
融合领域词典嵌入的航空不安全事件命名实体识别
2024-04-01 05:12许雅玺孟天宇王欣刘炳南
科学技术与工程 2024年8期
许雅玺, 孟天宇, 王欣, 刘炳南
(1.中国民用航空飞行学院经济与管理学院, 广汉 618307; 2.四川腾盾科技有限公司, 成都 610037;3.中国民用航空飞行学计算机学院, 广汉 618307; 4.中国国际航空股份有限公司, 重庆 401120)
建设民航强国重要标准就是安全水平。随着经济发展,航空公司面临航班规模增大、安全要求提高的双重压力。航空不安全事件是指在民用航空器运行阶段或者机场活动区域内由于环境恶劣、机械设备故障、人员操作不规范等引起的与航空器有关、造成航空器损伤、人员伤亡或其他影响飞行安全的意外事件,主要包括民用航空器事故征候、事故以及一般事件信息,反映了航空安全水平。
现以从某航司获取的航空公司安全信息周报为研究对象,这是航空公司周期性的文本记录文件,记录每一周在航班运行过程中出现的不安全事件,是文本挖掘和自然语言处理技术的宝贵数据资源。
知识图谱是人工智能的前沿技术方向,是从非结构化的自然语言文本中提炼知识,实现认知智能的关键技术,包含命名实体识别、关系抽取、事件抽取、知识推理等任务。针对航空公司安全信息周报构建知识图谱,从不安全事件文本中提炼知识,发现运行中存在的安全隐患和问题,可以实现向数据驱动的智慧化、主动式安全管理的转变。
命名实体识别(named entity recognition, NER)是知识图谱构建的基础性任务[1]。其目标是从非结构化的文本中,自动化的提取出所需要的命名实体,并按照预定义的类别对其进行准确的分类[2]。提出一种高精度且泛化性较好的命名实体识别方法,具有重要的意义。
命名实体识别任务通常被建模成一个序列标注任务来处理,通过预测序列中的每个字或每个词对应的实体类型标签来实现命名实体识别,目前主流的方法是基于深度学习的方法。Huang等[3]提出基于双向长短期记忆网络(bi-directional long short term memory, BiLSTM)和条件随机场(conditional random field, CRF)的命名实体识别模型,将预训练后的词向量送入BiLSTM,不额外使用人工特征提取方法。通过双向的LSTM网络学习词的上下文语义信息,进一步送入CRF层,利用实体标签之间的相互依赖关系,搜索出最优的标签序列。王红等[4]面向民航突发事件数据开展命名实体识别研究,降民航突发事件命名实体类别定义为事发时间、航空公司、飞机型号等13类,提出基于BiLSTM和CRF的民航突发事件命名实体识别方法,为民航突发事件知识图谱的自动构建提供了数据获取方法支撑。孙安亮等[5]利用航空事故报道进行人工标注构建命名实体识别数据集,将航空事故命名实体分为飞行类别、型号等8类实体类别,提出基于BiLSTM和CNN的字词融合嵌入模型,有效提升了航空安全领域命名实体识别任务精度。
