
基于分布式模型的流域地表水质模拟和污染来源识别方法研究
2024-04-30 15:01杜承阳吕森伟叶振宇林奕影章思捷
环境科学与管理 2024年3期
杜承阳 吕森伟 叶振宇 林奕影 章思捷


摘要:针对地表水控制断面污染物浓度预测和污染来源识别问题,以河道控制断面汇流区为基本单元,发展了直排源和非直排源负荷计算方法,基于大数据分析方法识别基本单元的污染物迁移转化主控过程划分了参数区,提出了分布式流域地表水质模拟方法和污染来源识别方法。分别采用瓯江一级支流好溪流域2018年-2022年水文流量、氨氮(NH3)和高锰酸盐指数(CODMn)浓度监测数据进行了参数率定和模型验证。结果表明:在89.448%的因子覆盖率的情况下,将好溪流域分为4类参数区,模型能够有效的模拟流域水质变化以及识别主要污染原来区域。
关键词:地表水水质;大数据分析;物理模型;好溪流域
中图分类号:X830.2 文献标志码:B
1 研究背景
动态掌控流域地表水中污染物的来源及其成因,是实现流域污染精准治理的基础。由于污染来源多样、驱动一迁移转化过程复杂,以及下垫面因子高度时空变异性等原因,难以直接確定污染负荷。
目前对流域地表水污染预测以及成因解析的方法主要可以分为二类,第一类基于分布式流域水文和污染负荷模型(如SWAT模型,HSPF模型),基于物理方法模拟流域内各种污染物的迁移转化过程,确定在断面的污染物浓度,需要详细的水文、气象、水质监测等参数,并且由于河道污染负荷是多个过程叠加的结果,通常难以实现对地表水污染的来源的精确追溯。第二类模型通过了解流域内污染负荷与各种因子之间的统计关系,基于因子的变化预测断面水质变化,包括LSTM模型,BP模型等。结合两种方法的优点,实现污染物迁移转化驱动因子诸多、迁移转化过程复杂条件下的流域水质预测和快速成因解析,对提高流域污染管控能力具有重要意义。基于以上需求,文章发展了一种流域地表水水质预测和污染来源快速解析方法,在丽水市瓯江一级支流好溪流域进行了验证分析。
2 数据与方法
2.1 研究区概况
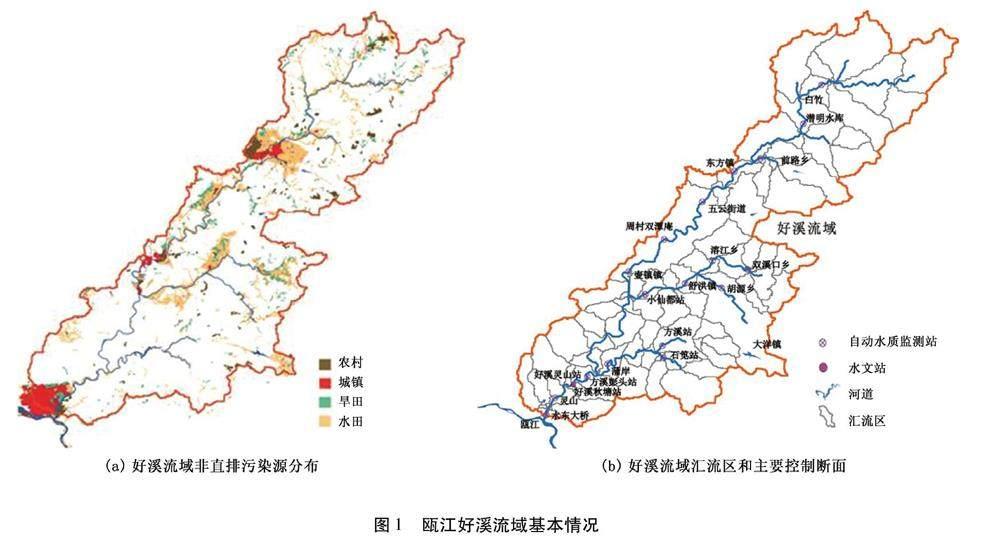
好溪为瓯江一级支流,干流总长为45km。流域面积1305km2。流域地形高程为36-1025m。流域年多年平均降雨量1571mm,土壤主要包括红壤、黄壤、紫色土、粗骨土和水稻土,分别占流域面积的36.93%、24.37%、1.40%、24.34%和11.91%-流域内的主要污染负荷来源(农村生活、城镇、农田等)如图1(a)所示。好溪流域水系和水文、水质监测断面以及汇流区划分如图1(b)所示。流域内设有秋塘水文站,水东大桥等河道控制断面水质一动监测站。每4hr对氨氮(NH4)、高锰酸盐指数(CODMn)等水质指标进行一次监测。
2.2 控制断面污染负荷模型构建
河道中污染负荷的变化主要受到直排源(工业点源、城镇污水处理厂以及其他直接排入河道的污染源强)和非直排源(降雨冲刷形成的面源以及地下水出流本底源强)的影响。
2.2.1 直排源负荷
基本单元i内直排源达到控制断面的污染负荷如式(1):
f1,i=Qp,icp,iexp(-k1R-k2li/v) 式(1)
