
基于生成对抗网络和迁移学习的电力碳流耦合特征数据生成与评估
2024-03-11 01:27杨至元陈晖李沛
电力建设 2024年3期
杨至元, 陈晖, 李沛
(1. 南方电网能源发展研究院有限责任公司, 广州市 510663;2. 南方电网产业投资集团有限责任公司,广州市 510663)
0 引 言
电力系统碳排放流(以下简称电力碳流)模型是基于电力潮流和碳排放强度表征供电区域碳排放流分布的一种有效计算方法[1-4],作为支撑高质量、高精度以及高时效电碳耦合技术的重要基础,对促进电、碳、绿证、绿电等多市场体系之间的协同发展至关重要[5-11]。但目前通过电力碳流模型关联的耦合特征数据质量有待提升[12-14],能够支撑电碳耦合技术分析和研究的可信数据样本较为不足[15-16],限制了数据驱动的电碳耦合技术发展和应用[17-18]。
当前电力监测数据和碳排放监测数据存在一定程度的质量问题[19-21],具体而言:1)在电能量监测方面,随着电网数智监测和调控技术不断革新,多类型监视和调控设备不断接入电网,对海量、多源异构数据缺乏统一和标准化的处理机制,特别是在发电侧和用户侧的数据质量还需进一步优化[22-24];2)在碳排放监测方面,不同企业、行业的用能工况不同,复杂程度不一,部分行业存在碳监测成本高、灵活性差、覆盖范围有限等问题,未能形成高精度且覆盖多行业的普适性碳排放指标监测方案,难以获得丰富的碳监测数据样本[25-26]。综上,目前电力碳流耦合特征数据存在数据失真、样本不足等问题,不够支撑现阶段电碳耦合技术实现高精细度和高感知度的应用需求[27-28]。
当前基于电力碳流等耦合技术的数据分析和特征建模研究主要集中在电能量数据质量优化[29-30]、典型行业或典型场景下电碳数据建模[31-32]以及多时空维度的电力碳流耦合效应分析等方面[33-34]。针对电碳耦合数据质量的研究较为割裂,大都聚焦在单方面的电力数据建模或是碳排放监测模型优化,缺少综合电力特征和碳排放特征的数据质量优化方法,特别是对电力碳流特征数据的稀缺性研究不够充分[35]。由此,发展综合电力系统特征和碳排放特征的数据采样方法,优化数据质量,是推动电碳耦合技术发展完善的关键要素[36]。
针对上述问题,本文提出了一种基于生成式对抗网络(generative adversarial networks,GAN)理论与电力碳流耦合模型的电力碳流耦合特征数据的模拟生成方法:首先阐述了现阶段电力碳流特征数据的完整性并通过时序电力碳流模型生成了电碳耦合特征数据[37];基于生成对抗网络在数据生成和数据质量优化方面的优势[38-40],结合电力碳流数据样本的现状,建立了电力碳流关联要素的GAN框架训练模型。但由于GAN本质是极小极大博弈问题,深度神经网络(deep neural networks,DNN)在训练电力碳流耦合特征数据过程中容易出现模型坍缩、梯度消失等情况,直接影响GAN对目标任务的学习效果。对此,本文在GAN框架中引入了迁移学习(transfer learning,TL)模块,在小样本中对GAN框架中的部分参数进行预训练,建立了生成式对抗迁移(GAN-TL)模型[41],优化GAN模型的收敛曲线和学习效能;并提出了基于电力碳流计算结果的GAN-TL有效性评估方法,从定性描述和定量分析两个方面弥补了GAN-TL验证机制缺失的弊端,提高生成式网络在特征数据建模方面的适用性。
本文研究是对电碳耦合特征分析和建模研究的重要补充,针对现阶段可信样本不足的问题提出基于GAN-TL的电力碳流耦合特征生成和评估方法,并在IEEE 14节点和118节点系统中进行验证,通过与变分自编码器(variational autoencoder,VAE)[42]训练结果进行比对分析,校验GAN-TL模型在电力碳流数据生成方面的适用性和有效性,同时对训练模型中的不确定性和局限性进行了阐述,并提出下一步研究计划。
本文的创新点主要包括以下几点:1)将电力系统状态参数和碳排放参数作为生成式框架的训练样本,实现电力碳流耦合关系的智能拟合;2)基于生成式框架和迁移学习模型提出电力碳流耦合特征数据的生成和评估方法;3)通过对比其他生成式模型,验证GAN-TL模型在电力碳流数据生成领域的有效性。
