
基于ISSA-SVM的钻井卡钻事故预测
2024-04-01 05:11陈晓张奇志王鑫黄圣杰陈浩宇
科学技术与工程 2024年8期
陈晓, 张奇志*, 王鑫, 黄圣杰, 陈浩宇
(1.西安石油大学电子工程学院, 西安 710065; 2.陕西省油气井重点测控实验室, 西安 710065;3.西安石油大学新能源学院, 西安 710065)
在钻井作业过程中,由于地层复杂或司钻操作失误的影响,卡钻事故时有发生,导致对现场施工人员的人身安全造成极大的威胁。若不及时发现并采取措施,将导致危险情况延续,造成无法挽救的后果,如导致井眼报废等[1]。因此,对突发的卡钻事故及时的分析与预测,进而采取有效的预防措施,是对井眼与施工人员人身安全强有力的保护。但由于技术局限性,工作人员仅能通过传感器采集到的实时数据进行粗略的人为判断,人为主观因素使得判断的准确性差。
中外学者提出了许多方法来预测卡钻事故。苏晓眉等[2]为预测复杂钻井工况下的沉砂卡钻,使用K均值(K-means)聚类方式对数据进行训练以预测卡钻事故,但该方法需多次运行才能得到最优解。刘建明等[3]提出了基于主成分分析法(principal component analysis, PCA)与随机森林(random forest, RF)相结合的方法以预测卡钻事故,得出两者结合可提高模型的运算效率。富浩等[4]提出了一种基于PCA-SVM的预测方法,预测准确率高,但模型仅适用于井眼不清洁导致的卡钻事故预测,其他预测仍需要进一步研究。Nakagawa等[5]采用一种无监督的学习方法来预测卡钻事故,并将其应用于卡钻事件,发现在某些情况下,观察值和预测值之间的误差在卡钻之前就增加了,以此实现卡钻的预测将导致预测的准确性降低。Brankovic等[6]使用机器学习的方式建立了统计模型,将提取出的泥浆录井数据与历史卡钻事故结合,并根据建立的统计模型和实时数据,绘制动态卡钻预测的风险地图,验证该卡钻预测风险地图能够及时预测卡钻事故。
PCA是一种提取数据特征的方法,其在保留原有数据信息的基础上,通过降低数据维度来提高运算效率。支持向量机(support vector machines, SVM)在解决小样本和非线性问题中表现优异。经实验证明,麻雀搜索算法(sparrow search algorithm, SSA)的启发来源于自然界中的麻雀觅食过程。相对于其他智能优化算法,SSA在迭代时间、寻优精度以及稳定性方面表现得更加优异。基于此,首先应用主成分分析法对卡钻数据进行主成分的提取,然后建立ISSA优化SVM的卡钻预测模型,以提高对卡钻事故的预测准确性。研究成果可有效防范钻井过程中可能发生的重大事故,保护工作人员的安全和钻井设备的完整性,提高钻井作业效率。
1 麻雀搜索算法(SSA)
SSA是通过模仿自然界中麻雀的捕食和反捕食行为而得到的一种算法。群体中麻雀分为3种类型:发现者、追随者和警戒者。发现者获取食物的位置信息,并将其提供给整个麻雀群体。追随者在得知发现者提供的位置信息后去获取食物,并监视其他想要获取食物的发现者。根据不同情况,发现者和追随者的角色可以自由切换。当麻雀群体在觅食时,警戒者会发现危险并发出警告,一旦群体收到警告,就会立即采取反捕食行为[7]。
发现者位置更新由式(1)获得。
(1)

追随者按式(2)进行位置更新。
(2)
警戒者根据式(3)进行更新位置。
(3)
2 支持向量机(SVM)
SVM可用于线性可分问题的分类,通过找到最优超平面使数据点完全分离,并使距该平面最近的数据点到该平面距离最大[10]。这可以解决下述最优化问题。
(4)
式(4)中:i=1,2,…,l;ξi为松弛变量因子,ξi≥0;xi为第i个样本;yi为分类类别;ω为垂直于超平面的向量;b为偏移量;C为惩罚因子,当出现错误分类时C就会增大。
引入拉格朗日函数以求解式(4),即