其中,Qp,i为单元i内全部直排污水排放量,cp,i为直排源污染物的平均浓度(由丽水市缙云县和莲都区排污口监测数据确定),li为基本单元i到控制断面的距离,R为降雨量,k2为河道中基础流量(90%枯水年最枯月平均流量)对应的污染物自净系数,v为基础流量对应的流速,k1为反映河道中自净能力随河道流量增加的系数。
2.2.2 非直排源对河道污染负荷
根据降雨径流曲线法,降雨形成的污染负荷表示为式(2):
控制断面汇流区的污染负荷为内基本单元(数量为n)负荷的累加:
2.3 基于大数据解析的参数分区
基于30m精度DEM,将好溪流域划分为87个基本单元图1(b),参数的初始值基于scs法取值,计算各单元的污染负荷以及叠加后在控制断面形成的通量。各基本单元之间的协方差矩阵为[r]ij,其中:
式(4)中,xi和xj分别为基本单元i和基本单元j的污染物浓度的时间序列,Cov(·)为协方差,σ(·)为标准差。基于矩阵正交求解协方差矩阵的特征值,特征值大小表征矩阵正交之后所对应特征向量对整个矩阵的贡献程度,即为主成分影响力度大小的指标。若特征值小于1,说明该主成分的贡献力度不如直接引入原变量的力度大,特征值大于l的情况下,作为独立因子。累积贡献率即因子对原始变量的整体贡献程度。
3 结果与讨论
3.1 参数分区与率定
流域87个基本单元污染负荷协方差矩阵特征值分析结果如表1所示,结果表明,特征值大于1.0的条件下,可将流域分为4类汇流区的情况下,全部因子对监测信息的累积贡献为89.448%。
在此基础上,将流域分为4类参数区,采用控制断面2018年-2021年水质监测数据参数率定。用Nash-Sutcliffe系数,相对均方根误差对模拟误差进行评价。参数率定结果如表2所示。采用率定参数,以实测气象和直排污染源为驱动因子,对2022年1月-10月的流域断面的污染物浓度变化和贡献率进行了模拟。如图2(a)、图2(b)所示模型验证期的降雨量(缙云县),好溪出口断面(水东大桥)NH3和CODMn模拟和实测结果的比较。采用率定参数,模型验证期NH3和CODMn模拟和实测均值的偏差分别为9.23%和7.20%,模拟值和实测值标准差的平均偏差分比为15.35%和2.34%,表明模拟值的变化区间与实测值一致。NH3和CODMn实测值的均值±标准差分别为0.114+0.070mg/l和2.226+0.727mg/l,模拟值的均值±标准差分别为0.124±0.046mg/l和1.934±0.727mg/l,N_S效率系数介于0.523-0.622,相对均方根误差介于0.054-0.168之间。表明所采用的方法模拟地表水质具有良好的精度。
NH3的模拟浓度与实测值的偏差小于CODMn的偏差,以溶解态形式为主的NH3的模拟精度更好,是由于所采用方法对于各种主控过程均采用了集总式的方法进行计算,在CODMn包括了更多形态和迁移方式的情况下,集总式的方法不可能避免的产生更大的误差。
3.2 主要负荷贡献区模拟分析
如图3(a)-图3(c)所示水东大桥断面日降雨量分别为0、19.4mm和30.4mm条件下的NH3主要来源区域的分布。在降雨量为0的情况下,主要污染负荷区与直排源强分布一致。随着降雨量的增强,首先是Ⅲ类参数区的贡献率增加,其实是IV类参数区的贡献率增加,然而NH3负荷的分担比例则随着降雨量的增加而下降,Ⅰ类参数区,对NH3负荷的影响非常小。