1 时序电力碳流耦合特征的数据质量分析
电力碳流计算的本质是将系统内各发电机组的碳排放指标依照电力潮流计算结果按计算比例均衡分布在电力系统的节点和支路上,以此评估电力系统支路、节点以及负荷的碳指标分布情况[2]。这里给出电力系统时序电力碳流特征的分析模型:
[CS,t,CB,t,CL,t,CG,t]=M(EG,t,PFS,G,L,B,t)
(1)
式中:s∈S为系统节点参数集合;B为系统支路参数集合;L为系统负荷参数集合;G为系统机组参数集合;t∈T表示时序参数;C表示碳流相关特征向量;CS,t、CB,t、CL,t、CG,t分别表示t时刻的节点碳势、支路碳流、负荷碳流以及机组注入碳流;EG,t为t时刻机组碳排放强度;等式右侧PFS,G,L,B,t为电力潮流计算模型,输出为潮流的断面信息;M(·)为时序电力碳流计算框架。
图1给出了理想情况和实际情况下电力碳流数据的差异分析。
在理想环境中,电力系统参数以及各机组的碳排放强度均假设为已知且准确的。由式(1)可知,在给定当前时刻的电力运行参数和各个机组的碳排放强度时,可以直接计算得到高精度、高时效性的电力碳流特征数据。然而在实际场景中,情况却不尽然:一方面,碳核算周期与统计周期无法保证完全一致,无法及时获取部分机组的碳排放强度数据,此时电力碳流特征数据即为缺失状态;另一方面,电力新兴业务种类繁多,发展环境、发展阶段不一,运营平台以及支撑技术等均存在不同程度的差异,监测和统计结果极有可能存在误差,而且新能源机组的建设周期远小于传统能源机组,无法有效保证统计周期内监测结果的准确性。
例如,对于第nt条时序数据,极有可能在统计间隔期间新增了部分新能源的投产并网,由此导致发电机机组集合G出现了统计误差。目前可获取的电碳数据极有可能存在误差和缺值,能够用于电碳耦合技术研究的可信样本容量不足[31]。开展基于有限可信样本生成其他可信样本的数据采样方法对现阶段电力碳流耦合特征分析和建模具有重要现实意义。
2 基于生成对抗网络框架与迁移学习的电碳耦合特征生成及验证
为了更好解决电力碳流耦合特征数据的可信样本不足问题,优化数据质量,本节提出基于生成式对抗网络搭建电力碳流特征数据的模拟生成方法,其核心是将电力系统状态参数和碳排放特征作为学习样本导入学习模块,并最终实现时序电力碳流耦合关系的智能拟合。本节就生成模型在训练中存在的梯度消失、收敛特性不稳定等问题增加了迁移学习模块,优化了收敛曲线,并针对生成数据评价机制缺失等问题提出基于电力碳流计算结果的校验方法。
2.1 基于生成对抗网络的电力碳流数据训练模型
GAN最初作为非监督学习框架提出,随后便在图像识别、图像超分辨率转换以及数据增强等方面得到了广泛应用。在近期发布的生成型预训练变换聊天应用(chat generative pre-trained transformer,ChatGPT)中,GAN也成为其视觉分类的核心框架之一[43]。GAN框架由生成器(generator)和判别器(discriminator)两组DNN组成。假定目标任务的训练数据为真实数据,生成器生成“虚假”数据,判别器通过对训练数据和“虚假”数据进行学习,不断提高其分辨能力。生成器和判别器通过零和博弈形式进行竞争,并将其中一个神经网络的损失作为另一个神经网络的收益,最终通过训练迭代实现损失和收益平衡。此时,判别器将无法区分生成数据和训练数据。
假设训练样本y满足分布y~pf,pf由真实数据集组成;生成器G(z;θG)是参数为θG的多层感知机(multilayer perceptron,MLP)组成的DNN,MLP作为一种通用的函数近似方法可以将噪声z映射到新的分布PG;类似地,判别器D[G(z;θG);θD]由参数为θD的MLP组成。判别器可以将生成器的输出xfake映射到[0,1]区间,形成概率输出,从而表征xfake满足pf分布或是PG分布。求解GAN博弈问题的本质是求解生成器和判别器的价值函数:

