
基于NB-IoT 与深度学习的校园用电监控及预测
2024-04-16 03:25吴游龙彭晨席云李龙祥李军
电子制作 2024年6期
吴游龙,彭晨,席云,李龙祥,李军
(吉首大学 通信与电子工程学院,湖南吉首,416000)
随着电力系统向交互性和智能化的方向发展,传统电力系统已较难适应现代电力需求,因此智能电网近几年来成为研究热点[1]。智能电网往往利用各类通信技术采集负荷数据进行分析和预测,以更好地实现电力供应和需求之间的平衡,有学者提出物联网在智能电网中有着广阔的应用前景[2~3]。目前大型负载级别的分析和预测较为常见,而在大学校园与一般办公区域的负荷分析预测仍然较少[4]。主要原因在于此类小型负载用电规律性不强,使预测结果往往存在较大偏差。同时,由于用电采集设备成本的限制,使采集到的用电数据往往存在部分异常和空白时段。本项目中,笔者用电气测量装置结合窄带物联网(Narrow Band Internet of Things,NB-IoT)技术对学校办公大楼的用电数据进行采集;采集到的用电数据在通过多层清理后,消去了空白时段与异常点,数据质量得到了提升。同时,为了改善校园级的小型负载用电情况规律性不强对预测结果的不良影响,本文采用Informer 神经网络模型进行负荷预测。该模型本为长时间序列预测设计,在应用于本项目时也改善了短期数据规律性不强的影响,提高了时间序列预测的推理速度及预测结果的准确性[5]。
1 数据采集系统的实现
■1.1 开口式电流互感器
常规的电流互感器通常是闭合磁路,采用闭合磁路可以确保磁路中的磁阻抗较低,有效地将一次侧的电能传输到二次侧端。然而,此类设计有一个比较显著的缺陷:若一次侧的电流中有直流分量,将导致磁路的磁阻非常低,使得闭磁路内存在较高的直流磁通量,最终导致铁芯磁化曲线工作点进入饱和区,造成测量误差。针对传统电流互感器的固有缺点,本项目采用了开口式电流互感器。它的工作原理是在磁路上插入一个空气隙的磁阻,以减少一次侧的直流成分对铁芯所产成的磁通[6]。由于铁芯的磁导率要大于空气的磁导率,所以其仍能形成较高的磁阻,从而确保电流互感器芯磁化曲线的工作点在线性区域,采用的开口式电流互感器参数规格为200/5A。
■1.2 NB-IoT 技术
近几年来NB-IoT 通信技术在各类智能表数据采集传输中应用得越来越广泛,是当前物联网发展的主流技术之一。NB-IoT 技术属于低功耗广域网,其依托3GPP 技术规范而制定,具有低功耗、低成本、高连接能力、强覆盖能力等优点。不仅可以应用于地下室或隧道等偏远恶劣用电负荷的终端,而且能满足各类超远程、多终端的智能装置的数据采集及通信需求[7]。
■1.3 工科楼实时负荷数据采集
本系统使用准同步采样,准同步采样是指被采样周期信号的周期T 不等于采样周期ts 的整数倍的采样[8]。使用开口式电流互感器与依托A/D 转换器计量芯片的采集器对负载端开展实时采集,每隔6 分钟对系统电气量进行一次采样,通过采集系统收集到的数据为:单、三相电压电流及有功功率、无功功率。同时为了增强所搭建的数据采集系统的数据传输覆盖率,使用NB-IoT 通信技术对其数据进行传输。如图2 所示,搭载NB-IoT 的数据采集电表,可将采集数据经窄带开关系统(Narrowband switching system,NBSS)通过NB-IoT 网络实时传输至IoT 平台,实现数据的高效采集,再由算法程序整理为excel 表格,每一个时刻的数据都会打上相应的时间戳,方便后续的数据分析与预测工作的展开。
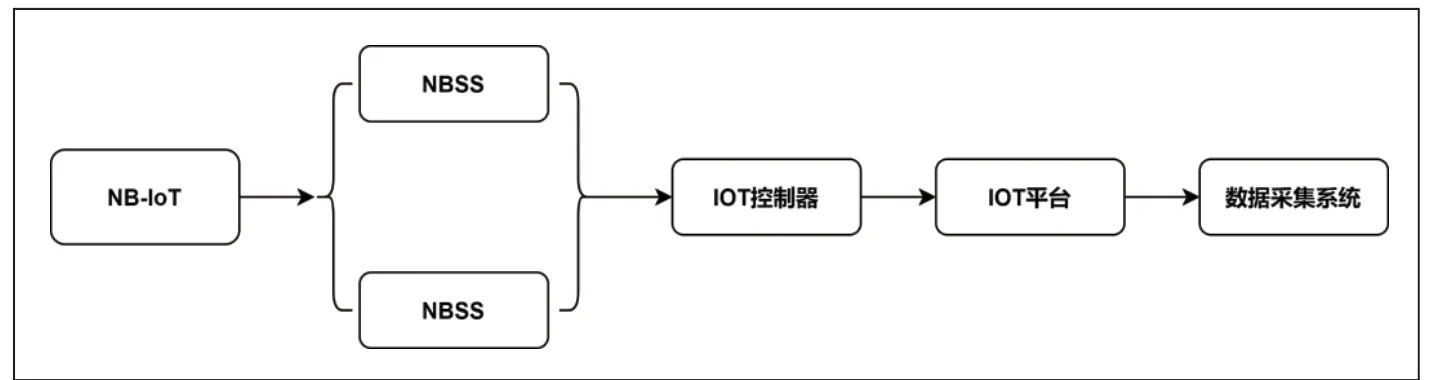
图2 NB-IoT 数据传输原理图
2 数据预处理
数据预处理是时间序列分析和预测的重要步骤,本研究使用了pandas_profiling 进行探索性数据分析。分析结果表明,数据集中存在部分异常点和零值。故在数据预处理阶段须对这些异常点剔除,零值进行插值填补,下面展示数据处理前后的情况。
■2.1 总体数据情况
图3 给出了所采集数据的总体概况,包括变量个数(Number of variables)、 样 本 行 数(Number of observations)、缺失行数(Missing cells)、缺失率(Missing cells)、重复行数(Duplicate rows)、重复率(Duplicate rows)等。如图4 所示,经过预处理后的数据缺失率达到0%,重复率0%。

