
基于语音识别的摩尔斯码训练系统研究
2024-04-16 03:25张骁韩凯
电子制作 2024年6期
张骁,韩凯
(海军潜艇学院,山东青岛,266000)
0 引言
摩尔斯码又被称为摩斯电码,是通过点、划、点和划之间的停顿、每个字符之间的停顿以及单词之间的停顿来实现不同的英文字母、数字和标点符号发送的编码方式。从19 世纪初开始,摩尔斯码就广泛应用于电报通信、紧急救援以及军事通信中,至今仍是一些紧急情况下的备用通讯形式。尤其是在舰船和陆地之间、舰船之间的通讯中,摩尔斯码发信作为稳定、简捷的通讯手段,是部分专业船员的必修课程。
摩尔斯电码对应的字符是全球统一的,直接采用代码发送的文字字符称作明码,也就是不加密的信息,任何收到明码的电报员都可以通过电码表翻译出发送者的原文。[1]摩尔斯码收发信通常需要结合灯光进行,通过目力观察灯光闪烁的长短和间隔,来实现报文内容的收发。海上收信环境复杂,要求船员对摩尔斯码非常熟悉才能准确收到报文,这需要通过持续性的日常训练维持收信水平。以往的摩尔斯码的训练以一人发送、一人手抄练习为主,效率低且受场地制约较大。使用智能终端为载体,基于Android 平台开发以语音识别为主的摩尔斯码训练系统能很好地解决船员出海时摩尔斯码的日常训练问题,大大提高船员摩尔斯码训练水平。
1 语音识别的技术原理
语音识别从根本上来说是根据语音特征参数的模式识别,目标的语音输入后经过预处理阶段,随后通过具体的识别系统提取目标声纹特征,再根据重复性训练的成果,将输入的语音按一定特征模式进行归类并保存下来。当再次遇到输入的语音后,系统将结合目标声纹特征,选取与之匹配的声纹类别,从而实现语音识别的目的。目前,大多数语音识别系统中都已经应用了模式匹配这一原理,图1 是基于模式匹配原理的语音识别系统框图。

图1 基于模式匹配原理的语音识别系统框图
模式识别一般包括预处理、特征提取、模式匹配等基本模块。预处理又可以分为分帧,加窗,预加重等,是对目标输入的语音信号进行初次处理,以凸显其声纹特征。其次是特征提取,对采集到的声音信号特征提取,从而区分不同的声音信号,根据声纹特征选择合适的特征参数。语音识别之前,要针对要识别的语音对识别系统进行重复性的训练,根据语言中的规律,将音素或音素序列转化为文本信息,最后根据失真判决准则来实现语音识别。
2 语音识别的摩尔斯码训练系统设计
■2.1 系统总体设计
摩尔斯码标准是通过时间间隔来进行分辨的。在发送摩尔斯码时,一个点的时长是一个单位时间,一个划的时长是三个单位时间,点和划之间的间隔是一个单位时间,字母之间是三个单位时间,单词之间是七个单位时间,通过灯光明暗、声音持续时间等来体现时间间隔。对于训练系统的设计,首先要解决的问题就是如何将摩尔斯码的发送,通过训练设备外置的灯光信号实现,从而通过灯光信号完成人机交互。
我们将信号的发送部分设置为亮灯,间隔部分设置为灭灯,通过控制亮灯和灭灯时长来实现摩尔斯码的发送。例如摩尔斯码:-...(B)..(I) --.(G) -.-.(C).-(A) -(T)可以转换为二进制:1110101010001010001110111010000000111010111 0100010111000111,根据此序列设计程序来对外置灯光进行控制,从而实现对摩尔斯码的发送。
其次要达到阶梯型训练目的,在系统设计上要实现发送速度的可调节性,通常根据受训者的学习阶段不同,训练系统要完成每分钟30 码~45 码的发送速度调节。在输入发送报文后,系统将要发送的报文所包含的字符量根据上述规则转化为单位时间,再根据受训者设置的发送码速计算单位时间的发送时长,通过软件控制一个单位时间的实际时长,从而实现对发送速度的调节。
最后要满足船员训练的实时性和便捷性,在系统中加入语音识别功能。由于灯光信号的训练需要受训者同步翻译成明码报文,采用打字输入的方式会影响到后续报文的接收。所以在接收到灯光信号后,通过麦克风说出接收到的摩尔斯码代音的方式能很好解决这一问题。训练系统实时识别语音内容并判断对错,记录在训练系统后台,在本次训练结束后显示正确率及错误点,能够有效帮助船员及时了解自己不足并进行纠错。
■2.2 语音识别模块设计
目前人工智能在语音处理方面已经达到了比较精确的阶段,但是基本上都需要连接互联网来实现功能。由于船员出海训练时经常会处于无网络状态,所以本系统需要在不联网的情况下进行语音识别,这就需要对摩尔斯码语音识别方面进行深入研究。经过对比选型,科大讯飞的离线产品可以基本满足不联网状态下语音识别的要求,通过不同船员提供的大量语音训练模型,可以使训练系统的语音识别率准确度达到90%以上,识别响应时间小于1s。
语音识别技术中的特征提取是语音识别技术应用的关键部分,将标准语言通过 AI 处理技术转换成数字信息,并从中提取出需要的特征参数[2]。为了便于区分不同摩尔斯码,不发生混淆,我们在训练时经常将摩尔斯码的读法通过代音来区别,例如将字母k 读作客人,r 读作日光等,这一训练方法也可以应用于语音识别当中。代音读法可以在训练中增强特征参数,提高语音识别成功率。
船员训练时通过语音收集装置将声音以波的形式录入到智能终端中,录入的声音文件通常需要转成非压缩的纯波形文件来处理,如wav 文件就是常用的文件形式。wav 文件里存储的内容包含一个文件头,以及声音波形的一个个点,便于我们提取出声音的分段波形。图2 是提取的一个声音波形示例:零零客人日光(00kr)。