(2)
式中:E表示样本的分布期望值;令pf和PG在Rn上存在分布μ(x)和κ(x),上述价值函数求解可以改写为:

(3)
在式(3)基础上,选取图1中准确的历史时序电力碳流计算模型中的输入xin和输出xout组成模型的训练集。式(3)中极小极大问题求解可等效为对判别器和生成器的参数训练,如下:
(4)
式中:g(θD)和g(θG)分别表示通过随机梯度下降(stochastic gradient descent,SGD)算法对判别器D参数θD和生成器G参数θG进行更新的计算过程;m为每一次训练选取的样本大小,对第i条样本:
(5)
(6)
其中:
(7)
需要注意的是,尽管理论上GAN模型在Rn上存在最优解,但在实际训练中,由于GAN模型受DNN参数和结构影响明显,GAN的收敛特性极不稳定,特别是生成器的训练就较易出现模型坍缩和梯度消失的情况。这在很大程度上限制了GAN模型的有效性。
2.2 基于对抗网络深度学习框架和迁移学习模型的电碳耦合特征数据的生成方法
为了解决GAN模型在学习中频繁遇到的模型坍缩和梯度消失等问题,本文在GAN中引入了迁移学习模型。迁移学习并不特指一种具体的方法,其模型架构需要依据具体的训练场景进行适配。迁移学习的核心思想是通过转移类似或相关分布中的先验知识来提高目标学习器在目标域上的学习表现,由此减少构建目标学习框架对大量目标域数据的依赖[44]。针对上一节提到的模型收敛问题,其关键是生成器在训练中的梯度消失。所以一个具有先验知识的判别器将极大提高生成器的收敛效率。这里给出基于判别器先验参数传递模型的特征生成算法(discriminator in GAN with transfer learning,DTL),如算法1所示。

算法1:基于DTL的电力碳流特征数据生成框架1输入:Xmin=[x1min,x2min,…],Xmax=[x1max,x2max,…]输出:D∗,G∗,xinfake,xoutfake2选取mc⊆Xmin定义训练世代epochsmin3for e in epochsmin do4g(θT)=θT1|mc|∑|mc|i=1T[mi,θT]5θT←θT-αg(θT)6end7选取mn⊆Xmax定义训练世代epochsmax8θ0D←θ∗T9for e in epochsminepochsmax do10zi=random(Rn)11{g(θD)←θD1|mn|∑|mn|i=1{log[D(ximax)]+log{1-D[G(zi)]}}g(θG)←θG1|mn|∑|mn|i=1log{1-D[G(zi)]}12end13[xinfake,xoutfake]=G∗(zi)
算法中,较少样本的Xmin用于迁移学习,样本较多的Xmax用于生成对抗网络学习的训练;同时给出一个参数为θT的迁移模型T(·),其本质也是由DNN组成的神经网络。TL训练模型如下:
(8)
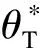
在GAN框架中部署迁移学习模块的操作流程是先将生成器(或判别器)部署在先验样本上进行预训练,使之获得先验知识,之后再将其部署进目标学习任务的GAN网络中,即为GAN-TL。GAN-TL既能很好解决模型生成器坍缩和判别器梯度消失的问题,也可以提高对小样本学习场景的学习效率和效能,同时在有效性上也适配现阶段小样本电力碳流特征数据的建模和分析。
2.3 生成特征校验与分析
目前主流机器学习模型的验证大都是将模型部署在与训练集同分布的测试域中进行验证,这种方法对应用场景较为固定且有明确标签的监督学习比较有效。对于无监督学习模型的验证,学界目前没有统一的框架,一般会采用聚类算法对学习结果进行聚类,生成聚类效果图。对于简单的学习场景,无监督学习效果的好坏可以直接通过专家系统或人工识别来直观判断,也可以通过人工标记的伪标签对学习结果进行校验。
但对于复杂且聚类特征不明显的学习目标,聚类结果并不能反映无监督学习模型的效果,同时也缺乏可以量化训练结果的聚类指标。具体而言,对于无监督学习模型GAN来说,如果原分布pf不具备明显的聚类特征,生成的虚拟分布PG也同样无法获得聚类结果。所以聚类结果并不能作为表征GAN模型的训练好坏。同样地,尽管GAN在图像领域的应用可以通过人工直观辨识来校验学习模型的好坏,但在本文提出的电力碳流GAN-TL模型的校验研究中,直观法并不能作为判断GAN训练结果的标准。