由于BiLSTM此类循环神经网络计算效率较低,传统卷积神经网络无法捕获长距离以来。Strubell等[6]将膨胀卷积应用在命名实体识别任务上,实现了利用卷积网络建模长距离以来,并行计算也使得模型训练速度大大提高。
随着深度学习技术的发展,Devlin等[7]提出基于Transformer[8]模型的大规模预训练语言模型BERT(bidirectional encoder representations from transformers),通过在大规模无标注语料库上的多任务预训练,结合微调的下游训练方式,在基于领域小规模标注数据的下游任务中取得极好的成绩。目前基于BERT预训练语言模型,衍生了众多预训练语言模型,如ERNIE(enhanced representation through knowledge integration,ERNIE)[9]、TinyBERT[10]、ALBERT(a lite BERT,ALBERT)[11]、RoBERTa(robustly optimized BERT pretraining approach,RoBERTa)[12]、MacBERT(MLM as correction BERT,MacBERT)[13]等。褚燕华等[14]基于BERT模型开展对数控机床故障领域的命名实体识别研究,取得了一定的性能提升。焦凯楠等[15]面向反恐领域,制定细粒度反恐实体标签体系,构建反恐实体语料集,基于BERT模型的变种MacBERT搭建命名实体识别模型,可以准确的识别反恐新闻中的重要实体。基于预训练语言模型解决命名实体识别等自然语言处理相关任务成为主流。
针对航空不安全事件知识图谱构建的基础性任务,进行航空不安全事件命名实体识别方法的研究。首先,充分分析航空安全信息周报数据特点,定义航空不安全事件命名实体类别,利用开源标注工具标注构建航空不安全事件命名实体识别数据集和领域词典。其次,针对主流的基于深度神经网络命名实体识别模型及大规模预训练语言模型对于实体边界信息的捕获尚有不足的问题,基于BERT预训练语言模型提出融合领域词典嵌入的航空不安全事件命名实体识别方法,实现领域实体语义信息增强,提高航空不安全事件命名实体识别的准确性。搭建相关模型进行实验测试,验证所提出方法的有效性。为航空公司文本数据分析提供了基础方法,推进基于数据驱动的主动式安全管理的发展。
1 航空不安全事件数据集构建
1.1 航空安全信息周报数据介绍
航空安全信息周报是航空公司以周为周期进行的不安全事件总结报告,包含航班运行过程中不同原因引起的航空不安全事件。本文数据集的构建使用2014—2016年的原始安全信息周报为基础数据,共150篇DOC文档。
1.2 航空安全信息周报数据预处理
原始DOC文档结构上分为主标题、期刊时间标题以及正文分类别的不安全事件内容。
对于航空安全信息周报原始DOC文档,无法直接进行内容读取,利用Python相关工具库对其进行格式转换,转换为TXT文档后,进行进一步的内容读取及处理。由于航空安全信息周报由不同人在不同时间进行撰写,文档存在一定的格式差异性,在对原始文档内容进行分析后,存在以下问题。
