井底流压均值)以及P3(渗透率)和P8(井底流压均值)的权重指数分列前两位,表明区块产能对它们的敏感性强. 另外,P2(孔隙度)和P6(日产气均值)的交互作用也对区块产能有较大的影响. 总体上看,地质参数与特征参数之间的交互作用对于煤层气产能影响更大,各地质参数之间或各特征参数之间的影响相对较小.

图12 煤层气区块产能双因素敏感性(P1:煤层埋深;P2:孔隙度;P3:渗透率;P4:煤层厚度;P5:含气量;P6:日产气均值;P7:日产水均值;P8:井底流压均值)Fig.12 Two-factor sensitivity of CBM block productivity (P1: buried depth; P2: porosity; P3: permeability; P4: thickness; P5: gas content;P6: average daily gas production; P7: average daily water production;P8: average bottom hole flow pressure)
4 结论
(1)针对已开采时间较长的煤层气井,基于静态数据中的地层压力与生产数据中的日产气和井底流压,提出了基于生产井史的单井产能计算公式,并以煤层气井产气曲线上最大日产气量为标准衡量计算公式的准确性. 结果表明:100 口煤层气井的波动系数整体围绕在0 周围,43%、72%和84%的井的波动系数分布在±10%、±20%以及±25%范围内,具有较高的计算精度.
(2)建立了基于DNN、SVR 以及RF 的煤层气产能标定智能算法,利用井位坐标、煤层埋深、孔隙度、测井渗透率、压后渗透率、煤层厚度、含气量7 个储层数据,日产气、日产水、井底流压3 个排采前期365、730、1000 以及1365 d 的生产数据以及相应的3 个特征数据拟合了煤层气单井产能,提供了一种适用于尚处于开采前期煤层气井的产能标定智能算法. 结果表明:随着生产数据排采天数的增加,智能算法预测煤层气单井产能的精度呈对数式增长,前期增长趋势明显,之后增长趋势减缓并最终趋于平稳,三种智能算法测试的平均R2值为0.828,其中DNN 模型的决定系数最高,在测试集上达到0.923,MAE、RMSE 分别为194.44 m3·d-1和214.66 m3·d-1.
(3)利用预测决定系数最高的DNN 模型分析了煤层气产能影响参数的敏感性. 结果显示:排采前期日产水均值、日产气均值以及井底流压均值依次占比17.54%、17.00%和13.91%,为影响因素占比最高的3 项;地质参数中占比最高的两项为含气量和渗透率,分别占比12.72%和12.41%;总体上看,特征参数与地质参数分别约占48%和52%.以上结果表明,排采前期的日产气、日产水和生产压差以及含气量和渗透率是影响煤层气产能的重要因素,产能对排采前期的动态参数和静态参数的敏感性都较强.
猜你喜欢
西南石油大学学报(自然科学版)(2019年5期)2019-12-20
意林·全彩Color(2019年8期)2019-11-13
特种油气藏(2019年5期)2019-11-08
中国煤层气(2019年2期)2019-08-27
中国煤层气(2019年2期)2019-08-27
石油知识(2019年1期)2019-02-26
录井工程(2017年3期)2018-01-22
中国煤层气(2017年3期)2017-07-21
领导文萃(2017年10期)2017-06-05
中国煤层气(2015年6期)2015-08-22