图2 基于GAN-TL框架的电力碳流特征数据的生成及验证框架Fig.2 The Framework of data acquisition from CEF model based on the GAN-TL method
(9)
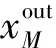
3 算例仿真
3.1 仿真环境
3.1.1 电力系统及碳排放初始仿真设置
本文选取IEEE 14节点系统和118节点系统作为电力系统仿真的测试环境。其中IEEE 14节点系统含有10个负荷节点,4个发电机节点,1个平衡节点,15条传输线路,5条变压器线路,负荷总计259 MW。IEEE 118节点系统含有99个负荷节点,53个发电机节点,1个平衡节点,173条线路,13条变压器线路,负荷总计4 242 MW。电力系统仿真测试软件为开源电力系统仿真包Pandapower,版本为2.11.1[45]。选取Pandapower中CIGRE_15 min新能源出力和负荷测试曲线作为仿真系统中部分发电机和负荷节点的变化曲线,以此模拟测试系统的时序变化,如图3所示。发电机碳排放的核算周期与电力系统的时域分析相比可以近似等效为静态模型,在15 min的时间尺度内变化不大。算例仿真中传统发电机的碳排放模型设置与文献[37]保持一致,按比例系数随机取样,系数取样区间为[1,5]。

图3 CIGRE_15 min时序新能源出力测试曲线Fig.3 The base generation output and load curves of CIGRE_15 mins testing profile
3.1.2 人工智能深度学习框架
本文选取开源人工智能软件库TensorFlow 2.9.1用于搭建GAN-TL框架的深度神经网络模型,通过调用TensorFlow内置集成的Keras应用编译接口(application programming interface,API)实现深度神经网络的模块化搭建。GAN-TL基于CPU训练平台,训练神经网络的硬件参数如下:AMD 6800HS,8核心,基频3.2 GHz,支持16线程扩展;16 GB DDR5 RAM,频率4 800 MHz。
3.2 IEEE 14节点和118节点系统测试结果
3.2.1 IEEE 14节点算例电力碳流特征仿真
在IEEE 14节点算例的迁移学习模块初始化设置中,迁移模块学习率设置为0.003,epochsmin为800,mc=16。训练样本包括系统发电机出力、节点负荷、机组碳排放强度、节点碳势、支路碳流、负荷碳流以及机组碳流,特征维度为137。小样本容量为1 000,深度神经网络中需要传递的参数个数为20 241,设置4线程并行计算。GAN框架中,训练样本容量为5 000,噪声zi的长度为200,学习率设置为0.002,epochsmin为10 000,mn=16。需要训练的神经网络参数共852 361个,设置8线程并行计算。
经比选,DTL的学习效果要优于基于生成器的先验参数传递算法(generator in GAN with transter learning, GTL)。完成训练后,由式(6)可以生成1 000条生成数据,并经式(9)校验矩阵校核。学习结果如图4、5所示。图4和图5展示了部分线路和节点的电力碳流特征学习结果。在生成的1 000个样本中,极个别样本的线路和节点数据的准确率出现异常,如图中红色方框所示。生成器一共新生成14 000个节点碳势数据,准确率在90%以上的碳势结果占比为89.93%,准确率在95%以上的碳势结果占比为62.62%;在新生成的20 000个碳流密度数据中,准确率在90%以上的碳流密度占比约83.98%;在新生成的14 000个负荷碳流和机组注入碳流结果中,准确率在90%以上的负荷碳流占比约79.11%;准确率在90%以上的机组注入碳流超过85%,如图4中的紫色虚框所示;准确率在95%以上的数据占比为83.49%。

图4 IEEE 14节点系统的支路碳流密度特征的误差结果Fig.4 The rate of errors of branch carbon emission flow intensity in the IEEE 14 bus system
3.2.2 IEEE 118节点算例电力碳流特征仿真
在IEEE 118节点算例的迁移学习模块初始化设置中,迁移样本容量为1 000,迁移模块学习率设置为0.000 2,epochsmin为1 000,mc=64。118节点系统的训练样本包括系统发电机出力、节点负荷、机组碳排放强度、节点碳势、支路碳流、负荷碳流以及机组注入碳流,特征维度为1 237。深度神经网络中需要传递的参数个数为3 367 937,设置4线程并行计算。在目标任务的GAN框架中,训练样本容量为5 000,噪声长度为1 200,学习率设置区间为[0.000 8,0.001 5],epochsmax设置为[10 000,15 000],mn取64。需要训练的神经网络参数共计3 497 997个,设置8线程并行计算。DTL和GTL的训练过程如图6所示。图6一共展示了3组不同GAN-TL模型和1组基础架构的GAN模型的训练过程。为排除其他因素干扰,3组GAN-TL模型仅学习率上做了差异化处理,其他参数保持一致,以展示各模型训练对参数的灵敏性和响应程度,其中2组GTL模型分别设置了0.000 8和0.001的学习率,DTL和GAN基础模型均设置为0.001的学习率。