(5)
式(5)中:α为拉格朗日方程的系数因子构成的向量;αi为拉格朗日方程的系数因子。
对式(5)中的ω和b分别求偏导,并令其等于0,解得式(4)的对偶问题,具体为
(6)
进一步解得,线性情况下的决策函数为
(7)
使用核函数将样本数据映射到高维空间,可以将一般非线性问题变为线性可分,核函数的表达式为
K(xi,xj)=φ(xi)φ(xj)
(8)
式(8)中:φ(xi)为将xi映射后的特征向量;φ(xj)为将xj映射后的特征向量。
径向基核函数表达式为
(9)
式(9)中:g为核参数。
同理,非线性情况下的决策函数得到如式(10)表达式,具体为
(10)
综上,使用SVM解决分类问题时,惩罚因子C和核参数g是影响分类结果的重要因素。
3 主成分分析法(PCA)
PCA本质上是一种提取数据特征的方法,它可在保留原有数据所包含信息基础上,降低数据维度,提高运算效率。利用PCA对钻井过程中收集的高维数据做降维处理,可减少数据冗杂造成的影响[11]。
假设存在n个样本数据,每个样本有p个指标变量,则可构建样本矩阵X,即
(11)
对式(11)中的样本矩阵X进行变换,PCA步骤如下。
步骤1对样本矩阵X中的每一个元素xij按照式(12)做标准化处理,具体为
(12)
步骤2根据标准化矩阵,得到相关系数矩阵R,即
(13)
步骤3计算式(13)中矩阵R的p个非负特征值,且满足λ1≥λ2≥…≥λp,以及对应的特征向量μ1,μ2,…,μp,重新构建线性关系,其表达式为
(14)
式(14)中:f1为第1主成分;f2为第2主成分;fp为第p个主成分;xp为第p个主成分的原始特征;μnp为第p个主成分中第n个特征系数。
步骤4计算主成分fj(j=1,2,…,p)的方差贡献率aj和累计方差贡献率bp,其计算公式分别为
(15)
式(15)中:λj为第j个主成分的方差;λi为i个主成分的总方差。
步骤5选取主成分个数。m(m≤p)个主成分的累计方差贡献率越接近100%,说明该m个主成分可以代表原始数据的信息[12]。
4 改进麻雀搜索算法(ISSA)
ISSA是种群智能优化算法,仍存在当算法搜索到全局最优解时,种群会趋于单一,导致难以跳出局部最优的限制问题。
4.1 自适应非线性惯性递减权重
研究指出,惯性权重参数在增强全局搜索能力和跳出局部最优方面起着重要作用。将此策略引入到发现者位置更新公式中,从而获得自适应非线性惯性递减权重ω的计算公式为
(16)
式(16)中:t为迭代次数;tmax为最大迭代次数;ω1和ω2为惯性调整参数,取ω1=0.9,ω2=0.4。
引入惯性权重ω后,发现者按照式(17)进行位置更新,具体为
(17)
式(17)中:i为第i只麻雀。
根据式(16)可知,在迭代初期,自适应非线性惯性递减权重缓慢衰减,有利于全局搜索,可更好地确定最优解位置。而在迭代后期,衰减迅速,有利于局部搜索,可缩短寻找最优解的时间[13]。
4.2 莱维飞行策略
莱维飞行策略(Levy Flight)适用于随机搜索,尤其是距离较短或随机距离较长的情况,通过进行更充分的全局搜索和局部搜索,可以使算法在寻找最优解时更为全面,同时更容易避免陷入局部最优的局限[14]。
Levy Flight的计算公式为
Lef=0.01s
(18)
式(18)中:Lef为莱维飞行路径;s为Levy Flight飞行步长,计算公式为
(19)
(20)
式(20)中:β一般取值为1.5。
σv=1
(21)
引入Levy Flight后,警戒者按式(22)更新位置,可表示为
(22)
5 ISSA性能测试
为验证ISSA在求解目标函数极值问题中的优越性及可行性,将ISSA与遗传算法(genetic algorithm,GA)、SSA、灰狼算法(grey wolf optimizer,GWO)在8个基准测试函数上进行对比测试。
5.1 基准测试函数
表1为测试函数表达式,从高维和低维对算法跳出局部最优的性能进行测试[15]。