(1)正文事件日期信息不完整,缺少年份信息,在跨年周报中也有此种情况。以及部分仅说明时间,未提及日期的情况,如“21:32”。
(2)由于行业特殊性,部分内容较口语化,如“回京”“左发”“下”等,此种情况会使得计算机进行模型训练时出现偏差。
(3)由于不同人的撰写习惯,部分人员撰写时会附带自己对近期事件的总结及建议,对安全事件的数据分析来说属于冗余数据。
针对以上3种问题,制定以下规则进行数据处理。
(1)对于信息缺失的情况,利用正则表达式对其进行字符串匹配,基于文档时间标题对缺失年份及日期信息进行补全。对于跨年周报,对其月份进行判断,进而赋予正确的年份时间信息。
(2)对于不规范用语的情况,同样利用正则表达式进行全文匹配,对不规范处进行更改,如“回京”更正为“返回北京”“下”更正为“下降”。
(3)对于冗余信息,结合字符串匹配,人工进行筛选删除。
通过以上几种数据处理手段,对原始数据进行清洗,保证基础数据质量。对清洗后的数据进行事件提取,对所有文档中的事件,按类别存储为json文件。最终整理出共1 600条不安全事件数据。
不安全事件示例:2016年8月6日,重庆分公司机组驾驶B737-800/B-5426飞机执行CA761(扬州—中国台北)航班,起飞前机组对侧窗是否关闭并锁好检查不到位,起飞滑跑过程中速度约50 kn时,右侧窗打开,机组中断起飞。滑回后机务开、关右侧窗检查正常,放行飞机。
1.3 航空不安全事件命名实体定义及标注
通过分析航空不安全事件数据,查阅相关文献以及咨询相关领域专家,对航空不安全事件命名实体进行分类定义,共分为日期、机型等10类。利用开源数据标注工具doccano对数据进行命名实体标注,命名实体数据标注如图1所示。最终得到共29 151个命名实体,各类别实体数量统计如表1所示,总计29 151。至此完成航空不安全事件命名实体识别数据集的构建。
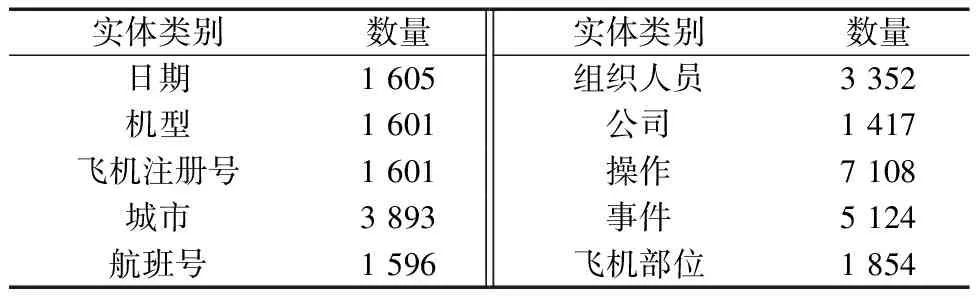
表1 实体数量统计Table 1 Entity Count Statistics

图1 航空不安全事件命名实体数据标注
对进行命名实体标注后的数据进行整理,将命名实体单独抽取出,整理为不重复的领域词典文件,共得到不重复的领域专有名词4 148个,用于命名实体识别模型中进行领域实体信息嵌入。
2 融合领域词典嵌入的命名实体识别方法
2.1 BERT预训练语言模型
BERT预训练语言模型,其基于Transformer编码器构建双向语言模型,相比较于Transformer解码器,编码器可以更准确地捕获预测信息,双向的语言模型也使得可以充分获取上下文语义信息,进而适应不同的下游任务。BERT模型结构如图2所示。
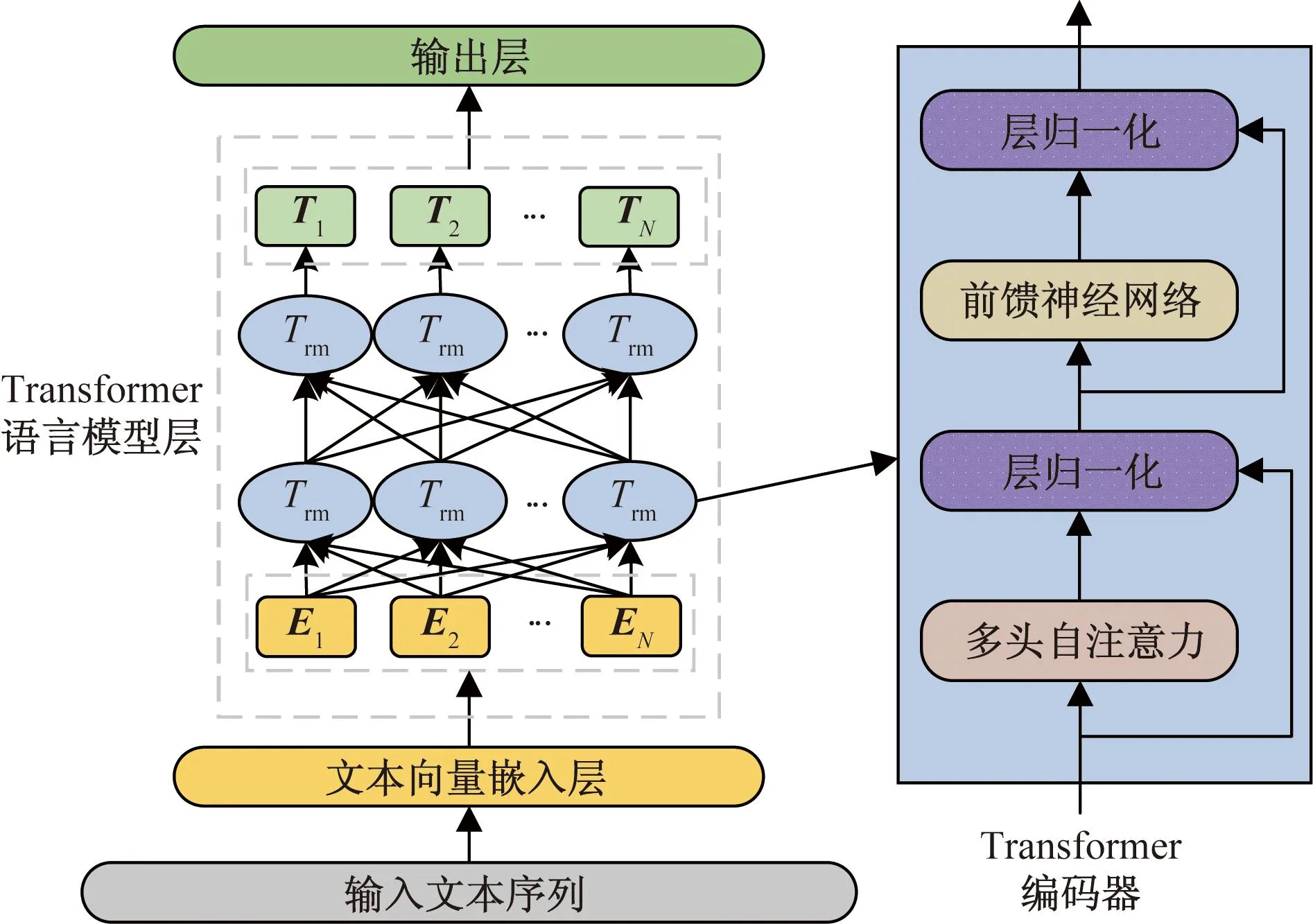
EN为输入词向量;Trm为Transformer编码器;TN为模型输出词向量
BERT设置了两种预训练任务,分别是掩码预测任务和下一句预测任务。因此在文本向量嵌入上,BERT使用了3种信息进行文本向量嵌入,分别是基础的字向量信息表示、基于句子分类的信息嵌入和位置信息嵌入,如图3所示。