图6 IEEE 118节点系统在不同训练参数下的收敛情况展示Fig.6 The converge results of GAN-TL models based on diverse settings using the IEEE 118 bus system
由图6可知,红色和深紫色折线显示基础GAN模型的生成器损失和判别器损失均存在极大的不稳定性;浅紫色和蓝色的折线为2组GTL的生成器损失曲线,epochs在2 000~3 000和8 000~9 000时GTL存在成大幅波动成器损失和判别器损失均存在极大的不稳定性;浅紫色和蓝色的折线为2组GTL的生器损失曲线,epochs在2 000~3 000和8 000~9 000时GTL存在大幅波动,也并没有实现很好的收敛。相较而言,橘色和绿色折线显示的DTL模型在训练中表现较为稳定,在epochs为5 000~6 000时已成功收敛。
进一步地,表1给出了DTL和GTL在IEEE 118节点系统上的对比验证。通过评价指标R可以得到不同参数设置下GAN基础模型与DTL/GTL的量化对比结果。与14节点系统类似,在118节点系统新生成的1 000组电碳特征中,一共生成有功通量数据、节点碳势数据以及机组注入数据共354 000个,新生成碳流密度数据186 000个。对于各个模型的训练结果,按准确率区间对各组特征数据进行分类比较,可以发现在95%以上区间:DTL的占比较GTL的占比在4组维度中平均提高了13.83%,最高提升了29.83%;尽管在注入碳流特征的准确率占比上DTL较GAN下降了约2.66%,但在有功通量特征的准确率占比上提高了37.49%,节点碳势特征的准确率占比提高了37.60%,碳流密度的准确率占比提高了24.62%。对于准确率在90%以上和85%以上的区间,DTL相对GTL/GAN模型分别提升了14.75%/32.26%和12.23%/33.99%。由此可知,DTL相较于GTL和GAN基础模型拥有更快的收敛速度以及更好的模型表达,更适用于算例中的学习场景。算例仿真结论也与2.2小节的直观推理相吻合。

表1 不同参数GAN-TL模型的灵敏性分析和对比验证Table 1 The sensitivity analysis and verifications with diverse parameters settings among the GAN-TL models
图7给出一个直观的展示结果。图中共有3组不同参数设置的DTL模型,2组GTL模型以及1组GAN基础模型作对比验证。每个子图的横坐标表示生成数据的特征空间,纵坐标表示生成的样本数。通过颜色的深浅可以形象表征每组模型生成样本的误差结果。颜色越深,表示该特征越不准确,反之则越准确。通过比对可以发现,GAN模型的颜色最深,模型的误差最大;红色虚框标识的第2组DTL模型生成样本浅色部分最多,模型也最精确。

图7 IEEE 118 节点系统中不同GAN-TL模型的学习校验结果直观展示Fig.7 The intuitive demonstration of verifications on diverse GAN-TL methods in the 118 bus system
3.2.3 GAN-TL模型与其他生成方法的比对分析
为了验证算法在电力碳流数据生成方面的有效性,本节补充了GAN-TL模型与VAE模型的电力碳流数据生成方法的对比验证。VAE是一种基于概率方法的无监督学习模型,由编码器、解码器两组神经网络组成,在图像生成、图像重建、特征学习等方面有着广泛的研究和应用[42]。编码器将输入数据映射为高斯分布,并从该潜在分布中采样得到潜在向量,用于解码器生成新的样本。这种重参数化技巧使得梯度可以反向传播从而实现对神经网络的迭代训练。图8给出了基于VAE框架的电力碳流数据生成和验证方法。