表1 基准测试函数Table 1 Benchmark test functions
5.2 算法性能对比分析
为增强实验结果可信度、避免偶然误差,实验针对8种基准测试函数进行30次独立运行,使用30作为种群维度,最大迭代次数为1 000。实验结果如表2所示,平均值和标准差为评价指标。
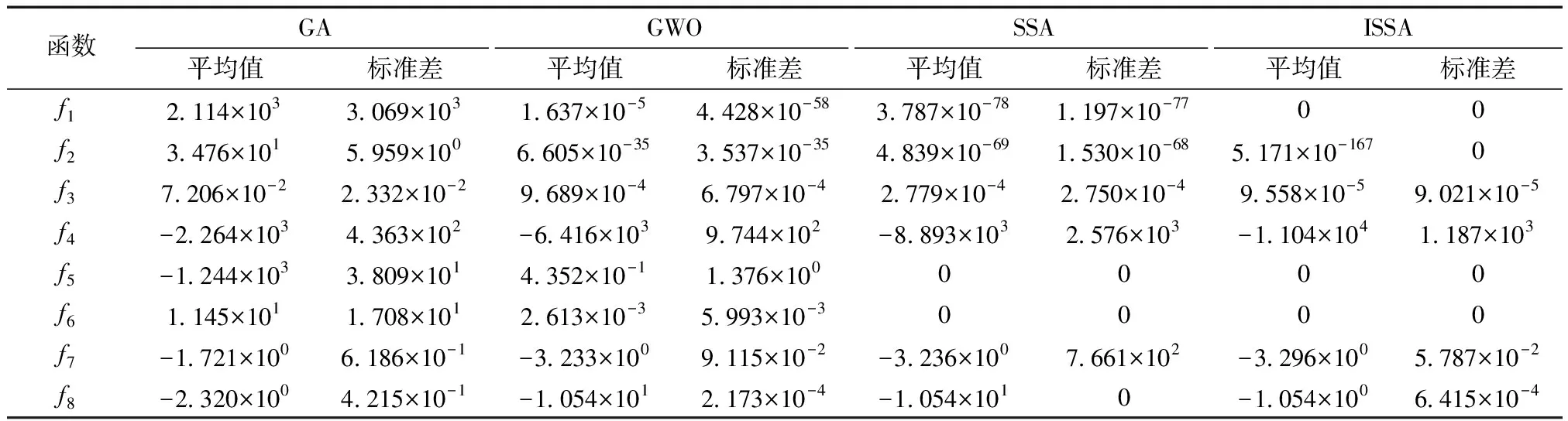
表2 基准函数优化结果比较Table 2 Comparison of optimization results of benchmark functions
由表2可知,在f1~f3高维单峰函数测试中,相较于其他算法,ISSA的寻优精度与稳定性均显著提升,且平均值和标准差提升了至少2个数量级;在f4~f6高维多峰函数测试中,ISSA的寻优能力相较于其他算法有显著的提升,且求解f5和f6时,ISSA和SSA的平均值和标准差均为0,为它们寻优能力相同。在测试低维函数f7~f8中,ISSA仍明显优于其他算法。综上,在单峰和多峰、高维和低维函数上,ISSA相对于其他算法,其求解精度有所提升,算法稳定性也更优。
6 ISSA-SVM的卡钻预测模型
6.1 PCA卡钻数据降维
实验所用的卡钻数据来自国外某大型油田,此油田共收集有1 600组数据记录。其中,400组为发生压差卡钻(differential stuck, DS)时的钻井数据;400组为发生机械卡钻(mechanical stuck, MS)时的钻井数据;400组为正常情况(non-stuck, NS)的钻井数据。数据记录共有10维特征,分别为:测深、泥浆比重、钻头大小、排量、初切力、终切力、扭矩、机械钻速、转盘转速和钻压。使用PCA对10个特征做降维处理,提取出的主成分方差贡献率和累计方差贡献率如图1所示。由于在10个特征信息中,3个主成分累计方差贡献率达到了88.841%,提取大于3个主成分,累计方差贡献率增长趋势变缓,即原始钻井数据的10个特征信息经PCA处理后大多集中在这3个主成分上,因此本次使用PCA卡钻数据降维选择提取3个主成分。部分卡钻数据如表3所示。

图1 主成分贡献率

表3 部分样本数据Table 3 Selected sample data
6.2 ISSA预测SVM流程
为预测卡钻事故,通过ISSA对SVM的惩罚因子C和核参数g进行优化。其优化流程图如图2所示[16]。