图3 BERT向量嵌入
针对下一句预测预训练任务,BERT为输入句子增加了“[CLS]”标签和“[SEP]”标签,同时引入基于句子分类的信息嵌入,用以在进行下一句预测任务时对输入的句子对进行区分。针对掩码预测任务,在训练过程中,选择随机掩盖掉15%的输入,为了更好地进行掩码预测任务,在被掩盖掉的内容中,有10%的词会被随机替换为其他词,10%的词会保持原样,剩下80%会被替换为“[MASK]”标记,训练的目标即是预测被掩盖掉的词。
BERT在大规模预料上的多任务预训练使得其字向量表示具有丰富的语义信息,基于Transformer的双向语言模型,使得在下游任务微调训练时可以取得比LSTM等模型更好的效果。
2.2 融合领域词典嵌入的命名实体识别模型
中文文本组成不同于英文文本,英文文本由26个英文字母组成,可以由空格进行分隔并结合词根词缀进行词语表达。在中文文本中每个字均有其含义,多个字组成不同含义的词语,且在不同语境下,每个字词的含义均不同。自然语言处理任务中对于中文文本的处理,通常选用字向量嵌入或词向量嵌入的方法来建模文本特征。对于命名实体识别任务,字向量嵌入不能很好地识别实体边界,而词向量嵌入往往受限于分词的性能,且对于航空不安全事件此类领域数据来说,通用分词模型无法满足需求。为解决这一问题,在大规模预训练语言模型进行字向量嵌入的基础上,提出融合航空不安全事件领域词典进行词向量信息嵌入的方法来增强模型所获取的语义特征,利用领域词典来提高航空不安全事件领域命名实体分词准确性,进一步使得命名实体模型能学习领域实体边界信息。
融合领域词典嵌入BERT的航空不安全事件命名实体识别模型(char and word based BERT, CW-BERT)结构如图4所示。输入文本序列通过切字和依照领域词典切词后各自送入向量嵌入层进行向量表示,使用BERT预训练模型获取航空不安全事件的字向量表示,使用文本向量嵌入层进行航空不安全事件领域词向量的生成。而后将词向量表示映射到同字向量相同的维度,逐字进行字词向量融合,最终得到包含领域实体信息的字向量表示,基于此向量进行进一步的序列标签分类。
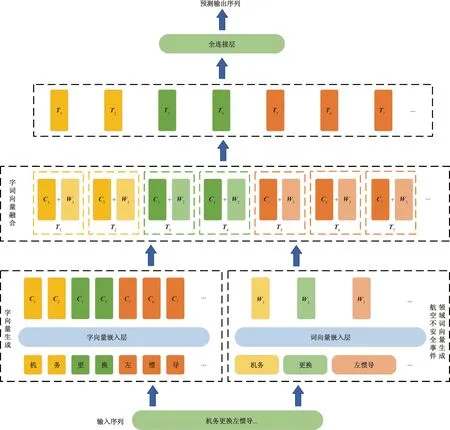
Ci为字向量;Wi为词向量;Ti为字词向量融合后的最终向量。
3 实验及结果分析
3.1 实验数据集及环境介绍
本次实验使用上文中以航空安全信息周报为基础构建的航空不安全事件命名实体识别数据集,共1 600条数据,分为10个类别领域实体,总实体个数29 151个。取全部数据用于实验,按照8∶2划分训练集和验证集,训练集和验证集各类别领域实体个数如表2所示。

表2 训练集及验证集实体数量统计Table 2 Statistics of the number of entities in the training set and verification set