图2 提取声音波形示例
声学模型的建模也即对似然概率部分的建模,即给定文本序列之后生成对应语音的概率, 是整个语音识别中最核心的部分,也是最复杂的部分[3]。在开始语音识别之前,首先需要用到信号处理技术把首尾端的静音切除,降低对后续步骤造成的干扰,这种静音切除的操作被称为VAD。对于浊音音素,声带的振动产生谐波丰富的声音,具有50~250 Hz 之间的明显音调。所有元音及也有一些辅音,可能会表现出这种谐波结构,因此这种特征被认为是语音的特征。然而单独使用基于谐度或基于音调的特征不能预期无声语音部分(例如一些摩擦音),所以在静音切除时要避免误识别。如图3 所示,是字母c “瓷器”的发音,上方波形是未进行降噪和切除静音,下方是进行降噪和静音消除之后的波纹。

图3 VAD 前后声音波纹对比
在此基础上要对声音进行分析,就需要对声音进行分帧,也就是把声音切开成一小段一小段,每小段称为一帧。通过分帧处理,我们可以将声音波形分成数段,便于对波形进行深入分析。此时声音波形的特征并不凸显,为了提取声音波形的特征,我们要对波形进行变换。常见的一种变换方法是提取MFCC 特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。这个过程叫做声学特征提取[4]。在提取到一定数量的声学特征后,将声学特征输入到训练系统中,通过机器学习进行训练,并形成声学模型。在程序调用过程中会根据实际输入的声音,通过模型对比分方式来获取对应的文字。如图4 所示,分别是两个“瓷器”的发音,经过模型对比计算可以对应出“瓷器”词组,从而实现摩尔斯码的语音识别功能。
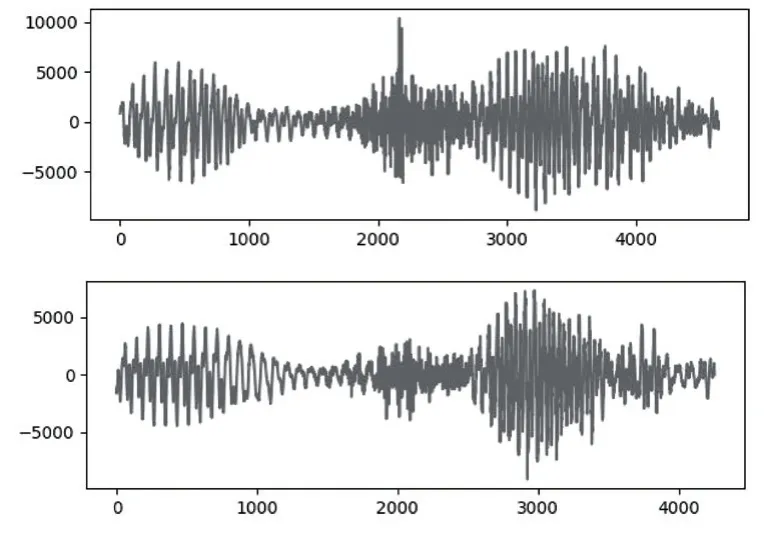
图4 声学模型对比图
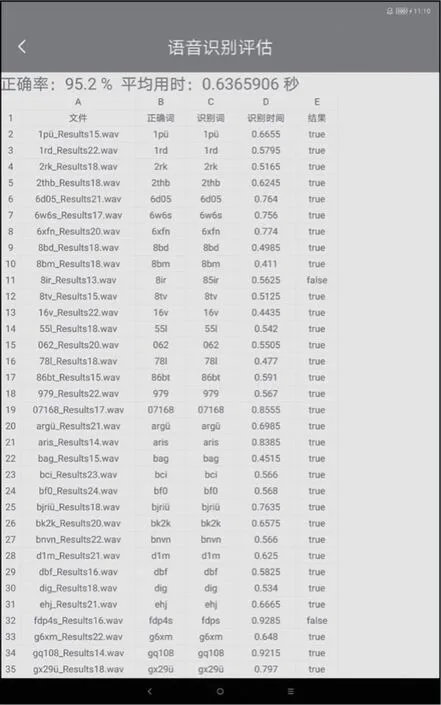
图5 语音识别效果评估
同理,系统通过不断的训练将逐步完善声学模型,将摩尔斯码的字母、数字、符号与各个代音关联起来,从而实现训练中的实时语音识别和纠错功能。在识别过程中可能会遇到同音汉字词组的产生,可以采用词组声母识别的方式可以消除同音词和音类似词的混淆。