图3(d)为19.4mm降雨量条件下,CODMn高负荷区的比较,与图3(c)比较可以看出,NH3和CODMn的主要污染分布区域显然不同,CODMn主要来源于Ⅱ类汇流区,并且CODMn贡献率分布的集中程度也明显的超过NH3贡献率分布的集中程度。
3.3 与SWAT模型对比分析
分布式流域水文和污染负荷模型,如SWAT模型,描述了陆面一河道完整水文和污染物迁移转化过程,模型本身则包括了大量的参数。文章所提出的方法,采用大数据方法,通过主控因子识别,保留89.448%的污染成因的条件下,将流域部分分为4类水文区,每一类水文区包括7个参数,描述了污染物达到控制断面整个迁移转化过程,在保留主控物理机制的情况下,极大的削减了模型参数。相比SWAT等分布式模型,文章所采用提出的方法在快速识别主要污染区域方面具有更大的灵活性。
文章提出的模型与SWAT模型在物理机制上,均为均衡模型,以集总的方式考虑污染物迁移的动态过程对浓度变化的影响。因此,在物理机制上,率定的参数是设定时间步长的最优解。因而模型设定的时间步长发生变化,模拟精度将在一定程度降低。
SWAT模型等物理模型的误差成因主要在于:模型各种物理过程的概化(如采用线性过程对非线性过程进行近似)和误差的传递性(如SWAT模型首先模拟流量和泥沙过程,水文模拟过程误差的传递与水质模拟本身模拟误差的叠加造成了水质模拟误差显著的超过了水文过程的模拟误差)。在大部分流域,尽管水文流量的N_S系数能够达到0.7,但水质指标的模拟误差通常很難超过0.6。文章所发展的模型,误差产生的原因主要是两个因素,影响控制断面水质各种因子总的覆盖度为89.448%,显著降低模型参数数量的情况下,同时也有10.5%的因子覆盖度并没有考虑,一定程度造成了计算偏差。此外,相比SWAT模型,文章对于各种污染物的物理化学和生物过程所采用的是集总式的方法,陆面水文过程和河道水文过程中污染物各种转化过程的速度显著不同,在时间步长较小的情况下,集总式的方法相对更为准确的反映了各种物理、化学和生物过程叠加对污染物浓度产生的影响,文章中模型的时间步长为4hr,较好的模拟了污染物的动态过程也表明了这一现象。
4 结论
发展了一种流域地表水质预测和主要负荷来源区识别的方法,通过大数据进行主控因子识别和参数分区,显著的减少了分布式模型的参数数量。在浙江省丽水市瓯江一级支流好溪流域应用结果表明,该方法经过参数率定后,有效的识别流域污染负荷及其来源。NH3和CODMn浓度模拟值的系统性偏差小于10%,N_S系数超过0.5。此方法直接建立了污染源一径流条件一污染负荷的关系,从而实现了污染负荷贡献率的直接核算。
猜你喜欢
中国水土保持(2022年6期)2022-06-08
韩国语教学与研究(2022年3期)2022-02-08
今日农业(2021年11期)2021-11-27
中国水土保持(2021年7期)2021-07-08
环境科学研究(2021年6期)2021-06-23
环境科学研究(2021年4期)2021-04-25
中国水土保持(2021年12期)2021-04-11
少儿科学周刊·儿童版(2021年23期)2021-03-24
水利规划与设计(2018年1期)2018-01-31
电力自动化设备(2015年4期)2015-09-28