本次实验在百度AI Studio深度学习平台下进行,硬件环境为Intel(R) Xeon(R) Gold 6148 CPU @ 2.40 GHz CPU、16 G RAM、Nvidia Tesla V100-SXM2-16 GB GPU,软件环境为paddlepaddle 2.4.2、paddlenlp 2.5.1、Python 3.8。
3.2 模型性能评价指标
命名实体识别任务通常处理为序列标注问题,其本质上为字符级别的多标签分类问题。本次实验采用常用的BIO序列标注方法,其中,B为某类实体开始标签,I为某类实体的后续部分,O为非实体类型。对于所构建的航空不安全事件命名实体识别数据集,共10类实体,即字符级别的21分类问题。
对于所构建的航空不安全事件命名实体识别数据集以及提出的融合领域词典嵌入的命名实体识别方法的精度验证,选用文本分类问题常用的精确率(P)、召回率(R)、F分数(F)作为评价指标,各评价指标表达式为
(1)
(2)
(3)
式中:F分数Fb是精确率和召回率的调和平均,可以更好地反应模型的整体性能;b为平衡精确率和召回率在F分数中的权重,一般情况下b的取值为1,也称为F1分数,即认为精确率和召回率同等重要,选用F1分数来作为模型综合性能评价指标;TP(true positive)表示预测标签为正样本且预测正确;FN(false negative)表示预测标签为负样本且预测错误;FP(false positive)表示预测标签为正样本且预测错误;TN(true negative)表示预测标签为负样本且预测正确。
对于多标签文本分类问题,在计算各个评价指标之前,需先计算出各个标签对应的二分类混淆矩阵,定义如表3所示。

表3 二分类混淆矩阵Table 3 Binary confusion matrix
而后计算各自标签下对应的精确率、召回率和F分数,需在计算标签一的混淆矩阵时,将标签一视为正例,其余标签视为反例来计算,将多标签文本分类问题视为多个文本二分类问题。
对于本文多标签文本分类问题,基于各类别的二分类混淆矩阵计算微平均精确率Pmicro和微平均召回率Rmicro,并基于此来计算微平均F分数Fmicro,用以评估模型整体的性能,Pmicro、Rmicro、Fmicro的计算公式为
(4)
(5)
(6)
式中:n为分类类别总数;i为某个分类。
3.3 实验数据集及环境介绍
模型训练时的优化器的选择,选用AdamW[16]优化器,它是在Adam[17]优化器加L2正则化的基础上进行改进的算法,解决了Adam优化器函数中L2正则化失效的问题,相比较于传统的随机梯度下降等优化算法有许多显著的优点。
为使得模型验证结果更加稳定及准确,所有模型测试均在相同随机数种子下进行。并在训练过程中加入早停机制,当模型F1分数连续下降4个Epoch或10个Epoch没有提升时提前结束训练。