3 训练系统软件设计
■3.1 Json 结果解析
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它使用易于读写的文本格式来表示数据对象。JSON 是一种常见的数据格式,主要用于传输数据。科大讯飞返回是json 格式,首先要对返回的 JSON 格式的数据进行解析,具体代码如下:

进行结果解析之后,我们就可以将声音波形与预先训练的模型进行匹配,从而转换为实际读出的中文文字,接着进行下一步识别。
■3.2 语音识别功能实现
通过解析可以得到返回的中文文字,此时将得到的中文文字通过代音对应的方式转为相应的字母,便于进行下一步识别:

再根据模型结果进行语音识别过程,通过声学模型对比的方式进行匹配,部分摩尔斯码识别过程示例如下:


经过测试比对,此系统的语音识别率达到95.2%,识别时间平均时长为0.63s,通过实机测试,能够满足船员摩尔斯码离线语音识别学习训练需求。
4 结论
基于语音识别技术的摩尔斯码训练系统研究,在Java编程技术基础上对语音识别系统的功能实现、程序代码进行了设计。同时基于语音识别完成了人机交互系统的设计,将摩尔斯码训练通过语音识别功能进行实现。结果表明,该系统能够满足船员摩尔斯码训练需求,其在系统的测试中展现出良好的识别率和识别速度,可用于船员摩尔斯码日常学习训练中。
猜你喜欢
水上消防(2021年4期)2021-11-24
中国特种设备安全(2021年9期)2021-03-02
河北画报(2020年10期)2020-11-26
小哥白尼(军事科学)(2018年12期)2018-12-19
测控技术(2018年2期)2018-12-09
英美文学研究论丛(2018年2期)2018-08-27
通信电源技术(2016年3期)2016-03-26
防灾减灾学报(2015年3期)2015-12-16
新疆大学学报(哲学社会科学版)(2015年1期)2015-10-13
雕塑(2000年4期)2000-06-24