图3 原始数据总体概况
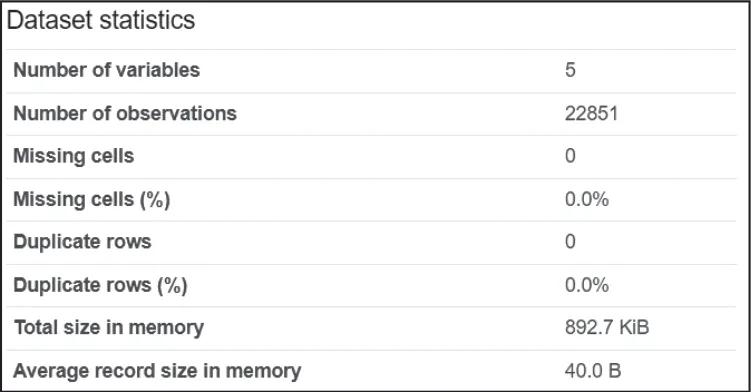
图4 预处理后数据总体概况
■2.2 单变量分析
从单变量分析的结果亦可看出预处理后效果,如图5所示,单相电压值个数为1011,其中最大值为243.9,最小值为0,对其进行预处理后,缺失率由原先的43.3%下降至小于0.1%。

图5 原始单相电压

图6 预处理后单相电压
利用相同的方法对单相电流、单相有功功率进行预处理后,使数据缺失率均降至0.1%左右。
■2.3 相关性分析
在统计学上,Pearson 的线性相关系数是衡量两个变量X、Y 的相关性的度量标准,其数值在[-1,+1]之间[9]。假定存在X、Y 这两个变量,那么用如下公式可以得到X 与Y 之间的 Pearson 系数:
其中E 是数学期望,cov 表示协方差。在此,需要指出,Pearson 相关系数只是其中可能性之一,而要利用Pearson 线性相关系数,就必须假定这些数据是由正态分布对得到的,同时数据必须是等间距的。当两个条件不一致时, Pearson 相关系数可以用可以使用 Spearman 相关系数替代。
而对于Spearman 相关系数,其是一个非参数性质(与分布无关)的秩统计参数,用来度量两个变量之间联系的强弱[10]。假设X 和Y 为两组数据,则Spearman 相关系数计算公式如下:
其中,d i为Xi和iY之间的等级差,ρ位于-1 和1 之间。图7 为预处理前后的Pearson 和Spearman 相关矩阵输出。通过数据处理后,两两变量间的相关性水平整体得到纠正,其中电流与有功功率的相关性接近于1,符合功率计算准则。

图7 预处理前后的Pearson 和Spearman 相关矩阵输出
3 Informer 预测模型
本研究使用神经网络模型Informer,预测方法如图8所示。模型主要由四个部分组成,分别为探索性数据分析模块、编码器、解码器以及全连接神经网络。输入数据先经过数据分析及处理,以抽取并推导出对实现工科楼负荷预测有价值、有意义的数据。接下来,编码器负责将输入的负荷特征序列进行编码,映射为包含输入特征信息的中间向量。解码器负责将编码器输出的中间向量解码为输出序列,训练好的模型通过全连接层获得最终的预测结果。