图8 基于VAE框架的电力碳流数据生成和验证Fig.8 Generation and Validation Method of CEF data based on VAE Framework
由图8可知,VAE模型中编码器将训练批次中的训练数据xi映射为由均值μi和方差σi2表征的高斯分布pφ(zi),解码器通过对潜在向量zi取样解码,生成新数据xi′。最后,生成数据和训练数据通过校验矩阵进行电力碳流计算校验。VAE相关训练参数设置如下,编码器和解码器均由卷积神经网络组成,共含有19万个训练参数,潜在空间维度取2,训练样本容量为5 000,设置8线程并行计算。
表2为GAN-TL模型与VAE模型在IEEE 14节点测试算例中的学习结果比对。比对特征包括节点碳势、碳流密度、负荷碳流以及机组注入碳流。表中数据表示在误差矩阵中,误差率为10%以内的生成数据占比,表中的数值越高表示学习结果越准确,反之,学习结果偏差越大。通过对比3种设置不同的VAE模型可知,本文提出的GAN-TL模型对节点碳势和碳流密度的训练效果提升明显,平均提高了21.89%和16.38%,对负荷碳流和注入碳流的训练效果也有小幅度提升,分别为6.38%和0.83%。VAE的训练是将样本的先验分布映射到潜在空间,为防止出现过拟合,训练世代不宜设置过大,这在一定程度上节省了计算资源。

表2 GAN-TL模型与VAE模型的训练结果对比Table 2 The comparison study between GAN-TL model and VAE models
VAE模型中潜在空间的维度和结构较为抽象,编码器对先验分布的映射可能丢失重要的细节,预设的先验正态分布也不适用于分布复杂的数据场景,同时解码器在进行样本重构时需要权衡样本的多样性和准确性。因此,映射过程的不确定性和重构过程的模糊性也会对训练结果造成影响。相较而言,GAN模型的数学原理和结构更为直观,对复杂分布的学习更有优势。
3.2.4 生成模型的讨论与分析
本文提出的基于生成对抗网络和迁移学习的电力碳流耦合特征数据生成和评估方法,本质上为小样本、无监督类型的数据生成任务,其有效性已通过IEEE实例研究以及与VAE模型的比对分析进行了验证。但现阶段的训练模型仍存在以下几点不足:
1)样本的数据质量需进一步提升。结合表1、2以及图7可以发现模型在某类特征上表现出较低的准确率。通过数据解析可以知道,这是因为训练样本中此类特征表达不明显,训练集不足以支撑神经网络参数对此类特征的表达,从而在生成样本中表现出随机性。
2)GAN-TL模型细节尚不完善,仍有优化空间。现阶段,本文并未对已获得源领域知识的TL模型参数的传递过程进行优化,这有可能限制了GAN-TL模型在目标领域的学习增益。
3)协同优化算法尚不明晰。电力碳流数据特征和分布暂不明确,生成模型也缺乏标准的通用算法。在复杂分布的特征提取、生成模型的多样性和准确性权衡博弈等方面,仍需继续探索有效的协同优化算法。
4 结 论
开展基于小样本的电力碳流特征分析和评估研究是现阶段电碳耦合技术的重要研究方向。本文基于GAN-TL框架提出了电力潮流和碳流耦合特征数据的生成式框架,以完善现有的电碳数据库和特征库,从而推进电碳耦合技术向平台化和实用化方向发展。
本文分析阐述了现阶段电力碳流数据的实际质量问题,针对小样本、无监督的电力碳流数据生成任务,提出将电力系统状态参数和碳排放参数作为训练样本,通过GAN-TL模型拟合了电力碳流耦合数据模型的分布特征,经由电力碳流计算框架和校验矩阵直观展示了生成数据的特征表达,同时实现了生成模型的定量评价,通过引入与VAE模型的对比分析,进一步验证了GAN-TL在电力碳流数据生成任务上的有效性。
本文研究目标是提出基于GAN-TL框架生成电力碳流数据的建模和评估方法,为电碳耦合数据质量提升提供新的研究思路。基于研究结果,本文在数据质量、模型构建、协同优化等方面对现阶段生成模型的局限性进行了梳理。后续的研究工作将针对实际任务场景开展必要的数据工程和特征工程,基于典型行业生产、运营环节的电力碳流特点,修正生成式模型的参数和结构,探索优化训练成本的有效方法,增强生成式框架在电碳耦合领域的实用性。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
数学物理学报(2022年2期)2022-04-26
国际眼科杂志(2021年9期)2021-09-15
中学生数理化·高一版(2021年2期)2021-03-19
装备制造技术(2020年2期)2020-12-14
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
大型铸锻件(2015年5期)2015-12-16
中国卫生(2015年12期)2015-11-10