图2 ISSA-SVM流程图
6.3 ISSA预测SVM的卡钻预测实现
对卡钻数据降维提取出的3个主成分,按照7∶3的比例将DS、MS和NS的数据分成训练集和测试集进行卡钻事故的分类预测。建立ISSA-SVM、SSA-SVM、GWO-SVM和GA-SVM的分类预测模型。这4种算法分类预测的适应度曲线如图3所示。其中,最大迭代次数为100次,种群数量为20。

红实线为每次迭代的最佳适应度值;蓝色虚线为每次迭代的种群平均适应度值
从图3可以看出,为达到分类准确率的最佳适应度,ISSA-SVM仅需迭代10次达到85.185 2%的最佳适应度值。而SSA-SVM和GA-SVM则需要分别迭代23次和24次。GWO-SVM仅需迭代2次就可达到75.185 2%的最佳适应度数值,但最佳适应度数值小于ISSA-SVM。相较于其他优化算法,ISSA能更快速、精确的找出SVM的惩罚参数C及核参数g。
将4种算法分别用于优化SVM的C和g,构建卡钻分类预测模型,如图4所示。

图4 ISSA-SVM分类结果图
4种算法的卡钻事故分类结果如表4所示。通过4种算法的对比分析可知:GA-SVM和GWO-SVM卡钻分类预测模型准确率η相同,均为75.185 2%。ISSA-SVM的预测效果最好,预测准确率可达到85.185 2%,相比于SSA-SVM、GA-SVM模型的预测准确率分别提高了0.37%、10%。结果表明,ISSA在寻找最优参数方面速度快,分类预测准确率也更高,即ISSA效果显著。

表4 4种算法对比Table 4 Comparison of the four algorithms
6.4 混淆矩阵分析
使用混淆矩阵来验证基于ISSA-SVM的卡钻事故预测模型的准确性,并根据混淆矩阵计算出预测模型的准确率。混淆矩阵可以比较分类结果与实际值之间的误差,评判模型分类的优劣[17]。为了验证准确性,对270个训练集进行了混淆矩阵分析,并通过可视化展示结果,如图5所示。

类别标签0为正常情况;1为压差卡钻;2为机械卡钻
如图5所示,纵轴标签为预测类别,横轴标签为真实类别,精确率为模型预测值与真实值相同所占预测值的比重,识别类型为0、1和2的精确率分别为91.1%、80%和84.4%;召回率为真实值正确的预测值所占真实值比重,分别为90.1%、84.7%和80.9%;准确率为分类中所有判断正确的结果占总预测值的比重,为85.2%。识别类型为0、1和2时,精确度大于80.0%,总的来说,改进麻雀算法优化支持向量机的方法应用于卡钻事故是有效的。
7 结论
为预防钻井卡钻事故的发生,通过提出ISSA-SVM的方法,在位置信息中引入改进的自适应非线性惯性递减权重和Levy飞行策略,并利用PCA对数据做降维处理,建立用于卡钻事故预测的模型,得到如下结论。
(1)利用基准测试函数在寻优性能上分析得,在收敛速度和寻优精度上,ISSA相对于GA、SSA和GWO有优势显著。
(2)提出ISSA-SVM模型以用于钻井卡钻事故的预测,并采用PCA对钻井数据做降维处理,提取出3个主成分。结果表明:机械卡钻、压差卡钻和正常情况的分类预测准确率提升至85.185 2%,相较于SSA-SVM、GWO-SVM和GA-SVM卡钻预测模型,ISSA-SVM卡钻预测模型在预测准确率及运算时间方面有显著优势,鲁棒性更好,并利用混淆矩阵来验证基于ISSA-SVM的卡钻事故预测模型的准确性。综上,提出了一种可行的方法来预测钻井卡钻事故,该方法能够提供技术支持,帮助钻井过程中及时、准确地发现卡钻事故,减少不必要的损失。
猜你喜欢
海洋石油(2021年3期)2021-11-05
汉语世界(The World of Chinese)(2021年4期)2021-09-05
小哥白尼(趣味科学)(2019年5期)2019-08-27
青少年科技博览(中学版)(2019年1期)2019-04-25
好日子(2018年9期)2018-10-12
当代化工研究(2016年6期)2016-03-20
西南石油大学学报(自然科学版)(2015年5期)2015-04-16
天然气与石油(2015年2期)2015-02-28
重庆科技学院学报(自然科学版)(2014年5期)2014-09-21