图8 预测流程图
■3.1 编码器
编码器主要由自注意力机制和蒸馏层组成。Informer模型中的自注意力机制通过较少的计算量从输入的负荷特征序列筛选出少量最重要的信息,使得模型聚焦于最为重要的信息上多头注意力机制可以从不同的表现子空间聚焦于重要信息,从而避免严重的信息损失。蒸馏层通过一维卷积和池化操作实现降维,可以起到减少维度和网络参数量的目的。
编码器的核心原理为多头概率稀疏自注意力机制。与Transformer 中的自注意力机制一样,多头概率稀疏自注意力机制也是通过计算特征向量间的相似度来表征相关性,以此解决长距离依赖问题。不同的是多头概率稀疏自注意力机制计算复杂度大大减少了。Informer 通过Kullback-Leibler 散度公式区分每一个查询矩阵的概率分布和均匀分布的相似性从而筛选出重要的查询矩阵。通过随机选择U 个点积对计算注意力使得复杂度降低,选出其中的 u 个对注意力贡献最大的查询矩阵计算特征矩阵的注意力值,最终的计算公式如下:
式中:Q的平均为筛选后的查询矩阵,K为键矩阵,V为值矩阵。
■3.2 生成式解码器
解码器包含多头掩码概率稀疏自注意力层与多头概率稀疏自注意层。将掩码操作应用于注意力的计算中,可以防止每个位置都关注未来的位置,从而避免了自回归。解码器中的自注意层与编码器中的不同,其键矩阵K 与值矩阵V 来自编码器的输出,查询矩阵Q 来自多头掩码概率稀疏自注意力机制模块的输出。最后,通过一个全连接层获得最终的对工科大楼照明预测的结果。Informer 所提出的生成式解码器只需一个前向步骤即可得到所有的预测结果,提升了长序列预测的速度,同时也避免了误差的累积。
4 实验结果分析
■4.1 数据集
实验使用的是校园工科大楼的用电数据,该数据集以分钟级别记录了工科大楼2021 年上半年期间的用电情况。数据集包含了单相电压、三相电压、频率及总有功尖电量等数十种电力数据类型。其中,单相电流、单相电压、单相有功功率以及日期特征被作为模型输入,功率因素作为模型预测的目标值。训练集/验证集/测试集的大小分别为4/1/1个月。
■4.2 评价指标
为了评估Informer 模型对于工科大楼用电负荷预测的能力,本研究采用了两个常用的评价指标,平均绝对误差(Mean Absolute Error ,MAE) 和 均 方 误 差(Mean Square Error,MSE)。
式中n 为训练样本的个数,yi表示工科楼实际历史负荷值,^yi表示模型输出的预测值。MAE 和MSE 取值范围都在[0,+∞)之间,其值越接近0,说明预测模型拥有更好的效果。
■4.3 实验参数设置
Informer 预测模型的编码层与解码层的参数分别设置为3 和2,所有的多头注意力层的头数均为8。初始学习率设置为0.0001 并随机初始化权重矩阵。Log-cosh 被用作损失函数并以Adam 优化算法进行训练。批次大小设置为32,epochs 总数为6。
模型以Pytorch 深度学习框架实现,数据集的输入均采用零归一化以消除不同量纲在回归预测中所带来的误差。
■4.4 结果分析
随机选取连续三天的上午、晚上和下午的时间段,图9 展示了采用Informer 算法作为预测模型时,功率因素(Power factor)真实值与预测值的对比。其中Ground Truth 为真实值,Prediction 为预测值,评价指标MSE 值0.796、MAE 为0.690,且由图可以看出Informer 模型能够在一定程度上较好地拟合实际值曲线。

图9 预测结果对比图
5 结语
电力负荷预测的准确性对于发电容量调度和电力系统管理具有重要意义。本研究将基于NB-IoT 技术的电流互感器安装到校园工科大楼配电箱,获取了工科楼的用电数据,并进行了全面的负荷分析、预测。其预测结果在一定程度上可以较好拟合实际的负荷曲线,其分析与预测方法将可推广到智能电网、用电负荷数据挖掘以及非侵入式故障检测等方向的研究。但是其仍然存在一定的进步空间,如数据集时间跨度不够,应最好超过一年,使得预测结果更加规律准确。其次可以使用校历信息,如节假日标签、学院活动标签等。因此可以针对此类问题做出进一步的完善与改进,其预测结果将会更加准确与科学。
猜你喜欢
先锋(2022年9期)2022-05-30
中国市场(2021年34期)2021-08-29
科技创新导报(2021年34期)2021-04-13
成都信息工程大学学报(2018年3期)2018-08-29
制导与引信(2017年3期)2017-11-02
电子设计工程(2017年20期)2017-02-10
工业设计(2016年11期)2016-04-16
电子器件(2015年5期)2015-12-29
环境科技(2015年6期)2015-11-08
无锡职业技术学院学报(2015年3期)2015-02-28