为验证模型精度,选用主流的BiLSTM、BiGRU(bi-directional gate recurrent unit)以及IDCNN(iterated dilated convolutional neural networks)3个模型结合CRF进行对比实验。3个模型的相关初始参数如表4所示,批处理大小为64,初始学习率为0.001,向量嵌入维度为512。所提出的融合领域词典嵌入BERT的命名实体识别模型加载BERT-base模型,向量嵌入维度为768,初始学习率为0.000 1。

表4 对比模型初始参数Table 4 Initial parameters of compare model
最终各个模型验证结果如表5所示。可以看出,融合领域词典进行嵌入后的模型相比原模型在几乎不增加模型复杂度的情况下一定程度提高了命名实体识别精度,对于命名实体边界信息捕获较弱的模型的提升尤为明显。IDCNN模型得益于其网络结构,相比较与循环神经网络类的模型有着相对较好的效果。相比于传统神经网络模型,基于大规模预训练语言模型进行文本向量表示和特征提取效果更佳,所提出的融合领域词典嵌入BERT的航空不安全事件命名实体识别模型(CW-BERT)相较于主流的BiLSTM-CRF模型,F1分数提高了约5%。
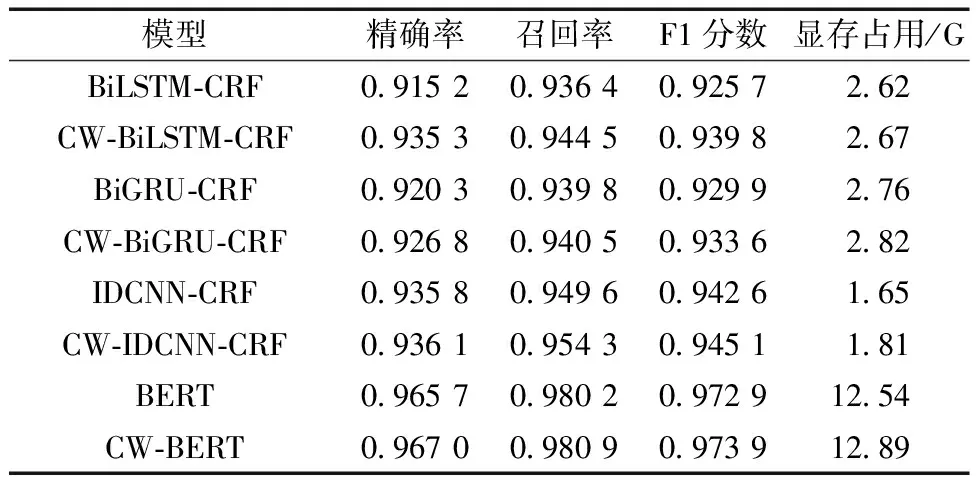
表5 模型验证结果Table 5 Validation results of models
所提出的CW-BERT模型在各个实体类别上的验证结果如表6所示。如日期、机型等相对具有一定规律或复用性较强的实体类别几乎可以实现完全正确的识别,对于操作、事件、飞机部位此类语义信息较为丰富且存在实体嵌套情况的实体类别也可实现高精度的识别。由于飞机部位此类实体样本相较于其他实体类别多样性更强,导致模型在学习时有一定的偏差,对于飞机部位实体识别精度有所欠缺,但也达到了较好的效果。

表6 CW-BERT模型验证结果Table 6 Validation results of CW-BERT model
4 结论
(1)智慧民航背景下,智能技术赋能航空公司安全管理是大势所趋。通过开展航空不安全事件命名实体识别方法的研究,为构建航空不安全事件知识图谱奠定基础,推动航空公司安全管理向数据驱动的智慧化、主动式安全管理转型。
(2)目前基于所构建的数据集,提出融合领域词典嵌入BERT命名实体识别方法,相较于传统神经网络模型有着更好的语义学习能力,一定程度提高了对于航空不安全事件领域命名实体边界信息的获取,但受限于数据的偏差性,性能提升仍有限。
(3)后续还需进一步扩充数据集,并针对不同参数进行调优,进一步优化模型。以及开展实体关系抽取研究,构建航空不安全事件知识图谱。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中国外汇(2019年18期)2019-11-25
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
华南农业大学学报(社会科学版)(2015年1期)2016-01-11
南风窗(2014年16期)2014-05-30
计算机与网络(2014年1期)2014-03-25
